Abstract
The purpose of this article is to present a framework for capturing and analyzing social media posts using a sentiment analysis tool to determine the views of the general public towards autonomous mobility. The paper presents the systems used and the results of this analysis, which was performed on social media posts from Twitter and Reddit. To achieve this, a specialized lexicon of terms was used to query social media content from the dedicated application programming interfaces (APIs) that the aforementioned social media platforms provide. The captured posts were then analyzed using a sentiment analysis framework, developed using state-of-the-art deep machine learning (ML) models. This framework provides labeling for the captured posts based on their content (i.e., classifies them as positive or negative opinions). The results of this classification were used to identify fears and autonomous mobility aspects that affect negative opinions. This method can provide a more realistic view of the general public’s perception of automated mobility, as it has the ability to analyze thousands of opinions and encapsulate the users’ opinion in a semi-automated way.
1. Introduction
Autonomous transportation modes have been a popular field of research, as increasing the autonomy of vehicles has a vast impact on everyday life, as well as the way that a lot of current business is conducted. For example, the introduction of autonomous vehicles promises to completely change the way in which mobility and transportation logistics are dealt with. The introduction of a fully automated and autonomous transportation system can mimic the revolution of the early 20th century and its introduction of motorized vehicles that allowed the transportation of large loads in a faster and more efficient manner [1]. This promised revolution needs to overcome one major obstacle, beyond the technical barriers, to be established as an integral part of modern life, user acceptance.
User acceptance has been a key performance indicator in the development of novel transportation modes; however, the way that this is currently measured is mostly by using traditional methods such as focus groups and questionnaires. These methods, though effective, can only reach a limited number of people that are usually geographically adjacent. Moreover, the recruitment approaches in such focus groups present difficulties on their own [2,3]. To this end, a novel popular mode of measuring public opinion has been the analysis of social media data, which allows the integration of social theories with computational methods, as “Social Media Mining is the process of representing, analyzing, and extracting actionable patterns from social media data” [4]. This social media mining process can then be used in combination with deep machine learning (DML) techniques. DML uses robust statistical models and natural language processing techniques to assess the user’s sentiments, identify the principal components of their opinion, and derive their “polarity” towards a studied subject.
1.1. Previous Work
As mentioned before, the acceptance of autonomous transportation has been a well-studied topic, with a plethora of previous assessments of user opinions. The research work presented in [5] studies the acceptance of autonomous public transportation modes using a series of interviews, while [6] studies on-demand business models of autonomous mobility. One of the most recent studies [7] also tries to identify gaps and suggest measures and best practices.
However, the most objective outcomes of such analyses come from reaching as many people as possible and trying to include individuals with varying backgrounds, locations, and levels of interest in the user group. Social media mining and natural language processing offer an effective set of tools in this and have been used in a large number of applications such as stock market prediction [8], disaster relief [9], various stressful events [10], and autonomous cars [11]. Finally, even in the bounded field of social media natural language processing, there is a plethora of approaches that utilize various models, such as rule-based approaches [12], unsupervised methods [13], and attention models [14].
This work presents a procedure that aims to elicit the main fears and reservations of the general public towards autonomous modes of transportation. To achieve this, a sentiment analysis framework was used, based on the mining of relevant social media data. The strategy of mining social media data was selected as a means of targeting a large sum of opinions, and since social media mining allows a direct connection between the analyzer and the general public, supporting the breakdown of their raw opinion in a more objective way. This paper presents the structure of such a framework, the data capturing process, as well as the results of the sentiment analysis performed on the captured social media posts. We aim to (i) present the current acceptance levels of autonomous mobility and (ii) determine the main fears that reduce that level of acceptance.
The rest of this work is organized in the following way. Section 2 formulates the problem and presents the mathematical basis of our approach. Section 3 discusses the available data captured by two popular social media platforms, Reddit and Twitter. The results of our analysis are presented in Section 4. This paper ends with our conclusions in Section 5.
1.2. Relevant Previous Studies
There are a number of studies that analyze the current status of acceptance of autonomous mobility as well as identify current gaps and propose ways of moving forward.
Reference [5] presents an experiment that assess user acceptance in the case of autonomous public transportation modes. Even before the execution of the experiment, a number of passengers indicated that they had concerns about the safety of the used Autonomous Vehicle (AV) shuttle bus; however, after participating in the shuttle ride, these issues seemed resolved, and the main concern about safety was limited to the way the AV shuttle braked during the identification of an obstacle. Moreover, on-demand models and their acceptability were studied in [6]. There, the authors even make the distinction between acceptability, view of a product before its use, and acceptance, view of the product after the user has used it and familiarized themselves with it. The researchers used a mixed methods approach, complementing acceptance questionnaires with a psychological needs-driven approach using UX cards in an effort to understand underlying factors that influence acceptability and acceptance. Again, the main issue expressed was safety, and the trend of users accepting the safety of an AV after they used it, even if they expressed concerns beforehand, continued. [6] studies on-demand business models of autonomous mobility. One of the most recent studies [7] also tries to identify gaps and suggest measures and best practices.
However, the most objective outcomes of such analyses come from reaching as many people as possible and trying to include individuals with varying backgrounds, locations, and levels of interest in the user group. Social media mining and natural language processing offer an effective set of tools in this that has been used in a large number of applications such as stock market prediction [8], disaster relief [9], various stressful events [10], and autonomous cars [11]. Specifically, [11] uses social media posts to mine the opinions towards fatalities with self-driving cars. This work focuses on the views of autonomous mobility before and after an accident that claimed the life of one pedestrian as described in [15]. To assess the changes in views, [11] analyzed the comments under self-driving related videos in YouTube. The results can be viewed in two different word clouds, presented in Figure 1a for before the crash and (b) for after.

Figure 1.
Word clouds generated (a) before and (b) after the killing of a pedestrian by an autonomous Uber truck [11].
2. Problem Formulation
Extracting information about the sentiments behind social media texts can be modelled as a classification problem, where we try to assort all the captured social media posts based on their overall sentiment intensity. Thus, we use an architecture that performs binary classification of a social media post, assigning it into one of two classes. These classes represent positively inclined opinions, i.e., posts that express positive feelings towards autonomous mobility, and negatively inclined opinions, i.e., posts that express negative feelings.
The identification of such sentiment values from social media posts is an arduous and complex task, the performance of which is bounded by the model’s properties and the inherent limitations of the captured data. For this reason, we employ a tool based on a machine learning framework that receives the captured text as input and returns the sentiment assessment of this post in the form of a class label. It should be noted that this architecture uses a model specifically trained to classify the sentiment polarity of similar data. In this section, we present briefly the mathematical formulation behind our approach.
Let us denote as a 2 × 1 vector that contains the probabilities PP and PN that the nth post can be classified as expressing positive or negative sentiments (class P and N, respectively). Let us now assume that there is a non-linear function that relates probabilities with some measurable observations . In the following notation, we assume that are multidimensional tensors of the input data. Assuming a non-linear dependency of the classification output and the previous classification values, we derive a non-linear autoregressive model:
where refers to the non-linear relationship and q expresses the order of the model. Vector is an independent and identically distributed error. Equation (1) cannot be easily calculated, as is unknown. The use of machine learning methods can produce an approximation of in a way that minimizes the error . A feed forward neural network (FNN) can approximate such a relationship, given sufficient relevant training data. However, this FNN model fails at effectively selecting features of high-dimensional space and complex heterogeneous input data (i.e., social media text). Deep learning architectures, however, have proved especially accurate in extracting features [16,17,18]. For extracting representative features, the Bidirectional Encoder Representations from Transformers (BERT) model [14] has presented state-of-the-art results in a wide variety of natural language processing (NLP) tasks. This type of feature extraction can apply bi-directional training to the transformer, allowing a non-causal analysis. The term non-causal analysis means that the assessment uses both previous and future instances. This means that while we assess the emotional polarity of a word, we use both previous and future words appearing in the posts to optimize the classification. This allows our approach to capture long-range dependencies with the use of a bi-directional long short-term memory (LSTM) network. LSTM networks are of a similar structure to the bidirectional recurrent regression models, but each node in the hidden layer is replaced by a memory cell, instead of a single neuron. The architecture of the memory cell is presented in Figure 2.
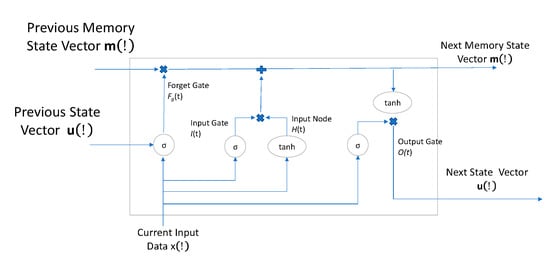
Figure 2.
The architecture of the memory cell for long short-term memory (LSTM) networks.
The basic unit of an LSTM is the memory cell. It consists of four components as shown in Figure 1, (i) the forget node, (ii) the input gate, (iii) the internal state, and (vi) the output gate. Each component non-linearly relates the inner product of the input vectors with appropriate weights, estimated via a training phase. The non-linear activation function adopted for the components is the sigmoid denoted as σ and the tanh. The forget gate throws out (forgets) information from the memory cell to model long-range dependence. The input node is the same as a hidden neuron, measuring the contribution of a hidden state to the final classification outcome. The internal gate decides if the respective hidden gate is ”significant enough” for the classification. Finally, the output gate regulates whether the response of the current memory cell is significant enough to contribute to the next cell.
After the input layer receives the current data/post, we transform the input data so as to maximize the classification performance. These transformations are executed over the input data and a set of kernels, in order to select appropriate features using a specialized transformer encoder, presented in Figure 3a. BERT makes use of transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. In its used form, transformer includes two separate mechanisms—an encoder that reads the text input and a decoder that produces a prediction for the task. Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary. An example of how this decoder works is presented in Figure 3b. In contrast to sequential models, which are often employed, BERT is considered bi-directional, as it analyses the entirety of a sentence at once. This results in the model learning the context of a word based on all its surroundings.
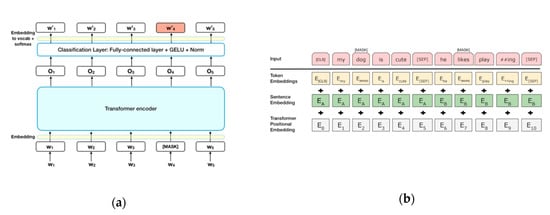
Figure 3.
(a) Transformer encoder (b) Bidirectional Encoder Representations from Transformers (BERT) process [14].
The kernel parameters are estimated in a way that minimizes the performance error on a ground-truth training set. The L feature maps, denoted as f1, f2, …, fL, are used as inputs in the final (classification) layer. The final component of the filter is the classification layer that receives the f1, f2, …, fL feature maps and triggers a supervised behavior classification.
The classification layer consists of r neurons, each stimulating a non-linear operation, where the sigmoid is neuron activation function. If we denote as the weights that connect the i-th feature map with the j-th hidden neuron of the classification layer, then the output of this neuron is , where is the aggregate feature map concatenating all features and the aggregate weights for the j-th hidden neuron. Then, output is given as:
where u includes all outputs over all the r hidden neurons and v the aggregate weights connecting the r hidden neurons of the classification layer with the output neuron. In Equation (2), expresses the input of the final output neuron before applying the activation function . In the previous notation, we assume that the classification output consists of one neuron. Extension to multiple neurons is straightforward. Subscript w in Equation (2) denotes the dependence of the classification on the network weights, which is estimated through a learning process. In our configuration, the proposed model consists of two output neurons. The classification output can be modelled in the following way:
Equation (3) means that the nth post is assigned to the class with the maximum probability. It is obvious that in our framework . Beyond the assigned classification label, we use as an additional qualitative metric.
Technical Architecture: Technical Workflow
All the aforementioned systems for the data capturing and the classification were implemented in Python using a number of relevant libraries such as PRAW (for Reddit data capturing), search-tweets-python (for data capturing on Twitter), and PyTorch (for the machine learning components). The machine learning systems were trained using the Stanford Sentiment Treebank [19], a widely used dataset for sentiment classification.
The overall architecture of the machine learning system is presented in Figure 4.
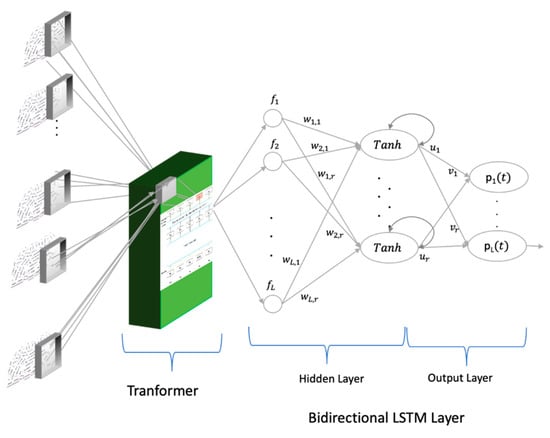
Figure 4.
Overall system architecture.
3. Dataset Description
3.1. Targeted Social Media Platforms
Nowadays, there is a plethora of social media platform types, based on the type of the user, type of content, etc. For our analysis, we captured data from two main types of social media, social networks and discussion forums. The parameters that led to this selection were (i) data availability, (ii) ability to collect data in a way that adheres to all relevant national and EU regulations and laws relevant to data privacy, and (iii) the popularity of the platform in order to capture an as objective as possible image of the current sentiments of the general public towards automated mobility. Thus, this analysis was performed over two social media platforms, namely Twitter and Reddit.
Twitter is a microblogging social media service, where users express everyday events and opinions in a concise and size restrictive manner. As of 2018, Twitter has more than 321 million active online users and approximately 500 million individual posts per day [20]. Moreover, Twitter offers a comprehensive application programming interface (API) that allows users to query its content repositories, through specialized endpoints, facilitating specialized data capturing activities.
Reddit, similar to Twitter, is a social media service that offers discussion forum services to its users. Contrary to Twitter though, its content is organized in a thematic way, through a large number of individual bulletin board types of forums, named subreddits. As of July 2019, Reddit is the 13th most popular website globally, with more than 330 million active users [21]. Similar to Twitter, Reddit offers a dedicated API service that allows users to traverse its content. Moreover, due to the thematic nature of its content sorting, can be used to capture data only from specific subreddits that are thematically relevant to our endeavors.
3.2. Data Capturing Lexicon
There are several terms used to describe how automation and control will be incorporated into transportation modes in the future. Several modifiers are used interchangeably in the press and scientific literature, such as:
- automated
- autonomous
- connected
- connected and automated
- connected and autonomous
- driverless
- self-driving
Thus, there was a need to create a lexicon of relevant terms that were used in our queries for data capturing social media data. The starting point of populating this lexicon was the European Commission’s STRIA “Roadmap on Connected and Automated Transport” [22] as well as various academic publications [23,24,25]. These works led us to the construction of a lexicon of keywords that were in turn fed into the Twitter Data Streaming API to receive all relevant posts. As it was critical that we captured a more up-to-date picture of the public’s view on our topics of interest, we limited the captured data from the 1st of May 2015 onwards. In the Reddit case, the lexicon was used to identify relevant subreddits that were queried through the corresponding Reddit API.
The list of terms used to query the aforementioned APIs is presented in Table 1.

Table 1.
Lexicon of terms used in the data capturing process.
These terms were selected based on experiments that assessed the number of posts they captured as well as the relevance of the posts with the Drive2theFuture project.
3.3. Data Capturing Per Social Media Platform
3.3.1. Twitter
During the data capturing process, a total of 8143 tweets were captured and analyzed. These data were in turn filtered to keep the most significant posts. This filtering initially removed all hyperlinks and mentions to other users. Moreover, non-textual tokens of the post, e.g., emojis, were replaced with a relevant keyword. For example, the  emoji was replaced by its keyword, i.e., (angryface). The resulting post was kept only if it complied with some qualitative metrics that made it possible to assess its sentiments. These metrics were (i) the length of the processed text must be at least 3 words and (ii) the resulting text must contain a verb. Essentially, tweets with the length of at least one full sentence were kept.
emoji was replaced by its keyword, i.e., (angryface). The resulting post was kept only if it complied with some qualitative metrics that made it possible to assess its sentiments. These metrics were (i) the length of the processed text must be at least 3 words and (ii) the resulting text must contain a verb. Essentially, tweets with the length of at least one full sentence were kept.
emoji was replaced by its keyword, i.e., (angryface). The resulting post was kept only if it complied with some qualitative metrics that made it possible to assess its sentiments. These metrics were (i) the length of the processed text must be at least 3 words and (ii) the resulting text must contain a verb. Essentially, tweets with the length of at least one full sentence were kept.This initial processing step took place in order to maximize the performance of the sentiment analysis tool by filtering out unnecessary data. After this filtering, a total of 5047 tweets were then fed into the sentiment analysis tool. The overall steps of the workflow can be seen in Algorithm 1.
| Algorithm 1: Data Mining Process for Twitter |
|
3.3.2. Reddit
The lexicon of Section 3.1 was used to identify relevant subreddits. This process identified five relevant subreddits, namely “Autonomous News”, “Autonomous Cars”, “Transport”, “Self-Driving Cars”, and “Autonomous Boats”. Using the Reddit API, we captured and analyzed all the posts in these subreddits as well as their first level comments (note: Reddit comments are organized in a nested structure, where Level 1 comments are directed to the posts, Level 2 comments are directed to Level 1 comments, etc.).
A total of 576 posts and 228 comments were captured. The same prefiltering was performed in these posts and comments, as in the Twitter case. This resulted again in omitting posts and comments that were simply announcing innovations or new products or where the length of the text was too small to be considered. This resulted in 495 total posts and comments that were analyzed. The overall steps of the workflow can be seen in Algorithm 2.
| Algorithm 2: Data Mining Process for Reddit |
|
4. Results
4.1. Overall Scores
In this section, we present the results of the classification task. Each individual tweet, Reddit post, or Reddit comment was fed into the sentiment analysis tool, which returned a classification label (either positive or negative polarity of the post). Beyond the classification outcome we also used the classification confidence score (i.e., the probability of each score to be labelled in a specific class). It is worth mentioning here that normally, confidence score is not used in such a way. This is because high probability of assigning a post in a class depicts the confidence of the machine learning model to assign a specific label and not a more positive/negative opinion. However, here we can safely make the assumption that higher confidence score can be translated in a clearly more positive/negative opinion. This is due to the character limitations and the conciseness of a social media post. This assumption, however, is not valid when analyzing longer more elaborate texts (e.g., online articles).
4.1.1. Twitter
The Twitter posts expressed a positive opinion towards autonomous mobility 61.66% of the time; this can be seen in Figure 5.
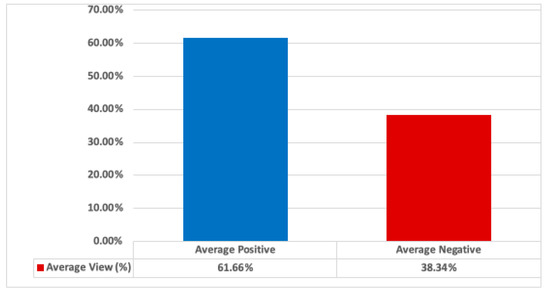
Figure 5.
Percentage of Twitter Posts expressing a positive/negative opinion.
Moreover, using the confidence scores we can visualize the overall distribution of the scores in a scatter diagram, as seen in Figure 6. This reveals that out of 5047 analyzed posts, 3342 expressed either highly positive or highly negative opinions (i.e., the probability of assigning them to the “positive opinion” class was respectively higher than 90% or lower than 10%). The breakdown of the confidence value of the all the captured tweets can be viewed in Figure 7.

Figure 6.
Scatter diagram of opinions expressed in the captured Twitter posts.
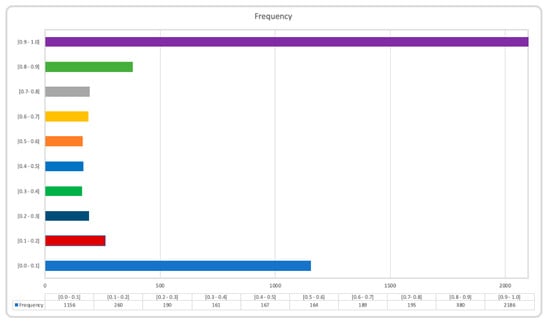
Figure 7.
Frequency of posts in each category (Twitter).
4.1.2. Reddit
A similar breakdown of opinions can be viewed when analyzing Reddit posts, though in the case of Reddit there is a more positive view of automated mobility. A total of 71.72% of the posts expressed a positive opinion, as seen in Figure 8. The more positive demeanor expressed in the analysis of Reddit posts can be explained by the way that Reddit organizes its content in a thematic way (in contrast to the user-centric way that Twitter organizes each result). This means that people participate in the analyzed subreddits choose to do so and have a higher interest in autonomous mobility than normal. However, we still identified negative opinions from those users 28.28% of the time.
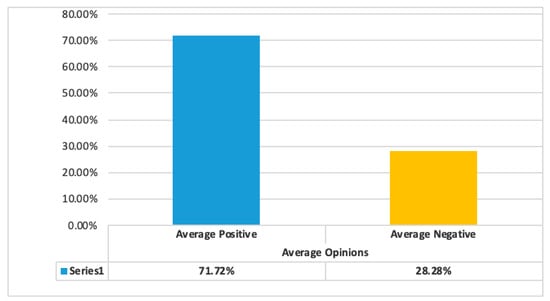
Figure 8.
Reddit breakdown of opinions.
Similar to the Twitter analysis, through the confidence scores we can visualize the overall distribution of the scores in a scatter diagram, as seen in Figure 9. This reveals that out of 576 analyzed posts/comments, 352 expressed either highly positive or highly negative opinions (i.e., the probability of assigning them to the “positive opinion” class was respectively higher than 90% or lower than 10%). The breakdown of the confidence value of the all the captured tweets can be viewed in Figure 10.
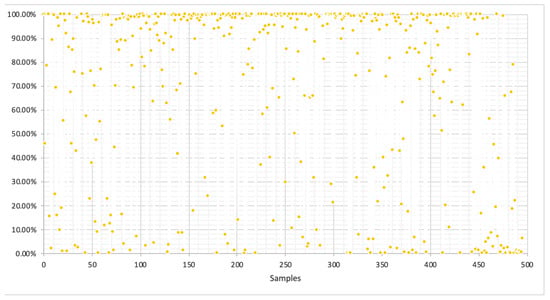
Figure 9.
Scatter diagram of BERT confidence levels for Reddit posts/comments.
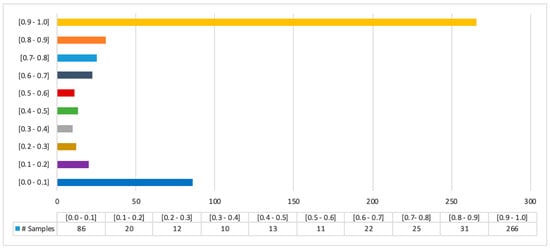
Figure 10.
Frequency of exported confidence levels of Reddit posts/comments.
4.2. Discussion of Results
A simple enumeration of the analysis results is not considered enough for the mission of this study. Beyond the statistical breakdown of the general public (as expressed in social media posts), we need to identify user fears and specific aspects of autonomous mobility that can affect user acceptance. To this end, we proceeded in an analysis of the negative opinions captured, trying to determine the specific facets of autonomous mobility that drive these opinions.
Technophobia is probably one of the main issues. An overall 30% of the general public is estimated to be affected by technophobia [26]. Specifically, in the negative opinions, a higher frequency of mentions of cyber-security, robotics, and hacking, combined with safety concerns, was observed in 42.55% of posts labeled as negative.
Another driving force of negative opinions were employment issues. It was observed that a frequent mentioning of “professional” terms was expressed in negative views of the public. A total of 32.41% of negative posts mentioned such fears. This was particularly evident in the “Autonomous Boats” subreddit, where 100% of negative opinions mentioned reductions in personnel.
Finally, a number of other issues were observed, such as:
- Fears due to the probable presence of both autonomous and conventional mobility solutions, i.e., users seem more fearful of a combination of autonomous and conventional traffic, such as the possibility of human error that an autonomous driving program could not anticipate;
- Issues regarding the insurance of autonomous cars and liability in crashes;
- Personal property and the possible extinction of driving as an everyday task/hobby.
To illustrate the principal components of the negative opinions, we created a word cloud that can be viewed in Figure 11.

Figure 11.
Word cloud of main fears towards autonomous cars.
5. Future Work
This work can be extended to a couple of areas. Firstly, there is a need to identify some automated translation processes in the data mining workflow that can enable the capture and analysis of social media posts from other languages. Moreover, it would be useful to assess the demographic profile of the user that expresses the opinion, thus enabling a correlation of the user’s opinion and his sociological profile. However, such an analysis has to be very carefully planned because (i) there is no direct source of information that would enable us to capture such demographic data, and (ii) the analysis should adhere to privacy preserving laws and regulations. Finally, the performance of similar classification schemes, which could employ more than two classes of opinions, can possibly improve the granularity of the model.
6. Conclusions
The current paper presents a framework for capturing and analyzing social media posts using a sentiment analysis tool to determine the views of the general public towards autonomous mobility. The study contained the detailed description of the sentiment analysis tool and concept, as well as the data gathering that took place during the endeavors of this research activity. We targeted two very popular social media websites, i.e., Twitter and Reddit, and managed to capture a significant number of social media posts relevant to autonomous mobility.
After the data capturing procedure, we used a sentiment analysis system, developed using state-of-the-art machine learning models, to identify the sentiments behind the data captured and determine the level of acceptance for autonomous modes of mobility. Moreover, after the classification, we used the data that expressed “negative” opinions towards social mobility to identify key fears and reservations that drive those negative responses. Such an approach can be very beneficial to policy makers to capture society’s perception of autonomous driving and vehicles, as it identifies the general fears of the public and thus defines targeted policies and activities to overcome these barriers. All the data capturing and analysis efforts followed a privacy preserving framework that adheres to all current regulations and ethical guidelines.
Author Contributions
Conceptualization, N.B., N.P. and A.L.; Data curation, N.B. and N.P.; Formal analysis, N.B., N.P. and A.L.; Methodology, N.B., N.P. and A.L.; Project administration, A.L.; Software, N.B. and N.P.; Supervision, N.P. and A.L.; Validation, N.B. and N.P.; Writing—original draft, N.B.; Writing—review & editing, N.P. and A.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union’s Horizon 2020 research and innovation program under grant agreement No 815001 (project name: Drive2theFuture).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Van Meldert, B.; De Boeck, L. Introducing autonomous vehicles in logistics: A review from a broad perspective. In FEB Research Report KBI_1618; KU Leuven—Faculty of Economics and Business: Leuven, Belgium, 2016. [Google Scholar]
- Morgan, D.L. Why things (sometimes) go wrong in focus groups. Qual. Health Res. 1995, 5, 516–523. [Google Scholar] [CrossRef]
- MacDougall, C.; Fudge, E. Planning and recruiting the sample for focus groups and in-depth interviews. Qual. Health Res. 2001, 11, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Zafarani, R.; Abbasi, M.A.; Liu, H. Social Media Mining: An Introduction; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Eden, G.; Nanchen, B.; Ramseyer, R.; Evéquoz, F. September. Expectation and experience: Passenger acceptance of autonomous public transportation vehicles. In IFIP Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2017; pp. 360–363. [Google Scholar]
- Distler, V.; Lallemand, C.; Bellet, T. Acceptability and acceptance of autonomous mobility on demand: The impact of an immersive experience. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 21–26 April 2018; pp. 1–10. [Google Scholar]
- Bekiaris, E.; Loukea, M.; Panou, M.; Földesi, E.; Jammes, T. Seamless Accessibility of Transportation Modes and Multimodal Transport Across Europe: Gaps, Measures and Best Practices. In Towards User-Centric Transport in Europe 2; Springer: Cham, Switzerland, 2020; pp. 43–59. [Google Scholar]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Exp. Syst. Appl. 2015, 42, 9603–9611. [Google Scholar] [CrossRef]
- Beigi, G.; Hu, X.; Maciejewski, R.; Liu, H. An overview of sentiment analysis in social media and its applications in disaster relief. In Sentiment Analysis and Ontology Engineering; Springer: Cham, Switzerland, 2016; pp. 313–340. [Google Scholar]
- Gaspar, R.; Pedro, C.; Panagiotopoulos, P.; Seibt, B. Beyond positive or negative: Qualitative sentiment analysis of social media reactions to unexpected stressful events. Comput. Hum. Behav. 2016, 56, 179–191. [Google Scholar] [CrossRef]
- Li, T.; Choi, M.; Guo, Y.; Lin, L. Opinion mining at scale: A case study of the first self-driving car fatality. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5378–5380. [Google Scholar]
- Hutto, C.J.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Hu, X.; Tang, J.; Gao, H.; Liu, H. Unsupervised sentiment analysis with emotional signals. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 607–618. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wakabayashi, D. Self-driving uber car kills pedestrian in arizona, whererobots roam. N. Y. Times 2018, 3, 19. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Doulamis, N.; Doulamis, A. Semi-Supervised Deep Learning for Object Tracking and Classification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 848–852. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Washington, DC, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Team, T. Twitter turns six. Twitter Blog 2012, 21–23. [Google Scholar]
- Pardes, A. The Inside Story of Reddit’s Redesign. Available online: https://www.wired.com/story/reddit-redesign/ (accessed on 1 June 2020).
- Meyer, G.; Blervaque, V.; Haikkola, P. STRIA Roadmap on Connected and Automated Transport: Road, Rail and Waterborne; The National Academies of Sciences, Engineering, and Medicine: Washington, DC, USA, 2019. [Google Scholar]
- Kohl, C.; Knigge, M.; Baader, G.; Böhm, M.; Krcmar, H. Anticipating acceptance of emerging technologies using twitter: The case of self-driving cars. J. Bus. Econ. 2018, 88, 617–642. [Google Scholar] [CrossRef]
- Sadiq, R.; Khan, M. Analyzing self-driving cars on twitter. arXiv 2018, arXiv:1804.04058. [Google Scholar]
- Alamsyah, A.; Rizkika, W.; Nugroho, D.D.A.; Renaldi, F.; Saadah, S. Dynamic large scale data on Twitter using sentiment analysis and topic modeling. In Proceedings of the 2018 6th International Conference on Information and Communication Technology (ICoICT) IEEE, Bandung, Indonesia, 3–5 May 2018; pp. 254–258. [Google Scholar]
- Nimrod, G. Technophobia among older Internet users. Educ. Gerontol. 2018, 44, 148–162. [Google Scholar] [CrossRef]











© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).