3. Case Studies
For topics that are closely linked to business administration, i.e., closely linked to the actions of organizations and people, qualitative research based on case studies and expert opinions is particularly well suited. Accordingly, it makes sense that case studies and expert surveys/interviews are often used in research regarding the use of blockchain and DLT in the context of supply chain management. Among the more recent studies in this field are those of [
6,
7,
23,
24,
25,
26,
27,
28]. The methodology used to analyze the results is quite different depending on the respective study. The authors of ref. [
25], for example, used a sensemaking approach with cognitive mapping. The authors of ref. [
23] and ref. [
24] used a grounded theory approach, ref. [
26] used a design science approach, ref. [
27] employed the Delphi study method, ref. [
28] used an explorative case study research approach, and ref. [
6], as well as ref. [
7], used a mindfulness framework to evaluate the selected use cases. Our study differs from the existing literature in mainly three ways. First, we placed an explicit focus on T&T in supply chains. The existing studies that we are aware of all adopt a broader perspective (SCM in general) and, therefore, do not explore specific topics, such as T&T, in depth. Secondly, we explicitly decoupled the problem description from the studied technology. This allowed us to take a more holistic viewpoint, whereas the existing literature we are aware of tends to focus directly on problems tailored to blockchain technology. Thirdly, we applied a systems thinking approach, which was particularly appropriate in our case, since T&T in SCs combines a technical system, an information system, as well as an organizational and economic system. The approach of [
25] is closest to our approach, as we also used cognitive mapping.
The remainder of the article follows the structure suggested by
Eisenhardt for theory building from case study research [
19]:
The first point “Getting started” has already been covered in the introduction (research questions) and the description of the technological basics.
Selecting cases: We were able to survey eight companies/experts. While this sample was too small to make broad, generalized statements about all businesses, it was sufficient for the intended purpose of the case studies, namely, to give a rough, explorative indication of the problems that are relevant in the context of business practice. Indeed,
Eisenhardt argues that a case count between 4 and 10 often works well because this number of cases usually provides sufficient empirical foundation without adding too much complexity [
19] (p. 545).
Table 2 contains anonymized information about the companies/experts.
Since the number of cases in case study research is typically small, it is usually not sensible to perform a random sampling or to attempt to statistically reconstruct a population (of companies). Instead, a so-called “theoretical sampling” is often sensible [
19] (p. 537). The idea behind theoretical sampling is to create a sample that is valuable for looking at a topic from different angles. Our goal was to survey experts from companies that operate in different parts of supply chains and perform different functions. We were able to include companies from raw material processing (company A) to B2C (e-)retailing (company H). Furthermore, the sample included companies from different industries and of different sizes. This diverse sample should have led to the emergence of a fairly broad and rich picture from the experts. Furthermore, it was important that the companies used at least some form of tracking and tracing in their supply chains. Please note that it was our goal to understand the main goals and problems companies have when they (consider to) use T&T in a supply chain. Therefore, our theoretical sampling did not put much emphasis on whether or not a company/expert has had much experience with distributed ledger technology. We believe that such an approach, which focuses directly on blockchain and distributed ledger technology, could also be valuable. However, there would be a risk that a sample from what is currently a very small population of companies that have extensive experience with DLT, would lead to theories that may not be generally applicable. Instead, we exploited the fact that DLT, as a database technology, is deterministic in its properties. Expert opinions about a technology are, therefore, arguably less interesting than the problems that the experts are trying to fix. Whether a technology is suitable for fixing these problems can be analyzed in a logically closed manner based on its technical properties.
Crafting instruments and protocols and entering the field: The three steps of “crafting instruments and protocols,” “entering the field,” and “analyzing data” are often overlapping with an iterative back and forth between the steps [
19] (p. 538). We opted for a data collection that was conducted in written form via e-mail with open-ended questions that allowed for the possibility of additional questions or answers from the interviewed experts and the interviewer. This approach is referred to as a
hybrid survey [
29] (p. 239). Personal, individual in-depth interviews carry the risk that the interviewer may, subconsciously, influence the experts’ answers [
29] (pp. 152, 238). In our case, we wanted to minimize this bias. Reducing personal biases is particularly important in the context of the topic at hand, as positive and negative opinions on distributed ledger technology and blockchain technology in particular are often strong, both in practice and in academia. On the other hand, we did not want to eliminate the possibility of subsequent questions from both sides; thus, the chosen hybrid approach seemed to be the most fitting one.
Reflecting the iterative nature of the process, the questions were initially discussed with two experts from two companies, and this resulted in a few minor adjustments that made the questions easier to understand. The data collection was conducted during the months of March, April, and May 2021. During our contact with the experts at companies A and H, there were several e-mails with follow-up questions on our part. With the expert at Company C, we had, in addition to the e-mail responses, a longer video call about the content of the questions; however, only the e-mail responses were included in the coding. Overall, our approach worked well and produced valuable and interesting data. Only the expert from company B answered our questions in a short-winded manner, but this was probably due to his position (CEO) and corresponding lack of time.
Our goal was to obtain an unbiased view from the examined experts; thus, we mainly asked broad, open-ended questions. We started with an explanation about what we meant when we spoke of T&T in supply chains, asked for metadata and then focused on the following questions:
- ▪
What are the company’s goals with its T&T IT system?
- ▪
What are the biggest problems related to successfully implementing a T&T IT system, and what are the biggest problems with T&T in general?
We also asked questions about T&T technology and IT systems currently employed or planned and their scope within the supply chains of the companies, what tracking and tracing data are collected and by whom, and what data are made available to the company and, if so, when. Furthermore, we asked which employees have access to which data and how the data are stored (database), transmitted, and accessed (e.g., automated IT interfaces). Finally, we briefly asked about DLT and blockchain technology.
Analyzing data (within-case analysis and cross-case patterns): When analyzing the collected data, one can distinguish between the within-case analysis and the discovery of cross-case patterns [
19] (p. 540). The first step in the within-case analysis is to clean, prepare, and structure the data. This step was easy in our case as we received written answers from the experts. This is followed by a step that is already strongly connected to the discovery of cross-case patterns. One has to code the metadata of the companies and the answers from the experts into predefined categories. Coding categories can result from the research questions or the underlying theory and technology, but can also be derived exploratively from the experts’ answers. Roughly speaking, this involves checking whether a statement made by one expert was also made exactly or in a similar form by other experts. The result are abstract categories or answers that summarize the responses of the various experts.
To create the coding in our case, two individuals independently coded all the answers. This did not only increase the reliability of the coding, but also the validity of the findings because multiple investigators often had complementary insights [
19] (p. 538). These individuals created a codebook together with the goal of making the categories exhaustive and mutually exclusive [
30] (p. 132). The derivation of the coding categories was mainly exploratory (e.g., goals and problems with T&T), but also based on the technological characteristics of DLT (e.g., immutability). For seven companies, 110 categories each were coded. For Company G (IT Consulting), only 63 categories were coded because the company did not perform T&T for itself. After the first round of coding, the intercoder reliability was acceptable but not very good (average Krippendorff’s alpha ≈ 0.723). Therefore, the two coders discussed the codebook, improved it, and independently recoded the categories that had unacceptable intercoder reliability scores in the first round. After the second round, the intercoder reliability was good or very good for each company and for almost all the questions (average Krippendorff’s alpha ≈ 0.921). The two coders discussed all the remaining discrepancies, and a consensus decision was reached.
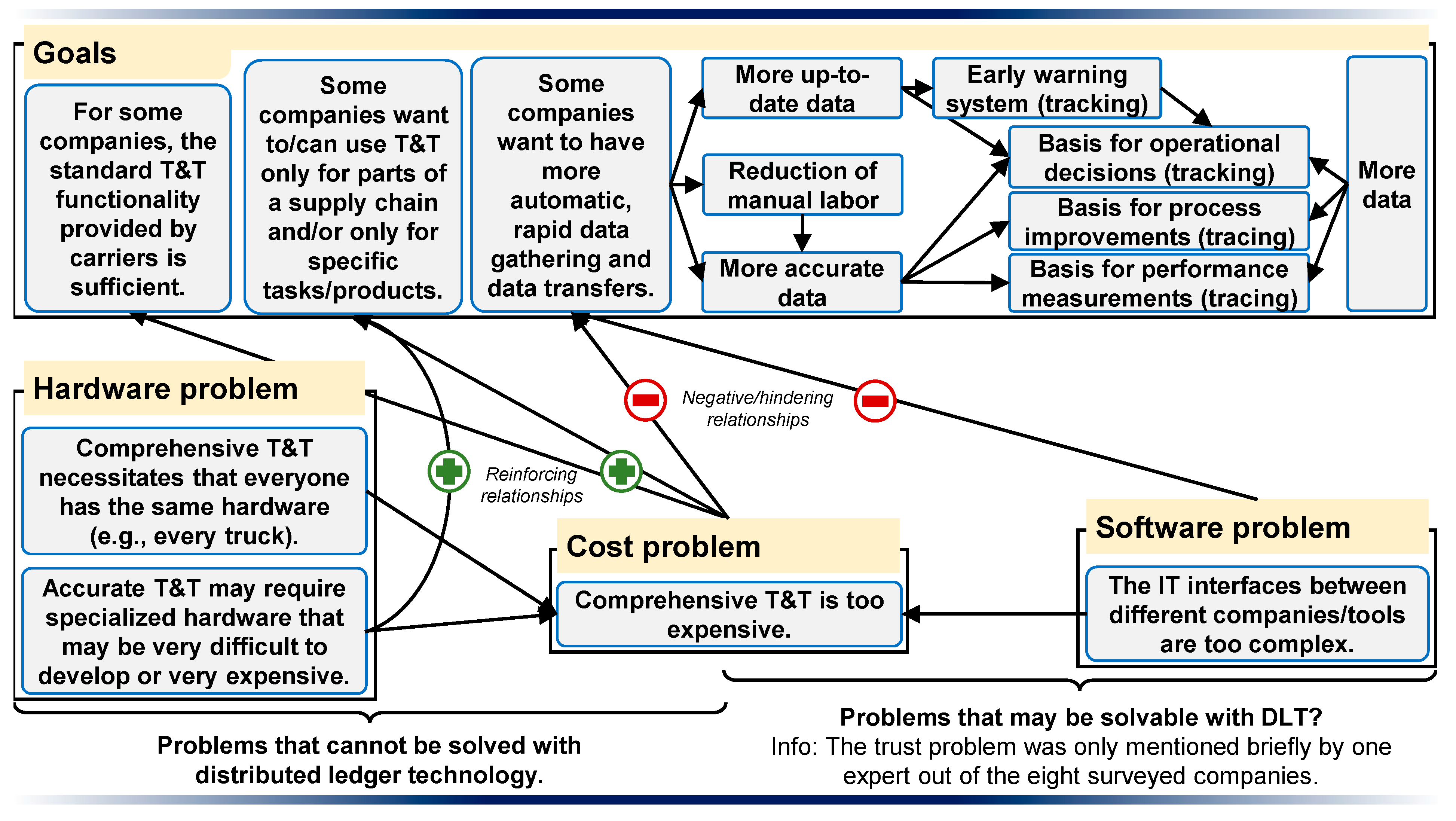
Results: Figure 2 provides a cognitive map of the survey results. A cognitive map is a systems thinking method, which was used in our case for the cross-case pattern analysis. The cognitive map summarizes the relationships between T&T goals and the different problems encountered by the studied companies.
None of the companies surveyed were engaged in comprehensive T&T along whole supply chains at the time of the study. Only company E had generally covered some parts of a supply chain and had the ambition to implement comprehensive T&T. In principle, there was a broad demand for more automated and efficient data gathering and data transfers. Software automation could reduce manual labor (A, E, F, and H), and make data handling less prone to errors (D, E, and H). More up-to-date data would also enable the use of early warning systems (D, E, F, G, and H) and could be used as a basis for operational decisions (A, B, C, D, and G, e.g., the short-term rescheduling of truck ramps (A) or early reorders of products (D)). These goals were enabled by the “tracking” component of T&T. Moreover, the additional data collected by the T&T systems could be used for performance measurements and reports and to identify potential process improvements (B, C, E, G, and H), which reflects the “tracing” component of T&T. Some representative answers were as follows:
What are your/typical goals with tracking and tracing IT systems?
(Interviewer)
“Transparency, competitive advantages, relevant for measurements (order lead time and delivery time measurement and performance), (…), identification of process weaknesses (gap analysis)”
(Expert E)
“In the case of real-time monitoring after the condition of the goods has been transmitted as presumably bad [g-forces], check for immediate resupply to avoid a production stop.”
(Expert D)
“(…) With better data and more reliable delivery performance, we can reduce safety stock and increase inventory turnover.”
(Expert C)
“(…) [Better] customer service through improved information basis. (…)”
(Expert F)
“Supervision of employees.”
(Expert G)
“[Regarding GPS tracking:] Basically, it is “just” a communicative shortcut so you do not have to keep contacting truck drivers directly via phone. (…) Example: A supplier arrives at our plant ahead of schedule (…). The ramp is free, but an unloading appointment for our truck is scheduled in 15 minutes. Now, the fleet team leader can check where our truck is and if it will make it to the appointment on time. If it is late, the other supplier can be pulled forward, for example.”
(Expert A)
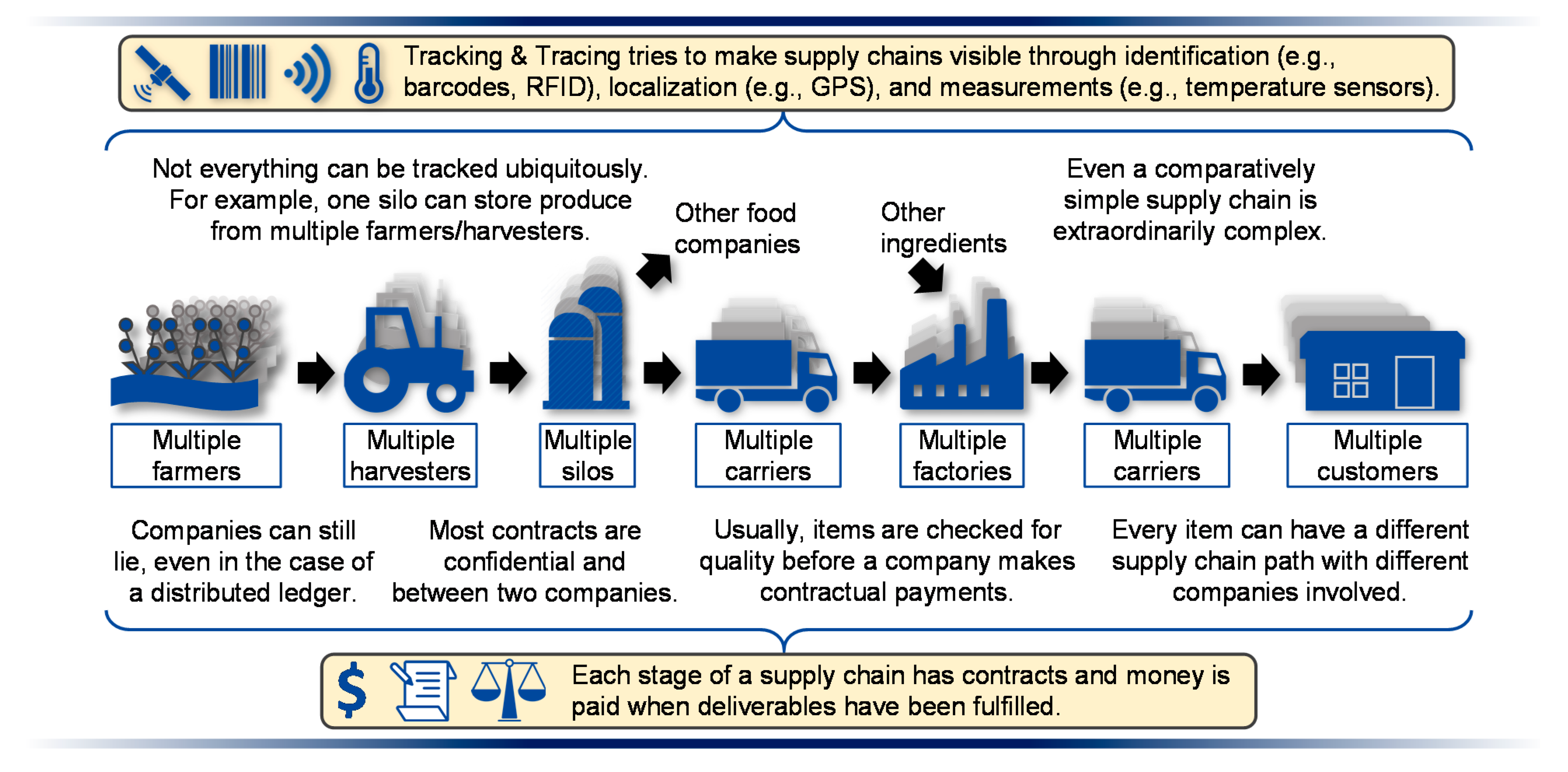
Many of the surveyed companies wished for more automation. However, this desire did not necessarily lead to a more automated T&T. Some companies were satisfied with standard carrier T&T capabilities and functionalities. Carriers usually make their T&T data available via a web portal. The experts gave two main reasons why companies were satisfied with this basic T&T: the excessive technical complexity of hardware and software (B, D, E, F, G, and H) and the high costs associated with them (A, C, D, G, and H).
Decisions for or against (automated) T&T are usually economic decisions (please note that none of the surveyed companies had a legal obligation to implement specific types of T&T). T&T not only has benefits, but also costs, and often the benefits are simply not worth the costs. Some representative answers were as follows:
“With the current form of shipment tracking (via carrier IT systems/websites), [company C] does not incur any costs since carriers generally make the data available. With the planned expansion already described (SupplyOn), the costs will certainly play a major role or could become a hurdle, and the costs and benefits will have to be weighed against each other. Moreover, in general, the more parties that are involved in a tracking and tracing chain, the more difficult the implementation will be.”
(Expert C)
“[Regarding the biggest/typical problems:] The desire to track every event vs. having the IT capacity to process all the data. Documenting every event, but not being able to perform any analyses with the data afterward, or not being able to draw any conclusions. (…) Infrastructure and costs in the companies:
- -
Processes must be set up.
- -
Hardware and software must be procured.
- -
Employees must be trained.
There must be a very concrete benefit/added value for the investment to be made.”
(Expert G)
“The T&T offerings of the carriers are sufficient. The integration and consolidation of information –especially from different carriers– is currently not trivial due to differences in data and systems. Intermediary stages (carriers ↔ own IT solution) would be required to be able to make the data available to customers through our own systems in a meaningful way.”
(Expert H)
T&T hardware and software are expensive (e.g., for comprehensive real-time transport tracking, individual trucks each have to have similar hardware installed (A, C, and D)) and very complex [
17] (p. 13). For example, Expert D stated that special sensors/adapters to accurately measure g-forces must be developed. Thus, a complete and accurate T&T is sometimes simply not possible due to hardware restrictions. Additionally, T&T software interfaces are very complex. Problems usually do not arise from a single interface, but rather from maintaining many different interfaces ([
24]). The complexity of maintaining many different IT interfaces is expensive and presents a problem for small companies with little IT knowledge. All of these issues lead to a situation where companies consider carefully in which SC segments and for which (expensive/sensitive (D)) products they want to selectively apply specific T&T technologies (e.g., inbound for increased operational efficiency (A and D) or outbound for increased customer benefit (F and G)). Implementing T&T across a whole supply chain is usually not a goal.
In addition to these hardware and software problems, the experts mentioned only a few other problems infrequently. A notable exception was the “employee problem”. Employees do not like to be monitored (A and G); moreover, they may lack the skills to use and maintain T&T IT systems (B, F). Trust issues, which are often mentioned in connection with DLT or blockchain technology, were only addressed by expert D (representative answers):
“As we understand it, with blockchain technology, data are verified and stored at/in all databases involved. (…) This (…) enables (…) better data availability and contestability in liability cases.”
(Expert D)
“Blockchain increases complexity. No use case or benefits identifiable. Exclusively trusted partners in the supply chain and plant network.”
(Expert E)
“Blockchains are difficult to set up. (…) The costs of a blockchain are usually greater than the benefits of the data collected. Only a few companies have goods that are high-priced enough for economic considerations to make sense. (…) Digitization in supply chains has not progressed far enough for blockchain. All supply chain partners need to participate for it to work.”
(Expert G)
“The requirements of mid-sized retailers can certainly be implemented without blockchain technology.”
(Expert H)
4. Discussion and Shaping Hypotheses
The two previous sections (
Section 2. Database Technologies and Their Characteristics and
Section 3. Case Studies) now served as the basis for a discussion of the research questions one and two:
For which problems related to T&T in supply chains is DLT necessary (RQ1) and/or sensible (RQ2) and why? 4.1. The Difference between Tracking and Tracing
One key finding of the case studies was that, for the following discussion, T&T should be divided into hardware and software components and that the individual components, namely, ‘tracking’ and ‘tracing’, should be considered separately.
Therefore, when we asked in the title of this article how useful DLT is for T&T in supply chains, it is important to note that there are many areas where DLT cannot be useful, because it is merely a software technology and merely a database technology.
Furthermore, some of the companies in our survey primarily used tracking and rarely or never used tracing. Tracking is the timely collection, provisioning, and use of T&T data. For this purpose, T&T data do not need to be stored long-term. Therefore, a complicated distributed ledger tailored to data immutability is not useful for tracking. Moreover, DLT does not make sense for purely intracompany use cases. Hence, the primary remaining question must be:
How useful or necessary is DLT for tracing cross-company T&T data?
4.2. The Supply Chain Context
To answer this question, it was important to consider the context of supply chains. A supply chain is a complex system with different levels and many relationships. In any given supply chain, there is (1) the institutional level, i.e., the companies operating in the supply chain, (2) the physical level, which entails the material flow from raw material suppliers to consumers, and (3) the informational level, which refers to the information flows and IT infrastructure in the supply chain. T&T can be viewed as part of the information flow and IT infrastructure of a supply chain, and it is accordingly embedded in this system and influenced by the physical and institutional levels. To a large extent, these system components were also reflected by our case studies. In the context of distributed ledger technology, three circumstances stood out in particular:
1. The volume of data generated in an SC is enormous. A distributed ledger is a shared replicating database that multiplies the necessary amount of storage; therefore, it would be wasteful and expensive (if not impossible) to store all the T&T data generated in an SC in a distributed ledger [
16] (p. 148). Instead, only selected T&T data or meta-data (e.g., hashes of data) can be sensibly stored in a distributed ledger.
2. In a supply chain, companies compete with each other. Suppliers or customers compete against each other, and the relationships between suppliers and buyers are delicate. A supplier or buyer must fear being replaced by a competitor.
Supply chain participants, therefore, generally want to keep much of their data secret; if they make their data available at all, they often want to do so only for direct business partners [
10] (p. 350). Cross-company T&T in supply chains, therefore, usually consists of many different private information-sharing relationships.
This context (extreme data volume and a need for data privacy/access controls) leads to a situation in which distributed ledgers cannot exist alone. Instead, accompanying central databases and IT interfaces are needed [
13]. Therefore, it is rather unlikely that DLT can reduce the number of IT interfaces used in an SC. Some of the experts who participated in our survey explicitly complained about the complexity of using many different IT interfaces.
3. Supply chain participants are interested in long-term business relationships and do not lightly damage or destroy their business relationships by lying about data. Risk mitigation costs money, and a company will employ specialized technology to protect itself against the risk that a supply chain partner may lie only if the expected cost of that risk is high. Indeed, Expert G gave this argument in our survey as a reason why blockchain technology is often not worth the effort. Furthermore, this result was also supported by other scientific studies (e.g., [
31]).
4.3. The Physical Level vs. the Informational Level
Nevertheless, one may still ask if DLT is useful when the stakes are high and companies want to protect themselves from lying. One might think that DLT could help in this case; however, database technology cannot prevent companies from lying about new data [
4] (p. 947). DLT only ensures that existing data are not changed or deleted.
However, a consensus mechanism has additional advantages. Through a consensus mechanism, data can be automatically and forcibly written to a database. This is called a smart contract. A smart contract is stored in a shared database and is triggered as soon as specified data are present in the database. For example, automatic payments linked to goods receipt confirmations are conceivable [
1] (p. 6889). Nevertheless, smart contracts encounter a problem whenever there is no automatic, accurate interface with physical reality. Companies can lie to force or prevent the execution of a smart contract (e.g., incorrectly stating that ordered items never arrived). Normally, only a package is tracked, and the contents of the package are not tracked. T&T data could help in this situation (e.g., by including weight and dimension measurements), but, in the end, a receiving company may still choose to manually verify the quality of received goods, especially in the case of expensive items. Moreover, goods receipt confirmations are also recorded in companies’ internal ERP systems. Thus, if a receiving company has complete control over when a goods receipt confirmation takes place (and, thus, when the related smart contract is triggered) and this confirmation is stored in the company’s ERP system anyway, the critical question arises of why a smart contract should be used when the company could instead simply arrange for the applicable payment to be performed automatically through its ERP system.
4.4. The Technological Alternatives
The question of whether DLT is useful or necessary for T&T in supply chains, therefore, ultimately revolves around how useful/necessary data immutability is and whether a sufficient level of data immutability can be achieved with other, less complex technologies. The importance of data immutability varies by use case, but can be very important (e.g., for anything directly related to contracts). Sometimes, data immutability is even required by law (e.g., in the pharmaceutical industry [
18]). Therefore, there is, undoubtedly, a place for and value in technologies that enable data immutability [
27]. However, technologically, DLTs with consensus mechanisms compete with simple centralized databases in combination with digital signatures.
Both of these technologies have security vulnerabilities. The strength of a consensus mechanism in a distributed ledger depends on the behavior of the database nodes (companies). Digital signatures, in contrast, initially rely on a trusted third party and later on the related company’s own security. This becomes problematic if a company’s private key is stolen and the company does not notice the theft. Public keys are less problematic. If a reputable certificate authority creates correct keys, the connection between a company and a public key cannot be changed easily without it being noticed. Since the corporate identity connected to a public key is publicly available information, strong public governance is possible. Data digitally signed with a private/public key combination are immutable as long as accurate backups of the public key servers exist and as long as all the database owners do not collectively delete the data. Thus, in some respects, digital signatures offer stronger data immutability than DLTs without digital signatures; however, they have a weakness in that companies could collectively decide to simply delete data. Nevertheless, in regard to contractually relevant T&T data, at least one of the companies involved in a contract is always interested in keeping the relevant data. Thus, in these situations, digital signatures are a viable choice and the question of which alternative is better ultimately comes down to what a company prefers in terms of security: relying on its own security or relying on the behavior of other companies in a distributed ledger?
Nevertheless, situations could exist where, for example, a law mandates data immutability and all the companies involved have an interest in illegally deleting data. In such cases, indeed, only a suitable DLT or a trusted third party (data trustee [
10] (p. 350)) can be used. However, a distributed ledger would have to be public or include companies that have no interest in deleting data.
4.5. Enfolding Literature
The majority of the literature on blockchains and DLT in supply chains seems to be rather positive towards the technology. While it is often pointed out that the technology is still young and needs to prove itself, it is also claimed that the technology has the potential to disrupt entire structures and relationships [
32] (p. 62) and that its future looks promising [
5] (p. 2063). Based on our study, however, we painted a more cautious picture. Our results indicated that blockchain technology and DLT in general seem to be useful only in rare cases. While we were not the only ones to come to such a cautious conclusion (e.g., [
4] (p. 950), it is, nevertheless, worth asking what causes such a wide range of, possibly contradictory, conclusions.
We believe that one important factor in answering this question is that some authors are more focused on the future and other authors (similar to us) are more focused on the current problems and goals found in practice. For example, it is an important prerequisite for the usefulness of DLT, that the data, which are stored immutably in the distributed ledger, are also correct. If this is not the case, the content of the data cannot be trusted and the technical complexity of a DLT would be unnecessary [
4] (p. 949). However, companies/people can lie and, currently, there is often no way to accurately track the physical world without the possibility of manipulation. Only if one looks into the distant future and simply assumes that at some point it will be possible to accurately track the physical (real) world, will there be an increased number of beneficial use cases for DLT and its ability to immutably store the data (e.g., for audits or smart contracts).
Another important factor is probably that the economic reality of businesses and the supply chain context is often neglected in current blockchain and DLT research. Distributed ledger technology is, foremost, a technology with deterministic properties. It is tempting to take these technical properties and look for problems that can be ‘technically’ solved with DLT. However, this type of approach can be deceptive. Sometimes, use cases are identified that could be solved with other simpler technology. In this case, DLT would be similar to ‘using a sledgehammer to crack a nut’. In other cases, it may be that DLT is the only feasible technology, but for economic reasons (including game theoretic reasons), it is simply not worth solving the problem. Both future-oriented research, and research that specifically investigates which problems can be technically solved by DLT, are valuable. This study and some other studies as well, have, however, taken a somewhat different approach, in the sense that a spotlight was put on the sobering reality of business administration.
5. Summary, Limitations, and Conclusions
The primary research questions of this article were: For which problems related to T&T in supply chains is DLT necessary (RQ1) and/or sensible (RQ2) and why?
Table 3 provides a concise overview of the discussions from the previous sections and may serve as a partial answer to RQ1 and RQ2. The preceding RQ0 (“What are the main goals and problems companies have when they (consider to) use T&T in supply chains?”) was already answered in the form of
Section 3 (“Case studies”), especially
Figure 2.
We found that DLT was only necessary in very special cases, such as when data immutability was mandated and all the companies that were directly associated with a set of data had an interest in deleting it. In some cases (e.g., tracing for external needs), a distributed ledger provides value; however, depending on the situation, it may not be sensible, as an alternative exists in the form of digital signatures. In many cases, DLT does not help at all (e.g., T&T hardware, tracking, tracing for purely internal needs). Nevertheless, this does not mean that DLT is useless. DLT offers additional features that other types of databases do not. This fact alone is positive in itself, even if these functions are not needed very often. Furthermore, DLT is simply useful as an alternative technology. Competition between technologies is generally a good thing. For example, digital signatures, as an alternative technology, rely on so-called certificate authorities (which typically do not offer their services for free). Even if competition between certificate authorities did not work (imperfect market), certificate authorities would have to keep in mind that customers could also use distributed ledgers as an alternative. This means that, even if using DLT would be significantly more complex than using digital signatures, the technology provides an upper-cost limit, which is useful to have.
We hope that the reader, both from practice and science, was able to draw valuable insights from our article.
Table 3 may be particularly helpful for a practitioner, as it allows the reader to easily check whether it makes sense to use DLT or not for many typical problems/objectives encountered in practice. There is of course a gray area in which several different technologies (including DLT) are viable alternatives. In this gray area, the decision for or against a technology is always a case-by-case decision that depends on the specific context. Unfortunately, it is not possible to provide practitioners with simple guidance for these cases. However, our results do narrow down this gray area.
The scientific reader may benefit from our article as we presented a theory that is parsimonious, logically coherent, and testable. The theory is parsimonious in the sense that the gray area mentioned above could be narrowed down relatively easily by asking a few control questions. The theory is logically coherent in the sense that the technical properties of DLT were deterministic and the T&T problems/goals found in practice were systematically analyzed and interconnected using systems thinking. The theory is testable in the sense that any researcher is free to ask other companies about their T&T goals and problems and also to verify whether DLT is useful for these problems/goals or not. In addition, we hope that this article will serve as an impetus for future research to give digital signatures in combination with conventional central databases more thought, as an alternative to DLT. The comparison of these two technologies, especially in terms of business and IT management, is probably too often overlooked.
However, this article also has some limitations, which may serve as a motivation for future research. In this paper, we presented the results of an exploratory case study research of eight companies. The case studies served as a basis to identify the major T&T requirements and problems that exist in practice. It is possible that these eight companies did not adequately represent all typical T&T problems and goals found in practice. In addition to conducting the case studies, we derived the components and used cases of T&T using a systems thinking approach. It is, therefore, possible that we overlooked important problems for which DLT would be very useful.
In addition, our article had a B2B focus. While the results should also be valid in a B2C context, it might be worthwhile to explore the B2C perspective in more detail.
Moreover, as already discussed, we did not take an explicit look into the future. It is exciting that it may someday be possible to use T&T technology to make entire supply chains visible in an error-free and tamper-proof way, but this is certainly very far in the future. However, an analysis of whether DLT makes sense in such a future, which entails the possibility of smart contracts, on the one hand, but an enormous amount of generated data, on the other hand, would undoubtedly be an important and sufficiently extensive topic for a separate article.
It is undisputed that logistics and supply chain management can benefit from more transparency. Wherever uncertainty and risk exist, economic inefficiencies arise (e.g., [
33]). In addition, production and logistics also have a strong social responsibility. Environmental pollution, welfare, and social justice are crucial issues worldwide (i.e., trend towards more sustainability) and production and logistics play a pivotal role in many aspects of these topics. Therefore, it is important that the role of production and logistics in relation to sustainability is made more transparent [
34]. However, merely for transparency on its own, DLT is not necessarily needed. Transparency can often also be achieved with conventional databases and information sharing. The most prominent feature of distributed ledgers is that they can combine high data availability for all participants with data immutability. Use cases that can benefit from both these properties are, therefore, particularly interesting for future-oriented discussions about DLT applications. However, it is often the case that companies do not (want) to record and share their information. This may simply be because transparency costs a lot of money, but it may also have competitive reasons, as transparency can create disadvantages when competing with rival companies. This means that, as other authors also have pointed out [
4] (p. 949), database technology is often not the problem at all. Instead, the attitude toward transparency and the connected processes within companies must first change. On game-theoretic grounds, it can be argued that, in many situations, such a change is unlikely to occur by itself. Therefore, it may sometimes make sense to mandate transparency and information sharing by law [
35], and perhaps these are the kind of situations where DLT is most valuable.
In any case, we thank the reader for their attention and hope that this article proved a valuable read.






{kind=link}
{kind=link}