1. Introduction
Modern-day supply chains are undergoing an inevitable surge in complexity, marked by the involvement of numerous entities. The escalating expectations of customers, stringent lead time requirements, demands for customisation, and the imperative of sustainability measures have prompted organisations to concentrate on the comprehensive optimisation of their operational processes. In response to the dynamic shifts in customer demands, manufacturing and service organisations must transition from conventional “one size fits all” business models to more nuanced “markets of one” paradigms. Consequently, these transformative alterations within supply chain ecosystems present formidable challenges in effectively managing logistics operations for organisations across manufacturing and service sectors.
In the broad landscape of logistics operations, three principal categories can be discerned: inbound, outbound, and intra-logistics. The latter has recently garnered increased scholarly and practical attention within process-based industries [
1]. Moreover, emphasising the significance of intra-logistics functions, extant research indicates that the absence of a well-structured intra-logistics system may precipitate supply disruptions, machine idling, and prevalent inefficiency within the overall operational system [
2,
3,
4,
5,
6]. This underscores the critical role played by intra-logistics operations in sustaining the seamless flow of materials and information, particularly within dynamic and complex supply chain environments.
Material handling is a pivotal logistics function that ensures the unbroken continuum of operations by incorporating the principles of “time and place utility” within its procedural framework. The evolutionary trajectory of material handling systems (MHS), propelled by integrating smart manufacturing and digitalisation concepts, strives towards realising predefined objectives while minimising the necessity for human intervention and oversight [
7]. In modern MHS frameworks, there is a discernible trend towards incorporating advanced technologies such as autonomous mobile robots (AMR), automated guided vehicles (AGV), and drones. These technological advancements are progressively harnessed to augment material handling processes’ overall efficiency and effectiveness. Even with the strides made in automation, conventional trucks persist in their role within specific material handling activities, notably in contexts such as transportation within mining pits, agricultural fields, and dry-bulk cargo terminals.
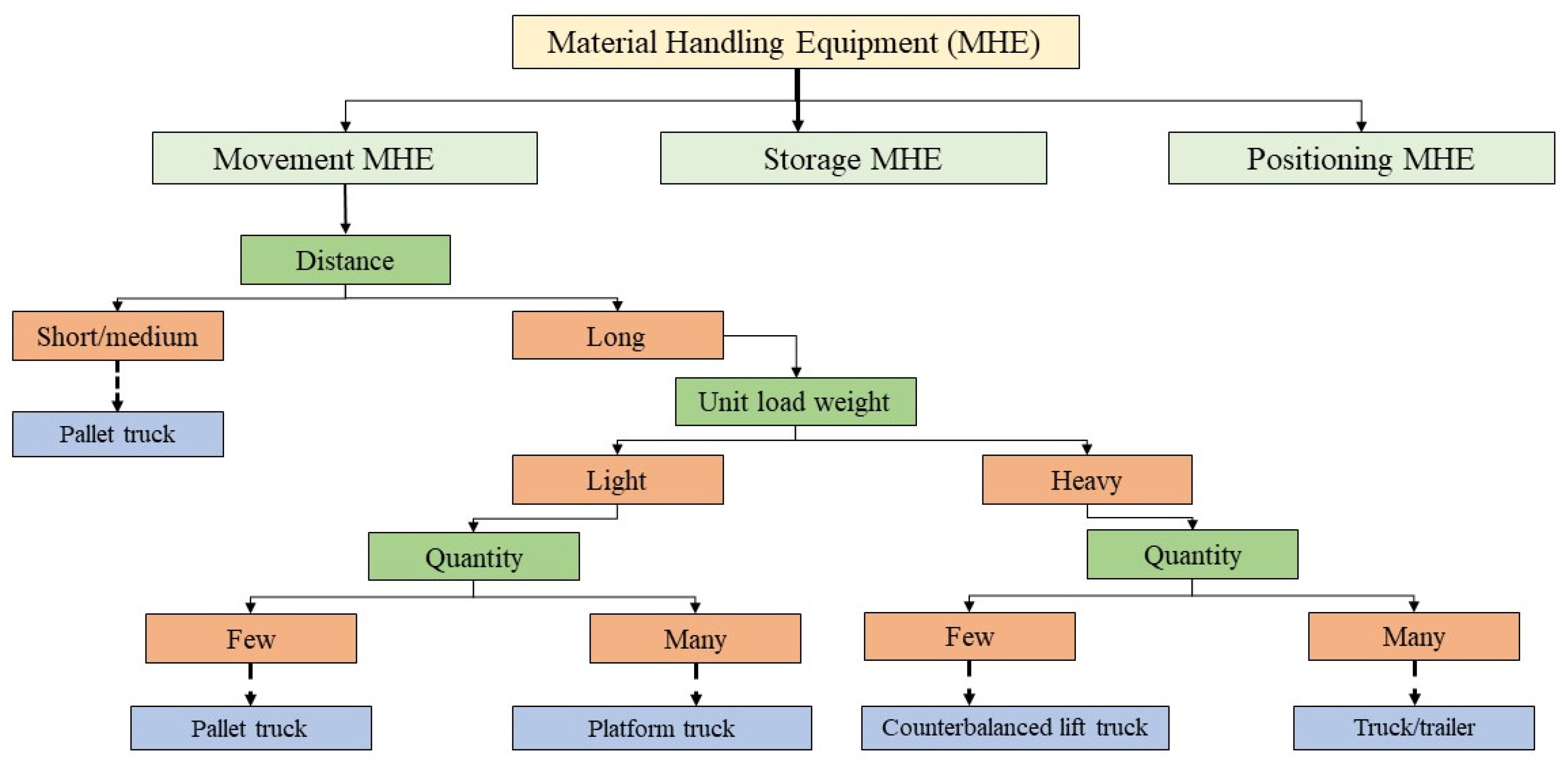
The complexity of decision making within material handling equipment (MHE) is illustrated in
Figure 1, which delineates a decision tree based on load types and features [
8]. This systematic representation is a visual aid for navigating the nuanced landscape of material handling, facilitating informed choices aligned with specific operational requirements.
Transportation, as a logistics function, has progressed positively through standardisation, unitisation, and reduced intermodal handling [
9]. Technological advancements in transportation have led to a decline in the compound average growth of transportation costs from a macro-environmental perspective. Despite this, transportation still constitutes the largest share of logistics costs [
10].
Transportation networks are integral to enterprise strategy formulation [
11].
Table 1 delineates various stakeholders and linkage types in the material flow of a given network, categorised by collaboration levels [
12]. Global networks feature nodes connected through transboundary transportation modes like ships, aircraft, and pipelines, characterised by long-term contractual agreements and reduced susceptibility to abrupt changes. In contrast, local networks predominantly employ road transportation modes for delivering materials and goods to customers. Internal networks have shorter planning horizons than global and regional networks, with MHSs facilitating material flows between facilities and departments within the same organisations.
In addition to basic network configurations, supply chain networks exhibit a range of topological arrangements, each designed to cater to specific operational needs. These configurations include the hub-spoke design, where a central hub serves as a focal point for distribution; the pendulum design, characterised by accommodating reverse supply chain activities; triangle line designs, forming triangular connectivity patterns; and double-dipping service designs, incorporating multiple connecting stakeholders or points [
13]. These diverse topologies offer strategic options for optimising supply chain operations based on efficiency, geographic dispersion, and service requirements.
The design of a MHS necessitates inputs and decisions from all levels of management to ensure alignment with the organisation’s objectives. These decisions are grounded in the organisation’s best interests and strategic goals.
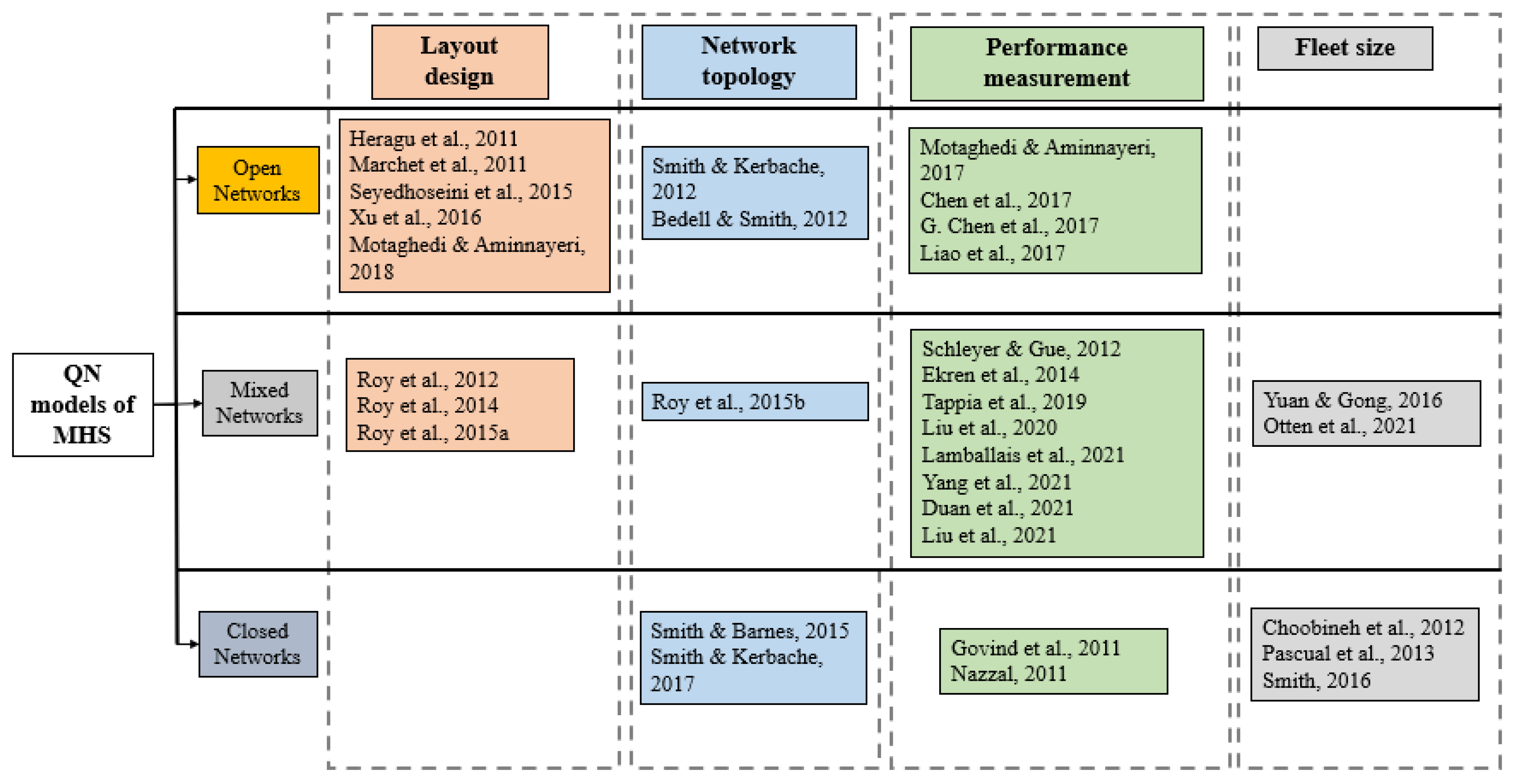
Figure 2, as presented by Fragapane et al. [
14], delineates managerial-level decisions pertinent to MHS design. Additionally, the figure underscores the pivotal role of optimal fleet size as a decision factor influencing all managerial echelons. Notably, the magnitude of the fleet significantly affects criteria for ownership decisions and scheduling considerations at both strategic and operational levels.
Optimisation of MHS operations within an internal network is classified under network optimisation. Ferriol-Galmes et al. [
15] delineated the critical components of a network optimisation process: constructing the network model and developing an optimisation algorithm. A plethora of literature exists, presenting techniques for modelling specific networks for analytical purposes. Analytical models, fluid models, and simulators represent well-established tools that emulate intricate systems, such as telecommunication networks, computer networks, manufacturing systems, and healthcare systems. Nevertheless, fluid models exhibit limitations in incorporating queueing delays and scheduling policies, stemming from the assumption that constant per-link delays may compromise accuracy in high-utilisation environments. Additionally, while simulators are acknowledged for their superior accuracy relative to analytical and fluid models, they entail elevated computational costs and extended development times [
15]. Queueing networks are a pervasive and widely applied modelling framework in analysing and optimising MHS across diverse operational contexts. This modelling approach is instrumental in comprehensively assessing and refining MHS performance by considering a spectrum of operational considerations [
16,
17,
18,
19,
20,
21,
22].
Transportation managers commonly exhibit a predilection for fleet uniformity and commonality due to the enhanced manageability and standardisation these attributes confer upon operations. This preference extends to various operational facets, including maintenance, scheduling, spare parts management, performance monitoring, and cost calculations. The inherent simplicity associated with a homogeneous fleet streamlines these operational aspects, rendering them comparatively more straightforward than their counterparts in a heterogeneous fleet. However, it is imperative to highlight that a heterogeneous fleet introduces distinct advantages, notably heightened operational flexibility. This flexibility translates into tangible benefits, including cost savings and optimised asset utilisation [
23]. From an operational perspective, this juxtaposition underlines the nuanced trade-offs that transportation managers must navigate in determining fleet composition, balancing the efficiencies derived from uniformity against the strategic advantages a diverse fleet offers.
This study introduces a novel methodology utilising queueing networks to optimise heterogeneous trucks’ fleet size and composition in internal logistics networks. Building upon the homogeneous fleet optimisation framework established by Amjath et al. [
24] in inter-facility logistics, this study extends into the domain of heterogeneous fleet optimisation. A key departure from Amjath et al.’s [
24] work lies in the modelling approach adopted here, wherein we employ a CQN featuring heterogeneous nodes. Unlike the previous study’s focus on minimising the total number of trucks, our emphasis centres on optimising operational costs. This shift necessitated the redevelopment of the Mean Value Analysis (MVA) algorithm using S-B approximation to evaluate the performance measures of CQN with heterogeneous nodes, detailed in
Section 3.2.
The paper is structured as follows.
Section 2 provides a literature review related to the problem addressed in this paper.
Section 3 encompasses the problem description, notations, problem formulation, and model development. It also delves into algorithm development, the optimization model, and analytical and simulation approaches.
Section 4 offers a case study featuring comprehensive numerical experiments, wherein outputs from the analytical model are validated using the simulation model. Additionally, the section includes sensitivity analyses of selected scenarios and highlights main managerial insights. Finally,
Section 5 outlines this research’s implications and concludes with remarks.
3. Methodology
This section delineates the methodology employed in formulating a modelling and solution approach for a fleet sizing problem within an inter-facility MHS governed by a heterogeneous fleet of trucks. Furthermore, the subsequent subsections explicate the methodology adopted in a phased manner. These phases encompass modelling, analytical techniques, optimisation approaches, validation methodologies, and analytical modules.
3.1. Modelling Approach
The optimisation of MHS operations within an internal network fall within the domain of network optimisation. Ferriol-Galmes et al. [
15] delineate the principal components of the network optimisation process, encompassing the construction of the network model and the development of an optimisation algorithm. In alignment with these principles, this study has chosen CQN to model inter-facility material transfer operations for subsequent analysis and optimisation.
Figure 4 illustrates the strategic roadmap for selecting this study’s modelling tool and solution approach.
This investigation is centred on elucidating the steady-state behaviour of the network, particularly in the context of interfacility material transfer processes characterised by multiple sub-processes. Given that a singular station queueing system fails to adequately meet the modelling requirements due to the presence of distinct nodes representing these sub-processes, a queueing network becomes the chosen modelling approach. The specificity of interfacility material transfer, where the vehicles involved do not exit the system, necessitates the application of a CQN. In order to streamline the modelling process, the study assumes a product-form solution for the network, and the MVA algorithm, selected for its efficiency, is employed to solve the system. The MVA algorithm’s recurrent use in CQN performance measurements is attributed to its computational efficiency and the circumvention of normalising constant calculations denoted by G (N, k).
3.2. A CQN for an Inter-Facility Material Transfer Operation with a Heterogeneous Fleet of Trucks
The daily occurrence of inter-facility material transfer operations, involving the transportation of multiple materials between storages and intermediate production facilities, necessitates the engagement of an outsourced heterogeneous fleet of trucks. The heterogeneity in truck characteristics, including capacity (throughput), service times (e.g., loading, unloading), and operational costs, coupled with the diverse physical attributes of each material, leads to variations in total truckload weights and service times. Distinct materials also prompt trucks to follow different routes and receive service at specific stations. The material flow sequence of a truck begins at a service station, progresses through subsequent stations sequentially, and encounters specific tasks and responsibilities at each. Two primary classes categorise service stations: those dedicated to a single product class and those accommodating multiple product classes.
In the context of a service station exclusively serving a single product class, it functions as a single-class heterogeneous node within the network. Here, service and waiting times for trucks depend on the truck type. Upon a truck’s arrival at such a node, two scenarios unfold: direct service if the station is unoccupied, with service duration contingent on the truck type, or queueing if the station is occupied, with waiting time determined by the type of truck currently undergoing service. The mathematical representation of this phenomenon is encapsulated in the first equation of our analysis. It is imperative to note that, in this framework, we assume infinite queue capacity across all service stations, eliminating instances of blocking. Equation (1) effectively elucidates the derivative of the total response time for a truck within a single-class heterogeneous node.
If a service station accommodates more than one product class, it assumes the role of a multi-class heterogeneous node within the network. In this scenario, when a truck (customer) arrives at the station, the response time is contingent upon both the product class and the type of the truck. Here, it is plausible for a truck to be serviced from the same product class but with a different truck type or, conversely, from a different product class with a distinct truck type. Consequently, in multi-class heterogeneous nodes, the incoming truck’s product class and truck type jointly influence the response time of the node in relation to the trucks. Equation (2) comprehensively delineates the constituent components of the response time for a truck within a multi-class heterogeneous node.
Single-class heterogeneous node’s response time:
Multi-class heterogeneous node’s response time:
According to
Figure 5, the response time for the truck (
k, t) in service station
j is the summation of the service time of the truck (
k, t) and the wait time, as in Equation (1) for single-class heterogeneous nodes. The wait time can be elaborated upon further as in Equation (2). If a service station is used by multi-class trucks, the wait time can be attributed to different classes and types of trucks.
In this logistical context, several foundational assumptions underpin the operational dynamics of the system. Firstly, service times at all service stations are assumed to follow an exponentially distributed probability distribution, enabling the modelling of service duration variability. Queue management adheres to a first-come-first-served (FCFS) discipline. A stringent class persistence policy is enforced, prohibiting trucks from switching between product classes within the same time frame. The intermediate production facility reliably meets material requirements on a regular operational day. A structured operational sequence is defined for each truck: arrival and documentation at the storage yard gate, weighbridge recording weights of empty trucks, loading at the station, recoding weights of loaded trucks and subsequent transportation to the facility for unloading. This cycle continues until the intermediate facility’s demand is met. During transit from loading to unloading, trucks are fully loaded, and on the return journey, they are empty.
Based on the model formulation and assumptions above, each service station is modelled as M/M/1 with an infinite queue capacity, and circulation between service stations is modelled as M/M/∞. As mentioned earlier, this study uses the parametric decomposition approach to solve the CQN using the MVA algorithm. The following nomenclature was introduced for algorithm development and mathematical model formulation.
The following part provides the steps for tailoring the MVA algorithm to this study using the work of Suri et al. [
84] and Smith and Kerbache.
According to Reiser and Lavenberg’s [
85] proof of the arrival theorem, the response time of a customer arriving at a node is equivalent to the summation of the customer’s service and wait times amalgamated from all of the customers already in the network minus one. Therefore, the following is the response time of a truck (
k, t) in the service station
j, where
j is only used by class
k and served by a single server:
Equation (3) can be extended to calculate the mean response time of a truck (
k, t) in the service station
j, where service station
j is used by all classes and served by a single server, using the Schweitzer–Bard (S-B) approximation [
84].
According to Little’s Law for product chains, the network throughput of class
k type
t trucks is:
Moreover, from Little’s Law for queues, the mean queue length of class
k type
t trucks at station
j is:
According to Suri et al. [
84], the utilisation rate of truck type
t for product class
k in a single server service station
j is:
The cycle time for a truck is the summation of all the service times in one trip. However, a truck visits only certain service stations along the trip according to the product class it carries. Therefore, a binary variable is included to ensure that service times from the service stations visited are only used to calculate the cycle time for a particular type of truck for a product class. The cycle time for truck type
t for product class
k can be written as follows.
Equation (8) can be re-written as follows by substituting the
from Equation (4):
3.3. Formulation of the Optimisation Problem
Fleet sizing is integral to the decision-making processes regarding outsourcing MHEs to an organisation. Moreover, determining the right size and composition from heterogeneous equipment fleets is more challenging because of each piece of equipment’s cost, capacity, and other operational factors varies. Similarly, determining the optimal number of trucks and composition from an available heterogeneous fleet is a complex decision-making problem.
This study focuses on minimising the outsourcing cost of the interfacility transportation process. The outsourcing cost depends on the number and types of trucks the organisation plans to acquire and is pro rata for the same truck. Therefore, the total price is an aggregate product of the number of a particular variety of trucks outsourced into the cost of that truck. Generally, the logistic and transport managers’ objective is to outsource the right kind and number of trucks to ensure the smooth flow of materials to the buffer locations. Moreover, the optimal fleet size and composition are bounded by the total available budget and a time window.
The decision variable and surrogate variable are as follows:
Number of type t trucks used for product class k
Cycle time for truck type t product class k with N number of trucks
The objective function is as follows:
and is subject to the following constraints:
Equation (11) can be re-written using the surrogate variable
as follows.
The objective function (Equation (11)) is linear and minimises the outsourced trucks’ total cost (Z). The first constraint (Equation (12)) is an allocation constraint where one truck must be allocated to either only a single type of product class or unassigned. The second constraint (Equation (13)) is non-linear and ensures that demand from the intermediate buffer locations is met for each product class within the provided time window. This constraint is notable because the decision variable is present in the numerator and influences the values in the denominator through the surrogate variable (Equation (17)). Equation (14) is a linear knapsack constraint that bounds the number of trucks to an available budget. The fourth constraint (Equation (15)) is a capacity constraint for each product class at the intermediate production facility that needs to be respected. Equation (16) shows that the decision variable is a positive integer and is a real positive variable.
3.4. Solution Approach for Solving the Mixed Integer Non-Linear Optimisation Problem
Determining the optimal network population in a CQN for a given throughput under the queue discipline of non-pre-emptive policies is an NP-Hard problem [
86]. This study problem, determining the optimal fleet size and composition using a CQN model, falls within the NP-Hard category. Therefore, obtaining solutions using exact algorithms in a polynomial time is unfeasible. Consequently, finding efficient solutions for these problems requires numerical approximation approaches and heuristics. Implementing a modified Sequential Quadratic Programming (SQP) method is one of the most powerful and efficient tools to solve mixed integer non-linear optimisation problems. Schittkowski [
87] presented an SQP method for solving a non-linear constrained optimisation problem with a Fortran subroutine NLPQL. This method assumes integer variables have a smooth influence on model functions, resulting in only marginal decrement or increment in the function value with the change of an integer value. The solution to the quadratic programming subproblem is to convert the objective function and constraints to a quadratic problem and then use iteration to determine the search direction. The main steps of implementing an SQP method for this study are as follows.
- Step 1.
Set the initial parameter and constant values.
- Step 2.
Implement a branch and bound method with several branching and node transversal strategies. Then, as an unconstrained problem, evaluate the objective function (using the MVA algorithm) to determine the minimizer for the relaxed problem.
- Step 3.
Using the solutions from the previous step, evaluate the objective function values while adding violated constraints.
- Step 4.
Evaluate the objective functions using the primal-dual method by incorporating Lagrangian multipliers and partial derivatives to find the direction of the optimal solution vector for the relaxed problem.
- Step 5.
Using the convergence solution from the previous step, create two sub-problems with integer values using lower and upper bounds from the continuous solution.
- Step 6.
Evaluate the objective function value using the new sub-problems and check for convergence. If there is no convergence, repeat Step 4 to find a new solution. Otherwise, terminate the process.
The above steps are shown in the following flowcharts to show the roadmap of the solution approach in a visual form. The final solution from each flowchart is the starting point for the following chart.
Figure 6 shows the steps to create a binary search tree for the relaxed constraint problem. The binary search tree is used in the next phase of the solution approach to determine optimal solutions while adding violated constraints step-by-step and evaluating the new solution. In this phase, the problem is solved as a non-integer (continuous) optimisation problem.
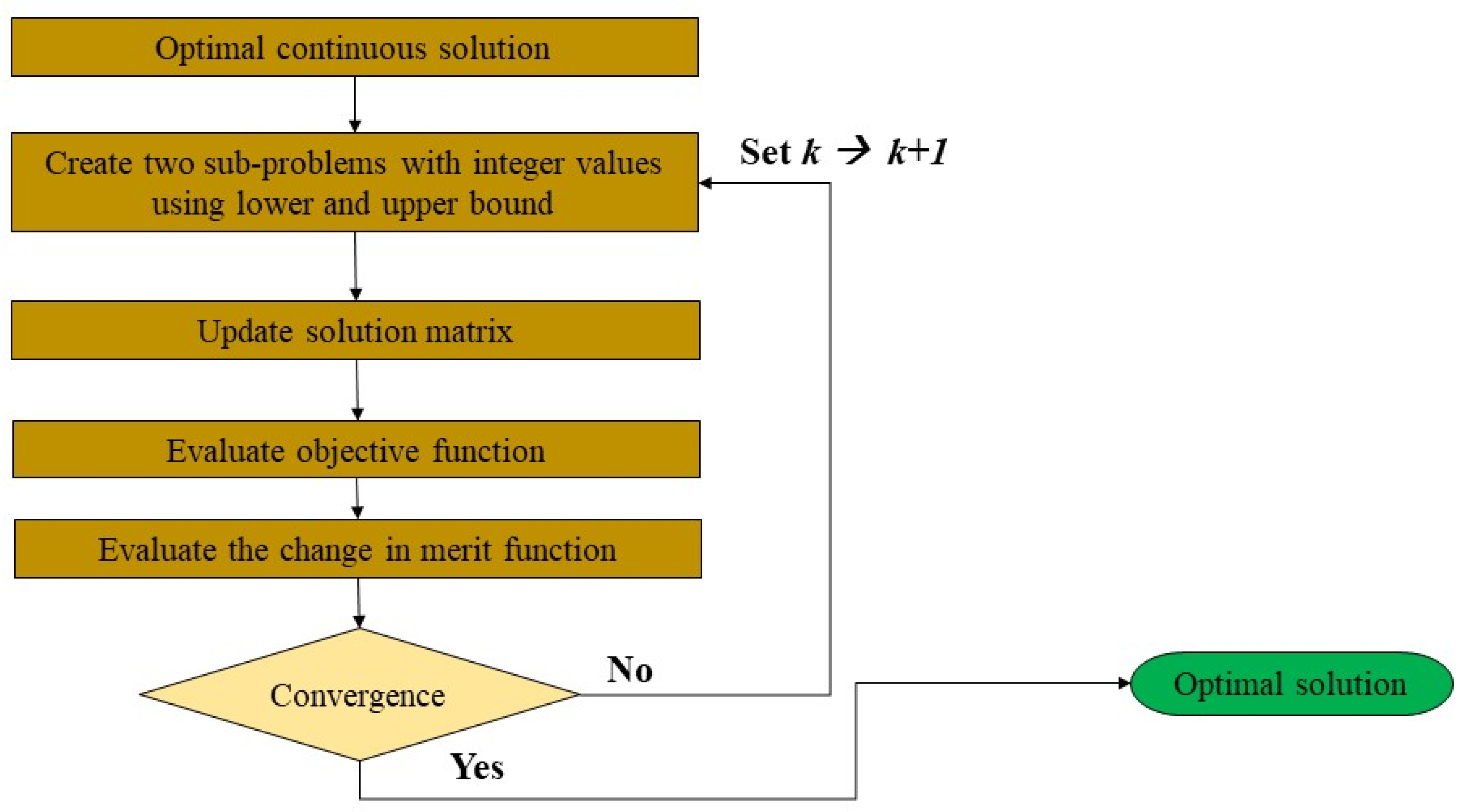
Figure 7 shows the steps of solving the problem to obtain continuous solutions. Finally, through the lower and upper integer bounds of the continuous solutions, sub-problems are created and evaluated to find the optimal solution.
Figure 8 shows the steps for finding the integer solution for the non-linear constrained optimisation problem.
In this study, the Fortran MISQP subroutine was used to implement the SQP method and solve the optimisation problem. As a subroutine, the main program, called the MVA algorithm, is used to solve the queueing network and find the performance measures. All the experiments were conducted on a PC with Intel(R) Core i3-7100U CPU 2.40 GHz, 4.00 GB RAM.
3.5. Discrete Event Simulation Model
In this study, Anylogic Simulation Software 8.7.7 University edition was used to construct a DES model, ensuring methodological rigour regarding stability and model validity.
Figure 9 shows the process map of developing a DES model for study. Utilising blocks from the process modelling library, the simulation model incorporated fundamental components detailed in
Figure 10.
Figure 11 elucidates the configuration options for agents, offering a foundational description.
The parameter component was pivotal in assigning values to agents based on specified requirements, encompassing cost, speed, and capacity. This component facilitated versatile parameterisation by Accommodating Boolean, integer, double, rate, string, and user-defined types. The variable component interfaced with agents, defining dynamic variables like stock levels influenced by agent activities. The function component introduced functionality to incorporate optimisation models, enabling users to establish requirements linked to optimisation experiments for maximisation or minimisation objectives.
AnyLogic’s simulation software implemented successive iterations and metaheuristic approaches for optimisation experiments. The OptQuest Optimisation Engine, integral to AnyLogic’s optimisation tool, harnessed metaheuristics to guide the search algorithm toward optimal solutions. The formulation of optimisation problems involved specifying the objective function, decision variables, constraints, and constraint relaxations through designated tabs, as exemplified in
Figure 12. Users determined iterations and allocated memory, tailoring the experiment to accuracy and computation time requirements.
The optimisation experiment within the ambit of AnyLogic simulation was executed by deploying the OptQuest optimisation engine. This advanced engine harnessed the power of successive iterations and metaheuristic methodologies, strategically navigating the solution space to glean optimal outcomes. The temporal dynamics of the simulation model were orchestrated with precision, spanning a temporal expanse of 20,000 units. A warm-up period of 1000 units was incorporated within this timeframe to ensure the model’s equilibrium before initiating data collection. The reliability and robustness of the results were ensured through the simulation experiments conducted over 20 replications, thereby encapsulating a comprehensive and statistically sound exploration of the system dynamics. This methodological configuration aligns with best practices in simulation experimentation, ensuring a nuanced and reliable analysis of the simulated logistics scenario.
Upon the entry of an agent (truck) into the system, each service block undertakes the crucial task of discerning the truck’s type and the associated product class it carries. Individual trucks exhibit distinct attributes, including carrying capacity, cost, and loading and unloading times. Concurrently, each product class is characterised by unique attributes such as density, demand, and service times at each station. Subsequently, the simulation process involves calculating costs, demand fulfilment for the identified product class, and time allocation. This iterative process continues throughout the cycle. User input imposition of budget, time, and demand constraints becomes imperative. By specifying constraints, the simulation model generates performance metrics for the identified scenarios, offering insights into the system’s dynamic behaviour and efficiency under various conditions (
Figure 13).
4. Steel Manufacturing Case Study—Numerical Experiments
SM manufactures steel rebars of various quality grades according to customer requirements. SM procures its raw materials from domestic and overseas suppliers. There are three major types of raw materials (A, B, and C) SM stores in its storage yards to produce steel billets. In the final processing phase, steel billets are converted into steel bars. Due to storage capacity limitations at the intermediate manufacturing facility, raw materials are stored in a storage yard near the facility (
Figure 14). Each material in the storage yard has a 1200-ton capacity dedicated space. Transportation between the storage yard and the intermediate manufacturing facility is operated by outsourced trucks.
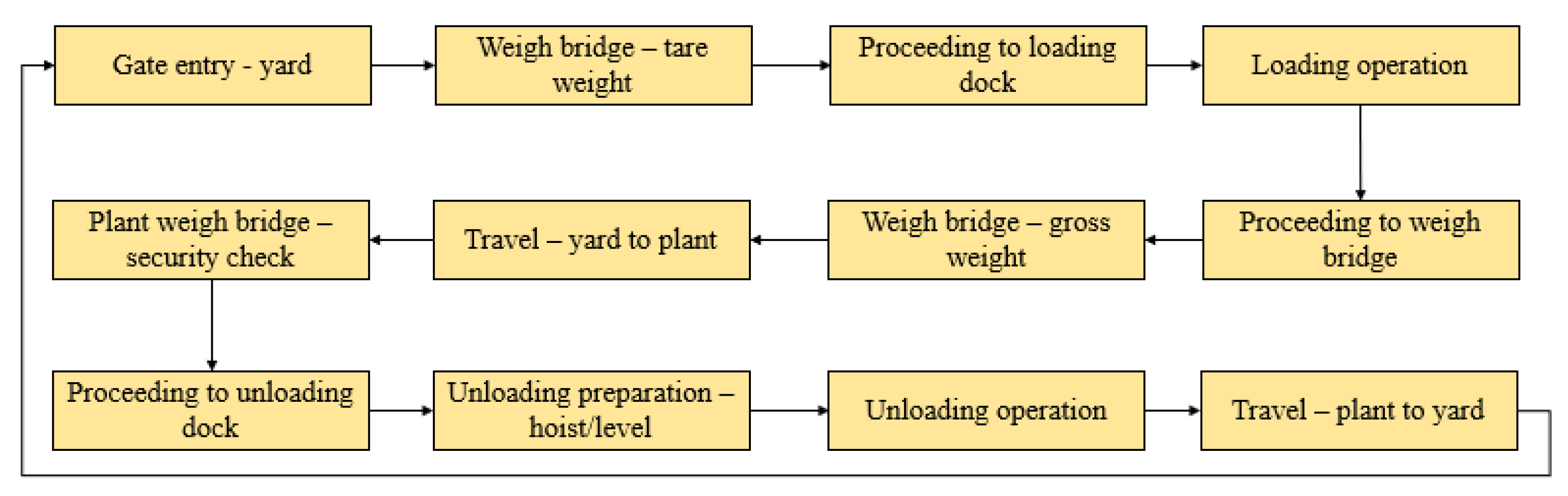
At the start of every day, the production plant informs the storage yard of the material required for that day’s production. Then, according to the day’s requirement, the logistics manager hires the required number and type of trucks to ensure the smooth feed of materials to the plant. In a typical forward flow, a truck goes through many processes, such as documentation, weighing, loading, security clearance, quality check, and unloading. The process map, service station’s node markings, and service times are presented in the
Appendix A (
Figure A1 and
Table A1 and
Table A2).
The heterogeneous fleet engaged in interfacility material transfer operations exhibits variations in cost, carrying capacity, and loading/unloading service times. A delineation of the distinct characteristics of this heterogeneous fleet is provided in
Table 3.
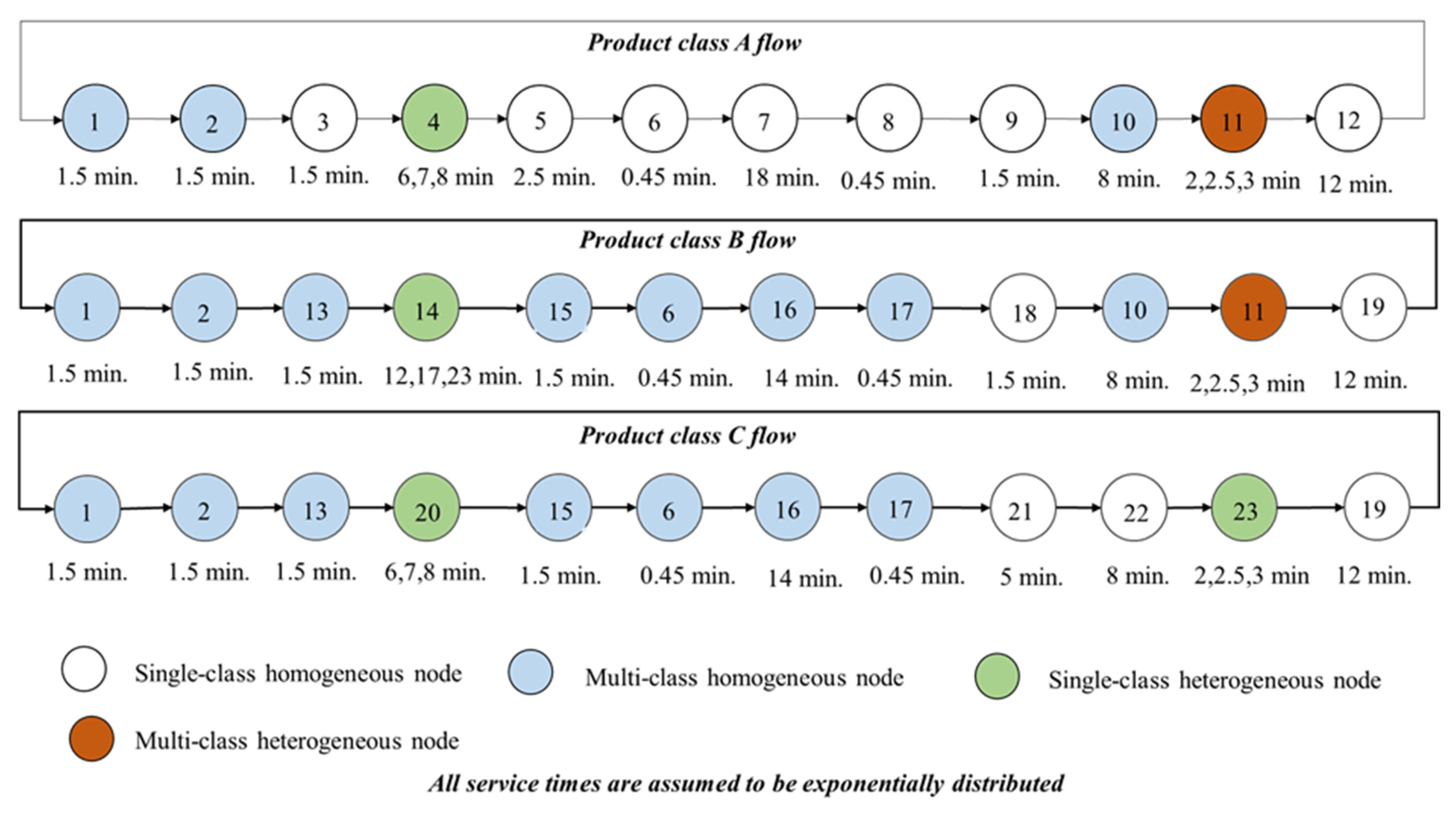
Figure 15 was designed to illustrate the problem as a CQN representation. Within this visualisation, the service times are juxtaposed with the salient features of the network nodes. This graphical representation offers a comprehensive and holistic perspective on the case study problem’s intricacies. It aids in elucidating the interplay between service times and the specific characteristics of the network’s constituent nodes, facilitating a deeper and more intuitive understanding of the problem within the broader context of queuing theory and network optimisation.
The production plant bill of materials (BOM) requirements depend on factors such as committed customer orders, available raw materials in the market, and prices. The management decides the production plan using their information about the above factors. The management then provides the BOM for that day to the storage to feed the intermediate production plant.
Table 4 shows different BOM requirements from the plant to the storage yard for a 12 h shift. This study’s numerical experiments were carried out for the following identified BOM scenarios.
4.1. Numerical Experiments Results Analysis and Validation
This section presents the outcomes of numerical experiments conducted on the scenarios outlined in
Table 4, utilising the analytical model. The results are validated through a comparison with outputs from the simulation model. Initial calculations involved determining the optimal number of trucks and compositions using the analytical method, subsequently verified against the simulation model. Performance metrics, including response times, utilisations, and queue lengths, were estimated through the analytical approach, and meticulously compared with simulation model outputs to gauge the method’s robustness. Subsequently, the algorithm’s performance was scrutinised under varying conditions to assess its resilience. A succinct set of sensitivity analyses were also performed, furnishing insights pertinent to decision-making processes.
4.1.1. Optimal Number of Trucks and Compositions
Table 5 and
Table 6 present the optimal truck quantities and compositions derived from the analytical method and simulation model for each scenario outlined in
Table 4. A DES model (
Figure 16) emulating the SM case study employed the simulation’s built-in optimisation black box.
Table 5 details the optimal truck allocation, composition, and the number of functions evaluated using the analytical method, utilising an SQP method that employs branch and bound techniques for integer point evaluations.
Table 6 mirrors the optimal truck allocation and composition obtained from the simulation model and the corresponding number of iterations. This comparison serves to validate the accuracy of the analytical method’s solutions.
Table 7 presents a comparative analysis of objective function values and computation times between the analytical and simulation methods, validating the analytical approach’s accuracy and efficiency. The objective function values, expressed in dollars, are meticulously documented for each scenario, showcasing the optimal solutions derived from both methodologies. Additionally, the computation times, measured in seconds, provide a critical insight into the time efficiency of each strategy.
Upon examination, it is evident that the analytical method consistently yields objective function values corresponding to the optimal solutions, affirming its robustness in addressing the fleet sizing optimisation problem. Moreover, the analytical method demonstrates superior computational efficiency when juxtaposed with the simulation method. Notably, the computation time for the analytical method remains notably lower across all scenarios, underscoring its proficiency in delivering swift and precise results.
Optimisation experiment settings were configured for a maximum of 5000 iterations in the simulation method, thereby standardising the computation time for all scenarios within the simulation experiments. This standardised setting facilitates a fair and comparable assessment of the two methodologies, emphasising the analytical method’s reliability and efficiency in solving complex fleet sizing optimisation challenges.
4.1.2. Comparison of Response Times
The analytical approach, leveraging the MVA algorithm detailed in
Section 3, employs Equations (3) and (4) to calculate mean response times for single and multiple class nodes. In parallel, the simulation model implemented in the AnyLogic software features an integrated code mechanism designed explicitly for computing mean response times within a given service block.
Table 8 systematically contrasts the response times obtained through the analytical and simulation methodologies, focusing on selected single-class use nodes. The disparity between the two methods is quantified using Equation (18), facilitating a precise evaluation of their alignment. The resultant difference column illustrates that the outputs generated by the analytical method consistently fall within an acceptable margin compared to simulation outputs, as depicted in
Figure 17. Notably, the calculated differences are limited to ±8%, underscoring the analytical method’s capacity to furnish outputs of commendable accuracy in determining queue response times.
Table 9 presents a comprehensive comparative analysis of queue response times between the analytical and simulation methods, explicitly focusing on selected multi-class nodes. The differences between these methodologies have been quantified by applying Equation (18). Furthermore, the calculated difference range serves as a critical metric to assess the acceptability of the disparities, adhering to the predefined criterion of ±8%. This rigorous evaluation aims to affirm the efficacy of the proposed analytical methodology.
The outcomes, as depicted in the tables (
Table 8 and
Table 9), conclusively demonstrate that the mean queue response times obtained through the suggested analytical method, both for single-class and multi-class nodes, exhibit a commendable level of accuracy. This proximity of results substantiates the effectiveness and reliability of the analytical approach in accurately estimating queue response times across diverse operational scenarios.
Moreover, in the context of single-class nodes, response time deviations are marginally lower than those of multi-class nodes (
Figure 18). Furthermore, the analytical method exhibited slightly superior performance in calculating queue response times for circulation nodes (nodes 13 and 19) than for resource nodes (nodes 2, 6, 11, and 10). The difference ranges for circulation nodes were less than ±3%.
4.1.3. Comparison of Utilisation Rates
Utilisation rates serve as crucial performance indicators in operational systems, and their assessment and management are paramount for continuous process improvement. Within the MHSs context, resource utilisation rates are vital in evaluating, controlling, and enhancing system efficiency. In the inter-facility material transfer process studied here, various resources were strategically allocated to cater to the service needs of trucks. Resources such as gates, weighbridges, and security offer uniform services to all trucks, regardless of type or product class, resulting in similar service times. Conversely, resource pools like loading equipment, quality inspection, and unloading equipment may deliver distinct services based on truck types and product classes.
The analytical method, employing Equation (8), was utilised to calculate utilisation rates, while the simulation model employed an in-built command line for the same purpose.
Table 10 provides a comparative analysis between the analytical method and simulation model outputs for selected resource nodes in identified scenarios, with differences quantified using Equation (19).
Table 10 delineates the disparity analysis between outputs derived from the analytical and simulation methods, revealing a consistent range of −2% to −8%, barring a solitary exception. Elevated differences tend to manifest in service station nodes exhibiting high utilisation levels. For instance, in scenario 4, node 10, registering a 0.989 utilisation rate through the simulation method elicited a discrepancy of approximately −12% in the analytical method. This phenomenon aligns with the established literature, indicating that the MVA algorithm may exhibit relative weakness in networks with node utilisation rates approaching 1.0 within CQN non-priority queue disciplines [
86]. Such close proximities to 1.0 signify congested nodes, acting as potential bottlenecks within the system. Timely identification of these bottlenecks aids managers in proactively reshaping systems to avert operational standstill. The proposed analytical methodology consistently furnishes highly accurate utilisation rate estimations, robustly validated against simulation outputs.
4.1.4. Comparison of Cycle Times
Cycle time, a pivotal metric guiding the optimal deployment of trucks for distinct product classes is subject to rigorous comparison between analytical and simulation methodologies in
Table 11. This tabulated data underscores the close alignment between outputs from the analytical method and simulation, with discrepancies confined within the narrow band of approximately ±7%. The findings robustly affirm the analytical method’s competence in delivering accurate mean cycle times, substantiating its reliability in operational scenarios. The disparity between analytical and simulation outputs is quantified by Equation (20), elucidating the negligible divergence within the stipulated range.
4.1.5. Performance of the Optimisation Algorithm
This section delineates the performance evaluation of the numerical SQP approach for solving mixed-integer non-linear optimisation problems.
Table 5 provides a comprehensive overview of the optimum results of the proposed analytical method substantiated through simulation optimisation experiments. The analytical methodology, proven to be a robust tool, demonstrates efficacy in swiftly resolving large-scale problems.
As delineated in
Table 5, the quantity of functions evaluated during the optimisation process emerges as a pivotal determinant influencing the algorithm’s performance. This section scrutinises the performance of the proposed methodology by considering two crucial factors: the lower and upper bounds of the solution and the initial solution. The ensuing analysis, elucidated in
Table 12, encapsulates the optimal solutions achieved under diverse conditions for these specified factors.
Establishing a judicious range for lower and upper bounds in optimising the solution enhances the algorithm’s efficacy. The absence of an upper bound typically leads to a sluggish algorithmic performance, precipitated by the need for an exhaustive search and the subsequent generation of an expansive search tree. Consequently, this amplifies both computation time and the number of functions evaluated. Moreover, introducing an upper bound contributes to the convexity of the objective function.
In the context of scenarios 1 and 2, the presented algorithm underwent rigorous testing against augmented upper bounds to assess its resilience. Encouragingly, the algorithm demonstrated robust functionality with the expanded upper bounds, affirming that the increased bounds did not compromise the number of functions evaluated or the computation time.
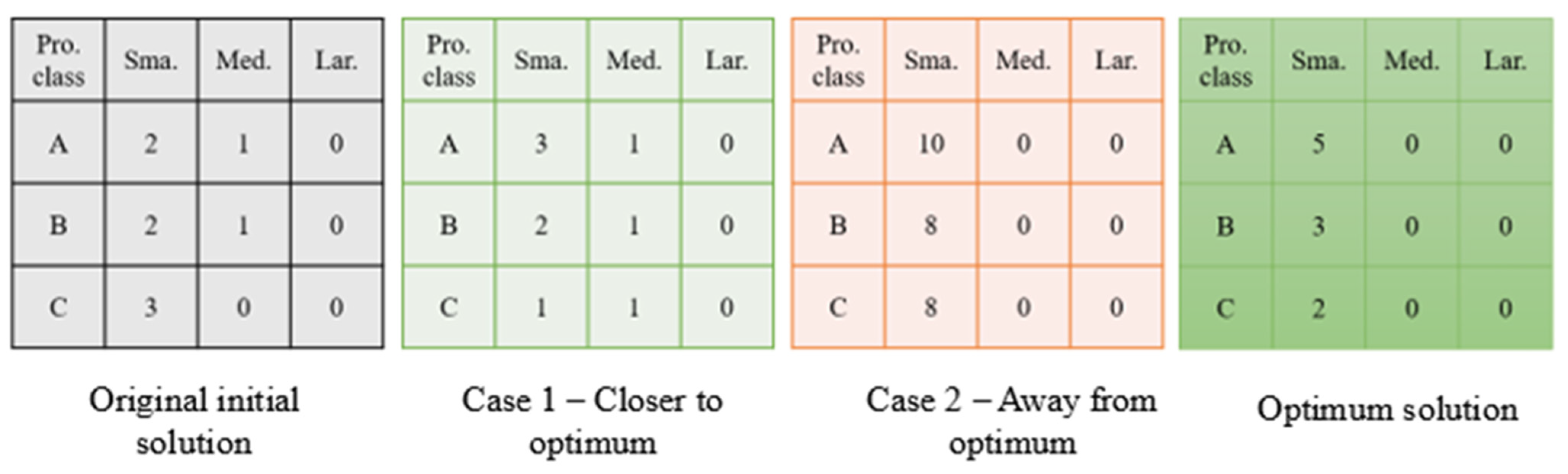
Figure 19 visually depicts the influence of initial solutions on the algorithm’s performance, providing insights into the algorithm’s responsiveness to different starting conditions. The illustration encompasses the representation of the original search’s initial solution, along with the incorporation of two novel starting solutions aimed at assessing algorithmic performance under varying circumstances. One initial solution has been strategically positioned in proximity to the optimal solution, while the other has been deliberately situated at a considerable distance from the optimum. This deliberate selection of divergent starting points allows for a comprehensive examination of the algorithm’s robustness and adaptability across a spectrum of initial conditions, shedding light on its efficacy under favourable and challenging scenarios. Exploring these distinct starting solutions contributes valuable insights into the algorithm’s sensitivity to the initialization phase and ability to converge toward optimal outcomes.
Table 13 presents a comprehensive output analysis for both cases, interpreting the algorithm’s performance under distinct initial solution scenarios. The findings reveal a notable correlation between the proximity of the initial solution to the optimum and the algorithm’s efficiency. Specifically, the algorithm demonstrates expedited performance when initiated closer to the optimum, manifesting in a discernible reduction in computation time and the number of evaluated functions.
Notably, the results in
Table 13 showcase that, in Case 2, where the initial solution is distanced from the optimum, the number of evaluated functions escalates from the initial 121 to 240, and the computation time experiences a substantial increase of 6.5 s. In contrast, Case 1, characterised by a closer initial solution, demonstrates a reduced evaluated function to 96 and improved computation time by 0.8 s. Despite these variations, it is noteworthy that the optimisation algorithm yields identical optimum objective function values for both cases.
This underscores the algorithm’s ability to converge to the optimum even under diverse starting conditions while emphasising the critical impact of the initial solution’s proximity on computational efficiency and resource utilisation. Notably, the non-convergence issue becomes evident when the initial solution is significantly distant from the optimum, underscoring the algorithm’s sensitivity to the initialisation phase.
4.2. Sensitivity Analysis
Sensitivity analysis is an indispensable instrument in decision-making processes across various managerial echelons, offering a nuanced examination of the repercussions associated with contemplated alterations in processes or resource allocations within a given setup. In this context, the present section delves into the ramifications of assigning multiple servers to congested nodes as a strategic intervention to enhance operational efficiency. The investigation meticulously observes changes in improvements in response times within service stations, optimal objective function values, and utilisation rates. Furthermore, an in-depth analysis is conducted on Bill of Materials (BOM) scenarios to minimise material transportation costs. In each scenario, graphical representations delineate material requirements concerning total material demand and transportation costs, facilitating the identification of optimal configurations. This holistic approach provides valuable insights for decision makers by systematically assessing the multifaceted impacts of varying operational parameters on critical performance metrics within the system.
In Scenario 4, the utilisation rates for Node 10 were meticulously estimated at 98.9%, as outlined in
Table 10. This node caters to both class A and B trucks. A node’s utilisation rate nearing 100% indicates a system bottleneck, necessitating strategic intervention. In order to ameliorate congestion, the operational process must undergo a redesign, or the number of servers at the corresponding service station should be augmented. The bottleneck issue at Node 10 demands a proposition that involves introducing an additional server, enabling the concurrent servicing of two trucks. In alignment with the optimal truck allocation, five small trucks for class A and three small trucks for class B were allocated, resulting in a total objective function value of
$1070.
Table 14 presents the enhanced performance metrics of the reconfigured setup, illustrating improved response times, utilisation rates, and objective function values. Notably, the optimised truck allocation objective function experienced a significant enhancement, reducing from
$1070 to
$1000. Simultaneously, response times for class A and class B trucks demonstrated reductions to 9.92 and 10.09 min, respectively. The mean service station utilisation rate exhibited a notable drop to 53.9%. This strategic adjustment effectively addresses the bottleneck issue, optimising system efficiency and resource utilisation, as the refined performance metrics substantiate.
Figure 20 presents 3D surface plots that intricately illustrate the interplay between each material class’s requirements, the total transportation cost, and the aggregate material requirement within the system. All scenarios considered within this visualisation maintain a constant total material requirement of 1800 tons, enabling a discerning examination of cost variations corresponding to changes in individual material requirements. Notably, the surface plots unveil nuanced relationships; for instance, as depicted in
Figure 17, a reduction in the material requirement for class C correlates with an increase in the total transportation cost. Conversely, an augmentation in the material requirement for class A yields a parallel increase in total cost. Material class B exhibits a more intricate pattern, demonstrating a mixed response to material requirements variations and associated costs.
Moreover, increments in the aggregate of materials A and B consistently result in corresponding increases in the total cost. Intriguingly, the transportation perspective attains optimal efficiency with higher material C requirements. This multifaceted analysis not only enriches our understanding of the intricate cost dynamics within the system but also provides nuanced insights into the varied impacts of individual material class requirements on the overall transportation costs, thereby contributing to a more refined decision-making framework.
4.3. Managerial Insights
Table 5 presents the optimal allocation and composition of trucks for different material classes, revealing a consistent preference for heterogeneous fleets in all scenarios. The data underscore the economic and asset utilization advantages of employing diverse truck types, mainly when dealing with the intricacies of transporting mixed products. However, the decision-making process is intricate due to the myriad combinatorial options inherent in heterogeneous fleets, compounded by multiple product classes’ shared usage of certain service stations. As shown in
Table 5, the material requirement and truck allocation for classes C (scenarios 1 and 2) and B (scenarios 3 and 4) are identical. The material requirements for classes B (scenarios 1 and 2) and A (scenarios 4 and 5) are different, but the optimum truck allocations are the same. Therefore, it is understood that optimum solutions are distinctive according to the requirements.
The material required for class A increased from scenarios 1 to 5, and the total cost increased for all the scenarios except for scenario 5 (see
Table 5). Generally, it is observed that when the class A requirement increases, the total cost increases. However, this could be a misleading conclusion since, when scenarios 4 and 5 are compared and the total cost of scenario 4 is higher than scenario 5, the class A requirement is higher for scenario 5. Therefore, managers must understand that they need views of all network situations when engaging in decision-making processes. The sensitivity analysis part, the multi-server case, further strengthens the point of analysing things holistically.
Table 14 shows that node 10 response times reduced for classes A and B improved with allocating an extra server. However, the truck allocation and composition remained the same. Surprisingly, the truck allocation changed for class C due to the improvement in node 10. It switched from 1 large truck to 2 small trucks, giving a
$70 cost advantage. This further highlights the need for a holistic approach to analysing systems for managerial decision making.
In summary, Logistics managers must adopt a systemic view, avoiding isolated improvements that may inadequately address performance issues. Operations should be studied as an interconnected whole, informing continuous improvement initiatives. Since all these processes were directly or indirectly connected, they should be studied and analysed as a whole system to achieve continuous process improvements. Moreover, planning teams can use this information related to the fleet sizing problem in their mid- and long-term planning of capacity capabilities when drafting master plan schedules and material requirement plans.
5. Conclusions, Implications, and Future Extensions
In conclusion, the ubiquitous preference for homogeneous fleets in logistics operations stems from their inherent advantages in operational simplicity, crew management efficiency, resource allocation optimisation, spare parts management streamlining, maintenance scheduling, and performance measurement. These attributes render uniform fleets an appealing choice for diverse logistics activities. However, the operational intricacies of scenarios involving materials with distinct physical attributes underscore the efficacy of heterogeneous fleets. The strategic utilisation of diverse features within a fleet facilitates more efficient multi-commodity transportation operations, enhancing overall operational efficiency. Whether engaged in manufacturing or services and contemplating the acquisition of transportation resources from third-party logistics (3PL) providers, organisations must meticulously evaluate their fleet size and composition to optimise operations, ensuring operational excellence and profitability.
This study explicitly addresses the intricate challenge of determining the optimal allocation and composition of heterogeneous trucks for interfacility material transfer operations obtained from a 3PL service provider. These trucks exhibit variations in cost, carrying capacity, and service times for loading and unloading, rendering them suitable for transporting different types of materials based on demand. The formulation of the interfacility material transfer operation as a CQN with heterogeneous nodes, where service times vary according to truck type, underscores the study’s methodological innovation. Leveraging the MVA algorithm to solve the queueing network and formulating the optimal truck allocation and composition problem as a Mixed Integer Non-Linear Programming (MINLP) problem demonstrates the study’s robust analytical approach.
Moreover, the implications of this study extend beyond its immediate context. The framework can be aptly adapted to optimise container handling operations within the maritime sector, addressing challenges posed by heterogeneous container ships and trailers differing in capacity, loading/unloading times, and container types. Application of these principles can result in enhanced efficiency, reduced port turnaround times, and improved vessel utilisation. Additionally, the study’s insights resonate in humanitarian logistics, where diverse goods with varying characteristics and requirements are commonplace. Optimising the allocation and composition of transport resources in humanitarian missions can facilitate rapid response and efficient distribution, potentially saving lives and resources in crises.
For future research extensions, the framework can be broadened to analyse and optimise multi-modal transportation networks featuring heterogeneous nodes within a CQN, thereby leveraging the distinctive features of various transportation modes. Further development could involve accommodating finite queueing systems, aligning more closely with real-world operational dynamics. Incorporating queueing networks with multi-servers represents a promising avenue for extending the study’s scope and applicability.
In a managerial context, organisations aiming to apply the results of this research should conduct comprehensive assessments of their transportation needs. A meticulous evaluation of transported material characteristics and corresponding fleet requirements is essential. By tailoring fleet composition to align with the specific demands of their supply chain, organisations can achieve improved operational efficiency and cost-effectiveness, ultimately bolstering their competitive position in the logistics landscape.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















