1. Introduction
Heart disease morbidity and mortality are increasing year after year. Meanwhile, heart disease has become a serious disease threatening human health. There are various methods for diagnosing cardiovascular diseases [
1]. Among them, the most common methods are electrocardiograms (ECG) and phonocardiograms (PCG), which are used for detection of heart diseases. ECG can evaluate the condition of the heart work directly. However, in some cases, the ECG cannot reflect all existing disorders, such as the presence of heart murmurs [
2].
In the clinical examination, the doctors first listen to the sounds on the surface of the patients’ chest by the stethoscope. These sounds are called heart sounds (HSs), and the recording of the HSs is called phonocardiogram (PCG). The PCG can reflect the condition of the cardiovascular system comprehensively, which contains pathological or physiological information of the heart. Therefore, PCG has great value in assisting doctors to diagnose or analyze different kinds of heart diseases [
3].
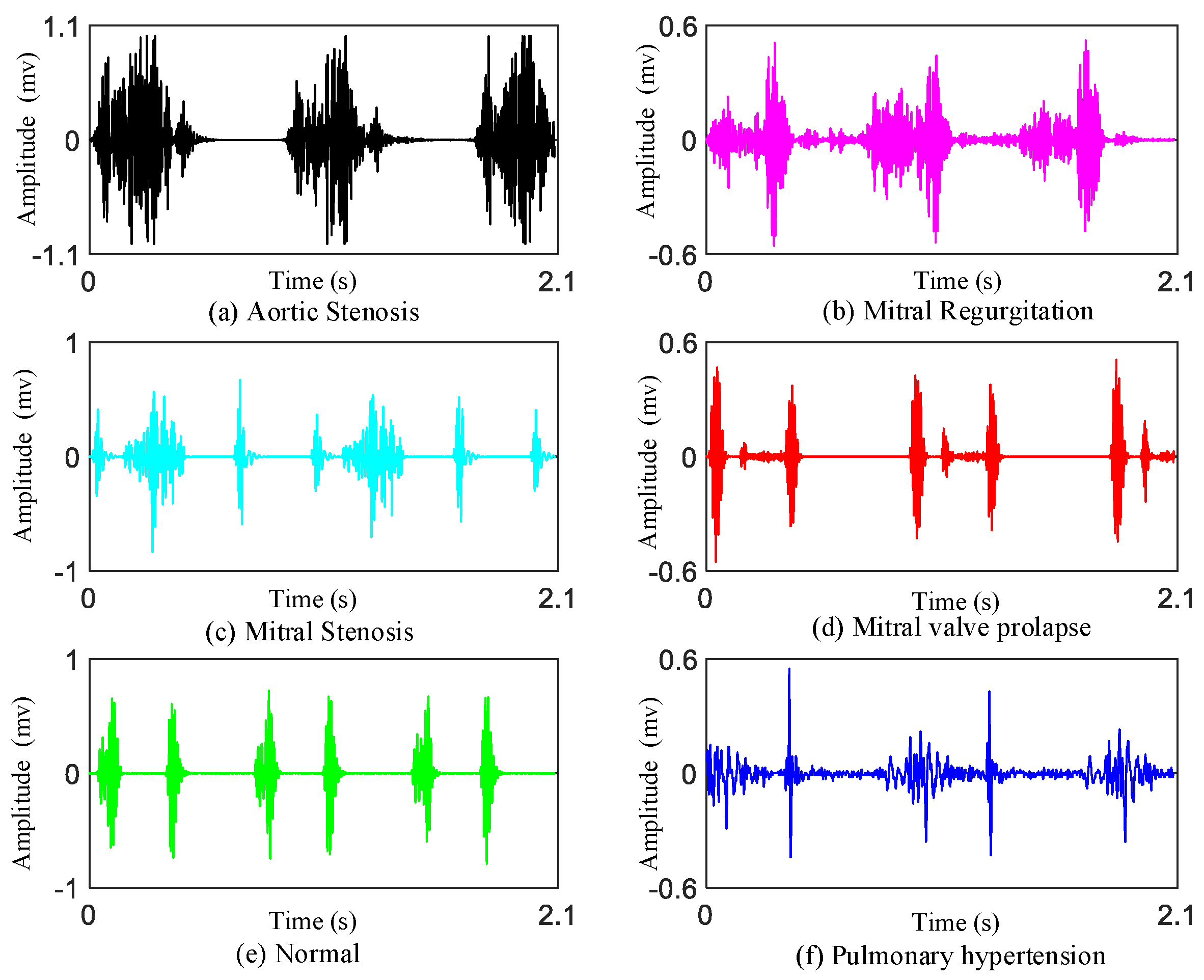
As we know, there are four valves (the mitral valve, tricuspid valve, pulmonary valve, aortic valve) in the heart. If there is a problem with these heart valves opening or closing, there will be damage to the heart which may cause heart valve disease. Heart valvular diseases usually involve mitral stenosis (MS), mitral regurgitation (MR), aortic stenosis (AS), and mitral valve prolapse (MVP). These different heart valvular diseases reflect different features on heart sounds.
Mitral stenosis: Mitral stenosis will cause rheumatic heart disease. Diastolic blood flows from the left atrium through the narrow mitral valve to the right ventricle. It will generate low-pitched murmurs. The murmur can be heard best at the apex.
Mitral regurgitation: The murmur of mitral regurgitation is generated as blood regurgitates from the left ventricle to left atrium. The first heart sounds (S1s) are very soft. We can hear a pan-systolic murmur best at the apex of heart.
Aortic stenosis: The murmur of aortic stenosis is a systolic ejection murmur that peaks early in systole. It is heard best at the second right interspace.
Mitral valve prolapse: If mitral valve prolapse is present, then a mid-systolic click may be heard, followed by a late systolic murmur.
In addition, we also provide the data on patients of pulmonary hypertension (PH).
Pulmonary hypertension: PH is a hemodynamic and pathophysiological condition in which the pulmonary artery pressure rises above a certain threshold. Symptoms of heart sound findings include augmented second heart sound (such as P2 component), tricuspid regurgitant, and the third heart sound (S3) gallop.
However, doctors are not always able to diagnose heart diseases accurately by simply listening or observing a HS record. For this reason, studies on PCG have been increased to make it easier for doctors to make a diagnosis. In recent years, computer-assisted detection technology for the processing and analysis of heart sound signals have made remarkable achievements and aroused great interest [
4,
5,
6,
7,
8].
Currently, smart detection of PCG technology has not been widely used in real-life clinical diagnosis, and the main method used for detection of heart sounds is still artificial auscultation. Therefore, research and application of computer-aided heart sound detection techniques will greatly facilitate the development in the field of cardiovascular disease diagnosis. From the existing research literature, there were mainly four strides used to detect cardiovascular disease: (1) pre-processing of the heart sound signals, (2) segmentation of the first heart sounds (S1s) and the second heart sounds (S2s) or division of cardiac cycles, (3) extraction of features, and (4) recognition of normal and abnormal HS recordings. In general, manual operation or algorithms extract the key features from PCG signals first. Then, they compare the monitoring sequence of the patients with the tagged database. At last, more intuitive diagnostic results can be obtained automatically.
In early years, many researchers paid close attention to the location of the boundaries of HS components (such as: S1s and S2s) [
9,
10,
11,
12,
13,
14,
15]. However, these segmentation methods may be inaccurate with the massive growth of databases today. If the segmentation is inaccurate, then the detection of cardiovascular disease will even be more inaccurate. Therefore, most of the current methods are based on feature extraction to detect heart diseases instead of segmentation of S1s and S2s. In our research, we classify the PCGs without segmentation of HSs.
In the feature-extraction stage, it is worth noting that some of the features of one-dimensional signals are similar in diverse cardiovascular diseases. These similar features may influence the results of the multi-classification. As a consequence, it is particularly important to magnify the variedness in different features of the heart diseases. Many researchers have extracted manual features [
16,
17,
18]. Most of these handcrafted features have physiological explanations, such as the amplitude, time interval, kurtosis, energy ratio, MFCC, and entropy etc. These features have usually been used to conduct binary classification (normal PCG vs. abnormal PCG) by previous researchers. The computation of these manual features is small and simple, but may be not good at multi-classification and new databases. For deep networks with complex and deep structures, the classification effect may be poor. Hence, deep features are needed for multi-classification of heart diseases. Some researchers have used deep-learning models to extract deeper features automatically, such as CNN or other ANN models [
19,
20,
21]. Additionally, their results were better than the results of manual features extraction.
Table 1 shows a detailed comparison with some recent existing excellent work. However, there are some limitations in the field of HSs classification due to the few clinical databases. Additionally, most of the studies have focused on binary classification. At the same time, most of the validation and training was based on one single database (such as PASCAL or Open heart sound database). This is because of the absence of multi-labels heart sound databases and corresponding annotations of the categories of heart sounds from the databases. To solve this problem, we combine the databases from the website [
22] with the data collected by ourselves together, which have six categories of heart sound signals in total (normal, mitral stenosis, mitral regurgitation, mitral valve prolapse, aortic stenosis and pulmonary hypertension). Furthermore, in our research, the proposed method is validated based on data augmentation condition. This works very well under the different noise recordings based on the heart sound augmentation method.
This paper is organized as follows: Part 2 introduces the two databases applied in our research. Part 3 describes the detailed method, such as the CWT for the creation of the time–frequency images and the transfer learning models with the augmented databases. Part 4 describes the results of the 10 transfer learning models. At the same time, the transfer learning models have compared the results with other multi-classification results. Part 5 contains the conclusion of this paper’s proposed method.
3. Methodology
The main objective of this work is to apply transfer leaning networks to detect major cardiac diseases using HS recordings automatically.
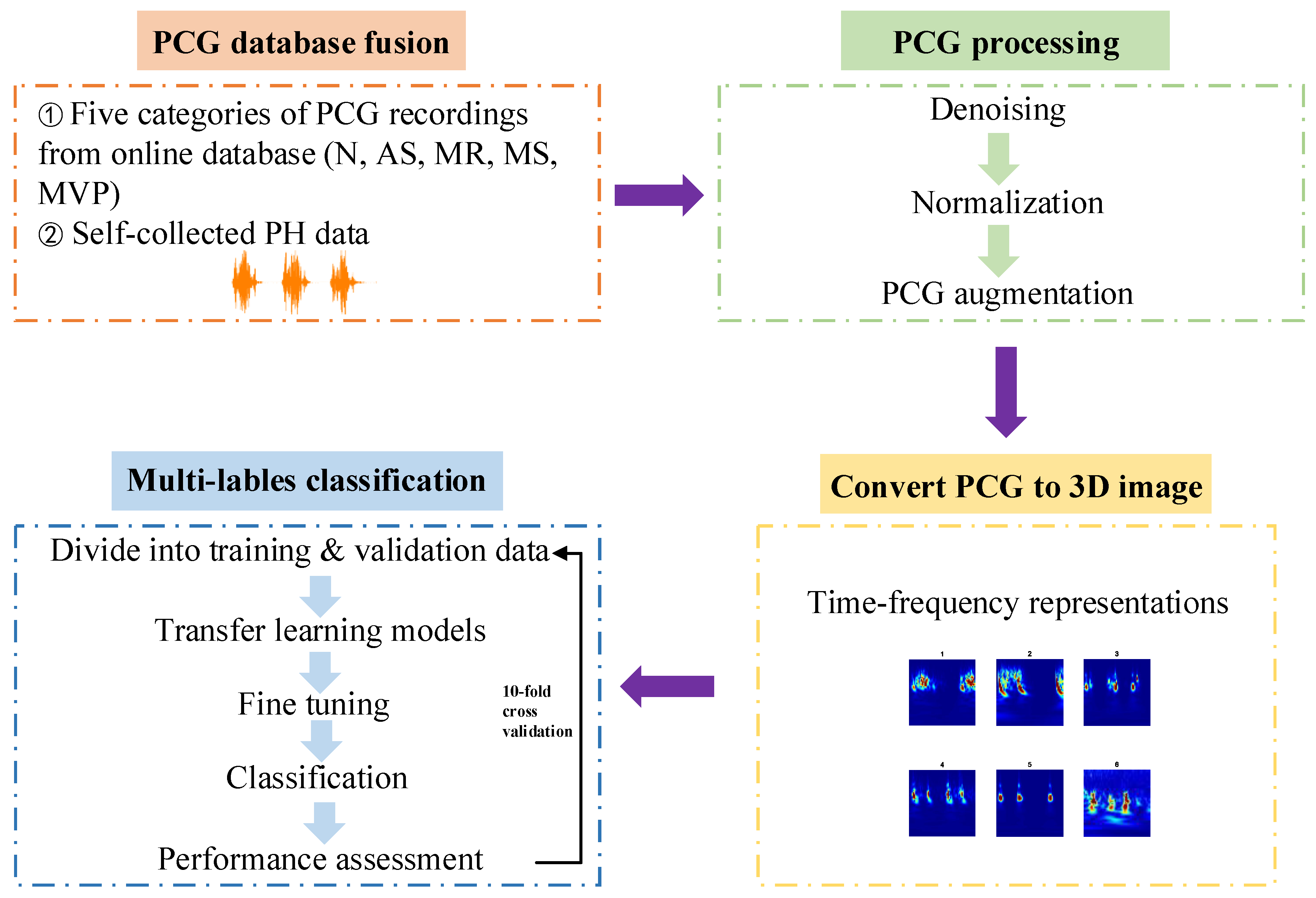
Figure 2 is the framework of this paper proposed approach. In summary, the research is divided into four steps: (1) Acquire the heart sound recordings, one is from the online database and the other one is PH subjects’ recordings collected by ourselves from the hospital; (2) Signal pre-processing including denoising, amplitude normalization and data augmentation; (3) One-dimensional heart sound signal is converted to three-dimensional time–frequency image which can help to improve the performance of the multi-classification results; (4) Apply transfer learning architectures to classify these images for training and testing the models in 10-fold cross validation. The proposed flow path could be used for multi-classification diagnosis of major heart diseases by PCG signals automatically.
Furthermore, the software platform to run the proposed method is based on Matlab 2021a.
3.1. Signal Preprocessing
The sampling frequency of database A is 8000 Hz. However, the sampling frequency of database B is 2000 Hz. We only conduct preprocessing of database B and retain the original signal of database A. To eliminate the difference in sampling frequency, the sampling frequency of database A is reduced to 2000 Hz. Then, each heart sound signal in the two databases has fixed sample length of 2312.
The signal quality of the database A is good, while the heart sound recordings from database B include slight noise. As we know, the frequency of heart sound signal is usually between 50 Hz and 150 Hz [
28]. Digital filters can be used to remove the low- and high-frequency components. In this paper, the HS signals pass a third-order Butterworth filter with bandwidth in the range of 15 Hz to 150 Hz and reverses the filtered sequence and runs it back through the filter to remove the noise outside the bandwidth and avoid time delay. Subsequently, the signals in both database A and database B are normalized using Equation (1).
3.2. PCG Augmentations
Heart sound signal is a time series signal, its characteristics and individual differences hinder the application of the traditional data augmentation methods in the field of heart sound signal. Hence, how to explore a more effective and more suitable augmentation method from the original heart sound signal is an important problem for building of the multi-label heart sound diagnosis system.
The operation process of data augmentation usually included flip, rotate/reflection, shift, zoom, contrast, color and noise disturbance [
29,
30,
31]. However, these data augmentation methods in the image field only change basic information such as position and angle from a macro perspective, and these methods can only apply in the field of simple computer vision methods such as image recognition, which can not be applied to data augmentation of heart sound signals.
In this research, the PCG augmentation method applies a 1D signal augmentation mechanism. The augmentation method includes HS signals under various cases in order to recognize the model with stronger generalization performance. The methodology explores background formations, and at the same time the transfer learning models are able to categorize various heart sound signals even in a noisy circumstance.
There is a given heart sound signal represented as ‘original_signal’. At the same time, the same-size background transformations are generated stochastically. The background transformation is displayed as ‘random_signal’, where the ‘delta’ represents the parameter of the deformation control. The background deformation ‘delta’ belongs to the interval “(0,1)". An augmented signal is calculated based on Equation (2), which is generated based on the random background noise mixed with the original heart sound signal. It should be noted that in the testing unit there is no data augmentation.
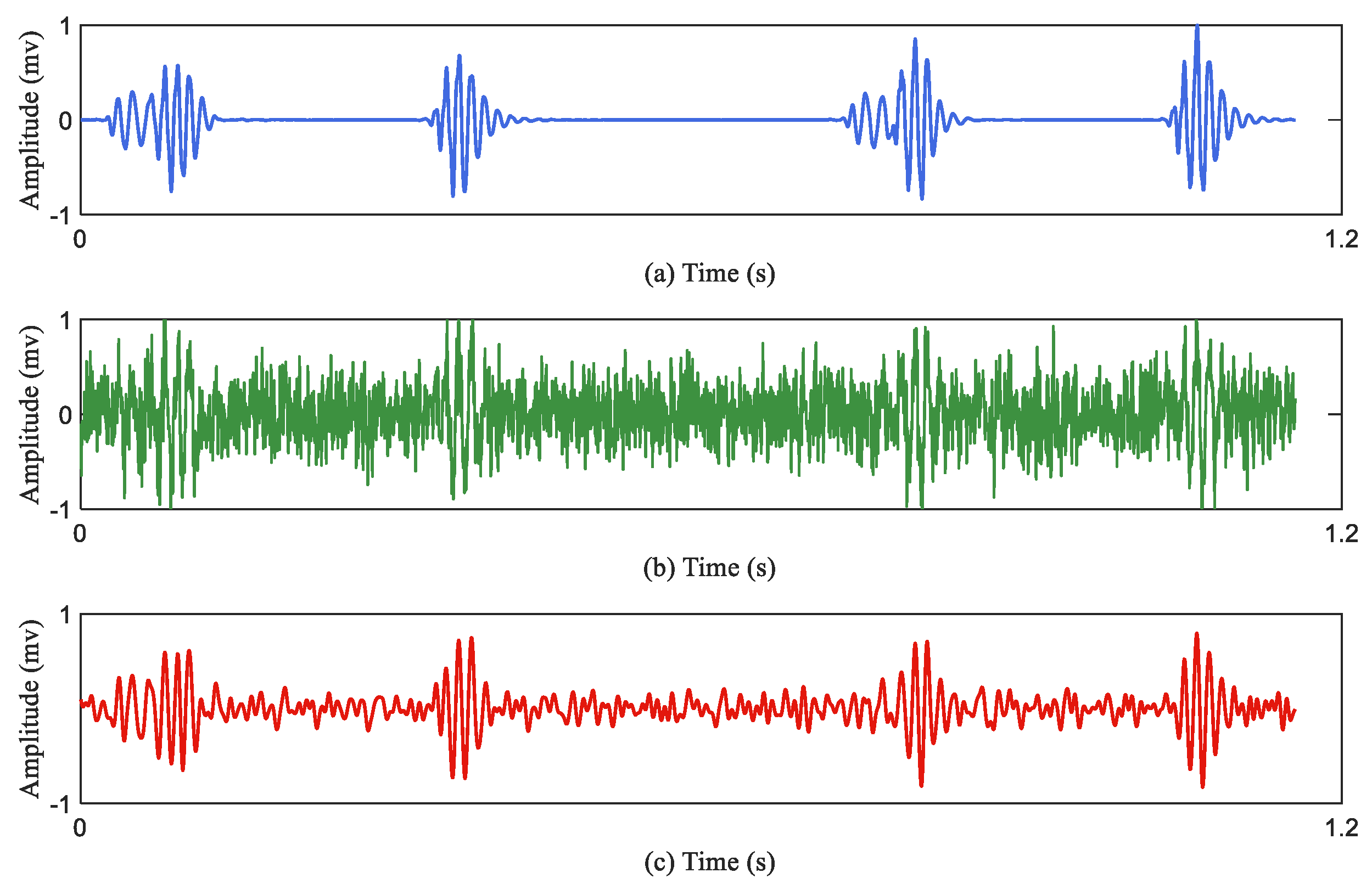
Figure 3 describes the effect of the data augmentation.
Figure 3a represents the original heart sound signal;
Figure 3b represents the augmented heart sound signal through the Equation (2);
Figure 3c represents the denoised signal of the
Figure 3b.
Table 3 summaries the recording distribution after data augmentation. Finally, the database contains 2400 PCG recordings in total. There are 400 PCG recordings in each class.
3.3. Creating Time–Frequency Representations
Time–frequency transformation is a common approach in the classification of speech events to extract a time–frequency representation of sound. Time–frequency representation is to convert a one-dimensional signal into a three-dimensional image representation. After that, the features extracted from the transformation are used to identify the most likely source of sound. Based on the investigation in [
32], the authors conclude that among three time–frequency representations (short-time Fourier transform (STFT), Wigner distribution, and continuous wavelet transform (CWT)), CWT gives the clearest presentation of the time–frequency content for PCG signals.
The CWT spectrogram is produced by Morse analysis. A magnitude spectrogram of the heart sound signal is calculated for each sample. These spectrograms are used to train and test the transfer learning models. The CWT of a heart sound signal
is defined in (3), and Equation (4) is the Morse analytic wavelet:
where
is a heart sound signal,
is the mother wavelet, and
and
are the parameters that manage the scaling and translation of the wavelet, respectively. The CWT is calculated by varying
and
continuously over the range of scales and the length of the heart sound signal, respectively.
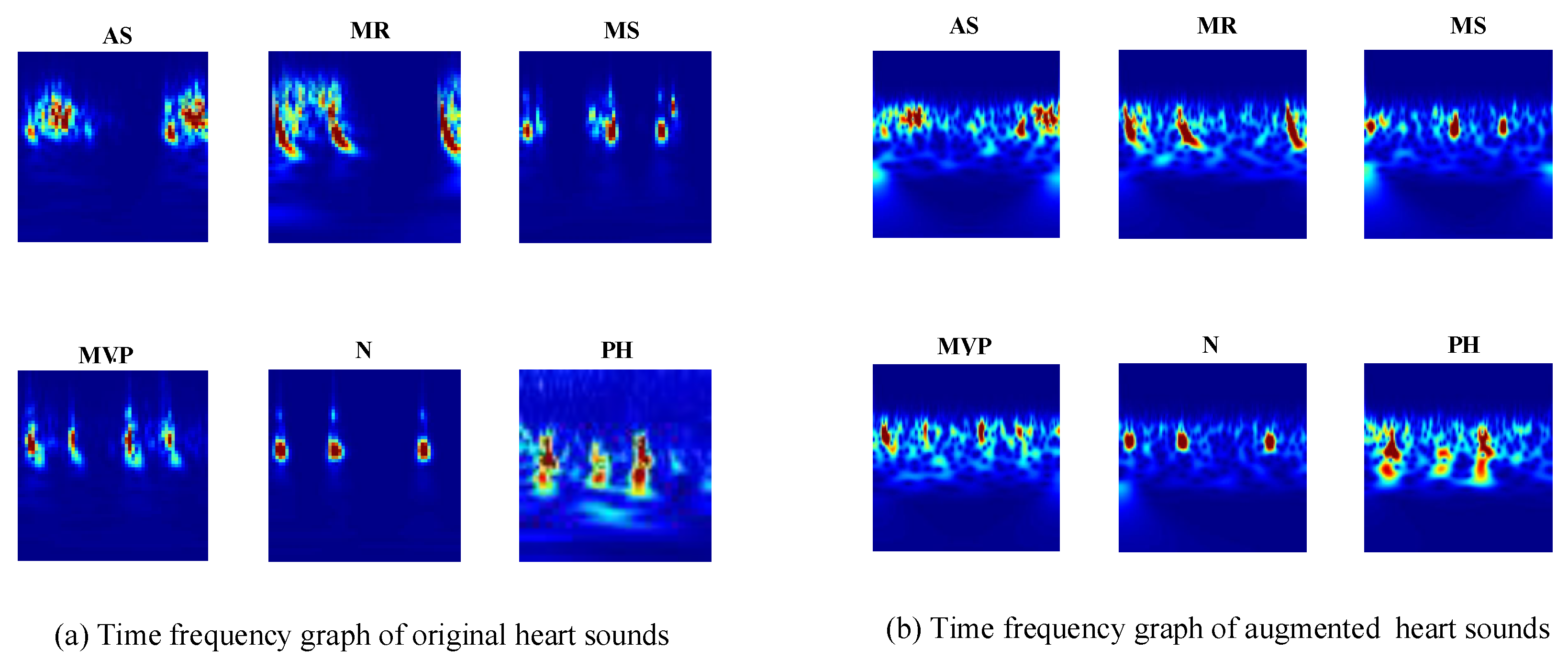
The CWT provide superior time and frequency resolution. This allows for different-sized analysis windows at different frequencies. The spectrograms of the heart sound signals show the frequencies at different times and provide an optical presentation that can be used to tell apart the various heart sounds. The CWT creates 3D scalogram data and they are stored as RGB images. To match the inputs of different transfer learning architectures, each RGB image is resized to an array of size n-by-m-by-3. For example, for the GoogLeNet architecture, the RGB image is resized to an array of size 224-by-224-by-3. The six typical spectrograms of HS signal are shown in
Figure 4.
Figure 4a represents the spectrogram of the original heart sound signals;
Figure 4b represents the spectrogram of the augmented heart sound signals.
3.4. Architecture of Transfer Learning for PCG Multiple Classification
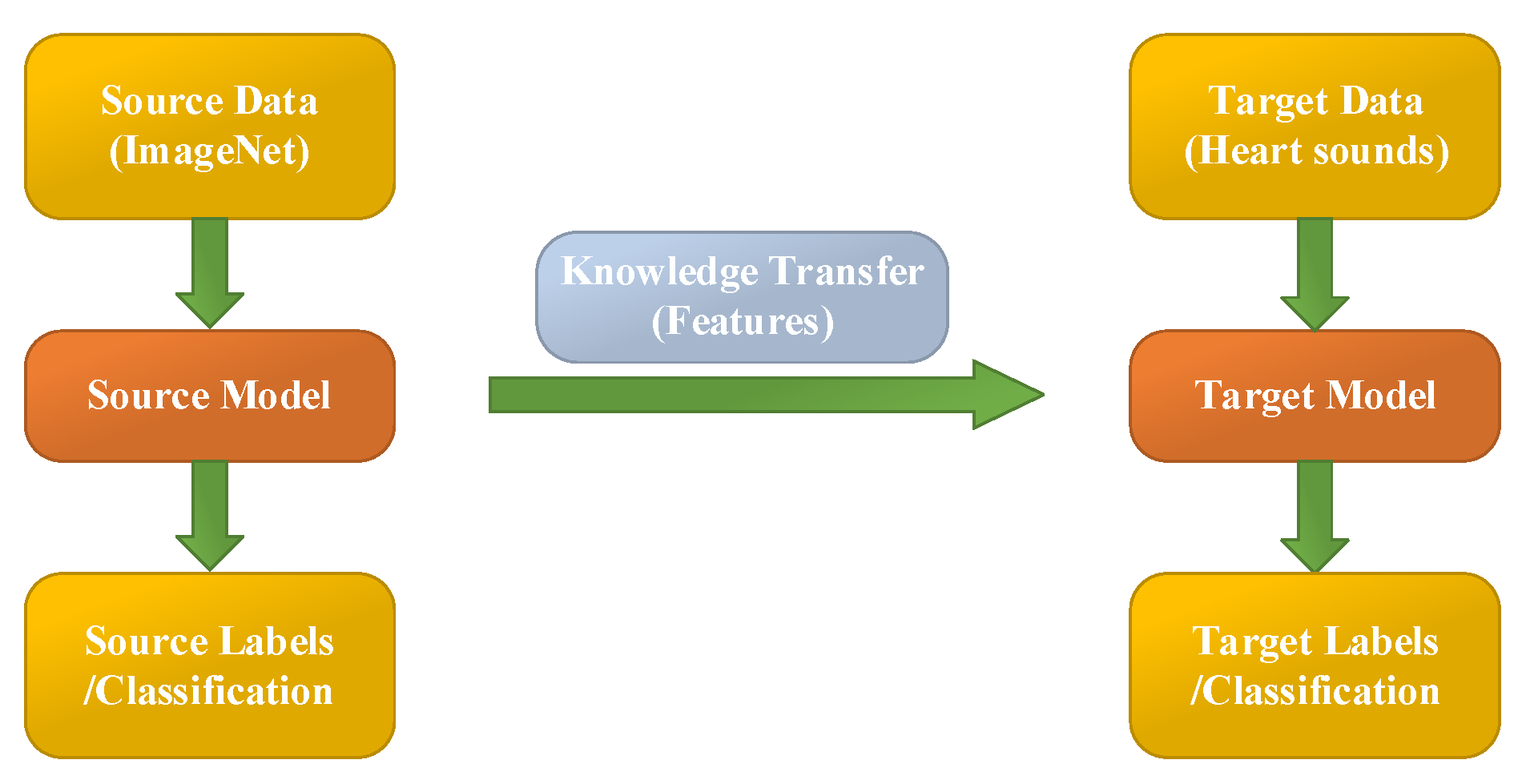
Transfer learning aims at utilizing the acquired knowledge on target domains to address other problems in different but related areas. This approach may be a better choice than some simple structures of CNN models. However, transfer learning is rarely reported and considered for classifying PCG signals.
In this work, the heart sound signal is converted into its corresponding pattern based on CWT spectrogram, and two syncretic databases of HS signals are taken as one database to perform experimentation. The 10 existing transfer learning models (Squeezenet, Googlenet, NasNet-Large, Inceptionv3, Densenet201, DarkNet19, Mobilenetv2, Resnet101, Xception and Inceptionresnetv2) are used to classify the heart sound signals into six categories (N, AS, MR, MS, MVP, PH). These parameters of transfer learning models are shown in
Table 4. It is worth noting that the different transfer learning models have different image input sizes, therefore the generated images should follow the input size of the models.
Table 4 shows the image input sizes of the models. Additionally,
Figure 5 illustrates the flow chart of transfer learning.
In this research, the pre-trained transfer learning networks’ parameters are modified and some of the architectures are fine-tuned. The earlier layers identify more common features of images, such as blobs, edges, and colors. Subsequent layers focus on more specific characteristics in order to differentiate categories.
For example, the original GoogLeNet is pretrained to categorize various pictures into 1000 target categories. However, in this research filed, we retrain GoogLeNet for solving the problem of PCG classification. To prevent over-fitting of the transfer learning model, a dropout layer is used. The final dropout layer (‘pool5-drop_7x7_s1’) is replaced for a dropout layer of probability 0.6. Furthermore, we also replace the layers of ‘loss3-classifier’ and ‘output’ with a new fully connected layer to adapt to the new data. At last, the learning rate factor is increased to 0.001. This is an iterative processing for training a neural network for minimizing the loss function. A gradient descent algorithm is used to minimize the loss function. In each reiteration, the loss function gradient is assessed, and at the same time the weight of the drop algorithm is updated. We set mini-batch size to 10 and max epochs to 15. In this paper, the stochastic gradient descent with momentum optimizer is applied. The other transfer learning models have the same settings as above.
The analysis and model development are performed in a workstation with hardware/software configuration and specification as follows: DELL(R) Precision T3240 i7-10700, Graphical Processing Units (GPU) NVIDIA Quadro RTX3000, 64GB RAM, and 64-bit Windows 10.
3.5. Model Training and Testing
The proposed methods used diverse HS data for training, validation and testing. The training and testing are based on 10-fold cross validation. In this research, nine folds are used for training the transfer learning models while one fold is used for testing. The process iterates repeatedly to ensure the coverage of the entire database for training and testing conditions. The choice of each fold is not based on independent subjects, because all the recordings of the patients are put in one collection. The training data includes all of the augmented data and 90% of the original heart sound data (There are 3800 heart sound recordings which include 2000 augmented heart sound recordings and 1800 original heart sound recordings). The testing data only include 10% of the original heart sound data (includes 200 original recordings).
3.6. Assessment Indicators
To evaluate the performance of the methodology in this paper, four indicators, accuracy, precision, recall and Fl-score, are used. Accuracy (ACC) is the indicator of all the correct recognition events. Precision and recall are powerful estimations when the database is quite imbalanced. Additionally, the F1_score is defined as the harmonic mean of precision and recall. The equations of the performance are calculated as follows:
4. Experiment Results and Discussions
4.1. Experiment Results
Table 5 shows one transfer learning model’s result—the accuracy with loss of the GoogleNet training and testing in the augmented PCG database and the original PCG database, respectively. The experiment is performed on the 10-fold cross validation. Here, in
Table 5, there are some parameters, such as train samples, test samples, training accuracy (Acc), testing accuracy (Val Acc), training loss (Loss) and testing loss (Val Loss) on each fold.
Table 5a shows 10-fold cross validation results on the augmented PCG database.
Table 5b shows 10-fold cross validation results on the original database. It is visible from the
Table 5a,b that the proposed methods achieve an average of 98% accuracy in classification of six categories both with the augmented data training and the original data training. The results of the PCG database show the efficiency of this method. Furthermore, we also evaluate the impact of the PCG augmentation method with additional background deformation.
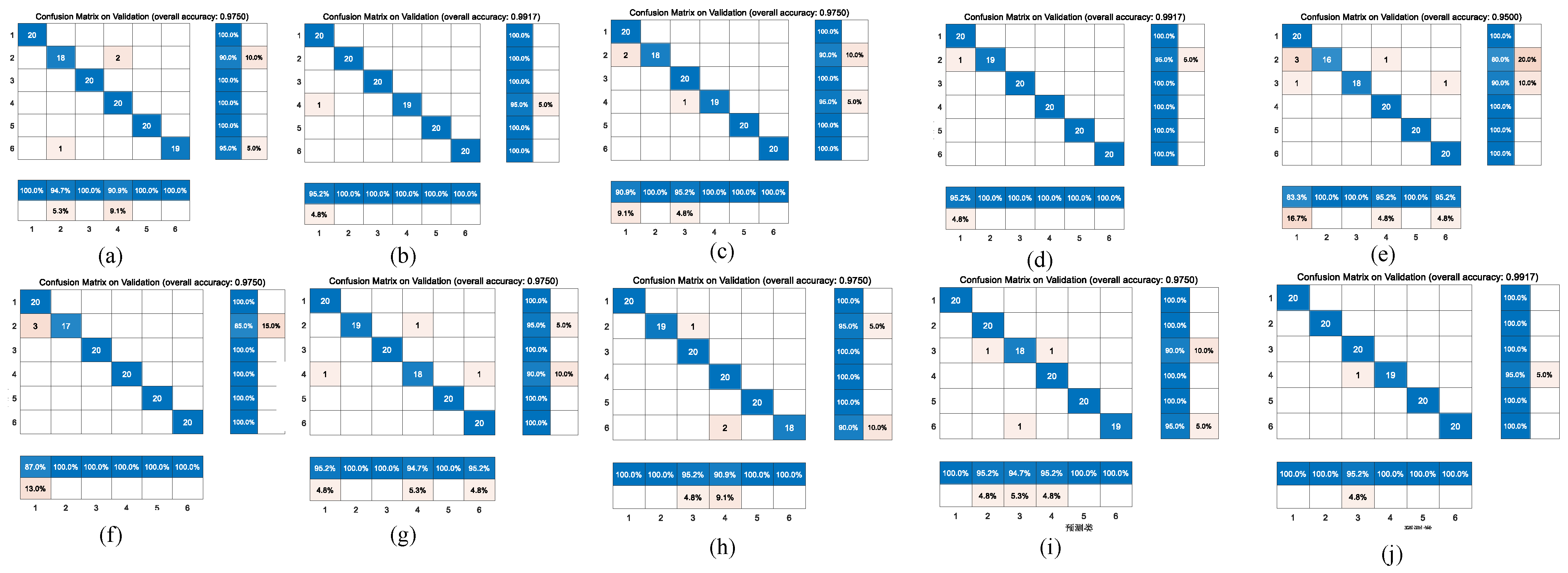
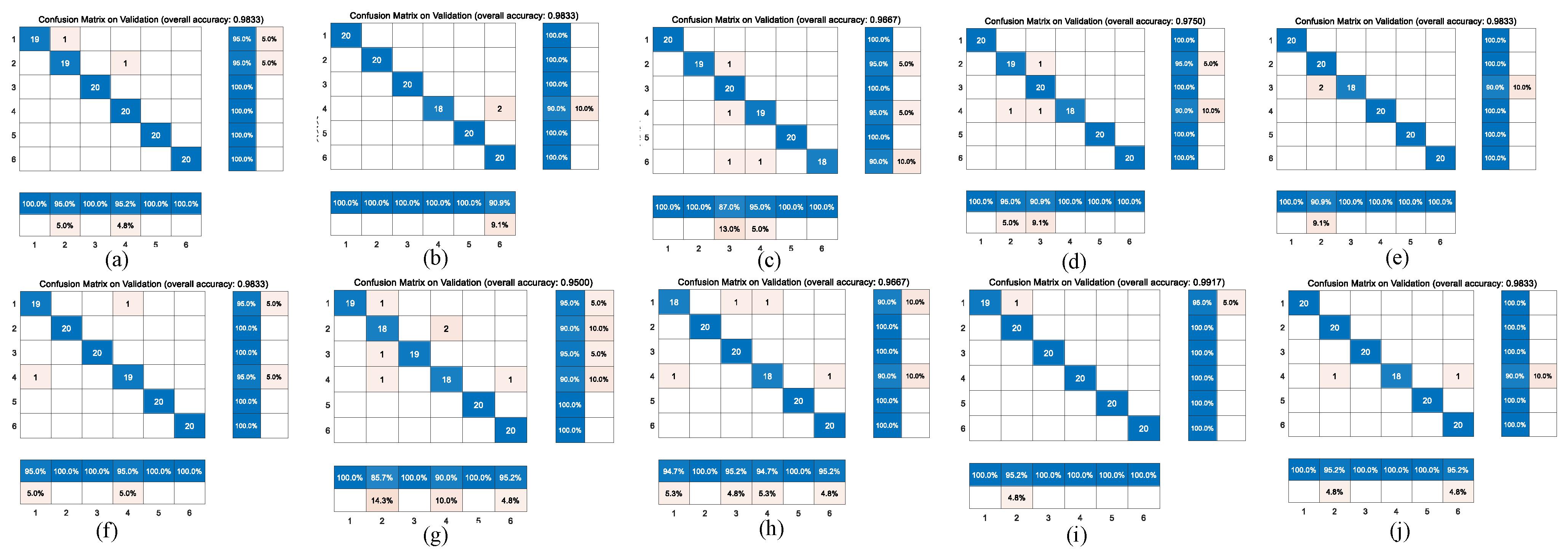
Figure 6 and
Figure 7 represent the confusion matrix for the entire 10-fold with multiple classification estimations. At the same time,
Table 6 shows the performance (precision, recall and Fl-score) of the GoogleNet structure for the multiple classifications of different heart diseases for all 10 folds with various indicators on the augmented PCG database and on the original PCG database.
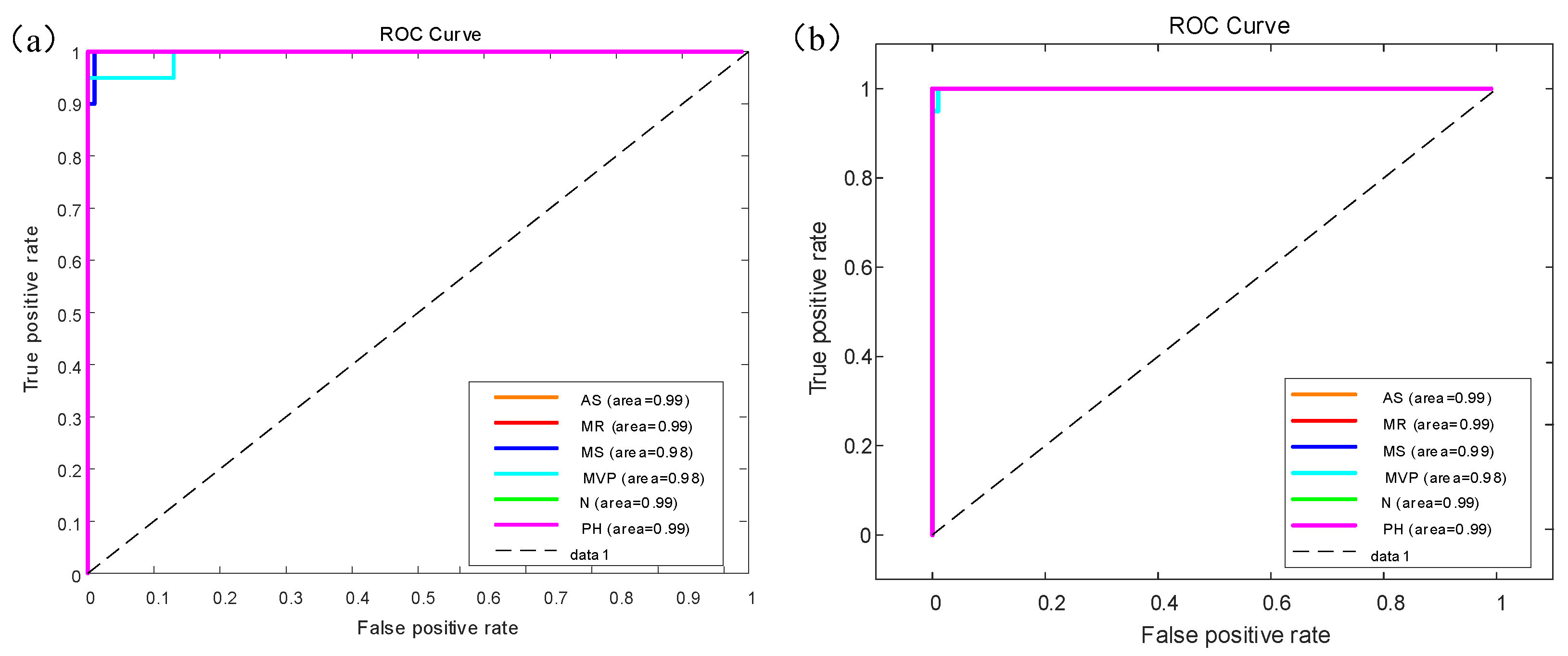
Figure 8 shows the receiver operating characteristic (ROC) curve for the GoogleNet model results of multiple classifiers for six categories of heart sounds with AUC area. There are six colors which represent different categories of heart sounds.
Figure 8a shows the ROC curve on the augmented PCG database;
Figure 8b shows the ROC curve on the original PCG database.
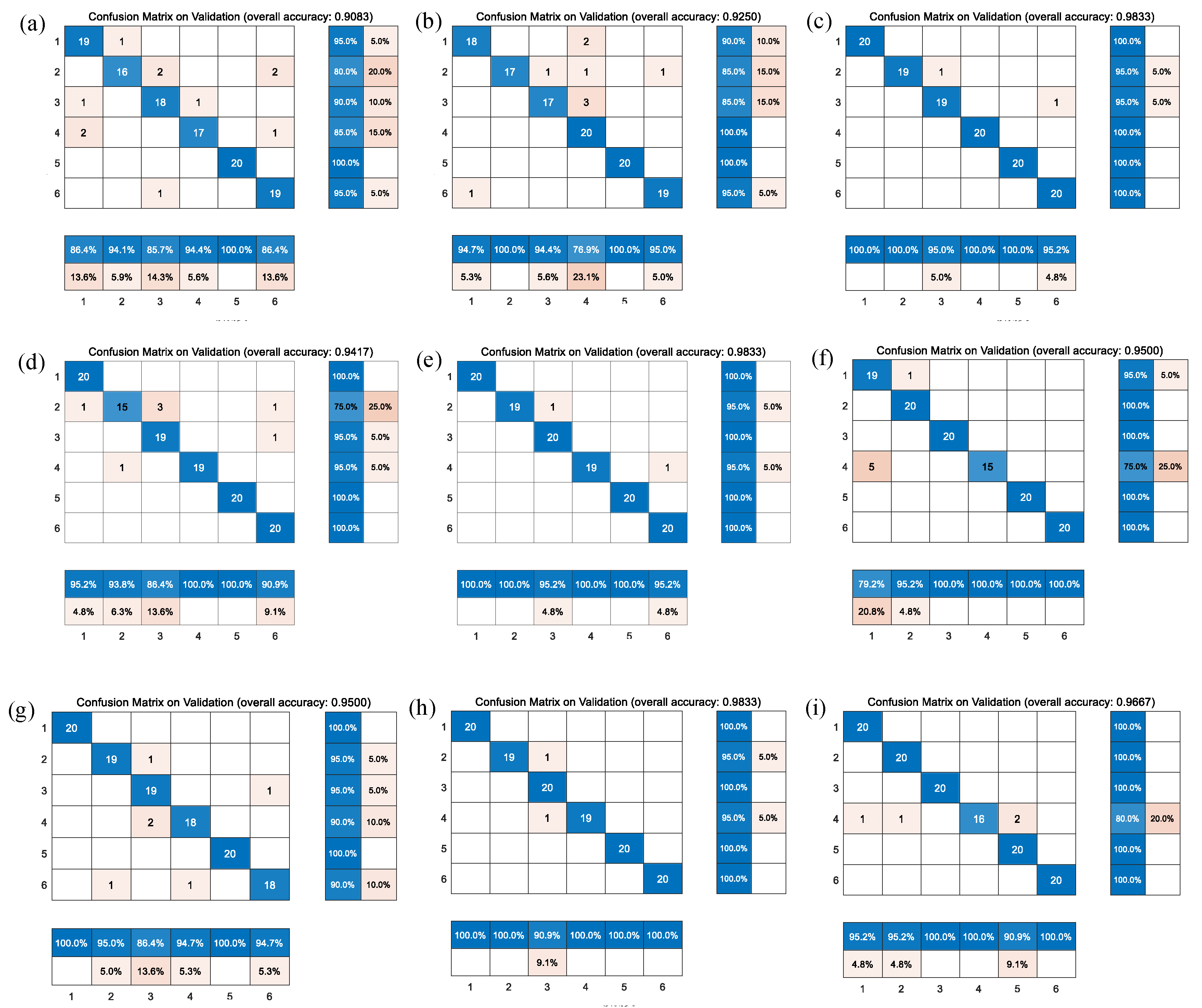
Figure 9 shows the comparison of the different confusion matrices for the multi-classification by the other transfer learning models, such as Xception convolutional neural network, NASNet-Large convolutional neural network, resnet101, inceptionv3, densenet201, Inception-ResNet-v2, mobilenetv2, darknet, and squeezenet.
Table 7 presents the accuracy, recall, precision, and F1-scores corresponding to these transfer learning models, where the results show that the Resnet101, Densenet201, Darknet and the model before we used GoogleNet obtained good accuracy in comparison with peer approaches.
4.2. Experiment Discussions
The methods proposed by the authors have only considered one depiction of heart sound signals, which is spectrogram from the HSs. The spectrogram is an image representation of sound signals in the time–frequency domain. The inputted heart sound signals have been first converted into the respective spectrogram and then are classified further into six categories using the transfer learning models.
In addition,
Table 8 describes the other methods without transfer learning. It shows the accuracy of other methods compared with the transfer learning models in the multiple classification of heart diseases. The comparison of these different methods is performed on the same database. However, the result from
Table 8 shows that the accuracy is very low. We conduct two controlled trials: (1) Original 1D PCG signals are inputted into the Bi-LSTM network for six categories of heart sound classification, but an accuracy of only 21.67% is achieved; (2) The 3D images of the heart sound spectrogram are inputted into the simple CNN network only with three convolution layers, and the accuracy is only 76.67%.
Compared with B-mode ultrasonography, nuclear magnetic resonance imaging, computed tomography and so on, phonocardiography has the characteristics of being non-invasive, non-destructive, good repeatability, simple operation and low cost, which could be applied for the prevention, preliminary diagnosis and long-term monitoring of related diseases. With the development of digital medical technology and biological technology, researchers have increased the demands on the processing and analysis of heart sound signal in related fields. Automatic analysis methods for processing of medical sequence signals can share the responsibility and pressure of the medical domain, and provide long-term monitoring of disease. At the same time, they can help medical staff to grasp the condition better then work out plans for disease prevention and treatment. Thereby, doctors can enhance the overall health of society.
Despite advancements in the automatic diagnosis of heart sounds domain, there are still some limitations to be overcome to develop this technology further. For example, database deficiencies, huge feature extraction and low accuracy in multiple classification of heart disease. Solving these challenges can allow deep-learning technology to obtain a huge breakthrough in the field of human health. In our paper, we provide a heart sound database of pulmonary hypertension which is the first heart sound database related to pulmonary hypertension. Furthermore, feature extraction of heart sounds often takes a lot of time to acquire, which is a limitation. For this reason, we also proposed one-dimensional signal transfer to the three-dimensional image for training and testing, which can generate features automatically by a convolution layer in the heart sound domain. At last, we propose transfer learning technologies to diagnose multiple heart sounds and obtain a good performance. This overcomes the independent learning pattern through applying previously learned knowledge to solve similar problems. It is important for small-sample-size data to use transfer learning in the artificial intelligence domain because the pre-trained weights can be more efficient in training and obtain a better performance.
In this work, we suspect that the diversity of the augmented data can contribute to the networks’ ability to generalize to unseen data during the training stage. Data augmentation can improve the robustness of training. Comparison is made with traditional methods and transfer learning. In all experiments, the transfer leaning networks performed better on the task than other simple networks (such as Convolutional Neural Network and Long Short-Term Memory Network), as shown by several performance metrics. This approach has the potential to provide physicians with an efficient and accurate means to triage patients.
The proposed approach would have a significant impact in clinical situations by assisting medical doctors in decision making regarding different kinds of heart diseases. Our model performs efficiently in predicting the occurrence of an abnormality in a recorded signal. Moreover, it is tested on specific valvular diseases and patients with pulmonary hypertension who are not easily diagnosed early.
In summary, there are three contributions of this work. (1) The first is that we provide a new type of heart sound database (PH database). Additionally, our methods are validated under different conditions of HS databases. (2) The second is that we use a HS data augmentation strategy for completely automatic heart disease diagnosis. The method of augmentation improves the robustness of the heart diseases diagnosis, especially in noisy environments. (3) According to the published literature, transfer learning is rarely applied in the field of heart sound classification. We use 10 transfer learning models to verify the classification methods. We obtain a low error rate and great accuracy (0.98 accuracy for six categories of heart sounds) for multiple classification of heart diseases, which help to cope with multiple classification issues.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}