

An Enhanced Python-Based Open-Source Particle Image Velocimetry Software for Use with Central Processing Units


Abstract
:1. Introduction
2. Materials and Methods
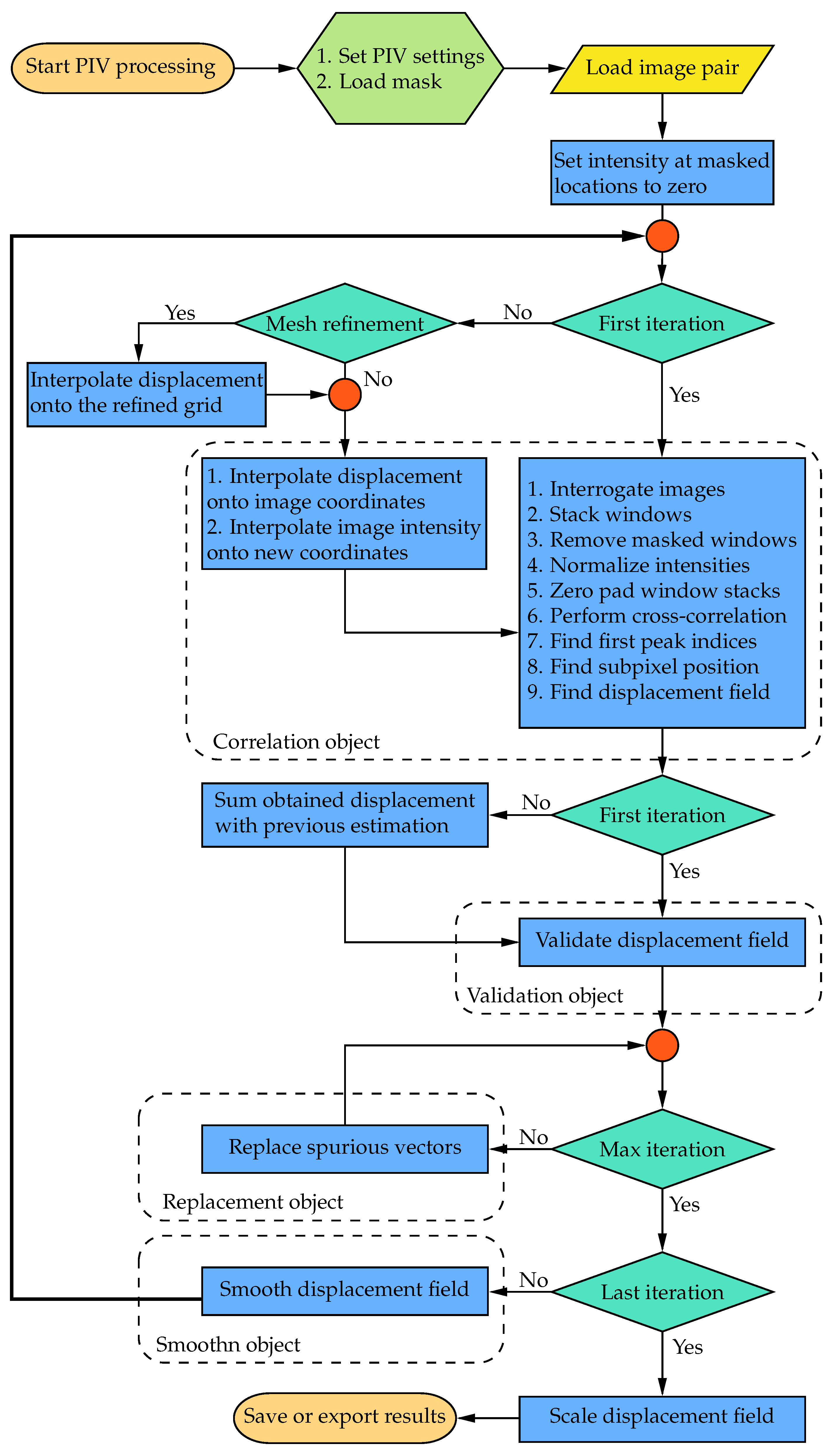
2.1. Implementation and Architecture
2.2. Datasets and Image Processing
3. Results
3.1. Mean Flow Field
3.2. Instantaneous Flow Field
3.3. Computational Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PIV | Particle Image Velocimetry |
| CPU | Central Processing Unit |
| GPU | Graphical Processing Unit |
| WIDIM | Window Deformation Iterative Multigrid |
| PyPI | Python Package Index |
| DFT | Discrete Fourier Transform |
| FFTW | Fastest Fourier Transform in the West |
| LIL | LIst of Lists |
| CSR | Compressed Sparse Row |
| DNS | Direct Numerical Simulation |
| CDI | Central Difference Interrogation |
| STD | Standard Deviation |
| CI | Confidence Interval |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| NSERC | Natural Sciences and Engineering Research Council of Canada |
Appendix A
Appendix B


References
- Adrian, R.J. Twenty years of particle image velocimetry. Exp. Fluids 2005, 39, 159–169. [Google Scholar] [CrossRef]
- Raffel, M.; Willert, C.E.; Scarano, F.; Kähler, C.J.; Wereley, S.T.; Kompenhans, J. Particle Image Velocimetry: A Practical Guide, 3rd ed.; Springer International: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Booth-Gauthier, E.A.; Alcoser, T.A.; Yang, G.; Dahl, K.N. Force-induced changes in subnuclear movement and rheology. Biophys. J. 2012, 103, 2423–2431. [Google Scholar] [CrossRef] [PubMed]
- Sarno, L.; Carravetta, A.; Tai, Y.C.; Martino, R.; Papa, M.; Kuo, C.Y. Measuring the velocity fields of granular flows–Employment of a multi-pass two-dimensional particle image velocimetry (2D-PIV) approach. Adv. Powder Technol. 2018, 29, 3107–3123. [Google Scholar] [CrossRef]
- Voorneveld, J.; Kruizinga, P.; Vos, H.J.; Gijsen, F.J.; Jebbink, E.G.; Van Der Steen, A.F.; De Jong, N.; Bosch, J.G. Native blood speckle vs ultrasound contrast agent for particle image velocimetry with ultrafast ultrasound-in vitro experiments. In Proceedings of the 2016 IEEE International Ultrasonics Symposium (IUS), Tours, France, 18–21 September 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Scarano, F.; Riethmuller, M.L. Iterative multigrid approach in PIV image processing with discrete window offset. Exp. Fluids 1999, 26, 513–523. [Google Scholar] [CrossRef]
- Meunier, P.; Leweke, T. Analysis and treatment of errors due to high velocity gradients in particle image velocimetry. Exp. Fluids 2003, 35, 408–421. [Google Scholar] [CrossRef]
- Dallas, C.; Wu, M.; Chou, V.; Liberzon, A.; Sullivan, P.E. Graphical Processing Unit-Accelerated Open-Source Particle Image Velocimetry Software for High Performance Computing Systems. J. Fluids Eng. 2019, 141, 111401. [Google Scholar] [CrossRef]
- Ben-Gida, H.; Gurka, R.; Liberzon, A. OpenPIV-MATLAB—An open-source software for particle image velocimetry; test case: Birds’ aerodynamics. SoftwareX 2020, 12, 100585. [Google Scholar] [CrossRef]
- Thielicke, W.; Sonntag, R. Particle Image Velocimetry for MATLAB: Accuracy and enhanced algorithms in PIVlab. J. Open Res. Softw. 2021, 9, 12. [Google Scholar] [CrossRef]
- PIVLab. Available online: https://www.mathworks.com/matlabcentral/fileexchange/27659-pivlab-particle-image-velocimetry-piv-tool-with-gui (accessed on 15 August 2023).
- OpenPIV. Available online: http://www.openpiv.net/ (accessed on 15 August 2023).
- Fluere. Available online: https://www.softpedia.com/get/Science-CAD/Fluere.shtml (accessed on 15 August 2023).
- Fluidimage. Available online: https://pypi.org/project/fluidimage/ (accessed on 15 August 2023).
- mpiv. Available online: https://www.mathworks.com/matlabcentral/fileexchange/2411-mpiv (accessed on 15 August 2023).
- JPIV. Available online: https://eguvep.github.io/jpiv/ (accessed on 15 August 2023).
- UVMAT. Available online: http://servforge.legi.grenoble-inp.fr/projects/soft-uvmat (accessed on 15 August 2023).
- Yang, E.; Ekmekci, A.; Sullivan, P.E. Phase evolution of flow controlled by synthetic jets over NACA 0025 airfoil. J. Vis. 2022, 25, 751–765. [Google Scholar] [CrossRef]
- Scarano, F. Iterative image deformation methods in PIV. Meas. Sci. Technol. 2001, 13, R1. [Google Scholar] [CrossRef]
- Garcia, D. Robust smoothing of gridded data in one and higher dimensions with missing values. Comput. Stat. Data Anal. 2010, 54, 1167–1178. [Google Scholar] [CrossRef] [PubMed]
- Gomersall, H. pyFFTW: Python Wrapper around FFTW. Astrophys. Source Code Libr. 2021, ascl:2109.009. Available online: http://xxx.lanl.gov/abs/2109.009 (accessed on 15 August 2023).
- Westerweel, J.; Scarano, F. Universal outlier detection for PIV data. Exp. Fluids 2005, 39, 1096–1100. [Google Scholar] [CrossRef]
- Perlman, E.; Burns, R.; Li, Y.; Meneveau, C. Data Exploration of Turbulence Simulations Using a Database Cluster. In Proceedings of the 2007 ACM/IEEE Conference on Supercomputing, SC’07, New York, NY, USA, 10–16 November 2007. [Google Scholar] [CrossRef]
- Saikrishnan, N.; Marusic, I.; Longmire, E.K. Assessment of dual plane PIV measurements in wall turbulence using DNS data. Exp. Fluids 2006, 41, 265–278. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Settings | Variable | Description | Value |
| Masking | mask | 2D array with non-zero values indicating the masked locations. | None |
| Data type | dtype_f 1 | Type of floating-point numbers. | “float32” |
| Geometry | frame_shape | Size of the images. | (512, 1608) |
| min_search_size | Interrogation window size for the final iteration. | 8 | |
| search_size_iters | Number of iterations for each window size. | (1, 1, 2) | |
| overlap_ratio | Ratio of overlap for each window size. | 0.5 | |
| shrink_ratio 2 | Ratio to shrink the search size for the first iteration. | 1 | |
| Correlation | deforming_order | Order of spline interpolation for window deformation. | 2 |
| normalize | Normalize the window intensity by subtracting the mean value. | True | |
| subpixel_method 3 | Method to estimate subpixel location of the correlation peak. | “gaussian” | |
| n_fft | Size factor for the 2D FFT. | (1, 1, 2) | |
| deforming_par 4 | Ratio of the predictor used to deform each frame. | 0.5 | |
| batch_size | Batch size for calculating the cross-correlation. | 1 | |
| Validation | s2n_method 5 | Method of signal-to-noise ratio measurement. | “peak2peak” |
| s2n_size | Half-size of a square around the first peak ignored for second peak. | 2 | |
| validation_size 6 | Size parameter for validation kernel. | 1 | |
| s2n_tol 7 | Tolerance for signal-to-noise ratio validation. | None | |
| median_tol 7 | Tolerance for median validation. | 2 | |
| mad_tol 7 | Tolerance for median-absolute-deviation validation. | None | |
| mean_tol 7 | Tolerance for mean validation. | None | |
| rms_tol 7 | Tolerance for root mean squared validation. | None | |
| Replacement | num_replacing_iters | Number of iterations per replacement cycle. | 2 |
| replacing_method 8 | Method to use for outlier replacement. | “spring” | |
| replacing_size 6 | Size parameter for replacement kernel. | 1 | |
| revalidate | Revalidate the fields in between replacement iterations. | True | |
| Smoothing | smooth 9 | Smooth the displacement fields. | True |
| smoothing_par 10 | Smoothing parameter to apply to the velocity fields. | None | |
| Scaling | dt 11 | Time delay separating the two images. | 1 |
| scaling_par 11 | Scaling factor to apply to the velocity fields. | 1 |
| Subroutine | Computational Time per Run 1 | Average | ||||
| Interrogation | 0.893 | 0.894 | 0.833 | 0.867 | 0.791 | 0.855 |
| Deformation 2 | 14.596 | 14.533 | 14.626 | 14.308 | 4.511 | 14.515 |
| Normalization | 1.902 | 1.865 | 1.783 | 1.852 | 1.820 | 1.845 |
| Cross-correlation | 65.573 | 65.769 | 65.797 | 66.103 | 65.560 | 65.760 |
| Peak estimation 3 | 1.203 | 1.282 | 1.190 | 1.222 | 1.263 | 1.232 |
| Validation | 3.066 | 3.185 | 3.209 | 3.153 | 3.124 | 3.148 |
| Replacement | 3.493 | 3.615 | 3.727 | 3.587 | 3.639 | 3.612 |
| Smoothing | 0.658 | 0.698 | 0.672 | 0.748 | 0.671 | 0.689 |
| Time per vector 4 | 50.611 | 50.557 | 49.586 | 49.859 | 49.704 | 50.063 |
| Method | Error | Mean | STD 1 | 95% CI 2 |
| Spring | u | |||
| v | ||||
| Mean | u | |||
| v | ||||
| Median | u | |||
| v | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shirinzad, A.; Jaber, K.; Xu, K.; Sullivan, P.E. An Enhanced Python-Based Open-Source Particle Image Velocimetry Software for Use with Central Processing Units. Fluids 2023, 8, 285. https://doi.org/10.3390/fluids8110285
Shirinzad A, Jaber K, Xu K, Sullivan PE. An Enhanced Python-Based Open-Source Particle Image Velocimetry Software for Use with Central Processing Units. Fluids. 2023; 8(11):285. https://doi.org/10.3390/fluids8110285
Chicago/Turabian StyleShirinzad, Ali, Khodr Jaber, Kecheng Xu, and Pierre E. Sullivan. 2023. "An Enhanced Python-Based Open-Source Particle Image Velocimetry Software for Use with Central Processing Units" Fluids 8, no. 11: 285. https://doi.org/10.3390/fluids8110285
APA StyleShirinzad, A., Jaber, K., Xu, K., & Sullivan, P. E. (2023). An Enhanced Python-Based Open-Source Particle Image Velocimetry Software for Use with Central Processing Units. Fluids, 8(11), 285. https://doi.org/10.3390/fluids8110285