


Pressure Drop Estimation of Two-Phase Adiabatic Flows in Smooth Tubes: Development of Machine Learning-Based Pipelines

 , and
, and
Abstract
1. Introduction
Research Gap and Contributions of the Present Work
2. Frictional Pressure Gradient in Two-Phase Flow
- Homogeneous flow model: The two-phase mixture is modeled as an equivalent single-phase fluid, using properties that are averaged to reflect the characteristics of both phases.
- Separated flow model: The two-phase mixture is presumed to consist of two independent single-phase streams flowing separately. The resulting pressure gradient is determined through an appropriate combination of the pressure gradients from each individual single-phase stream.
2.1. Homogeneous Models
2.2. Separated Flow Models
- —liquid alone: refers to the liquid moving independently, specifically at the liquid superficial velocity.
- —liquid only: refers to the liquid moving with the total flow rate, specifically at the mixture velocity.
- —gas alone: refers to the gas moving alone, specifically at the gas superficial velocity.
- —gas only: refers to the gas flowing with the total flow rate, specifically at the mixture velocity.
3. Experimental Procedures and Utilized Dataset
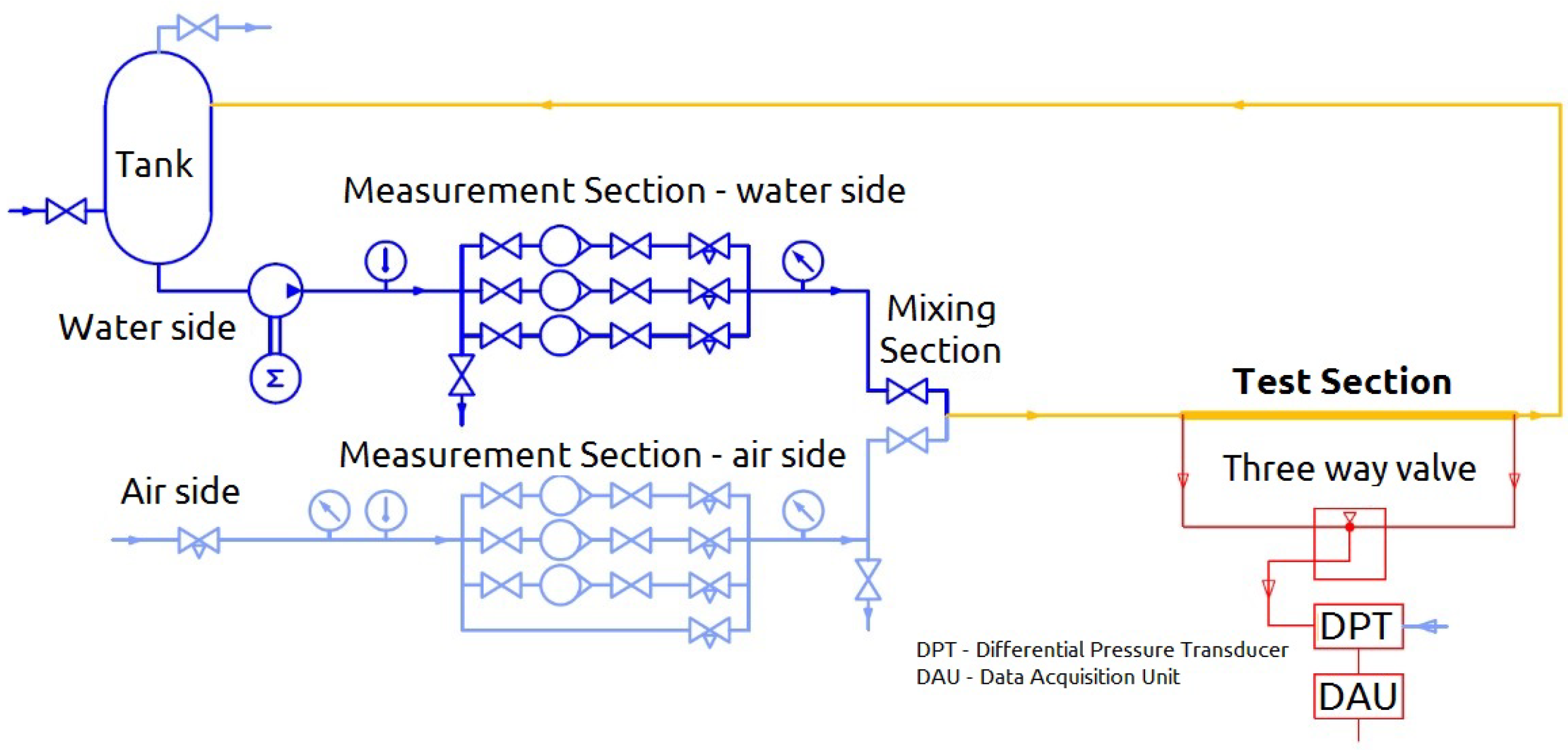
3.1. Overview of the Laboratory Setup
3.2. Data Processing
4. Machine Learning
4.1. Overall Framework
4.2. Machine Learning Algorithms
4.3. Optimisation of Machine Learning Pipelines
4.3.1. Optimization Settings
- Generations (generations = 100): number of iterations for the genetic algorithm.
- Population Size (population size = 100): number of candidate pipelines in each generation.
- Scoring Function (MAPE): Mean Absolute Percentage Error used to evaluate pipeline performance.
- Cross-Validation (cv = 10): 10-fold cross-validation to assess pipeline generalizability.
4.3.2. Pool of Hyperparameters
5. Methodology and Implemented Pipelines
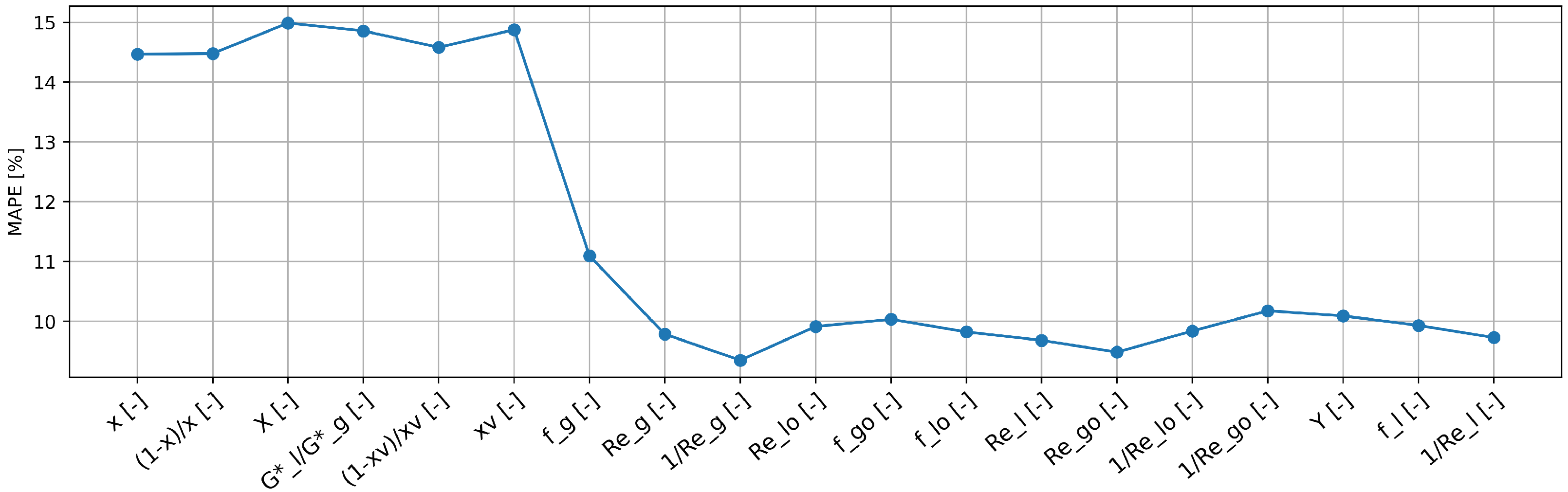
5.1. Feature Selection Procedure
5.2. Feature Selection Based on Random Forest-Derived Feature Importance
6. Results and Discussions
6.1. Accuracy of Existing Standard Physical Models
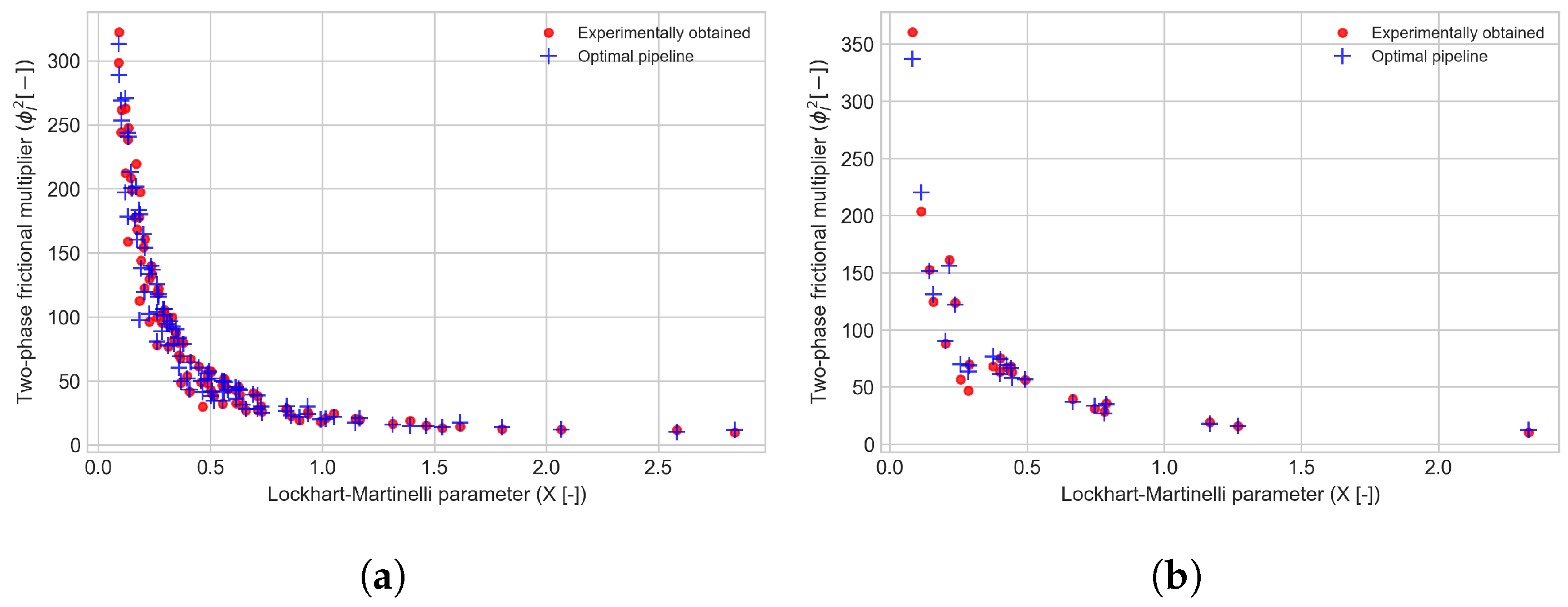
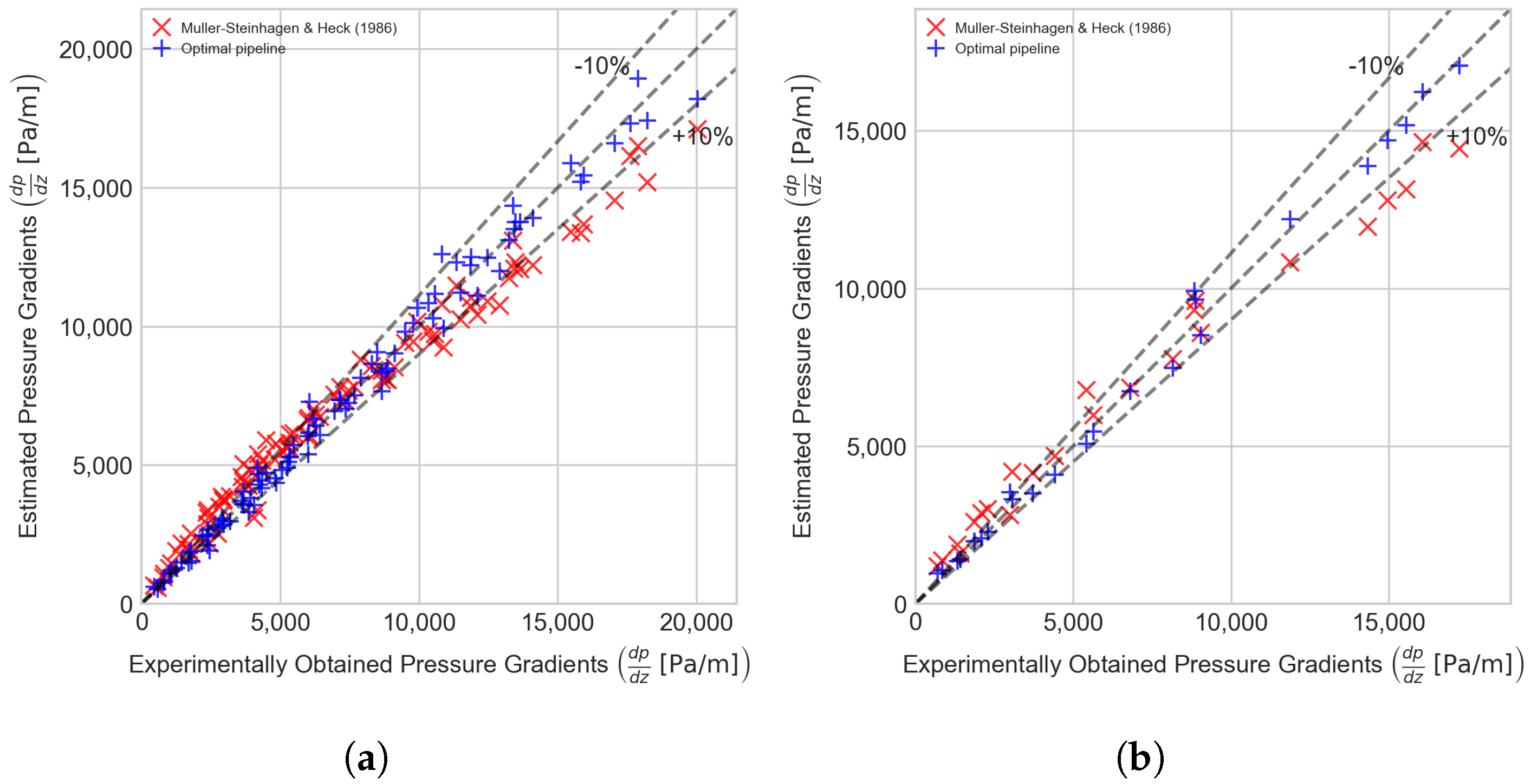
6.2. Implemented Hybrid Data-Driven/Physical-Based Models
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Pressure drop [Pa] | |
| Pressure gradient | |
| Normal litter per hour | |
| Artificial intelligence | |
| Artificial Neural Network | |
| Cross-Validation | |
| Pipe internal diameter [m] | |
| f | Friction factor (by Fanning) [-] |
| Froude number [-] | |
| G | Mass flux |
| Apparent mass flux | |
| J | Superficial velocity |
| Laplace constant [-] | |
| Mean Absolute Percentage Error [%] | |
| Machine learning | |
| Mean Percentage Error [%] | |
| p | Pressure [Pa] |
| Q | Volume flow rate |
| Reynolds number [-] | |
| Random Forest algorithm | |
| S | Internal wetted perimeter [m] |
| Support Vector Machines | |
| U | Phase velocity |
| Weber number [-] | |
| X | Lockhart–Martinelli parameter [-] |
| x | Average mass quality [-] |
| Average volume quality [-] | |
| Y | Chisholm parameter [-] |
| Greek symbols | |
| Void fraction [-] | |
| Mass flow rate , non-dimensional parameter (Equation (13)) | |
| Dynamic viscosity | |
| Cross-section | |
| Two-phase flow friction multiplier [-] | |
| Density | |
| Surface tension | |
| Shear stress [Pa] | |
| Subscripts | |
| a | Accelerative |
| Average | |
| b | Bulk |
| Experimental value | |
| f | Frictional |
| Gas only | |
| l | Liquid |
| Liquid only | |
| m | Micro-finned |
| Manufacturer’s specifications | |
| Predicted value | |
| s | Smooth |
| Two-phase | |
| Turbulent liquid, turbulent gas flow | |
| Turbulent liquid, laminar gas flow | |
| Laminar liquid, turbulent gas flow | |
| Laminar liquid, Laminar gas flow |
Appendix A. Optimal Pipeline

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optimal Benchmark Algorithm | Arguments | Definitions | Values |
|---|---|---|---|
| RandomForestRegressor | bootstrap | Whether bootstrap samples are used when building trees | False |
| max-features | The number of features to consider when looking for the best split | 0.2 | |
| min-samples-leaf | The minimum number of samples required to be at a leaf n | 1 | |
| min-samples-split | The minimum number of samples required to split an internal node | 2 | |
| n-estimators | The number of trees in the forest | 100 |
| Optimal Pipeline Steps | Arguments | Definitions | Values |
|---|---|---|---|
| Step 1: PCA 1 | iterated-power | The number of iterations used by the randomized SVD solver to improve accuracy | 3 |
| svd-solver | Selects the algorithm for computing SVD, balancing speed and accuracy | randomized | |
| Step 2: StackingEstimator: estimator = ExtraTreesRegressor | bootstrap | Whether bootstrap samples are used when building trees | False |
| max-features | The number of features to consider when looking for the best split | 0.95 | |
| min-samples-leaf | The minimum number of samples required to be at a leaf n | 15 | |
| min-samples-split | The minimum number of samples required to split an internal node | 8 | |
| n-estimators | The number of trees in the forest | 100 | |
| Step 3: StandardScaler 2 | - | - | - |
| Step 4: PolynomialFeatures 3 | degree | The degree of the polynomial features | 2 |
| include-bias | bias column is considered | False | |
| interaction-only | interaction features are produced | False | |
| Step 5: RidgeCV | - | - | - |
References
- Szilas, A.P. Production and Transport of Oil and Gas; Elsevier: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Ebrahimi, A.; Khamehchi, E. A robust model for computing pressure drop in vertical multiphase flow. J. Nat. Gas Sci. Eng. 2015, 26, 1306–1316. [Google Scholar] [CrossRef]
- Osman, E.S.A.; Aggour, M.A. Artificial neural network model for accurate prediction of pressure drop in horizontal and near-horizontal-multiphase flow. Pet. Sci. Technol. 2002, 20, 1–15. [Google Scholar] [CrossRef]
- Taccani, R.; Maggiore, G.; Micheli, D. Development of a process simulation model for the analysis of the loading and unloading system of a CNG carrier equipped with novel lightweight pressure cylinders. Appl. Sci. 2020, 10, 7555. [Google Scholar] [CrossRef]
- Xu, Y.; Fang, X. A new correlation of two-phase frictional pressure drop for evaporating flow in pipes. Int. J. Refrig. 2012, 35, 2039–2050. [Google Scholar] [CrossRef]
- Xu, Y.; Fang, X.; Su, X.; Zhou, Z.; Chen, W. Evaluation of frictional pressure drop correlations for two-phase flow in pipes. Nucl. Eng. Des. 2012, 253, 86–97. [Google Scholar] [CrossRef]
- Lockhart, R.; Martinelli, R. Proposed correlation of data for isothermal two-phase, two-component flow in pipes. Chem. Eng. Prog. 1949, 45, 39–48. [Google Scholar]
- Chisholm, D. A theoretical basis for the Lockhart-Martinelli correlation for two-phase flow. Int. J. Heat Mass Transf. 1967, 10, 1767–1778. [Google Scholar] [CrossRef]
- Mishima, K.; Hibiki, T. Some characteristics of air-water two-phase flow in small diameter vertical tubes. Int. J. Multiph. Flow 1996, 22, 703–712. [Google Scholar] [CrossRef]
- Zhang, W.; Hibiki, T.; Mishima, K. Correlations of two-phase frictional pressure drop and void fraction in mini-channel. Int. J. Heat Mass Transf. 2010, 53, 453–465. [Google Scholar] [CrossRef]
- Sun, L.; Mishima, K. Evaluation analysis of prediction methods for two-phase flow pressure drop in mini-channels. In Proceedings of the International Conference on Nuclear Engineering, Orlando, FL, USA, 11–15 May 2008; Volume 48159, pp. 649–658. [Google Scholar]
- Colombo, M.; Colombo, L.P.; Cammi, A.; Ricotti, M.E. A scheme of correlation for frictional pressure drop in steam–water two-phase flow in helicoidal tubes. Chem. Eng. Sci. 2015, 123, 460–473. [Google Scholar] [CrossRef]
- De Amicis, J.; Cammi, A.; Colombo, L.P.; Colombo, M.; Ricotti, M.E. Experimental and numerical study of the laminar flow in helically coiled pipes. Prog. Nucl. Energy 2014, 76, 206–215. [Google Scholar] [CrossRef]
- Chisholm, D. Pressure gradients due to friction during the flow of evaporating two-phase mixtures in smooth tubes and channels. Int. J. Heat Mass Transf. 1973, 16, 347–358. [Google Scholar] [CrossRef]
- Baroczy, C. Systematic Correlation for Two-Phase Pressure Drop. Chem. Eng. Progr. Symp. Ser. 1966, 62, 232–249. [Google Scholar]
- Müller-Steinhagen, H.; Heck, K. A simple friction pressure drop correlation for two-phase flow in pipes. Chem. Eng. Process. Process. Intensif. 1986, 20, 297–308. [Google Scholar] [CrossRef]
- Lobo de Souza, A.; de Mattos Pimenta, M. Prediction of pressure drop during horizontal two-phase flow of pure and mixed refrigerants. ASME-Publ.-FED 1995, 210, 161–172. [Google Scholar]
- Friedel, L. Improved friction pressure drop correlation for horizontal and vertical two-phase pipe flow. In Proceedings of the European Two-Phase Group Meeting, Ispra, Italy, 5–8 June 1979. [Google Scholar]
- Cavallini, A.; Censi, G.; Del Col, D.; Doretti, L.; Longo, G.A.; Rossetto, L. Condensation of halogenated refrigerants inside smooth tubes. Hvac&R Res. 2002, 8, 429–451. [Google Scholar]
- Tran, T.; Chyu, M.C.; Wambsganss, M.; France, D. Two-phase pressure drop of refrigerants during flow boiling in small channels: An experimental investigation and correlation development. Int. J. Multiph. Flow 2000, 26, 1739–1754. [Google Scholar] [CrossRef]
- Najafi, B.; Ardam, K.; Hanušovský, A.; Rinaldi, F.; Colombo, L.P.M. Machine learning based models for pressure drop estimation of two-phase adiabatic air-water flow in micro-finned tubes: Determination of the most promising dimensionless feature set. Chem. Eng. Res. Des. 2021, 167, 252–267. [Google Scholar] [CrossRef]
- Ardam, K.; Najafi, B.; Lucchini, A.; Rinaldi, F.; Colombo, L.P.M. Machine learning based pressure drop estimation of evaporating R134a flow in micro-fin tubes: Investigation of the optimal dimensionless feature set. Int. J. Refrig. 2021, 131, 20–32. [Google Scholar] [CrossRef]
- Bar, N.; Bandyopadhyay, T.K.; Biswas, M.N.; Das, S.K. Prediction of pressure drop using artificial neural network for non-Newtonian liquid flow through piping components. J. Pet. Sci. Eng. 2010, 71, 187–194. [Google Scholar] [CrossRef]
- Tian, Z.; Gu, B.; Yang, L.; Liu, F. Performance prediction for a parallel flow condenser based on artificial neural network. Appl. Therm. Eng. 2014, 63, 459–467. [Google Scholar] [CrossRef]
- Garcia, J.J.; Garcia, F.; Bermúdez, J.; Machado, L. Prediction of pressure drop during evaporation of R407C in horizontal tubes using artificial neural networks. Int. J. Refrig. 2018, 85, 292–302. [Google Scholar] [CrossRef]
- López-Belchí, A.; Illan-Gomez, F.; Cano-Izquierdo, J.M.; García-Cascales, J.R. GMDH ANN to optimise model development: Prediction of the pressure drop and the heat transfer coefficient during condensation within mini-channels. Appl. Therm. Eng. 2018, 144, 321–330. [Google Scholar] [CrossRef]
- Khosravi, A.; Pabon, J.; Koury, R.; Machado, L. Using machine learning algorithms to predict the pressure drop during evaporation of R407C. Appl. Therm. Eng. 2018, 133, 361–370. [Google Scholar] [CrossRef]
- Zendehboudi, A.; Li, X. A robust predictive technique for the pressure drop during condensation in inclined smooth tubes. Int. Commun. Heat Mass Transf. 2017, 86, 166–173. [Google Scholar] [CrossRef]
- Shadloo, M.S.; Rahmat, A.; Karimipour, A.; Wongwises, S. Estimation of Pressure Drop of Two-Phase Flow in Horizontal Long Pipes Using Artificial Neural Networks. J. Energy Resour. Technol. 2020, 142, 112110. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, L.; Wang, T.; Wang, X.; Hu, Y.; Duan, Q. Application of soft computing techniques to multiphase flow measurement: A review. Flow Meas. Instrum. 2018, 60, 30–43. [Google Scholar] [CrossRef]
- Shaban, H.; Tavoularis, S. Measurement of gas and liquid flow rates in two-phase pipe flows by the application of machine learning techniques to differential pressure signals. Int. J. Multiph. Flow 2014, 67, 106–117. [Google Scholar] [CrossRef]
- Nie, F.; Yan, S.; Wang, H.; Zhao, C.; Zhao, Y.; Gong, M. A universal correlation for predicting two-phase frictional pressure drop in horizontal tubes based on machine learning. Int. J. Multiph. Flow 2023, 160, 104377. [Google Scholar] [CrossRef]
- Faraji, F.; Santim, C.; Chong, P.L.; Hamad, F. Two-phase flow pressure drop modelling in horizontal pipes with different diameters. Nucl. Eng. Des. 2022, 395, 111863. [Google Scholar] [CrossRef]
- Moradkhani, M.; Hosseini, S.; Song, M.; Abbaszadeh, A. Reliable smart models for estimating frictional pressure drop in two-phase condensation through smooth channels of varying sizes. Sci. Rep. 2024, 14, 10515. [Google Scholar] [CrossRef] [PubMed]
- Moradkhani, M.; Hosseini, S.H.; Mansouri, M.; Ahmadi, G.; Song, M. Robust and universal predictive models for frictional pressure drop during two-phase flow in smooth helically coiled tube heat exchangers. Sci. Rep. 2021, 11, 20068. [Google Scholar] [CrossRef] [PubMed]
- McAdams, W. Vaporization inside horizontal tubes-II, Benzene oil mixtures. Trans. ASME 1942, 64, 193–200. [Google Scholar] [CrossRef]
- Beattie, D.; Whalley, P. A simple two-phase frictional pressure drop calculation method. Int. J. Multiph. Flow 1982, 8, 83–87. [Google Scholar] [CrossRef]
- Awad, M.; Muzychka, Y. Effective property models for homogeneous two-phase flows. Exp. Therm. Fluid Sci. 2008, 33, 106–113. [Google Scholar] [CrossRef]
- Vega-Penichet Domecq, P. Pressure Drop Measurement for Adiabatic Single and Two Phase Flows inside Horizontal Micro-Fin Tubes. Available online: https://oa.upm.es/52749/ (accessed on 12 June 2024).
- Mandhane, J.; Gregory, G.; Aziz, K. A flow pattern map for gas–liquid flow in horizontal pipes. Int. J. Multiph. Flow 1974, 1, 537–553. [Google Scholar] [CrossRef]
- Breirnan, L. Arcing classifiers. Ann. Stat. 1998, 26, 801–849. [Google Scholar]
- Olson, R.S.; Bartley, N.; Urbanowicz, R.J.; Moore, J.H. Evaluation of a tree-based pipeline optimization tool for automating data science. In Proceedings of the Genetic and Evolutionary Computation Conference 2016, Denver, CO, USA, 20–24 July 2016; pp. 485–492. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pearson, K. VII. Note on regression and inheritance in the case of two parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and robust automated machine learning. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/hash/11d0e6287202fced83f79975ec59a3a6-Abstract.html (accessed on 12 June 2024).
- Brunton, S.L.; Proctor, J.L.; Kutz, J.N. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc. Natl. Acad. Sci. USA 2016, 113, 3932–3937. [Google Scholar] [CrossRef] [PubMed]
- Loiseau, J.C.; Brunton, S.L. Constrained sparse Galerkin regression. J. Fluid Mech. 2018, 838, 42–67. [Google Scholar] [CrossRef]

| Author(s) and the Respective Reference(s) | Equation | Eq. No |
|---|---|---|
| McAdams et al. [36] | (3) | |
| Beattie and Whalley [37] | (4) | |
| Awad and Muzychka [38] | (5) |
| Author(s) and the Respective Reference(s) | Equation | Eq. No |
|---|---|---|
| Chisholm [8] | for for for for | (7) |
| Mishima and Hibiki [9] | (8) | |
| Zhang et al. [10] | For gas and liquid For vapor and liquid | (9) |
| Sun and Mishima [11] | For viscous flow: For turbulent flow: where | (10) |
| Chisholm [14] | if if if | (11) |
| Muller-Steinhagen and Heck [16] | (12) | |
| Souza and Pimenta [17] | (13) | |
| Friedel [18] | (14) | |
| Cavallini et al. [19] | (15) | |
| Tran et al. [20] | (16) |
| Parameters | Units | Values |
|---|---|---|
| Utility | - | E-C-A |
| External diameter of the tube | [mm] | 9.52 |
| Thickness of the tube | [mm] | 0.3 |
| Internal diameter of the tube | [mm] | 8.92 |
| Length of the test section | [m] | 1.295 |
| Wet perimeter | [mm] | 28.02 |
| Cross-section area | [mm2] | 62.49 |
| Number of two-phase data points | - | 119 |
| Mass fluxes range of the air | 5.30–47.42 | |
| Mass fluxes range of the water | 44.29–442.91 | |
| Mass quality range | 0.01–0.52 | |
| Pressure gradient range | 450.05–20,047.16 |
| Device | Range | Uncertainty |
|---|---|---|
| Manometer | 0–6 bar (gauge) | 0.2 bar |
| Thermometer | 5–120 [°C] | 1 [°C] |
| Differential Pressure Transducer | 0–70 kPa | 1.5% full scale |
| Air Flow Meter | 4–190 | 3% of the observed value |
| Air Flow Meter | 85–850 | 3% of the observed value |
| Air Flow Meter | 400–4000 | 3% of the observed value |
| Water Flow Meter | 10–100 | 3% of the observed value |
| Water Flow Meter | 40–400 | 3% of the observed value |
| Model | Hyperparameters |
|---|---|
| ElasticNetCV |
|
| ExtraTreesRegressor |
|
| GradientBoostingRegressor |
|
| AdaBoostRegressor |
|
| DecisionTreeRegressor |
|
| KNeighborsRegressor |
|
| LassoLarsCV |
|
| LinearSVR |
|
| RandomForestRegressor |
|
| XGBRegressor |
|
| SGDRegressor |
|
| RidgeCV | |
| Preprocessors | |
| Model | Hyperparameters |
| Binarizer |
|
| FastICA |
|
| FeatureAgglomeration |
|
| MaxAbsScaler | |
| MinMaxScaler | |
| Normalizer |
|
| Nystroem |
|
| PCA |
|
| PolynomialFeatures |
|
| RBFSampler |
|
| RobustScaler | |
| StandardScaler | |
| ZeroCount | |
| OneHotEncoder |
|
| Author(s) and the Respective Reference(s) | MPE [%] | MAPE [%] |
|---|---|---|
| McAdams et al. [36] | −10.05 | 18.56 |
| Bettiel and Whalley [37] | −28.27 | 28.38 |
| Awad and Muzychka [38] | 6.67 | 17.58 |
| Chisholm [8] | −13.25 | 16.69 |
| Mishima and Hibiki [9] | −4.37 | 17.13 |
| Zhang et al. [10] | −8.75 | 18.29 |
| Sun and Mishima [11] | −35.94 | 36.52 |
| Chisholm [14] | 65.91 | 66.18 |
| Muller-Steinhagen and Heck [16] | 7.80 | 15.79 |
| Souza and Pimenta [17] | 32.93 | 54.93 |
| Friedel [18] | 23.97 | 36.04 |
| Cavallini et al. [19] | −89.03 | 89.03 |
| Tran et al. [20] | −65.45 | 65.45 |
| Pipeline | Two-Phase Flow Multiplier () | Pipeline | Validation (CV) | Test | ||
|---|---|---|---|---|---|---|
| MPE [%] | MAPE [%] | MPE [%] | MAPE [%] | |||
| A | l | All Features—Random Forest | 3.97 | 9.89 | 9.97 | 18.01 |
| B | Selected Features—Random Forest | 1.95 | 9.16 | 7.99 | 15.04 | |
| C | Selected Features—Optimal Pipeline | 0.40 | 5.99 | 2.86 | 7.03 | |
| D | lo | All Features—Random Forest | 4.01 | 11.76 | 11.71 | 17.28 |
| E | Selected Features—Random Forest | 5.25 | 10.41 | 8.44 | 11.80 | |
| F | Selected Features—Optimal Pipeline | −0.31 | 7.29 | 3.29 | 9.33 | |
| G | g | All Features—Random Forest | 2.07 | 8.34 | 5.43 | 9.97 |
| H | Selected Features—Random Forest | 0.20 | 7.49 | 4.90 | 9.83 | |
| I | Selected Features—Optimal Pipeline | 0.45 | 6.05 | 4.21 | 8.68 | |
| J | go | All Features—Random Forest | 2.45 | 9.42 | 3.08 | 10.09 |
| K | Selected Features—Random Forest | 0.81 | 8.16 | −0.20 | 6.56 | |
| L | Selected Features—Optimal Pipeline | 0.66 | 6.09 | 2.63 | 7.79 | |
| Features | ||||
|---|---|---|---|---|
| x [-] | 0.96 | 0.85 | 0.60 | 0.96 |
| [-] | 0.73 | 0.74 | 0.53 | 0.78 |
| X [-] | 0.64 | 0.69 | 0.98 | 0.70 |
| [-] | 0.63 | 0.67 | 0.62 | 0.68 |
| [-] | 0.62 | 0.46 | 0.47 | 0.63 |
| [-] | 0.61 | 0.66 | 0.98 | 0.68 |
| [-] | 0.60 | 0.65 | 0.99 | 0.66 |
| [-] | 0.60 | 0.60 | 0.64 | 0.60 |
| [-] | 0.59 | 0.64 | 0.98 | 0.65 |
| [-] | 0.59 | 0.64 | 0.98 | 0.65 |
| [-] | 0.57 | 0.40 | 0.42 | 0.60 |
| [-] | 0.56 | 0.61 | 0.63 | 0.61 |
| [-] | 0.52 | 0.52 | 0.59 | 0.51 |
| [-] | 0.52 | 0.52 | 0.59 | 0.51 |
| [-] | 0.49 | 0.42 | 0.53 | 0.50 |
| [-] | 0.42 | 0.32 | 0.45 | 0.45 |
| [-] | 0.42 | 0.32 | 0.45 | 0.45 |
| [-] | 0.23 | 0.02 | 0.24 | 0.27 |
| Y [-] | 0.09 | 0.18 | 0.02 | 0.15 |
| Targets | Selected Features | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| x | X | |||||||||
| Y | ||||||||||
| x | ||||||||||
| x | ||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolourchifard, F.; Ardam, K.; Dadras Javan, F.; Najafi, B.; Vega Penichet Domecq, P.; Rinaldi, F.; Colombo, L.P.M. Pressure Drop Estimation of Two-Phase Adiabatic Flows in Smooth Tubes: Development of Machine Learning-Based Pipelines. Fluids 2024, 9, 181. https://doi.org/10.3390/fluids9080181
Bolourchifard F, Ardam K, Dadras Javan F, Najafi B, Vega Penichet Domecq P, Rinaldi F, Colombo LPM. Pressure Drop Estimation of Two-Phase Adiabatic Flows in Smooth Tubes: Development of Machine Learning-Based Pipelines. Fluids. 2024; 9(8):181. https://doi.org/10.3390/fluids9080181
Chicago/Turabian StyleBolourchifard, Farshad, Keivan Ardam, Farzad Dadras Javan, Behzad Najafi, Paloma Vega Penichet Domecq, Fabio Rinaldi, and Luigi Pietro Maria Colombo. 2024. "Pressure Drop Estimation of Two-Phase Adiabatic Flows in Smooth Tubes: Development of Machine Learning-Based Pipelines" Fluids 9, no. 8: 181. https://doi.org/10.3390/fluids9080181
APA StyleBolourchifard, F., Ardam, K., Dadras Javan, F., Najafi, B., Vega Penichet Domecq, P., Rinaldi, F., & Colombo, L. P. M. (2024). Pressure Drop Estimation of Two-Phase Adiabatic Flows in Smooth Tubes: Development of Machine Learning-Based Pipelines. Fluids, 9(8), 181. https://doi.org/10.3390/fluids9080181