Discriminative Multi-Stream Postfilters Based on Deep Learning for Enhancing Statistical Parametric Speech Synthesis


Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution
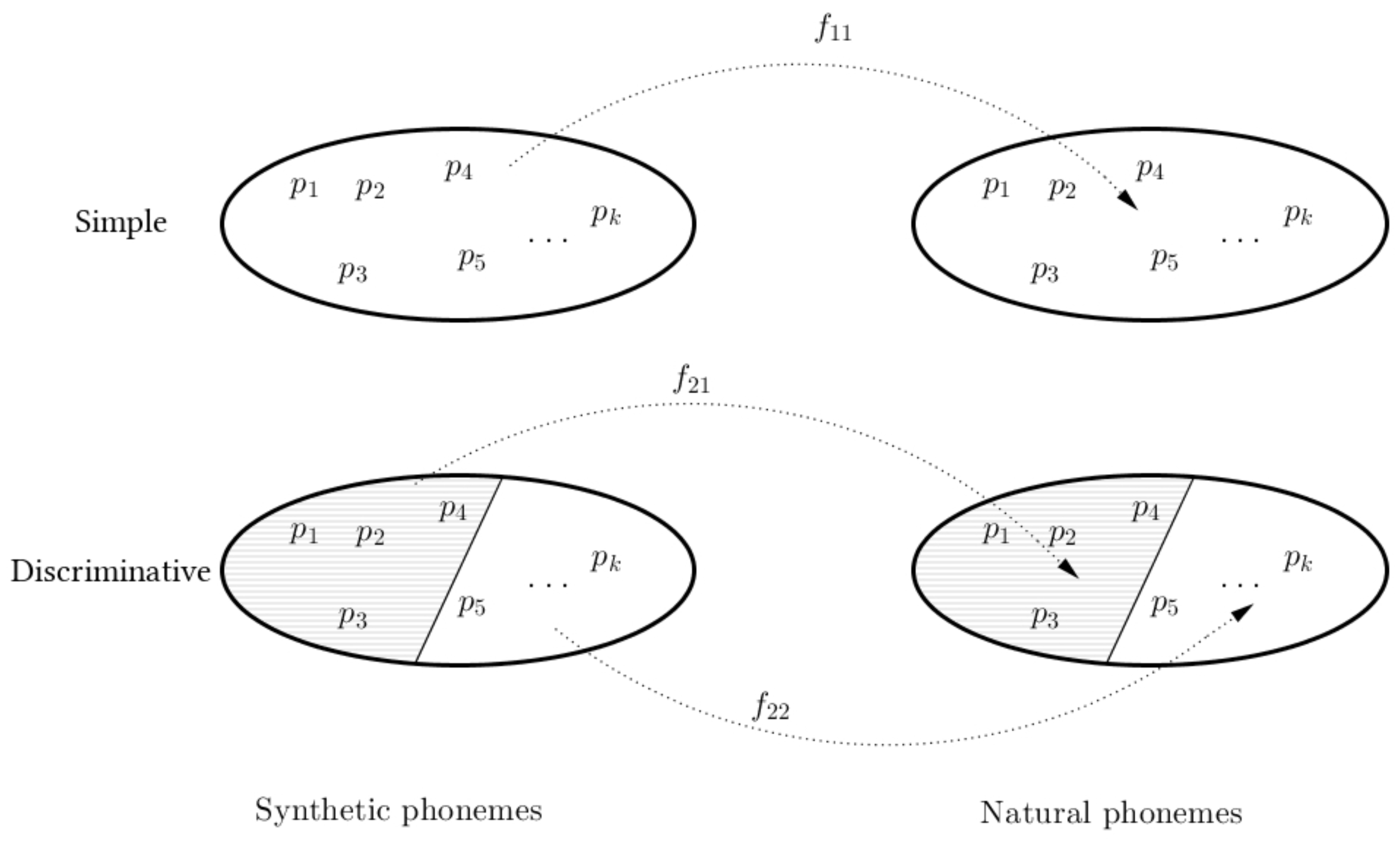
2. Problem Statement
3. Long Short-Term Memory Neural Networks
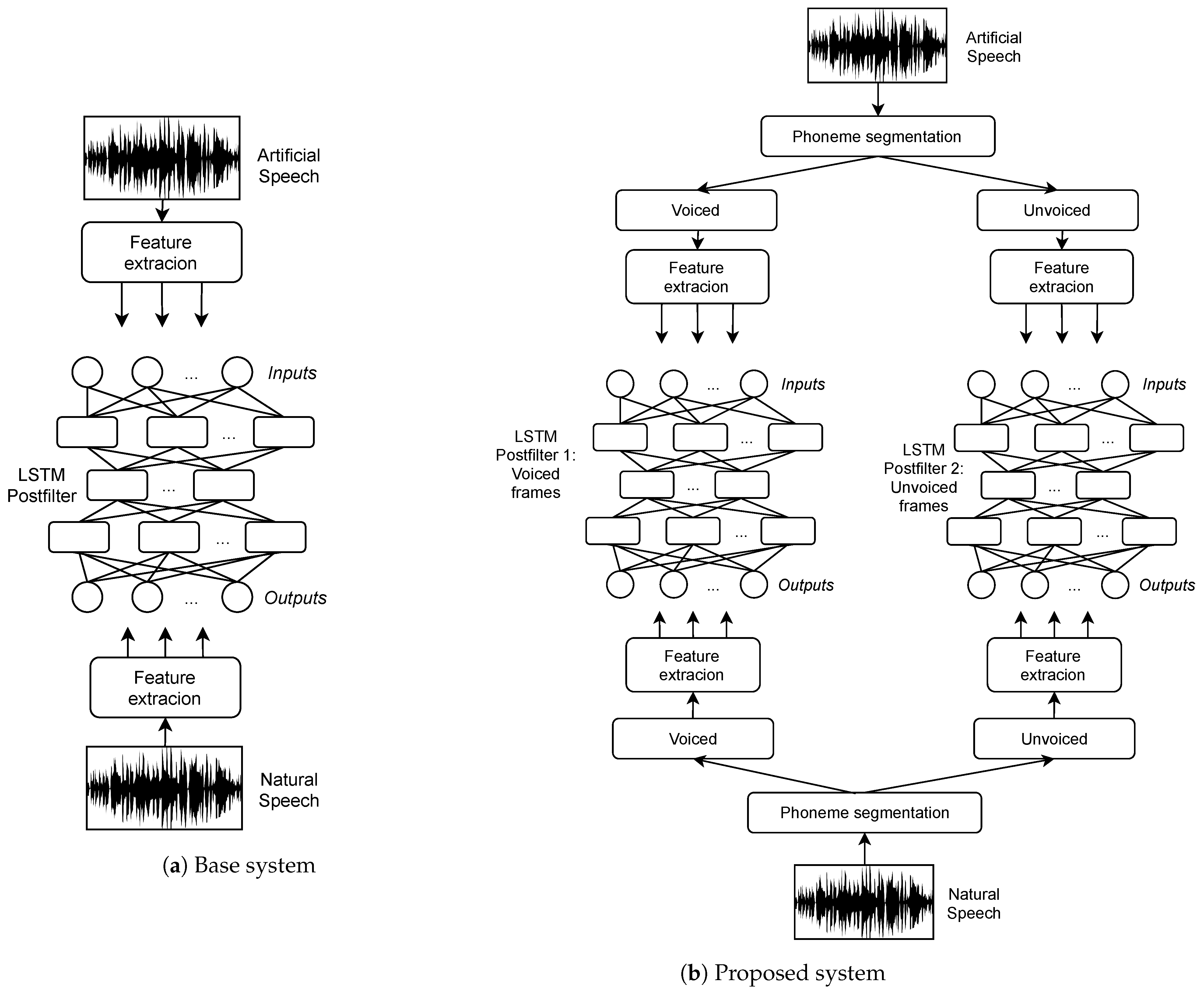
4. Proposed System
- In the first type of postfilter proposed (LSTM-1), a LSTM neural network with the same number of units at the input and at the output (autoencoder) is trained, with the inputs corresponding to the MFCC parameters of each frame of the HMM-based voice, and the outputs correspond to the MFCC parameters of the natural voice for the same aligned sentence.
- In the second type of postfilter, LSTM-2, the MFCC are enhanced in the same way as the previous case LSTM-1, but a new LSTM is trained to map the energy parameter from the HMM-based voice, to the energy parameter of the corresponding natural voice, also using natural MFCC features at the input and the output during training, in a particular form of auto-associative network.
- In the third type of postfilter, LSTM-3, the difference with LSTM-2 is an additional auto-associative LSTM network trained on the parameter.
5. Experimental Setup
5.1. Corpus Description
5.2. Experiments
- HTS: The HMM-based voice without postfiltering.
- Base-Type 1: Postfiltering of MFCCs of the HTS voice with one denoising autoencoder of LSTM network, while the and energy parameters remain the same of the HTS.
- Base Type 2: The same of Base-Type 1, with an additional auto-associative LSTM network for separately enhance the energy parameter. The parameter remain the same of HTS.
- Base Type 3: The same of Base-Type 2, with an additional auto-associative LSTM network for separately enhance the parameter.
- Discriminative-Type 1: Postfiltering of MFCCs of the HTS voice with two denoising autoencoder LSTM networks, discriminating one for voiced and one for unvoiced MFCCs. The and energy parameters remain the same of the HTS.
- Discriminative-Type 2: The same of Discriminative-Type 1, with two additional auto-associative LSTM networks: one for enhancing the energy of voiced sounds and one for the energy of the unvoiced segments of speech.
- Discriminative-Type 3: The same of Discriminative-Type 2, with one additional auto-associative LSTM network for enhancing the of the voiced sounds. The unvoiced segments of speech remain with and don’t need to be changed.
5.3. Evaluation
- Segmental SNR (SegSNR): Is a measure of the relation of the energy of the speech and the noise, commonly used to measure speech quality. Is implemented following the equation:where is the original and the ith processed speech samples, N is the total number of samples and L is the frame length.
- PESQ: PESQ is a measure based on a predictive model of the subjective quality of speech. This measure is defined in ITU-T recommendation P.862.ITU. Results are reported in the interval , where 4.5 is the perfect quality of the speech, according to the reference sound (the natural recording).PESQ is computed with the equation:where are adjusted to optimize the measure according to the signal distortion and overall quality.
- Weighted-slope spectral distance (WSS): This is a measure calculated in the frequency domain, comparing the slopes presented in the spectrum, calculated using the equation:where and are the slopes for the jth in the frame i. K is the total number of spectral bands. The weights are established according to the magnitude of the peaks in the spectrum.
6. Results
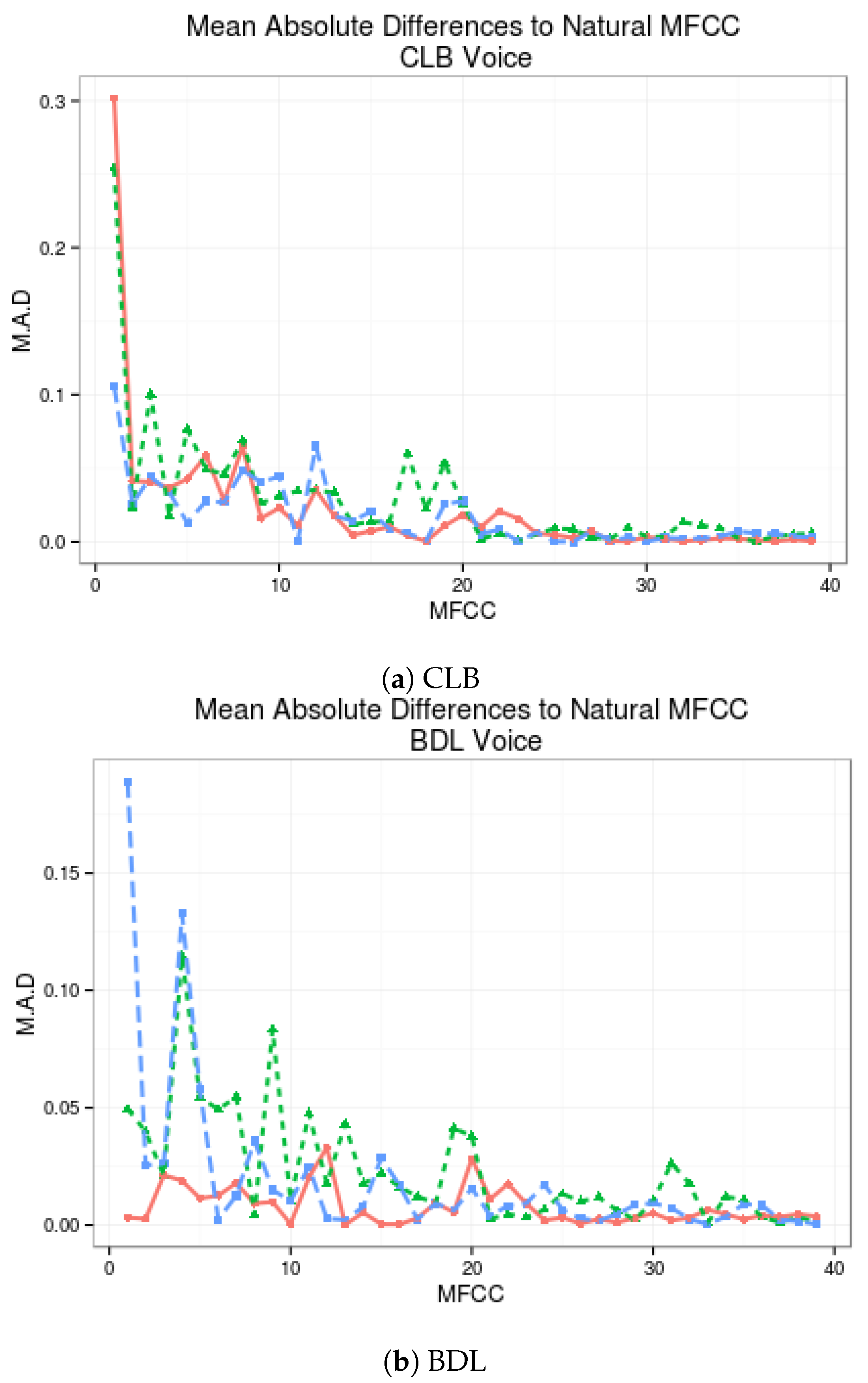
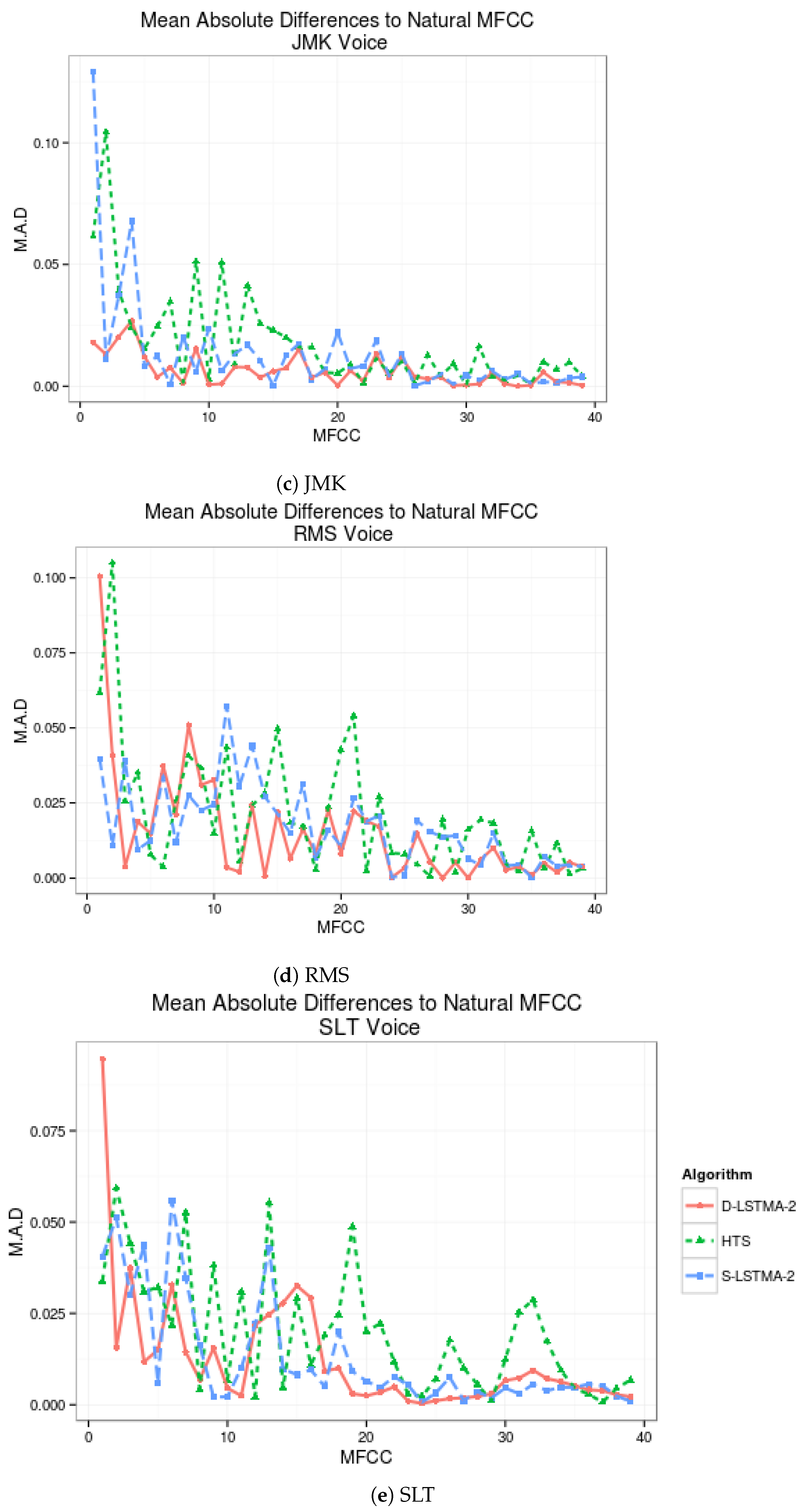
6.1. Objective Measures
6.2. Statistically Significant Enhancement of the Noisy Speech Signal
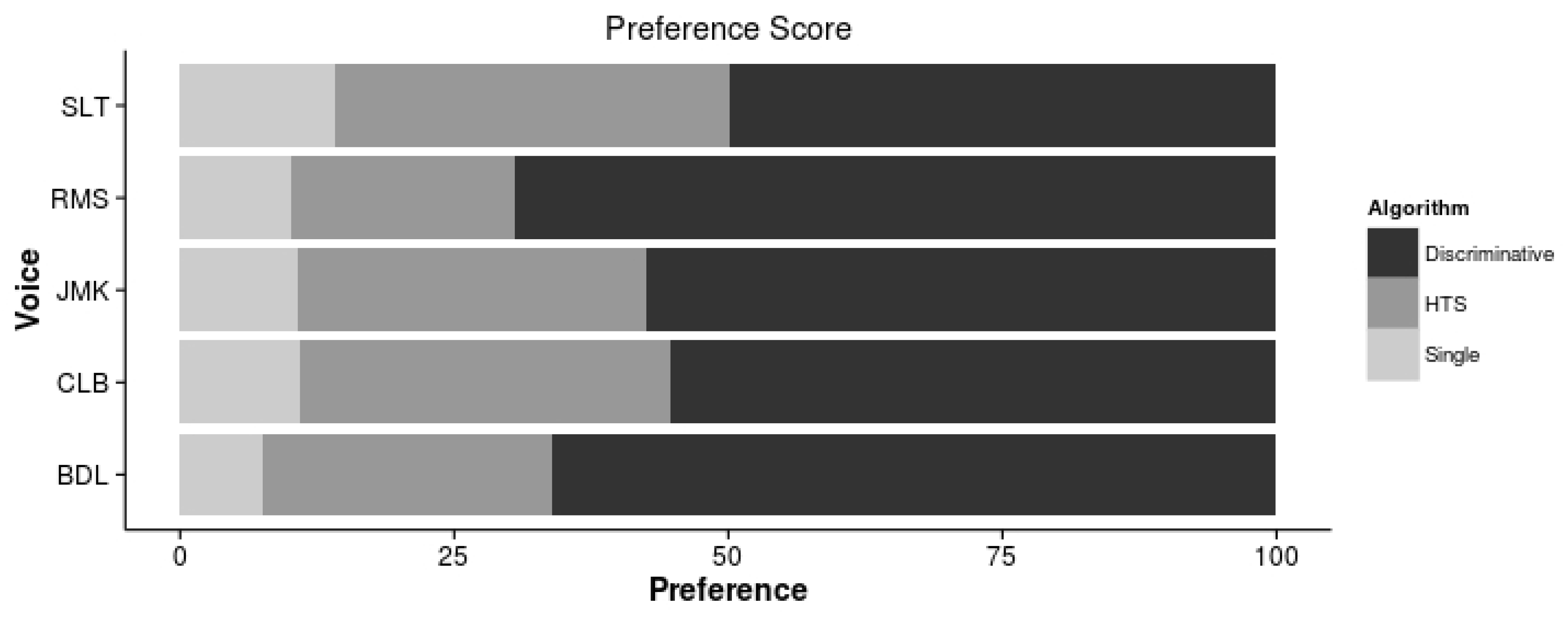
6.3. Subjective Results
7. Conclusions
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BAM | Bidirectional Associative Memory |
| CMU | Carnegie Mellon University |
| DBN | Deep Belief Network |
| DNN | Deep Neural Network |
| Fundamental frequency | |
| GPU | Graphics Processing Unit |
| HMM | Hidden Markov Models |
| HTS | H-Triple-S: HMM-based Speech Synthesis System |
| LSTM | Long Short-term Memory |
| MFCC | Mel-Frequency Cepstral Coefficients |
| PESQ | Perceptual Evaluation of Speech Quality |
| RBM | Restricted Boltzmann Machine |
| RNN | Recurrent Neural Network |
| SegSNR | Segmental Signal-to-noise Ratio |
| SNR | Signa-to-noise Ratio |
| WSS | Weighted-slope Spectral Distance |
References
- Black, A.W.; Zen, H.; Tokuda, K. Statistical Parametric Speech Synthesis. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP ’07, Honolulu, HI, USA, 15–20 April 2007; pp. IV-1229–IV-1232. [Google Scholar] [CrossRef] [Green Version]
- Zen, H.; Tokuda, K.; Black, A.W. Statistical parametric speech synthesis. Speech Commun. 2009, 51, 1039–1064. [Google Scholar] [CrossRef]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Li, B.; Zen, H. Multi-language multi-speaker acoustic modeling for LSTM-RNN based statistical parametric speech synthesis. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, San Francisco, CA, USA, 2016; pp. 2468–2472. [Google Scholar] [CrossRef] [Green Version]
- Sefara, T.J.; Mokgonyane, T.B.; Manamela, M.J.; Modipa, T.I. HMM-based speech synthesis system incorporated with language identification for low-resourced languages. In Proceedings of the IEEE 2019 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Winterton, South Africa, 5–6 August 2019. [Google Scholar] [CrossRef]
- Reddy, M.K.; Rao, K.S. Improved HMM-Based Mixed-Language (Telugu–Hindi) Polyglot Speech Synthesis. In Advances in Communication, Signal Processing, VLSI, and Embedded Systems; Springer: Singapore, 2020; pp. 279–287. [Google Scholar]
- Liu, M.; Yang, J. Design and Implementation of Burmese Speech Synthesis System Based on HMM-DNN. In Proceedings of the IEEE 2019 International Conference on Asian Language Processing (IALP), Shanghai, China, 15–17 November 2019. [Google Scholar] [CrossRef]
- Ninh, D.K. A speaker-adaptive hmm-based vietnamese text-to-speech system. In Proceedings of the IEEE 2019 11th International Conference on Knowledge and Systems Engineering (KSE), Da Nang, Vietnam, 24–26 October 2019. [Google Scholar]
- Tokuda, K.; Nankaku, Y.; Toda, T.; Zen, H.; Yamagishi, J.; Oura, K. Speech synthesis based on hidden Markov models. Proc. IEEE 2013, 101, 1234–1252. [Google Scholar] [CrossRef] [Green Version]
- Öztürk, M.G.; Ulusoy, O.; Demiroglu, C. DNN-based speaker-adaptive postfiltering with limited adaptation data for statistical speech synthesis systems. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar] [CrossRef]
- Coto-Jiménez, M. Improving post-filtering of artificial speech using pre-trained LSTM neural networks. Biomimetics 2019, 4, 39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hayden, R.E. The relative frequency of phonemes in general-American English. Word 1950, 6, 217–223. [Google Scholar] [CrossRef] [Green Version]
- Suk, H.W.; Hwang, H. Regularized fuzzy clusterwise ridge regression. Adv. Data Anal. Classif. 2010, 4, 35–51. [Google Scholar] [CrossRef]
- Takamichi, S.; Toda, T.; Neubig, G.; Sakti, S.; Nakamura, S. A postfilter to modify the modulation spectrum in HMM-based speech synthesis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Takamichi, S.; Toda, T.; Black, A.W.; Neubig, G.; Sakti, S.; Nakamura, S. Postfilters to Modify the Modulation Spectrum for Statistical Parametric Speech Synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 755–767. [Google Scholar] [CrossRef]
- Nakashika, T.; Takashima, R.; Takiguchi, T.; Ariki, Y. Voice conversion in high-order eigen space using deep belief nets. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Lyon, France, 25–29 August 2013; pp. 369–372. [Google Scholar]
- Chen, L.H.; Raitio, T.; Valentini-Botinhao, C.; Ling, Z.H.; Yamagishi, J. A deep generative architecture for postfiltering in statistical parametric speech synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2015, 23, 2003–2014. [Google Scholar] [CrossRef]
- Muthukumar, P.K.; Black, A.W. Recurrent Neural Network Postfilters for Statistical Parametric Speech Synthesis. arXiv 2016, arXiv:1601.07215. [Google Scholar]
- Coto-Jiménez, M.; Goddard-Close, J.; Martínez-Licona, F.M. Improving Automatic Speech Recognition Containing Additive Noise Using Deep Denoising Autoencoders of LSTM Networks. In Proceedings of the International Conference on Speech and Computer, SPECOM 2016, Budapest, Hungary, 23–27 August 2016; Springer: Cham, Switzerland, 2016; Volume 9811. [Google Scholar] [CrossRef]
- Chen, L.-H.; Raitio, T.; Valentini-Botinhao, C.; Yamagishi, J.; Ling, Z.H. DNN-based stochastic postfilter for HMM-based speech synthesis. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Singapore, 14–18 September 2014; pp. 1954–1958. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Jaitly, N.; Mohamed, A. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Olomouc, Czech Republic, 8–12 December 2013. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Artificial Neural Networks: Formal Models and Their Applications—ICANN; Springer: Berlin/Heidelberg, Germany, 2005; pp. 799–804. [Google Scholar]
- Fan, Y.; Qian, Y.; Xie, F.L.; Soong, F.K. TTS synthesis with bidirectional LSTM based recurrent neural networks. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Singapore, 14–18 September 2014; pp. 1964–1968. [Google Scholar]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning precise timing with LSTM recurrent networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar]
- Erro, D. Improved HNM-Based Vocoder for Statistical Synthesizers. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 1809–1812. [Google Scholar]
- Koc, T.; Ciloglu, T. Nonlinear interactive source-filter models for speech. Comput. Speech Lang. 2016, 36, 365–394. [Google Scholar] [CrossRef]
- Kominek, J.; Black, A.W. The CMU Arctic Speech Databases. Available online: http://festvox.org/cmu_arctic/index.html (accessed on 5 December 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Total | Train | Validation | Test |
|---|---|---|---|---|
| BDL | 676,554 | 473,588 | 135,311 | 67,655 |
| SLT | 677,970 | 474,579 | 135,594 | 67,797 |
| CLB | 769,161 | 538,413 | 153,832 | 76,916 |
| RMS | 793,067 | 555,147 | 158,613 | 79,307 |
| Voice | HTS | Base-Type | Discriminative-Type | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 2 | 3 | ||
| SLT | 46.30 | 42.78 | 43.21 | 69.54 | 42.18 | 41.97 | 33.84 * |
| RMS | 38.30 | 32.39 | 32.54 | 38.62 | 30.76 * | 31.39 | 31.45 |
| JMK | 35.26 | 31.69 | 31.45 | 35.65 | 30.50 * | 31.18 | 32.10 |
| CLB | 37.20 | 34.96 | 34.94 | 36.92 | 32.55 | 32.23 * | 36.61 |
| BDL | 41.71 | 37.20 | 37.09 * | 41.59 | 37.82 | 37.60 | 38.72 |
| Voice | HTS | Base-Type | Discriminative-Type | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 2 | 3 | ||
| SLT | 1.0 | 1.0 | 1.0 | 0.6 | 1.0 | 1.0 | 1.3 * |
| RMS | 1.5 | 1.6 * | 1.5 | 1.4 | 1.6 * | 1.4 | 1.4 |
| JMK | 1.3 | 1.4 * | 1.4 * | 1.2 | 1.3 | 1.2 | 1.2 |
| CLB | 1.3 | 1.2 * | 1.2 * | 1.1 | 1.2 * | 1.1 | 1.0 |
| BDL | 1.4 | 1.4 * | 1.4 * | 1.1 | 1.4 * | 1.4 * | 1.3 |
| Voice | HTS | Base-Type | Discriminative-Type | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 2 | 3 | ||
| SLT | 0.5 | 1.2 | 1.7 | 0.3 | 1.5 | 1.8 | 2.8 * |
| RMS | 1.4 | 2.4 | 2.5 * | 1.4 | 2.2 | 2.0 | 1.8 |
| JMK | 1.7 | 1.9 | 1.1 | 0.8 | 2.0 | 2.1 * | 2.0 |
| CLB | 2.4 | 2.7 | 2.2 | 2.4 | 3.4 * | 3.1 | 2.8 |
| BDL | 0.5 | 1.4 | 1.5 * | 0.7 | 1.3 | 1.3 | 1.2 |
| Voice | Base-Type | Discriminative-Type | ||||
|---|---|---|---|---|---|---|
| WSS | PESQ | SegSNRf | WSS | PESQ | SegSNRf | |
| SLT | ns | ns | ✓ | ✓ | ✓ | ✓ |
| RMS | ✓ | ns | ✓ | ✓ | ns | ✓ |
| JMK | ✓ | ns | ns | ✓ | ns | ns |
| CLB | ns | ns | ✓ | ✓ | ||
| BDL | ✓ | ns | ✓ | ns | ns | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coto-Jiménez, M. Discriminative Multi-Stream Postfilters Based on Deep Learning for Enhancing Statistical Parametric Speech Synthesis. Biomimetics 2021, 6, 12. https://doi.org/10.3390/biomimetics6010012
Coto-Jiménez M. Discriminative Multi-Stream Postfilters Based on Deep Learning for Enhancing Statistical Parametric Speech Synthesis. Biomimetics. 2021; 6(1):12. https://doi.org/10.3390/biomimetics6010012
Chicago/Turabian StyleCoto-Jiménez, Marvin. 2021. "Discriminative Multi-Stream Postfilters Based on Deep Learning for Enhancing Statistical Parametric Speech Synthesis" Biomimetics 6, no. 1: 12. https://doi.org/10.3390/biomimetics6010012
APA StyleCoto-Jiménez, M. (2021). Discriminative Multi-Stream Postfilters Based on Deep Learning for Enhancing Statistical Parametric Speech Synthesis. Biomimetics, 6(1), 12. https://doi.org/10.3390/biomimetics6010012