

MC-YOLOv5: A Multi-Class Small Object Detection Algorithm

Abstract
1. Introduction
- The feature extraction process incorporates a novel CB module, which effectively enhances the semantic information of small objects and significantly improves detection precision.
- The SNO was implemented to enhance the receptive field and minimize the rate of missed object detection.
- The decoupled head based on the anchor frame is employed for object classification and localization to enhance reasoning efficiency. Following an extensive evaluation on VisDrone2019, Tinyperson, and RSOD datasets, MC-YOLOv5 demonstrates superior precision and speed compared to the original YOLOv5L.
2. Related Work
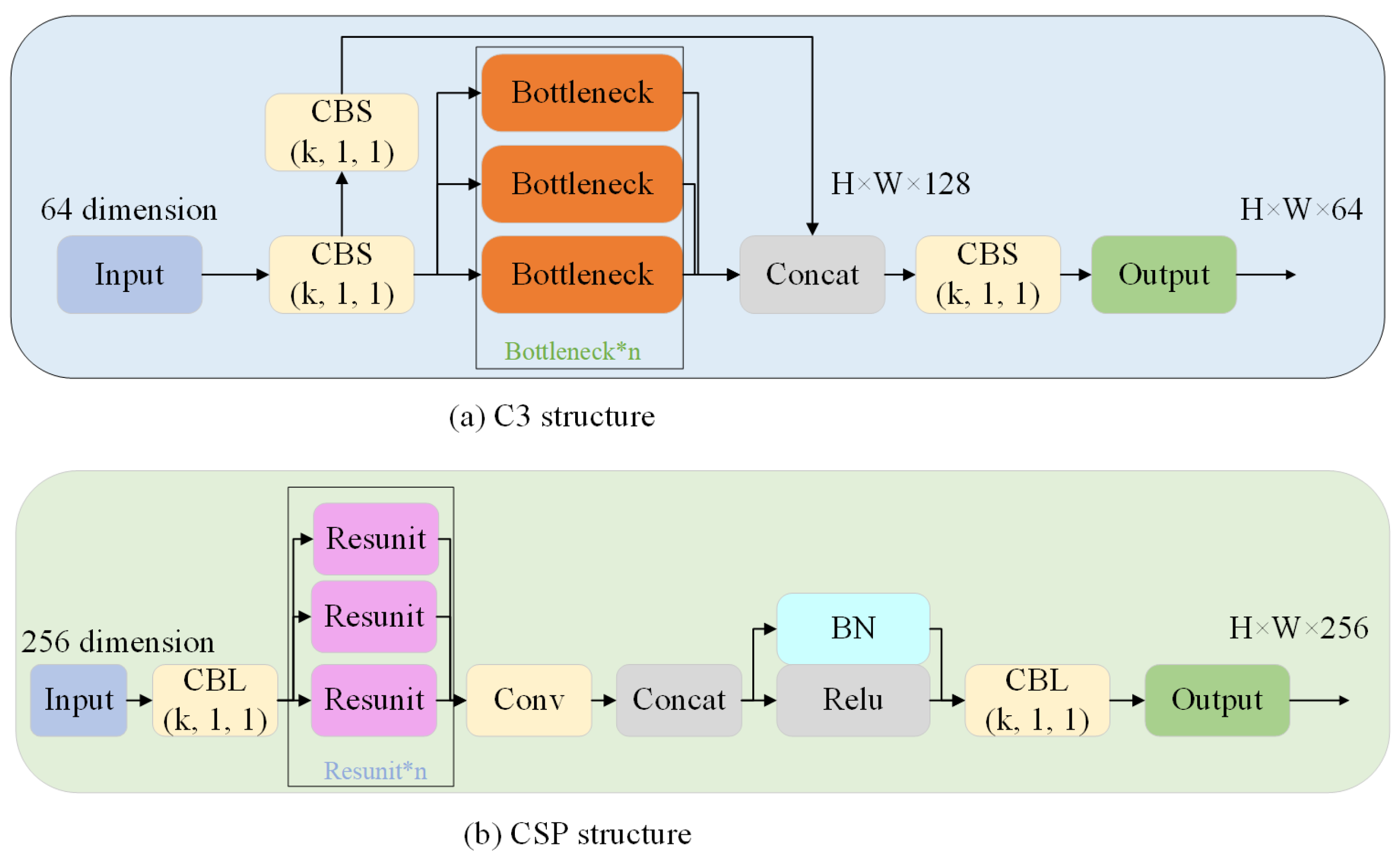
3. The Proposed MC-YOLOv5
3.1. New CB Module
3.2. The Revised Shallow Network Optimization Strategy (SNO)
3.3. The Decoupled Head Based on Anchor
4. Experiments
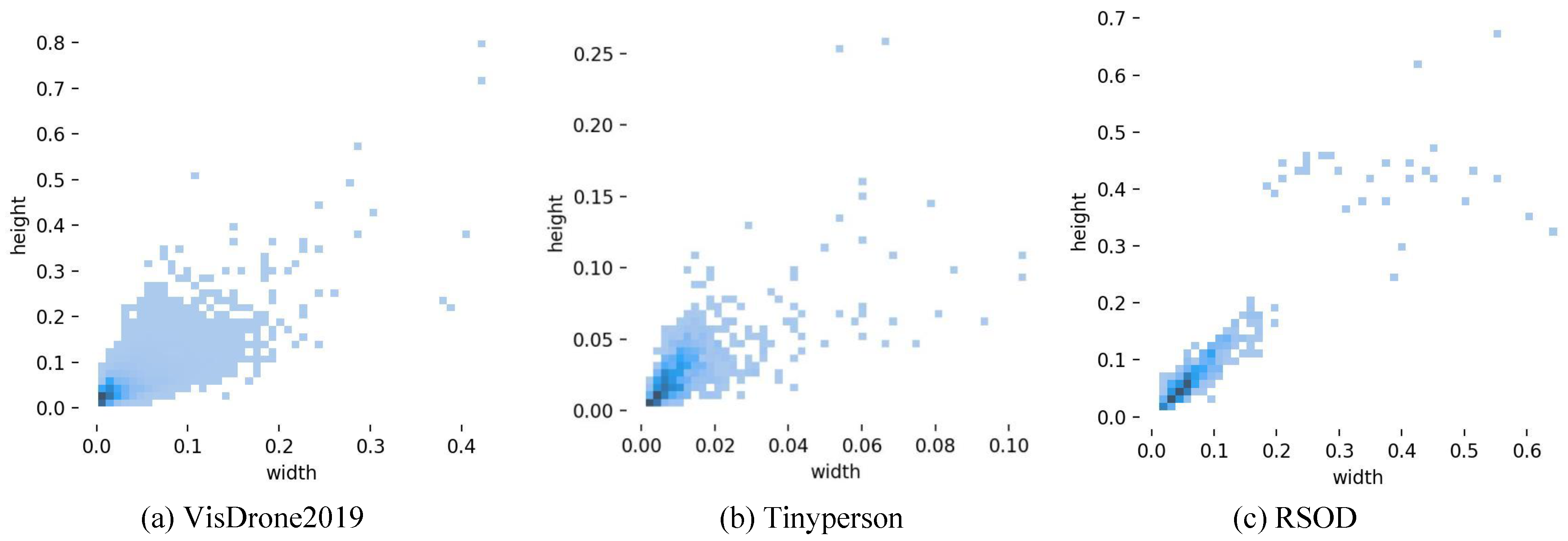
4.1. Datasets
4.2. Experimental Results and Comparison
4.3. Ablation Experiments
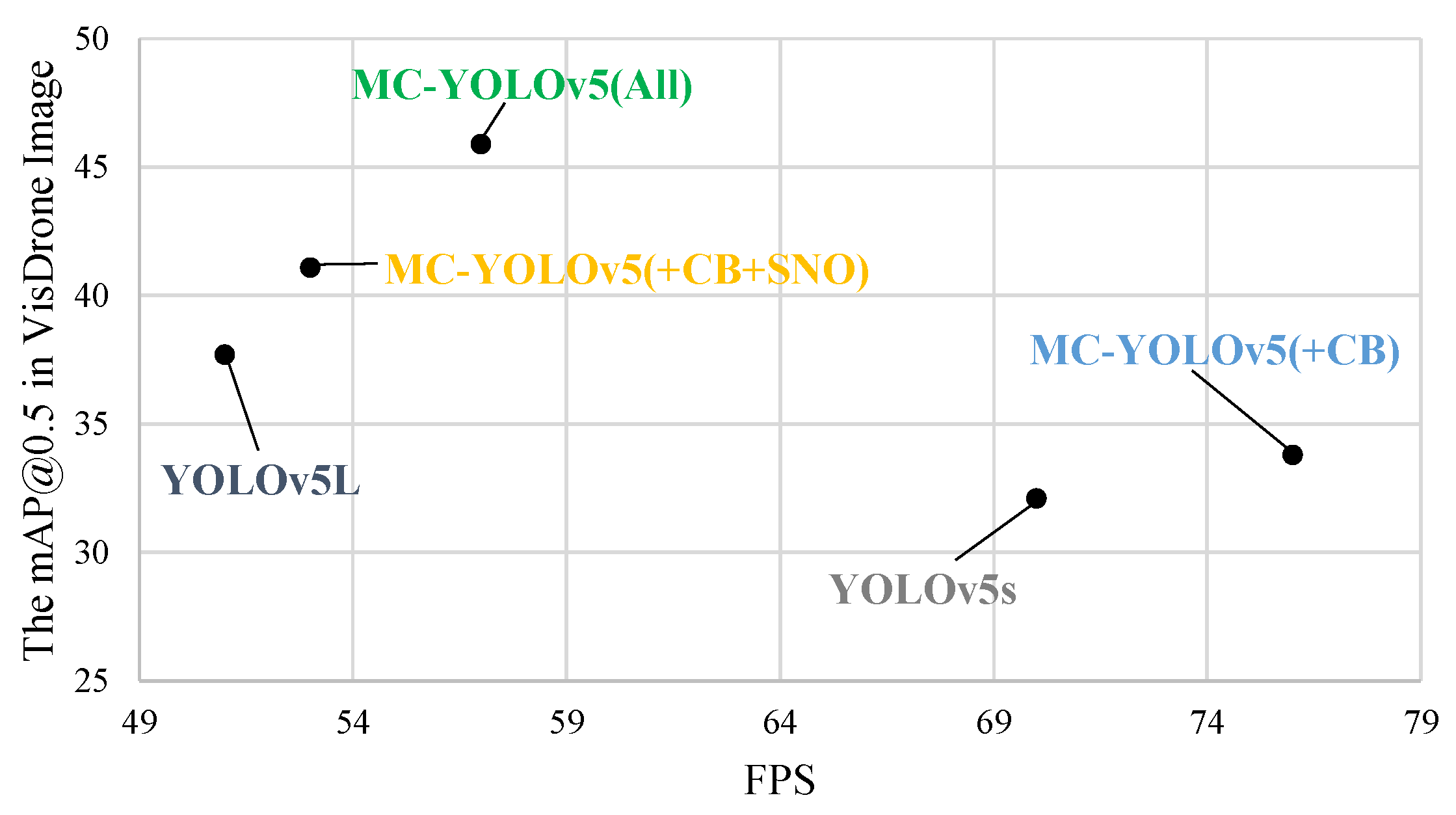
4.4. Discussion on Efficiency of MC-YOLOv5
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Glenn, J. 6.2—YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML And Deci.ai Integrations. August 2022. Available online: https://github.com/ultralytics/yolov5 (accessed on 21 July 2023).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects incontext. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lian, J.; Yin, Y.; Li, L.; Wang, Z.; Zhou, Y. Small Object Detection in Traffic Scenes Based on Attention Feature Fusion. Sensors 2021, 21, 3031. [Google Scholar] [CrossRef] [PubMed]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1257–1265. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the Conference on Computer Vision Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Leibe, B.; Matas, J.; Sebe, N.; Welling, M. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science Computer Vision; Springer: Cham, Switerland, 2016; pp. 1–17. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1–17. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCVW, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Bai, W.; Zhao, J.; Dai, C.; Zhang, H.; Zhao, L.; Ji, Z.; Ganche, I. Two Novel Models for Traffic Sign Detection Based on YOLOv5s. Axioms 2023, 12, 160. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2023, 14, 2412. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, J.; Zhao, L.; Zhang, H.; Li, L.; Ji, Z.; Ganche, I. Detection of River Floating Garbage Based on Improved YOLOv5. Mathematics 2022, 10, 4366. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1–9. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tuggener, L.; Elezi, I.; Schmidhuber, J.; Pelillo, M.; Stadelmann, T. Deepscores-a dataset for segmentation, detection and classification of tinyobjects. In Proceedings of the International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3704–3709. [Google Scholar]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Dunn, O.J. Multiple Comparisons among Means. J. Am. Stat. Assoc. 1961, 56, 52–64. [Google Scholar] [CrossRef]
- Lin, Y.; Hu, Q.; Liu, J.; Li, J.; Wu, X. Streaming feature selection for multilabel learning based on fuzzy mutual information. IEEE Trans. Fuzzy Syst. 2017, 25, 1491–1507. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Improvement | Classes |
|---|---|---|
| TPH-YOLOv5 | +TPH | VisDrone2021(UAV) |
| YOLOv5-TDHSA | +T, +DH, +SA | TT100k& CCTSDB (traffic) |
| CME-YOLOv5 | +CA, +EIoU | River floating garbage (private) |
| YOLOv5_CBS | +CCUB, +BiFPN, +SIoU | Fish (private) |
| MC-YOLOv5 (Ours) | +CB, +SNO, +(A)DH | VisDrone2019(UAV), Tinyperson(person), RSOD(airplane) |
| Methods | mAP@0.5 | mAP@0.5:0.95 | Parameters (M) | Flops (G) | Times (ms) | F1 Score |
|---|---|---|---|---|---|---|
| YOLOv4 | 24.2 | 14.2 | 64.3 | 143.2 | 58.6 | 0.26 |
| YOLOv5s | 32.1 | 16.9 | 7.0 | 15.8 | 14.1 | 0.37 |
| MC-YOLOv5 (+CB) | 33.8 | 18.2 | 6.4 | 15.3 | 13.1 | 0.39 |
| YOLOv3 | 39.0 | 21.5 | 61.5 | 154.7 | 47.9 | 0.44 |
| YOLOv5L | 37.7 | 21.3 | 46.1 | 107.8 | 19.3 | 0.42 |
| YOLOv7 | 45 | 25.2 | 36.5 | 103.3 | 19.6 | 0.47 |
| MC-YOLOv5 (All) | 45.9 | 26.6 | 38.2 | 69.7 | 17.5 | 0.49 |
| Datasets | Metrics | YOLOv5s | YOLOv3 | YOLOv4 | YOLOv5L | YOLOv7 | MC-YOLOv5 (All) |
|---|---|---|---|---|---|---|---|
| Tinyperson | mAP@0.5 | 11.3 | 20.3 | 12.63 | 19.1 | 6.91 | 20.3 |
| mAP@0.5:0.95 | 2.6 | 5.22 | 3.64 | 4.8 | 1.52 | 5.87 | |
| RSOD | mAP@0.5 | 92.9 | 94.2 | 92.4 | 94.8 | 95.5 | 96.7 |
| mAP@0.5:0.95 | 61.6 | 66.8 | 59.3 | 66.6 | 63.8 | 66.9 |
| Classes (Complete) | YOLOv5s (Baseline) | MC-YOLOv5 (+CB) | YOLOv5L (Baseline) | MC-YOLOv5 (+CB+SNO) | MC-YOLOv5 (All) |
|---|---|---|---|---|---|
| Pedestrian | 40.3 | 40.9(+0.6) | 46.5 | 50.5(+4) | 55.3(+4.8) |
| People | 32.1 | 33.5(+1.4) | 36.6 | 38.2(+1.6) | 45.1(+6.9) |
| Bicycle | 9.9 | 10.7(+0.8) | 14.4 | 17.6(+3.2) | 22.6(+5.0) |
| Car | 72.7 | 74.2(+1.5) | 77 | 82.2(+5.2) | 84.1(+1.9) |
| Van | 33.4 | 37.2(+3.8) | 41.4 | 44.7(+3.3) | 48.1(+3.4) |
| Trunk | 26.4 | 27.9(+1.5) | 33.1 | 34.3(+1.2) | 39.3(+5) |
| Tricycle | 18.5 | 18.7(+0.2) | 24.2 | 28.1(+3.9) | 32.2(+4.1) |
| Awnin-tricycle | 11.6 | 12.4(+0.8) | 11.4 | 14.1(+2.7) | 18.3(+4.2) |
| Bus | 39.0 | 43.4(+4.4) | 48.9 | 53.8(+4.9) | 60.4(+6.6) |
| Motor | 38.1 | 38.9(+0.8) | 43.5 | 47.7(+4.2) | 54.0(+6.3) |
| Sea-person | 12.4 | 14.7(+2.3) | 17.6 | 12.9(−4.7) | 16.3(+3.4) |
| Earth-person | 10.2 | 16.5(+6.3) | 20.6 | 22.6(+2) | 24.4(+1.8) |
| Aircraf t | 94.8 | 95.4(+1.6) | 95.2 | 95.5(+0.3) | 95.7(+0.5) |
| Oil-tank | 99.1 | 99.3(+0.2) | 99.4 | 99.4(−) | 99.4(−) |
| Overpass | 78.3 | 89.3(+11) | 87.1 | 92.3(+5.2) | 94.9(+2.6) |
| Playground | 99.5 | 99.5(−) | 97.5 | 99.6(+2.1) | 99.7(+0.1) |
| Average Rank | 4.84 | 3.72 | 3.22 | 2.15 | 1.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Liu, H.; Sun, T.; Lou, H.; Duan, X.; Bi, L.; Liu, L. MC-YOLOv5: A Multi-Class Small Object Detection Algorithm. Biomimetics 2023, 8, 342. https://doi.org/10.3390/biomimetics8040342
Chen H, Liu H, Sun T, Lou H, Duan X, Bi L, Liu L. MC-YOLOv5: A Multi-Class Small Object Detection Algorithm. Biomimetics. 2023; 8(4):342. https://doi.org/10.3390/biomimetics8040342
Chicago/Turabian StyleChen, Haonan, Haiying Liu, Tao Sun, Haitong Lou, Xuehu Duan, Lingyun Bi, and Lida Liu. 2023. "MC-YOLOv5: A Multi-Class Small Object Detection Algorithm" Biomimetics 8, no. 4: 342. https://doi.org/10.3390/biomimetics8040342
APA StyleChen, H., Liu, H., Sun, T., Lou, H., Duan, X., Bi, L., & Liu, L. (2023). MC-YOLOv5: A Multi-Class Small Object Detection Algorithm. Biomimetics, 8(4), 342. https://doi.org/10.3390/biomimetics8040342