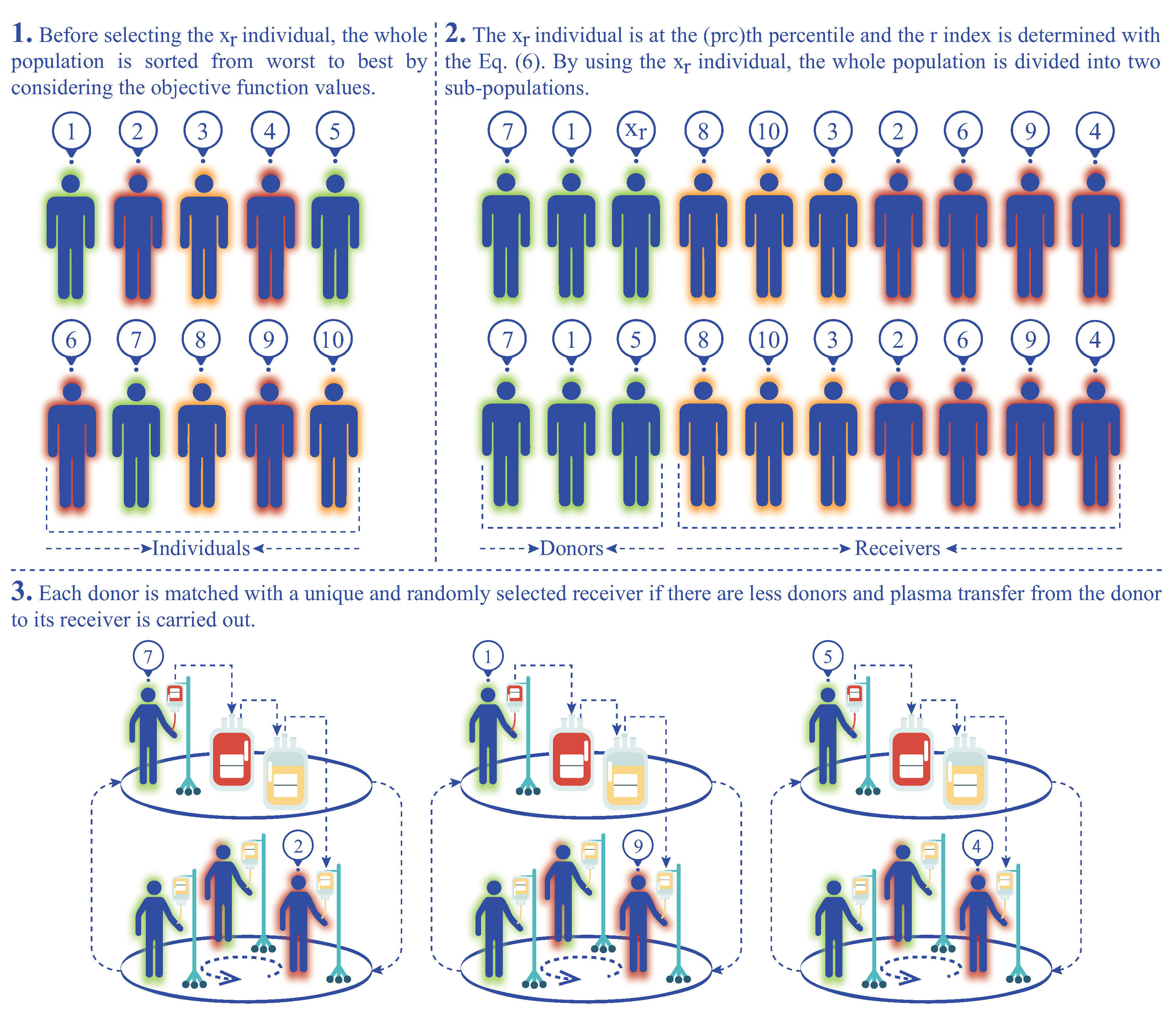
4.1. Solving Classical Benchmark Problems with pIPA
The benchmark problems or functions for which the formulation, lower and upper bounds are given in
Table 1 were solved with the pIPA. The global minimum values of all these problems except the
are equal to zero. For the
, the global minimum value is calculated as
where
D corresponds to the number parameters as stated before. When solving the 100-dimensional benchmark problems given in
Table 1, the population size and maximum evaluation number were set to 30 and 30,000 [
24]. To analyze how the qualities of the solutions change with the values assigned to
, nine positive integers, including 30, 35, 40, 50, 60, 70, 80, 90, and 95 were used. The pIPA with the mentioned configurations was tested 30 times for each problem instance using random seeds. The objective function values of the best solutions found at each of 30 runs were averaged and reported in
Table 2 with the related standard deviations.
The results reported in
Table 2 give important information about the pIPA and appropriate values of the
parameter. Although the pIPA obtains the global minimum solutions with all of the nine different values assigned to the
for the
,
and
functions, it finds relatively close mean best objective function values for the
function with all of the constants assigned to the
. As distinct from the global minimums of
,
and
functions, the global minimum of the
function is located at the end of a long and narrow valley and converging to the global minimum of it is extremely difficult. Because of this main reason, meta-heuristic algorithms usually require subtly configured control parameters and more evaluations for the mentioned function. However, it should be noted that the percentile-based donor–receiver selection mechanism adjusts the workflow and contributes to the convergence of the pIPA even though the
is changed. For
,
,
and
functions, the qualities of the solutions found by the pIPA get better or change slightly when the value assigned to the
increases from 30 to 80 or even 90. Similar generalizations can also be made for the
,
,
, and
functions by considering a small set of values of
. The qualities of the solutions found by the pIPA get better or change slightly for the these functions when the
increases from 30 to 40.
As stated before, the number of donors and receivers in pIPA can be different at each cycle, while the
remains unchanged. To analyze whether the number of donors and the number of receivers change or not when the initial value of the
is preserved until the end of a run, they are first counted at each cycle, averaged, and then recorded. After completing 30 independent runs, the number of donors and number of receivers recorded for each run are averaged again and presented in
Table 3. When the results given in
Table 3 are controlled, it is seen that the newly proposed mechanism is capable of changing or adjusting the number of donors and receivers for the
,
,
,
and
functions. It tries to increase the number of donors and decrease the number of receivers while the value of the
is protected. By changing the number of donors and number of receivers without increasing or decreasing the initial value of the
, pIPA also has a chance to adjust the execution of exploration and exploitation dominant phases explicitly.
The newly proposed percentile-based donor–receiver selection strategy requires the execution of extra computational operations compared to the standard implementation of the IPA and changes the density of the exploration and exploitation dominant phases. To understand whether the usage of the percentile-based donor–receiver selection strategy increases the execution time of the algorithm or not, the duration of each run in terms of seconds is recorded and then averaged after the completion of 30 independent tests of pIPA with different values. Also, the duration of each run in terms of seconds is recorded and then averaged when 30 independent tests are completed for the standard IPA whose and parameters are set to 1. Both pIPA and IPA were coded in C programming language, and experiments were carried out on a PC equipped with a single-core processor with Ghz.
From the average execution times and related standard deviations belonging to pIPA and IPA given in
Table 4, it is clearly seen that IPA requires less time compared to the pIPA with lower
values. Moreover, it is understood that there is a relationship between the execution time of the pIPA and the value assigned to the
. Although the
is increased, the average execution time of the pIPA generally decreases. If the
is increased, the number of possible donors decreases, and plasma treatment is carried out for a small set of randomly determined receivers. Otherwise, the number of possible donors increases, more receivers are supported with the plasma treatment, and the execution time of the pIPA increases because of the computationally intensive operations of the plasma transfer. However, it should be noted that when the difference between the number of donors tried to be adjusted with the
and
decreases, the difference between the average execution times of the pIPA and IPA also decreases.
The contribution of the proposed mechanism can be understood by comparing the results of the pIPA with the results of other meta-heuristics. For this purpose, the results of the pIPA were compared with the results of the IPA [
51], MFO [
24], PSO [
55], GSA [
41], BA [
19], FPA [
20], SMS [
44], FA [
18] and GA [
6]. To guarantee that all meta-heuristics obtain their results under the same conditions, population sizes of them were set to 30, and the maximum evaluation number was taken equal to 30,000 [
24,
51]. Although the
of the pIPA was 90 for
,
,
,
,
and
, it was determined as 60 and 50 for the
and
. Moreover, the value of the
was equal to 40 for
,
and
and equal to 30 for the
function. When the mean best objective function values and standard deviations belonging to the 30 independent runs of these algorithms in
Table 5 are investigated, the superiority of the pIPA can be seen. For 10 of 12 benchmark functions, pIPA outperforms its competitors or obtains the same mean best objective function values. It only lags behind the IPA for the
function and the GSA for the
function and becomes the second-best algorithm among other tested meta-heuristics for these functions. The idea lying behind the pIPA manages donor and receiver selection operations more robustly compared to the standard implementation of the IPA by setting only one control parameter. In pIPA, the number of donors and receivers can be updated from one cycle to another while the
remains unchanged. Furthermore, although the number of donors and receivers are the same for different cycles, donors and receivers are matched by a controlled–randomized approach, and receivers have a chance of treatment with the plasma of a different donor.
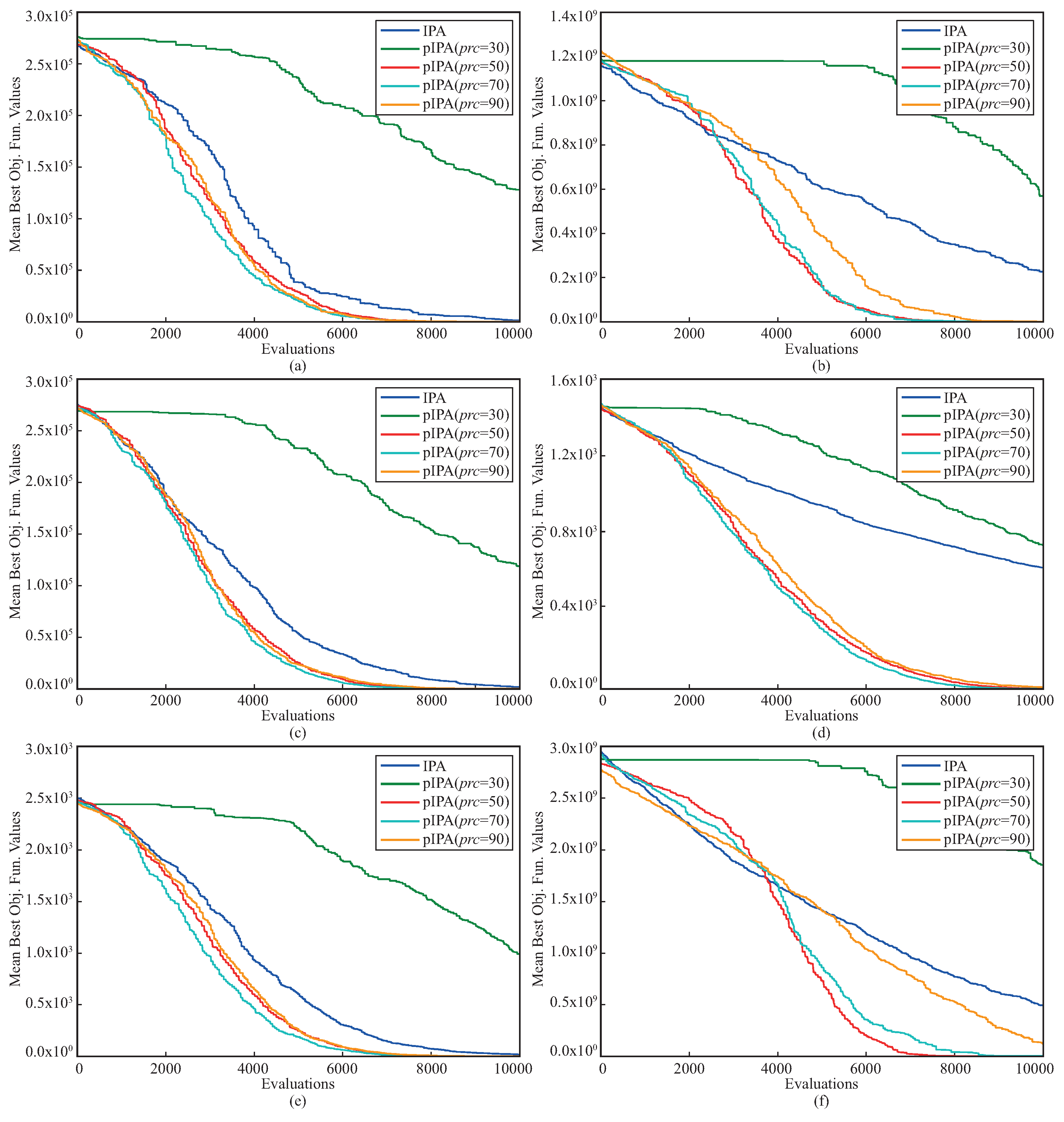
Another comparison between pIPA and IPA was made for the convergence performances. To analyze and compare the convergence performances of meta-heuristic algorithms, there are two commonly used metrics, namely success rate and mean evaluation. If a run of the algorithm achieves a better solution compared to a threshold before the previously determined termination criteria are met, it is said that the run is successful. The success rate is the ratio between the number of successful runs and the total number of runs. For each successful run, the minimum number of function evaluations required to achieve a better solution compared to a threshold is recorded. The average of these recorded values corresponds to the mean evaluation. The convergence comparison between pIPA and IPA was made by setting the threshold to
for
,
,
,
,
and
functions,
for
function,
for
function,
for
function,
for
function,
for
function,
for
function and then success rate and mean evaluation metrics abbreviated as
and
were summarized in
Table 6. When these metrics given in
Table 6 are investigated, it is easily seen that the convergence performance of pIPA is more robust than the convergence performance of IPA. Even though the
metrics of both pIPA and IPA are equal to
for
,
,
,
and
functions, the
metric of pIPA is better than the
metric of IPA. For all the remaining benchmark functions, pIPA outperforms the standard implementation of the IPA by considering the convergence performance measured in terms of
and
. The
Figure 2 given should also be viewed to investigate the changes in the convergence curves of the pIPA with the varying
values.
The final comparison between pIPA and other meta-heuristics for 100-dimensional problems was carried out to decide whether the result of pIPA is enough to generate a statistical difference in favor of pIPA or not using the Wilcoxon signed rank test with the significance level equal to
. If the significance level shown as
is less than
, it is said that the difference between the two algorithms is statistically significant in favor of one of them. Otherwise, the results obtained by the algorithms are not enough to decide which one is statistically significant. The statistical test results related to the pIPA and its competitors were given in
Table 7. In
Table 7,
and
show the sum of positive ranks and the sum of negative ranks, respectively. Also, the
Z corresponds to the standardized test statistic. The results given in
Table 7 show that the statistical difference between pIPA and MFO, PSO, GSA, BA, FPA, SMS, FA, or GA is in favor of pIPA. Only the decision about whether a statistical difference between pIPA and IPA exists or not cannot be made from the current results of the algorithms.
The qualities of the final solutions, convergence performance, and statistical test results of the pIPA for 100-dimensional problems gave strong evidence of its capabilities. However, its capabilities should also be analyzed with another scenario in which population size, dimensionalities of the problems, and termination criteria are changed. For this purpose, the benchmark functions given in
Table 1 were solved by setting the population size of the pIPA to 100 and number of parameters to 200 [
25,
51]. The maximum evaluation number was taken equal to
[
25,
51]. Nine positive integers including 30, 35, 40, 50, 60, 70, 80, 90 and 95 were assigned to the
and pIPA was tested 30 times with random seeds for each problem instance and
combination. The objective function values of the best solutions found for each of 30 runs were averaged and reported in
Table 8 with the related standard deviations.
When the results given in
Table 8 are investigated, it is seen that the change trend of the pIPA with the different
for 200-dimensional problems is similar to the change trend of the pIPA with the different
for 100-dimensional problems. The pIPA obtains the global minimum solutions with the different values assigned to the
for the
,
,
, and
functions. Moreover, it finds almost the same mean best objective function values for the
function with all nine different values of the
as in the previous experimental settings. For
,
, and
functions, pIPA obtains better or slightly changed solutions when the value assigned to the
increases from 30 to 80 or even 90. Similar generalization can also be made for the
and
,
functions by considering the
increasing from 30 to 40 and
function by considering the
increasing from 60 to 90. However, it should be noted that more robust solutions for the
function can be obtained with the
less than 40.
The changes in the average number of donors and receivers of the pIPA for 200-dimensional benchmark functions can be examined with
Table 9. As seen from
Table 9, pIPA tries to adjust the number of donors and receivers for the
,
,
,
,
and
functions while the number of donors and receivers remains unchanged for the other functions. Choosing the value of the
relatively close to its upper or lower bound decreases the number of possible donors or receivers. However, the donor–receiver selection strategy of the pIPA can increase the number of donors compared to the number of donors determined with the value of the
, if the objective function values of the qualified individuals are relatively close to each other or same. Otherwise, the number of donors and receivers is simply calculated using the assigned value to the
.
The results of the pIPA for 200-dimensional problems should be validated with the comparison to the results of other meta-heuristics obtained under the same conditions. For this purpose, pIPA was compared with the standard implementation of the IPA [
51], ALO [
25], PSO [
55], SMS [
44], BA [
19], FPA [
20], CS [
17], FA [
18] and GA [
6]. Although population sizes of the tested algorithms were equal to 100, the maximum evaluation number was set to
. The
of the pIPA was 90 for
,
,
,
,
and
. Also, it was determined as 40 for the
,
,
,
,
and
. When the mean best objective function values and standard deviations of the algorithms in
Table 10 are controlled, it is seen that pIPA outperforms other tested algorithms or obtains the same mean best objective function values for ten of 12 benchmark functions. Although pIPA lags behind the ALO for the
function and the IPA for the
function, it becomes the second-best algorithm among other competitors for these functions and proves its superiority with the average rank equal to
.
The comparison between pIPA and other meta-heuristics for classical benchmark problems was completed by the results of the Wilcoxon signed rank test with the significance level
. From the test results given in
Table 11, it is understood that the solutions obtained by the pIPA for 200-dimensional problems are strong enough to generate a statistical difference in favor of the pIPA. Although the
value is found equal to
for the statistical comparison between the pIPA and PSO, SMS, BA, FPA, CS, FA, or GA and proves that the difference is in favor of pIPA, the
value is found equal to
for the statistical comparison between pIPA and ALO and
for the statistical comparison between pIPA and IPA. The results found by the IPA for the
function and ALO for the
function cause a slight change in the
values. However, it is still less than
, and validates the comparative performance of the pIPA.
4.2. Solving CEC 2015 Benchmark Problems with pIPA
The complexities of the benchmark problems can be increased using operations related to shifting, rotation, hybridization, and composition. To investigate the performance of pIPA on solving these kinds of problems, ten different 30-dimensional problems introduced at CEC 2015 were chosen, and their names, base functions, and global minimums are listed in
Table 12 [
61]. The lower and upper bounds of these functions were equal to
and
[
61]. Although the
and
functions in
Table 12 are rotated,
,
,
,
,
and
functions are both shifted and rotated [
61]. Moreover, while the
is a hybrid function generated by four base functions, the
is a compositional function joining three base functions [
61]. When solving the problems given in
Table 12, the population size of the pIPA was set to 100, and the maximum evaluation number was taken equal to 100,000 [
37]. Nine different values including 30, 35, 40, 50, 60, 70, 80, 90 and 95 were assigned to
and pIPA was tested 30 times with random seeds for each problem and
combination. The objective function values of the best solutions found by each of 30 runs were averaged and reported in
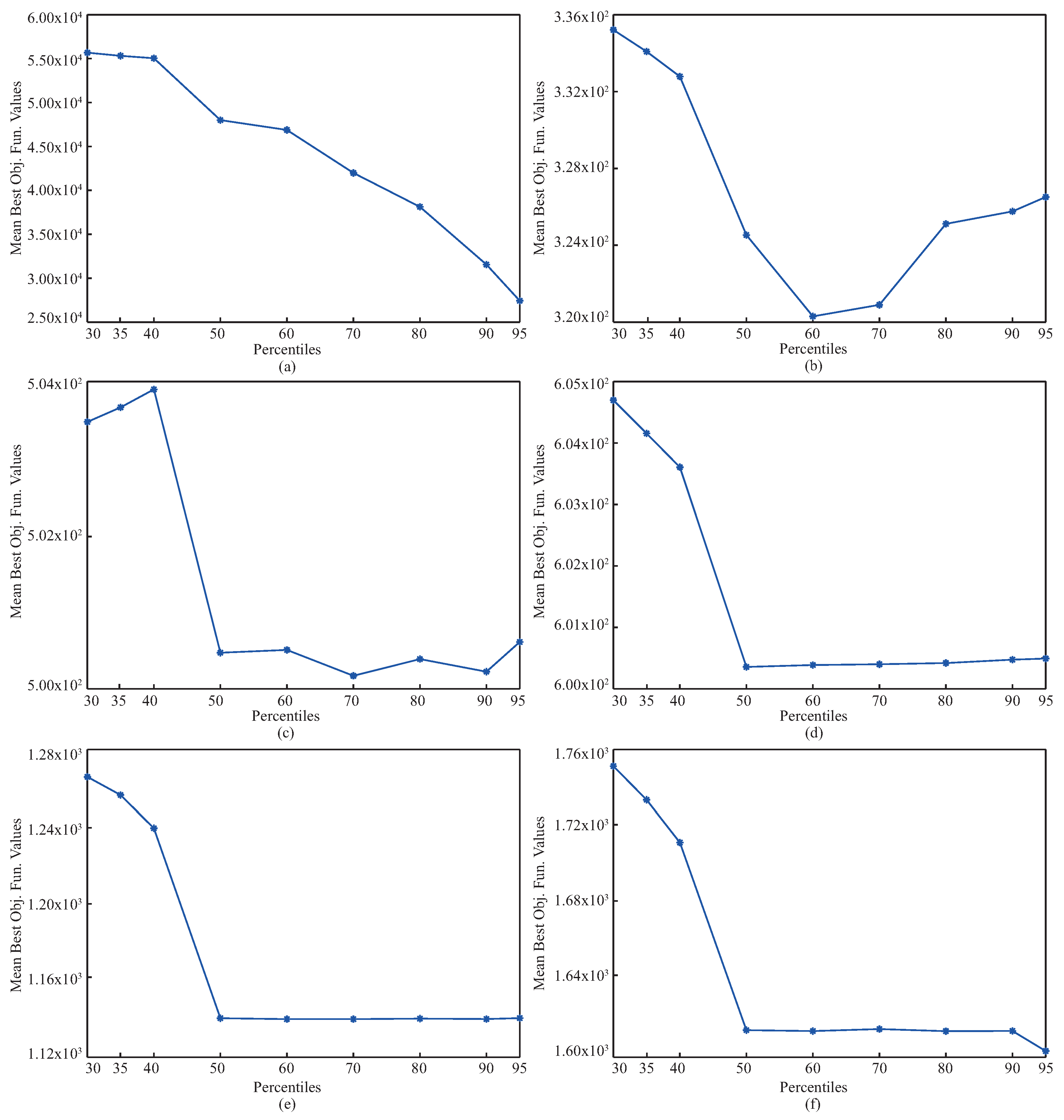
Table 13 with the related standard deviations. The results given in
Table 13 guide us to interpret the change trend of the pIPA with the varied
values. For the
and
functions, the objective function values of the obtained solutions by pIPA grow better with the
increasing from 30 to 90 or 95. Similar generalizations can be made for the remaining functions except
. Although the increasing values of
from 30 to 60 or 70 improves the qualities of the solutions found by pIPA for
,
,
and
functions, the qualities of the solutions found by pIPA grow better with the
increasing from 30 to 50. Only for the
function do the values assigned to the
not cause a significant change in the solution qualities of the pIPA.
Figure 3 should also be viewed to analyze the effect of the
on the performance of the pIPA.
For validating the qualities of the solutions found by the pIPA, its mean best objective function values and standard deviations are compared with the mean best objective function values and standard deviations belonging to the IPA [
51], SOA [
37], SHO [
35], GWO [
23], PSO [
55], MFO [
24], MVO [
27], SCA [
26], GSA [
41], GA [
6] and DE [
56] as in
Table 14. To ensure that the comparison is made under the same conditions, the population size and maximum evaluation number were set to 100 and 100,000 for all algorithms [
37]. The
value of the pIPA was taken equal to 50 for
and
functions, 60 for
and
functions, 70 for
function, 80 for
function, 90 for
and
functions, 95 for
and
functions. The
and
parameters of the IPA were set to 1. The results given in
Table 14 showed that the pIPA and IPA outperform SOA, SHO, GWO, PSO, MFO, MVO, SCA, GSA, GA and DE for the
,
,
,
,
and
functions. Although all the tested algorithms find the same mean best objective function values for the
function, SOA outperforms tested algorithms for the
function, and GSA outperforms tested algorithms for the
function.
4.3. Solving Noise Minimization Problem with pIPA
The volume, velocity, variety, and veracity properties of the data moved the difficulties of data-dependent optimization problems into another stage [
62,
63]. One of the data-dependent optimization problems has recently been introduced by Abbass et al., and a special competition has been organized at CEC 2015 with the name BigOpt [
64]. The real-world optimization problem introduced by Abbass et al. mainly focuses on minimizing the measurement noise of the electro-encephalography (EEG) signals [
65,
66]. They stored
megabit of binary formatted data and 20 kilobyte of text formatted data per second and organized them for providing different problem instances. If the measurement of the EEG signal is extended to a period of time, a unique problem instance per second by neglecting the time spent for the storage and preparation will be encountered. Assume that
X and
S are two different matrices of size
. Although
N corresponds to the number of time series belonging to the EEG signal,
M is used on behalf of the number of elements for a time series. In addition to the
X and
S matrices, there is a square transformation matrix
A of size
, and it relates
S matrix to the
X matrix as described in Equation (
7) [
64]. If the
S matrix is matched with the EEG signal containing
N time series with
M samples in each series, the noise-free part of the
S showed by
and the noise part of the
S showed by
must be obtained and used with the
A matrix for finding
X as in Equation (
8) [
65,
66]. Even though the relationship between
S,
and
matrices is straightforward, a simple method splitting the
S matrix into
and
matrices cannot be found easily. By considering the difficulty of splitting the
S matrix, Abbass et al. decided to guide the Pearson Correlation Coefficients showed as
C in Equation (
9) [
66]. In Equation (
9),
is the covariance matrix and
and
are variance matrices, respectively.
Abbass et al. also stated that the diagonal and off-diagonal elements of the
C matrix have important information about the appropriateness of the
matrix and can be referenced for splitting the original
S matrix [
65,
66]. Although the
matrix is obtained from the
S matrix, the diagonal elements of the
C should be maximized, and other elements should be minimized by considering the upper and lower bounds. To understand how the calculated
C matrix for a guessed
satisfies the mentioned properties about the diagonal and off-diagonal elements, Equation (
10) is utilized [
65,
66].
Another important situation that should be controlled when the
matrix is tried to be determined is its similarity with the original
S matrix. Because the
matrix represents the noise-free part of the original
S matrix, the difference between
S and
matrices should be minimized. For measuring the difference between
S and
matrices, Equation (
11) can be used [
65,
66]. As easily seen from Equation (
11), the
matrix should be chosen relatively close to the
S matrix for representing the properties of the EEG signal. When the
matrix is tried to be found by guiding the minimization of the sum of
and
, an optimization problem can be introduced. For analyzing the performance of the solving techniques on the mentioned optimization problem, different instances named D4, D4N, D12, and D12N were introduced by Abbass et al. and required
X,
A, and
S matrices for each instance were reported [
65,
66]. The D4 and D12 instances have four and 12 time series with length 256. Similar to the D4 and D12 instances, D4N and D12N instances also have four and 12 time series with length 256. However, these problem instances are changed slightly with the additional noise components.
The pIPA was tested for solving the D4, D4N, D12, and D12N problem instances. The population size of pIPA was set to 50 [
51]. Nine different values including 30, 35, 40, 50, 60, 70, 80, 90 and 95 were assigned to the
. For each combination of problem instance and
, pIPA was tested 30 times with random seeds by setting the maximum evaluation number to 10,000 [
51]. The mean best objective function values and standard deviation of each test scenario were recorded and presented in
Table 15. The results given in
Table 15 showed that mean best objective function values of pIPA decrease with the increasing value of the
from 30 to 80 for D4, D4N, and D12 problem instances and increasing value of the
from 30 to 90 for D12N problem instance. Although the appropriate value of the
parameter is 80 for D4, D4N, and D12 problem instances by considering the mean best objective function values, the appropriate value of the
parameter is 90 for D12N problem instance by considering the mean best objective function values.
The results obtained by the pIPA for noise minimization problem were compared with the results of IPA [
51], GA [
6], PSO [
55], DE [
56], ABC [
57], GSA [
41], MFO [
24], SCA [
26], SSA [
28] and HHO [
29]-based techniques. To guarantee that the comparison is made under equal conditions, the population or colony size of the algorithms was set to 50, and the maximum evaluation number was taken as 10,000 [
51]. The
parameter of pIPA was set to 80 for the D4, D4N, and D12 problem instances and 90 for the D12N problem instance. The
and
parameters of the standard IPA were equal to 4 and 8, respectively [
51]. For the GA, the crossover rate was
, and the mutation rate was
. The inertia weight of PSO achieved its value between
and
, and both
and
acceleration coefficients were set to 2. Although the scaling factor of DE achieved its value randomly between
and
, the crossover rate was taken equal to
. The
parameter of ABC was set to the half of
where
D was equal to 1024 for D4 and D4N and 3072 for D12 and D12N. The calculation of the logarithmic spiral was completed by setting the
b constant to 1 for MFO. Assuming that
l and
L are current and maximum iteration numbers, the
coefficient of SSA was calculated as
. When the best, mean best objective function values and standard deviation over 30 independent runs given in
Table 16 are controlled, it is seen that pIPA removes artifacts or noises more robustly compared to the other tested algorithms for all four problem instances. The percentile-based donor–receiver selection strategy that already proved its efficiency in solving classical benchmark problems also contributes to the performance of the algorithm, and more robust
matrices are obtained.
As stated earlier, if the measurement of the EEG signal is extended to a period of time, a unique problem instance per second will be encountered, and algorithms should generate their solutions within a second to successfully handle the subsequent instance. To decide whether the pIPA and some of its competitors, including IPA and ABC, can produce their solutions within a second or not using the existing test configuration, the average execution times in terms of seconds were calculated and then presented in
Table 17. The pIPA, IPA, and ABC were coded in C programming language. Also, all experiments were carried out on a PC equipped with a single-core
Ghz processor. The results of
Table 17 help to state that neither pIPA nor IPA is capable of filtering EEG instances within a second. Especially for the problem instances with 12 time series, parallelization of the algorithms is seen as a necessity for processing the ongoing measurements.
The comparative studies between meta-heuristics should be supported with the appropriate statistical tests. By considering this requirement, the Wilcoxon signed rank test with the significance level
was used again for determining whether a statistical difference between pIPA and other tested meta-heuristics exists or not. The test results given in
Table 18 represent that the contribution of the newly proposed selection mechanism is enough to generate a statistical difference in favor of pIPA. The results also help to state that pIPA outperforms its competitors in almost all the 30 different runs related to the D4, D4N, D12, and D12N instances when the calculated
values are considered.
4.4. Solving Path Planning Problem with pIPA
The operational success and safety of a UAV or UCAV are directly related to the path or flight route on the battlefield equipped by using sophisticated anti-air weapon systems, radars, missiles, and artilleries [
67]. The path or route determined on the task region for a UAV or UCAV should minimize the probability of being shot down and fuel consumption [
67]. By considering these objectives, Xu et al. proposed a mathematical model describing how a path from the start point
to the target point
can be found optimally [
67]. The model described by Xu et al. first divides the line between
to
equally into
segments using
D different segmentation points. Each segmentation point is intersected vertically by a line, and a set of lines showed as
is generated [
67]. If a point is found on each line in the set
L and then these points are connected one by one, a single path from the start point
to target point
can be described as a set of points showed as
.
The search operations of points in the set
P except the
and
can be further simplified by appropriately transforming the current coordinate system. If the current coordinate system is transformed in a manner that the line between the
and
corresponds to the horizontal axis in the new coordinate system, each point tried to be determined is represented only single parameter [
67]. For transforming the
point of the original coordinate system into the suitable point of the new coordinate system, Equation (
12) is employed [
67]. In Equation (
12),
is the rotation angle between the
x-axis of the original coordinate system and the line between
and
and calculated as
[
67].
When the required points are determined, the suitability of the path generated using these points can be estimated with Equation (
13) [
67]. In Equation (
13),
J corresponds to the sum of costs related to the enemy threats and fuel consumption weighted using the
and
, respectively. Also, while the
represents the cost of enemy threats changing with the length of path abbreviated as
l,
is used on behalf of the cost of fuel consumption changing with the
l [
67].
Even though the equation used for determining the suitability of the path is relatively simple, it can be further purified by replacing the integral calculations with their appropriate approximations [
67]. For this purpose, the
is first taken equal to 1, and the integral calculation about the cost of fuel consumption becomes directly proportional to the length of the path [
67]. Second, the integral calculation about the cost of enemy threats is changed with an approximation in which the cost of threats is determined for each segment of the path. Assume that
is the segment between the segmentation points
i and
j. In addition to this,
is divided equally into ten sub-segments, and the first, third, fifth, seventh, and ninth sub-segmentation points are selected. For the cost of all
threats related to the
, the summation described in Equation (
14) is utilized [
67]. Given that
is the degree of the threat
k, if the segment of length
is within the effect range of the threat
k, the cost of threat
k showed as
for the sub-segmentation point
m is found equal to
where
corresponds to the Euclidean distance between the center of threat
k and sub-segmentation point
m.
For investigating the performance of the pIPA on the path planning problem, the battlefield whose details are given in
Table 19 was used [
58,
59]. The number of segmentation points or
D was taken equal to 5, 10, 15, 20, 25, 30, 35 and 40 [
58,
59]. The value of the
coefficient was determined as
[
58,
59]. The population size of the pIPA and maximum evaluation number were set to 30 and 6000 [
58,
59]. Six different values including 50, 60, 70, 80, 90 and 95 were assigned to the
sequentially. The pIPA was tested 100 times with random seeds for each combination about
D and
. The best, worst, mean best objective function values and standard deviations of 100 runs were recorded and presented in
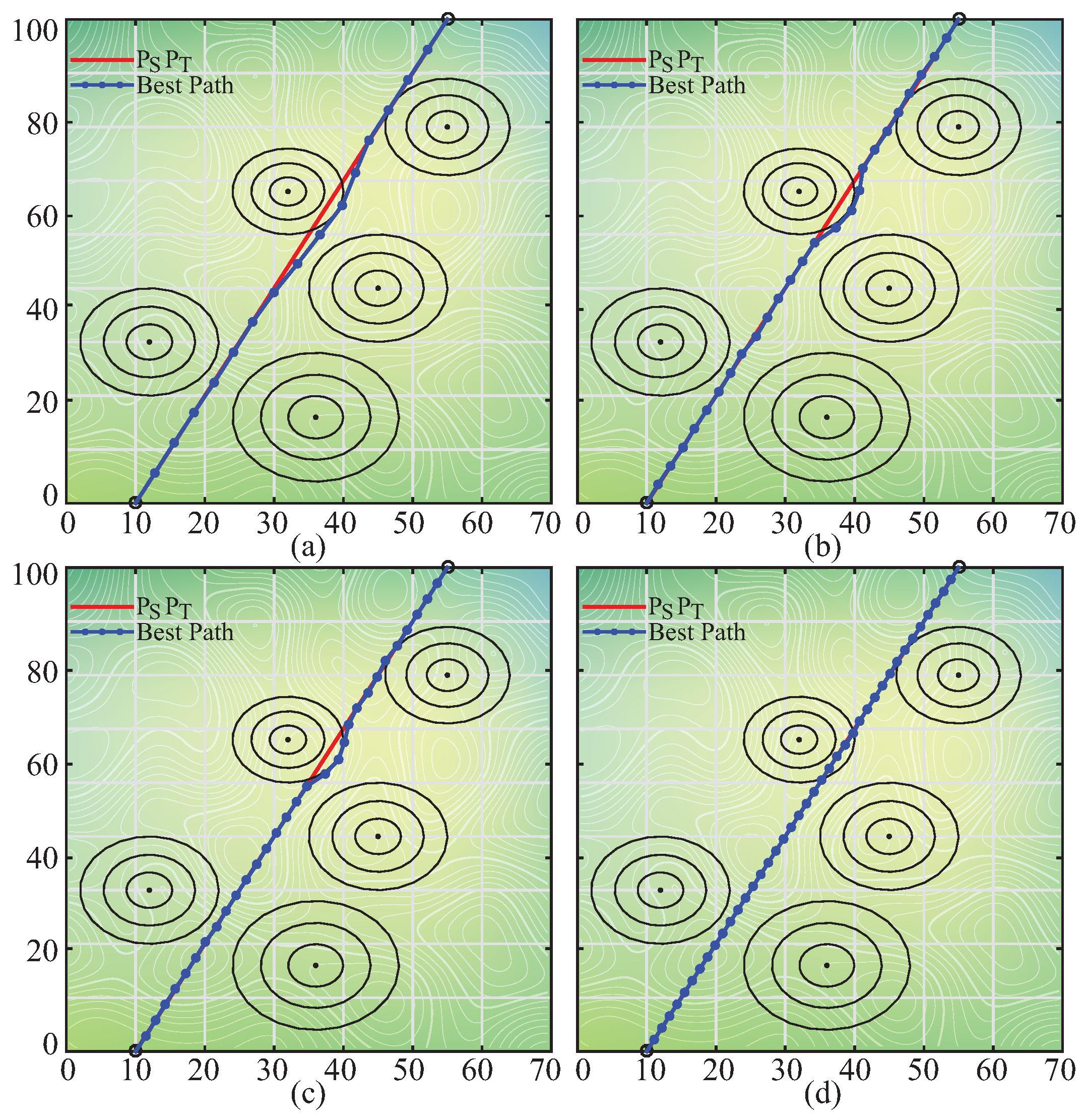
Table 20. The results presented in
Table 20 state that the
value should be chosen between 60 and 70. Although the pIPA obtains more suitable paths for the UCAV on the battlefield with
D equal to 15, 20, 25, 30, and 35 by setting the
to 60, the appropriate value of the
for the remaining battlefield configurations is equal to 70. The best paths found by the pIPA with
set to 60 for different cases can be visualized as in
Figure 4.
The qualities of the paths found by the pIPA should be compared with the qualities of the paths obtained by different meta-heuristics. For this purpose, the best, worst, mean best objective function values and standard deviations found by the pIPA with
equal to 60 were compared to the corresponding results of the IPA [
68] with
and
equal to 1, ABC [
68] with
equal to 100, BA [
58], BAM [
58], ACO [
59], BBO [
59], DE [
59], ES [
59], FA [
60], GA [
59], MFA [
60], PBIL [
59], PSO [
59], SGA [
59] and PGSO [
59]-based UCAV path planners. To guarantee that the results were obtained under the same conditions, the population or colony size of the mentioned algorithms was set to 30. Each algorithm was executed 100 times by taking a maximum evaluation number equal to 6000, and their results were summarized in
Table 21. The results given in
Table 21 showed that the pIPA is the best path planner with the average rank calculated as
among all 16 meta-heuristics when the mean best objective function values are considered. It outperforms other tested algorithms or shares the first rank for the battlefield with
D set to 5, 15, 30, 35, and 40. Moreover, the paths found by the pIPA for the battlefield with
D set to 20 and 25 are in the second rank by considering the mean best objective function values. Even though the path obtained by the pIPA for the battlefield with
D set to 10 lags slightly behind its competitors, it is still in the third rank and produces a better path compared to 13 different algorithms.
The contribution of the percentile-based selection strategy on the convergence performance can be guessed by referencing the paths and their qualities belonging to the pIPA. However, unique properties of the UCAV path planning problem require a further control for
and
metrics. For this purpose, the
and
values of the pIPA, IPA, and ABC were calculated by adjusting the threshold to 55 and given in
Table 22. When the
and
metrics of
Table 22 are investigated, it can be seen that pIPA with
equal to 50 or 60 obtains paths whose qualities are equal to the determined threshold or better for all eight battlefield configurations at each of 100 different runs. Moreover, the pIPA with
set to 70, 80, or 90 still protects its stability and converges more quickly compared to the IPA and ABC for most of the test cases. Although the pIPA with
set to 60 converges
times faster compared to IPA for the battlefield with
D equal to 25, it converges
,
and
times faster compared to IPA for the battlefield with
D equal to 30, 35 and 40.
The comparative studies between pIPA and other techniques for the UCAV path planning problem were concluded by controlling the results of the Wilcoxon signed rank test with the significance level of
. The test results were calculated using the best objective function values and then presented in
Table 23. As easily seen from the test results, the difference between pIPA and IPA, ABC, BA, ACO, BBO, DE, ES, GA, PBIL, PSO, SGA, or PGSO is enough to generate a statistical difference in favor of the pIPA. Only the difference between the pIPA and BAM, FA, or MFA is not enough to state that there is a statistical significance in favor of the pIPA. However, it should be noted that the
value calculated for the comparison between pIPA and BAM or FA is relatively close to
and supplies information about the qualities of the paths found by pIPA.








{kind=link}
{kind=link}
{kind=link}
{kind=link}