
A Reinforcement Learning-Based Bi-Population Nutcracker Optimizer for Global Optimization


Abstract

1. Introduction
- An RL-based bi-population nutcracker optimizer algorithm (RLNOA) is developed to solve complex optimization problems;
- The foraging strategy of the NOA is enhanced using ROBL, improving its ability to search for feasible solutions;
- Q-learning is utilized to control the selection of the most appropriate exploitation strategy for each iteration, dynamically improving the refinement of the optimal solution.
2. Preliminaries
2.1. Nutcracker Optimization Algorithm
2.1.1. Foraging and Storage Strategies
2.1.2. Cache Search and Recovery Strategies
2.2. Reinforcement Learning
3. The Development of the Proposed Algorithm
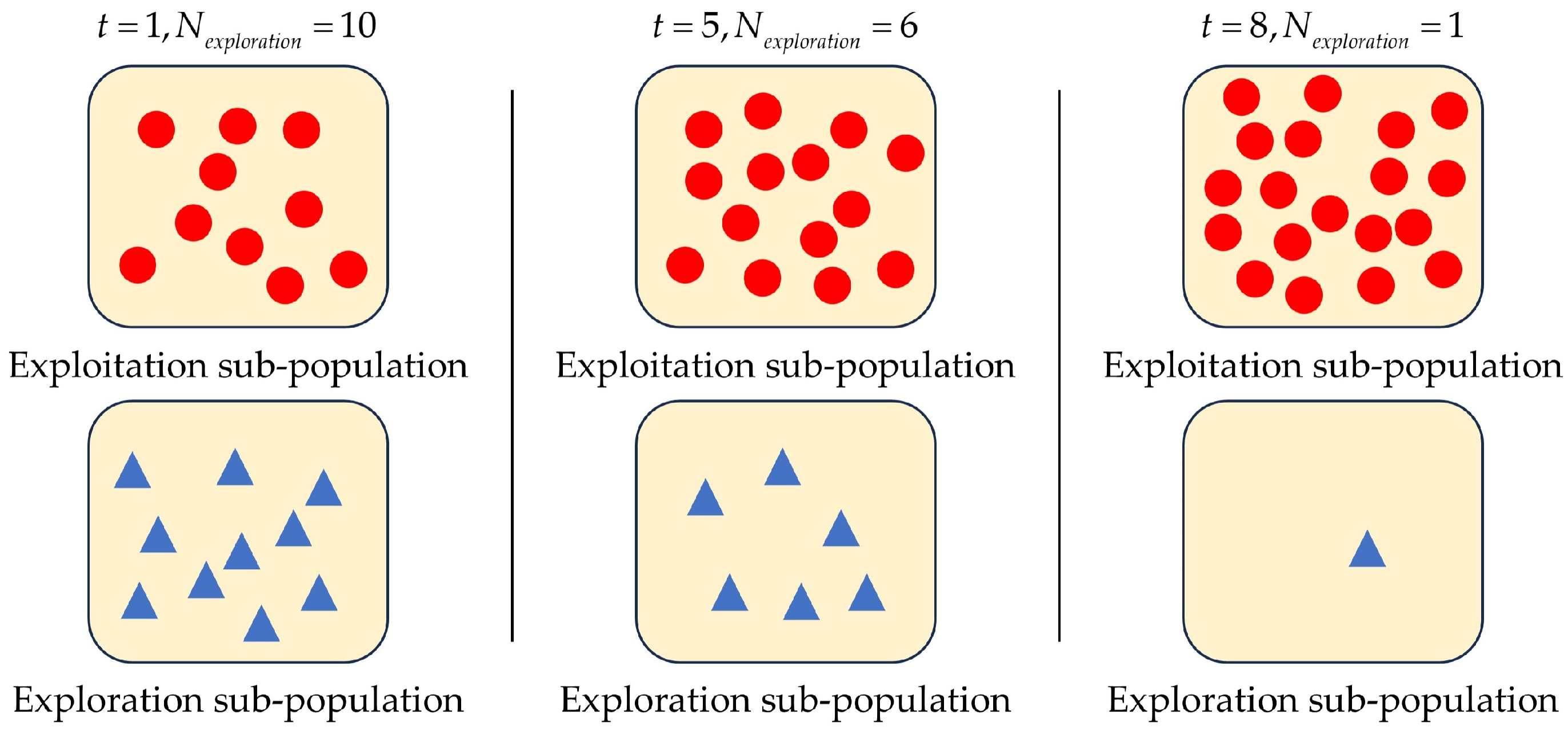
3.1. Overview
| Algorithm 1: The pseudocode of the RLNOA |
| Learning rate Discount factor , , . Set the initial Q-table: Q(s, a) = 0 Set t = 1 While t < Tmax do Acquire sub-population by Equation (19) belong to exploration sub-population by Equation (16) Else Determine the state of the exploitation sub-population by Equations (20) and (21) Choose the best a for the current s from Q-table Switch action Case 1: Storage by Equation (4) Case 2: Recovery by Equation (13) End Switch Set the reward by Equation (25) End if if its fitness is improved End for Calculate the relative changes of fitness and local diversity for the population Update Q-table by the exploitation sub-population t = t + 1 End While Return results Terminate |
3.2. ROBL-Based Foraging Strategy
3.3. Q-Learning-Based Exploitation Behavior
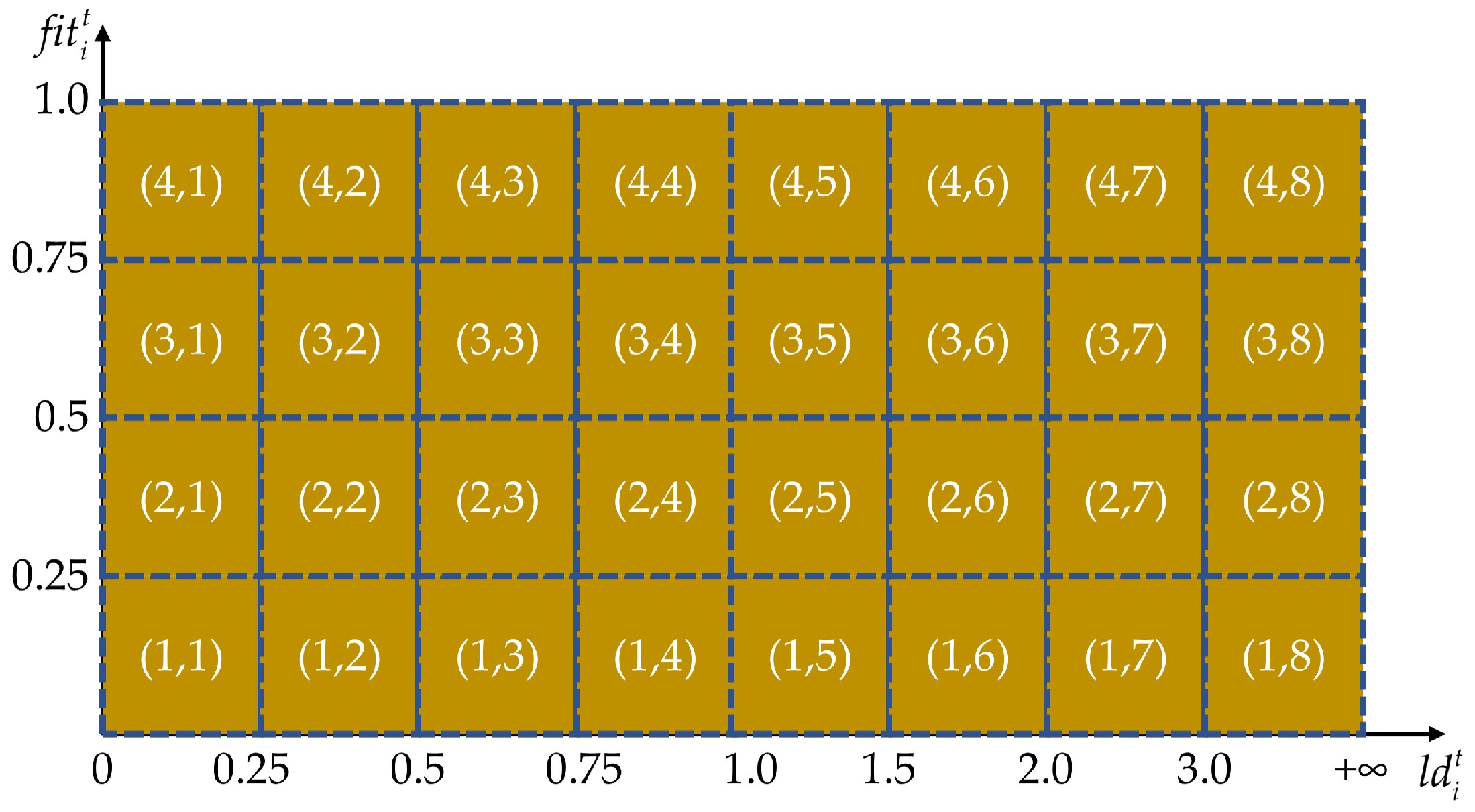
3.3.1. State Encoding
3.3.2. Action Options
3.3.3. Reward Options
3.4. Time Complexity
4. Experimental Results
4.1. Test Conditions
4.2. Comparison over CEC-2014
4.3. Comparison over CEC-2017
4.4. Comparison over CEC-2020
4.5. Analysis of the Q-Table
4.6. Analysis of the RLNOA’s Parameters
- Global exploration threshold : to verify the effect of on the efficiency of the RLNOA, experiments are performed for several values of , taken as 0.2, 0.4, 0.6, and 0.8, while other parameters are unchanged. As shown in Table 5, the RLNOA is insensitive to this parameter. The results of F17 indicate that the RLNOA performs best when is set to a specific value.
- Control parameter : experiments are performed for several values of , taken as 0.05, 0.1, 0.2, and 0.5, while other parameters are unchanged. As shown in Table 6, the RLNOA is not sensitive to small changes in the parameter .
- Control parameter : to explore the sensitivity of the RLNOA to the parameter , experiments are caried out for different values of , as shown in Table 8. It is apparent that the RLNOA is sensitive to . This is primarily because controls the variation trend of the exploration sub-population during the optimization process. Table 8 also shows that the RLNOA acquires the best results when the value of is set to 1.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indices | A, B, and C | Integers randomly selected in the range of [0, NP] | |
| Index of individuals in the population | The lower bound of the optimization problem in the jth dimension | ||
| Index of dimensions | NP | The population size | |
| Index of individuals in the neighborhood set | A probability value | ||
| Index of iteration | A global exploration threshold | ||
| Sets | The maximum iterations | ||
| The population in the iteration | The upper bound of the optimization problem in the jth dimension | ||
| The neighborhood set of | Variables | ||
| Parameters | and | The current and next actions respectively | |
| The learning rate | The relative changes of fitness value | ||
| The discount factor | The relative changes of local diversity | ||
| and | Control parameter | and | The current and next states respectively |
| , , and | A parameter generated by the levy flight | The new position of the ith individual generated in the foraging phase | |
| A parameter chosen in the range of [0, ] | The jth dimension of the ith individual in the iteration | ||
| and | A parameter that linearly decreased from 1 to 0 | The new position of the ith individual generated in the storage phase | |
| A random number selected within the range [0, 1] | The mean position of the jth dimensions for current population in the iteration | ||
| A random number generated based on a normal distribution | The local diversity of individual | ||
| The dimension of the search space | The size of the exploration sub-population | ||
| The number of near neighbors | The corresponding value in the Q-table | ||
| and | Random numbers selected within the range [0, 1] | The reward acquired after performing action | |
| An integer chosen randomly between zero and one |
References
- Hubálovsky, S.; Hubálovská, M.; Matousová, I. A New Hybrid Particle Swarm Optimization-Teaching-Learning-Based Optimization for Solving Optimization Problems. Biomimetics 2024, 9, 8. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.T.; Zhang, S.S.; Zou, G.Y. An Improved Multi-Strategy Crayfish Optimization Algorithm for Solving Numerical Optimization Problems. Biomimetics 2024, 9, 361. [Google Scholar] [CrossRef] [PubMed]
- Pardo, X.C.; González, P.; Banga, J.R.; Doallo, R. Population based metaheuristics in Spark: Towards a general framework using PSO as a case study. Swarm Evol. Comput. 2024, 85, 101483. [Google Scholar] [CrossRef]
- Tatsis, V.A.; Parsopoulos, K.E. Reinforcement learning for enhanced online gradient-based parameter adaptation in metaheuristics. Swarm Evol. Comput. 2023, 83, 101371. [Google Scholar] [CrossRef]
- Wang, Y.; Xiong, G.J.; Xu, S.P.; Suganthan, P.N. Large-scale power system multi-area economic dispatch considering valve point effects with comprehensive learning differential evolution. Swarm Evol. Comput. 2024, 89, 101620. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, H.F.; Tian, Y.Z.; Li, C.W.; Yue, D. Cooperative constrained multi-objective dual-population evolutionary algorithm for optimal dispatching of wind-power integrated power system. Swarm Evol. Comput. 2024, 87, 101525. [Google Scholar] [CrossRef]
- Feng, X.; Pan, A.Q.; Ren, Z.Y.; Hong, J.C.; Fan, Z.P.; Tong, Y.H. An adaptive dual-population based evolutionary algorithm for industrial cut tobacco drying system. Appl. Soft Comput. 2023, 144, 110446. [Google Scholar] [CrossRef]
- Luo, T.; Xie, J.P.; Zhang, B.T.; Zhang, Y.; Li, C.Q.; Zhou, J. An improved levy chaotic particle swarm optimization algorithm for energy-efficient cluster routing scheme in industrial wireless sensor networks. Expert Syst. Appl. 2024, 241, 122780. [Google Scholar] [CrossRef]
- Qu, C.Z.; Gai, W.D.; Zhang, J.; Zhong, M.Y. A novel hybrid grey wolf optimizer algorithm for unmanned aerial vehicle (UAV) path planning. Knowl.-Based Syst. 2020, 194, 105530. [Google Scholar] [CrossRef]
- Qu, C.Z.; Gai, W.D.; Zhong, M.Y.; Zhang, J. A novel reinforcement learning based grey wolf optimizer algorithm for unmanned aerial vehicles (UAVs) path planning. Appl. Soft Comput. 2020, 89, 106099. [Google Scholar] [CrossRef]
- Qu, C.; Zhang, Y.; Ma, F.; Huang, K. Parameter optimization for point clouds denoising based on no-reference quality assessment. Measurement 2023, 211, 112592. [Google Scholar] [CrossRef]
- Chauhan, D.; Yadav, A. An archive-based self-adaptive artificial electric field algorithm with orthogonal initialization for real-parameter optimization problems. Appl. Soft Comput. 2024, 150, 111109. [Google Scholar] [CrossRef]
- Li, G.Q.; Zhang, W.W.; Yue, C.T.; Wang, Y.R. Balancing exploration and exploitation in dynamic constrained multimodal multi-objective co-evolutionary algorithm. Swarm Evol. Comput. 2024, 89, 101652. [Google Scholar] [CrossRef]
- Ahadzadeh, B.; Abdar, M.; Safara, F.; Khosravi, A.; Menhaj, M.B.; Suganthan, P.N. SFE: A Simple, Fast, and Efficient Feature Selection Algorithm for High-Dimensional Data. IEEE Trans. Evol. Comput. 2023, 27, 1896–1911. [Google Scholar] [CrossRef]
- Fu, S.; Huang, H.; Ma, C.; Wei, J.; Li, Y.; Fu, Y. Improved dwarf mongoose optimization algorithm using novel nonlinear control and exploration strategies. Expert Syst. Appl. 2023, 233, 120904. [Google Scholar] [CrossRef]
- Li, J.; Li, G.; Wang, Z.; Cui, L. Differential evolution with an adaptive penalty coefficient mechanism and a search history exploitation mechanism. Expert Syst. Appl. 2023, 230, 120530. [Google Scholar] [CrossRef]
- Hu, C.; Zeng, S.; Li, C. A framework of global exploration and local exploitation using surrogates for expensive optimization. Knowl.-Based Syst. 2023, 280, 111018. [Google Scholar] [CrossRef]
- Chang, D.; Rao, C.; Xiao, X.; Hu, F.; Goh, M. Multiple strategies based Grey Wolf Optimizer for feature selection in performance evaluation of open-ended funds. Swarm Evol. Comput. 2024, 86, 101518. [Google Scholar] [CrossRef]
- Hashim, F.A.; Hussien, A.G. Snake Optimizer: A novel meta-heuristic optimization algorithm. Knowl.-Based Syst. 2022, 242, 108320. [Google Scholar] [CrossRef]
- Braik, M.; Hammouri, A.; Atwan, J.; Al-Betar, M.A.A.; Awadallah, M.A. White Shark Optimizer: A novel bio-inspired meta-heuristic algorithm for global optimization problems. Knowl.-Based Syst. 2022, 243, 108457. [Google Scholar] [CrossRef]
- Kumar, S.; Sharma, N.K.; Kumar, N. WSOmark: An adaptive dual-purpose color image watermarking using white shark optimizer and Levenberg-Marquardt BPNN. Expert Syst. Appl. 2023, 226, 120137. [Google Scholar] [CrossRef]
- Abualigah, L.; Abd Elaziz, M.; Sumari, P.; Geem, Z.W.; Gandomi, A.H. Reptile Search Algorithm (RSA): A nature-inspired meta-heuristic optimizer. Expert Syst. Appl. 2022, 191, 116158. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Abouhawwash, M. Crested Porcupine Optimizer: A new nature-inspired metaheuristic. Knowl.-Based Syst. 2024, 284, 111257. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Jameel, M.; Abouhawwash, M. Nutcracker optimizer: A novel nature-inspired metaheuristic algorithm for global optimization and engineering design problems. Knowl.-Based Syst. 2023, 262, 110248. [Google Scholar] [CrossRef]
- Qaraad, M.; Amjad, S.; Hussein, N.K.; Farag, M.A.; Mirjalili, S.; Elhosseini, M.A. Quadratic interpolation and a new local search approach to improve particle swarm optimization: Solar photovoltaic parameter estimation. Expert Syst. Appl. 2024, 236, 121417. [Google Scholar] [CrossRef]
- Ahmed, R.; Rangaiah, G.P.; Mahadzir, S.; Mirjalili, S.; Hassan, M.H.; Kamel, S. Memory, evolutionary operator, and local search based improved Grey Wolf Optimizer with linear population size reduction technique. Knowl.-Based Syst. 2023, 264, 110297. [Google Scholar] [CrossRef]
- Khosravi, H.; Amiri, B.; Yazdanjue, N.; Babaiyan, V. An improved group teaching optimization algorithm based on local search and chaotic map for feature selection in high-dimensional data. Expert Syst. Appl. 2022, 204, 117493. [Google Scholar] [CrossRef]
- Ekinci, S.; Izci, D.; Abualigah, L.; Abu Zitar, R. A Modified Oppositional Chaotic Local Search Strategy Based Aquila Optimizer to Design an Effective Controller for Vehicle Cruise Control System. J. Bionic Eng. 2023, 20, 1828–1851. [Google Scholar] [CrossRef]
- Xiao, J.; Wang, Y.J.; Xu, X.K. Fuzzy Community Detection Based on Elite Symbiotic Organisms Search and Node Neighborhood Information. IEEE Trans. Fuzzy Syst. 2022, 30, 2500–2514. [Google Scholar] [CrossRef]
- Zhu, Q.L.; Lin, Q.Z.; Li, J.Q.; Coello, C.A.C.; Ming, Z.; Chen, J.Y.; Zhang, J. An Elite Gene Guided Reproduction Operator for Many-Objective Optimization. IEEE Trans. Cybern. 2021, 51, 765–778. [Google Scholar] [CrossRef]
- Zhang, Y.Y. Elite archives-driven particle swarm optimization for large scale numerical optimization and its engineering applications. Swarm Evol. Comput. 2023, 76, 101212. [Google Scholar] [CrossRef]
- Zhong, X.X.; Cheng, P. An elite-guided hierarchical differential evolution algorithm. Appl. Intell. 2021, 51, 4962–4983. [Google Scholar] [CrossRef]
- Zhou, L.; Feng, L.; Gupta, A.; Ong, Y.S. Learnable Evolutionary Search Across Heterogeneous Problems via Kernelized Autoencoding. IEEE Trans. Evol. Comput. 2021, 25, 567–581. [Google Scholar] [CrossRef]
- Feng, L.; Zhou, W.; Liu, W.C.; Ong, Y.S.; Tan, K.C. Solving Dynamic Multiobjective Problem via Autoencoding Evolutionary Search. IEEE Trans. Cybern. 2022, 52, 2649–2662. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Wang, Z.J.; Jin, H.; Zhang, J. Adaptive Distributed Differential Evolution. IEEE Trans. Cybern. 2020, 50, 4633–4647. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Li, J.Y.; Kwong, S.; Zhang, J. Learning-Aided Evolution for Optimization. IEEE Trans. Evol. Comput. 2023, 27, 1794–1808. [Google Scholar] [CrossRef]
- Zabihi, Z.; Moghadam, A.M.E.; Rezvani, M.H. Reinforcement Learning Methods for Computation Offloading: A Systematic Review. Acm Comput. Surv. 2024, 56, 1–41. [Google Scholar] [CrossRef]
- Wang, D.; Gao, N.; Liu, D.; Li, J.; Lewis, F.L. Recent Progress in Reinforcement Learning and Adaptive Dynamic Programming for Advanced Control Applications. IEEE-CAA J. Autom. Sin. 2024, 11, 18–36. [Google Scholar] [CrossRef]
- Zhao, F.; Wang, Q.; Wang, L. An inverse reinforcement learning framework with the Q-learning mechanism for the metaheuristic algorithm. Knowl.-Based Syst. 2023, 265, 110368. [Google Scholar] [CrossRef]
- Ghetas, M.; Issa, M. A novel reinforcement learning-based reptile search algorithm for solving optimization problems. Neural Comput. Appl. 2023, 36, 533–568. [Google Scholar] [CrossRef]
- Li, Z.; Shi, L.; Yue, C.; Shang, Z.; Qu, B. Differential evolution based on reinforcement learning with fitness ranking for solving multimodal multiobjective problems. Swarm Evol. Comput. 2019, 49, 234–244. [Google Scholar] [CrossRef]
- Tan, Z.; Li, K. Differential evolution with mixed mutation strategy based on deep reinforcement learning. Appl. Soft Comput. 2021, 111, 107678. [Google Scholar] [CrossRef]
- Wu, D.; Wang, S.; Liu, Q.; Abualigah, L.; Jia, H. An Improved Teaching-Learning-Based Optimization Algorithm with Reinforcement Learning Strategy for Solving Optimization Problems. Comput. Intell. Neurosci. 2022, 2022, 1535957. [Google Scholar] [CrossRef] [PubMed]
- Samma, H.; Lim, C.P.; Saleh, J.M. A new Reinforcement Learning-Based Memetic Particle Swarm Optimizer. Appl. Soft Comput. 2016, 43, 276–297. [Google Scholar] [CrossRef]
- Hu, Z.P.; Yu, X.B. Reinforcement learning-based comprehensive learning grey wolf optimizer for feature selection. Appl. Soft Comput. 2023, 149, 110959. [Google Scholar] [CrossRef]
- Li, J.; Dong, H.; Wang, P.; Shen, J.; Qin, D. Multi-objective constrained black-box optimization algorithm based on feasible region localization and performance-improvement exploration. Appl. Soft Comput. 2023, 148, 110874. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, S.; Li, G.; Zhang, Q. Multiobjective Combinatorial Optimization Using a Single Deep Reinforcement Learning Model. IEEE Trans. Cybern. 2024, 54, 1984–1996. [Google Scholar] [CrossRef]
- Huang, L.; Dong, B.; Xie, W.; Zhang, W. Offline Reinforcement Learning with Behavior Value Regularization. IEEE Trans. Cybern. 2024, 54, 3692–3704. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Jameel, M.; Abouhawwash, M. Exponential distribution optimizer (EDO): A novel math-inspired algorithm for global optimization and engineering problems. Artif. Intell. Rev. 2023, 56, 9329–9400. [Google Scholar] [CrossRef]







| Algorithm | Specifications | Population Size NP |
|---|---|---|
| RLNOA | 100 | |
| NOA | 100 | |
| SO | 100 | |
| RSA | 100 | |
| CPO | 100 | |
| GWO | Convergence constant decreases linearly from 2 to 0 | 100 |
| PSO | 100 | |
| RLTLBO | 33 because this algorithm has three main stages | |
| RLMPSO | is set as 0.2 of search range | 100 |
| RLCGWO | 100 |
| Fun | Metrics | RLNOA | NOA | SO | RSA | CPO | GWO | PSO | RLTLBO | RLMPSO | RLCGWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Ave | 1.00 × 102 | 1.04 × 102 | 3.86 × 107 | 1.02 × 108 | 1.64 × 102 | 4.57 × 106 | 1.24 × 104 | 2.39 × 104 | 3.28 × 105 | 1.86 × 107 |
| Std | 4.65 × 10−3 | 2.55 × 100 | 2.05 × 107 | 4.09 × 107 | 4.73 × 101 | 3.34 × 106 | 1.33 × 104 | 3.63 × 104 | 2.44 × 105 | 1.79 × 107 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 4 | 5 | 6 | 8 | |
| F2 | Ave | 2.00 × 102 | 2.00 × 102 | 2.16 × 109 | 5.89 × 109 | 2.00 × 102 | 6.15 × 103 | 1.10 × 103 | 5.83 × 102 | 2.04 × 103 | 2.60 × 109 |
| Std | 2.61 × 10−6 | 1.15 × 10−3 | 9.40 × 108 | 1.50 × 109 | 1.03 × 10−5 | 4.49 × 103 | 1.17 × 103 | 6.06 × 102 | 2.90 × 103 | 1.26 × 109 | |
| Rank | 1 | 3 | 8 | 10 | 2 | 7 | 5 | 4 | 6 | 9 | |
| F3 | Ave | 3.00 × 102 | 3.00 × 102 | 1.54 × 104 | 8.05 × 103 | 3.00 × 102 | 4.01 × 103 | 3.39 × 102 | 3.89 × 102 | 4.27 × 103 | 4.97 × 104 |
| Std | 1.52 × 10−8 | 1.60 × 10−6 | 4.95 × 103 | 3.32 × 103 | 1.12 × 10−8 | 3.55 × 103 | 6.59 × 101 | 1.18 × 102 | 1.70 × 103 | 2.18 × 104 | |
| Rank | 2 | 3 | 9 | 8 | 1 | 6 | 4 | 5 | 7 | 10 | |
| F4 | Ave | 4.00 × 102 | 4.05 × 102 | 8.49 × 102 | 1.37 × 103 | 4.09 × 102 | 4.29 × 102 | 4.28 × 102 | 4.16 × 102 | 4.31 × 102 | 5.15 × 102 |
| Std | 3.68 × 10−3 | 1.14 × 101 | 2.81 × 102 | 6.97 × 102 | 1.51 × 101 | 1.17 × 101 | 1.34 × 101 | 1.63 × 101 | 8.74 × 100 | 5.83 × 101 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 6 | 5 | 4 | 7 | 8 | |
| F5 | Ave | 5.13 × 102 | 5.18 × 102 | 5.21 × 102 | 5.20 × 102 | 5.17 × 102 | 5.20 × 102 | 5.20 × 102 | 5.20 × 102 | 5.19 × 102 | 5.20 × 102 |
| Std | 8.38 × 100 | 6.18 × 100 | 1.16 × 10−1 | 8.23 × 10−2 | 7.38 × 100 | 5.93 × 10−2 | 1.06 × 10−3 | 6.58 × 10−2 | 4.55 × 100 | 1.13 × 10−1 | |
| Rank | 1 | 3 | 10 | 9 | 2 | 7 | 5 | 8 | 4 | 6 | |
| F6 | Ave | 6.00 × 102 | 6.00 × 102 | 6.10 × 102 | 6.09 × 102 | 6.00 × 102 | 6.01 × 102 | 6.02 × 102 | 6.02 × 102 | 6.03 × 102 | 6.09 × 102 |
| Std | 6.70 × 10−6 | 1.89 × 10−2 | 6.27 × 10−1 | 1.09 × 100 | 4.34 × 10−2 | 6.05 × 10−1 | 1.47 × 100 | 9.28 × 10−1 | 1.34 × 100 | 1.19 × 100 | |
| Rank | 1 | 3 | 10 | 9 | 2 | 4 | 5 | 6 | 7 | 8 | |
| F7 | Ave | 7.00 × 102 | 7.00 × 102 | 7.48 × 102 | 7.79 × 102 | 7.00 × 102 | 7.01 × 102 | 7.00 × 102 | 7.00 × 102 | 7.00 × 102 | 7.23 × 102 |
| Std | 8.66 × 10−3 | 2.32 × 10−2 | 1.69 × 101 | 2.48 × 101 | 3.57 × 10−2 | 1.03 × 100 | 7.46 × 10−2 | 8.26 × 10−2 | 8.76 × 10−2 | 7.51 × 100 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 4 | 5 | 6 | 8 | |
| F8 | Ave | 8.00 × 102 | 8.00 × 102 | 8.58 × 102 | 8.69 × 102 | 8.00 × 102 | 8.07 × 102 | 8.15 × 102 | 8.11 × 102 | 8.16 × 102 | 8.60 × 102 |
| Std | 0.00 × 100 | 3.58 × 10−13 | 1.10 × 101 | 9.38 × 100 | 2.83 × 10−10 | 3.19 × 100 | 7.35 × 100 | 6.43 × 100 | 6.83 × 100 | 9.87 × 100 | |
| Rank | 1 | 2 | 8 | 10 | 3 | 4 | 6 | 5 | 7 | 9 | |
| F9 | Ave | 9.02 × 102 | 9.04 × 102 | 9.61 × 102 | 9.58 × 102 | 9.12 × 102 | 9.11 × 102 | 9.15 × 102 | 9.22 × 102 | 9.21 × 102 | 9.59 × 102 |
| Std | 6.20 × 10−1 | 1.14 × 100 | 1.27 × 101 | 5.78 × 100 | 2.46 × 100 | 4.78 × 100 | 7.19 × 100 | 1.26 × 101 | 7.73 × 100 | 8.83 × 100 | |
| Rank | 1 | 2 | 10 | 8 | 4 | 3 | 5 | 7 | 6 | 9 | |
| F10 | Ave | 1.00 × 103 | 1.00 × 103 | 2.51 × 103 | 1.97 × 103 | 1.01 × 103 | 1.30 × 103 | 1.35 × 103 | 1.52 × 103 | 1.29 × 103 | 2.01 × 103 |
| Std | 5.16 × 10−2 | 9.51 × 10−1 | 2.37 × 102 | 2.07 × 102 | 3.48 × 100 | 2.15 × 102 | 1.25 × 102 | 1.93 × 102 | 1.88 × 102 | 2.48 × 102 | |
| Rank | 1 | 2 | 10 | 8 | 3 | 5 | 6 | 7 | 4 | 9 | |
| F11 | Ave | 1.22 × 103 | 1.56 × 103 | 3.18 × 103 | 2.43 × 103 | 2.16 × 103 | 1.72 × 103 | 1.80 × 103 | 1.73 × 103 | 2.70 × 103 | 4.04 × 103 |
| Std | 4.64 × 101 | 1.65 × 102 | 2.95 × 102 | 1.80 × 102 | 1.26 × 102 | 3.94 × 102 | 2.84 × 102 | 2.64 × 102 | 1.41 × 102 | 4.54 × 102 | |
| Rank | 1 | 2 | 9 | 7 | 6 | 3 | 5 | 4 | 8 | 10 | |
| F12 | Ave | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 | 1.20 × 103 |
| Std | 1.74 × 10−2 | 5.36 × 10−2 | 4.70 × 10−1 | 2.00 × 10−1 | 6.69 × 10−2 | 4.50 × 10−1 | 1.23 × 10−1 | 3.44 × 10−1 | 1.55 × 10−1 | 3.60 × 10−1 | |
| Rank | 1 | 3 | 10 | 9 | 5 | 4 | 2 | 7 | 8 | 6 | |
| F13 | Ave | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 | 1.30 × 103 |
| Std | 8.47 × 10−3 | 1.91 × 10−2 | 6.58 × 10−1 | 8.19 × 10−1 | 2.70 × 10−2 | 6.50 × 10−2 | 7.76 × 10−2 | 8.02 × 10−2 | 5.51 × 10−2 | 2.29 × 10−1 | |
| Rank | 1 | 2 | 9 | 10 | 5 | 4 | 3 | 6 | 7 | 8 | |
| F14 | Ave | 1.40 × 103 | 1.40 × 103 | 1.41 × 103 | 1.41 × 103 | 1.40 × 103 | 1.40 × 103 | 1.40 × 103 | 1.40 × 103 | 1.40 × 103 | 1.40 × 103 |
| Std | 1.29 × 10−2 | 3.13 × 10−2 | 5.57 × 100 | 3.50 × 100 | 3.96 × 10−2 | 1.66 × 10−1 | 5.65 × 10−2 | 1.02 × 10−1 | 4.79 × 10−2 | 1.93 × 100 | |
| Rank | 1 | 2 | 10 | 9 | 4 | 5 | 3 | 7 | 6 | 8 | |
| F15 | Ave | 1.50 × 103 | 1.50 × 103 | 2.77 × 103 | 2.68 × 103 | 1.50 × 103 | 1.50 × 103 | 1.50 × 103 | 1.50 × 103 | 1.50 × 103 | 2.14 × 103 |
| Std | 8.24 × 10−2 | 1.35 × 10−1 | 1.83 × 103 | 1.25 × 103 | 2.30 × 10−1 | 6.79 × 10−1 | 3.66 × 10−1 | 4.93 × 10−1 | 9.82 × 10−1 | 9.17 × 102 | |
| Rank | 1 | 2 | 10 | 9 | 5 | 4 | 3 | 6 | 7 | 8 | |
| F16 | Ave | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 | 1.60 × 103 |
| Std | 2.10 × 10−1 | 2.95 × 10−1 | 1.86 × 10−1 | 1.87 × 10−1 | 2.46 × 10−1 | 4.42 × 10−1 | 5.19 × 10−1 | 3.45 × 10−1 | 4.04 × 10−1 | 2.30 × 10−1 | |
| Rank | 1 | 2 | 10 | 9 | 4 | 3 | 6 | 5 | 7 | 8 | |
| F17 | Ave | 1.71 × 103 | 1.73 × 103 | 2.74 × 105 | 4.34 × 105 | 1.79 × 103 | 4.06 × 104 | 4.15 × 103 | 2.57 × 103 | 7.96 × 103 | 4.44 × 105 |
| Std | 2.72 × 100 | 1.17 × 101 | 2.38 × 105 | 1.39 × 105 | 2.59 × 101 | 1.04 × 105 | 2.11 × 103 | 6.71 × 102 | 3.88 × 103 | 8.66 × 105 | |
| Rank | 1 | 2 | 8 | 9 | 3 | 7 | 5 | 4 | 6 | 10 | |
| F18 | Ave | 1.80 × 103 | 1.80 × 103 | 1.95 × 105 | 8.88 × 104 | 1.80 × 103 | 9.13 × 103 | 1.25 × 104 | 4.15 × 103 | 9.55 × 103 | 3.19 × 104 |
| Std | 1.66 × 10−1 | 5.94 × 10−1 | 3.26 × 105 | 1.83 × 105 | 7.55 × 10−1 | 6.34 × 103 | 7.24 × 103 | 1.78 × 103 | 6.03 × 103 | 3.89 × 104 | |
| Rank | 1 | 2 | 10 | 9 | 3 | 5 | 7 | 4 | 6 | 8 | |
| F19 | Ave | 1.90 × 103 | 1.90 × 103 | 1.91 × 103 | 1.91 × 103 | 1.90 × 103 | 1.90 × 103 | 1.90 × 103 | 1.90 × 103 | 1.90 × 103 | 1.91 × 103 |
| Std | 5.49 × 10−2 | 1.78 × 10−1 | 4.63 × 100 | 2.64 × 100 | 1.98 × 10−1 | 7.61 × 10−1 | 1.02 × 100 | 5.08 × 10−1 | 1.15 × 100 | 7.90 × 10−1 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 5 | 6 | 4 | 7 | 8 | |
| F20 | Ave | 2.00 × 103 | 2.00 × 103 | 1.22 × 104 | 1.05 × 104 | 2.00 × 103 | 4.80 × 103 | 2.67 × 103 | 2.11 × 103 | 2.34 × 103 | 1.62 × 104 |
| Std | 4.59 × 10−2 | 1.65 × 10−1 | 7.65 × 103 | 3.22 × 103 | 3.20 × 10−1 | 3.80 × 103 | 8.27 × 102 | 3.41 × 101 | 5.31 × 102 | 1.26 × 104 | |
| Rank | 1 | 2 | 9 | 8 | 3 | 7 | 6 | 4 | 5 | 10 | |
| F21 | Ave | 2.10 × 103 | 2.10 × 103 | 1.02 × 105 | 2.04 × 105 | 2.11 × 103 | 8.61 × 103 | 2.27 × 103 | 2.26 × 103 | 6.38 × 103 | 1.21 × 104 |
| Std | 1.49 × 10−1 | 5.73 × 10−1 | 1.72 × 105 | 1.76 × 105 | 1.96 × 100 | 4.53 × 103 | 1.29 × 102 | 9.87 × 101 | 4.71 × 103 | 1.13 × 104 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F22 | Ave | 2.20 × 103 | 2.20 × 103 | 2.39 × 103 | 2.35 × 103 | 2.21 × 103 | 2.28 × 103 | 2.29 × 103 | 2.23 × 103 | 2.28 × 103 | 2.29 × 103 |
| Std | 6.58 × 10−2 | 6.00 × 10−1 | 8.30 × 101 | 4.06 × 101 | 1.22 × 100 | 5.28 × 101 | 6.40 × 101 | 2.86 × 101 | 5.90 × 101 | 3.40 × 101 | |
| Rank | 1 | 2 | 10 | 9 | 3 | 6 | 7 | 4 | 5 | 8 | |
| F23 | Ave | 2.50 × 103 | 2.50 × 103 | 2.67 × 103 | 2.50 × 103 | 2.50 × 103 | 2.63 × 103 | 2.63 × 103 | 2.50 × 103 | 2.63 × 103 | 2.69 × 103 |
| Std | 0.00 × 100 | 0.00 × 100 | 2.48 × 101 | 0.00 × 100 | 0.00 × 100 | 3.56 × 100 | 2.95 × 10−13 | 0.00 × 100 | 2.77 × 10−7 | 1.17 × 101 | |
| Rank | 1 | 2 | 9 | 3 | 4 | 8 | 6 | 5 | 7 | 10 | |
| F24 | Ave | 2.50 × 103 | 2.50 × 103 | 2.59 × 103 | 2.60 × 103 | 2.52 × 103 | 2.52 × 103 | 2.52 × 103 | 2.59 × 103 | 2.53 × 103 | 2.58 × 103 |
| Std | 2.76 × 100 | 3.85 × 100 | 1.62 × 101 | 8.64 × 100 | 2.98 × 100 | 5.84 × 100 | 8.79 × 100 | 2.88 × 101 | 9.68 × 100 | 1.37 × 101 | |
| Rank | 1 | 2 | 8 | 10 | 4 | 3 | 5 | 9 | 6 | 7 | |
| F25 | Ave | 2.61 × 103 | 2.62 × 103 | 2.70 × 103 | 2.70 × 103 | 2.64 × 103 | 2.70 × 103 | 2.68 × 103 | 2.70 × 103 | 2.64 × 103 | 2.70 × 103 |
| Std | 3.29 × 100 | 3.40 × 100 | 7.49 × 100 | 1.10 × 10−2 | 2.25 × 101 | 1.46 × 101 | 2.73 × 101 | 0.00 × 100 | 1.74 × 101 | 7.56 × 100 | |
| Rank | 1 | 2 | 6 | 8 | 3 | 7 | 5 | 9 | 4 | 10 | |
| F26 | Ave | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 | 2.70 × 103 |
| Std | 9.37 × 10−3 | 1.53 × 10−2 | 5.68 × 10−1 | 5.20 × 10−1 | 2.72 × 10−2 | 3.39 × 10−2 | 6.53 × 10−2 | 7.06 × 10−2 | 4.19 × 10−2 | 1.82 × 10−1 | |
| Rank | 1 | 2 | 9 | 10 | 6 | 3 | 4 | 5 | 7 | 8 | |
| F27 | Ave | 2.70 × 103 | 2.70 × 103 | 3.04 × 103 | 2.96 × 103 | 2.72 × 103 | 3.05 × 103 | 2.99 × 103 | 2.81 × 103 | 2.97 × 103 | 3.14 × 103 |
| Std | 2.19 × 10−1 | 3.35 × 10−1 | 1.44 × 102 | 1.33 × 102 | 8.89 × 101 | 3.79 × 101 | 1.27 × 102 | 1.01 × 102 | 1.73 × 102 | 1.29 × 102 | |
| Rank | 1 | 2 | 8 | 5 | 3 | 9 | 7 | 4 | 6 | 10 | |
| F28 | Ave | 3.00 × 103 | 3.00 × 103 | 3.19 × 103 | 3.27 × 103 | 3.04 × 103 | 3.26 × 103 | 3.31 × 103 | 3.00 × 103 | 3.19 × 103 | 3.26 × 103 |
| Std | 0.00 × 100 | 0.00 × 100 | 2.19 × 102 | 1.40 × 102 | 8.85 × 101 | 8.53 × 101 | 7.12 × 101 | 0.00 × 100 | 1.08 × 102 | 5.94 × 101 | |
| Rank | 1 | 2 | 5 | 9 | 4 | 7 | 10 | 3 | 6 | 8 | |
| F29 | Ave | 3.05 × 103 | 3.10 × 103 | 1.14 × 105 | 4.50 × 104 | 3.12 × 103 | 3.68 × 103 | 3.24 × 103 | 3.15 × 103 | 1.98 × 105 | 4.18 × 105 |
| Std | 6.18 × 100 | 1.85 × 101 | 1.75 × 105 | 1.10 × 105 | 1.22 × 101 | 5.20 × 102 | 9.86 × 101 | 1.56 × 102 | 5.98 × 105 | 8.48 × 105 | |
| Rank | 1 | 2 | 8 | 7 | 3 | 6 | 5 | 4 | 9 | 10 | |
| F30 | Ave | 3.45 × 103 | 3.49 × 103 | 8.35 × 103 | 7.21 × 103 | 3.64 × 103 | 4.10 × 103 | 4.74 × 103 | 3.37 × 103 | 4.34 × 103 | 3.92 × 103 |
| Std | 4.79 × 101 | 1.63 × 101 | 3.30 × 103 | 2.05 × 103 | 3.27 × 101 | 7.90 × 102 | 4.97 × 102 | 2.72 × 102 | 7.15 × 102 | 2.90 × 102 | |
| Rank | 2 | 3 | 10 | 9 | 4 | 6 | 8 | 1 | 7 | 5 | |
| Mean | Ranking | 1.0345 | 2.1724 | 8.8966 | 8.6897 | 3.4483 | 5.4828 | 5.1379 | 5.3103 | 6.3103 | 8.5172 |
| Final | Rank | 1 | 2 | 10 | 9 | 3 | 6 | 4 | 5 | 7 | 8 |
| Fun | Metrics | RLNOA | NOA | SO | RSA | CPO | GWO | PSO | RLTLBO | RLMPSO | RLCGWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Ave | 1.00 × 102 | 1.00 × 102 | 3.65 × 109 | 9.70 × 109 | 1.00 × 102 | 1.30 × 106 | 1.25 × 103 | 2.12 × 103 | 3.10 × 103 | 1.95 × 109 |
| Std | 8.32 × 10−5 | 1.59 × 10−2 | 1.44 × 109 | 2.68 × 109 | 3.70 × 10−4 | 4.96 × 106 | 2.07 × 103 | 2.45 × 103 | 3.34 × 103 | 6.61 × 108 | |
| Rank | 1 | 3 | 9 | 10 | 2 | 7 | 4 | 5 | 6 | 8 | |
| F3 | Ave | 3.00 × 102 | 3.00 × 102 | 1.14 × 104 | 7.33 × 103 | 3.00 × 102 | 7.61 × 102 | 3.00 × 102 | 3.00 × 102 | 7.22 × 102 | 1.42 × 104 |
| Std | 1.32 × 10−11 | 5.52 × 10−8 | 3.10 × 103 | 2.01 × 103 | 9.79 × 10−7 | 8.18 × 102 | 4.12 × 10−14 | 3.04 × 10−9 | 1.65 × 102 | 6.44 × 103 | |
| Rank | 2 | 4 | 9 | 8 | 5 | 7 | 1 | 3 | 6 | 10 | |
| F4 | Ave | 4.00 × 102 | 4.00 × 102 | 6.44 × 102 | 9.52 × 102 | 4.01 × 102 | 4.08 × 102 | 4.01 × 102 | 4.07 × 102 | 4.08 × 102 | 5.30 × 102 |
| Std | 8.57 × 10−6 | 7.44 × 10−3 | 1.22 × 102 | 4.15 × 102 | 4.06 × 10−1 | 2.34 × 100 | 7.61 × 10−1 | 1.46 × 101 | 1.36 × 101 | 8.14 × 101 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 6 | 4 | 5 | 7 | 8 | |
| F5 | Ave | 5.03 × 102 | 5.04 × 102 | 5.70 × 102 | 5.78 × 102 | 5.12 × 102 | 5.14 × 102 | 5.17 × 102 | 5.16 × 102 | 5.22 × 102 | 5.61 × 102 |
| Std | 7.16 × 10−1 | 1.42 × 100 | 1.13 × 101 | 1.38 × 101 | 1.70 × 100 | 8.36 × 100 | 6.65 × 100 | 7.73 × 100 | 8.66 × 100 | 1.07 × 101 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 4 | 6 | 5 | 7 | 8 | |
| F6 | Ave | 6.00 × 102 | 6.00 × 102 | 6.36 × 102 | 6.45 × 102 | 6.00 × 102 | 6.00 × 102 | 6.01 × 102 | 6.00 × 102 | 6.05 × 102 | 6.30 × 102 |
| Std | 4.16 × 10−12 | 4.59 × 10−8 | 9.52 × 100 | 7.07 × 100 | 1.04 × 10−6 | 5.11 × 10−1 | 7.29 × 10−1 | 7.53 × 10−1 | 3.59 × 100 | 7.44 × 100 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 5 | 6 | 4 | 7 | 8 | |
| F7 | Ave | 7.14 × 102 | 7.15 × 102 | 8.16 × 102 | 8.01 × 102 | 7.23 × 102 | 7.26 × 102 | 7.21 × 102 | 7.31 × 102 | 7.44 × 102 | 8.58 × 102 |
| Std | 6.13 × 10−1 | 1.58 × 100 | 1.82 × 101 | 1.26 × 101 | 2.83 × 100 | 9.37 × 100 | 6.15 × 100 | 9.14 × 100 | 1.08 × 101 | 4.68 × 101 | |
| Rank | 1 | 2 | 9 | 8 | 4 | 5 | 3 | 6 | 7 | 10 | |
| F8 | Ave | 8.02 × 102 | 8.04 × 102 | 8.58 × 102 | 8.51 × 102 | 8.11 × 102 | 8.10 × 102 | 8.13 × 102 | 8.16 × 102 | 8.23 × 102 | 8.78 × 102 |
| Std | 7.86 × 10−1 | 9.54 × 10−1 | 9.68 × 100 | 7.96 × 100 | 2.33 × 100 | 5.53 × 100 | 6.70 × 100 | 5.15 × 100 | 9.85 × 100 | 1.21 × 101 | |
| Rank | 1 | 2 | 9 | 8 | 4 | 3 | 5 | 6 | 7 | 10 | |
| F9 | Ave | 9.00 × 102 | 9.00 × 102 | 1.46 × 103 | 1.46 × 103 | 9.00 × 102 | 9.06 × 102 | 9.00 × 102 | 9.02 × 102 | 9.08 × 102 | 2.40 × 103 |
| Std | 0.00 × 100 | 2.61 × 10−14 | 2.65 × 102 | 2.16 × 102 | 0.00 × 100 | 1.43 × 101 | 4.52 × 10−14 | 1.48 × 100 | 7.89 × 100 | 5.80 × 102 | |
| Rank | 1 | 2 | 8 | 9 | 3 | 6 | 4 | 5 | 7 | 10 | |
| F10 | Ave | 1.04 × 103 | 1.19 × 103 | 2.89 × 103 | 2.50 × 103 | 1.55 × 103 | 1.58 × 103 | 1.64 × 103 | 1.47 × 103 | 1.80 × 103 | 2.11 × 103 |
| Std | 1.95 × 101 | 8.33 × 101 | 2.00 × 102 | 1.85 × 102 | 1.44 × 102 | 3.29 × 102 | 2.47 × 102 | 3.29 × 102 | 2.30 × 102 | 3.47 × 102 | |
| Rank | 1 | 2 | 10 | 9 | 4 | 5 | 6 | 3 | 7 | 8 | |
| F11 | Ave | 1.10 × 103 | 1.10 × 103 | 6.78 × 103 | 4.83 × 103 | 1.10 × 103 | 1.12 × 103 | 1.11 × 103 | 1.11 × 103 | 1.72 × 103 | 9.36 × 104 |
| Std | 2.58 × 10−1 | 1.11 × 100 | 1.02 × 104 | 2.47 × 103 | 4.60 × 10−1 | 1.74 × 101 | 6.89 × 100 | 9.19 × 100 | 4.22 × 102 | 1.38 × 105 | |
| Rank | 1 | 2 | 9 | 8 | 3 | 6 | 4 | 5 | 7 | 10 | |
| F12 | Ave | 1.24 × 103 | 1.36 × 103 | 7.05 × 107 | 3.70 × 108 | 1.55 × 103 | 6.79 × 105 | 1.19 × 104 | 1.16 × 104 | 2.81 × 105 | 4.66 × 107 |
| Std | 1.38 × 101 | 4.92 × 101 | 6.17 × 107 | 4.42 × 108 | 8.08 × 101 | 9.50 × 105 | 9.58 × 103 | 7.96 × 103 | 1.10 × 106 | 4.11 × 107 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F13 | Ave | 1.30 × 103 | 1.31 × 103 | 2.15 × 105 | 2.03 × 107 | 1.31 × 103 | 9.55 × 103 | 7.69 × 103 | 3.28 × 103 | 1.25 × 104 | 3.91 × 104 |
| Std | 7.95 × 10−1 | 1.35 × 100 | 2.41 × 105 | 2.30 × 107 | 2.99 × 100 | 4.31 × 103 | 5.51 × 103 | 1.77 × 103 | 8.14 × 103 | 2.96 × 104 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 6 | 5 | 4 | 7 | 8 | |
| F14 | Ave | 1.40 × 103 | 1.40 × 103 | 8.12 × 103 | 4.26 × 103 | 1.41 × 103 | 2.63 × 103 | 1.46 × 103 | 1.43 × 103 | 1.53 × 103 | 1.98 × 103 |
| Std | 1.03 × 10−1 | 7.23 × 10−1 | 1.11 × 104 | 2.20 × 103 | 1.82 × 100 | 1.65 × 103 | 3.58 × 101 | 1.10 × 101 | 2.99 × 101 | 6.48 × 102 | |
| Rank | 1 | 2 | 10 | 9 | 3 | 8 | 5 | 4 | 6 | 7 | |
| F15 | Ave | 1.50 × 103 | 1.50 × 103 | 1.03 × 104 | 8.90 × 103 | 1.50 × 103 | 3.18 × 103 | 1.57 × 103 | 1.55 × 103 | 2.04 × 103 | 5.38 × 103 |
| Std | 4.70 × 10−2 | 2.08 × 10−1 | 4.77 × 103 | 5.49 × 103 | 2.71 × 10−1 | 1.66 × 103 | 4.52 × 101 | 3.08 × 101 | 3.62 × 102 | 4.70 × 103 | |
| Rank | 1 | 2 | 10 | 9 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F16 | Ave | 1.60 × 103 | 1.60 × 103 | 2.04 × 103 | 2.09 × 103 | 1.60 × 103 | 1.72 × 103 | 1.83 × 103 | 1.64 × 103 | 1.73 × 103 | 1.75 × 103 |
| Std | 1.11 × 10−1 | 3.35 × 10−1 | 1.11 × 102 | 1.29 × 102 | 3.50 × 10−1 | 1.19 × 102 | 1.20 × 102 | 6.58 × 101 | 1.24 × 102 | 6.74 × 101 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 5 | 8 | 4 | 6 | 7 | |
| F17 | Ave | 1.70 × 103 | 1.70 × 103 | 1.86 × 103 | 1.82 × 103 | 1.71 × 103 | 1.74 × 103 | 1.75 × 103 | 1.74 × 103 | 1.76 × 103 | 1.86 × 103 |
| Std | 3.84 × 10−1 | 1.65 × 100 | 4.44 × 101 | 2.78 × 101 | 3.25 × 100 | 1.90 × 101 | 2.26 × 101 | 1.22 × 101 | 3.39 × 101 | 7.27 × 101 | |
| Rank | 1 | 2 | 10 | 8 | 3 | 5 | 6 | 4 | 7 | 9 | |
| F18 | Ave | 1.80 × 103 | 1.80 × 103 | 4.46 × 106 | 1.53 × 107 | 1.80 × 103 | 2.64 × 104 | 4.97 × 103 | 4.05 × 103 | 2.02 × 104 | 5.60 × 104 |
| Std | 1.09 × 10−1 | 5.46 × 10−1 | 6.83 × 106 | 3.52 × 107 | 1.12 × 100 | 1.63 × 104 | 4.20 × 103 | 1.92 × 103 | 1.66 × 104 | 1.81 × 104 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F19 | Ave | 1.90 × 103 | 1.90 × 103 | 2.85 × 104 | 4.99 × 105 | 1.90 × 103 | 6.71 × 103 | 2.19 × 103 | 1.94 × 103 | 2.53 × 103 | 2.61 × 104 |
| Std | 3.39 × 10−2 | 9.22 × 10−2 | 3.37 × 104 | 5.34 × 105 | 2.28 × 10−1 | 5.57 × 103 | 6.10 × 102 | 2.65 × 101 | 1.16 × 103 | 1.40 × 104 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F20 | Ave | 2.00 × 103 | 2.00 × 103 | 2.18 × 103 | 2.22 × 103 | 2.00 × 103 | 2.05 × 103 | 2.07 × 103 | 2.03 × 103 | 2.10 × 103 | 2.19 × 103 |
| Std | 2.20 × 10−12 | 2.30 × 10−1 | 6.39 × 101 | 3.92 × 101 | 1.30 × 10−1 | 3.26 × 101 | 6.49 × 101 | 1.34 × 101 | 6.33 × 101 | 6.47 × 101 | |
| Rank | 1 | 2 | 8 | 10 | 3 | 5 | 6 | 4 | 7 | 9 | |
| F21 | Ave | 2.20 × 103 | 2.20 × 103 | 2.35 × 103 | 2.29 × 103 | 2.21 × 103 | 2.30 × 103 | 2.29 × 103 | 2.25 × 103 | 2.26 × 103 | 2.34 × 103 |
| Std | 5.94 × 10−9 | 1.38 × 10−2 | 3.05 × 101 | 5.86 × 101 | 2.49 × 101 | 4.07 × 101 | 5.33 × 101 | 5.36 × 101 | 6.20 × 101 | 4.49 × 101 | |
| Rank | 1 | 2 | 10 | 7 | 3 | 8 | 6 | 4 | 5 | 9 | |
| F22 | Ave | 2.25 × 103 | 2.21 × 103 | 2.61 × 103 | 2.87 × 103 | 2.30 × 103 | 2.35 × 103 | 2.30 × 103 | 2.30 × 103 | 2.30 × 103 | 2.50 × 103 |
| Std | 5.13 × 101 | 2.39 × 101 | 1.68 × 102 | 2.02 × 102 | 5.58 × 10−1 | 1.81 × 102 | 2.02 × 101 | 1.12 × 100 | 1.83 × 101 | 9.39 × 101 | |
| Rank | 2 | 1 | 9 | 10 | 4 | 7 | 3 | 6 | 5 | 8 | |
| F23 | Ave | 2.60 × 103 | 2.61 × 103 | 2.69 × 103 | 2.69 × 103 | 2.61 × 103 | 2.62 × 103 | 2.62 × 103 | 2.62 × 103 | 2.62 × 103 | 2.64 × 103 |
| Std | 1.08 × 100 | 1.13 × 100 | 2.25 × 101 | 9.98 × 100 | 3.18 × 100 | 8.09 × 100 | 1.31 × 101 | 6.32 × 100 | 6.65 × 100 | 6.20 × 100 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 4 | 6 | 5 | 7 | 8 | |
| F24 | Ave | 2.50 × 103 | 2.50 × 103 | 2.82 × 103 | 2.85 × 103 | 2.62 × 103 | 2.74 × 103 | 2.72 × 103 | 2.73 × 103 | 2.72 × 103 | 2.78 × 103 |
| Std | 9.21 × 10−13 | 3.92 × 10−8 | 3.07 × 101 | 5.95 × 101 | 1.22 × 102 | 1.11 × 101 | 7.72 × 101 | 5.34 × 101 | 9.35 × 101 | 6.29 × 100 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 6 | 4 | 8 | |
| F25 | Ave | 2.90 × 103 | 2.88 × 103 | 3.11 × 103 | 3.30 × 103 | 2.90 × 103 | 2.93 × 103 | 2.92 × 103 | 2.92 × 103 | 2.92 × 103 | 3.04 × 103 |
| Std | 9.33 × 10−13 | 6.65 × 101 | 1.04 × 102 | 1.13 × 102 | 1.66 × 101 | 1.60 × 101 | 3.27 × 101 | 2.39 × 101 | 2.47 × 101 | 3.27 × 101 | |
| Rank | 2 | 1 | 9 | 10 | 3 | 7 | 4 | 6 | 5 | 8 | |
| F26 | Ave | 2.81 × 103 | 2.83 × 103 | 3.66 × 103 | 4.01 × 103 | 2.90 × 103 | 3.02 × 103 | 2.88 × 103 | 2.99 × 103 | 2.96 × 103 | 3.29 × 103 |
| Std | 1.30 × 102 | 1.08 × 102 | 2.85 × 102 | 2.96 × 102 | 2.24 × 101 | 3.03 × 102 | 7.36 × 101 | 7.85 × 101 | 2.28 × 102 | 4.75 × 102 | |
| Rank | 1 | 2 | 9 | 10 | 4 | 7 | 3 | 6 | 5 | 8 | |
| F27 | Ave | 3.09 × 103 | 3.09 × 103 | 3.16 × 103 | 3.19 × 103 | 3.09 × 103 | 3.09 × 103 | 3.10 × 103 | 3.10 × 103 | 3.10 × 103 | 3.10 × 103 |
| Std | 9.42 × 10−1 | 8.96 × 10−1 | 2.43 × 101 | 5.12 × 101 | 1.51 × 100 | 3.54 × 100 | 1.67 × 101 | 1.20 × 101 | 1.52 × 101 | 1.10 × 101 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 4 | 8 | 6 | 5 | 7 | |
| F28 | Ave | 3.10 × 103 | 3.10 × 103 | 3.53 × 103 | 3.73 × 103 | 3.10 × 103 | 3.33 × 103 | 3.22 × 103 | 3.20 × 103 | 3.30 × 103 | 3.33 × 103 |
| Std | 9.46 × 10−12 | 5.12 × 10−5 | 1.13 × 102 | 9.77 × 101 | 7.76 × 10−9 | 1.00 × 102 | 1.41 × 102 | 1.00 × 102 | 1.75 × 102 | 7.95 × 101 | |
| Rank | 1 | 3 | 9 | 10 | 2 | 8 | 5 | 4 | 6 | 7 | |
| F29 | Ave | 3.14 × 103 | 3.15 × 103 | 3.39 × 103 | 3.33 × 103 | 3.17 × 103 | 3.18 × 103 | 3.21 × 103 | 3.17 × 103 | 3.21 × 103 | 3.25 × 103 |
| Std | 1.75 × 100 | 7.83 × 100 | 7.79 × 101 | 7.80 × 101 | 6.72 × 100 | 3.31 × 101 | 5.19 × 101 | 1.92 × 101 | 4.20 × 101 | 6.61 × 101 | |
| Rank | 1 | 2 | 10 | 9 | 3 | 5 | 6 | 4 | 7 | 8 | |
| F30 | Ave | 3.41 × 103 | 3.51 × 103 | 1.35 × 107 | 3.61 × 106 | 3.69 × 103 | 4.29 × 105 | 2.96 × 105 | 1.00 × 105 | 2.73 × 105 | 4.49 × 105 |
| Std | 3.52 × 100 | 5.74 × 101 | 1.27 × 107 | 4.38 × 106 | 1.57 × 102 | 7.89 × 105 | 4.63 × 105 | 2.25 × 105 | 4.75 × 105 | 4.78 × 105 | |
| Rank | 1 | 2 | 10 | 9 | 3 | 7 | 6 | 4 | 5 | 8 | |
| Mean | Ranking | 1.1071 | 2.0714 | 9.1429 | 9.3571 | 3.1786 | 6.0000 | 4.9643 | 4.6429 | 6.2143 | 8.3214 |
| Final | Rank | 1 | 2 | 9 | 10 | 3 | 6 | 5 | 4 | 7 | 8 |
| Fun | Metrics | RLNOA | NOA | SO | RSA | CPO | GWO | PSO | RLTLBO | RLMPSO | RLCGWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Ave | 1.00 × 102 | 1.44 × 102 | 1.70 × 1010 | 2.91 × 1010 | 1.04 × 102 | 1.40 × 108 | 3.58 × 103 | 3.41 × 103 | 6.56 × 103 | 1.57 × 1010 |
| Std | 2.14 × 10−1 | 3.57 × 101 | 5.57 × 109 | 4.45 × 109 | 3.33 × 100 | 3.75 × 108 | 3.13 × 103 | 3.52 × 103 | 4.52 × 103 | 2.63 × 109 | |
| Rank | 1 | 3 | 9 | 10 | 2 | 7 | 5 | 4 | 6 | 8 | |
| F2 | Ave | 1.36 × 103 | 1.96 × 103 | 5.71 × 103 | 5.53 × 103 | 2.70 × 103 | 2.54 × 103 | 2.45 × 103 | 2.61 × 103 | 3.49 × 103 | 5.53 × 103 |
| Std | 1.14 × 102 | 1.62 × 102 | 3.81 × 102 | 2.06 × 102 | 2.39 × 102 | 5.79 × 102 | 3.68 × 102 | 5.94 × 102 | 6.67 × 102 | 4.30 × 102 | |
| Rank | 1 | 2 | 10 | 9 | 6 | 4 | 3 | 5 | 7 | 8 | |
| F3 | Ave | 7.31 × 102 | 7.42 × 102 | 1.04 × 103 | 1.01 × 103 | 7.63 × 102 | 7.67 × 102 | 7.53 × 102 | 7.99 × 102 | 8.26 × 102 | 1.74 × 103 |
| Std | 3.04 × 100 | 1.01 × 101 | 3.51 × 101 | 2.94 × 101 | 4.60 × 100 | 2.22 × 101 | 1.03 × 101 | 3.05 × 101 | 3.73 × 101 | 1.90 × 102 | |
| Rank | 1 | 2 | 9 | 8 | 4 | 5 | 3 | 6 | 7 | 10 | |
| F4 | Ave | 1.90 × 103 | 1.90 × 103 | 1.54 × 105 | 3.54 × 105 | 1.91 × 103 | 1.91 × 103 | 1.90 × 103 | 1.92 × 103 | 1.91 × 103 | 3.63 × 104 |
| Std | 3.02 × 10−1 | 4.32 × 10−1 | 1.13 × 105 | 1.81 × 105 | 6.18 × 10−1 | 3.06 × 100 | 6.75 × 10−1 | 1.04 × 101 | 3.31 × 100 | 2.18 × 104 | |
| Rank | 2 | 3 | 9 | 10 | 4 | 5 | 1 | 7 | 6 | 8 | |
| F5 | Ave | 2.12 × 103 | 2.40 × 103 | 3.16 × 106 | 5.01 × 106 | 3.02 × 103 | 3.95 × 105 | 8.93 × 104 | 6.03 × 104 | 2.74 × 105 | 2.75 × 106 |
| Std | 5.42 × 101 | 1.28 × 102 | 1.41 × 106 | 2.14 × 106 | 2.16 × 102 | 6.93 × 105 | 5.25 × 104 | 3.58 × 104 | 1.55 × 105 | 2.52 × 106 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F6 | Ave | 1.60 × 103 | 1.60 × 103 | 2.88 × 103 | 3.12 × 103 | 1.61 × 103 | 1.86 × 103 | 1.88 × 103 | 1.75 × 103 | 1.94 × 103 | 2.38 × 103 |
| Std | 1.82 × 10−1 | 4.85 × 10−1 | 3.61 × 102 | 4.69 × 102 | 4.30 × 100 | 1.49 × 102 | 1.58 × 102 | 1.10 × 102 | 1.58 × 102 | 2.12 × 102 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 5 | 6 | 4 | 7 | 8 | |
| F7 | Ave | 2.25 × 103 | 2.39 × 103 | 1.33 × 106 | 3.21 × 106 | 2.69 × 103 | 1.36 × 105 | 5.24 × 104 | 1.85 × 104 | 9.30 × 104 | 1.04 × 106 |
| Std | 3.46 × 101 | 8.91 × 101 | 1.32 × 106 | 3.63 × 106 | 1.06 × 102 | 8.51 × 104 | 7.68 × 104 | 1.91 × 104 | 7.48 × 104 | 6.58 × 105 | |
| Rank | 1 | 2 | 9 | 10 | 3 | 7 | 5 | 4 | 6 | 8 | |
| F8 | Ave | 2.30 × 103 | 2.30 × 103 | 4.78 × 103 | 5.30 × 103 | 2.30 × 103 | 2.71 × 103 | 2.40 × 103 | 2.30 × 103 | 2.30 × 103 | 5.47 × 103 |
| Std | 1.43 × 101 | 1.44 × 10−4 | 9.68 × 102 | 7.07 × 102 | 4.04 × 10−6 | 7.46 × 102 | 4.47 × 102 | 5.71 × 100 | 1.23 × 100 | 1.08 × 103 | |
| Rank | 1 | 3 | 8 | 9 | 2 | 7 | 6 | 5 | 4 | 10 | |
| F9 | Ave | 2.81 × 103 | 2.81 × 103 | 3.13 × 103 | 3.19 × 103 | 2.86 × 103 | 2.85 × 103 | 2.86 × 103 | 2.86 × 103 | 2.88 × 103 | 2.94 × 103 |
| Std | 4.14 × 100 | 6.80 × 101 | 6.79 × 101 | 1.85 × 102 | 1.01 × 101 | 3.68 × 101 | 3.03 × 101 | 1.97 × 101 | 3.45 × 101 | 1.33 × 101 | |
| Rank | 2 | 1 | 9 | 10 | 6 | 3 | 4 | 5 | 7 | 8 | |
| F10 | Ave | 2.91 × 103 | 2.91 × 103 | 4.26 × 103 | 4.82 × 103 | 2.93 × 103 | 2.95 × 103 | 2.93 × 103 | 2.98 × 103 | 2.95 × 103 | 4.15 × 103 |
| Std | 4.49 × 100 | 3.87 × 10−2 | 5.13 × 102 | 7.40 × 102 | 2.54 × 101 | 3.01 × 101 | 3.04 × 101 | 3.81 × 101 | 3.41 × 101 | 4.77 × 102 | |
| Rank | 1 | 2 | 9 | 10 | 4 | 5 | 3 | 7 | 6 | 8 | |
| Mean | Ranking | 1.2222 | 2.2222 | 9.0000 | 9.5556 | 3.6667 | 5.5556 | 4.2222 | 4.8889 | 6.2222 | 8.4444 |
| Final | Rank | 1 | 2 | 9 | 10 | 3 | 6 | 4 | 5 | 7 | 8 |
| Fun | ||||
|---|---|---|---|---|
| F1 | F4 | F17 | F23 | |
| 0.8 | 1.00 × 102 | 4.00 × 102 | 1.72 × 103 | 2.50 × 103 |
| 0.6 | 1.00 × 102 | 4.00 × 102 | 1.72 × 103 | 2.50 × 103 |
| 0.4 | 1.00 × 102 | 4.00 × 102 | 1.72 × 103 | 2.50 × 103 |
| 0.2 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| Fun | ||||
|---|---|---|---|---|
| F1 | F4 | F17 | F23 | |
| 0.5 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 0.2 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 0.1 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 0.05 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| Fun | ||||
|---|---|---|---|---|
| F1 | F4 | F17 | F23 | |
| 5 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 10 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 20 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 50 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| Fun | ||||
|---|---|---|---|---|
| F1 | F4 | F17 | F23 | |
| 1 | 1.00 × 102 | 4.00 × 102 | 1.71 × 103 | 2.50 × 103 |
| 2 | 1.01 × 102 | 4.00 × 102 | 1.72 × 103 | 2.50 × 103 |
| 4 | 1.04 × 102 | 4.00 × 102 | 1.72 × 103 | 2.50 × 103 |
| 8 | 1.17 × 102 | 4.00 × 102 | 1.72 × 103 | 2.50 × 103 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, Y. A Reinforcement Learning-Based Bi-Population Nutcracker Optimizer for Global Optimization. Biomimetics 2024, 9, 596. https://doi.org/10.3390/biomimetics9100596
Li Y, Zhang Y. A Reinforcement Learning-Based Bi-Population Nutcracker Optimizer for Global Optimization. Biomimetics. 2024; 9(10):596. https://doi.org/10.3390/biomimetics9100596
Chicago/Turabian StyleLi, Yu, and Yan Zhang. 2024. "A Reinforcement Learning-Based Bi-Population Nutcracker Optimizer for Global Optimization" Biomimetics 9, no. 10: 596. https://doi.org/10.3390/biomimetics9100596
APA StyleLi, Y., & Zhang, Y. (2024). A Reinforcement Learning-Based Bi-Population Nutcracker Optimizer for Global Optimization. Biomimetics, 9(10), 596. https://doi.org/10.3390/biomimetics9100596