1. Introduction
Optimization algorithms are always asked to find optimal or near-optimal solutions [
1]. Heuristic algorithms and meta-heuristic algorithms (Mas) are concrete implementations of optimization algorithms. Separately, heuristic algorithms optimize the performance of the algorithm by searching the solution space through heuristic rules and empirical guidance [
2]. In addition, MAs ensure that the algorithm achieves optimal results by combining and adjusting different heuristic algorithms.
MAs are widely used and essential in science, technology, finance, and medicine. For example, in artificial intelligence (AI), MAs improve the model’s performance and accuracy [
3]. It can also be used to optimize problems in AI applications such as intelligent recommendation systems, image processing, and natural language processing to provide better user experience and quality of service. In the financial field, MAs can be used to optimize investment portfolios and risk management to improve investment returns and reduce risks. In the medical field, the MAs can be used to optimize the allocation and scheduling of medical resources to optimize work efficiency in medical services. In transportation, MAs can be used to optimize traffic signal control and route planning to reduce traffic congestion and improve transportation efficiency [
4] and so on. In addition, the application of MAs presents some opportunities for algorithmic improvement, multi-objective optimization, and integration with machine learning, but also some challenges, including high complexity, parameter selection, and local optimal solutions.
There are many different types of MAs. This paper mainly classifies them according to animal, plant, discipline, and other types. Animal-based optimization algorithms simulate the social behavior of animals in groups and collectives. For example, the best known is Particle Swarm Optimization (PSO), which simulates specific behaviors of birds during flight or foraging [
5]. Krill Herd (KH) [
6] simulates the grazing behavior of individual krill. Harris Hawk Optimization (HHO) [
7] is mainly inspired by the cooperative behavior and chasing style of Harris hawks in nature. Abdel-Basset et al. proposed a Nutcracker Optimizer (NO) [
8]. NO simulates two different behaviors exhibited by Nutcracker at different times. Whale Optimization Algorithm (WOA) [
9] was developed, inspired by the feeding process of whales. The Genghis Khan Shark Optimizer (GKSO) simulates [
10] predation and survival behaviors.
A plant-based optimization algorithm simulates the intelligent clustering behavior of plants. Dandelion Optimizer (DO) simulates the process of dandelion seeds flying over long distances relying on the wind [
11]. Invasive Weed Optimization (IWO) simulates the basic processes of dispersal, growth, reproduction, and competitive extinction of weed seeds in nature [
12]. Tree Growth Algorithm (TGA) [
13] is an algorithm that simulates the competition among trees for access to light and food.
Discipline-based approaches include primarily chemical, mathematical, and physical approaches. They both accomplish optimization by simulating natural physical, fundamental laws, and chemical phenomena. Physics-based methods, such as those seen in Zhang et al., propose a Growth Optimizer (GO) subject to the learning and reflective mechanisms of individuals during social growth. It mathematically simulates growth behavior [
14]. Abdel-Basset and El-Shahat proposed a Young’s Double-Slit Experiment (YDSE) optimizer. The YDSE optimizer was inspired by Young’s double-slit experiment [
15]. Special Relativity Search (SRS) simulates the interaction of particles in a magnetic field [
16]. Chemistry-based methods, such as Atomic Search Optimization (ASO), mathematically models and simulates the movement of atoms in nature [
17]. Nature-inspired chemical reaction optimization algorithms mimic the principles of chemical reactions in nature [
18]. Smell Agent Optimization (SAO) considers the relationship between odor agents and objects that vaporize odor molecules [
19]. Ray Optimization (RO) [
20] is proposed based on the idea of Snell’s light refraction law. Algorithms based on mathematical methods have also been extensively studied, for example, the Arithmetic Optimization Algorithm (AOA) [
21] simulates the distributional properties of four basic operators. The Sine Cosine Algorithm (SCA) [
22] is an algorithm proposed by the ideas of sine and cosine. Subtraction-Average-Based Optimizer (SABO) [
23] proposes an individual updating the position of an individual by subtracting the average of the position idea.
Other types of algorithms include, but are not limited to, optimization algorithms based on human acquisition, e.g., Social Group Optimization (SGO) simulates the social behavior of humans in solving complex problems [
24]. Social Evolution and Learning Optimization (SELO) simulates the social learning behavior of humans organized in families in social settings [
25]. Student Psychology-Based Optimization (SPBO) simulates the process of students improving their level of proficiency in multiple ways during the learning process [
26]. Further, the corresponding algorithms and publication dates are given, as shown in
Figure 1.
To increase the broad application of MAs in various fields, researchers constantly update the design and performance of MAs and develop more efficient and accurate algorithms. Fatma A. Hashim [
27] proposed a physics-based MA called Fick’s Law Algorithm (FLA) to optimize the process by constantly updating the position of molecules in different motion states under the concentration difference. It has been proven that FLA leads to optimal solutions with high robustness when confronted with real-world engineering optimization problems. However, some experimental studies have also found that FLA suffers from local convergence as well as degradation of convergence accuracy when faced with high-dimensional, high-complexity problems [
28]. Therefore, we try to improve the FLA algorithm by introducing some efficient but non-redundant strategies and the proposed multi-strategy improved FLA algorithm (FLAS).
The proposed FLAS adopts many strategies to improve its performance and effect. Specifically, at the beginning of the exploration phase, the FLAS adds differential and Gaussian local mutation strategies to expand the search range in the later iteration. During the transition process phase, FLAS uses intersectional integrated learning strategies to enhance the ability to inquire about the overall situation and randomness. FLAS also adopts the Levy flight strategy in location updates and generates random steps with Levy distribution, which can carry out an extensive range of random searches in the search space. This randomness has an excellent global search ability and effectively controls the degree of the search and convergence rate. Finally, in the exploitation phase, FLAS also adds a global search mechanism for the migration phase of the seagull algorithm, aiming to speed up its convergence by avoiding molecular aggregation. Through the organic combination of these strategies, FLAS can effectively solve the problems of FLA in convergence accuracy and the convergence process and achieve better performance. The competitiveness and validity of FLAS are validated in 23 benchmark functions and CEC2020 tests, 7 engineering design problems, and solar PV parameter estimation applications. The results of FLAS are compared with those of other recent Mas, and are statistically analyzed using the Wilcoxon rank sum test.
The main contributions of this study are as follows:
(1) To overcome the shortcomings of the original algorithm FLA, a new optimization algorithm named FLAS is proposed by introducing the differential variational strategy, Gaussian local variational strategy, interleaving-based integrated learning strategy, and seagull updating strategy.
(2) Some classical and newly proposed algorithms are selected as comparison algorithms, and the optimization ability of FLAS is evaluated on 23 benchmark functions and the CEC2020 test set. The computational results of various performance metrics show that the proposed FLAS has the best overall performance in most of the tested functions.
(3) The FLAS is applied to seven engineering optimizations and the solar PV model parameter estimation, respectively. The results show that FLAS can stably provide the most reliable optimization design strategies for most practical problems.
The remainder of this paper is as follows: first,
Section 2 analyzes, summarizes, and improves FLA. Then, in
Section 3, the multi-strategy improved Fick algorithm is presented by adding five different strategies. Secondly, we test the performance of FLAS in
Section 4. The results of FLAS on the CEC2020 test set are compared with other methods. In
Section 5 and
Section 6, FLAS is applied to seven practical engineering design problems and the solar PV parameter estimation application. Finally, this study is summarized and prospected.
2. An Overview of the FLA
Fick’s law describes the fundamental principle of diffusion of substances in physics and chemistry. Therefore, Fick’s law algorithm simulates Fick’s law process of substance diffusion [
27]. According to Fick’s law, the greater the concentration gradient, the faster the diffusion rate [
29]. Therefore, Fick’s algorithm changes the concentration relationship between the two sides by adjusting the position of molecules in different regions to ensure a stable position of the molecules, thus realizing the optimization process.
Figure 2 shows the schematic diagram of molecular movement in Fick’s law.
In the FLA algorithm, the optimization process first requires randomly initializing a set of candidate populations (
X), whose matrix can be expressed as Equation (1).
where
N is the population size, and
D is the individual dimension. In addition,
Xi,j in the matrix represents the
jth dimension of the
ith molecule. The formula for random initialization is as follows:
where
ub and
lb represent the upper and lower bounds. The
rand (1,
D) is the random number uniformly generated in the search region. Divide
N into two equal-sized subgroups,
N1 and
N2, and the fitness of the populations of
N1 and
N2 were calculated, respectively. The molecule constantly moved from high to low concentration, and
TFt was a parameter of the iteration function.
TFt is described by Equation (3).
where
t represents the
tth iteration and
T represents the maximum number of iterations. sinh serves as a nonlinear transfer function that ensures an efficient transition from exploration to exploitation [
27]. Further, the molecular position equation is updated by Equation (4).
The FLA update process consists of three stages (diffusion operator (DO), equilibrium operator (EO), steady-state operator (SSO)). Through the three ways, FLA can find the best value of the system. We will specifically describe these three parts below.
2.1. Exploration Phase
In the first stage, the diffusion of a molecule from high concentration to low concentration is called DO, as shown in
Figure 3. When
, due to the different concentration differences between the two regions
i and
j, the molecule will be transferred from one area to the other by the given parameter
, which can be provided by Equation (5):
where
C5 represents a fixed constant with a value of 2, and
r means a random number with a value between 0 and 1.
From the parameter
, the flow direction of the molecule is determined by the following formula Equation (6).
where
rand is a random number with a value between 0 and 1. Consider that some molecules move from region
i to region
j. The formula for the number of molecules that move from region
i to region
j is as follows:
where
C3 and
C4 represent the fixed constant with values of 0.1 and 0.2, respectively.
NT12 and
Ntransfer denote the number of molecules flowing at different stages, respectively.
r1 is the random number in the interval [0, 1]. The specific formulae are as follows:
The molecule
NT12 will move to another, and its position will be updated mainly on the best-balanced molecule in the
j region using Equation (10).
where
DOF is the change of flow direction with time,
is the diffusion flux,
denotes the balance position of region
i. r2 is the random number in the interval [0, 1].
where
C2 represents a fixed constant with a value of 2.
and
are the positions of the
j and
i regions, respectively and
eps is a small value.
D is the effective diffusion coefficient constant,
is the concentration gradient. In addition,
NR1 denotes molecules that remain in region
i; the molecules in the
NR1 are updated in their positions by Equation (15).
The positions of molecules in the formula are divided into three different strategies and position of region
i; their positions do not change.
where
r3 is the random number in the interval [0, 1].
U and
L are the max and min limit.
For molecules in the
j region, because the concentration in the
j region is higher, the
j region, boundary problem is treated with the following Equation (17):
where
r4 is the random number in the interval [0, 1].
2.2. The Transition Phase from Exploration to Exploitation
In the second phase, for the second stage where the concentration difference is almost zero, the molecule tries to reach an equilibrium state called
EO, as shown in
Figure 4.
This phase is considered a transition from the exploration phase to the exploitation phase. Molecules update their location by the following Equation (18).
where
and
are the positions in group
p and
g,
is the relative quantity of group
g, calculated by the following Equation (25).
is the diffusion rate factor of the group
g region, and the calculation formula is as follows:
where
is the direction factor equal to ±1,
is a random number in the interval [0, 1], and
represents the diffusion rate.
where
is the optimum of group
g at time
t, and
is the optimum of molecule
p in group
g at time
t.
2.3. Exploitation Phase
In the third phase, we move the barrier so that the molecule moves to the most stable position to achieve a more stable molecule distribution. In the SSO phase, the molecule updates its position by the following Equation (27).
where
and
are the position of the stable phase and
p molecule, and
and
respectively represent the relative quantity of
g region and the motion step, the calculation formula is as follows:
From the above overview, the pseudo-code for FLA is obtained in Algorithm 1.
| Algorithm 1 FLA Algorithm |
![Biomimetics 09 00205 i001]() |
3. An Enhanced FLA (FLAS)
FLA can effectively mitigate the imbalance between exploration and utilization. However, it faces the same challenge as other MAs, being that it falls into local optimal solutions. Its main primitive is that the physical simulation search strategy of FLA leads to the inability of the molecules to get out of the local optimal solution. Therefore, to overcome this problem, this study proposes a multi-strategy improved FLA by introducing four effective search strategies, including differential variation, Gaussian local variation, Levy flight, and global search strategies.
3.1. Improvement Strategy
3.1.1. Differential Variation Strategy
Differential variational strategy, as an effective strategy, has the advantages of diversity, efficient searchability, low computing cost, strong robustness, and ease of implementation and understanding [
3]. Introducing random perturbations into the population helps algorithms maintain diversity in the search process and avoid the population falling into excessive convergence. At the same time, it can generate a new solution, often different from the parent solutions. Controlling the mutation operator makes more extensive exploration possible in the search space, which helps find potentially better solutions.
In the DO phase, FLA may have locally optimal solutions due to uneven diffusion of molecules when solving the optimization problem. Therefore, in order to better optimize the results, we try to introduce a differential variation strategy to improve the problem that the original algorithm tends to fall into local solutions. First, the weighted position difference between the two individuals is calculated. Further, the obtained result is then added to the position of a random individual to generate the variant individually. The specific formula is as follows:
where
represents the new position after updating,
represents the different individuals in the
tth iteration, and
represents the random individual position in the population
NT12. In additional,
F = 0.3 represents the scaling factor. The adaptive adjustment mutation operator
F0 is described as follows:
In addition, the differential variation strategy is more adaptable to the constraints of the boundary. By setting appropriate parameters, the amplitude and direction of variation operation can be controlled to ensure that the generated variation solution satisfies the constraint conditions of the problem.
3.1.2. Gauss Local Variation Strategy
In fact, the development phase affects the convergence accuracy of the algorithm. To facilitate the low accuracy problem of FLA, we introduce a variational strategy in the development phase to improve the convergence performance. As a result, the Gaussian local variation can effectively help the algorithm further search for the optimal solution, expanding the search range of FLA in the later iteration stage [
11]. The Gaussian local variation is specifically calculated by Equation (36):
where
represents a random number between 0 and 1. In the first
t iteration,
denotes the current individual optimum.
r3 is the random number in the interval [0, 1].
3.1.3. Integrated Learning Strategies Based on Intersections
In the DO and EO phases, the optimal individuals contribute to the bidirectional search of the whole population. However, the individual optimal values in FLA are not representative, and cannot lead to realizing the global search. Therefore, in order to obtain the most representative optimal individuals, we are inspired by the crossover operator and introduce a crossover-based comprehensive learning (CCL) strategy [
12]. The CCL strategy can mutate better individuals through the crossover operator to guide the individual global search. The specific calculation formula is Equation (37):
where
is a randomly generated number evenly distributed among [−1, 1], and both
and
are randomly numbers evenly distributed among [0, 1].
3.1.4. Levy Flight Strategy
For better convergence and global optimization, the proposed FLAS employs Levy flight for position update of subgroup
N2 [
30]. After the FLA updates the position, a Levy flight is performed to update the individual position. Levy flight strategy is designed to simulate the stochastic and exploratory nature of Levy flights. It can perform a global search in the search space to achieve the desired result of jumping out of the local optimum. The specific calculation formula is described as Equation (38):
where
levyrand means the Levy distribution [
30]. In addition,
alfa means the levy scale parameter, and the value of
alfa is 0.05 + 0.04 ×
rand and
.
3.1.5. Global Search Strategy of Gull Algorithm during Migration Phase
In the stable phase (SSO), due to the local development of the algorithm, a large number of molecules may gather around the current environment, which restricts the development of the FLA, thus causing the FLA to be unable to break through its intrinsic limitations. At this time, the global search strategy of the seagull algorithm [
31] is added to accelerate the convergence rate of FLA and avoid the collision between molecules in the process of motion [
32].
D_alphs indicates that the new position of molecules has no conflict. The update process is shown in
Figure 5, and the formula is as follows:
where
is the control factor,
,
.
In the seagull optimization algorithm, the moving direction of each seagull individual, is calculated as the position. The moving distance is adjusted based on the fitness. The higher the fitness, the smaller the moving distance. Therefore, this strategy is employed to update the molecule positions during the stable phase. The specific position update formula is as follows
where
Xe is a new position that is reached by moving in the direction of the optimal position.
represents a random number that balances global and local searches.
3.2. The Improved FLA Steps
The FLAS improved algorithm is established by introducing the differential variation strategy, Gaussian local variation strategy, interleave-based comprehensive learning strategy, Levy flight strategy, and the global search strategy in the migration phase of the Gull algorithm. The FLAS algorithm process is as follows:
When
TFt < 0.9 and
, the position of
NT12 obtained by Equation (10) in
N1 population is updated by Equation (34).
At the same time, for the remaining individuals (
N1 −
NT12) and the population individual position update, the strategies in Equations (36) and (37) are adopted. The formula is as follows:
In the
N2 population, individual location updating adopts the strategies in Equations (36) and (38).
when
TtDO <
rand, the position update of
Ntransfer obtained with Equation (10) in
N2 population is:
For the remaining individuals (
N2 −
Ntransfer), the same strategies in Equations (36) and (37) were adopted as the individual renewal mode of
N1 population in
TtDO <
rand phase.
In this phase, the same strategies Equations (36) and (38) are used to update the positions of
N1 population in the same phase as those of
N2 population in
TtDO <
rand phase. The formula is as follows:
When
TFt ≤ 1, the EO phase will be entered, and the strategy Equation (36) will be adopted for both
N1 population individual location renewal and
N2 population individual location renewal. The formula is as follows:
When
TFt > 1, entering the SSO phase, Equations (55) and (56) were adopted for individual location updates of the
N1 population and
N2 population, and the formula was as follows:
The basic steps of the FLAS:
Step 1. Specify both N and T, divide N into two equal small populations N1 and N2, randomly generate the initial positions of N1 and N2 individuals in the solution search space, and set the current iteration number t = 1.
Step 2. The fitness values of N1 and N2 individuals were calculated, and the optimal individual position was obtained.
Step 3. When TFt < 0.9, and N1 population enters the exploration phase (DO), and Equation (41) is used to update individual locations for NT12.
Step 4. When , for the remaining population of individuals in N1, if rand < 0.8, the individual location is updated using Equation (43); if 0.8 < rand < 0.9, the individual location is updated using Equation (44); Others, using Equation (45) to update individual position.
Step 5. When , in the population of individuals in N2, the individual locations were updated using Equation (46).
Step 6. In the case of , in the N2 population, individual positions are updated using Equation (46) for Ntransfer. For the remaining individuals (N2 − Ntransfer), if rand < 0.8, the individual position is updated using Equation (46); if 0.8 < rand < 0.9, the individual location is updated using Equation (49); otherwise, the individual location is updated using Equation (50).
Step 7. When , individual positions are updated using Equation (52) for N1 populations.
Step 8. When TFt ≤ 1, individual positions are updated using Equation (53) for N1 populations and individual positions are updated using Equation (54) for N2 populations.
Step 9. When TFt > 1, individual positions of population N1 are updated using Equation (55), and those in populations of N2 are updated using Equation (56).
Step 10. The boundary treatment of population location is carried out.
Step 11. Output the position and fitness values of the globally optimal individual.
The pseudo-code of FLAS is shown in Algorithm 2.
| Algorithm 2 FLAS Algorithm |
![Biomimetics 09 00205 i002]() |
3.3. Time Complexity of the FLAS
MAs time complexity is influenced by both the dimensionality of variables
D, population
N, and iteration
T. Determining the time complexity (
TC) of an algorithm helps evaluate its operational efficiency. In the FLAS algorithm, first of all, the TC required during the initialization phase is
O(
N ×
D). FLAS then entered an iterative search for an updated solution. Entering the exploration phase. When the
,
TC is
O(
NT12 ×
D) +
O((
N/2 −
NT12) ×
D) +
O(
N/2 ×
D), when the
, TC is
O(
Ntransfer ×
D) +
O((
N/2 −
Ntransfer) ×
D) +
O(
N/2 ×
D). The
TC entering the EXE phase are
O(
N/2 ×
D) +
O(
N/2 ×
D). Finally, the
TC for the exploitation phase is
O(
N/2 ×
D) +
O(
N/2 ×
D). The total
TC of FLAS is calculated:
For a clearer description of the situation and the steps of FLAS to solve the optimization model,
Figure 6 shows the algorithm solution flow chart.
4. Experimental Results
To verify the effectiveness of the FLAS method, the 23 benchmark functions and CEC2020 test sets are used to examine the optimization capability, and several algorithms have been selected for comparison. The selected comparison algorithms include the differential evolution algorithm (DE) [
33], the improved molecule swarm optimization algorithm (PSO_ELPM) [
34], the spectral optimization algorithm LSO [
35] inspired by physics and mathematics, the arithmetic optimization algorithm AOA [
36], the Harris Eagle algorithm (HHO) [
7] inspired by animal nature, and the improved Golden Jackal optimization (IGJO) [
37] and improved Grey Wolf algorithm (IGWO) [
38]. The parameter values of the above 10 MAs are depicted in
Table 1.
To accurately analyze the performance of FLAS, this article will use the following six performance metrics:
;
;
;
;
where besti represents the optimal result for the ith run, m implies the number of runs.
Rank: All algorithms are ranked according to the quality of their performance indicators. The sequence number is the corresponding Rank. If the specific values of the comparison algorithms are equal, they are recorded as having the same Rank.
Wilcoxon rank sum test: We estimate whether a noticeable disparity exists between the two algorithms. Calculate whether the two arrays of fitness values after m runs come from a continuous distribution with the same median. p-values derived by the Wilcoxon rank sum test for the other nine algorithms are shown at the α = 0.05 level. Bolded data show insignificant differences between the comparative algorithms and FLAS calculations. The “=” symbol indicates the number where there is no distinct difference between the results of other MAs and FLAS; the “+” symbol represents the number that outperformed FLAS, while the “−” symbol represents the number of functions that have inferior results compared to FLAS.
4.1. Parameter Analysis of Levy Scale Alfa
For the update strategy based on Levy flights, the parameter alfa affects the improvement of the algorithm performance with Levy flights. Due to the kinematic nature of each Levy flight, the random numbers it generates can only guide the overall convergence. The value of the parameter alfa affects the search range of the molecular neighborhood region. The larger the value of alfa, the larger the search range of the molecular neighborhood region and the greater the tendency of the algorithm to converge. If the value of alfa is too small, the search range of the molecular neighborhood region is small, and the Levy flight has less influence on the search process, which reduces the search capability and accuracy. Therefore, an appropriate value of alfa can improve the exploration ability of FLAS in individual molecular neighborhood locations.
In order to find an appropriate
alfa value, the effects of different
alfa values on the convergence performance of the FLAS algorithm are discussed. Ten test functions from the cec2020 test suite are selected for numerical experiments. Ten correlation parameters were obtained at intervals of 0.04 in the interval [0.01, 0.5] (0.01 +
rand × 0.04, 0.05 +
rand × 0.04, 0.1 +
rand × 0.04, 0.15 +
rand × 0.04, 0.2 +
rand × 0.04, 0.25 +
rand × 0.04, 0.3 +
rand × 0.04, 0.35 +
rand × 0.04, 0.4 +
rand × 0.04 and 0.45 +
rand × 0.04). For each given value of the ten parameters, the average values obtained using FALS over 20 independent runs of the test are shown in
Table 2. The maximum iteration is 1000 and the population size is 30.
From the results in
Table 2, it can be seen that the accuracy of the FLAS solution is higher when the value of α is taken as 0.05 + 0.04 ×
rand. The reason for this result is that smaller
alfa allows FLAS to increase the distance connection between the population and the most available position, which enhances the local development ability of FLAS. Smaller values of
alfa give better experimental results when faced with more complex mixing and combining functions. This result suggests that smaller
alfa values increase the solution space search in the presence of more comprehensive functions and help the Levy flight strategy to better utilize its ability to jump out of local solutions. Thus, smaller values of
alfa contribute to the local search ability of FLAS when dealing with complex functions. The last part of the table lists the rankings for different values of
alfa. It can be noticed that FLAS performs well for all functions when
alfa is 0.05 + 0.04 ×
rand.
4.2. Qualitative Analysis of FLAS
EXE are two important concepts in MAs. Exploration refers to looking for new solutions or improving existing solutions. Exploitation refers to the optimization and utilization of existing solutions in the hope of getting better results. To infer whether a group is currently more inclined to explore or exploit, it can be judged by counting the differences between individuals. If the differences between individuals are large, it indicates that the group is currently more inclined to explore; if the differences between individuals are small, it indicates that the group is currently more inclined to develop [
39]. How the algorithm balances these two capabilities will be the key to determining optimal performance. Therefore, calculate the proportional formula of the two capabilities in the iterative process, as shown in Equation (58):
where median (
j) represents the median value of the
J-dimensional variable among all individuals in the population (
N). After taking the median dimension distance of dimension j of each individual
i in the
N, the average
Diversity is obtained for all individuals in turn. Then, the average value of
Diversity in each dimension is calculated to obtain
Diversity. The percentage of EXE of the population in each iteration formula are Equations (59) and (60).
Firstly, the EXE ability of FLAS is tested on 23 benchmark functions, and the single-peak test function (F1–F7) is related to the capability of finding the optimal solution. The multimodal function (F8–F13) can test the MA’s capability to explore and escape local optima values because there are many local minima and the EXE ability of the fixed-dimensional multimodal function (F14–F23). The EXE diagram of FLAS is displayed in
Figure 6. In the EXE diagram, Exploration is represented by the red area, and the blue area represents exploitation. The final exploitation should be close to 100% because the population gradually approaches optimum in the late phase of evolution, and the whole solution set is concentrated near optimum. In addition, the percentage of EXE should alternate as the iteration progresses: the blue area should go up and eventually approach 1; the red area is going to come down and eventually approach 0.
Figure 7 shows that FLAS converges very fast on other functions except F8, F17, and F20, and the population soon approaches the optimal solution. According to the latest research [
40], when EXE accounts for 10% and 90%, respectively, in the search process, the algorithm has the best performance. Therefore, FLAS meets this requirement; the Exploration of the population finally accounts for about 90%, and the exploitation accounts for about 10%.
To enhance the stability and reliability of the outcomes, give the ability to the EXE. FLAS continued testing on CEC2022. The EXE diagram on CEC2022 is shown in
Figure 8, from which the FLAS demonstrates its ability to quickly find globally optimal solutions and flexibly switch between unimodal, fundamental, and combinatorial functions. When dealing with complex mixed functions, FLAS shows high exploration ability in the later iteration, and avoids the dilemma of local optimal solutions. FLAS has adopted a strategy to extend the time required to transition to the exploitation phase, effectively improving optimization capabilities.
4.3. Comparison of FLAS and Other MAs on 23 Benchmark Functions
In order to validate the effectiveness of the proposed algorithm for FLAS, comparison experiments with PSO_ELPM, HHO, IGWO, DE, LSO, BWO, AOA, and IGJO algorithms are conducted in 23 benchmark functions. All comparison algorithms are run 30 times. In addition, N is chosen to be 500 for all algorithms. The iterative plots and boxplots of FLAS and the other comparison algorithms for the 23 benchmark functions are given in
Figure 9 and
Figure 10, respectively. In addition, the results of the comparison experiments for the four metrics are given in
Table 3. In order to statistically validate the effectiveness of the proposed algorithms, the statistical results of the Wilcoxon rank sum test for FLAS and other methods are given in
Table 4.
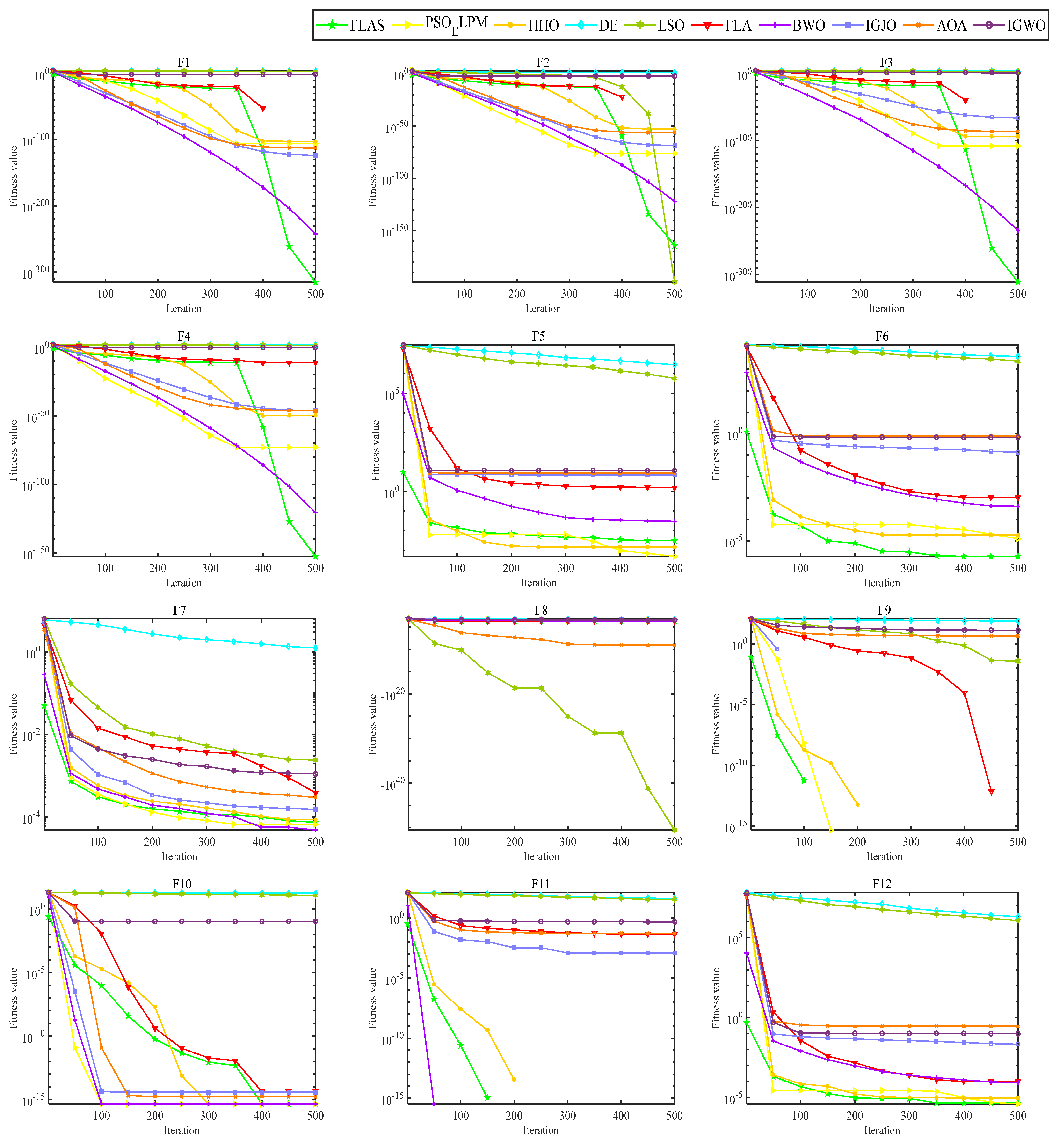
As illustrated in
Figure 9, the FLAS demonstrates noticeable superiority over other MAs, particularly from F1 to F7. For the multimodal test function, F8–F13, the FLAS outperforms other MAs in convergence speed and accuracy. For low-dimensional multi-peak test functions (F14–F23), FLAS is better than other MAs, particularly on F14, F15, and F20. Among the remaining functions, the optimum of 23 benchmark functions can be obtained accurately. For the F14–F23 function, we can see that FLAS can quickly transition between the early search and the late transition phase, converging near the optimal position at the beginning of the iteration. Then, FLAS progressively determines the optimal position and updates the answer to validate the previous observations. We can find that FLAS performs quite competitively across the three types of functions and maintains a consistent dominance in most of them. In addition, convincing results show that the FLAS algorithm is also able to balance both exploratory and developmental search. To infer information from
Figure 10, the FLAS obtains lower and narrower boxes in most functions. The finding that in most cases, the distribution of the objectives of FLAS is centered on the other intelligent algorithms also illustrates the consistency and stability of FLAS. According to the comparison results between
Table 3 and various algorithms, FLAS is generally the first. In addition, the proposed FLAS is ranked first for 15 of the test functions and is ranked second for the remaining 5 test functions. For the single-peak functions F1–F7, FLAS is ranked at least second in all of them, indicating that the proposed FLAS can find the single-peak optimal solution effectively. In addition, FLAS ranks first in all multi-peak functions, indicating that FLAS can effectively avoid the interference of localized solutions. Competitive performance is also demonstrated in complex problems such as fixed dimension. Considering the contingency of the test results, we further analyze the experimental results from the perspective of statistical tests. From
Table 4, only two functions are better than the algorithm. FLAS is obviously superior to PSO_ELPM, HHO, DE, LSO, FLA, BWO, IGJO, AOA, and IGWO algorithms. Therefore, in the reference function, the FLAS converges significantly better. From the experimental results, it can be found that the proposed algorithm can effectively solve the single-peak as well as multi-peak optimization problems, and obtain better optimization results. But it can and will have a longer running time.
4.4. Comparison between FLAS and Other MAs on CEC2020
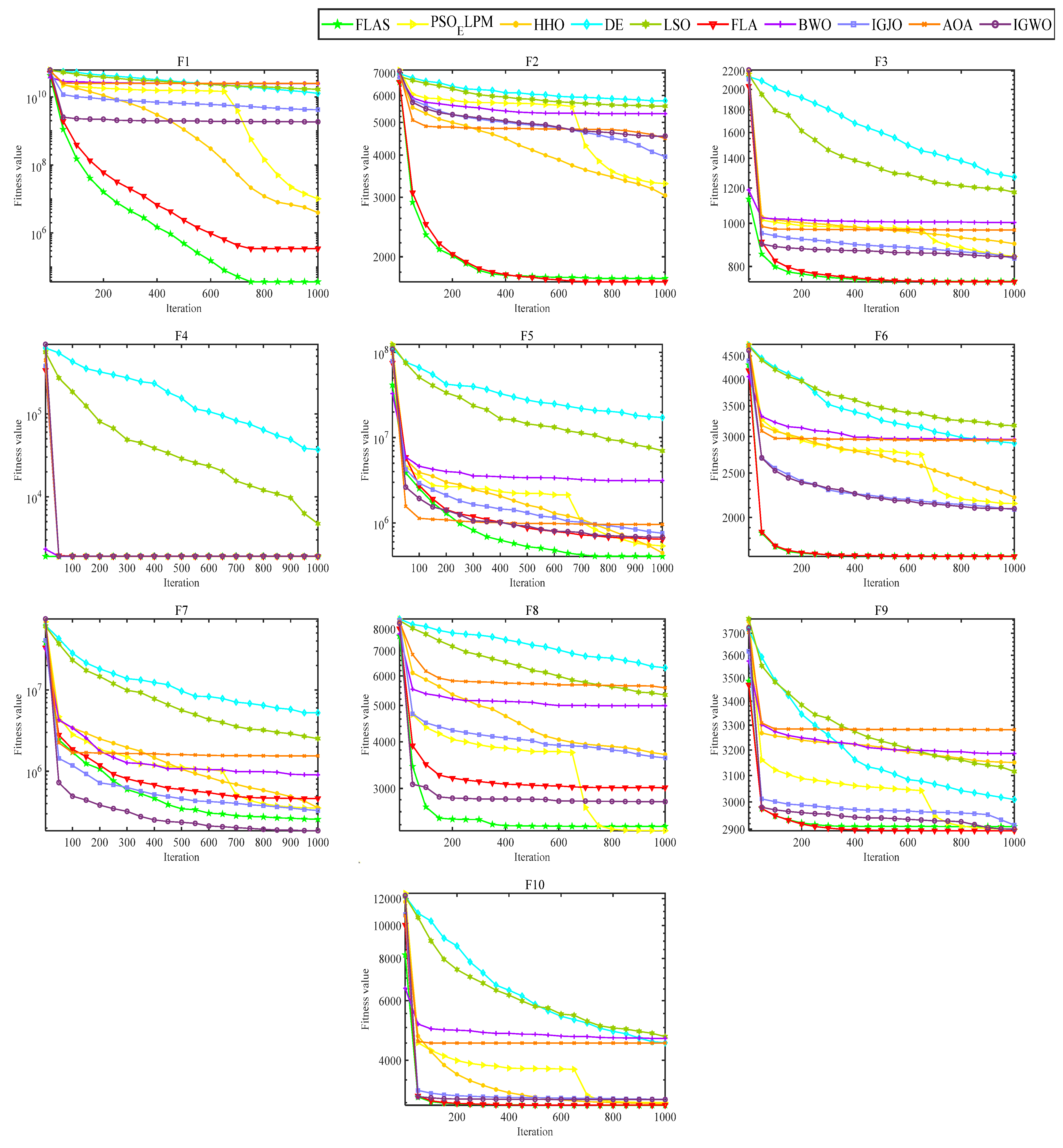
FLAS and other MAs are analyzed on the CEC2020 test set. The value has 20 dimensions and runs 30 times independently. As shown in
Table 5, FLAS ranks first in F1, F4-F5, and F10. Among the ten algorithms, FLAS was in the top three on 90% of the tested functions. In
Figure 11, FLAS converges the fastest of all functions except F6.
Figure 12 shows a boxplot of MAs and data distribution for MAs.
Figure 13 shows the radar plot of MAs. According to the data listed in
Table 6, among the nine groups of comparison algorithms, only one function of the PSO_ELPM algorithm is superior to FLAS, and the others are inferior to FLAS.
4.5. Comparison of FLAS and DIRECT in CEC2020
In order to further validate the convergence and optimization performance of the proposed FLAS in the face of complex optimization problems, this section conducts experiments comparing FLAS with the well-known deterministic optimization method, DIRECT [
41], in the CEC2020 test function. To ensure the validity of the experiments, both FLAS and DIRECT perform 10,000 function evaluation times [
42]. Meanwhile, the population of FLAS is set to 30. for the CEC2020 test function, the dimension of all ten functions is set to 10.
Figure 14 gives the operational zones built using 30 runs performed by the FLAS method and operational characteristics for the DIRECT method on ten CEC2020 functions. The upper and the lower boundaries of the zone are shown as dark blue curves [
43].
As can be seen from the experimental result plots, the algorithmic performance of the proposed FLAS is competitive with the deterministic methods. FLAS demonstrates absolute optimization advantages in cec02, cec05, cec06, and cec07. The worst results of FLAS are comparable to or even better than those of DIRECT. For cec01, cec08, cec09, and cec10 test functions, the results of DIRECT optimize the average results of FLAS and are comparable to the best results of FLAS. In contrast, the optimal results for FLAS tend to be optimized better, indicating that FLAS has a higher upper bound. For cec04, both FLAS and DIRECT obtained optimal results. Only on cec03 did DIRECT obtain better results than FLAS. Thus, FLAS can also obtain better optimization results than deterministic methods.
In addition, in order to effectively demonstrate the convergence situation of FLAS, we give plots of the convergence results of the ten test functions of CEC2020 for different numbers of function evaluations. Considering that the convergence speed of FLAS varies for different test functions, the number of function evaluations is set to 10,000 for the cec01–cec04, cec06, and cec08–cec10 test functions. For the cec05 and cec07 test functions, the number of function evaluations is set to 30,000. The graphs of the convergence of FLAS are given in
Figure 15. In order to minimize the negative impact of the resultant magnitude on the presentation of the convergence plot results, only the convergence results for cec01 are given in
Figure 15a.
From the results of the convergence plots, it can be found that FLAS guarantees effective convergence for different test functions.
6. Parameter Estimation of Solar Photovoltaic Model
The high-precision estimation of solar PV parameters is an urgent problem in power systems and the key to improving the output of power systems. In this section, parameters of the single diode model (SDM) in the photovoltaic (PV) model [
64] are optimized by using to explore its effectiveness further. In the experiment, two sets of data [
65] from the RTC France PV module and the Photowatt-PWP201 PV module were used to estimate the parameters of the SDM model of the RTC France PV module; the unknown parameters of the Photowatt-PWP201 PV module were estimated.
Because of its simplicity, SDM has wide applications in simulating the performance of solar photovoltaic systems, and its structure is shown in
Figure 23.
The relationship between the PV current, diode current and resistance current in the circuit and the output current is expressed as follows:
where
is the output current of SDM,
is the photovoltaic current,
represents the reverse saturation current of SDM,
is the output voltage,
and
warm are the series resistance and parallel resistance of SDM, respectively,
e is the electronic charge, usually 1.60217646 × 10-19C,
n is the ideal factor of a single diode,
I is the Boltzmann constant with a value of 1.3806503 × 10
−23 J/K, and
Tk is the Kelvin temperature [
66]. In Formula (68), since
I,
e and
Tk are all fixed constants, there are five parameters to be optimized in SDM:
and
n, constituting a decision variable of
XSDM =
parameter optimization problem.
PV Parameter Optimization Model and Experimental Setup
In a photovoltaic system, the output voltage
and output current
are the actual data measured in the experiment. The goal of the model is to find the values of unknown parameters [
67] through MAs to minimize error. Jiao et al. [
68] used the root-mean-square error to measure the deviation, and, based on this, they established a PV system parameter optimization model as follows:
where
X represents the set of unknown parameters,
k = 1 represents the label of the SDM module model, and
Nk represents the amount of data obtained for the
K-th model.
represents the error when the
i-th output voltage and current of the
k type model are
,
, respectively.
where
and
represent the left and right ends of the output current, respectively, FLAS is used to find the vector
X that minimizes
RMSEk(
X). The absolute error (IAE) and relative error are used to evaluate the performance of the algorithm more accurately.
where
is a real current value measured and
is a model current value calculated when the parameter is optimized.
In the experiment, the current and voltage values obtained with
Nk = 26 pairs of French RTC photovoltaic cells at temperatures of 1000 W/m
2 and 33 °C were used as experimental data to estimate SDM and DDM model parameters. The current and voltage values of 36 polycrystalline silicon cells at 45 °C and low irradiance of 1000 W/m
2 were connected as experimental data to estimate [
69].
Table 21 lists some relevant parameters of SDM [
70],
Lb and
Ub, on behalf of the upper and lower bounds. The parameters of all remaining algorithms are the same.
Table 22 shows that FLAS performs well in performance evaluation compared to other MAs, significantly improving processing efficiency and achieving higher accuracy. This result undoubtedly strengthens the competitive advantage of FLAS in the field of intelligent computing.
Table 22 shows the 26 groups of measured voltage
V, current
I and power
P data of SDM, as well as the results of current
Im, absolute current error
IAEI and absolute power error
IAEP estimated using FLAS; the absolute current error is all less than 1.61E-03. Combined with the curves in
Figure 24a,b, the current data
Im and voltage data Pm calculated using FLAS are highly close to the actual data
I and
P.
Figure 24c,d shows the
IAE and
RE of the simulated current; there is a high similarity between the experimental data and the estimated data. The FLAS is a method that can accurately estimate SDM parameters.
At the same time, using FLAS to seek SDM related Parameters,
Table 23 shows the comparison results of five parameter values obtained using eight other MAs such as FLA, DMOA [
69], IPSO [
71], IGWO, ISSA [
72], CSA [
73], SCHO [
74], and TSA to estimate SDM and
RMSE. The
RMSE value of FLAS is 1.09E-03. In summary, FLAS can find the solution faster, and the optimal solution is more accurate and stable. The results show that FLAS improves the output efficiency of the model.
7. Conclusions and Future Prospects
This paper proposes a multi-strategy augmented Fick’s law optimization algorithm to improve performance in facing high-dimensional and high-complexity problems, which combines the differential mutation strategy, Gaussian local mutation strategy, interweaving-based comprehensive learning strategy, and seagull update strategy. First, in the DO phase, FLAS improves the search diversity by adding differential and Gaussian local variation strategies, which further improves the aggregation efficiency and exploration capability in later iterations. In addition, the improved algorithm can effectively enhance search capability and stochasticity by introducing an integrated cross-based comprehensive learning strategy in the EO phase. Secondly, by introducing the Levy flight strategy in the position update, the Levy distribution can be effectively utilized to generate random steps to improve the search space’s overall randomization ability. Further, influenced by the idea of a seagull algorithm, FLAS introduces a migration strategy in the SSO stage to avoid the transition aggregation of molecules effectively. FLAS compares and analyzes other excellent improved algorithms, and the latest search algorithms on 23 benchmark functions and CEC2020. The results show that FLAS provides dominant results, especially when dealing with multimodal test functions. However, there is still room for further improvement in the ability of FLAS to face unimodal functions. In addition, the FLAS proposed in this paper is applied to seven real-world engineering optimization problems. The results show that the proposed algorithm has advantages in terms of computational power and convergence accuracy. Finally, FLAS is applied to the parameter estimation of solar PV models, and the experimental results demonstrate the applicability and potential of the proposed algorithm in engineering applications.
In future work, we will consider adding strategies at the initial population phase, such as Tent, Cubic chaos mapping, etc., and further improve the optimization capability of algorithm through different adaptive selection parameter values or combining them with other strategies. Enhanced optimized performance through more diverse test sets more challenging engineering applications for detailed testing. In addition, image feature selection [
75,
76], multi-objective problems [
77], image segmentation [
78,
79], path planning [
80,
81,
82], truss topology optimization [
83], and shape optimization [
84] can all be experimentally solved with FLAS.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}