
E-DQN-Based Path Planning Method for Drones in Airsim Simulator under Unknown Environment
Abstract
1. Introduction
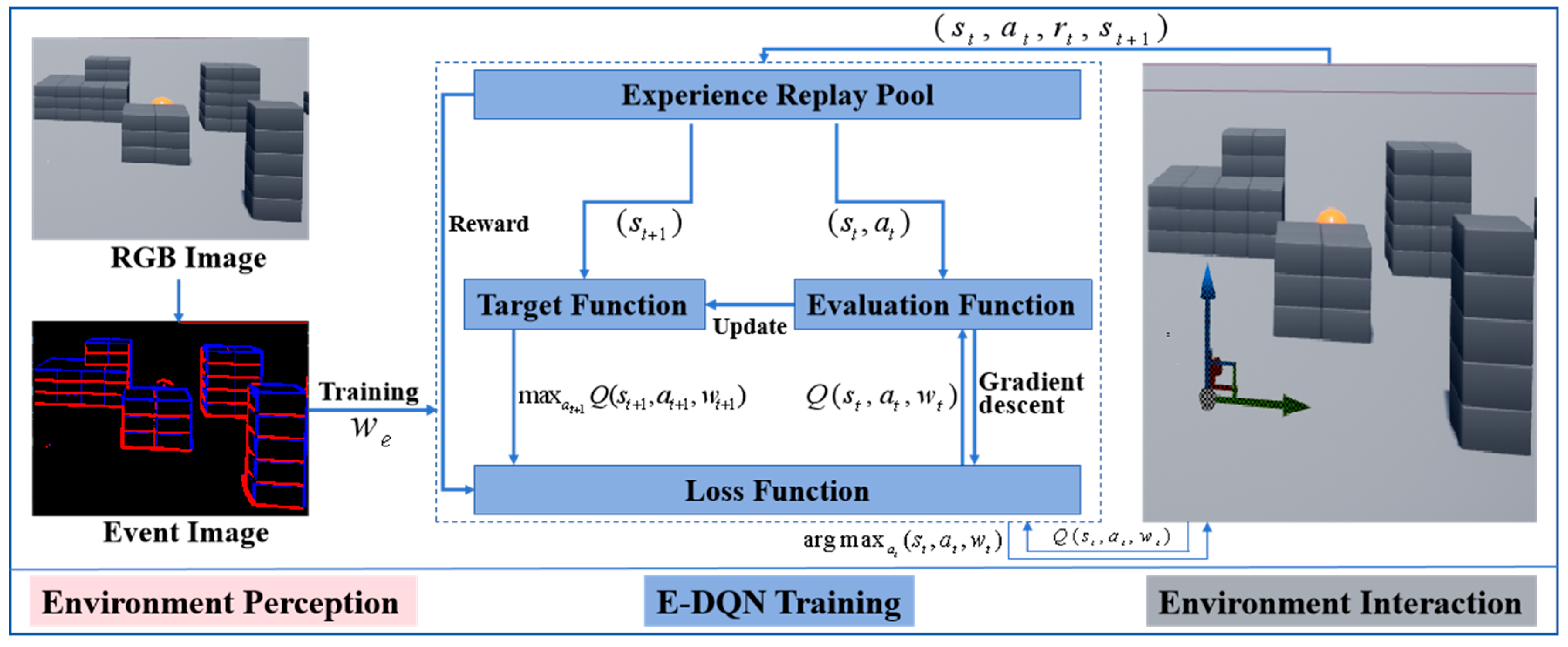
2. System Framework
3. E-DQN-Based Path-Planning Method
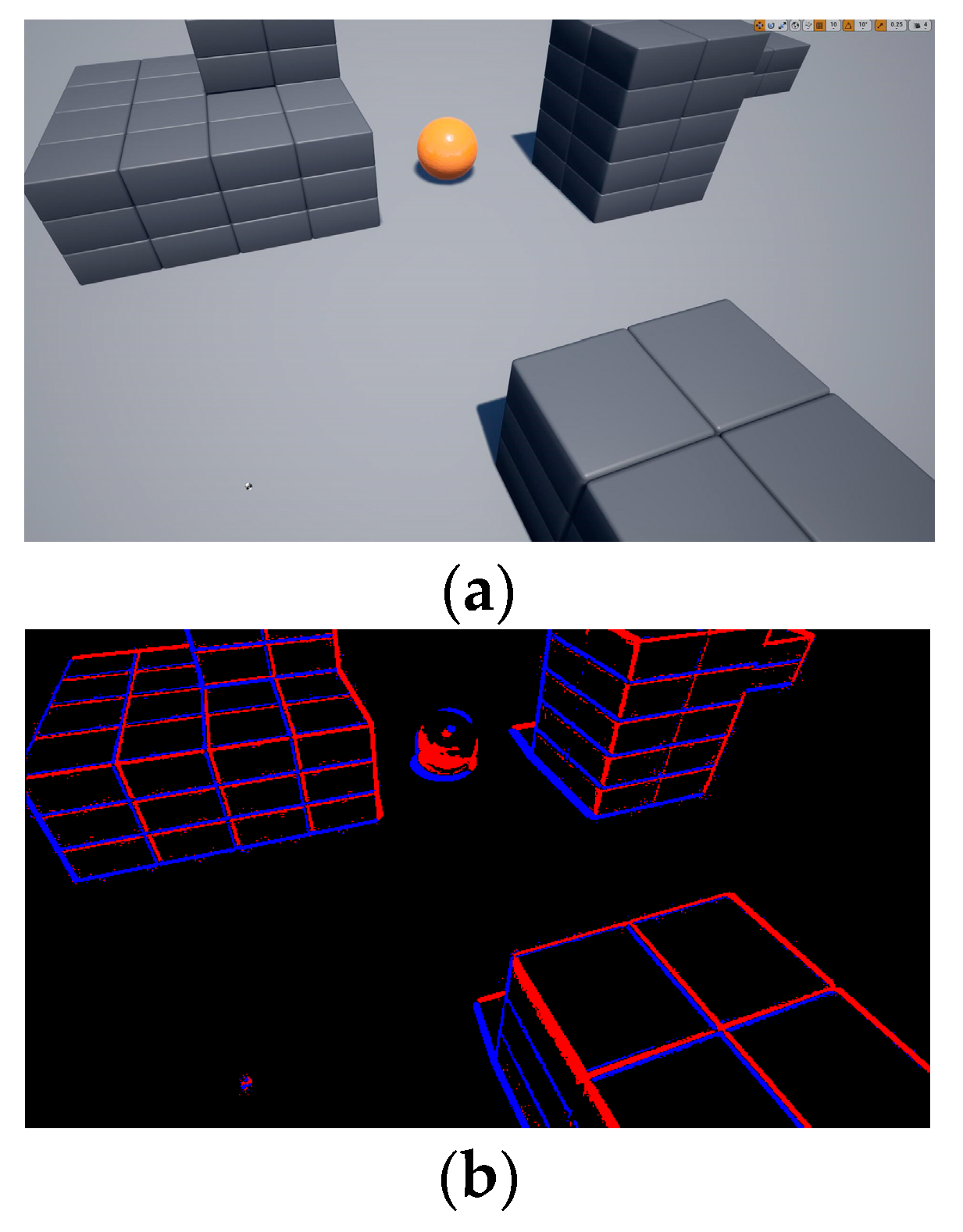
3.1. Bio-Inspired Environment Perception
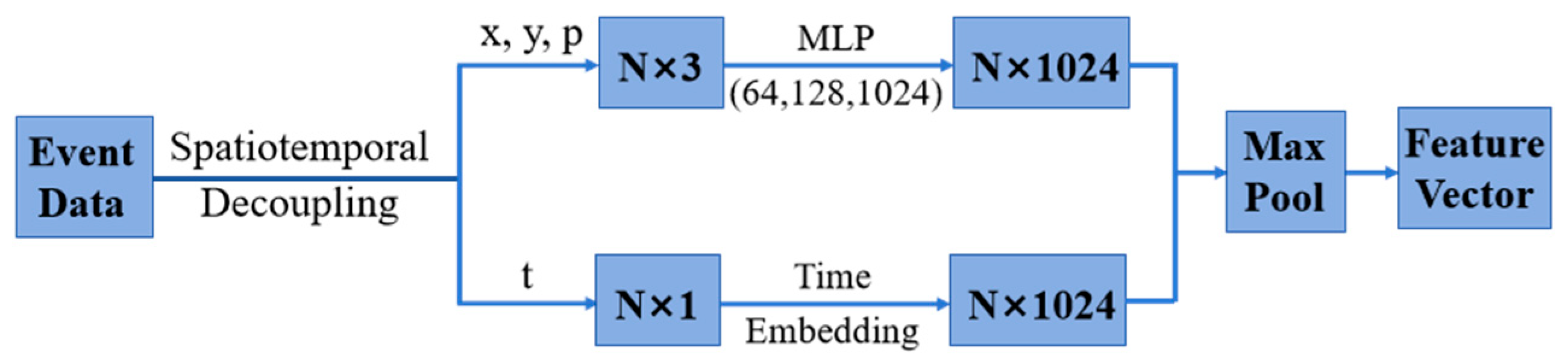
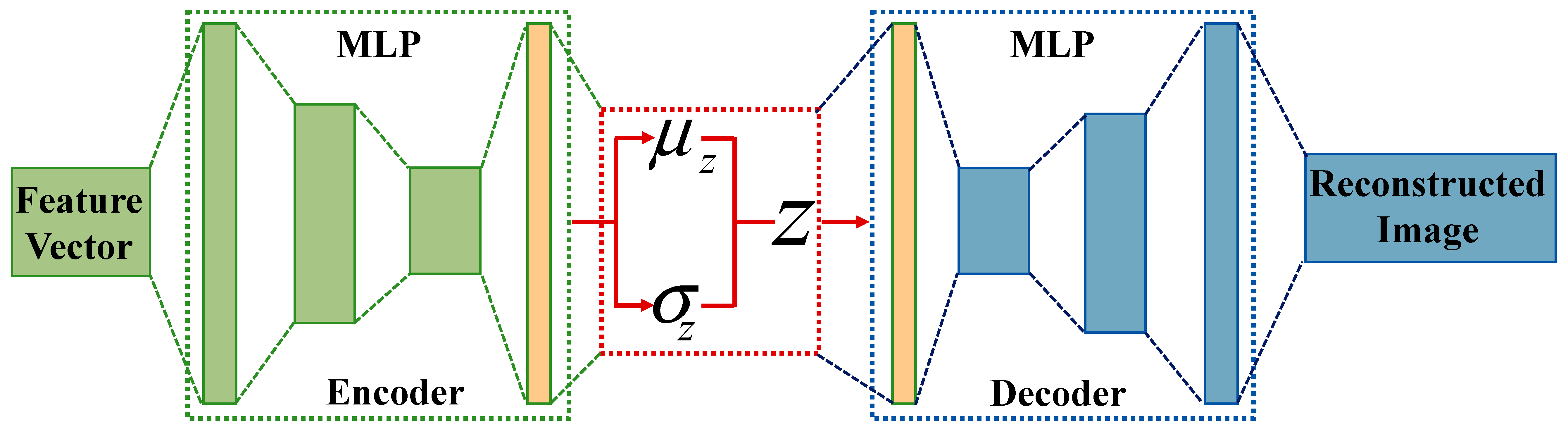
3.2. Feature Extraction of Event Data
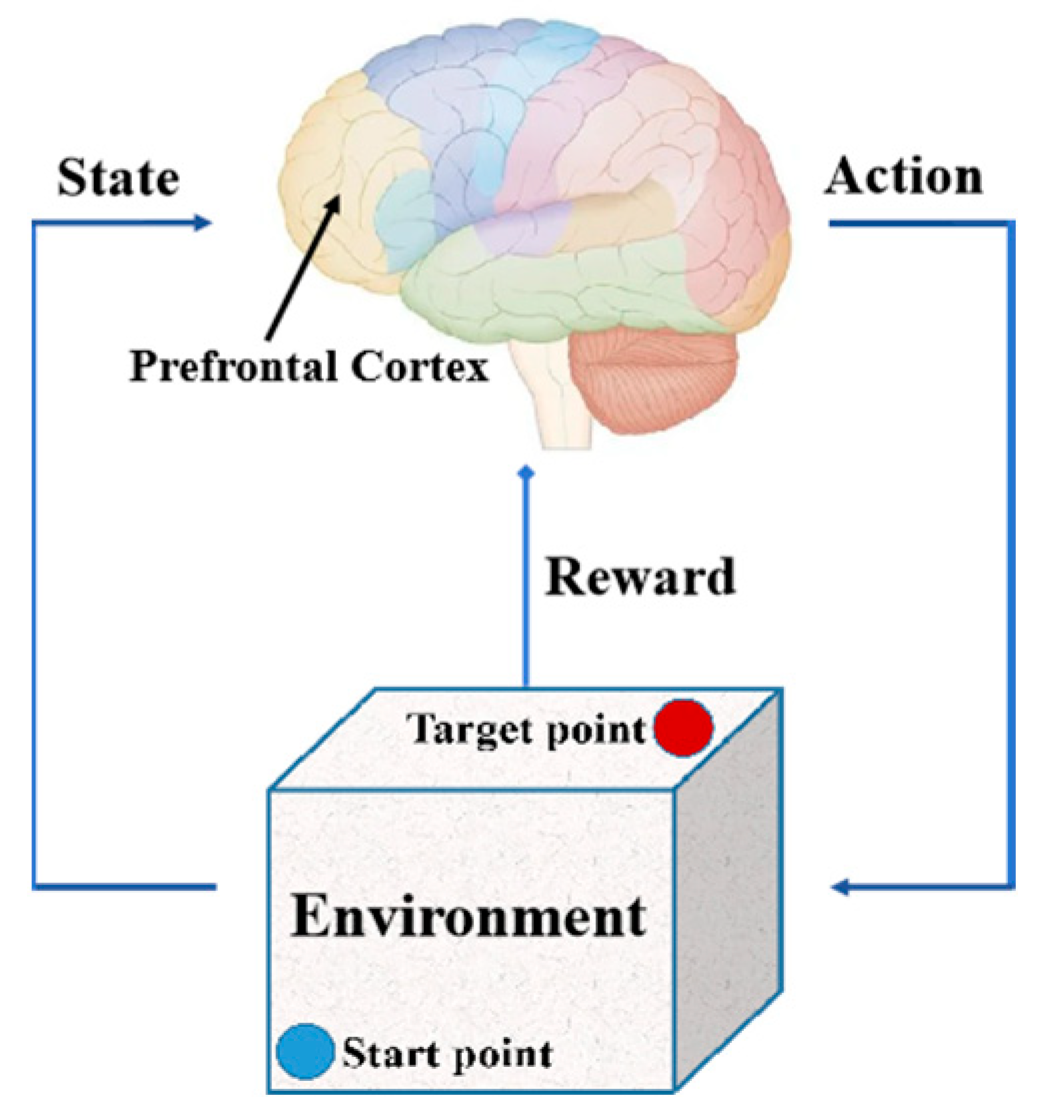
3.3. E-DQN Training of Drones
| Algorithm 1. E-DQN training process for bio-inspired path planning of drones in complex environments. |
| 1: Input: ; Event weight We |
| 2: Output: Optimal path |
| 3: Initialize: |
| 4: |
| 5: strategy. |
| 6: and . |
| 7: |
| 8: |
| 9: Introduce experience replay and update parameters |
| 10: end for |
4. Experiments
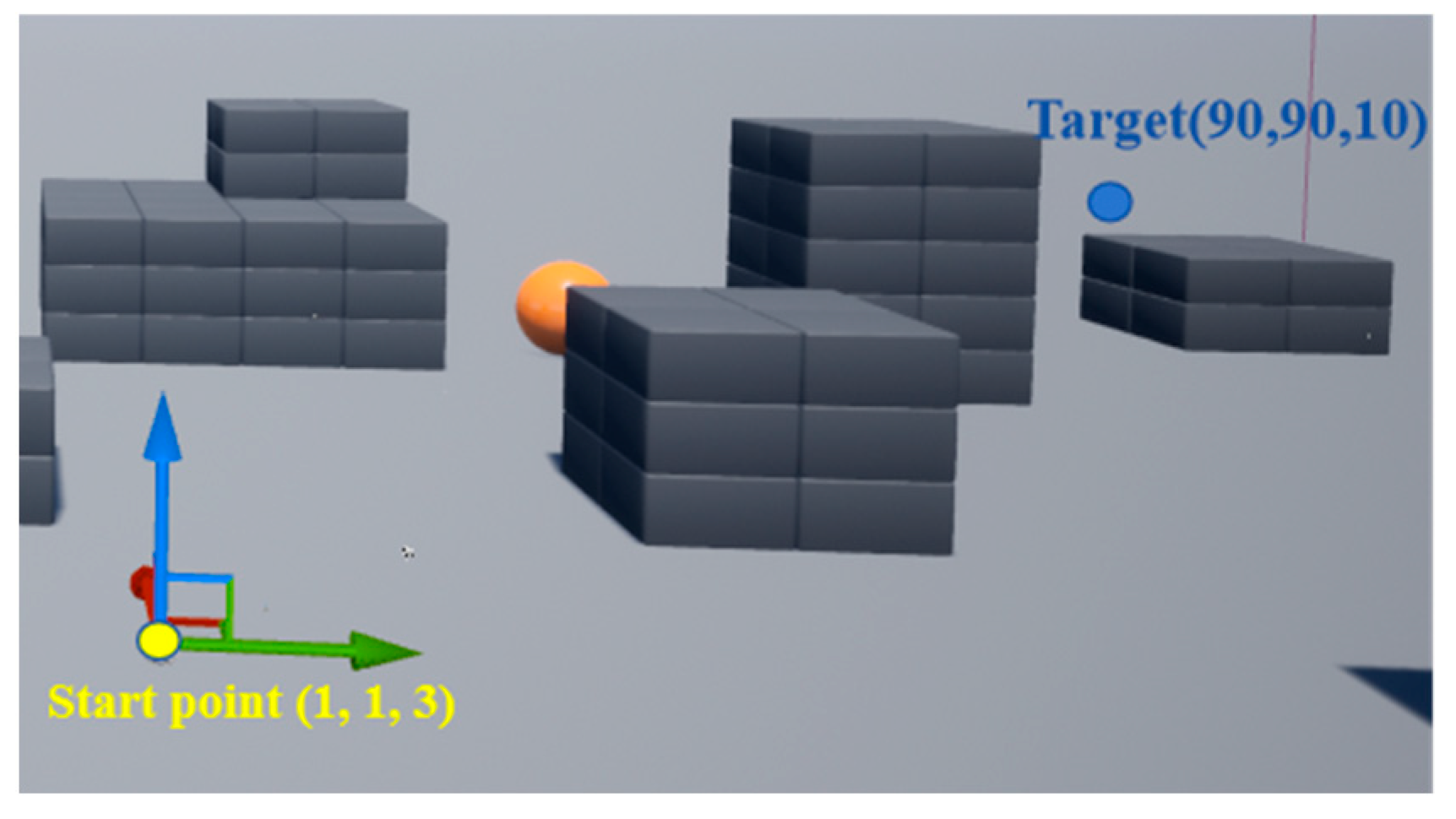
4.1. Experimental Setup
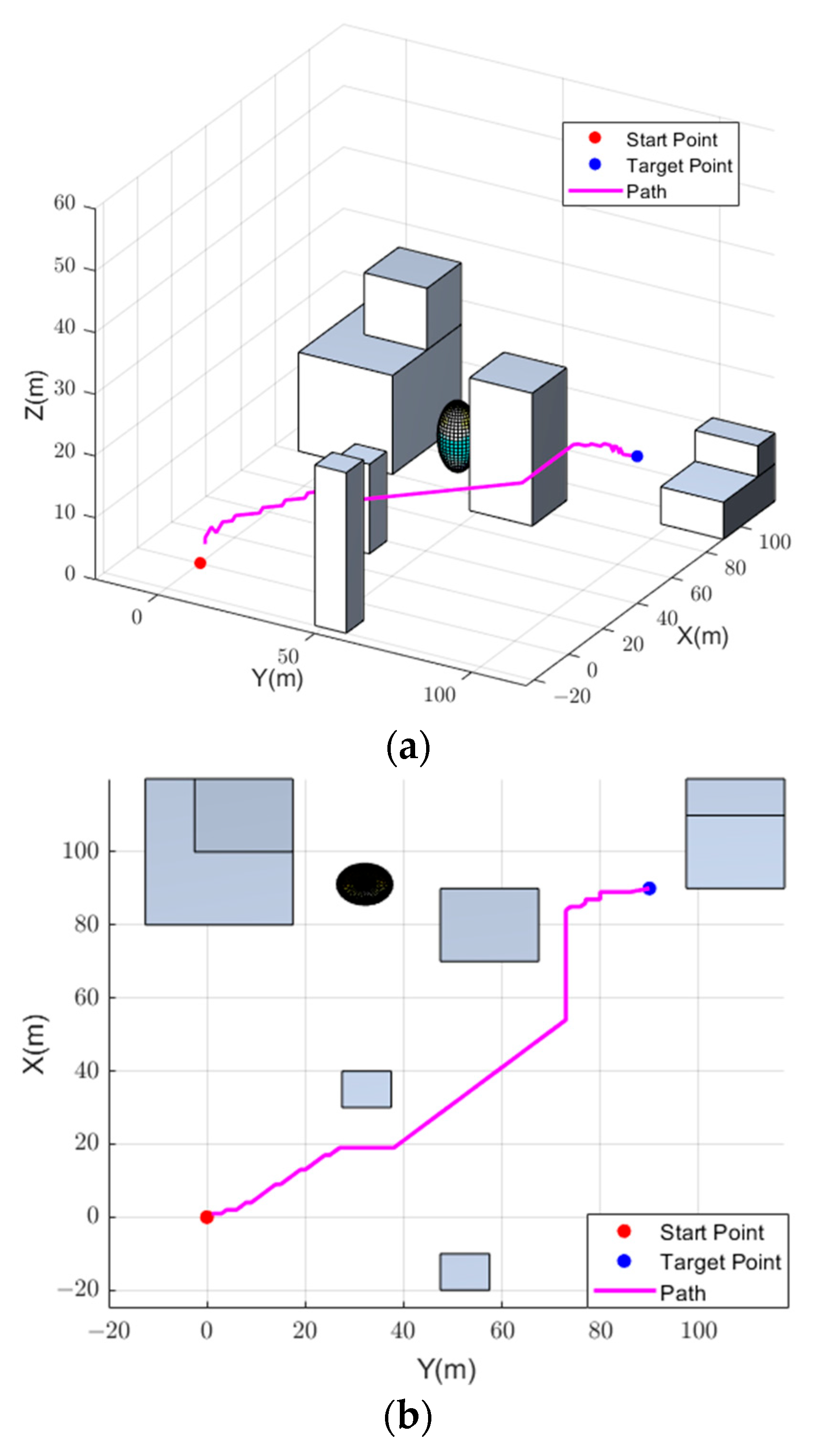
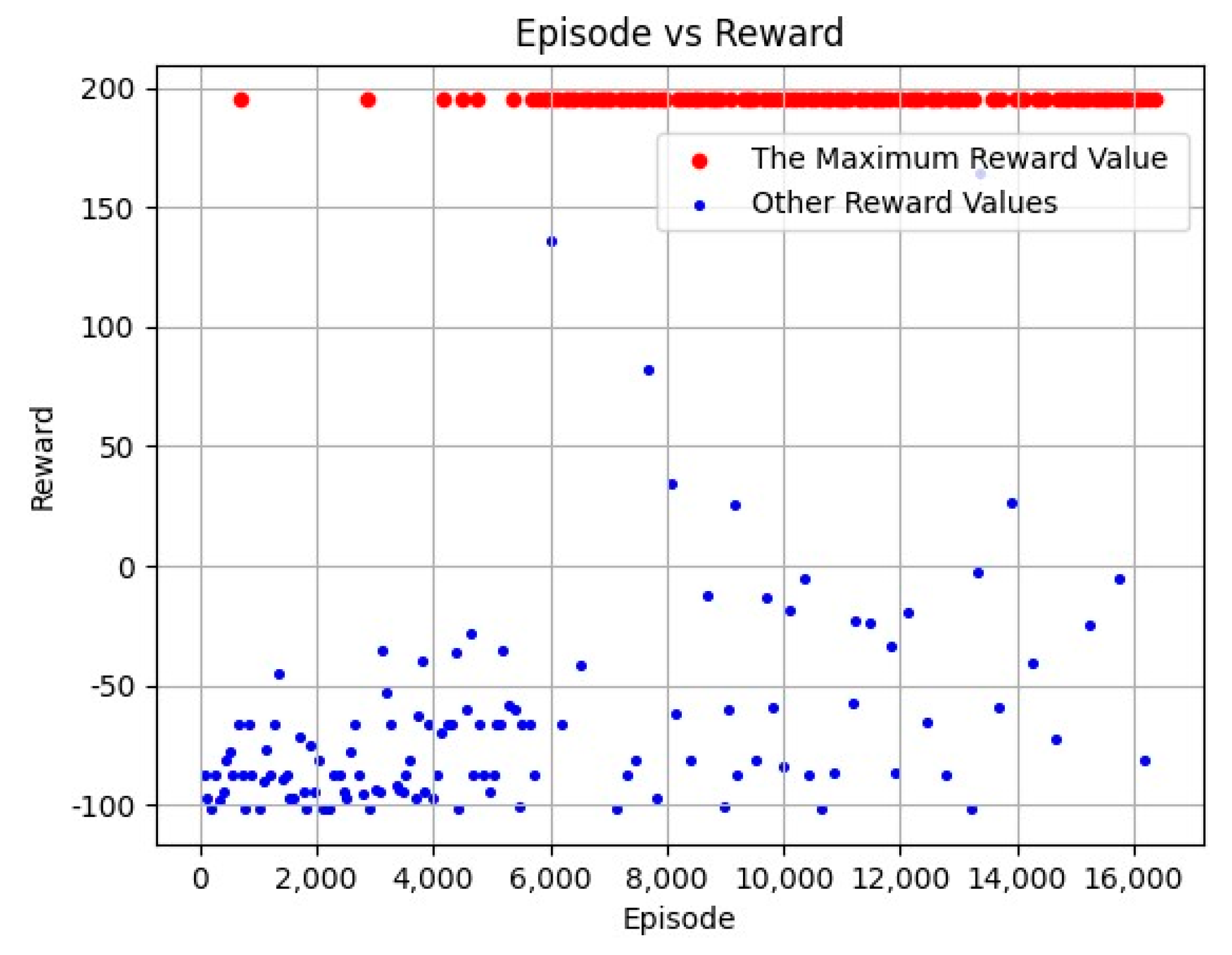
4.2. Experimental Results
5. Conclusions
- (1)
- An event auto-encoder for the unsupervised representation learning is presented from fast and asynchronous spatiotemporal event byte stream data.
- (2)
- Motion policies are trained over event representations using the DQN for path planning for drones, which is superior to traditional path-planning algorithms.
- (3)
- The dopamine reward mechanism is adopted for obstacle avoidance, which is more in line with animal action decision-making behavior.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ramalepa, L.P.; Jamisola, R.S. A review on cooperative robotic arms with mobile or drones bases. Int. J. Autom. Comput. 2021, 18, 536–555. [Google Scholar] [CrossRef]
- Quinones, G.M.; Biswas, G.; Ahmed, I.; Darrah, T.; Kulkarni, C. Online decision making and path planning framework for safe operation of unmanned aerial vehicles in urban scenarios. Int. J. Progn. Health Manag. 2021, 12, 1–17. [Google Scholar]
- Martinez, N.A.; Lu, L.; Campoy, P. Fast RRT* 3D-sliced planner for autonomous exploration using MAVs. Unmanned Syst. 2022, 10, 175–186. [Google Scholar] [CrossRef]
- Mohammed, H.; Romdhane, L.; Jaradat, M.A. RRT* N: An efficient approach to path planning in 3D for static and dynamic environments. Adv. Robot. 2021, 35, 168–180. [Google Scholar] [CrossRef]
- Rostami, S.M.H.; Sangaiah, A.K.; Wang, J.; Liu, X. Obstacle avoidance of mobile robots using modified artificial potential field algorithm. EURASIP J. Wirel. Commun. Netw. 2019, 1, 70. [Google Scholar] [CrossRef]
- Duchon, F.; Babinec, A.; Kajan, M.; Beňo, P.; Florek, M.; Fico, T.; Jurišica, L. Path planning with modified a star algorithm for a mobile robot. Procedia Eng. 2014, 96, 59–69. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Nguyen, X.T.; Pham, D.A.; Tran, B.L.; Bui, D.B. A new approach for mobile robot path planning based on RRT algorithm. Mod. Phys. Lett. B 2023, 37, 2340027. [Google Scholar] [CrossRef]
- Sabudin, E.N.; Omar, R.; Debnath, S.K.; Sulong, M.S. Efficient robotic path planning algorithm based on artificial potential field. Int. J. Electr. Comput. Eng. 2021, 11, 4840–4849. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Y. Mobile robot path planning algorithm based on improved a star. J. Phys. Conf. Ser. 2021, 1848, 012013. [Google Scholar] [CrossRef]
- Machmudah, A.; Shanmugavel, M.; Parman, S.; Manan, T.S.A.; Dutykh, D.; Beddu, S.; Rajabi, A. Flight trajectories optimization of fixed-wing UAV by bank-turn mechanism. Drones 2022, 6, 69. [Google Scholar] [CrossRef]
- Hu, H.; Wang, Y.; Tong, W.; Zhao, J.; Gu, Y. Path planning for autonomous vehicles in unknown dynamic environment based on deep reinforcement learning. Appl. Sci. 2023, 13, 10056. [Google Scholar] [CrossRef]
- Xie, R.; Meng, Z.; Wang, L.; Li, H.; Wang, K.; Wu, Z. Unmanned aerial vehicle path planning algorithm based on deep reinforcement learning in large-scale and dynamic environments. IEEE Access 2021, 9, 24884–24900. [Google Scholar] [CrossRef]
- Banino, A.; Barry, C.; Uria, B.; Blundell, C.; Lillicrap, T.; Mirowski, P.; Pritzel, A.; Chadwick, M.J.; Degris, T.; Modayil, J.; et al. Vector-based navigation using grid-like representations in artificial agents. Nature 2018, 557, 429–433. [Google Scholar] [CrossRef] [PubMed]
- Edvardsen, V. Goal-directed navigation based on path integration and decoding of grid cells in an artificial neural network. Nat. Comput. 2019, 18, 13–27. [Google Scholar] [CrossRef]
- Wang, S.; Xie, X.; Huang, K.; Zeng, J.; Cai, Z. Deep reinforcement learning-based traffic signal control using high-resolution event-based data. Entropy 2019, 21, 744. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhou, M.; Li, Z. An intelligent train operation method based on event-driven deep reinforcement learning. IEEE Trans. Ind. Inform. 2021, 18, 6973–6980. [Google Scholar] [CrossRef]
- Menda, K.; Chen, Y.C.; Grana, J.; Bono, J.W.; Tracey, B.D.; Kochenderfer, M.J.; Wolpert, D. Deep reinforcement learning for event-driven multi-agent decision processes. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1259–1268. [Google Scholar] [CrossRef]
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep q-learning from demonstrations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 29 April 2018; Volume 32. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In Field and Service Robotics: Results of the 11th International Conference; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 621–635. [Google Scholar]
- Falanga, D.; Kleber, K.; Scaramuzza, D. Dynamic obstacle avoidance for quadrotors with event cameras. Sci. Robot. 2020, 5, 9712. [Google Scholar] [CrossRef] [PubMed]
- Andersen, P.A.; Goodwin, M.; Granmo, O.C. Towards safe reinforcement-learning in industrial grid-warehousing. Inf. Sci. 2020, 537, 467–484. [Google Scholar] [CrossRef]
- Xie, D.; Hu, R.; Wang, C.; Zhu, C.; Xu, H.; Li, Q. A simulation framework of unmanned aerial vehicles route planning design and validation for landslide monitoring. Remote Sens. 2023, 15, 5758. [Google Scholar] [CrossRef]
- Buck, A.; Camaioni, R.; Alvey, B.; Anderson, D.T.; Keller, J.M.; Luke, R.H., III; Scott, G. Unreal engine-based photorealistic aerial data generation and unit testing of artificial intelligence algorithms. In Geospatial Informatics XII; SPIE: Orlando, FL, USA, 2022; Volume 12099, pp. 59–73. [Google Scholar]
- Available online: https://microsoft.github.io/AirSim/event_sim/ (accessed on 30 December 2023).
- Vemprala, S.; Mian, S.; Kapoor, A. Representation learning for event-based visuomotor policies. Adv. Neural Inf. Process. Syst. 2021, 34, 4712–4724. [Google Scholar]
- Zhou, J.; Komuro, T. Recognizing fall actions from videos using reconstruction error of variational autoencoder. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3372–3376. [Google Scholar]
- Si, J.; Harris, S.L.; Yfantis, E. A dynamic ReLU on neural network. In Proceedings of the 2018 IEEE 13th Dallas Circuits and Systems Conference (DCAS), Dallas, TX, USA, 12 November 2018; pp. 1–6. [Google Scholar]
- Rynkiewicz, J. Asymptotic statistics for multilayer perceptron with ReLU hidden units. Neurocomputing 2019, 342, 16–23. [Google Scholar] [CrossRef]
- Low, E.S.; Ong, P.; Cheah, K.C. Solving the optimal path planning of a mobile robot using improved Q-learning. Robot. Auton. Syst. 2019, 115, 143–161. [Google Scholar] [CrossRef]
- Coy, M.V.C.; Casallas, E.C. Training neural networks using reinforcement learning to reactive path planning. J. Appl. Eng. Sci. 2021, 19, 48–56. [Google Scholar]
- Ab Azar, N.; Shahmansoorian, A.; Davoudi, M. Uncertainty-aware path planning using reinforcement learning and deep learning methods. Comput. Knowl. Eng. 2020, 3, 25–37. [Google Scholar]
- Kim, C. Deep Q-Learning Network with Bayesian-Based Supervised Expert Learning. Symmetry 2022, 14, 2134. [Google Scholar] [CrossRef]
- Rubí, B.; Morcego, B.; Pérez, R. Quadrotor path following and reactive obstacle avoidance with deep reinforcement learning. J. Intell. Robot. Syst. 2021, 103, 62. [Google Scholar] [CrossRef]
- Chao, Y.; Augenstein, P.; Roennau, A.; Dillmann, R.; Xiong, Z. Brain inspired path planning algorithms for drones. Front. Neurorobotics 2023, 17, 1111861. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Discount rate | 0.99 |
| Time constant | 0.005 |
| Batch_size | 128 |
| Hidden_dim | 16 |
| Learning_rate | 0.0004 |
| Num_episodes | 40,000 |
| Max_eps_episode | 10 |
| threshold | 200 |
| State_dim | 42 |
| Action_dim | 27 |
| Parameter | Value |
|---|---|
| membrane time constant | 0.002 |
| rest membrane potential | 0 mV |
| membrane resistance | 20 M |
| pre-amplitude | 1.0 |
| post-amplitude | 1.0 |
| pre-time constant | 0.0168 |
| post-time constant | 0.0337 |
| Method | Run Time (s) |
|---|---|
| E-DQN | 41.364 |
| DQN | 161.88 |
| SNN | 155.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, Y.; Dillmann, R.; Roennau, A.; Xiong, Z. E-DQN-Based Path Planning Method for Drones in Airsim Simulator under Unknown Environment. Biomimetics 2024, 9, 238. https://doi.org/10.3390/biomimetics9040238
Chao Y, Dillmann R, Roennau A, Xiong Z. E-DQN-Based Path Planning Method for Drones in Airsim Simulator under Unknown Environment. Biomimetics. 2024; 9(4):238. https://doi.org/10.3390/biomimetics9040238
Chicago/Turabian StyleChao, Yixun, Rüdiger Dillmann, Arne Roennau, and Zhi Xiong. 2024. "E-DQN-Based Path Planning Method for Drones in Airsim Simulator under Unknown Environment" Biomimetics 9, no. 4: 238. https://doi.org/10.3390/biomimetics9040238
APA StyleChao, Y., Dillmann, R., Roennau, A., & Xiong, Z. (2024). E-DQN-Based Path Planning Method for Drones in Airsim Simulator under Unknown Environment. Biomimetics, 9(4), 238. https://doi.org/10.3390/biomimetics9040238