
Multivariate Independent Component Analysis Identifies Patients in Newborn Screening Equally to Adjusted Reference Ranges

 , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Patients and Samples
2.2. DBS Analysis by Mass Spectrometry
2.3. Data Analysis—ICA
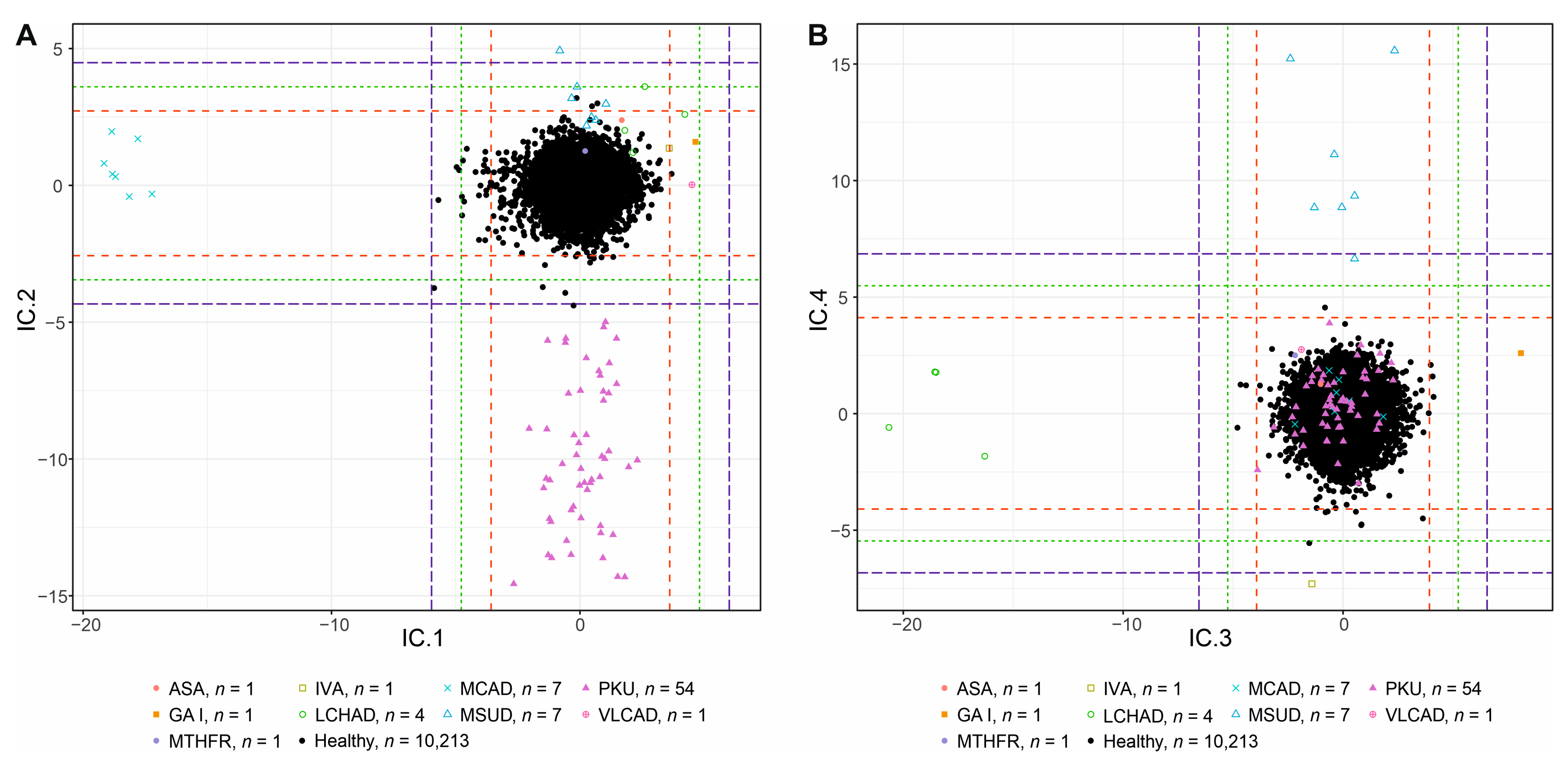
3. Results and Discussion
3.1. Interpretation of Components
3.1.1. IC1—MCADD × VLCAD/LCHAD/IVA/GAI
3.1.2. IC2—PKU × MSUD
3.1.3. IC3—LCHAD × GAI
3.1.4. IC4—MSUD × IVA
3.1.5. IC5—Weights
3.1.6. IC6—GAI
3.1.7. IC7—ASA
3.1.8. IC8—IVA
3.1.9. Other ICs
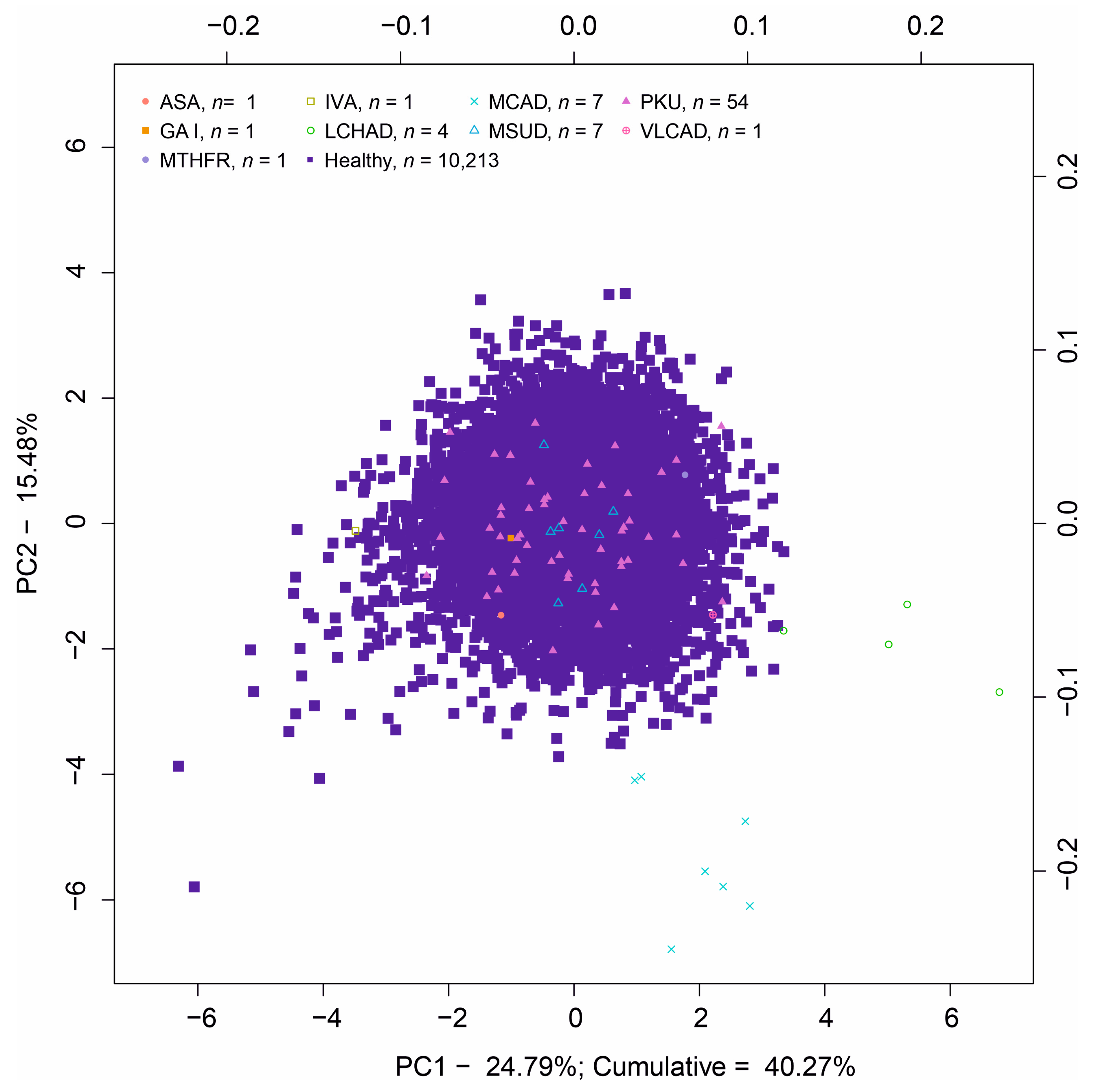
3.2. Principal Component Analysis
3.3. Comparison of Diagnostic Performance with the Routine Screening Procedure
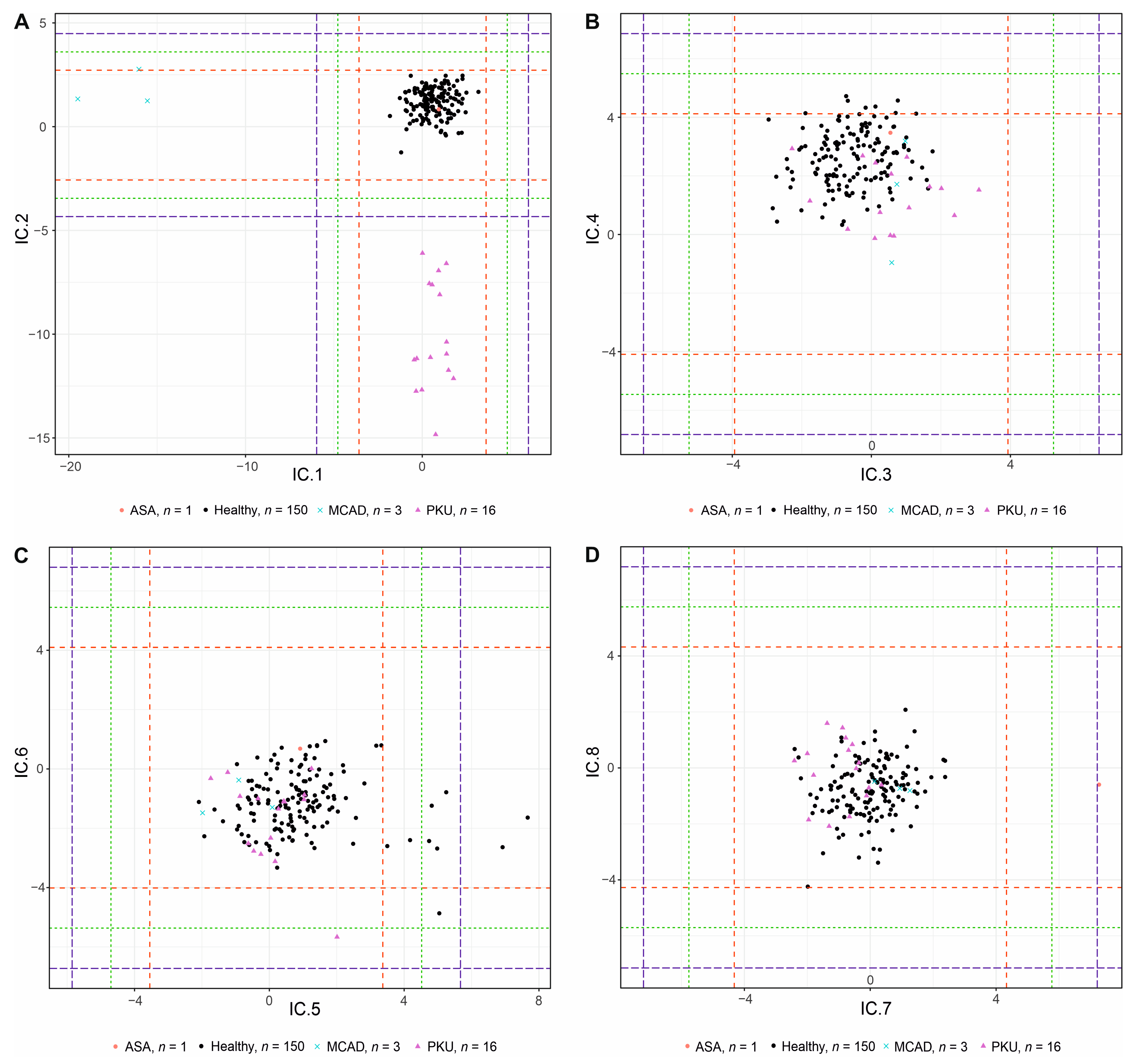
3.4. Validation Study
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chace, D.H.; Kalas, T.A.; Naylor, E.W. Use of tandem mass spectrometry for multianalyte screening of dried blood specimens from newborns. Clin. Chem. 2003, 49, 1797–1817. [Google Scholar] [CrossRef]
- Maccready, R.A.; Hussey, M.G. Newborn phenylketonuria detection program in Massachusetts. Am. J. Public Health Nations Health 1964, 54, 2075–2081. [Google Scholar] [CrossRef]
- McHugh, D.M.S.; Cameron, C.A.; Abdenur, J.E.; Abdulrahman, M.; Adair, O.; Al Nuaimi, S.A.; Åhlman, H.; Allen, J.J.; Antonozzi, I.; Archer, S.; et al. Clinical validation of cutoff target ranges in newborn screening of metabolic disorders by tandem mass spectrometry: A worldwide collaborative project. Genet. Med. 2011, 13, 230–254. [Google Scholar] [CrossRef] [PubMed]
- Hsia, D.Y.Y. Phenylketonuria: The phenylalanine-tyrosine ratio in the detection of the heterozygous carrier. J. Ment. Defic. Res. 1958, 2, 8–16. [Google Scholar] [CrossRef] [PubMed]
- Wilson, J.M.G.; Jungner, G. Principles and Practice of Screening for Disease; World Health Organization: Geneva, Switzerland, 1968. [Google Scholar]
- Chace, D.H.; Millington, D.S.; Terada, N.; Kahler, S.G.; Roe, C.R.; Hofman, L.F. Rapid diagnosis of phenylketonuria by quantitative analysis for phenylalanine and tyrosine in neonatal blood spots by tandem mass spectrometry. Clin. Chem. 1993, 39, 66–71. [Google Scholar] [CrossRef] [PubMed]
- Eastman, J.; Sherwin, J.; Wong, R.; Liao, C.; Currier, R.; Lorey, F.; Cunningham, G. Use of the phenylalanine:tyrosine ratio to test newborns for phenylketonuria in a large public health screening programme. J. Med. Screen. 2000, 7, 131–135. [Google Scholar] [CrossRef] [PubMed]
- Jager, E.A.; Kuijpers, M.M.; Bosch, A.M.; Mulder, M.F.; Gozalbo, E.R.; Visser, G.; de Vries, M.; Williams, M.; Waterham, H.R.; van Spronsen, F.J.; et al. A nationwide retrospective observational study of population newborn screening for medium-chain acyl-CoA dehydrogenase (MCAD) deficiency in the Netherlands. J. Inherit. Metab. Dis. 2019, 42, 890–897. [Google Scholar] [CrossRef]
- Tajima, G.; Hara, K.; Tsumura, M.; Kagawa, R.; Okada, S.; Sakura, N.; Maruyama, S.; Noguchi, A.; Awaya, T.; Ishige, M.; et al. Newborn screening for carnitine palmitoyltransferase II deficiency using (C16+C18:1)/C2: Evaluation of additional indices for adequate sensitivity and lower false-positivity. Mol. Genet. Metab. 2017, 122, 67–75. [Google Scholar] [CrossRef]
- De Sain-van der Velden, M.G.M.; Rinaldo, P.; Elvers, B.; Henderson, M.; Walter, J.H.; Prinsen, B.H.C.M.T.; Verhoeven-Duif, N.M.; de Koning, T.J.; van Hasselt, P. The Proline/Citrulline Ratio as a Biomarker for OAT Deficiency in Early Infancy. JIMD Rep. 2012, 6, 95–99. [Google Scholar] [CrossRef]
- Bedoyan, J.K.; Hage, R.; Shin, H.K.; Linard, S.; Ferren, E.; Ducich, N.; Wilson, K.; Lehman, A.; Schillaci, L.; Manickam, K.; et al. Utility of specific amino acid ratios in screening for pyruvate dehydrogenase complex deficiencies and other mitochondrial disorders associated with congenital lactic acidosis and newborn screening prospects. JIMD Rep. 2020, 56, 70–81. [Google Scholar] [CrossRef]
- Archimbaud, A.; Nordhausen, K.; Ruiz-Gazen, A. ICS for multivariate outlier detection with application to quality control. Comput. Stat. Data Anal. 2018, 128, 184–199. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; Available online: https://www.R-project.org/ (accessed on 8 March 2022).
- Miettinen, J.; Nordhausen, K.; Taskinen, S. fICA: FastICA Algorithms and Their Improved Variants. R J. 2018, 10, 148–158. [Google Scholar] [CrossRef]
- Templ, M.; Hron, K.; Filzmoser, P. robCompositions: An R-package for robust statistical analysis of compositional data. In Compositional Data Analysis: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011; pp. 341–355. [Google Scholar] [CrossRef]
- Nordhausen, K.; Oja, H. Independent component analysis: A statistical perspective. WIREs Comput. Stat. 2018, 10, e1440. [Google Scholar] [CrossRef]
- Muehlmann, C.; Fačevicová, K.; Gardlo, A.; Janečková, H.; Nordhausen, K. Independent component analysis for compositional data. In Advances in Contemporary Statistics and Econometrics; Daouia, A., Ruiz-Gazen, A., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 525–545. [Google Scholar] [CrossRef]
- Miettinen, J.; Nordhausen, K.; Oja, H.; Taskinen, S. Deflation-based FastICA with adaptive choices of nonlinearities. IEEE Trans. Signal Process. 2014, 62, 5716–5724. [Google Scholar] [CrossRef]
- Pawlowsky-Glahn, V.; Buccianti, A. (Eds.) . Compositional Data Analysis: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Fišerová, E.; Hron, K. On the interpretation of orthonormal coordinates for compositional data. Math. Geosci. 2011, 43, 455–468. [Google Scholar] [CrossRef]
- Leys, C.; Ley, C.; Klein, O.; Bernard, P.; Licata, L. Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median. J. Exp. Soc. Psychol. 2013, 49, 764–766. [Google Scholar] [CrossRef]
- Dodge, Y. Median Absolute Deviation. In The Concise Encyclopedia of Statistics; Springer: New York, NY, USA, 2008. [Google Scholar] [CrossRef]
- Stroek, K.; Boelen, A.; Bouva, M.J.; De Sain-van der Velden, M.; Schielen, P.C.J.I.; Maase, R.; Engel, H.; Jakobs, B.; Kluijtmans, L.A.J.; Mulder, M.F.; et al. Evaluation of 11 years of newborn screening for maple syrup urine disease in the Netherlands and a systematic review of the literature: Strategies for optimization. JIMD Rep. 2020, 54, 68–78. [Google Scholar] [CrossRef] [PubMed]
- CLIR. Login Page. Available online: https://clir.mayo.edu/ (accessed on 29 October 2022).
- Aitchison, J. Principal component analysis of compositional data. Biometrika 1983, 70, 57–65. [Google Scholar] [CrossRef]
- Radojičić, U.; Nordhausen, K.; Virta, J. Large-sample properties of unsupervised estimation of the linear discriminant using projection pursuit. Electron. J. Stat. 2021, 15, 6677–6739. [Google Scholar] [CrossRef]
- David, J.; Chrastina, P.; Pešková, K.; Kožich, V.; Friedecký, D.; Adam, T.; Hlídková, E.; Vinohradská, H.; Novotná, D.; Hedelová, M.; et al. Epidemiology of rare diseases detected by newborn screening in the Czech Republic. Cent. Eur. J. Public Health 2019, 27, 153–159. [Google Scholar] [CrossRef]
- Zaunseder, E.; Haupt, S.; Mütze, U.; Garbade, S.F.; Kölker, S.; Heuveline, V. Opportunities and challenges in machine learning-based newborn screening—A systematic literature review. JIMD Rep. 2022, 63, 250–261. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease * | Primary Biomarkers | Secondary Biomarkers | Number of Patients (Discovery/Validation Set) |
|---|---|---|---|
| PKU | Phe, Phe/Tyr | - | 54/16 |
| MSUD | Xle, Xle/Ala, (Xle + Val)/Pro + Tyr) | Val | 7/0 |
| MCAD | C8, C8/C2 | C10, C10:1, C6, C8/C10 | 7/3 |
| LCHAD | C16-OH, C18:1-OH | C18-OH | 4/0 |
| VLCAD | C14:1, C14:1/C16 | C14 | 1/0 |
| CPT I | C0, C0/(C16 + C18) | C18, C18:1, C16 | - |
| CPT II/CACT ** | C16, (C16 + C18:1)/C2 | C18, C18:1, C0 | - |
| GA I | C5DC, C5DC/C16 | C5DC/C8 | 1/0 |
| IVA | C5, C5/C8 | C5/C2 | 1/0 |
| HCY(CBS) | Met, Met/Phe | - | - |
| HCY(MTHFR) | Met, Met/Phe, | - | 1/0 |
| ARG | Arg, Arg/Orn, Arg/Phe | - | - |
| CIT/ASA ** | Cit, Cit/Phe, Orn/Cit, ArgSucc | - | 1/1 |
| IC | Group | −3SD FPR ICA | −3SD FPR ICA | −4SD FPR ICA | −4SD FPR ICA | −5SD FPR ICA | −5SD FPR ICA | FPR David et al., 2019 [27] | FPR Olomouc 2017–2021 |
|---|---|---|---|---|---|---|---|---|---|
| IC 1 | MCAD | 26 | 0.255% | 4 | 0.039% | 0 | 0.000% | 0.002% | 0.000% |
| IC 2 | PKU | 11 | 0.108% | 4 | 0.039% | 1 | 0.010% | 0.027% | 0.003% |
| IC 3 | LCHAD | 3 | 0.029% | 0 | 0.000% | 0 | 0.000% | 0.000% | 0.001% |
| IC 4 | IVA | 7 | 0.069% | 1 | 0.010% | 0 | 0.000% | 0.008% | 0.004% |
| IC 5 | weights * | 0 | 0.000% | 0 | 0.000% | 0 | 0.000% | --- | --- |
| IC 6 | GAI | 19 | 0.186% | 2 | 0.020% | 0 | 0.000% | 0.003% | 0.003% |
| IC 7 | --- | 0 | 0.000% | 0 | 0.000% | 0 | 0.000% | --- | --- |
| IC 8 | IVA | 4 | 0.039% | 0 | 0.000% | 0 | 0.000% | 0.008% | 0.004% |
| IC | Group | +3SD FPR ICA | +3SD FPR ICA | +4SD FPR ICA | +4SD FPR ICA | +5SD FPR ICA | +5SD FPR ICA | FPR David et al., 2019 [27] | FPR Olomouc 2017–2021 |
| IC 1 | VLCAD/IVA/GAI | 1 | 0.010% | 0 | 0.000% | 0 | 0.000% | 0.007/0.008/0.003% | 0.008/0.004/0.003% |
| IC 2 | MSUD | 3 | 0.029% | 0 | 0.000% | 0 | 0.000% | 0.010% | 0.019% |
| IC 3 | GAI | 3 | 0.029% | 0 | 0.000% | 0 | 0.000% | 0.003% | 0.003% |
| IC 4 | MSUD | 1 | 0.010% | 0 | 0.000% | 0 | 0.000% | 0.010% | 0.019% |
| IC 5 | weights * | 123 | 1.204% | 85 | 0.832% | 41 | 0.401% | --- | --- |
| IC 6 | --- | 0 | 0.000% | 0 | 0.000% | 0 | 0.000% | --- | --- |
| IC 7 | CIT ** | 3 | 0.029% | 0 | 0.000% | 0 | 0.000% | 0.006% | 0.014% |
| IC 8 | --- | 2 | 0.020% | 0 | 0.000% | 0 | 0.000% | --- | --- |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kouřil, Š.; de Sousa, J.; Fačevicová, K.; Gardlo, A.; Muehlmann, C.; Nordhausen, K.; Friedecký, D.; Adam, T. Multivariate Independent Component Analysis Identifies Patients in Newborn Screening Equally to Adjusted Reference Ranges. Int. J. Neonatal Screen. 2023, 9, 60. https://doi.org/10.3390/ijns9040060
Kouřil Š, de Sousa J, Fačevicová K, Gardlo A, Muehlmann C, Nordhausen K, Friedecký D, Adam T. Multivariate Independent Component Analysis Identifies Patients in Newborn Screening Equally to Adjusted Reference Ranges. International Journal of Neonatal Screening. 2023; 9(4):60. https://doi.org/10.3390/ijns9040060
Chicago/Turabian StyleKouřil, Štěpán, Julie de Sousa, Kamila Fačevicová, Alžběta Gardlo, Christoph Muehlmann, Klaus Nordhausen, David Friedecký, and Tomáš Adam. 2023. "Multivariate Independent Component Analysis Identifies Patients in Newborn Screening Equally to Adjusted Reference Ranges" International Journal of Neonatal Screening 9, no. 4: 60. https://doi.org/10.3390/ijns9040060
APA StyleKouřil, Š., de Sousa, J., Fačevicová, K., Gardlo, A., Muehlmann, C., Nordhausen, K., Friedecký, D., & Adam, T. (2023). Multivariate Independent Component Analysis Identifies Patients in Newborn Screening Equally to Adjusted Reference Ranges. International Journal of Neonatal Screening, 9(4), 60. https://doi.org/10.3390/ijns9040060