The Definition and Software Performance of Hashstream, a Fast Length-Flexible PRF


Abstract
:1. Introduction
1.1. Notation
1.2. Hashstream Uses
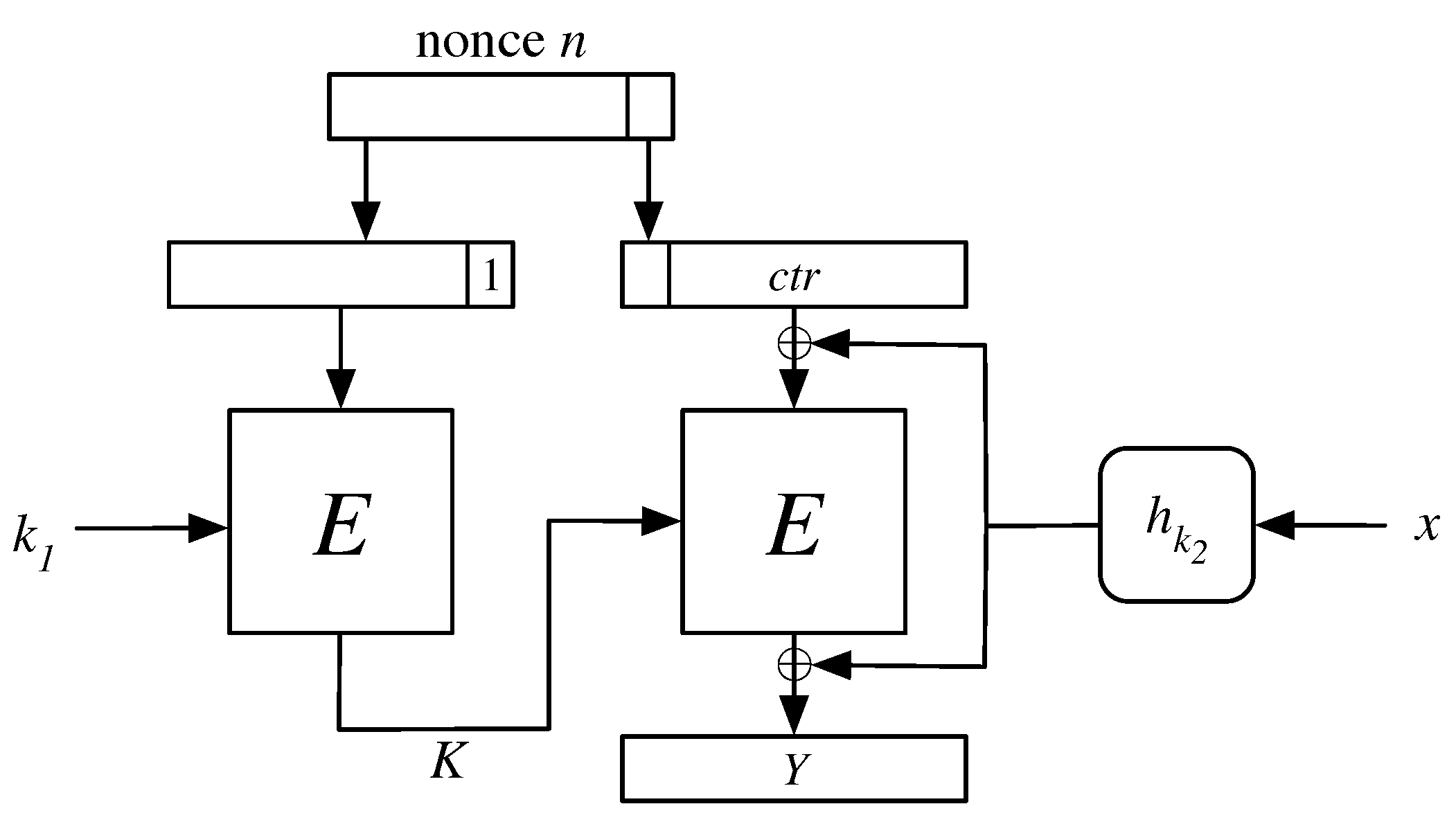
1.3. Hashstream Constructions
1.4. Hashstream Speed
1.5. Hashstream Security
1.6. Hashstream Abstraction and API
1.7. Related Work
2. Results
3. Discussion
3.1. Nonces
3.2. Relation to HS1-SIV
3.3. Concluding Remarks and Future Work
4. Materials and Methods
4.1. Software Availability
4.2. Building
- Download OpenSSL anywhere on your system from https://www.openssl.org/source/ [12]. This paper was developed using Version 1.1.1.
- Build OpenSSL: extract the OpenSSL archive, cd, into the new directory, run the configurator ./config -march=native -mtune=native, and execute make. Depending on your architecture, you may need to change the -march=native -mtune=native to whatever is right for your machine. Adding CC=clang appears to work on Clang-based installations.
- Compile your Hashstream application with the resulting libcrypto.a file. For example: gcc -march=native -mtune=native -O3 hs_timer.c hspc.c openssl-1.1.1/libcrypto.a.
4.3. Timing
Funding
Conflicts of Interest
Appendix A. Sample API
Appendix B. Sample Implementation: Hashstream/PC
References
- Bernstein, D.J. The Poly1305-AES message-authentication code. In Fast Software Encryption; Gilbert, H., Handschuh, H., Eds.; Lecture Notes in Computer Science 3557; Springer: Berlin/Heidelberg, Germany, 2005; pp. 32–49. [Google Scholar] [CrossRef]
- McGrew, D.A.; Viega, J. The Security and Performance of the Galois/Counter Mode (GCM) of Operation. In Progress in Cryptology—INDOCRYPT 2004; Canteaut, A., Viswanathan, K., Eds.; Lecture Notes in Computer Science 3348; Springer: Berlin/Heidelberg, Germany, 2004; pp. 343–355. [Google Scholar] [CrossRef]
- Bernstein, D.J. ChaCha, A Variant of Salsa20. Presented at SASC 2008: The State of the Art of Stream Ciphers, Lausanne, Switzerland. 2008. Available online: http://www.ecrypt.eu.org/stvl/sasc2008/ (accessed on 1 June 2018).
- Dworkin, M. Recommendation for Block Cipher Modes of Operation: Methods and Techniques; SP 800-38A; NIST: Gaithersburg, MD, USA, 2001.
- Krovetz, T. HS1-SIV (v2). CAESAR Submissions. 2015. Available online: https://competitions.cr.yp.to/round2/hs1sivv2c.pdf (accessed on 1 June 2018).
- Rogaway, R.; Shrimpton, T. A provable-security treatment of the keywrap problem. In Advances in Cryptology—EUROCRYPT 2006; Vaudenay, S., Ed.; Lecture Notes in Computer Science 4004; Springer: Berlin/Heidelberg, Germany, 2006; pp. 373–390. [Google Scholar] [CrossRef]
- Liskov, M.; Rivest, R.L.; Wagner, D. Tweakable Block Ciphers. In Advances in Cryptology—CRYPTO 2002; Yung, M., Ed.; Lecture Notes in Computer Science 2442; Springer: Berlin/Heidelberg, Germany, 2002; pp. 31–46. [Google Scholar] [CrossRef]
- Naito, Y. Tweakable blockciphers for efficient authenticated encryptions with beyond the birthday-bound security. IACR Trans. Symmetric Cryptol. 2017, 2, 1–26. [Google Scholar] [CrossRef]
- Halevi, S.; Krawczyk, H. MMH: Software message authentication in the Gbit/second rates. In Fast Software Encryption; Biham, E., Youssef, A.M., Eds.; Lecture Notes in Computer Science 4356; Springer: Berlin/Heidelberg, Germany, 2007; pp. 172–189. [Google Scholar] [CrossRef]
- Black, J.; Halevi, S.; Krawczyk, H.; Krovetz, T.; Rogaway, P. UMAC: Fast and secure message authentication. In Advances in Cryptology—CRYPTO ’99; Wiener, M., Ed.; Lecture Notes in Computer Science 1666; Springer: Berlin/Heidelberg, Germany, 1999; pp. 216–233. [Google Scholar] [CrossRef]
- Krovetz, T. Message authentication on 64-bit architectures. In Fast Software Encryption; Gilbert, H., Handschuh, H., Eds.; Lecture Notes in Computer Science 3557; Springer: Berlin/Heidelberg, Germany, 2005; pp. 327–341. [Google Scholar] [CrossRef]
- OpenSSL: Cryptography and SSL/TLS Toolkit. Available online: https://www.openssl.org (accessed on 1 June 2018).
- Bernstein, D.J.; Lange, T. (Eds.) eBACS: ECRYPT Benchmarking of Cryptographic Systems. Available online: https://bench.cr.yp.to (accessed on 1 June 2018).
- Bernstein, D.J. Response to “On the Salsa20 Core Function”. 2008. Available online: https://cr.yp.to/snuffle/reoncore-20080224.pdf (accessed on 1 June 2018).
- Bellare, M.; Rogaway, R. Optimal asymmetric encryption. In Advances in Cryptology—EUROCRYPT ’94; De Santis, A., Ed.; Lecture Notes in Computer Science 950; Springer: Berlin/Heidelberg, Germany, 1995; pp. 92–111. [Google Scholar] [CrossRef]
- Boldyreva, A.; Chenette, N.; Lee, Y.; O’Neill, A. Order-preserving symmetric encryption. In Advances in Cryptology—EUROCRYPT 2009; Joux, A., Ed.; Lecture Notes in Computer Science 5479; Springer: Berlin/Heidelberg, Germany, 2009; pp. 224–241. [Google Scholar] [CrossRef]
- CAESAR. Competition for Authenticated Encryption, Security, Applicability, and Robustness. Available online: https://competitions.cr.yp.to/caesar.html (accessed on 1 June 2018).
- Bernstein, D.J. Some Challenges in Heavyweight Cipher Design. Presented at Dagstuhl Seminar on Symmetric Encryption, Dagstuhl, Germany, 15 January 2016; Available online: https://cr.yp.to/talks/2016.01.15/slides-djb-20160115-a4.pdf (accessed on 1 June 2018).
- Bertoni, G.; Daemen, J.; Hoffert, S.; Peeters, M.; Van Assche, G.; Van Keer, R. Farfalle: parallel permutation-based cryptography. IACR Trans. Symmetric Cryptol. 2017, 4, 1–38. [Google Scholar] [CrossRef]
- Gueron, S.; Langley, A.; Lindell, Y. AES-GCM-SIV: Specification and Analysis. 2017. Cryptology ePrint Archive. Available online: https://eprint.iacr.org/2017/168Report2017/168 (accessed on 1 June 2018).
- Krovetz, T. Hashstream Code. GitHub Repository. 2018. Available online: https://github.com/krovetz/Hashstream (accessed on 1 June 2018).


{kind=link}
| Hash | Stream | SIV | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Skylake | 64 | 256 | 1024 | 64 | 256 | 1024 | 64 | 256 | 1024 |
| Poly1305 + Chacha20 | 2.8 | 1.5 | 0.7 | 5.2 | 2.5 | 1.2 | 15.0 | 5.6 | 2.4 |
| GHASH + AES-CTR | 1.8 | 0.6 | 0.4 | 1.6 | 0.9 | 0.7 | 6.4 | 2.2 | 1.3 |
| Cortex-A15 | 64 | 256 | 1024 | 64 | 256 | 1024 | 64 | 256 | 1024 |
| Poly1305 + Chacha20 | 8.2 | 3.0 | 1.7 | 11.9 | 5.2 | 5.0 | 38.0 | 12.8 | 7.9 |
| GHASH + AES-CTR | 9.9 | 8.1 | 7.7 | 22.8 | 16.6 | 14.8 | 44.2 | 27.7 | 23.2 |
| Cortex-A5 without NEON | 64 | 256 | 1024 | 64 | 256 | 1024 | 64 | 256 | 1024 |
| Poly1305 + Chacha20 | 16.4 | 8.9 | 7.0 | 21.4 | 20.0 | 19.4 | 75.1 | 38.4 | 28.8 |
| GHASH + AES-CTR | 52.3 | 43.7 | 41.5 | 49.2 | 46.7 | 46.1 | 141.2 | 100.3 | 90.2 |
| Skylake | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
|---|---|---|---|---|---|---|---|---|---|---|
| Poly1305 + Chacha20 | 22.3 | 12.0 | 5.2 | 4.9 | 2.5 | 1.3 | 1.2 | 1.2 | 1.2 | 1.2 |
| GHASH + AES-CTR | 5.5 | 3.0 | 1.6 | 1.1 | 0.9 | 0.7 | 0.7 | 0.7 | 0.6 | 0.6 |
| GHASH + AES-CTR (rekey) | 14.9 | 7.9 | 4.0 | 2.3 | 1.5 | 1.0 | 0.8 | 0.7 | 0.7 | 0.7 |
| Ryzen | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 19.0 | 10.0 | 4.5 | 4.3 | 3.4 | 1.7 | 1.7 | 1.7 | 1.7 | 1.7 |
| GHASH + AES-CTR | 4.1 | 2.2 | 1.1 | 0.9 | 0.6 | 0.4 | 0.3 | 0.3 | 0.3 | 0.3 |
| Cortex-A72 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 36.0 | 19.0 | 8.5 | 8.3 | 5.1 | 4.6 | 4.5 | 4.5 | 4.5 | 4.5 |
| GHASH + AES-CTR | 6.8 | 3.4 | 2.4 | 1.6 | 1.3 | 1.1 | 1.0 | 1.0 | 1.0 | 0.9 |
| Cortex-A53 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 43.7 | 24.3 | 9.6 | 9.1 | 5.1 | 4.9 | 4.8 | 4.8 | 4.7 | 4.7 |
| GHASH + AES-CTR | 14.1 | 7.1 | 4.7 | 2.9 | 2.3 | 1.8 | 1.7 | 1.5 | 1.5 | 1.5 |
| Cortex-A15 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 51.1 | 27.1 | 11.9 | 11.4 | 5.2 | 5.1 | 5.0 | 5.0 | 5.0 | 5.0 |
| GHASH + AES-CTR | 27.4 | 24.2 | 22.3 | 18.8 | 16.6 | 15.5 | 14.9 | 14.6 | 14.4 | 14.4 |
| Cortex-A5 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 90.7 | 47.8 | 21.3 | 20.4 | 14.8 | 14.5 | 14.3 | 14.2 | 14.1 | 14.1 |
| GHASH + AES-CTR | 56.2 | 47.8 | 43.4 | 47.0 | 41.6 | 38.9 | 37.5 | 36.9 | 36.6 | 36.4 |
| Cortex-A5 w/o NEON | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 91.6 | 48.8 | 21.2 | 20.4 | 19.9 | 19.6 | 19.4 | 19.3 | 19.3 | 19.3 |
| GHASH + AES-CTR | 58.8 | 52.0 | 48.4 | 46.6 | 45.6 | 45.2 | 44.9 | 44.8 | 44.8 | 44.8 |
| Skylake | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
|---|---|---|---|---|---|---|---|---|---|---|
| Poly1305 + Chacha20 | 6.5 | 4.6 | 2.8 | 2.4 | 1.5 | 1.0 | 0.7 | 0.6 | 0.6 | 0.5 |
| GHASH + AES-CTR | 7.2 | 3.6 | 1.8 | 0.9 | 0.6 | 0.5 | 0.4 | 0.4 | 0.4 | 0.4 |
| Ryzen | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 5.3 | 3.0 | 2.0 | 2.5 | 1.7 | 1.3 | 1.1 | 1.0 | 1.0 | 1.0 |
| GHASH + AES-CTR | 3.2 | 1.8 | 1.1 | 0.7 | 0.5 | 0.4 | 0.4 | 0.4 | 0.4 | 0.4 |
| Cortex-A72 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 9.8 | 6.2 | 4.5 | 4.0 | 2.5 | 1.8 | 1.5 | 1.3 | 1.2 | 1.2 |
| GHASH + AES-CTR | 7.2 | 3.8 | 2.1 | 1.4 | 1.1 | 0.9 | 0.8 | 0.8 | 0.7 | 0.7 |
| Cortex-A53 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 16.2 | 9.5 | 6.1 | 5.4 | 3.4 | 2.4 | 2.0 | 1.7 | 1.6 | 1.5 |
| GHASH + AES-CTR | 7.3 | 4.5 | 2.4 | 1.7 | 1.3 | 1.1 | 1.0 | 0.9 | 0.9 | 0.9 |
| Cortex-A15 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 18.0 | 10.5 | 8.2 | 4.8 | 3.0 | 2.1 | 1.7 | 1.5 | 1.4 | 1.3 |
| GHASH + AES-CTR | 17.0 | 12.4 | 9.9 | 8.7 | 8.1 | 7.8 | 7.7 | 7.6 | 7.5 | 7.5 |
| Cortex-A5 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 40.0 | 22.4 | 18.3 | 10.8 | 6.9 | 4.9 | 4.0 | 3.5 | 3.2 | 3.1 |
| GHASH + AES-CTR | 42.0 | 29.9 | 23.9 | 20.9 | 19.3 | 18.6 | 18.2 | 18.0 | 17.9 | 17.9 |
| Cortex-A5 w/o NEON | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 |
| Poly1305 + Chacha20 | 42.3 | 24.3 | 15.3 | 10.9 | 8.6 | 7.5 | 6.9 | 6.6 | 6.5 | 6.4 |
| GHASH + AES-CTR | 86.4 | 63.3 | 51.5 | 45.6 | 42.7 | 41.2 | 40.5 | 40.1 | 40.0 | 39.9 |
| Skylake | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
|---|---|---|---|---|---|---|---|---|---|---|
| Poly1305 + Chacha20 | 57.9 | 30.0 | 15.1 | 10.7 | 5.6 | 3.1 | 2.4 | 2.0 | 1.8 | 1.8 |
| GHASH + AES-CTR | 25.0 | 12.8 | 6.4 | 3.5 | 2.2 | 1.6 | 1.3 | 1.1 | 1.1 | 1.0 |
| Farfalle SAE | 88.8 | 44.4 | 22.2 | 11.1 | – | – | – | – | 1.9 | 1.4 |
| AES-GCM | – | – | – | – | – | – | – | – | – | 0.7 |
| OCB | – | – | – | – | – | – | – | – | – | 0.6 |
| Ryzen | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
| Poly1305 + Chacha20 | 48.5 | 25.7 | 12.7 | 9.9 | 6.8 | 3.9 | 3.2 | 2.9 | 2.8 | 2.7 |
| GHASH + AES-CTR | 15.7 | 8.2 | 4.3 | 2.5 | 1.6 | 1.1 | 0.9 | 0.7 | 0.7 | 0.7 |
| AES-GCM | – | – | – | – | – | – | – | – | – | 1.1 |
| OCB | – | – | – | – | – | – | – | – | – | 0.4 |
| Cortex-A72 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
| Poly1305 + Chacha20 | 92.2 | 49.1 | 25.2 | 18.3 | 10.7 | 7.9 | 6.8 | 6.2 | 5.9 | 5.8 |
| GHASH + AES-CTR | 28.1 | 14.2 | 8.1 | 4.8 | 3.3 | 2.4 | 2.1 | 1.8 | 1.7 | 1.7 |
| AES-GCM | – | – | – | – | – | – | – | – | – | 1.8 |
| OCB | – | – | – | – | – | – | – | – | – | 1.2 |
| Cortex-A53 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
| Poly1305 + Chacha20 | 122.6 | 65.1 | 31.4 | 22.3 | 12.4 | 9.3 | 7.8 | 7.0 | 6.6 | 6.4 |
| GHASH + AES-CTR | 44.3 | 23.3 | 13.0 | 7.5 | 5.0 | 3.6 | 3.0 | 2.6 | 2.5 | 2.4 |
| Cortex-A15 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
| Poly1305 + Chacha20 | 140.2 | 73.1 | 38.0 | 25.2 | 12.8 | 9.5 | 7.9 | 7.0 | 6.6 | 6.4 |
| GHASH + AES-CTR | 89.8 | 59.1 | 43.6 | 33.2 | 27.6 | 24.7 | 23.2 | 22.5 | 22.2 | 22.0 |
| AES-GCM | – | – | – | – | – | – | – | – | – | 37.6 |
| OCB | – | – | – | – | – | – | – | – | – | 20.5 |
| Cortex-A5 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
| Poly1305 + Chacha20 | 269.4 | 140.1 | 74.3 | 48.4 | 30.4 | 23.7 | 20.4 | 18.7 | 17.8 | 17.4 |
| GHASH + AES-CTR | 199.8 | 128.5 | 93.1 | 80.7 | 67.5 | 60.7 | 57.4 | 55.7 | 54.9 | 54.5 |
| AES-GCM | – | – | – | – | – | – | – | – | – | 53.9 |
| OCB | – | – | – | – | – | – | – | – | – | 40.8 |
| Cortex-A5 w/o NEON | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | long |
| Poly1305 + Chacha20 | 276.1 | 144.2 | 71.8 | 49.1 | 37.5 | 31.5 | 28.5 | 27.1 | 26.3 | 26.0 |
| GHASH + AES-CTR | 294.2 | 190.9 | 137.7 | 111.1 | 97.7 | 91.1 | 87.8 | 86.2 | 85.4 | 84.9 |
| File | Contents |
|---|---|
| hashstream.h | C header with programming interface and Doxygen documentation |
| hspc.c | Hashstream/PC implementation (Poly1305 and Chacha20) |
| hsga.c | Hashstream/GA implementation (GHASH and AES-CTR) |
| hs_timer.c | Program for producing Hashstream timings |
| README.md | Build instructions and more information |
| LICENSE | License file placing code into public domain |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krovetz, T. The Definition and Software Performance of Hashstream, a Fast Length-Flexible PRF. Cryptography 2018, 2, 31. https://doi.org/10.3390/cryptography2040031
Krovetz T. The Definition and Software Performance of Hashstream, a Fast Length-Flexible PRF. Cryptography. 2018; 2(4):31. https://doi.org/10.3390/cryptography2040031
Chicago/Turabian StyleKrovetz, Ted. 2018. "The Definition and Software Performance of Hashstream, a Fast Length-Flexible PRF" Cryptography 2, no. 4: 31. https://doi.org/10.3390/cryptography2040031
APA StyleKrovetz, T. (2018). The Definition and Software Performance of Hashstream, a Fast Length-Flexible PRF. Cryptography, 2(4), 31. https://doi.org/10.3390/cryptography2040031