
Beyond Bitcoin: Recent Trends and Perspectives in Distributed Ledger Technology



Abstract
:1. Introduction
1.1. Paper Contribution and Organization
- an in-depth critical discussion of the concept of decentralization and its implementation in current DL systems. Decentralization is the primary goal of any DL system, and we discuss it for system architecture and governance, also considering how the system interacts with the outside world during its operation;
- a reference architecture for DLT, in order to provide an integrated and comprehensive view of the function and role of the various concepts and tools offered by this technology;
- a new classification for consensus protocols based on a five-component framework, aimed at underlining similarities and differences between the protocols recently introduced for DL systems and those introduced since the eighties for more traditional distributed systems. Rather than providing a broad array of blockchain consensus protocols with technical details, we focus on the milestones of research developments in this sector, citing only those protocols that we believe have introduced truly innovative features;
- a review of the most relevant tools and strategies introduced for integrating DL systems with the physical world. This integration is an emerging and exciting research field whose primary goal is to design and develop cyber-physical systems capable of implementing an extended notion of process authentication, which encompasses both digital and physical assets. In this context, we introduce the notion of authentic data encoding for physical resources (AD-ExPR), which results in a constructive scheme for the authentication of a physical resource through alphanumeric data. To the best of our knowledge, some authors in the literature implicitly used but did not explicitly define this scheme.
1.2. Related Works
2. The Quest for Decentralization and Its Realization through DLT
- risks deriving from assuming a single point of failure/trust, as in the case of the “trusted third party” assumption;
- costs reduction, both in the financial field and more generally in the commercial one, thanks to the elimination of intermediaries and interoperability “by design”;
- need to coordinate safely and reliably complex distributed systems, which, by their nature, are better suited, in whole or in part, to peer-to-peer models.
2.1. Permissionless versus Permissioned Systems
2.2. Governance Models
2.2.1. On-Chain Governance
- initially, an approval voting is issued to accept proposed tarballs containing new protocols. Each proposal collects some preferences;
- stakeholders vote for the most preferred protocol again counting votes for, against, and abstained;
- if a certain quorum of votes is reached, including those explicitly abstained, with a minimum approval rate of 80%, the new protocol goes into the test chain. In each cycle, the system automatically updates the quorum to avoid lost coins;
- stakeholders vote again to adopt the tested protocol in the main chain. Furthermore, in this case, quorum and 80% of preferences are the minimums to pass.
2.2.2. Off-Chain Governance
- Roles: Contributors, Maintainers, Ethereum Improvement Proposal (EIP) editors.
- Incentives: Contributors expect potential value increase of Ether from working voluntarily, as well as fun and social recognition. The Ethereum Foundation (EF) pays some maintainers.
- Membership: Everybody is free to contribute. There is no formal selection procedure for maintainers or EIP editors. Usually, the most recognized contributors are called to relevant positions by EF.
- Communication: Contributors communicate via GitHub comments, meet-ups, events, and scheduled calls. Core developers’ calls notes are published.
- Decision Making: Decisions happen during calls or through the EIP process.
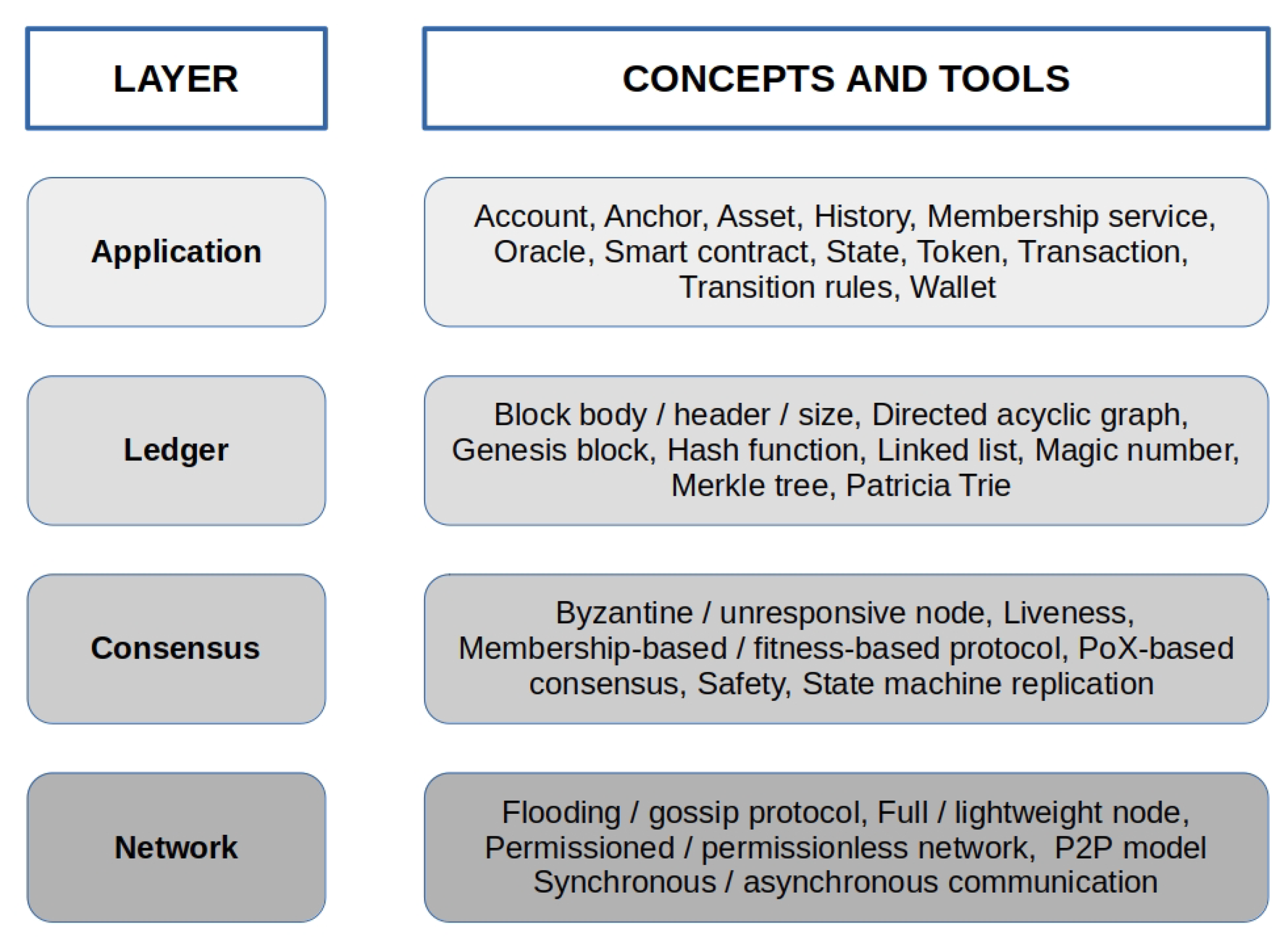
3. DLT Reference Architecture and Building Blocks
3.1. Application
3.1.1. User Management
3.1.2. Service Specification
3.2. Ledger
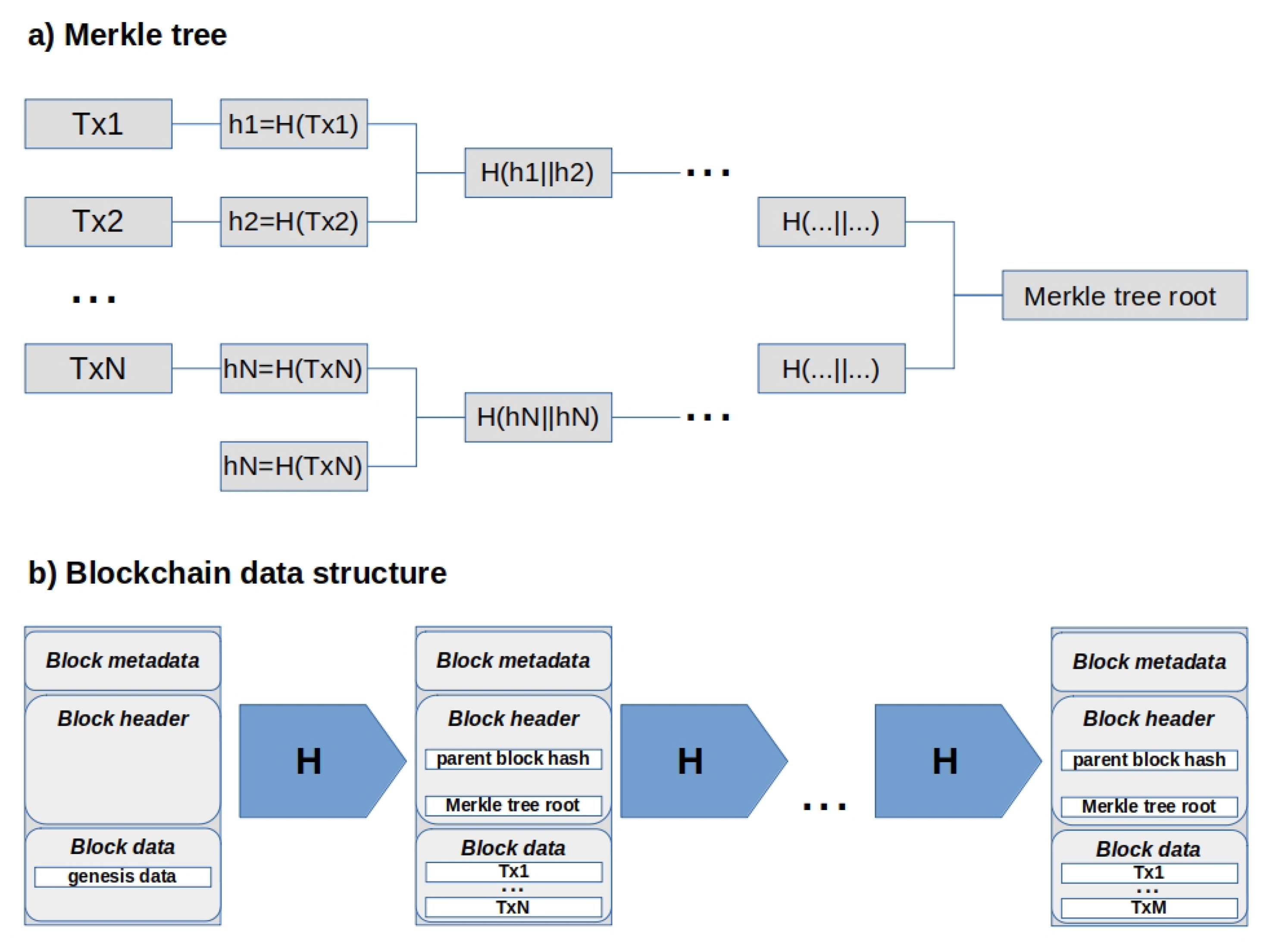
3.2.1. Block Structure
3.2.2. Blockchain Alternatives
3.3. Consensus
3.3.1. Network-Oriented Consensus Protocols
- Proposal: where a node assembles a block of transactions and attaches proof to it demonstrating its investment of the fitness resource in such a task;
- Validation: in which nodes check the validity of the blocks proposed in the previous phase, alongside with their alleged proofs;
- Finalization: in which the network, following a rule usually based on the majority of participants, selects a unique block among those that passed the validation phase.
3.3.2. Committee-Oriented Consensus Protocols
- Committee selection: to designate a (relatively small) subset of nodes in the network as eligible to participate in the consensus process for adding one or more upcoming new blocks;
- Leader selection: to designate a node in the committee as the one that is actually in charge of adding the next block or of leading the consensus process for adding the next block;
- Proposal: where the leader node returns the new current block along with a proof to demonstrate the block validity;
- Validation: in which nodes check the validity of the blocks proposed in the previous phase, alongside with their alleged proofs;
- Finalization: in which the network, following a rule, usually based on the majority of participants, selects a unique block among those that passed the validation phase.
3.4. Network
3.4.1. Network Architecture
3.4.2. Communication Models
3.4.3. Communication Uncertainty
- Synchronous, which assumes the existence of some a priori known finite-time bound , such that each message gets transmitted with a delay of at most ;
- Asynchronous, where the delivery messages might require any finite amount of time so that each message must eventually be delivered, without prediction of time needed to get to the destination;
- Partial synchronous, whose assumption is that there exists some known finite-time bound and a special event called Global Stabilization Time (GST) such that: (i) the GST eventually happens after some amount of unknown finite time, and; (ii) the delivery of any message sent at time must happen by time .
4. Emerging Concepts and Their Relevance in Applications
4.1. Assets and Tokens
4.1.1. Ethereum Tokens
- EIP-20: Token Standard [121] is an API for fungible tokens, i.e., tokens all identical in specifications that can get expressed into smaller units, and both tokens and units can be implicitly interchangeable provided that they sum up to the same value. The first and foremost example of a fungible token is cash, and all other examples (e.g., game chips, cryptocurrencies, commodities, common shares) are functionally equivalent to it. Accordingly, this API provides functionalities, such as the tokens’ transfer from one account to another, the current token balance of an account, and the total supply of the token available on the network; other functionalities include creating and checking allowances. EIP-20 is composed of six mandatory functions, three optional functions, and two events.
- EIP-721: Non-Fungible Token Standard [122] is an API for non-fungible tokens (NFTs). NFTs are used to identify something or someone uniquely since this kind of token comes up in unique samples, even if generated from the same smart contract. NFTs can be used to encode and manage the ownership of digital files, such as collectible items (e.g., photos, audio, and other digital artworks), access keys, and nominal tickets. However, access to any copy of the original file does not restrict the buyer of the NFT. Thus NFTs provide the owner with proof of ownership that is separate from copyright. EIP-721 provides core methods that allow tracking the owner of a unique identifier and a permissioned way for the owner to transfer the asset to others. This standard requires compliant tokens to implement ten mandatory functions and three events; moreover, they must implement the EIP-165: Standard Interface Detection [123].
- EIP-777: Token Standard [124] defines advanced features to interact with tokens while remaining backward compatible with EIP-20. This API introduces operators for sending tokens on behalf of another account and sending/receiving hooks offering holders more control over their tokens. It is composed of thirteen mandatory functions and five events.
- EIP-1155: Multi-Token Standard [125] outlines instead an interface that can represent any combination of fungible and non-fungible tokens in a single contract and transfer multiple token types at once. This API serves as an alternative to EIP-20 and EIP-721, which require the deployment of a separate contract for each token type or collection, placing a lot of redundant bytecode on the blockchain and limiting certain functionalities in some usage scenarios (e.g., blockchain games). It is composed of six mandatory functions and four events.
- EIP-1450 [126] extends EIP-20 in order to facilitate the issuance and trading of securities in compliance with the U.S. Securities Exchange Commission (SEC) regulations. According to SEC requirements, this proposed standard mandates that the issuer is the only role that may create a token and assign the Registered Trade Agent (RTA), while the RTA is the only role that is allowed to execute the mint (creation), burn (destruction), and transfer of tokens. Implementers must maintain off-chain services and databases that record and track the investor’s private information (name, physical address, Ethereum address, and security ownership amount) so that: (i) implementers and the SEC can access it on an as-needed basis; (ii) issuers and the RTA can produce a current list of all investors with names, addresses, and security ownership levels for every security at any given moment, and; (iii) issuers and the RTA can re-issue securities to investors for a variety of regulated reasons.
- EIP-1462 [127] is another extension to EIP-20 that provides compliance with securities regulations and legal enforceability. However, in contrast to EIP-1450, this API defines a minimal set of additions to comply with the U.S. and international legal requirements. Such requirements include Know Your Customer (KYC) and Anti Money Laundering (AML) regulations, besides the ability to lock tokens for an account and restrict them from transfer due to a legal dispute. Another important requirement provided by this standard is the ability to attach additional legal documentation to set up a dual-binding relationship between the token and off-chain legal entities.
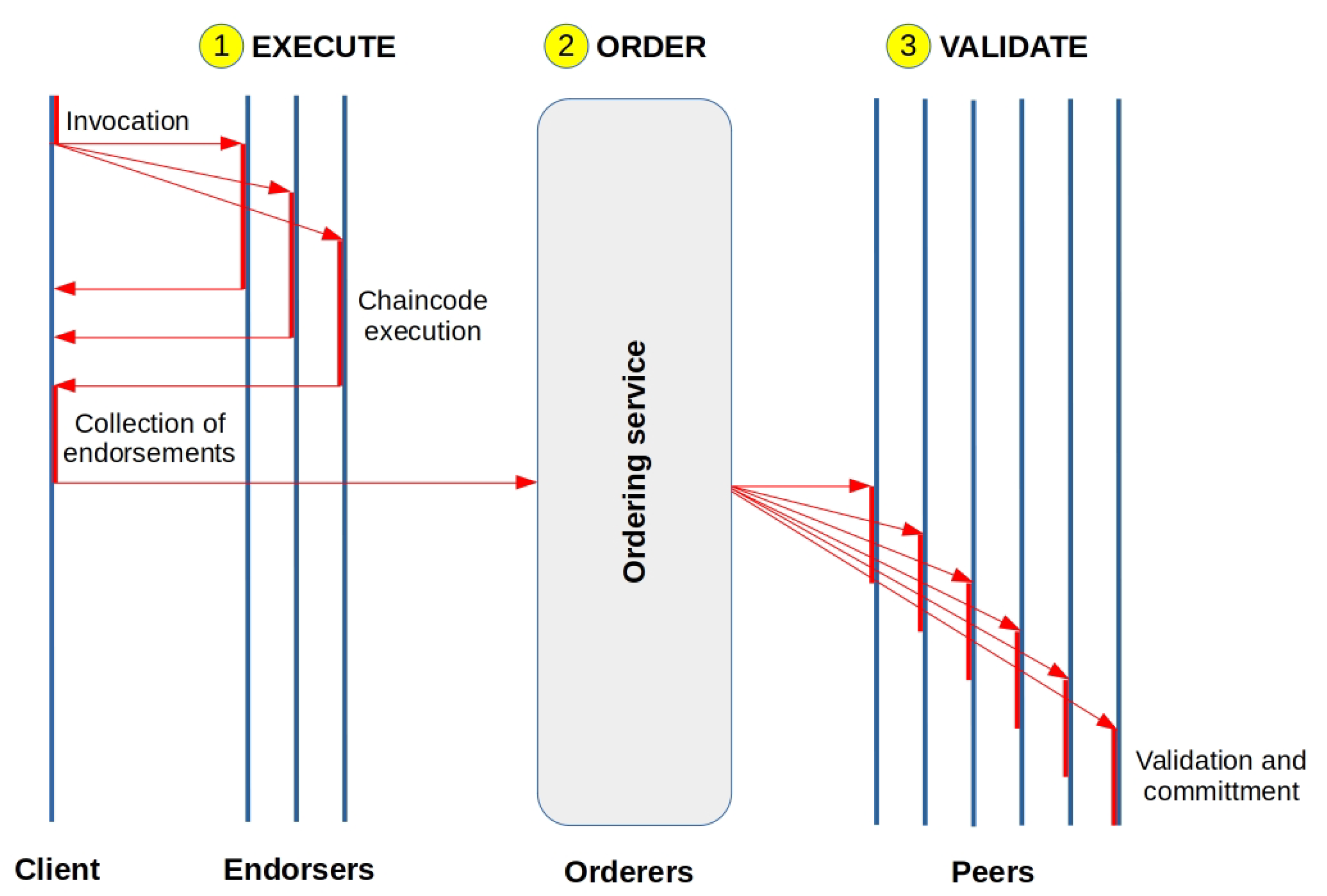
4.1.2. Assets and Tokens in Hyperledger Fabric
- the trust model for transaction validation is determined at the consensus layer rather than at the application layer, thus forcing transactions to follow a validation workflow that can diverge from the actual application requirements;
- consensus is hard-coded within the platform, resulting in monolithic applications that are difficult to upgrade and adapt to different network environments and threat scenarios;
- the fact that all peers should execute all transactions degrades performance, increases consumption, and makes it more challenging to enforce privacy when necessary;
- smart contracts must be written in a fixed, non-standard, or domain-specific language to avoid the occurrence of non-deterministic or non-terminating executions.
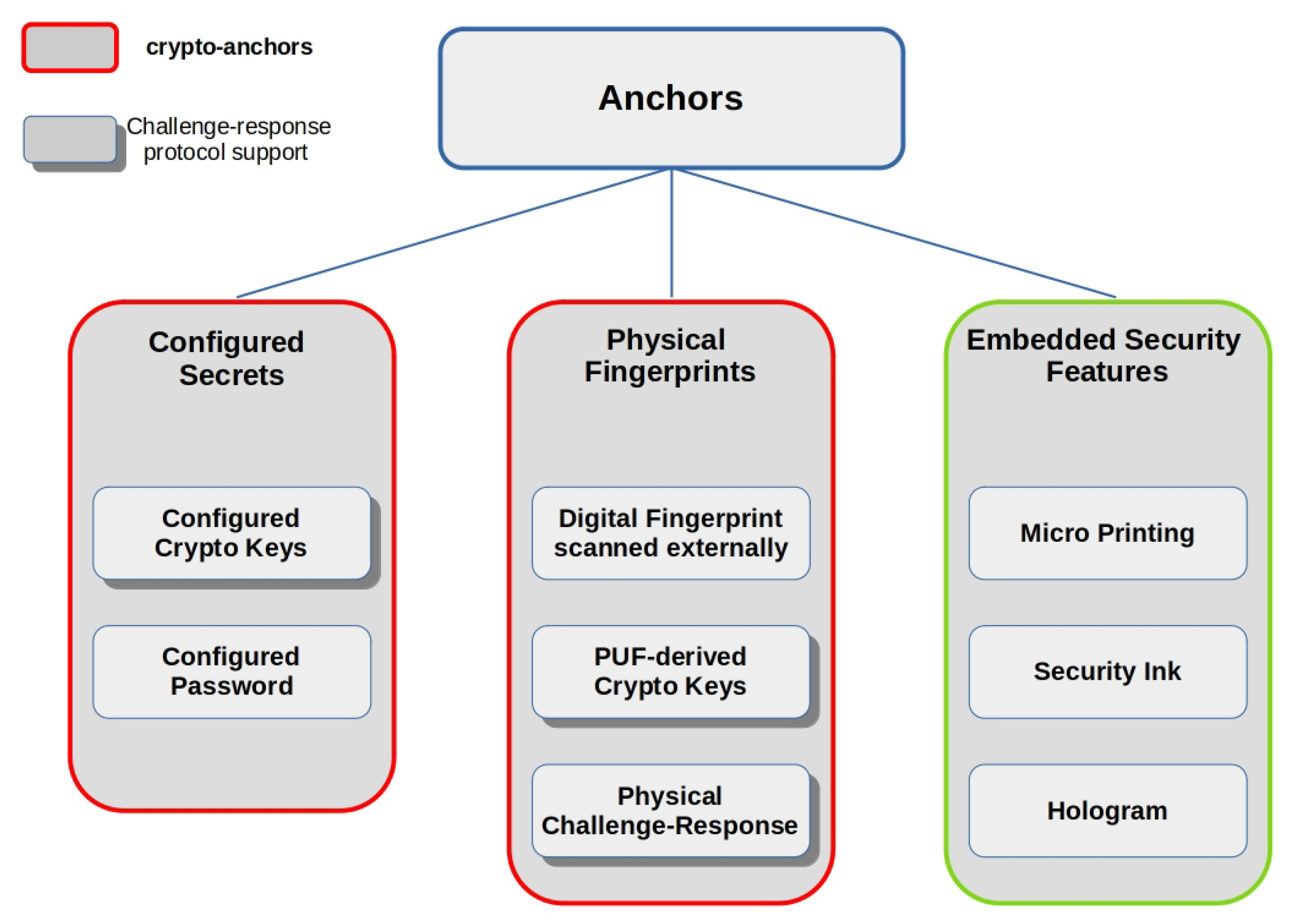
4.2. Anchors
- there must be a one-to-one unforgeable association between data items and resources, so that each data item corresponds to only one resource and vice versa, without any possible swapping or substitution in such correspondence;
- the data item associated with the object must be authentic; that is, only the party who creates or holds the resource must be able to generate a valid data item representing it;
- if a resource is subject to changes in its status (e.g., ownership, physical properties), then the one-to-one unforgeable association considered in (1) must guarantee a one-to-one correspondence with all the states that characterize the resource life cycle, thanks to an appropriate field in the data item.
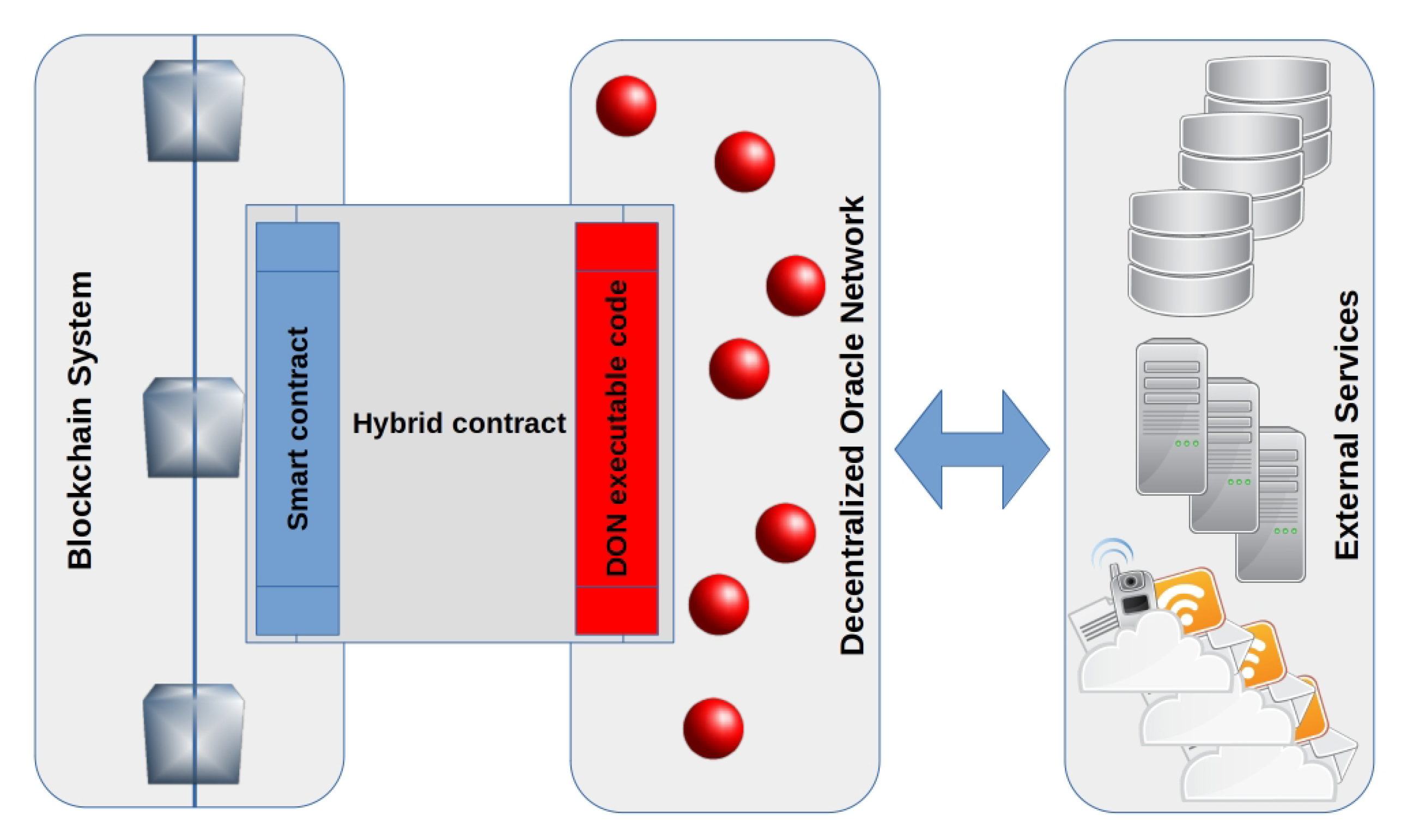
4.3. Oracles
- TLSNotary Proof; which relies on a feature of TLS 1.x protocols to enable the splitting of the TLS master key among three parties: the server, an auditee, and an auditor. Provable is the auditee in this scheme, while a locked-down instance of a specially designed, open-source virtual machine on Amazon Elastic Computing Cloud (https://aws.amazon.com/ec2, accessed 15 October 2021) acts as the auditor.
- Android Proof; which makes use of a software remote attestation technology developed by Google, called SafetyNet [134], to validate that a given Android application is running on a safe, non-rooted physical device connected to Provable’s infrastructure. It also remotely validates the application code hash, enabling authentication of the application running on the device.
- Ledger Proof; which leverages a trusted execution environment comprising an STMicroelectronics secure element, a controller, and BOLOS [135], an operating system developed for hardware wallets by Ledger (https://www.ledger.com/the-company, accessed 15 October 2021). BOLOS exposes a set of kernel-level cryptographic APIs, including attestation: any application can ask the kernel to measure its binary and produce a signed hash.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Truong, N.B.; Um, T.W.; Zhou, B.; Lee, G.M. Strengthening the blockchain-based internet of value with trust. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Rauchs, M.; Glidden, A.; Gordon, B.; Pieters, G.C.; Recanatini, M.; Rostand, F.; Vagneur, K.; Zhang, B.Z. Distributed Ledger Technology Systems: A Conceptual Framework; The Cambridge Centre for Alternative Finance: Cambridge, UK, 2018. [Google Scholar]
- Sunyaev, A. Distributed ledger technology. In Internet Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 265–299. [Google Scholar]
- Dossier Blockchain. 2021. Available online: https://www.statista.com/study/39859/blockchain-statista-dossier/ (accessed on 23 September 2021).
- Witzig, P.; Salomon, V. Cutting Out the Middleman: A Case Study of Blockchain-Induced Reconfigurations in the Swiss Financial Services Industry; Technical Report; Université de Neuchâtel: Neuchâtel, Switzerland, 2018. [Google Scholar]
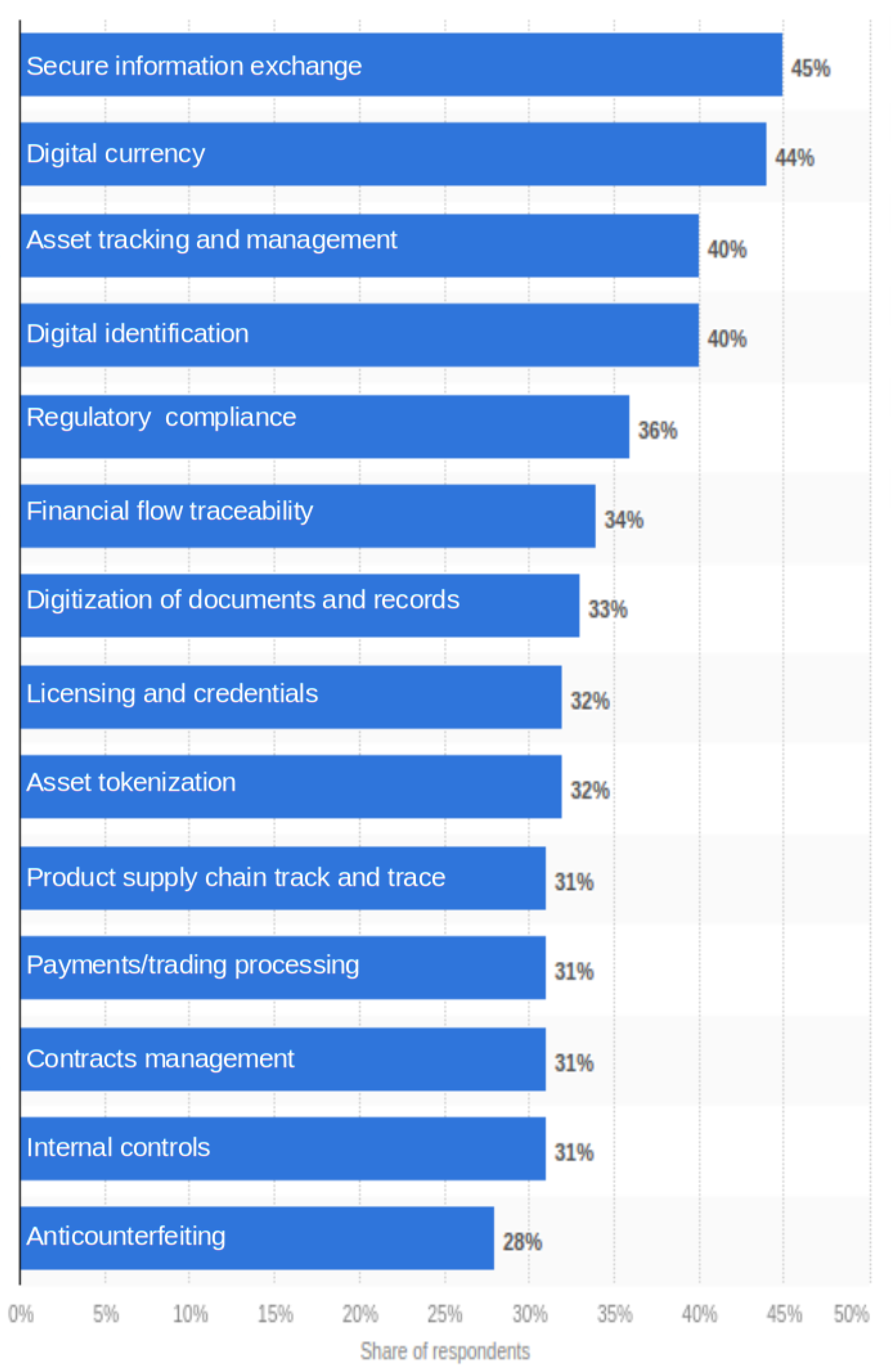
- Statista2021usecases. 2021. Available online: https://www.statista.com/statistics/878732/worldwide-use-cases-blockchain-technology/ (accessed on 23 September 2021).
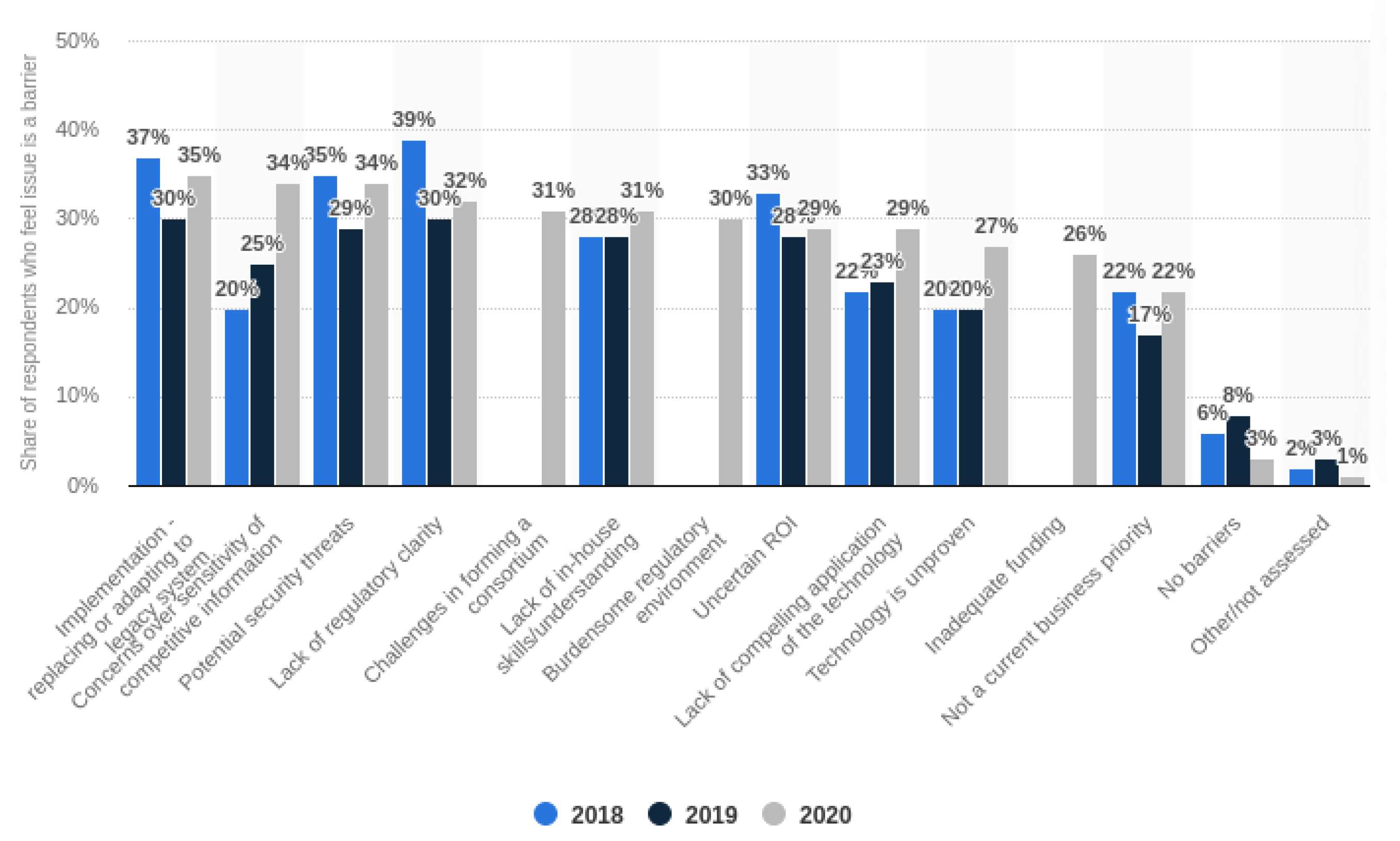
- Statista2020barriers. 2020. Available online: https://www.statista.com/statistics/878686/worldwide-investment-barriers-blockchain-technology/ (accessed on 23 September 2021).
- Babich, V.; Hilary, G. OM Forum—Distributed ledgers and operations: What operations management researchers should know about blockchain technology. Manuf. Serv. Oper. Manag. 2020, 22, 223–240. [Google Scholar] [CrossRef] [Green Version]
- Powell, W.; Foth, M.; Cao, S.; Natanelov, V. Garbage in garbage out: The precarious link between IoT and blockchain in food supply chains. J. Ind. Inf. Integr. 2021, 25, 100261. [Google Scholar] [CrossRef]
- Zhang, R.; Xue, R.; Liu, L. Security and privacy on blockchain. ACM Comput. Surv. 2019, 52, 51. [Google Scholar] [CrossRef] [Green Version]
- Belotti, M.; Božić, N.; Pujolle, G.; Secci, S. A vademecum on blockchain technologies: When, which, and how. IEEE Commun. Surv. Tutor. 2019, 21, 3796–3838. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, M.J.M.; Ferdous, M.S.; Biswas, K.; Chowdhury, N.; Kayes, A.; Alazab, M.; Watters, P. A comparative analysis of distributed ledger technology platforms. IEEE Access 2019, 7, 167930–167943. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhang, N.; Lou, W.; Hou, Y.T. A survey of distributed consensus protocols for blockchain networks. IEEE Commun. Surv. Tutor. 2020, 22, 1432–1465. [Google Scholar] [CrossRef] [Green Version]
- Antal, C.; Cioara, T.; Anghel, I.; Antal, M.; Salomie, I. Distributed Ledger Technology Review and Decentralized Applications Development Guidelines. Future Internet 2021, 13, 62. [Google Scholar] [CrossRef]
- Dorri, A.; Kanhere, S.; Jurdak, R. Blockchain for Cyberphysical Systems; Artech House: London, UK, 2020. [Google Scholar]
- Beniiche, A. A study of blockchain oracles. arXiv 2020, arXiv:2004.07140. [Google Scholar]
- Balagurusamy, V.S.K.; Cabral, C.; Coomaraswamy, S.; Delamarche, E.; Dillenberger, D.N.; Dittmann, G.; Friedman, D.; Gökçe, O.; Hinds, N.; Jelitto, J.; et al. Crypto anchors. IBM J. Res. Dev. 2019, 63, 4:1–4:12. [Google Scholar] [CrossRef]
- Prada-Delgado, M.A.; Dittmann, G.; Circiumaru, I.; Jelitto, J. A blockchain-based crypto-anchor platform for interoperable product authentication. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Fowler, M.; Lewis, J. Microservices. 2014. Available online: http://hashcash.org/docs/hashcash.txt (accessed on 14 June 2021).
- Newman, S. Building Microservices: Designing Fine-Grained Systems; O’Reilly Media, Inc.: Newton, MA, USA, 2015. [Google Scholar]
- Guo, D.; Wang, W.; Zeng, G.; Wei, Z. Microservices architecture based cloudware deployment platform for service computing. In Proceedings of the 2016 IEEE Symposium on Service-Oriented System Engineering (SOSE), Oxford, UK, 29 March–2 April 2016; pp. 358–363. [Google Scholar]
- Spoonhower, D. Lessons from the Birth of Microservices at Google. 2018. Available online: https://dzone.com/articles/lessons-from-the-birth-of-microservices-at-google (accessed on 23 September 2021).
- Hillpot, J. 4 Microservices Examples: Amazon, Netflix, Uber, and Etsy. 2021. Available online: https://blog.dreamfactory.com/microservices-examples/ (accessed on 23 September 2021).
- Gilder, G. Life after Google: The Fall of Big Data and the Rise of the Blockchain Economy; Simon and Schuster: New York, NY, USA, 2018. [Google Scholar]
- Zuboff, S. Big other: Surveillance capitalism and the prospects of an information civilization. J. Inf. Technol. 2015, 30, 75–89. [Google Scholar] [CrossRef]
- Pathirana, N. How to Set Up a Private Ethereum Blockchain. 2019. Available online: https://medium.com/swlh/how-to-set-up-a-private-ethereum-blockchain-c0e74260492c (accessed on 23 July 2021).
- Medicalchain Whitepaper 2.1. 2018. Available online: https://medicalchain.com/Medicalchain-Whitepaper-EN.pdf (accessed on 6 November 2021).
- Douceur, J.R. The sybil attack. In International Workshop on Peer-to-Peer Systems; Springer: Berlin/Heidelberg, Germany, 2002; pp. 251–260. [Google Scholar]
- Osipkov, I.; Vasserman, E.Y.; Hopper, N.; Kim, Y. Combating double-spending using cooperative P2P systems. In Proceedings of the 27th International Conference on Distributed Computing Systems (ICDCS’07), Toronto, ON, Canada, 25–27 June 2007; p. 41. [Google Scholar]
- Bevand, M. Cambridge Bitcoin Electricity Consumption Index. 2017. Available online: https://cbeci.org/ (accessed on 27 July 2021).
- Bevand, M. Energy Consumption of a Bitcoin (BTC, BTH) and VISA Transaction. 2021. Available online: https://www.statista.com/statistics/881541/bitcoin-energy-consumption-transaction-comparison-visa/ (accessed on 27 July 2021).
- Cox, J. Yellen Sounds Warning about “Extremely Inefficient” Bitcoin. 2021. Available online: https://www.cnbc.com/2021/02/22/yellen-sounds-warning-about-extremely-inefficient-bitcoin.html (accessed on 27 July 2021).
- Kolodny, L. Elon Musk Says Tesla Will Stop Accepting Bitcoin for Car Purchases, Citing Environmental Concerns. 2021. Available online: https://www.cnbc.com/2021/05/12/elon-musk-says-tesla-will-stop-accepting-bitcoin-for-car-purchases.html (accessed on 27 July 2021).
- Xu, B.; Luthra, D.; Cole, Z.; Blakely, N. EOS: An Architectural, Performance, and Economic Analysis. 2018, p. 25. Available online: https://whiteblock.io/wp-content/uploads/2019/07/eos-test-report.pdf (accessed on 1 August 2021).
- Goodman, L.M. Tezos—A Self-Amending Crypto-Ledger White Paper. 2014, p. 17. Available online: https://tezos.com/whitepaper.pdf (accessed on 1 August 2021).
- Internet Computer Governance. Available online: https://sdk.dfinity.org/docs/introduction/welcome.html (accessed on 1 August 2021).
- DFINITY Technical Library. Available online: https://dfinity.org/technicals (accessed on 1 August 2021).
- Kahng, A.; Mackenzie, S.; Procaccia, A. Liquid Democracy: An Algorithmic Perspective. J. Artif. Intell. Res. 2021, 70, 1223–1252. [Google Scholar] [CrossRef]
- Decred Documentation. Available online: https://docs.decred.org/ (accessed on 1 August 2021).
- Pelt, R.V.; Jansen, S.; Baars, D.; Overbeek, S. Defining Blockchain Governance: A Framework for Analysis and Comparison. Inf. Syst. Manag. 2021, 38, 21–41. [Google Scholar] [CrossRef]
- Johnson, D.; Menezes, A.; Vanstone, S. The elliptic curve digital signature algorithm (ECDSA). Int. J. Inf. Secur. 2001, 1, 36–63. [Google Scholar] [CrossRef]
- Cooper, D.; Santesson, S.; Farrell, S.; Boeyen, S.; Housley, R.; Polk, W. Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. 2008. Available online: http://tools.ietf.org/html/rfc5280 (accessed on 27 June 2021).
- Membership Service Providers. 2020. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/msp.html (accessed on 14 August 2021).
- Rani, D.; Ranjan, R.K. A comparative study of SaaS, PaaS and IaaS in cloud computing. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 158–161. [Google Scholar]
- Rimal, B.P.; Maier, M. Workflow scheduling in multi-tenant cloud computing environments. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 290–304. [Google Scholar] [CrossRef]
- Romano, D.; Schmid, G. Beyond bitcoin: A critical look at blockchain-based systems. Cryptography 2017, 1, 15. [Google Scholar] [CrossRef] [Green Version]
- Contract ABI Specification. 2020. Available online: https://docs.soliditylang.org/en/develop/abi-spec.html (accessed on 14 August 2021).
- Fabric Chaincode Lifecycle. 2020. Available online: https://hyperledger-fabric.readthedocs.io/en/release-2.2/chaincode_lifecycle.html (accessed on 14 August 2021).
- Nakamoto, S. Bitcoin: A Peer to Peer Electronic Cash System. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 27 June 2021).
- Rogaway, P.; Shrimpton, T. Cryptographic hash-function basics: Definitions, implications, and separations for preimage resistance, second-preimage resistance, and collision resistance. In Fast Software Encryption; Springer: Berlin/Heidelberg, Germany, 2004; pp. 371–388. [Google Scholar]
- Haber, S.; Stornetta, W.S. How to time-stamp a digital document. In Proceedings of the Conference on the Theory and Application of Cryptography, Santa Barbara, CA, USA, 11–15 August 1990; Springer: Berlin/Heidelberg, Germany, 1990; pp. 437–455. [Google Scholar]
- Merkle, R.C. A digital signature based on a conventional encryption function. In Proceedings of the Advances in Cryptology—CRYPTO’87, Santa Barbara, CA, USA, 16–20 August 1987; Springer: Berlin/Heidelberg, Germany, 1987; pp. 369–378. [Google Scholar]
- Dwork, C.; Naor, M. Pricing via processing or combatting junk mail. In Proceedings of the Advances in Cryptology—CRYPTO’92, Santa Barbara, CA, USA, 16–20 August 1992; Springer: Berlin/Heidelberg, Germany, 1993; pp. 139–147. [Google Scholar]
- Howell, A. The Longest Blockchain Is Not the Strongest Blockchain. 2019. Available online: https://cryptoservices.github.io/blockchain/consensus/2019/05/21/bitcoin-length-weight-confusion.html (accessed on 27 July 2021).
- Eyal, I.; Sirer, E.G. Majority is not enough: Bitcoin mining is vulnerable. In Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2014; pp. 436–454. [Google Scholar]
- Buterin, V. Ethereum White Paper. 2013. Available online: https://ethereum.org/en/whitepaper/ (accessed on 3 July 2021).
- Gervais, A.; Karame, G.O.; Wüst, K.; Glykantzis, V.; Ritzdorf, H.; Capkun, S. On the security and performance of proof of work blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 3–16. [Google Scholar]
- Szilagyi, P.; Wilcke, J.; Lange, F.; Zsolt, F. Go-Ethereum/Core/Blockchain.go: Difficulty Calculation. 2017. Available online: https://github.com/ethereum/go-ethereum/blob/525116dbff916825463931361f75e75e955c12e2/core/blockchain.go#L840 (accessed on 27 July 2021).
- Morrison, D.R. PATRICIA—Practical algorithm to retrieve information coded in alphanumeric. J. ACM 1968, 15, 514–534. [Google Scholar] [CrossRef]
- Lerner, S.D. DagCoin Draft. 2015. Available online: https://bitslog.files.wordpress.com/2015/09/dagcoin-v41.pdf (accessed on 27 July 2021).
- Thulasiraman, K.; Swamy, M.N. Graphs: Theory and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Ribero, Y. DagCoin Whitepaper. 2018. Available online: https://prismic-io.s3.amazonaws.com/dagcoin/f4e531e1-a5db-43b6-930c-14bf705e65ee_Dagcoin_White_Paper.pdf (accessed on 27 July 2021).
- Sompolinsky, Y.; Lewenberg, Y.; Zohar, A. SPECTRE: A fast and scalable cryptocurrency protocol. IACR Cryptol. ePrint Arch. 2016, 2016, 1–71. [Google Scholar]
- Li, C.; Li, P.; Zhou, D.; Xu, W.; Long, F.; Yao, A. Scaling nakamoto consensus to thousands of transactions per second. arXiv 2018, arXiv:1805.03870. [Google Scholar]
- Popov, S. The Tangle. 2018. Available online: https://assets.ctfassets.net/r1dr6vzfxhev/2t4uxvsIqk0EUau6g2sw0g/45eae33637ca92f85dd9f4a3a218e1ec/iota1_4_3.pdf (accessed on 27 July 2021).
- Popov, S.; Moog, H.; Camargo, D.; Capossele, A.; Dimitrov, V.; Gal, A.; Greve, A.; Kusmierz, B.; Mueller, S.; Penzkofer, A.; et al. The Coordicide. 2020. Available online: https://files.iota.org/papers/20200120_Coordicide_WP.pdf (accessed on 27 July 2021).
- Hearn, M.; Brown, R.G. Corda: A Distributed Ledger. 2019. Available online: https://www.r3.com/wp-content/uploads/2019/08/corda-technical-whitepaper-August-29-2019.pdf (accessed on 27 July 2021).
- Junqueira, F.P.; Reed, B.C.; Serafini, M. Zab: High-performance broadcast for primary-backup systems. In Proceedings of the IEEE/IFIP 41st International Conference on Dependable Systems & Networks (DSN), Hong Kong, China, 27–30 June 2011; pp. 245–256. [Google Scholar]
- Ongaro, D.; Ousterhout, J. In search of an understandable consensus algorithm. In Proceedings of the USENIX Annual Technical Conference ATC 14, Philadelphia, PA, USA, 19–20 June 2014; pp. 305–319. [Google Scholar]
- Lamport, L. Proving the correctness of multiprocess programs. IEEE Trans. Softw. Eng. 1977, SE-3, 125–143. [Google Scholar] [CrossRef] [Green Version]
- Lamport, L.; Shostak, R.; Pease, M. The Byzantine Generals Problem. ACM Trans. Program. Lang. Syst. 1982, 4, 382–401. [Google Scholar] [CrossRef] [Green Version]
- Pease, M.; Shostak, R.; Lamport, L. Reaching agreement in the presence of faults. J. ACM 1980, 27, 228–234. [Google Scholar] [CrossRef] [Green Version]
- Castro, M.; Liskov, B. Practical byzantine fault tolerance. OSDI 1999, 99, 173–186. [Google Scholar]
- Schneider, F.B. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv. 1990, 22, 299–319. [Google Scholar] [CrossRef]
- Miller, A.; Xia, Y.; Croman, K.; Shi, E.; Song, D. The honey badger of BFT protocols. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 31–42. [Google Scholar]
- Duan, S.; Reiter, M.K.; Zhang, H. BEAT: Asynchronous BFT made practical. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 2028–2041. [Google Scholar]
- Cachin, C.; Vukolić, M. Blockchain consensus protocols in the wild. arXiv 2017, arXiv:1707.01873. [Google Scholar]
- Bano, S.; Sonnino, A.; Al-Bassam, M.; Azouvi, S.; McCorry, P.; Meiklejohn, S.; Danezis, G. Consensus in the age of blockchains. arXiv 2017, arXiv:1711.03936. [Google Scholar]
- Wang, W.; Hoang, D.T.; Hu, P.; Xiong, Z.; Niyato, D.; Wang, P.; Wen, Y.; Kim, D.I. A survey on consensus mechanisms and mining strategy management in blockchain networks. IEEE Access 2019, 7, 22328–22370. [Google Scholar] [CrossRef]
- Wood, G. Ethereum: A Secure Decentralized Generalized Transaction Ledger. 2016. Available online: https://ethereum.github.io/yellowpaper/paper.pdf (accessed on 27 July 2021).
- King, S.; Nadal, S. Ppcoin: Peer-to-Peer Crypto-Currency with Proof-of-Stake. 2012. Available online: https://peercoin.net/assets/paper/peercoin-paper.pdf (accessed on 27 July 2021).
- Community, N. Nxt White Paper. 2014. Available online: https://www.jelurida.com/sites/default/files/NxtWhitepaper.pdf (accessed on 3 July 2021).
- Miller, A.; Juels, A.; Shi, E.; Parno, B.; Katz, J. Permacoin: Repurposing bitcoin work for data preservation. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 475–490. [Google Scholar]
- Chen, L.; Xu, L.; Shah, N.; Gao, Z.; Lu, Y.; Shi, W. On security analysis of proof-of-elapsed-time (poet). In Proceedings of the International Symposium on Stabilization, Safety, and Security of Distributed Systems, Boston, MA, USA, 5–8 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 282–297. [Google Scholar]
- Costan, V.; Devadas, S. Intel sgx explained. IACR Cryptol. ePrint Arch. 2016, 2016, 1–118. [Google Scholar]
- Ethash Design Rationale. 2020. Available online: https://eth.wiki/concepts/ethash/design-rationale (accessed on 3 July 2021).
- Proof of Stake FAQs. 2020. Available online: https://eth.wiki/concepts/proof-of-stake-faqs (accessed on 3 July 2021).
- Bentov, I.; Lee, C.; Mizrahi, A.; Rosenfeld, M. Proof of Activity: Extending Bitcoin’s Proof of Work via Proof of Stake. In Proceedings of the SIGMETRICS 2014 Workshop on Economics of Networked Systems, Austin, TX, USA, 16–20 June 2014. [Google Scholar]
- Li, W.; Andreina, S.; Bohli, J.M.; Karame, G. Securing proof-of-stake blockchain protocols. In Data Privacy Management, Cryptocurrencies and Blockchain Technology; Springer: Berlin/Heidelberg, Germany, 2017; pp. 297–315. [Google Scholar]
- Kiayias, A.; Russell, A.; David, B.; Oliynykov, R. Ouroboros: A provably secure proof-of-stake blockchain protocol. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 357–388. [Google Scholar]
- Gilad, Y.; Hemo, R.; Micali, S.; Vlachos, G.; Zeldovich, N. Algorand: Scaling byzantine agreements for cryptocurrencies. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28 October 2017; pp. 51–68. [Google Scholar]
- David, B.; Gaži, P.; Kiayias, A.; Russell, A. Ouroboros praos: An adaptively-secure, semi-synchronous proof-of-stake blockchain. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tel Aviv, Israel, 30 April–4 May 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 66–98. [Google Scholar]
- Daian, P.; Pass, R.; Shi, E. Snow white: Robustly reconfigurable consensus and applications to provably secure proof of stake. In Proceedings of the International Conference on Financial Cryptography and Data Security, St. Kitts, Saint Kitts and Nevis, 18–22 February 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 23–41. [Google Scholar]
- Buchman, E. Tendermint: Byzantine Fault Tolerance in the Age of Blockchains. Ph.D. Thesis, University of Guelph, Guelph, ON, Canada, 2016. [Google Scholar]
- Wood, G. PoA Private Chains. 2015. Available online: https://github.com/ethereum/guide/blob/master/poa.md (accessed on 27 July 2021).
- Buchman, E.; Kwon, J.; Milosevic, Z. The latest gossip on BFT consensus. arXiv 2019, arXiv:1807.04938. [Google Scholar]
- Bentov, I.; Gabizon, A.; Mizrahi, A. Cryptocurrencies without proof of work. In Proceedings of the International Conference on Financial Cryptography and Data Security, Christ Church, Barbados, 22–26 February 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 142–157. [Google Scholar]
- Stadler, M. Publicly verifiable secret sharing. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Saragossa, Spain, 12–16 May 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 190–199. [Google Scholar]
- Cramer, R.; Damgård, I. Multiparty computation, an introduction. In Contemporary Cryptology; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–87. [Google Scholar]
- Pass, R.; Shi, E. The sleepy model of consensus. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 380–409. [Google Scholar]
- Micali, S.; Rabin, M.; Vadhan, S. Verifiable random functions. In Proceedings of the 40th Annual Symposium on Foundations of Computer Science (cat. No. 99CB37039), New York, NY, USA, 17–19 October 1999; pp. 120–130. [Google Scholar]
- Bitshares Documentation: Delegated Proof of Stake (DPOS). Available online: https://how.bitshares.works/en/master/technology/dpos.html (accessed on 11 September 2021).
- Lavin, J.; Larimer, D.; Hourt, N.; Ma, Q.; Prioriello, W. EOS.IO Technical White Paper v2. 2018. Available online: https://github.com/EOSIO/Documentation/blob/master/TechnicalWhitePaper.md (accessed on 27 July 2021).
- Buterin, V.; Griffith, V. Casper the friendly finality gadget. arXiv 2017, arXiv:1710.09437. [Google Scholar]
- Dang, H.; Dinh, T.T.A.; Loghin, D.; Chang, E.C.; Lin, Q.; Ooi, B.C. Towards scaling blockchain systems via sharding. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 123–140. [Google Scholar]
- Schollmeier, R. A definition of peer-to-peer networking for the classification of peer-to-peer architectures and applications. In Proceedings of the First International Conference on Peer-to-Peer Computing, Linköping, Sweden, 27–29 August 2001; pp. 101–102. [Google Scholar]
- Fanti, G.; Viswanath, P. Deanonymization in the bitcoin P2P network. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1364–1373. [Google Scholar]
- Biryukov, A.; Tikhomirov, S. Deanonymization and linkability of cryptocurrency transactions based on network analysis. In Proceedings of the 2019 IEEE European Symposium on Security and Privacy (EuroS&P), Stockholm, Sweden, 17–19 June 2019; pp. 172–184. [Google Scholar]
- Ren, L. Analysis of Nakamoto Consensus. IACR Cryptol. ePrint Arch. 2019, 2019, 943. [Google Scholar]
- Fischer, M.J.; Lynch, N.A.; Paterson, M.S. Impossibility of distributed consensus with one faulty process. J. ACM 1985, 32, 374–382. [Google Scholar] [CrossRef]
- Liu, S.; Viotti, P.; Cachin, C.; Quéma, V.; Vukolić, M. XFT: Practical fault tolerance beyond crashes. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 485–500. [Google Scholar]
- Dolev, D.; Strong, H.R. Authenticated algorithms for Byzantine agreement. SIAM J. Comput. 1983, 12, 656–666. [Google Scholar] [CrossRef]
- Abraham, I.; Malkhi, D.; Nayak, K.; Ren, L.; Yin, M. Sync hotstuff: Simple and practical synchronous state machine replication. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 106–118. [Google Scholar]
- Dwork, C.; Lynch, N.; Stockmeyer, L. Consensus in the presence of partial synchrony. J. ACM 1988, 35, 288–323. [Google Scholar] [CrossRef]
- Bitcoin Wiki. Script. Available online: https://en.bitcoin.it/wiki/Script (accessed on 3 July 2021).
- Solidity Documentation. Available online: https://solidity.readthedocs.io/en/develop/ (accessed on 3 July 2021).
- Ethereum Virtual Machine (EVM). 2020. Available online: https://ethereum.org/en/developers/docs/evm/ (accessed on 14 August 2021).
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar] [CrossRef]
- Rosenfeld, M. Overview of Colored Coins. 2012. Available online: https://bitcoil.co.il/BitcoinX.pdf (accessed on 14 August 2021).
- Bitcoin Wiki. Colored Coins. Available online: https://en.bitcoin.it/wiki/Colored_Coins (accessed on 3 July 2021).
- Vogelsteller, F.; Buterin, V. EIP-20: Token Standard. 2015. Available online: https://eips.ethereum.org/EIPS/eip-20 (accessed on 14 August 2021).
- Entriken, W.; Shirley, D.; Evans, J.; Sachs, N. EIP-721: Non-Fungible Token Standard. 2018. Available online: https://eips.ethereum.org/EIPS/eip-721 (accessed on 14 August 2021).
- Reitwießner, C.; Johnson, N.; Vogelsteller, F.; Baylina, J.; Feldmeier, K.; Entriken, W. EIP-165: Standard Interface Detection. 2018. Available online: https://eips.ethereum.org/EIPS/eip-165 (accessed on 14 August 2021).
- Dafflon, J.; Baylina, J.; Shababi, T. EIP-777: Token Standard. 2017. Available online: https://eips.ethereum.org/EIPS/eip-777 (accessed on 14 August 2021).
- Radomski, W.; Cooke, A.; Castonguay, P.; Therien, J.; Binet, E.; Sandford, R. EIP-1155: Multi-Token Standard. 2018. Available online: https://eips.ethereum.org/EIPS/eip-1155 (accessed on 14 August 2021).
- Shiple, J.; Marks, H.; Zhang, D. EIP-1450: A Compatible Security Token for Issuing and Trading SEC-Compliant Securities. 2018. Available online: https://eips.ethereum.org/EIPS/eip-1450 (accessed on 14 August 2021).
- Kupriianov, M.; Svirsky, J. EIP-1462: Base Security Token. 2018. Available online: https://eips.ethereum.org/EIPS/eip-1462 (accessed on 14 August 2021).
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger fabric: A distributed operating system for permissioned blockchains. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018; pp. 1–15. [Google Scholar]
- Androulaki, E.; De Caro, A.; El Khiyaoui, K. Making Fungible Tokens and NFTs Safer to Use for Enterprises. 2021. Available online: https://www.ibm.com/blogs/blockchain/2021/06/making-fungible-tokens-and-nfts-safer-to-use-for-enterprises/ (accessed on 27 July 2021).
- Global Trade Item Number (GTIN). 2020. Available online: https://www.gs1.org/docs/idkeys/GS1_GTIN_Executive_Summary.pdf (accessed on 14 August 2021).
- Prada-Delgado, M.Á.; Baturone, I.; Dittmann, G.; Jelitto, J.; Kind, A. PUF-derived IoT identities in a zero-knowledge protocol for blockchain. Internet Things 2020, 9, 100057. [Google Scholar] [CrossRef]
- Schmid, G. Un procedimento di Anti-Contraffazione su Base Collaborativa. 2016. Available online: http://brevettidb.uibm.gov.it/download/177979616119184_W3_RM2014A000256-G07-4-28-023.pdf (accessed on 23 September 2021).
- Authenticity Proofs. 2019. Available online: https://docs.provable.xyz/#ethereum-quick-start-authenticity-proofs (accessed on 27 July 2021).
- SafetyNet Attestation API. 2021. Available online: https://developer.android.com/training/safetynet/attestation (accessed on 27 July 2021).
- Introducing BOLOS: Blockchain Open Ledger Operating System. 2016. Available online: https://www.ledger.com/introducing-bolos-blockchain-open-ledger-operating-system (accessed on 27 July 2021).
- Benet, J. IPFS–content addressed, versioned, p2p file system. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Breidenbach, L.; Cachin, C.; Chan, B.; Coventry, A.; Ellis, S.; Juels, A.; Koushanfar, F.; Miller, A.; Magauran, B.; Moroz, D.; et al. Chainlink 2.0: Next Steps in the Evolution of Decentralized Oracle Networks. 2021, p. 136. Available online: https://research.chain.link/whitepaper-v2.pdf (accessed on 1 August 2021).
- Ellis, S.; Juels, A.; Nazarov, S. ChainLink—A Decentralized Oracle Network. 2017, p. 38. Available online: https://research.chain.link/whitepaper-v1.pdf (accessed on 1 August 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HLF Field | Description |
|---|---|
| Block number | An integer starting at 0 (the genesis block), and increased by 1 for every new block appended to the blockchain. |
| Current block hash | The Merkle tree root of all the transactions contained in the current block. |
| Previous block hash | The hash digest from the previous block header. |
| ETH Field | Description |
| Number | Number of ancestor blocks (genesis block = 0). |
| Hash | Hash digest, which combined with Nonce proves that the PoW has been carried out for this block. |
| Parent hash | The hash digest from the previous block header. |
| Nonce | The solution to the PoW for this block. |
| Uncles hash | The hash digest of the list of uncles for this block, which are children of the parent block that are not parents of this block. |
| Logs bloom | Bloom filter of the indexable info contained in the log entry from the receipt of each transaction in the transaction list. |
| Transactions root | Hash digest of the Patricia trie built from the transaction list. |
| State root | Hash digest of the Patricia trie built from the world state, which maps addresses to account states. |
| Receipts root | Hash digest of the Patricia trie built from the receipts of the transactions in the transaction list. |
| Miner | Address for the fees collected because of successful mining. |
| Extra data | Arbitrary byte array (<32 byte) containing data relevant to this block. |
| Gas limit | Current limit of gas expenditure per block. |
| Gas used | Total gas used for the transactions in this block. |
| Timestamp | Unix time at the inception of this block. |
| HLF Field | Description |
|---|---|
| Header | Metadata about the transaction (e.g., name of the relevant chaincode, and its version). |
| Signature | A cryptographic signature by the client application is used to check if the transaction details have not been tampered with. |
| Proposal | Encodes the input parameters supplied by an application to the smart contract, which creates the proposed ledger update. |
| Response | The output of a smart contract that captures the world state before and after this transaction. |
| Endorsements | A list of signed transaction responses from each required endorser sufficient to satisfy the endorsement policy. |
| ETH Field | Description |
| Nonce | A sequence number of transactions from a given address, which is increased by one for each new transaction in order to prevent reply attacks. |
| Gas price | Price of Gas in Gwei (1 Gwei = ether). |
| Gas limit | Limit of the amount of ETH the sender is willing to pay for the transaction. |
| Recipient | An external owned address (EOA) or a contract address, which is the destination of this transaction. |
| Value | The amount of ether/wei from the sender to the recipient. Value is used for both transfer money and contract execution. |
| Data | Data for activities, such as deployment or execution of a contract. |
| (v, r, s) | Components of the transaction signature by the sender with the Elliptic Curve Digital Signature Algorithm (ECDSA). |
| NET Protocol | Proposer Selection | Validation Check | Finalization Rule |
|---|---|---|---|
| PBFT | Client request | Signature | Mutual agreement |
| Nakamoto | PoW solver | PoW solution | Heaviest chain |
| Ethash + GHOST | PoW solver | PoW solution | GHOST variant |
| PoET | TEE waiting time | TEE attestation | Longest chain |
| Ethash + Casper FFG | PoW solver | PoW solution | Casper FFG |
| COM Protocol | Proposer Selection | Validation Check | Finalization Rule |
| Tendermint | Round robin | Stake, signature | Mutual agreement |
| Chain of Activity | FTS output | FTS output | Longest chain |
| Proof of Authority | Certification | Signature | Mutual agreement |
| Honey Badger BFT | Client request | Signature | Mutual agreement |
| Ouroboros | FTS and PVSS | PVSS output | Longest chain |
| Algorand | VRF + agreement | VRF, signature | Mutual agreement |
| Ouroboros Praos | VRF output | VRF output | Longest chain |
| Snow White | PRF (application) | PoS solution | Longest chain |
| Delegated PoS | Stake delegation | Delegate eligibility | Mutual agreement |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romano, D.; Schmid, G. Beyond Bitcoin: Recent Trends and Perspectives in Distributed Ledger Technology. Cryptography 2021, 5, 36. https://doi.org/10.3390/cryptography5040036
Romano D, Schmid G. Beyond Bitcoin: Recent Trends and Perspectives in Distributed Ledger Technology. Cryptography. 2021; 5(4):36. https://doi.org/10.3390/cryptography5040036
Chicago/Turabian StyleRomano, Diego, and Giovanni Schmid. 2021. "Beyond Bitcoin: Recent Trends and Perspectives in Distributed Ledger Technology" Cryptography 5, no. 4: 36. https://doi.org/10.3390/cryptography5040036
APA StyleRomano, D., & Schmid, G. (2021). Beyond Bitcoin: Recent Trends and Perspectives in Distributed Ledger Technology. Cryptography, 5(4), 36. https://doi.org/10.3390/cryptography5040036