
ChaCha20–Poly1305 Authenticated Encryption with Additional Data for Transport Layer Security 1.3 †


Abstract
:1. Introduction
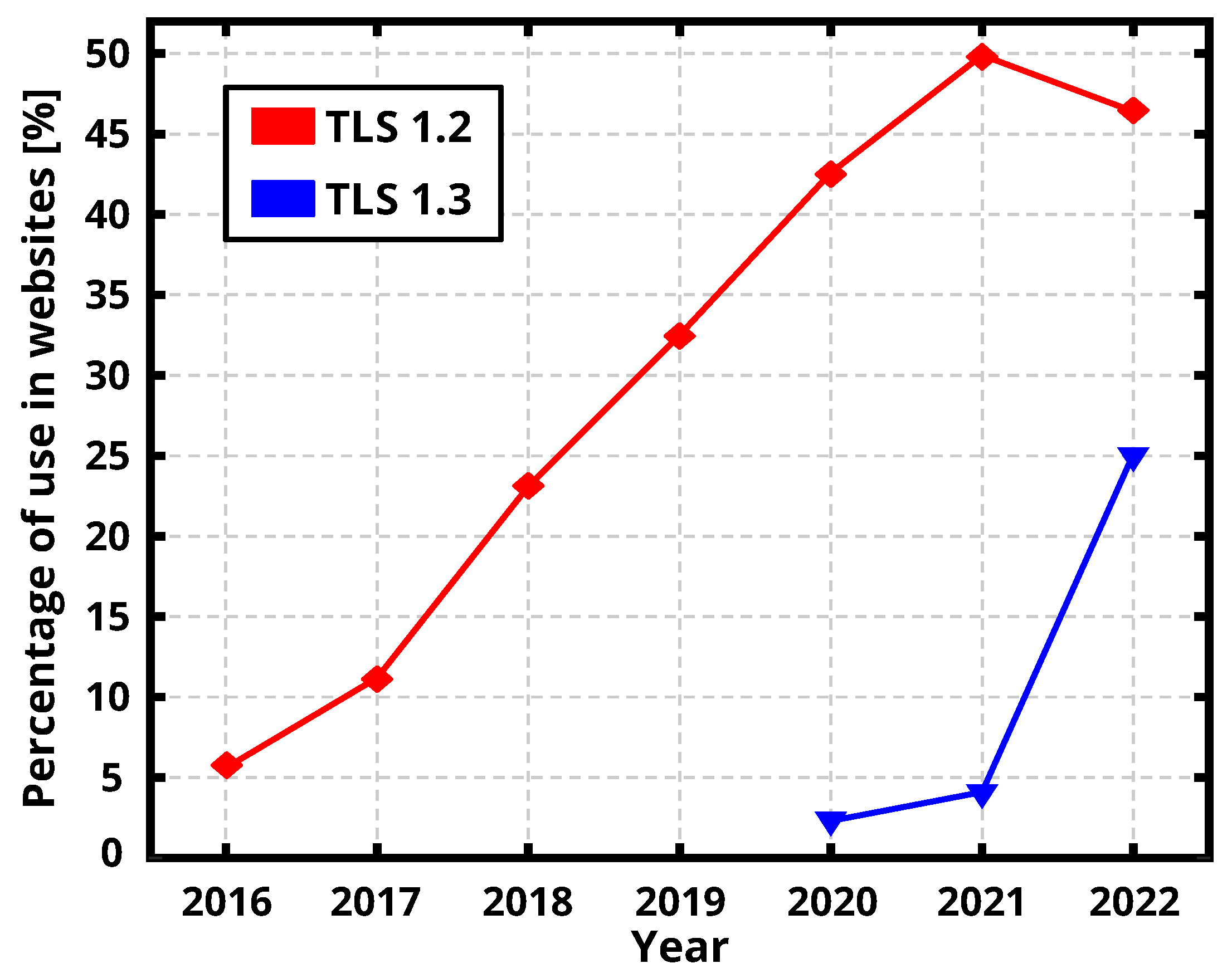
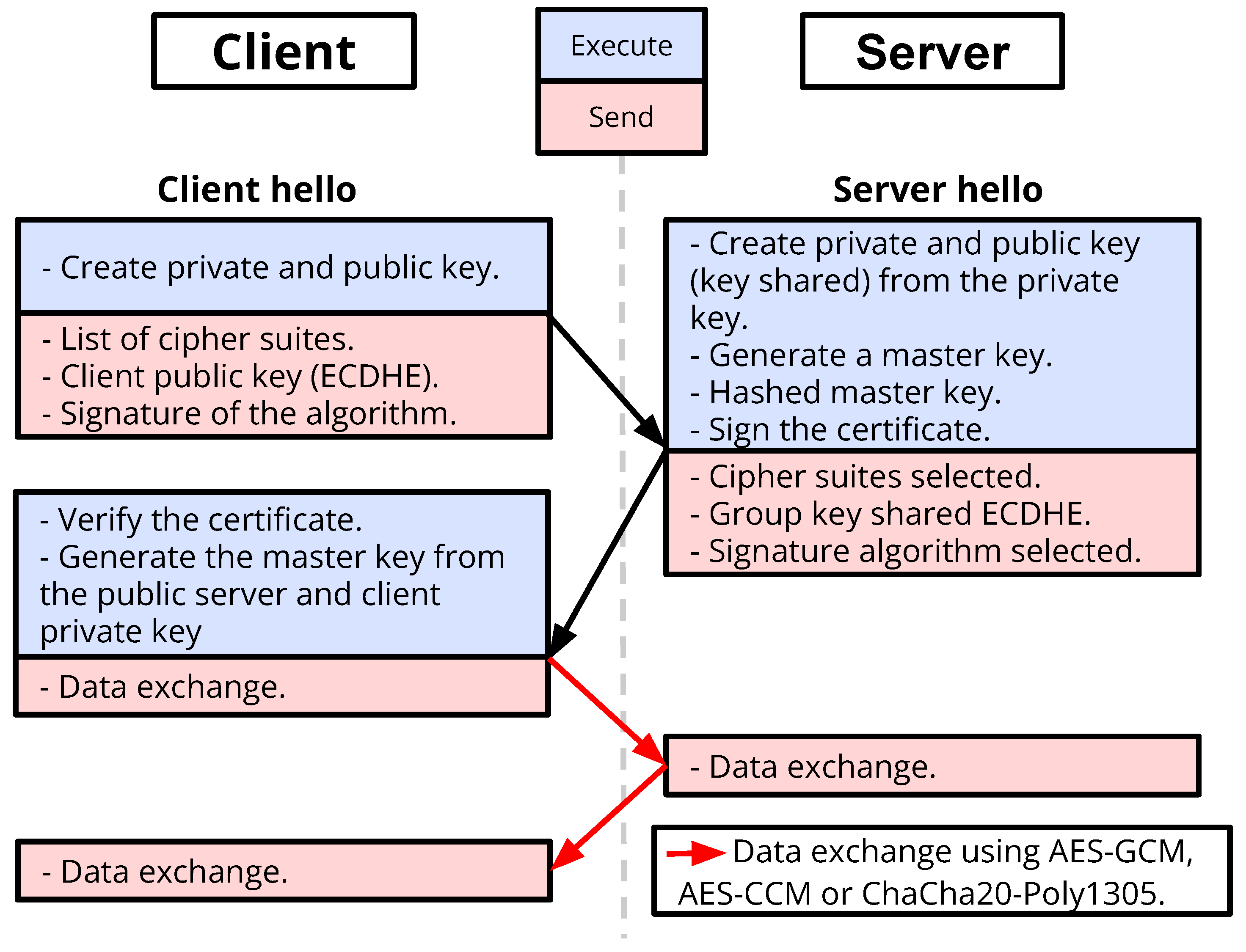
2. Transport Layer Security
3. ChaCha20
3.1. Algorithm
| Algorithm 1 ChaCha20 cipher suite algorithm |
| Require:K ∈ , N ∈ , C ∈ , ∈ Ensure: ChaCha20
|
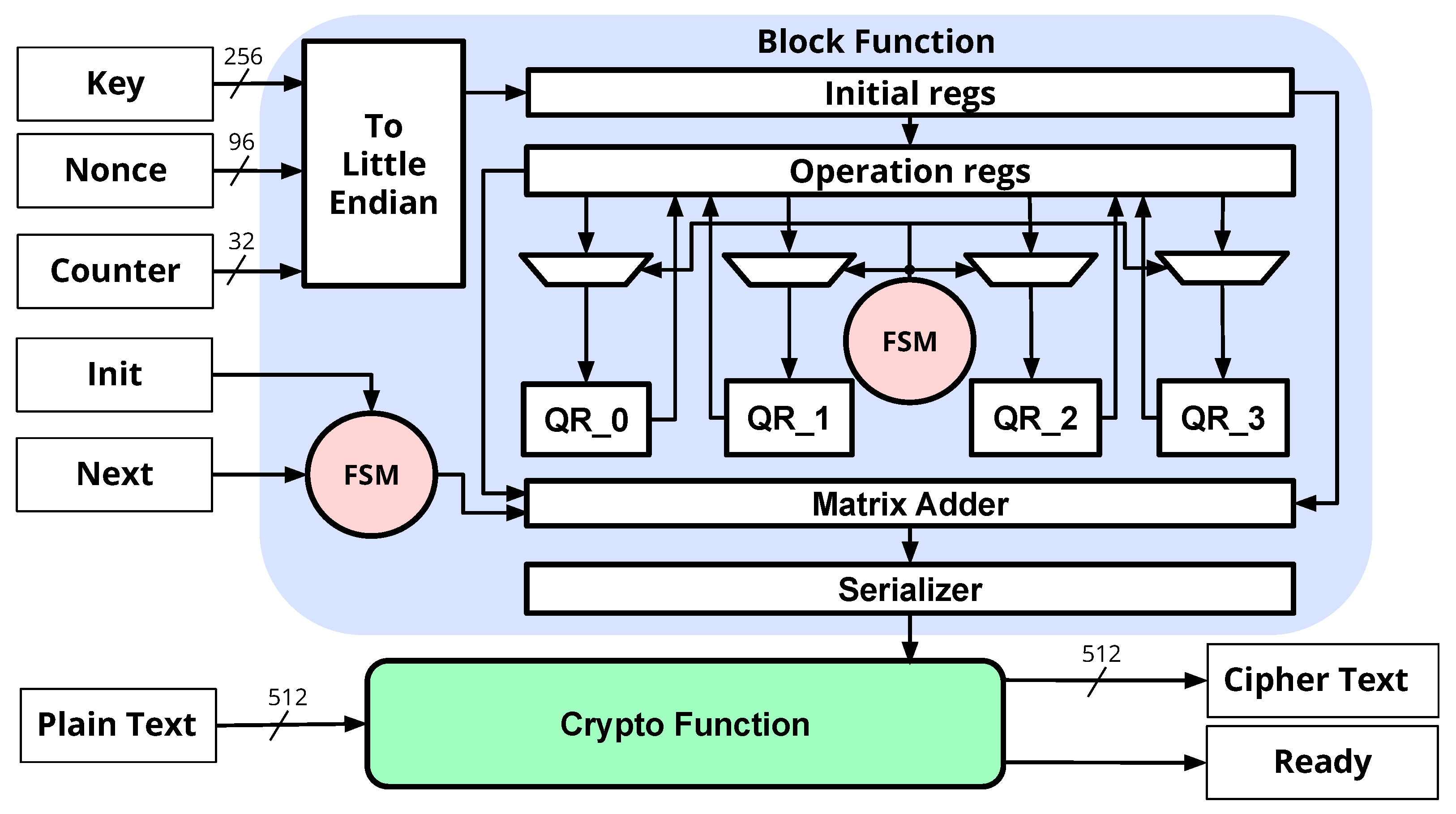
3.2. Hardware Implementation
4. Poly1305
4.1. Algorithm
| Algorithm 2 Poly1305 authenticator algorithm |
| Require: Ensure: Poly1305
|
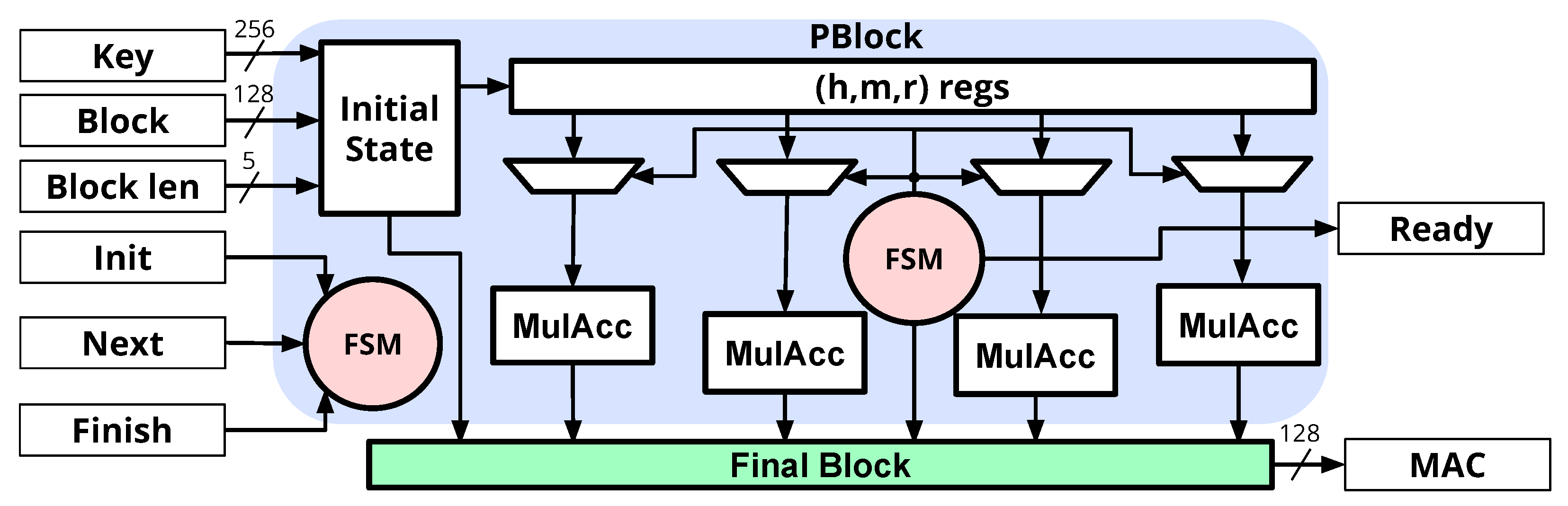
4.2. Hardware Implementation
5. System Implementation
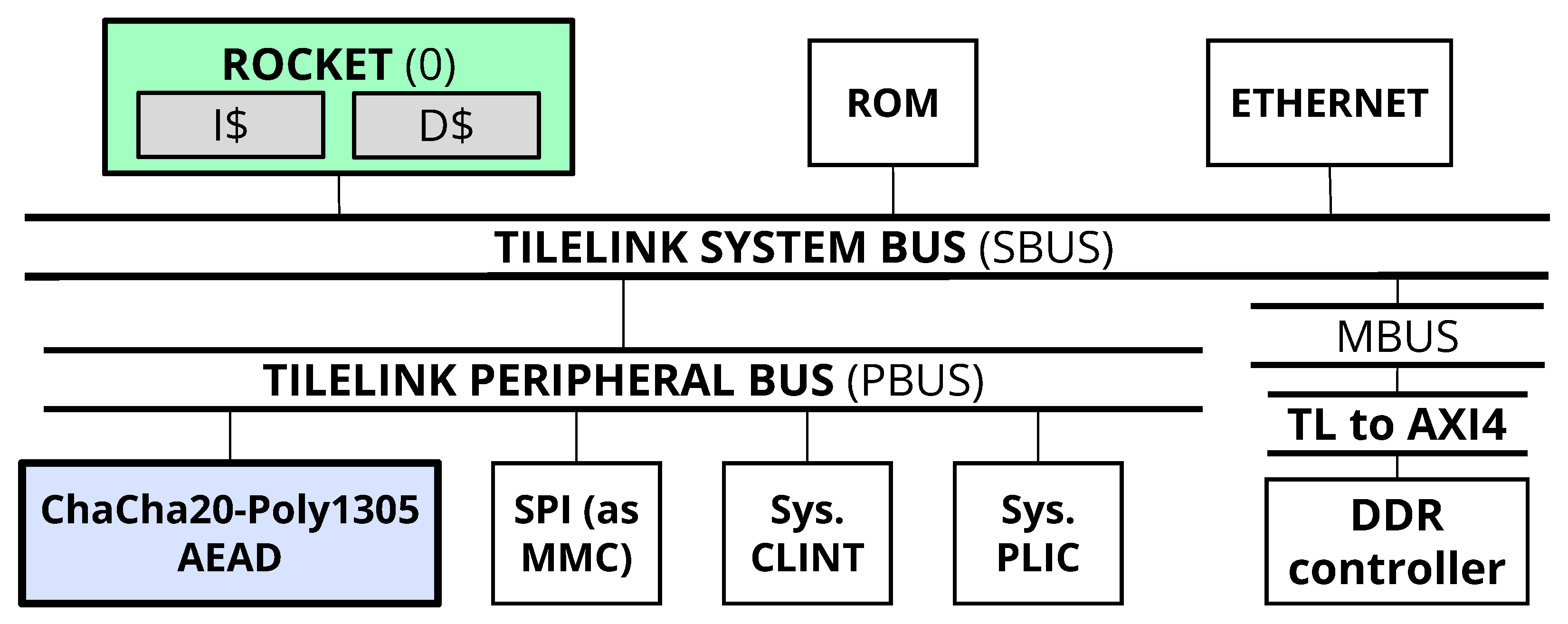
5.1. SoC Implementation
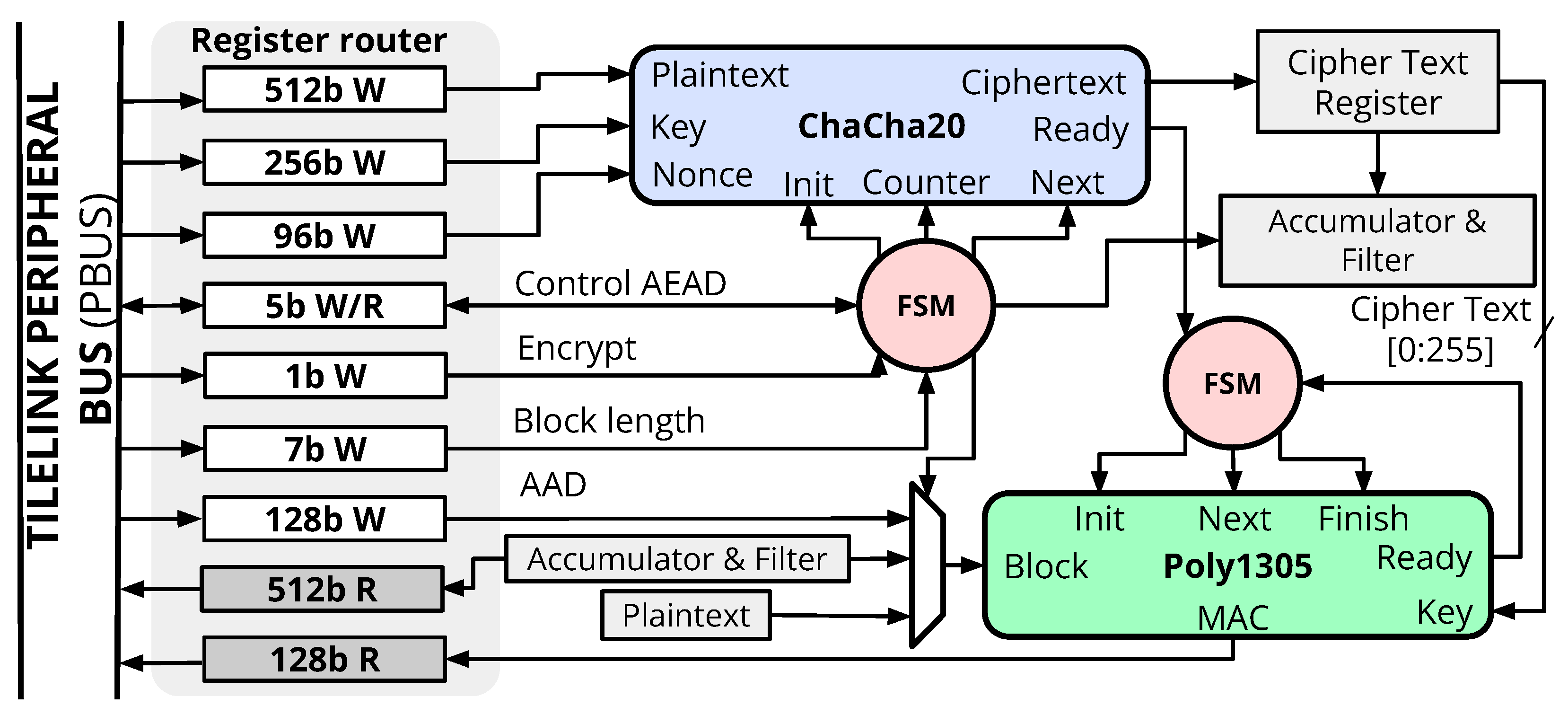
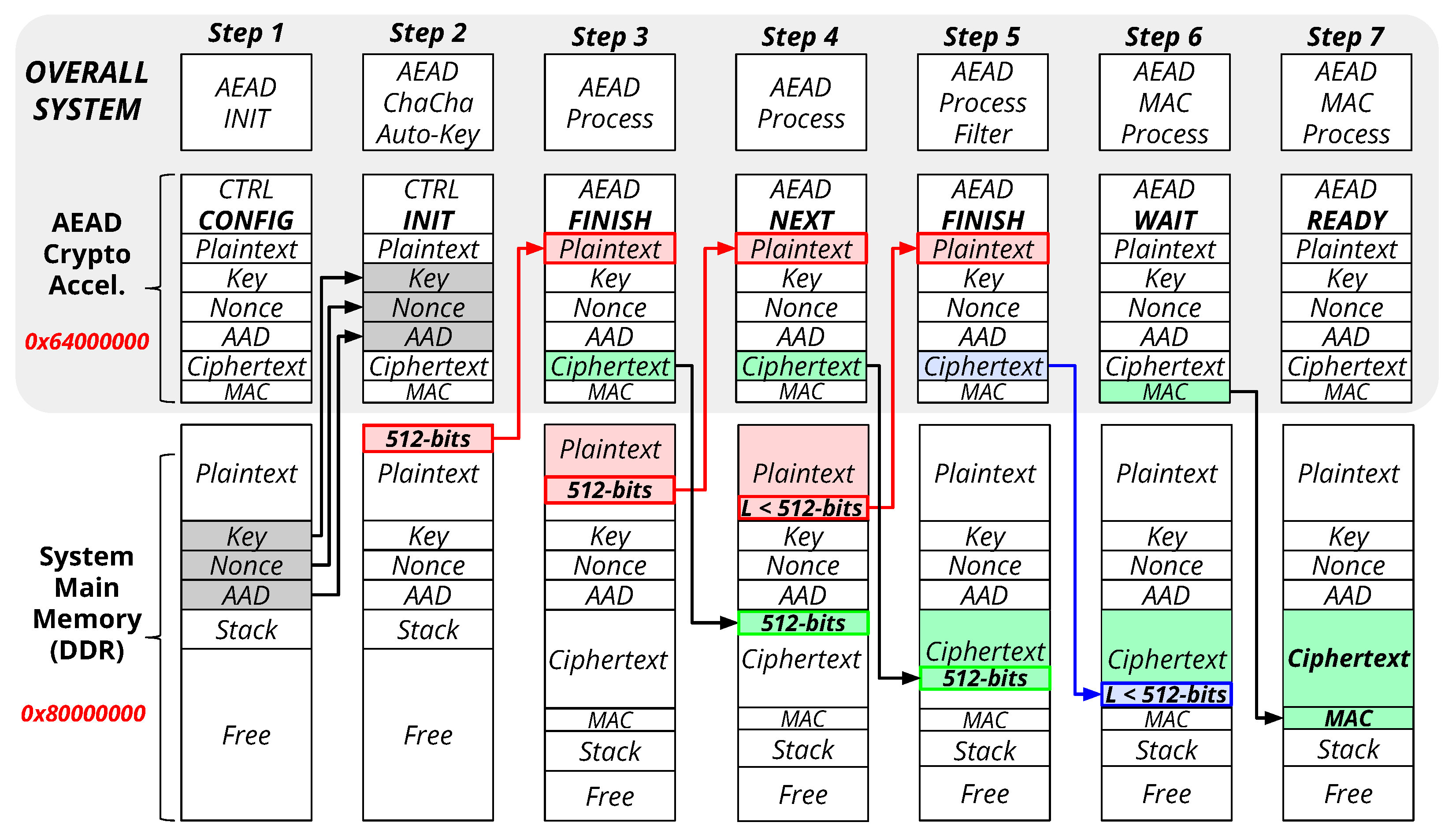
5.2. ChaCha20–Poly1305 AEAD
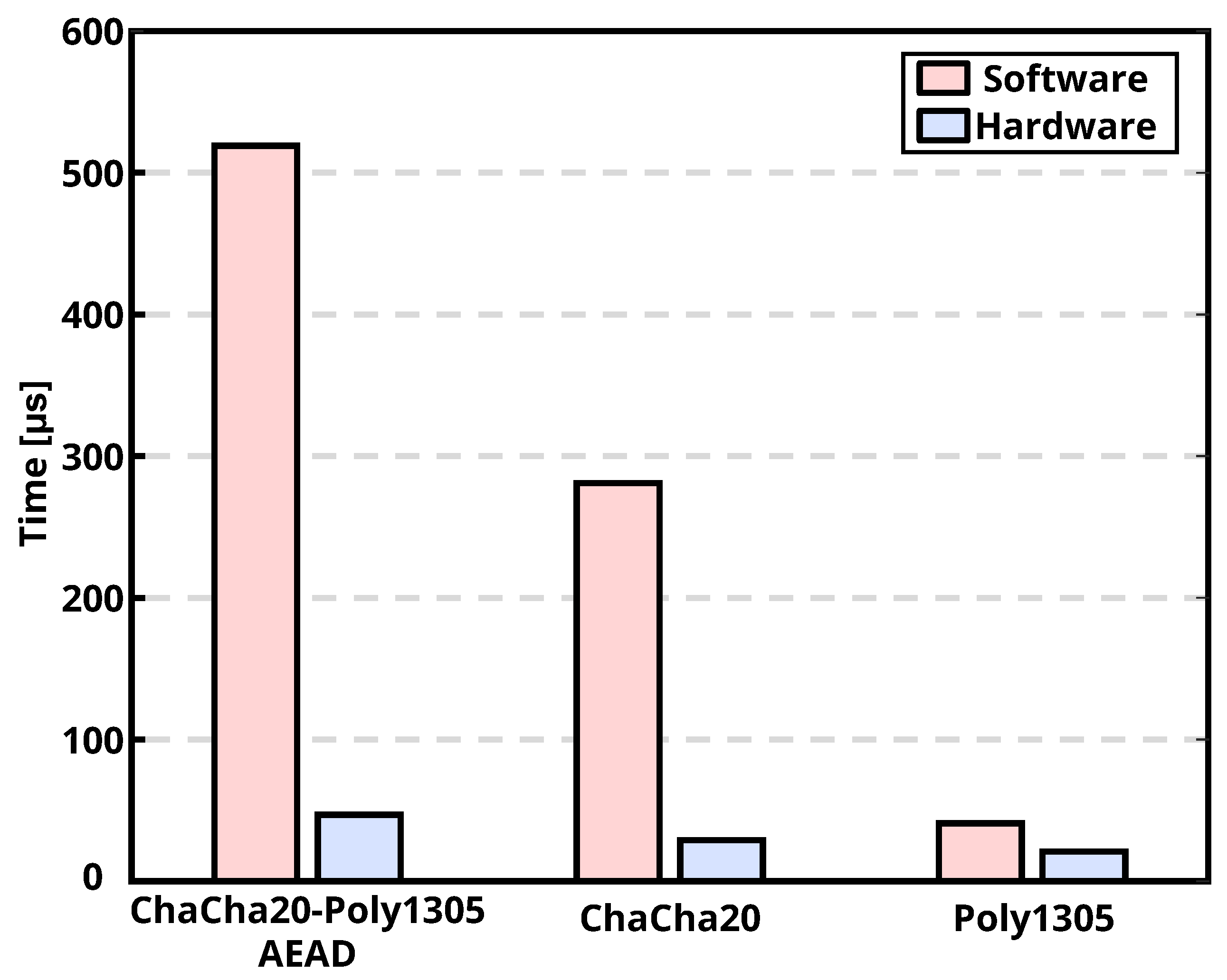
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lim, J.P.; Nagarakatte, S. Automatic Equivalence Checking for Assembly Implementations of Cryptography Libraries. In Proceedings of the IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Washington, DC, USA, 16–20 February 2019; pp. 37–49. [Google Scholar]
- Saraiva, D.A.F.; Leithardt, V.R.Q.; de Paula, D.; Mendes, A.S.; González, G.V.; Crocker, P. PRISEC: Comparison of Symmetric Key Algorithms for IoT Devices. Sensors 2019, 19, 4312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Najm, Z.; Jap, D.; Jungk, B.; Picek, S.; Bhasin, S. On Comparing Side-channel Properties of AES and ChaCha20 on Microcontrollers. In Proceedings of the IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Chengdu, China, 26–30 October 2018; pp. 552–555. [Google Scholar]
- Rescorla, E. The Transport Layer Security (TLS) Protocol Version 1.3. RFC 8446, August 2018. Available online: https://datatracker.ietf.org/doc/html/rfc8446 (accessed on 10 June 2022).
- Almeida, J.B.; Barbosa, M.; Barthe, G.; Grégoire, B.; Koutsos, A.; Laporte, V.; Oliveira, T.; Strub, P.-Y. The Last Mile: High-Assurance and High-Speed Cryptographic Implementations. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 965–982. [Google Scholar]
- De Santis, F.; Schauer, A.; Sigl, G. ChaCha20-Poly1305 Authenticated Encryption for High-speed Embedded IoT Applications. In Proceedings of the Design, Automation & Test in Europe Conference Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 692–697. [Google Scholar]
- Jungk, B.; Bhasin, S. Do not Fall Into a Trap: Physical Side-channel Analysis of ChaCha20-Poly1305. In Proceedings of the Design, Automation & Test in Europe Conference Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1110–1115. [Google Scholar]
- Lavaud, A.D.; Fournet, C.; Kohlweiss, M.; Protzenko, J.; Rastogi, A.; Swamy, N.; Beguelin, S.Z.; Bhargavan, K.; Pan, J.; Zinzindohoue, J.K. Implementing and Proving the TLS 1.3 Record Layer. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 463–482. [Google Scholar]
- Islam, M.M.; Paul, S.; Haque, M.M. Reducing Network Overhead of IoT DTLS Protocol Employing ChaCha20 and Poly1305. In Proceedings of the International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; pp. 1–7. [Google Scholar]
- Barthe, G.; Cauligi, S.; Grégoire, B.; Koutsos, A.; Liao, K.; Oliveira, T.; Priya, S.; Rezk, T.; Schwabe, P. High-Assurance Cryptography in the Spectre Era. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 1884–1901. [Google Scholar]
- Sadio, O.; Ngom, I.; Lishou, C. Lightweight Security Scheme for MQTT/MQTT-SN Protocol. In Proceedings of the International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Granada, Spain, 22–25 October 2019; pp. 119–123. [Google Scholar]
- Aamir, M.; Sharma, S.; Grover, A. ChaCha20-in-Memory for Side-Channel Resistance in IoT Edge-Node Devices. IEEE Open J. Circ. Syst. 2021, 2, 833–842. [Google Scholar] [CrossRef]
- Pfau, J.; Reuter, M.; Harbaum, T.; Hofmann, K.; Becker, J. A Hardware Perspective on the ChaCha Ciphers: Scalable Chacha8/12/20 Implementations Ranging from 476 Slices to Bitrates of 175 Gbit/s. In Proceedings of the IEEE International System-on-Chip Conference (SOCC), Singapore, 3–6 September 2019; pp. 294–299. [Google Scholar]
- Henzen, L.; Carbognani, F.; Felber, N.; Fichtner, W. VLSI Hardware Evaluation of the Stream Ciphers Salsa20 and ChaCha, and the Compression Function Rumba. In Proceedings of the International Conference on Signals, Circuits and Systems (SCS), Monastir, Tunisia, 7–9 November 2008; pp. 1–5. [Google Scholar]
- Kermani, M.M.; Azarderakhsh, R.; Aghaie, A. Fault Detection Architectures for Post-Quantum Cryptographic Stateless Hash-Based Secure Signatures Benchmarked on ASIC. ACM Trans. Embed. Comput. Syst. 2017, 16, 1–19. [Google Scholar] [CrossRef]
- Kanda, G.; Ryoo, K. High-Throughput Low-Area Hardware Design of Authenticated Encryption with Associated Data Cryptosystem that Uses ChaCha20 and Poly1305. Int. J. Recent Technol. Eng. 2019, 8, 86–94. [Google Scholar]
- Rambus Inc. Cipher Accelerators: CHACHA-IP-13 ChaCha20 Accelerators, 2021. Available online: https://www.rambus.com/security/crypto-accelerator-hardware-cores/basic-crypto-blocks/chacha-ip-13/ (accessed on 10 June 2022).
- Rambus Inc. Hash Accelerators: POLY-IP-53 Poly1305-based MAC Accelerators, 2021. Available online: https://www.rambus.com/security/crypto-accelerator-hardware-cores/basic-crypto-blocks/poly-ip-53/ (accessed on 10 June 2022).
- SilexInsight. ChaCha20-Poly1305 AEAD Crypto Engine, 2021. Available online: https://www.silexinsight.com/products/security/chacha20-poly1305-ip-core/ (accessed on 10 June 2022).
- Serrano, R.; Duran, C.; Hoang, T.-T.; Sarmiento, M.; Tsukamoto, A.; Suzaki, K.; Pham, C.-K. ChaCha20-Poly1305 Crypto Core Compatible with Transport Layer Security 1.3. In Proceedings of the International SoC Design Conference (ISOCC), Jeju Island, Korea, 6–9 October 2021; pp. 17–18. [Google Scholar]
- Li, J.; Chen, R.; Su, J.; Huang, X.; Wang, X. ME-TLS: Middlebox-Enhanced TLS for Internet-of-Things Devices. IEEE Internet Things J. 2019, 7, 1216–1229. [Google Scholar] [CrossRef]
- W3 Techs. Usage Statistics of Default Protocol Https for Websites, May 2022. Available online: https://w3techs.com/technologies/details/ce-httpsdefault (accessed on 10 June 2022).
- Rescorla, E.; Dierks, T. The Transport Layer Security (TLS) Protocol Version 1.2. RFC 5246, August 2008. Available online: https://datatracker.ietf.org/doc/html/rfc5246 (accessed on 10 June 2022).
- Rodríguez, M.; Astarloa, A.; Lázaro, J.; Bidarte, U.; Jiménez, J. System-on-Programmable-Chip AES-GCM implementation for wire-speed cryptography for SAS. In Proceedings of the Conference on Design of Circuits and Integrated Systems (DCIS), Lyon, France, 14–16 November 2018; pp. 1–6. [Google Scholar]
- Koteshwara, S.; Das, A.; Parhi, K.K. Architecture Optimization and Performance Comparison of Nonce-Misuse-Resistant Authenticated Encryption Algorithms. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1053–1066. [Google Scholar] [CrossRef]
- Hoang, V.-P.; Phan, T.-T.-D.; Dao, V.-L.; Pham, C.-K. A compact, ultra-low power AES-CCM IP core for wireless body area networks. In Proceedings of the International Conference on Very Large Scale Integration (VLSI-SoC), Tallinn, Estonia, 26–28 September 2016; pp. 1–4. [Google Scholar]
- Badillo, I.A.; Uribe, C.F.; Cumplido, R.; Sandoval, M.M. FPGA Implementation and Performance Evaluation of AES-CCM Cores for Wireless Networks. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 3–5 December 2008; pp. 421–426. [Google Scholar]
- Nir, Y.; Langley, A. ChaCha20 and Poly1305 for IETF Protocols. RFC 8439, June 2018. Available online: https://datatracker.ietf.org/doc/html/rfc8439 (accessed on 10 June 2022).
- Bernstein, D.J. The Salsa20 Family of Stream Ciphers. In New Stream Cipher Designs: The eSTREAM Finalists; Springer: Berlin/Heidelberg, Germany, 2008; pp. 84–97. [Google Scholar]
- Hoang, T.-T.; Duran, C.; Serrano, R.; Sarmiento, M.; Nguyen, K.-D.; Tsukamoto, A.; Suzaki, K.; Pham, C.-K. Trusted Execution Environment Hardware by Isolated Heterogeneous Architecture for Key Scheduling. IEEE Access 2022, 10, 46014–46027. [Google Scholar] [CrossRef]
- RISC-V Foundation. Rocket Chip Generator, 2019. Available online: https://github.com/chipsalliance/rocket-chip (accessed on 10 June 2022).
- SiFive, Inc. SiFive TileLink Specification, August 2019. Available online: https://static.dev.sifive.com/docs/tilelink/tilelink-spec-1.7-draft.pdf (accessed on 10 June 2022).
- ARM. AMBA AXI and ACE Protocol Specification; Jan. 2021. Available online: https://developer.arm.com/documentation/ihi0022/hc?lang=en (accessed on 10 June 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slices | Performance (Cycles/Byte) | ||||
|---|---|---|---|---|---|
| Module | LUT | FF | Total | Standalone | System |
| This work | 10,808 | 3731 | 14,539 | 1.4 | 11.56 |
| [16] | 3383 | 4921 | 8304 | 21.26 | N/A |
| [20] | 7897 | 4840 | 12,737 | N/A | 21.50 |
| Module | Device | Resources Utilization | Standalone Imp. | System Imp. | ||||
|---|---|---|---|---|---|---|---|---|
| LUT FF | Slices BRAM | Max. Freq. (MHz) | Througput (Gbps) | Cycles/ Byte | Cycles/ Byte | |||
| This work | ChaCha20 Poly1305 | Virtex7 C7VX485T | 10,808 3731 | 3034 0 | 166 | 0.948 | 1.4 | 11.56 |
| [24] | AES-GCM | Virtex7 | — — | 4194 40 | 125 | 4 * | — | — |
| [25] | AES-GCM | Cyclone V 5CSEMA4U23C6 | 4572 2407 | — 0 | 36.46 | 0.275 | 1.058 | 19.19 |
| [26] | AES-CCM | Artix7 XC7A200TL | — — | 554 76 | 177 | 0.119 | 11.89 | — |
| [27] | AES-CCM | Virtex4 XC4VLX40 | 1995 0 | 1200 18 | 152 | 1.951 * | 0.635 | — |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serrano, R.; Duran, C.; Sarmiento, M.; Pham, C.-K.; Hoang, T.-T. ChaCha20–Poly1305 Authenticated Encryption with Additional Data for Transport Layer Security 1.3. Cryptography 2022, 6, 30. https://doi.org/10.3390/cryptography6020030
Serrano R, Duran C, Sarmiento M, Pham C-K, Hoang T-T. ChaCha20–Poly1305 Authenticated Encryption with Additional Data for Transport Layer Security 1.3. Cryptography. 2022; 6(2):30. https://doi.org/10.3390/cryptography6020030
Chicago/Turabian StyleSerrano, Ronaldo, Ckristian Duran, Marco Sarmiento, Cong-Kha Pham, and Trong-Thuc Hoang. 2022. "ChaCha20–Poly1305 Authenticated Encryption with Additional Data for Transport Layer Security 1.3" Cryptography 6, no. 2: 30. https://doi.org/10.3390/cryptography6020030
APA StyleSerrano, R., Duran, C., Sarmiento, M., Pham, C.-K., & Hoang, T.-T. (2022). ChaCha20–Poly1305 Authenticated Encryption with Additional Data for Transport Layer Security 1.3. Cryptography, 6(2), 30. https://doi.org/10.3390/cryptography6020030