
Improve Parallel Resistance of Hashcash Tree


Abstract
1. Introduction
2. Background
2.1. Hash Functions and Hashcash
- (i)
- the probability of a particular hash value for a message is ;
- (ii)
- finding a message that matches a given hash value is unfeasible (preimage resistance);
- (iii)
- finding a second message that matches the hash value of a given message is unfeasible (second-preimage resistance);
- (iv)
- finding two different messages that yield the same hash value is unfeasible (collision resistance).
| Algorithm 1: Hashcash(s, h, k) |
 |
| Algorithm 2: HashcashVerify(, s, h, k) |
1 return and ; |
2.2. Hashcash Trees
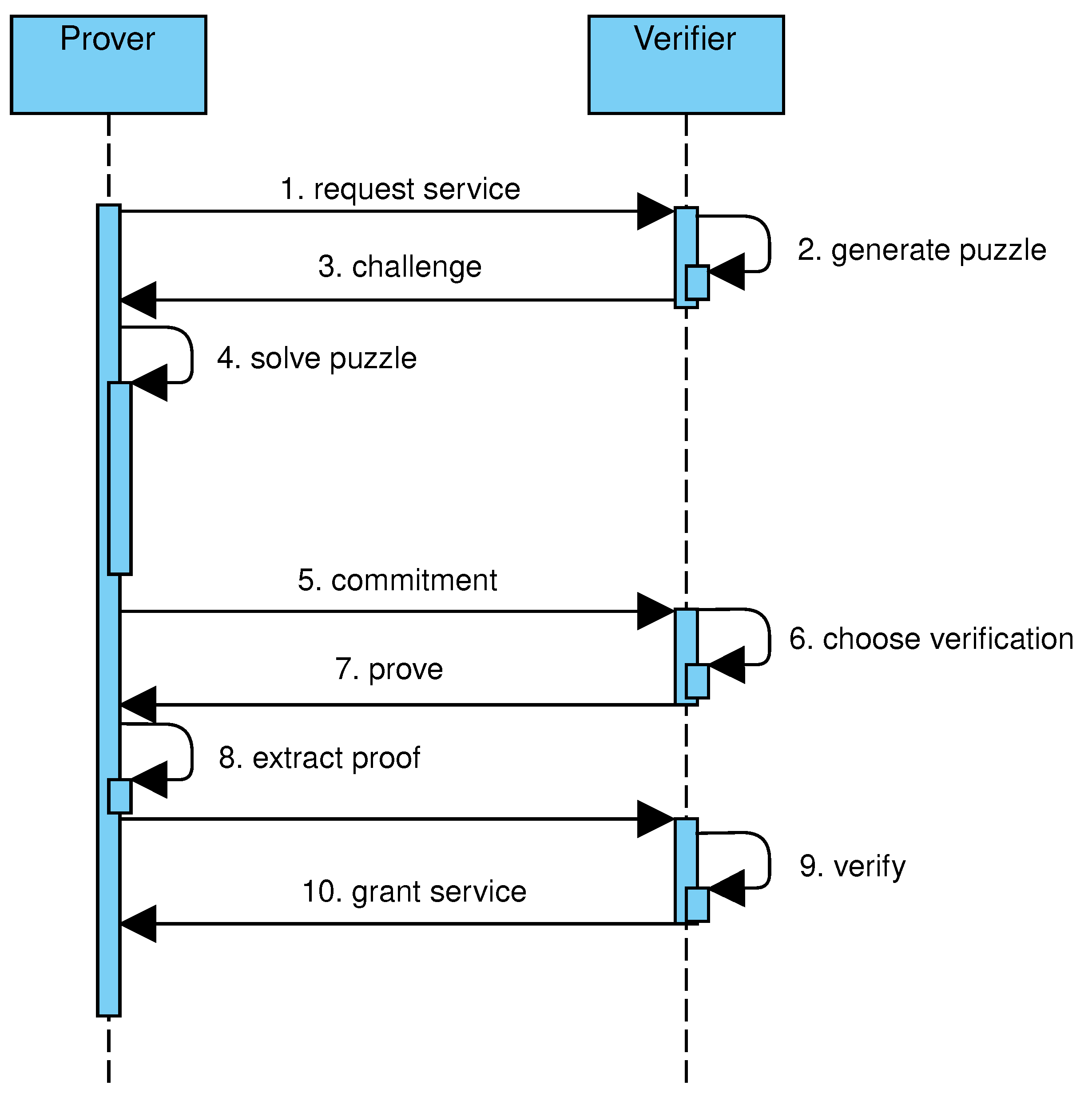
2.3. Client Puzzle Protocols
- At the beginning, the verifier V generates and retains a master key denoted as .
- To initiate the process, the prover P must transmit a request to V. To accomplish this, P sends to V.
- Based on its current workload, V determines the difficulty parameter , generates a timestamp t indicating the deadline for completing the protocol, calculates , and transmits to P.
- P computes and generates the hashcash tree T of size n for s using Algorithm 3 and subsequently transmits to V. Here, is .
- V verifies that ; ensures that t represents a future timestamp; randomly chooses a number i within the range (referring to a leaf node); and sends to P, where .
- P sends to V, where S comprises the labels associated with nodes along the path from i to the root as well as their child nodes; in formulas, S represents the sequence containing for , , and . (As an optimization, integer witnesses for labels that are not on the path from i to the root can be excluded).
- V checks all the following conditions: ; t is in the future; , where is in S (i.e., the hash value linked to the root of the partial hashcash tree transmitted by P); S is valid; . If all criteria are satisfied, the request is handled.
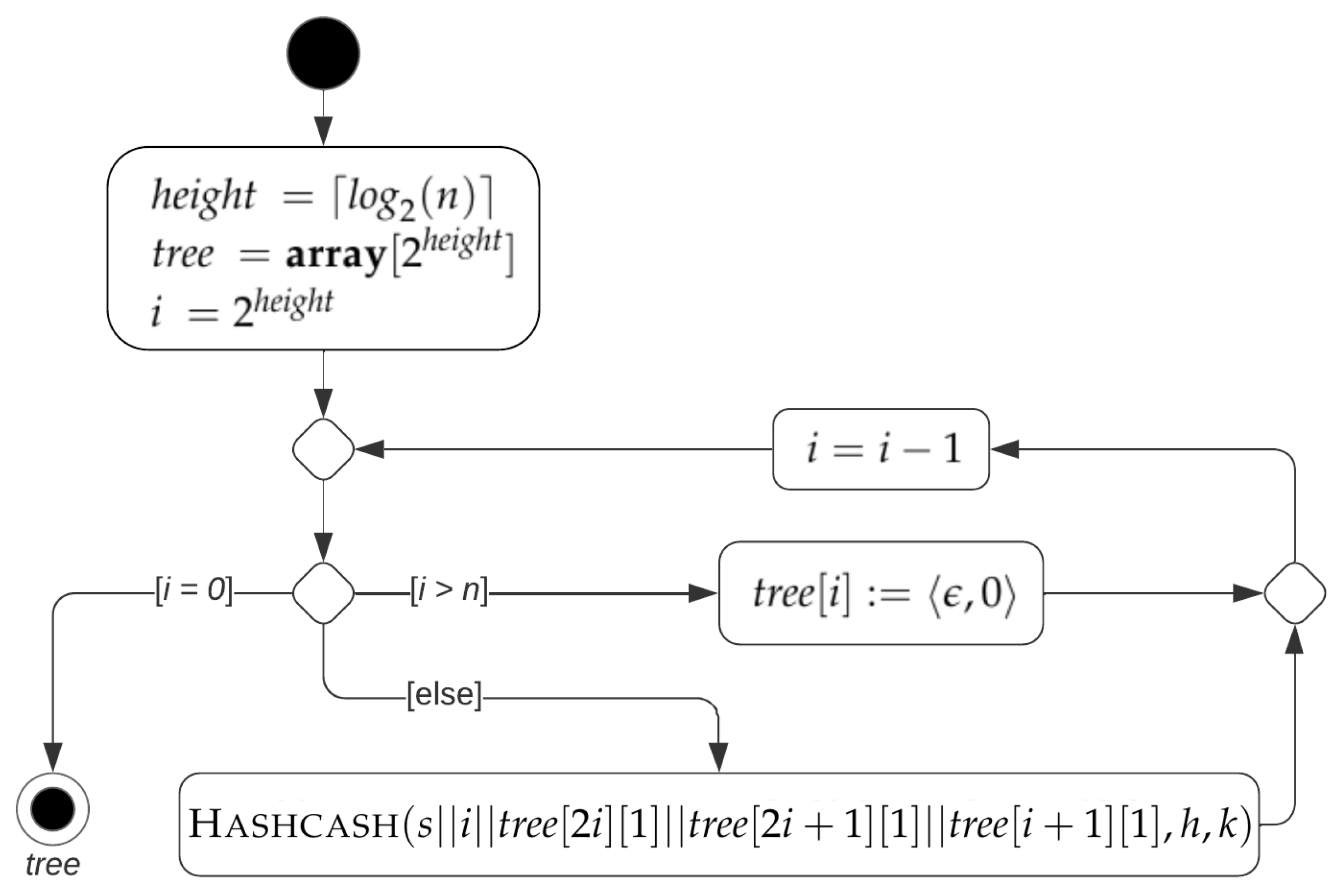
| Algorithm 3: HashcashTree(s, n, h, k) |
 |
| Algorithm 4: HashcashTreeVerify(T, i, s, n, h, k) |
 |
3. Hashcash Tree with Improved Parallel Resistance
- 7’
- Hashcash;
- 5’
- ;
- 5”
- if not HashcashVerify
- 8” if
- 4’
- P computes and generates the hashcash tree T of size n for s using the modified version of Algorithm 3 shown in Figure 2; subsequently, it transmits to V. Here, is .
- 6’
- P sends to V, where S comprises the labels associated with nodes along the path from i to the root as well as their child nodes and subsequent nodes in BFS; in formulas, S represents the sequence containing and, for , , , and . (As an optimization, integer witnesses for labels that are not on the path from i to the root can be excluded).
- 7’
- V checks all the following conditions: ; t is in the future; , where is in S (i.e., the hash value linked to the root of the partial hashcash tree transmitted by P); S is valid; . Here, the validation of S involves verifying that each label along the path from i to the root is computed according to (3); the modified version of Algorithm 4 shown in Figure 3 is used for this purpose. If all criteria are satisfied, the request is handled.
- The probability that HashcashTree terminates after computing hash values isfor all . On average, the number of unused hash values computed by Algorithm 3 (via Algorithm 1) is , with variance .
- HashcashTreeVerify terminates after computing at most hash values.
4. Implementation and Experiment
- Q1
- Overhead of the New Data Structure: This question investigates the additional processing time or resource consumption introduced by the new data structure compared to the original version. We will measure the overhead by comparing the execution times of equivalent operations on both data structures for various input sizes and configurations.
- Q2
- Parallel Resistance Weakness: This question explores the vulnerability of the original hashcash tree to parallelized construction attempts. We will identify parameter settings (e.g., tree size and hash function choice) under which the effectiveness of the original data structure deteriorates when utilizing parallel processing for construction. This will involve running the parallel construction algorithm for the original data structure with various parameter combinations and analyzing the impact on execution time and security properties.
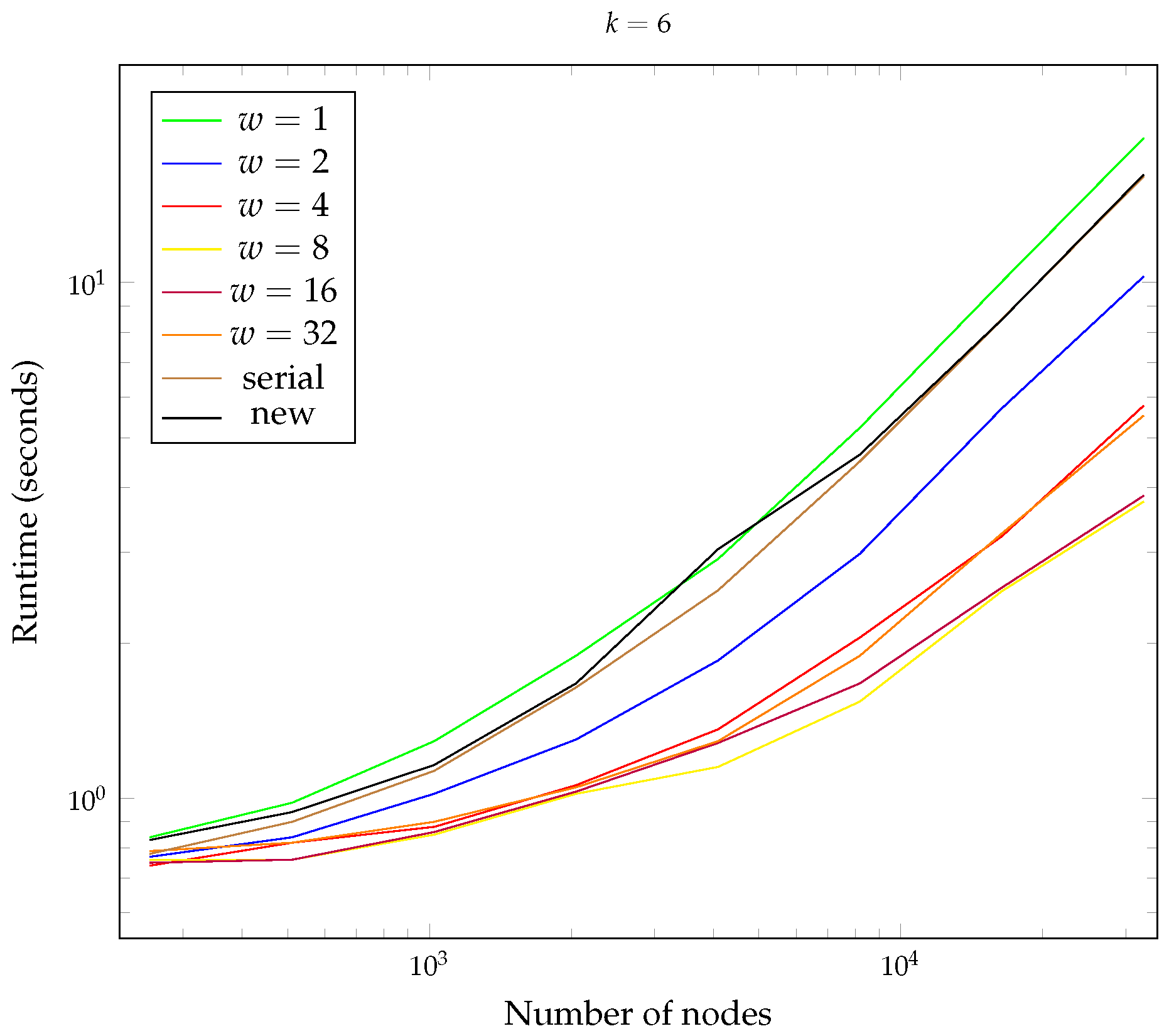
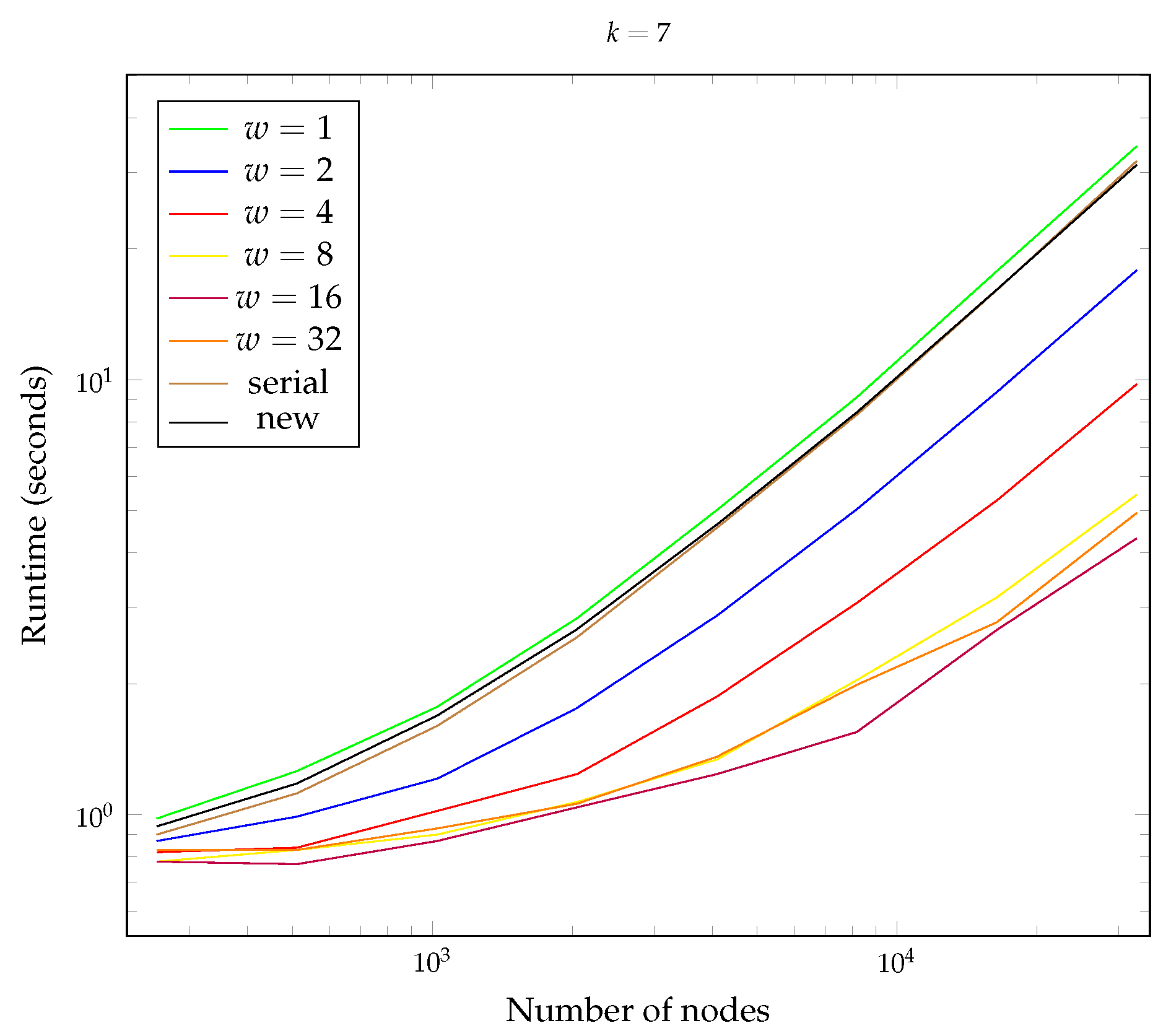
- Prefix Length (k): This parameter controls the difficulty of the proof-of-work mechanism within the hashcash tree. We varied the prefix length (denoted by k) to assess its impact on construction time.
- Number of Nodes: This parameter determines the size of the hashcash tree, directly influencing the number of hashing operations required during construction, and therefore providing a fine-grained control on the difficulty of the proof-of-work mechanism within the hashcash tree. We experimented with different tree sizes to understand the scalability of both data structures.
- Number of Parallel Workers (w): This parameter is specific to the parallel construction algorithm for the original hashcash tree. It controls the number of worker processes utilized for concurrent execution. By varying the number of workers (denoted by w), we aimed to identify potential weaknesses in the possibility to parallelize the construction of the original hashcash tree.
5. Related Work
- Unforgeability: it should be computationally infeasible for an attacker to forge a valid solution without actually solving the puzzle [19].
- Difficulty: solving a client puzzle should require a sufficient amount of computational effort to deter attackers from launching resource-intensive DoS attacks.
- Determinable Difficulty: ideally, the server should be able to determine the difficulty level of the puzzle beforehand [20].
- Parallel Computation Resistance: the puzzle’s difficulty should not significantly decrease when attackers attempt to solve it using parallel processing techniques [20].
- CPU-bound Client Puzzles: In this category, the effort required by the prover (typically a client) to solve the puzzle is measured by the number of CPU cycles needed. Several client puzzle schemes fall under this category, as presented in the works by Back et al. (2002) [11], Chen et al. (2009) [19], Dwork and Naor (1992) [9], Jakobsson and Juels (1999) [21], Juels and Brainard (1999) [17], Rivest et al. (1996) [18], Tritilanunt et al. (2007) [22], and Waters et al. (2004) [23].
- Memory-bound Client Puzzles: For memory-bound client puzzles, the solving effort is measured by the number of memory lookups required. The primary motivation behind memory-bound puzzles stems from the observation that CPU power can vary significantly across different computers, whereas memory access speeds tend to be more uniform. This is supported by works from Abadi et al. (2005) [24], Dean (2001) [25], and Doshi and Moore (2006) [26].
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mahjabin, T.; Xiao, Y.; Sun, G.; Jiang, W. A survey of distributed denial-of-service attack, prevention, and mitigation techniques. Int. J. Distrib. Sens. Netw. 2017, 13, 1550147717741463. [Google Scholar] [CrossRef]
- Bendovschi, A. Cyber-Attacks—Trends, Patterns and Security Countermeasures. Procedia Econ. Financ. 2015, 28, 24–31. [Google Scholar] [CrossRef]
- Biju, J.M.; Gopal, N.; Prakash, A.J. Cyber attacks and its different types. Int. Res. J. Eng. Technol. 2019, 6, 4849–4852. [Google Scholar]
- He, Z.; Zhang, T.; Lee, R.B. Machine Learning Based DDoS Attack Detection from Source Side in Cloud. In Proceedings of the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, 26–28 June 2017; pp. 114–120. [Google Scholar]
- Luong, T.K.; Tran, T.D.; Le, G.T. Ddos attack detection and defense in sdn based on machine learning. In Proceedings of the 2020 7th NAFOSTED Conference on Information and Computer Science (NICS), IEEE, Ho Chi Minh City, Vietnam, 26–27 November 2020; pp. 31–35. [Google Scholar]
- Jyoti, N.; Behal, S. A meta-evaluation of machine learning techniques for detection of DDoS attacks. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), IEEE, New Delhi, India, 17–19 March 2021; pp. 522–526. [Google Scholar]
- de Neira, A.B.; Kantarci, B.; Nogueira, M. Distributed denial of service attack prediction: Challenges, open issues and opportunities. Comput. Netw. 2023, 222, 109553. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Alkahtani, H. Cyber Security for Detecting Distributed Denial of Service Attacks in Agriculture 4.0: Deep Learning Model. Mathematics 2023, 11, 233. [Google Scholar] [CrossRef]
- Dwork, C.; Naor, M. Pricing via Processing or Combatting Junk Mail. In Proceedings of the Advances in Cryptology—CRYPTO ’92, 12th Annual International Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 1992; Lecture Notes in Computer Science. Brickell, E.F., Ed.; Springer: Berlin/Heidelberg, Germany, 1992; Volume 740, pp. 139–147. [Google Scholar] [CrossRef]
- Lachtar, N.; Elkhail, A.A.; Bacha, A.; Malik, H. A Cross-Stack Approach Towards Defending Against Cryptojacking. IEEE Comput. Archit. Lett. 2020, 19, 126–129. [Google Scholar] [CrossRef]
- Back, A.; Hashcash—Amortizable Publicly Auditable Cost-Functions. Technical Report. 2002. Available online: http://www.hashcash.org/papers/amortizable.pdf (accessed on 1 July 2024).
- Coelho, F. An (Almost) Constant-Effort Solution-Verification Proof-of-Work Protocol Based on Merkle Trees. In Proceedings of the Progress in Cryptology—AFRICACRYPT 2008, First International Conference on Cryptology in Africa, Casablanca, Morocco, 11–14 June 2008; Lecture Notes in Computer Science. Vaudenay, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5023, pp. 80–93. [Google Scholar] [CrossRef]
- Alviano, M. Hashcash Tree, a Data Structure to Mitigate Denial-of-Service Attacks. Algorithms 2023, 16, 462. [Google Scholar] [CrossRef]
- Chiriaco, V.; Franzen, A.; Thayil, R.; Zhang, X. Finding partial hash collisions by brute force parallel programming. In Proceedings of the 37th IEEE Sarnoff Symposium 2016, Newark, NJ, USA, 19–21 September 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Pettis, B.T. reCAPTCHA challenges and the production of the ideal web user. Convergence 2022, 29, 886–900. [Google Scholar] [CrossRef]
- Gaggi, O. A study on Accessibility of Google ReCAPTCHA Systems. In Proceedings of the OASIS ’22: Proceedings of the 2022 Workshop on Open Challenges in Online Social Networks, Barcelona, Spain, 28 June–1 July 2022. [Google Scholar]
- Juels, A.; Brainard, J.G. Client Puzzles: A Cryptographic Countermeasure Against Connection Depletion Attacks. In Proceedings of the Network and Distributed System Security Symposium, NDSS, San Diego, CA, USA, 4 February 1999; The Internet Society: Reston, VA, USA, 1999. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Wagner, D. Time-Lock Puzzles and Timed-Release Crypto; Technical Report MIT/LCS/TR-684; Institute of Technology: Cambridge, MA, USA, 1996. [Google Scholar]
- Chen, L.; Morrissey, P.; Smart, N.P.; Warinschi, B. Security Notions and Generic Constructions for Client Puzzles. In Proceedings of the Advances in Cryptology—ASIACRYPT 2009, 15th International Conference on the Theory and Application of Cryptology and Information Security, Tokyo, Japan, 6–10 December 2009; Lecture Notes in Computer Science. Matsui, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5912, pp. 505–523. [Google Scholar] [CrossRef]
- Tang, Q.; Jeckmans, A. Towards a security model for computational puzzle schemes. Int. J. Comput. Math. 2011, 88, 2246–2257. [Google Scholar] [CrossRef]
- Jakobsson, M.; Juels, A. Proofs of Work and Bread Pudding Protocols. In Proceedings of the Secure Information Networks: Communications and Multimedia Security, IFIP TC6/TC11 Joint Working Conference on Communications and Multimedia Security (CMS ’99), Leuven, Belgium, 20–21 September 1999; Preneel, B., Ed.; Kluwer: Alphen aan den Rijn, Netherlands, 1999; Volume 152, pp. 258–272. [Google Scholar]
- Tritilanunt, S.; Boyd, C.; Foo, E.; Nieto, J.M.G. Toward Non-parallelizable Client Puzzles. In Proceedings of the Cryptology and Network Security, 6th International Conference, CANS 2007, Singapore, 8–10 December 2007; Lecture Notes in Computer Science. Bao, F., Ling, S., Okamoto, T., Wang, H., Xing, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4856, pp. 247–264. [Google Scholar] [CrossRef]
- Waters, B.; Juels, A.; Halderman, J.A.; Felten, E.W. New client puzzle outsourcing techniques for DoS resistance. In Proceedings of the 11th ACM Conference on Computer and Communications Security, CCS 2004, Washington, DC, USA, 25–29 October 2004; Atluri, V., Pfitzmann, B., McDaniel, P.D., Eds.; Association for Computing Machinery: New York, NY, USA, 2004; pp. 246–256. [Google Scholar] [CrossRef]
- Abadi, M.; Burrows, M.; Manasse, M.S.; Wobber, T. Moderately hard, memory-bound functions. ACM Trans. Internet Technol. 2005, 5, 299–327. [Google Scholar] [CrossRef]
- Dean, D.; Stubblefield, A. Using Client Puzzles to Protect TLS. In Proceedings of the 10th USENIX Security Symposium, Washington, DC, USA, 13–17 August 2001; Wallach, D.S., Ed.; USENIX: Berkeley, CA, USA, 2001. [Google Scholar]
- Doshi, S.; Monrose, F.; Rubin, A.D. Efficient Memory Bound Puzzles Using Pattern Databases. In Proceedings of the Applied Cryptography and Network Security, 4th International Conference, ACNS 2006, Singapore, 6–9 June 2006; Lecture Notes in Computer Science. Zhou, J., Yung, M., Bao, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3989, pp. 98–113. [Google Scholar] [CrossRef]
- Back, A.; Merkle, R.C. Method of Providing Digital Signatures. U.S. Patent 4,309,569A, 1979. [Google Scholar]
- Baniata, H.; Kertesz, A. Partial Pre-Image Attack on Proof-of-Work based Blockchains. Blockchain Res. Appl. 2024, 2024, 100194. [Google Scholar] [CrossRef]
- Agarwal, S. A Novel Corona Graph Based Proof-of-Work Algorithm for Public Blockchains. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 450–455. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size | |||||
|---|---|---|---|---|---|
| Stress | 15 | 31 | 63 | 127 | 255 |
| 1 | 38% (8.54 s) | 38% (10.63 s) | 31% (14.47 s) | 25% (23.11 s) | 18% (39.38 s) |
| 2 | 39% (8.66 s) | 35% (10.68 s) | 30% (14.68 s) | 23% (22.77 s) | 17% (39.22 s) |
| 4 | 43% (8.48 s) | 38% (10.54 s) | 30% (14.58 s) | 23% (22.87 s) | 17% (38.61 s) |
| 8 | 38% (8.75 s) | 35% (10.61 s) | 29% (14.77 s) | 23% (22.44 s) | 16% (38.75 s) |
| 16 | 38% (8.58 s) | 34% (10.86 s) | 28% (14.88 s) | 21% (22.73 s) | 16% (39.09 s) |
| 32 | 35% (8.94 s) | 32% (11.55 s) | 27% (15.15 s) | 30% (24.10 s) | 11% (52.86 s) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alviano, M.; Gabriele, G. Improve Parallel Resistance of Hashcash Tree. Cryptography 2024, 8, 30. https://doi.org/10.3390/cryptography8030030
Alviano M, Gabriele G. Improve Parallel Resistance of Hashcash Tree. Cryptography. 2024; 8(3):30. https://doi.org/10.3390/cryptography8030030
Chicago/Turabian StyleAlviano, Mario, and Giada Gabriele. 2024. "Improve Parallel Resistance of Hashcash Tree" Cryptography 8, no. 3: 30. https://doi.org/10.3390/cryptography8030030
APA StyleAlviano, M., & Gabriele, G. (2024). Improve Parallel Resistance of Hashcash Tree. Cryptography, 8(3), 30. https://doi.org/10.3390/cryptography8030030