1. Introduction
According to the Perception-Action Model (PAM), suggested by Milner and Goodale [
1,
2], the visual system consists of two functionally separated streams, the dorsal stream and the ventral stream. The ventral stream provides vision for perception and the dorsal stream provides vision for action. The model was first formulated to account for deficits observed in patients suffering from ventral or dorsal stream damage. Visual form agnosic patient D.F., who suffered from ventral stream lesions, was found to still have functioning motor control, despite her severely impaired visual perception [
3,
4]. In contrast, optic ataxia patients suffering from dorsal lesions tend to show impaired motor control, while their visual perception remains largely normal. [
5].
The model contains an important assertion. The visual processes taking place in the two distinct streams use different representations and different processing modes [
6]. In principle, it is therefore possible to test this two-visual pathway hypothesis also in healthy participants. For example, finding that some processing error (or to put it more neutrally: processing feature) affects only perceptual tasks, but not visuomotor tasks, could be taken as an indication that the two tasks use different visual representations and that only one type of representation is affected by this error. In this context, the most extensively studied error is the susceptibility to perceptual illusions. Many studies have suggested that perceptual illusions affect perceptual but not visuomotor tasks (e.g., [
7,
8]). However, this evidence has been challenged in numerous studies, and counter-examples and alternative accounts have been provided (for reviews, see Carey [
9], Bruno [
10], Franz [
11], Franz and Gegenfurtner [
12], Bruno and Franz [
13], Schenk, et al. [
14], and Schenk [
15]). A recent large-scale, multicenter, preregistered study showed that for the Ebbinghaus illusion, one of the most commonly studied illusions, the illusion effects are pretty much identical for perception and action [
16,
17]. Illusions are, however, not the only tool employed to demonstrate the distinctness of representations in the perceptual and the visuomotor system. Ganel and Goodale [
18], for example, showed that the Garner-interference effect influences perceptual size-judgements but not the size of the grip apertures in a visuomotor task. Furthermore, Ganel, et al. [
19] also reported that a fundamental psychophysical law, Weber’s law, is selectively violated in grasping. Finally, Singhal et al. [
20] showed that a more general cognitive phenomenon, namely the finding that the concurrent execution of two tasks creates performance costs for at least one of the two tasks, reliably occurs in tasks that can be assigned to the perceptual system but is much less prominent in tasks assigned to the visuomotor system. However, all these approaches have been met with counter-evidence and are currently bogged down in controversy [
21,
22,
23,
24,
25,
26,
27,
28,
29].
In 2012, Ganel, Freud, Chajut, and Algom [
30] proposed another novel approach to test for the existence of distinct processing modes in perception and action. They presented participants with objects that differed in size by only 0.5 mm. Participants were first asked to indicate verbally which of the two objects was the bigger one, and subsequently had to grasp the object directly in front of them. It turned out that participants were at chance level with their verbal judgements. Yet, when their hand-openings during the grasping movements were analyzed, those hand-openings differed significantly for the smaller and bigger objects. Most interestingly, even when observers erroneously labelled the bigger object as the smaller one their hand-opening was still (on average) bigger than when they erroneously labelled the smaller object as being bigger. Thus, it seemed that observers’ hand-openings were not affected by their conscious size judgement. Their hands reliably adjusted to the true physical size of the objects, even when they could not perceptually discriminate between those objects. Based on these findings, Ganel and colleagues concluded that perceptual judgement and grasping are based on distinct representations of visual size and that the size representation for grasping is more precise than the one used for explicit perceptual judgements. Furthermore, these findings were interpreted as support for Milner and Goodale’s claim that vision for perception and vision for action are served by distinct neural pathways.
This conclusion relies, however, on the assumption that both tasks use visual size as their main input which has been challenged by Smeets and Brenner [
31]. They presented a model which could correctly account for most aspects of grasping movements, while assuming that the sensorimotor system does not compute object size but instead determines the optimal contact positions for the grasping digits (typically index finger and thumb) on the target object. They demonstrated that using this assumption, grip apertures still positively correlate with object size, despite this parameter never being explicitly computed. On the basis of this account, it would not be expected that visual requirements for perceptual size-discrimination and grasping are identical and thus, in the context of this model, it is hardly newsworthy that significant differences can be found when grasping objects whose sizes cannot be reliably discriminated.
While we accept the more general point, namely that grasping and size discrimination do not necessarily use the same sensory inputs and that grasping should not be treated as the motor equivalent of a size-judgement task (for a more detailed discussion of this point, see Hesse et al. [
32] and Schenk et al. [
24]), we do think that there is evidence to suggest that visual size information is commonly used for grasping in healthy participants (albeit possibly not, or to a lesser extent, by patients with agnosia [
33,
34]). For example, the above discussed finding that grasping and perceptual judgements are impacted very similarly by visual size illusions [
16] seems to indicate that object size is used also for grasping (for a slightly different view, see de Grave, et al. [
35]). Further evidence comes from studies on grasping familiar objects. For example, McIntosh and Lashley [
36] showed that the assumptions that we make about the size of familiar objects have a significant impact on how we grasp those objects. Taken together these findings suggest that size does play an important role in shaping our grasping response. Thus, if we accept that grasping relies on object size information, it is indeed surprising and noteworthy that in grasping we seem to be able to distinguish between object sizes that are perceptually identical. However, while we do not question the assumption that both grasping and perceptual judgement rely on object size information, we challenge the claim by Ganel, Freud, Chajut, and Algom [
30] that there is a dissociation in the accuracy of this information.
So, let us have a closer look at the evidence upon which the claim is based that the representation of size underlying grasping is superior to the representation underlying perceptual judgement. On average observers guessed the correct size of the object only in 58.7% of trials, i.e., barely above chance. In contrast, when the average maximum grip aperture (MGA) was analyzed a reliable and significant difference between the MGAs for the smaller and bigger object emerged. However, is this contrast enough to claim that the hand distinguishes between objects more reliably than the observer? To illustrate the problem with this claim, we can take the example of body height in Scottish and English men. The mean height of adult male Scots is 176 cm, and thus approximately 2 cm less than the mean height of English adult males. Thus, if we took a representative sample of Scottish and English males to compare their average height, we would expect to find that the average Scottish height is significantly below that of the English sample. Nevertheless, would we be asked to assign nationality on the basis of body height we would make frequent errors. The same analogy holds for comparing grasping and perceptual data. MGAs for smaller objects may well be significantly smaller than for bigger objects, but chances are there are many grasping responses directed to the bigger object producing smaller MGAs than those found for grasping responses directed to the smaller object. Thus, the following question arises: if we tried to guess the size of the target on the basis of the observed MGAs, would the number of correct guesses significantly exceed the number of correct guesses achieved by the observers in the perceptual judgement task? To address this question, we replicated the study by Ganel, Freud, Chajut, and Algom [
30] and re-analyzed the findings by obtaining measures for size-classification accuracy based on the MGAs of the participants grasping responses.
In total, we performed three experiments. In the first experiment, we aimed to replicate the first experiment from Ganel, Freud, Chajut, and Algom [
30]. Surprisingly, our findings differed from those obtained by Ganel, Freud, Chajut, and Algom [
30] already prior to the proposed re-analysis of the data. We therefore decided to replicate this experiment (Experiment 2) with a new sample of participants to check whether our original findings were reliable. The second experiment produced a new pattern of findings which (again prior to the proposed re-analysis) were more similar to the results obtained by Ganel and colleagues [
30]. In our final experiment (Experiment 3) we examined the role of hand-sight and asked participants to perform the tasks used in Experiments 1 and 2 once under closed-loop conditions (i.e., moving hand remained visible throughout the trial) and again under open-loop conditions (i.e., hand only visible at the start of the movement). In this last experiment we found for the closed loop condition a pattern more similar to Experiment 1.
4. Discussion
Ganel, Freud, Chajut, and Algom [
30] presented participants with two very similarly sized target objects. The diameter of the smaller object was just 0.5 mm less than that of the bigger object. When asked to tell whether a given object was the smaller or the bigger one, their performance was at chance level. However, when asked to grasp one of the two objects, the average grip aperture for the smaller object was significantly smaller than that found for the bigger object. It was concluded that the visual information available for motor performance is more precise than that available to conscious perception – which has been presented as a further piece of evidence in favor of the hypothesis that vision for action and perception are based on distinct visual representations and are served by different anatomical systems [
1,
2]. In a series of three experiments, we aimed to replicate and extend the results presented by Ganel, Freud, Chajut, and Algom [
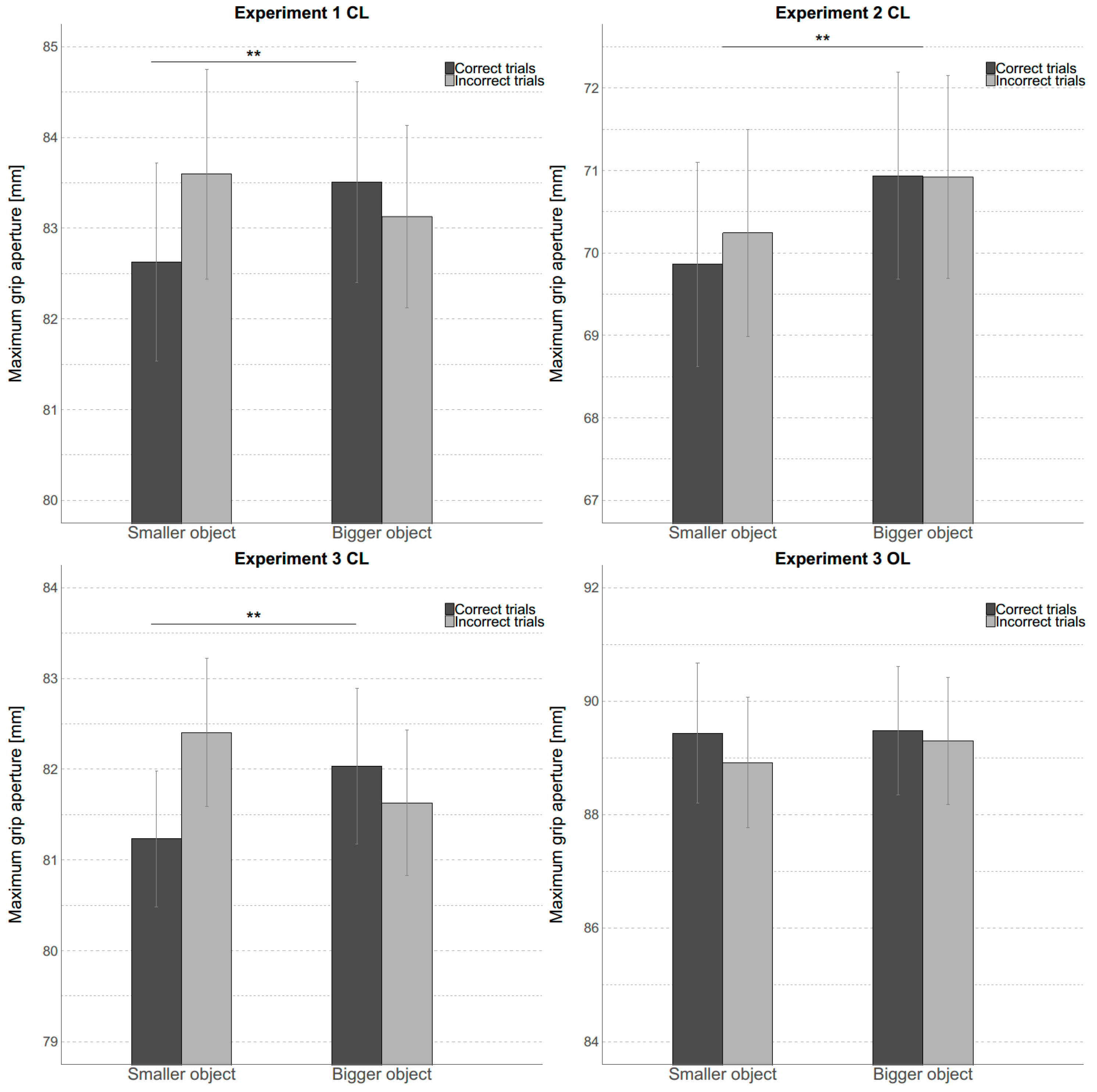
30]. We aimed to answer two questions. Firstly, can we replicate the original results, i.e., the finding that participants’ grasping movements distinguish between object sizes that participants are unable to discriminate verbally. The second, more important, question was, however, whether such a difference really implies that the visual information available to the visuomotor system is more precise than the information available to the perceptual system. Such a claim would lead us to expect that the classification of objects into smaller and bigger objects can be done more reliably on the basis of measures derived from motor performance than from verbal performance.
Let us look at the first question of whether we can replicate the main finding from the Ganel, Freud, Chajut, and Algom [
30] study. The answer is no, not consistently. Ganel, Freud, Chajut, and Algom [
30] found that MGA was determined by the actual size of the object irrespective of whether participants identified the size of the object correctly or not. In contrast, we found that in two out of three experiments, participants’ beliefs about the object’s size influenced their MGAs. What about the second claim that the precision of the size-information reflected in the grasping performance is superior to the size-information used for the perceptual report? We found consistently (in all three experiments) the opposite pattern. When using classification accuracy, we found that motor-based classification is worse than classification based on participants’ verbal reports. Taken together, the findings from our three experiments suggest that visual information used for grasping is not better than information available to the perceptual system. While Ganel, Freud, Chajut, and Algom [
30] used their findings to support the PAM our analysis suggests that their results do not actually demonstrate the superiority of visuomotor classification as compared to perceptual classification.
In this context it is interesting to note that in the second experiment, where our data followed the same pattern as observed by Ganel and colleagues, the re-analysis of the data using the motor-classification approach nevertheless showed that classification based on perception is better than classification based on action. This demonstrates the potential of the motor-classification approach to allow a direct comparison of information used in motor tasks and non-motor tasks. It also means that our study coming to a different conclusion than Ganel and colleague’s is primarily due to our use of a different type of analysis and does not just present a failure to replicate.
In the following we will explore the implications of our findings and discuss some open questions and limitations of our study.
4.1. The Role of Knowledge in Visuomotor Performance
The role of knowledge in visuomotor performance is a contentious issue. According to the division of labor within the visual system as suggested by Milner, Goodale, and colleagues [
1,
2], vision in the ventral system is used to identify objects. Object identification allows the cognitive system to retrieve stored information about an object. The dorsal system, in charge of using vision for guiding actions, does not have direct access to such memorized information. Consequently, visuomotor responses are expected to remain unaffected by our knowledge about objects. This prediction was tested by McIntosh and Lashley [
36] and found to be wrong. When participants were presented with objects whose actual size did not correspond to their familiar and expected size, they made errors in their grasping responses. This demonstrates that participants’ knowledge determines, at least in part, their visuomotor response. Similar findings were obtained by others [
41,
42,
43,
44]. Ganel, Freud, Chajut, and Algom’s [
30] study addressed a similar question in a somewhat different way. Presenting target objects that appeared to the observer to be near-identical led to numerous instances where the observer’s judgement about the object’s size and its true size were at odds. This provided an opportunity to test whether it is the perceived size or the actual size of the object that drives the grasping response. Ganel, Freud, Chajut, and Algom [
30] argued that the perceived size was irrelevant and only the actual size affected the grip aperture. However, our findings are in conflict with this conclusion. Two out of three experiments demonstrated a significant influence of the perceived size on grasping. On the basis of our findings, we conclude that beliefs or knowledge about objects affect object-oriented actions, a finding that undermines the hypothesis that the visual processes in the ventral and dorsal systems are independent of each other.
4.2. Classification Versus Comparing Means
Our results show that the type of analysis used will determine what conclusions are drawn from the data. Ganel, Freud, Chajut, and Algom [
30] focused on the significant MGA difference between trials with small versus big objects and concluded that the grasping hand can distinguish more reliably between small and big objects than the perceptual system of the observer. More importantly, however, they did not test how good classification performance would actually be, were they to use MGAs to guess whether the target was the big or the small object. Here, we computed this classification performance and found that classification based on the grip aperture size is less reliable than classification based on observers’ verbal reports.
It is easy to be fooled into the belief that finding a significant difference indicates above chance discrimination performance. This potential fallacy is not restricted to the field of motor control. Franz and von Luxburg [
45] recently demonstrated that the same problem also occurs in a very different cognitive domain. They re-examined data from a study on lie-detection [
46]. ten Brinke, Stimson, and Carney [
46] asked volunteers to judge whether people on videos were lying or telling the truth (i.e., dichotomous measure). It turned out that most observers were poor at that task and their guesses were hardly better than chance. However, the researchers speculated that observers’
implicit ability to distinguish between liars and truth-tellers might be superior. They tested this idea in a priming experiment. Static images of liars and non-liars were presented shortly before words relating to lying or truthfulness were flashed onto the screen. Observers had to classify those words and it was found that response times (i.e., continuous measure) were faster whenever the meaning of the word and the truthfulness of the presented face were congruent, i.e., observers were quicker to classify a word related to lying when this word was preceded by a face belonging to a liar than when it was preceded by a face belonging to an honest person. Franz and von Luxburg [
45] took the response times and applied various classification procedures. They found that the accuracy of the classification based on the response times in the priming task was no better than the classification accuracy based on observers’ verbal responses. This example and our own findings in this study illustrate why we should be wary of any dissociation that contrasts a significant mean difference of a continuous measure in one task with a non-significant classification ability in a different task.
4.3. Is Size-Information for Motor Control Inferior to Size-Information in the Perceptual System?
We did not just find that size-classification based on motor performance is not better than perceptual size-classification. In fact, we found that motor-based size-classification is worse. One might argue that this also implies the existence of distinct representations of visual size in dorsal and ventral pathways. Thus, proponents of the perception-action model might be tempted to conclude that, while our findings may prompt some minor adjustments to the model, this finding still provides support for the PAM’s core claim of distinct visual representations for perception and action. However, this conclusion assumes that the trial-by-trial distribution of grip aperture values is entirely driven and shaped by the trial-by-trial distribution of the represented sizes in the visual system. This assumption is, however, implausible. The value of the grip aperture in any given trial is likely to be the result of many factors: the estimated size of the object, the current noise in the motor system, and the intended approach angle to name just a few possible factors that can influence the maximum grip aperture. As we have argued elsewhere [
23,
24,
32], it is in our view a mistake to treat the MGA as a perfect read-out of the motor system’s estimate of the target object’s size. Other constraints and sources of noise will contaminate this measure. Given these considerations, it should perhaps not surprise that classification based on grasping is worse than classification based on verbal report. In addition, it is important to point out that we also found a direct influence of perceptual judgement on grip aperture in two of our experiments. This finding suggests that the visual information used in perception is also used in action.
4.4. Manual Estimation
Someone familiar with the original study by Ganel, Freud, Chajut, and Algom [
30] might wonder why we did not use a so-called manual-estimation (ME) condition in our study and whether this limits or compromises the conclusions we can draw from our findings in any way. In the ME condition of the original study participants were asked to indicate the size of the target object using their index finger and thumb. Their results for the manual-estimation condition followed the findings for the perceptual (verbal report) task. However, there are several reasons why we think the absence of a manual estimation condition is not a critical issue for our study and does not affect its main conclusions.
Firstly, it should be noted that Ganel and colleagues primarily based their conclusions on the findings from their verbal report and not on those from the ME condition. For example, when they emphasize that the hand seems to distinguish between objects that are perceptually indiscriminable, they refer to a perceptual threshold based on observers’ verbal report. Furthermore, the key statistical finding reported and used in support of the PAM is the significant difference in hand-opening between the two differently sized objects that is found irrespective of the observers’ verbal judgements. In contrast, the findings from the ME condition are only compared in a qualitative manner to those obtained in the grasping condition. It is remarked that while ME mirrors observers’ verbal assessments, the same is not true for the grasping condition. However, no statistical comparison between the ME condition and the grasping condition is reported, and thus we do not know whether this difference is reliable (for a more detailed discussion of this problem, see [
47]).
Secondly, the absence of the ME condition does not affect our main argument, which is that comparisons between continuous and dichotomous performance measures can be highly misleading. We demonstrated that even if statistical tests suggest that the task with the continuous measure is more sensitive than the task with the dichotomous measure, a comparison of the two tasks based on a mapping of both measures onto a dichotomous level can negate, or even contradict, this conclusion. Given that such comparisons are frequently used in the discussion of the PAM, our conclusions remain valid and relevant to this specific scientific debate regardless of whether or not a ME condition is included.
Thirdly, a little thought experiment illustrates that the addition of a ME condition would not substantially affect the implications of our study. We demonstrated that grasping when probed for its ability to discriminate between the small and the big object does no better job than observers’ verbal report. Now, let us assume we added a ME condition and analyzed it the same way as the grasping condition. Two outcomes are possible: It turns out that discrimination is not worse or potentially even better for ME than for grasping. In this case the findings from ME provide further support for our conclusion that accuracy of vision for perception is not worse than accuracy of vision for action. Alternatively, we might find that ME is in fact worse than grasping (as would be hypothesized by the proponents of the PAM). In this case, we would have conflicting results. One measure for perception shows accuracy that is superior to grasping, while the other perceptual measure suggests that accuracy is inferior to grasping. What would we learn from this result? Most likely, we would conclude that grasping is not in general better than perception (but that it depends on the exact perceptual measure used) and that thus one could not use the findings to support the PAM (for examples of such data constellations, see [
48]).
Thus, if someone intended to derive PAM-supporting evidence from such a data-pattern, they would have to resort to the assumption that ME is a truer measure of perception than verbal reports. We think such an assumption is not necessarily justified. As we have argued before [
24,
33], ME is not an unproblematic task. Its direct comparison with grasping is made difficult by confounds. In grasping, participants can use direct visual and haptic feedback to improve their performance over time. The same is not true for ME where they receive either no, or only indirect or delayed visual and haptic feedback. As we have reported elsewhere [
49], feedback where the endpoint of the action cannot be directly related to the target positions is not very useful.
To conclude, our study refutes the claim by Ganel, Freud, Chajut, and Algom [
30] that the visuomotor system can discriminate between object sizes more reliably than the perceptual system. In fact, our results suggest that the opposite is true. Moreover, we found that the perceptual judgement has a direct effect on the grasping performance. Taken together, our findings further undermine the claim of distinct representations of visual size for perception and action.


{kind=link}
{kind=link}
{kind=link}


