Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination

 ,
,  , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Prompt Engineering
2.2. Quality Metrics
2.3. Secondary Outcomes
2.4. Statistical Analysis
3. Results
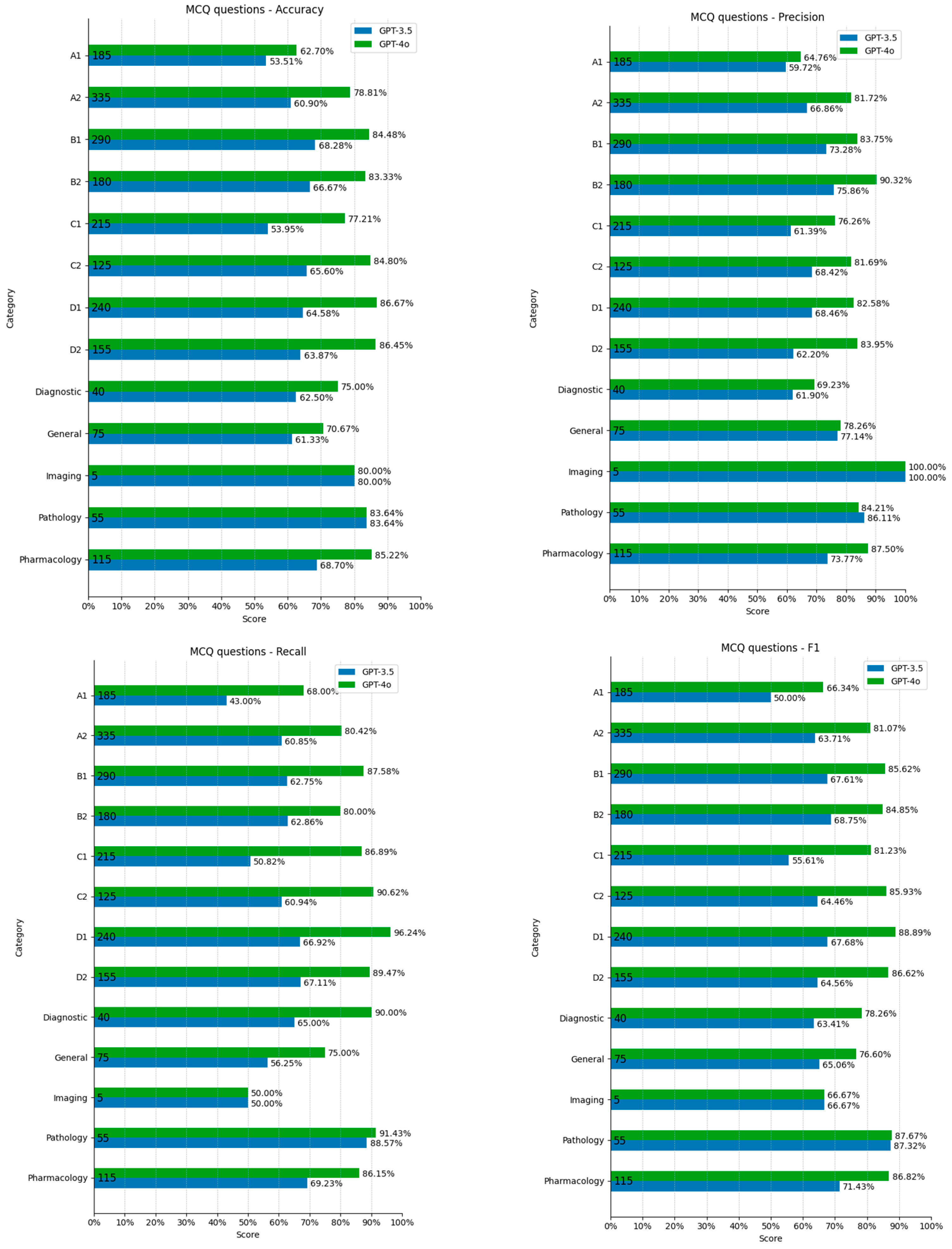
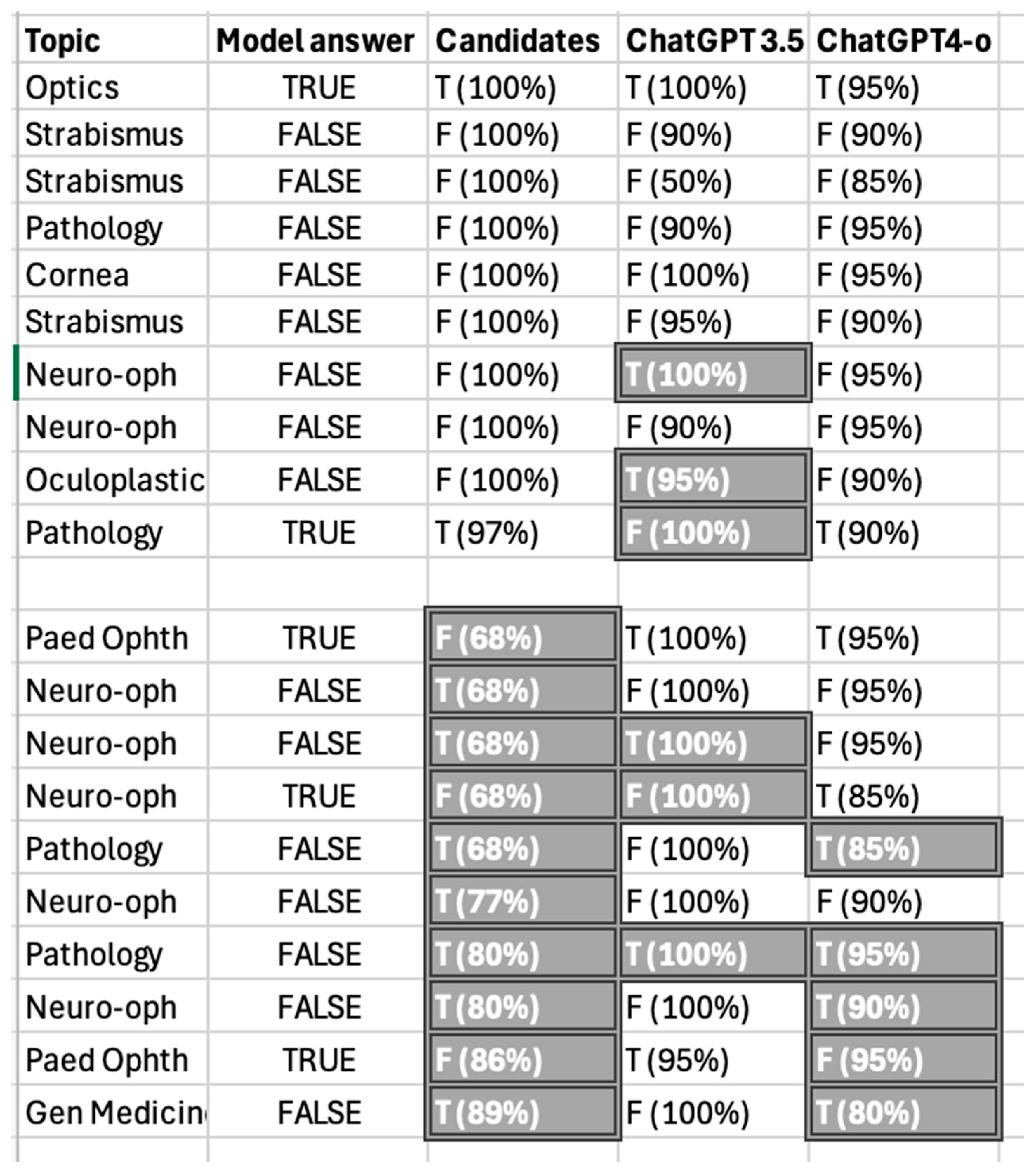
3.1. Multiple Choice Questions (MCQs)
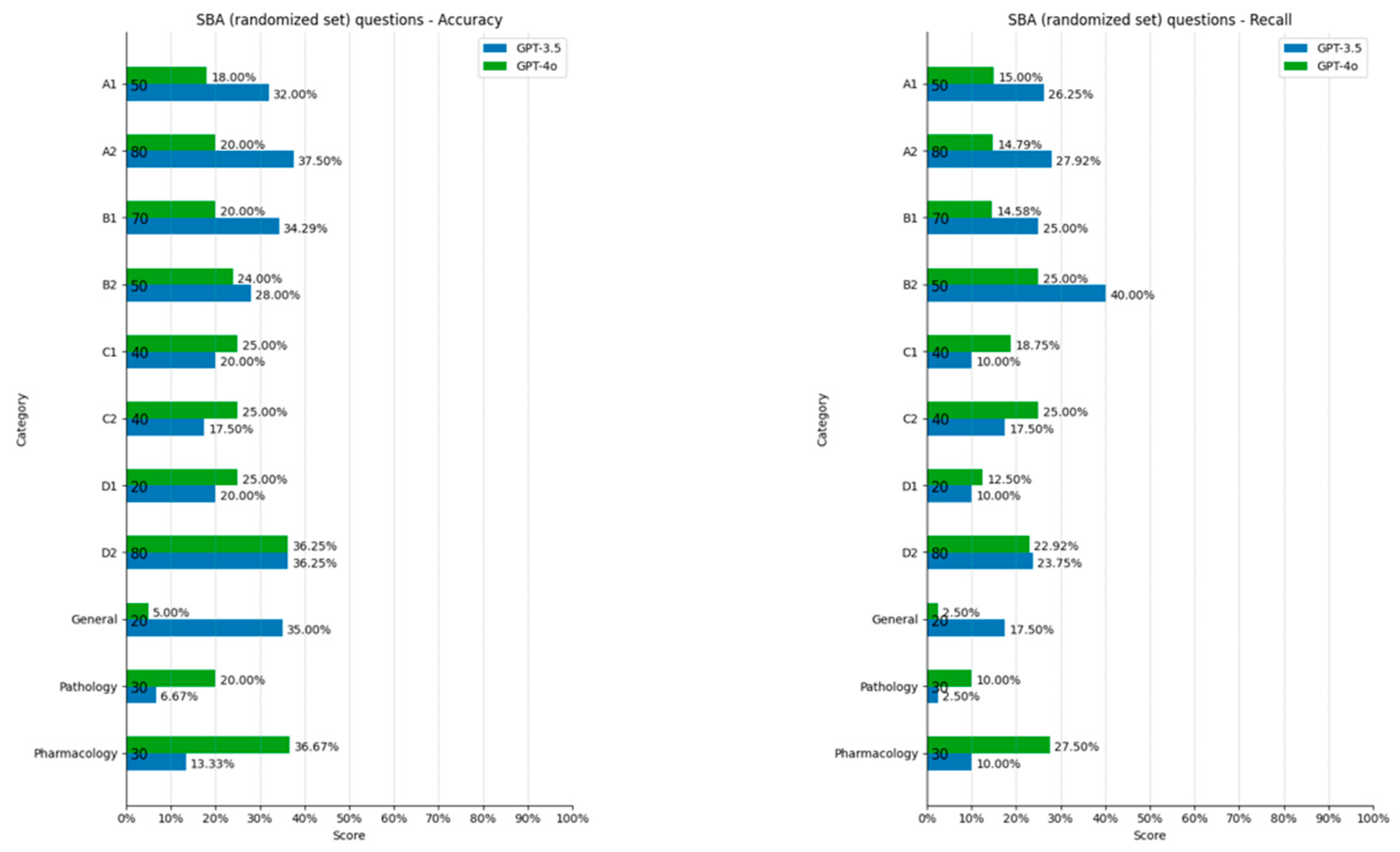
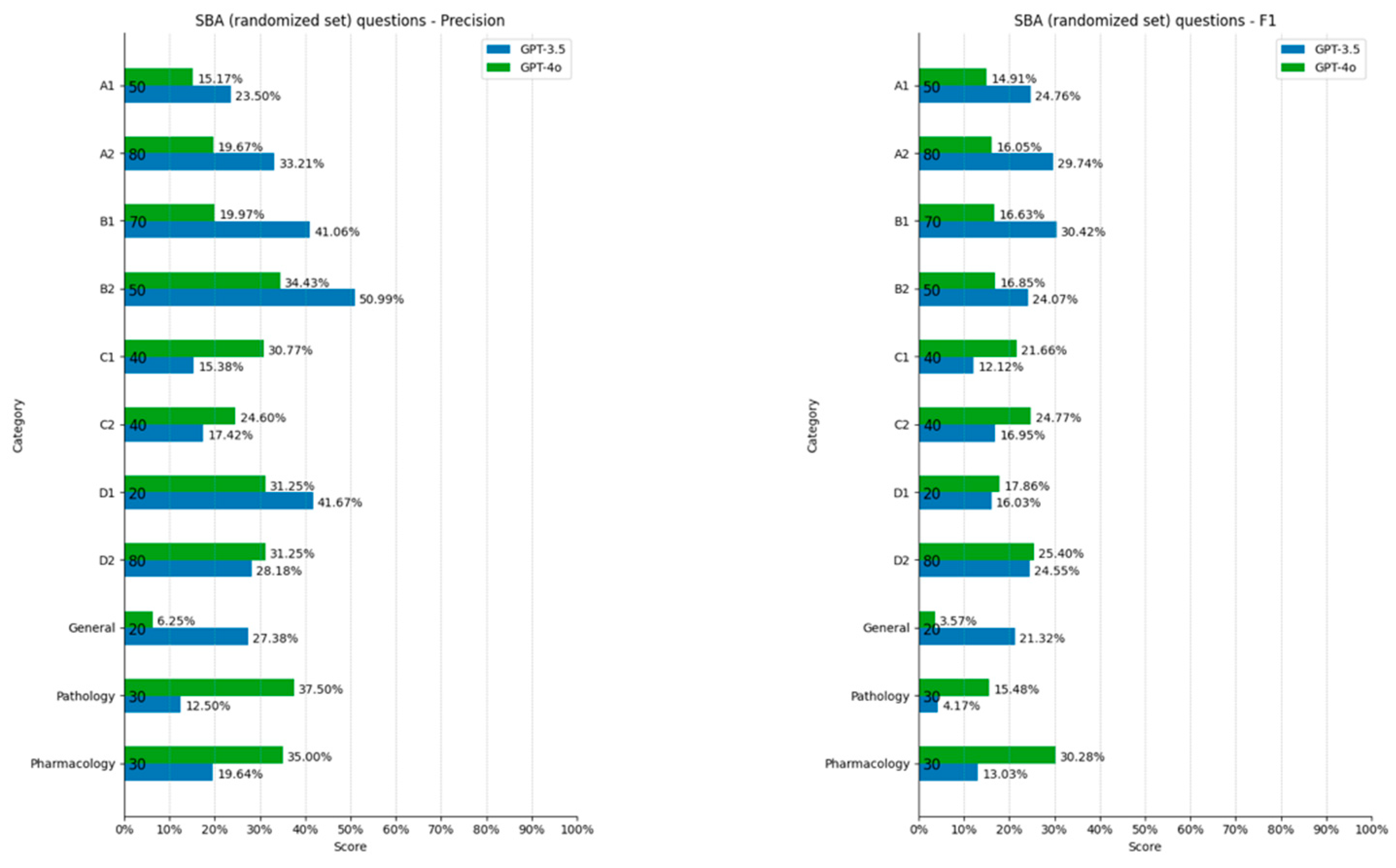
3.2. Single Best Answers (SBAs)
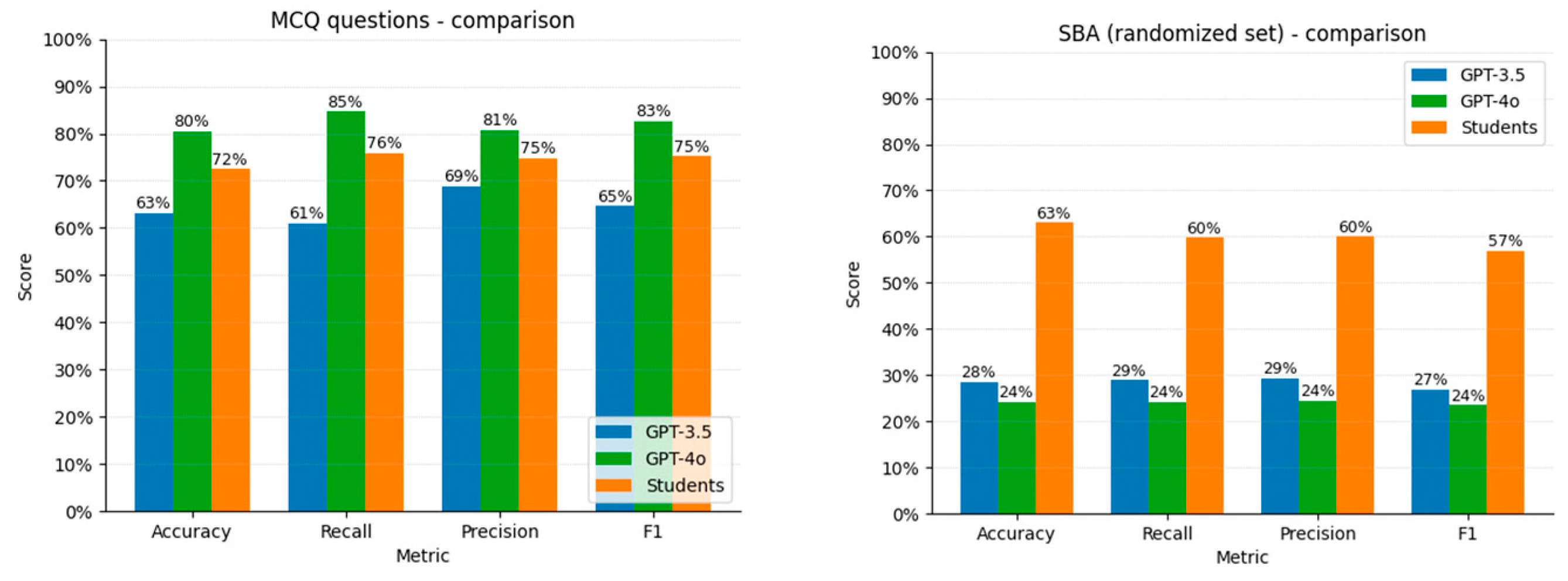
3.3. Comparison with Candidates’ Performance
4. Discussion
4.1. MCQ Performance
4.2. Performance Across MCQ Categories
4.3. SBA Performance
4.4. Performance Across SBA Categories
4.5. Comparison with Previous Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EBO | European Board of Ophthalmology |
| MCQ | Multiple choice question |
| SBA | Single best answer |
References
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Turing, A.M. On Computable Numbers, with an Application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Han, E.R.; Yeo, S.; Kim, M.J.; Lee, Y.H.; Park, K.H.; Roh, H. Medical education trends for future physicians in the era of advanced technology and artificial intelligence: An integrative review. BMC Med. Educ. 2019, 19, 460. [Google Scholar] [CrossRef]
- Kimmerle, J.; Timm, J.; Festl-Wietek, T.; Cress, U.; Herrmann-Werner, A. Medical Students’ Attitudes Toward AI in Medicine and Their Expectations for Medical Education. J. Med. Educ. Curric. Dev. 2023, 10, 1–3. [Google Scholar] [CrossRef]
- Mir, M.M.; Mir, G.M.; Raina, N.T.; Mir, S.M.; Mir, S.M.; Miskeen, E.; Alharthi, M.H.; Alamri, M.M.S. Application of Artificial Intelligence in Medical Education: Current Scenario and Future Perspectives. J. Adv. Med. Educ. Prof. 2023, 11, 133–140. [Google Scholar] [CrossRef]
- Mihalache, A.; Popovic, M.M.; Muni, R.H. Performance of an Artificial Intelligence Chatbot in Ophthalmic Knowledge Assessment. JAMA Ophthalmol. 2023, 141, 589–597. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Lin, J.C.; Younessi, D.N.; Kurapati, S.S.; Tang, O.Y.; Scott, I.U. Comparison of GPT-3.5, GPT-4, and human user performance on a practice ophthalmology written examination. Eye 2023, 37, 3694–3695. [Google Scholar] [CrossRef]
- Panthier, C.; Gatinel, D. Success of ChatGPT, an AI language model, in taking the French language version of the European Board of Ophthalmology examination: A novel approach to medical knowledge assessment. J. Fr. Ophtalmol. 2023, 46, 706–711. [Google Scholar] [CrossRef] [PubMed]
- Fowler, T.; Pullen, S.; Birkett, L. Performance of ChatGPT and Bard on the official part 1 FRCOphth practice questions. Br. J. Ophthalmol. 2024, 108, 1379–1383. [Google Scholar] [CrossRef] [PubMed]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination (USMLE)? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef] [PubMed]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Gurnani, B.; Kaur, K. Leveraging ChatGPT for ophthalmic education: A critical appraisal. Eur. J. Ophthalmol. 2023, 34, 323–327. [Google Scholar] [CrossRef]
- Hurst, A.; Lerer, A.; Goucher, A.P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.J.; Welihinda, A.; Hayes, A.; Radford, A.; et al. Gpt-4o system card. arXiv 2024, arXiv:2410.21276. [Google Scholar]
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms; Cambridge University Press: Cambridge, UK, 2011; pp. 100–106. [Google Scholar]
- Stapor, K.; Ksieniewicz, P.; García, S.; Woźniak, M. How to design the fair experimental classifier evaluation. Appl. Soft Comput. 2021, 104, 107219. [Google Scholar] [CrossRef]
- Taloni, A.; Borselli, M.; Scarsi, V.; Rossi, C.; Coco, G.; Scorcia, V.; Giannaccare, G. Comparative performance of humans versus GPT-4.0 and GPT-3.5 in the self-assessment program of American Academy of Ophthalmology. Sci. Rep. 2023, 13, 18562. [Google Scholar] [CrossRef]
- Craig, L. GPT 4.o vs. GPT-4: How Do They Compare? Available online: https://techtarget.com/searchenterpriseai/feature/GPT-4o-vs-GPT-4-How-do-they-compare (accessed on 3 February 2025).
- Moshirfar, M.; Altaf, A.W.; Stoakes, I.M.; Tuttle, J.J.; Hoopes, P.C. Artificial Intelligence in Ophthalmology: A Comparative Analysis of GPT-3.5, GPT-4, and Human Expertise in Answering StatPearls Questions. Cureus 2023, 5, e40822. [Google Scholar] [CrossRef]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef]
- Ting, D.S.W.; Cheung, C.Y.L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; Yeo, I.Y.S.; Lee, S.Y.; et al. Development and validation of a deep learning system for diabetic retinopathy and related eye diseases using retinal images from multiethnic populations with diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef] [PubMed]
- Thirunavukarasu, A.J. ChatGPT Cannot Pass FRCOphth Examinations: Implications for Ophthalmology and Large Language Model Artificial Intelligence. EyeNews 2023, 30, 1–3. Available online: https://www.eyenews.uk.com/media/31505/eye-am23-onex-arun-proof-2.pdf (accessed on 17 November 2023).
- Sychev, O. Open-answer question with regular expression templates and string completion hinting. Softw. Impacts 2023, 17, 100539. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maino, A.P.; Klikowski, J.; Strong, B.; Ghaffari, W.; Woźniak, M.; Bourcier, T.; Grzybowski, A. Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination. Vision 2025, 9, 31. https://doi.org/10.3390/vision9020031
Maino AP, Klikowski J, Strong B, Ghaffari W, Woźniak M, Bourcier T, Grzybowski A. Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination. Vision. 2025; 9(2):31. https://doi.org/10.3390/vision9020031
Chicago/Turabian StyleMaino, Anna P., Jakub Klikowski, Brendan Strong, Wahid Ghaffari, Michał Woźniak, Tristan Bourcier, and Andrzej Grzybowski. 2025. "Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination" Vision 9, no. 2: 31. https://doi.org/10.3390/vision9020031
APA StyleMaino, A. P., Klikowski, J., Strong, B., Ghaffari, W., Woźniak, M., Bourcier, T., & Grzybowski, A. (2025). Artificial Intelligence vs. Human Cognition: A Comparative Analysis of ChatGPT and Candidates Sitting the European Board of Ophthalmology Diploma Examination. Vision, 9(2), 31. https://doi.org/10.3390/vision9020031