
The Design and Construction of a Grid Skyline for Custom-Built PC Recommendations Based on a Multi-Attribute Model

Abstract
:1. Introduction
2. Related Work
2.1. Skyline Query
2.2. GridPPPS
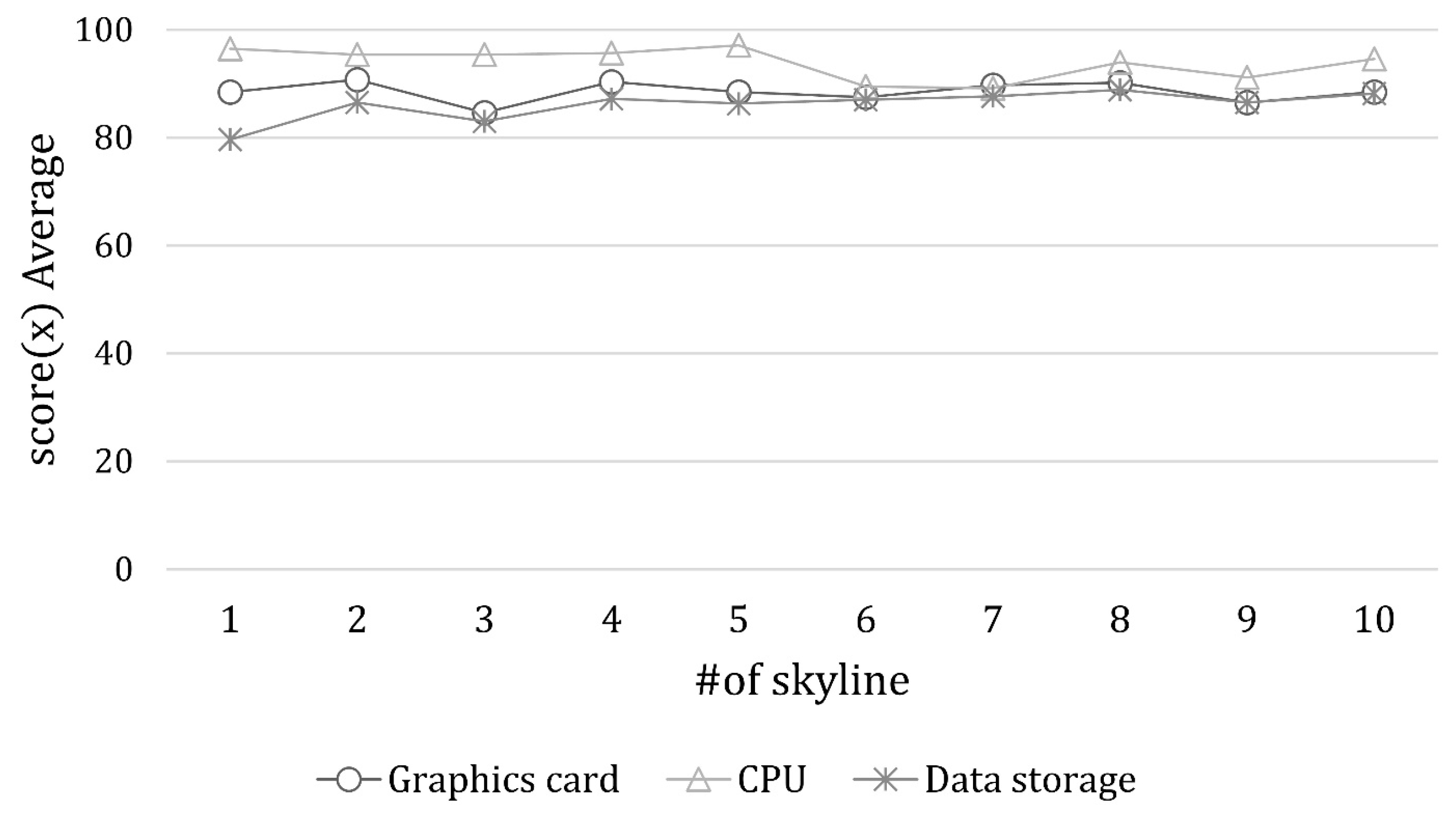
3. Experiments
4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Korean Statistical Information Service. Available online: https://kosis.kr (accessed on 25 August 2023).
- IDC (International Data Corporation). Available online: https://www.idc.com/ (accessed on 25 August 2023).
- Bao, W.W.; Jang, S.M.; Yoo, J.S. An Efficient Method for Processing Top-n Skyline Queries. J. KIISE 2011, 38, 126–131. [Google Scholar]
- Soundararajan, R.; Kumar, S.R.; Gayathri, N.; Al-Turjman, F. Skyline query optimization for preferable product selection and recommendation system. Wirel. Pers. Commun. 2021, 117, 3091–3108. [Google Scholar] [CrossRef]
- Chowdhury, N.; Arefin, M.S. Skyline Path Queries for Location-based Services. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 436–444. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, J.W. An Improved Skyline Query Scheme for Recommending Real-Time User Preference Data Based on Big Data Preprocessing. J. Inf. Process. Syst. 2022, 11, 189–196. [Google Scholar]
- Cui, B.; Lu, H.; Xu, Q.; Chen, L.; Dai, Y.; Zhou, Y. Parallel distributed processing of constrained skyline queries by filtering. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 546–555. [Google Scholar]
- Wu, P.; Zhang, C.; Feng, Y.; Zhao, B.Y.; Agrawal, D.; El Abbadi, A. Parallelizing skyline queries for scalable distribution. In Advances in Database Technology-EDBT 2006: 10th International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 112–130. [Google Scholar]
- Ihm, S.Y.; Park, Y.H. A Study on Construction and Processing Techniques of a Grid Skyline for Processing Top-k Queries. Database Res. 2013, 29, 85–93. [Google Scholar]
- Choi, W.; Liu, L.; Yu, B. Multi-criteria decision making with skyline computation. In Proceedings of the 2012 IEEE 13th International Conference on Information Reuse & Integration (IRI), Las Vegas, NV, USA, 8–10 August 2012; pp. 316–323. [Google Scholar]
- Georgiadis, N.; Tiakas, E.; Manolopoulos, Y.; Papadopoulos, A.N. Skyline-based dissimilarity of images. J. Intell. Inf. Syst. 2019, 53, 509–545. [Google Scholar] [CrossRef]
- Li, Z.H.; Han, A.; Park, Y.B. Efficient Reverse Skyline Query Processing using Two-Level Skyline. J. KIISE Databases 2011, 38, 329–338. [Google Scholar]
- Borzsony, S.; Kossmann, D.; Stocker, K. The skyline operator. In Proceedings of the 17th International Conference on Data Engineering, Berlin/Heidelberg, Germany, 2–6 April 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 421–430. [Google Scholar]
- Woods, L.; Alonso, G.; Teubner, J. Parallel computation of skyline queries. In Proceedings of the 2013 IEEE 21st Annual International Symposium on Field-Programmable Custom Computing Machines, Seattle, WA, USA, 28–30 April 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–8. [Google Scholar]
- Chomicki, J.; Godfrey, P.; Gryz, J.; Liang, D. Skyline with presorting. ICDE 2003, 3, 717–719. [Google Scholar] [CrossRef]
- Vlachou, A.; Doulkeridis, C.; Kotidis, Y. Angle-based space partitioning for efficient parallel skyline computation. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 227–238. [Google Scholar]
- Köhler, H.; Yang, J.; Zhou, X. Efficient parallel skyline processing using hyperplane projections. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 85–96. [Google Scholar]
- Ihm, S.Y.; Nasridinov, A.; Park, Y.H. Grid-PPPS: A Skyline Method for Efficiently Handling Top-Queries in Internet of Things. J. Appl. Math. 2014, 2014, 401618. [Google Scholar] [CrossRef]
- Chen, L.; Chen, F.; Liu, Z.; Lv, M.; He, T.; Zhang, S. Parallel gravitational clustering based on grid partitioning for large-scale data. Appl. Intell. 2023, 53, 2506–2526. [Google Scholar] [CrossRef]
- Zheng, B.; Xu, J.; Lee, W.C.; Lee, D.L. Grid-partition index: A hybrid method for nearest-neighbor queries in wireless location-based services. VLDB J. 2006, 15, 21–39. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computer Device Model | Spec 1 | Price |
|---|---|---|
| A | 10 | 120 |
| B | 14 | 109 |
| C | 19 | 100 |
| D | 29 | 95 |
| E | 39 | 92 |
| F | 48 | 90 |
| G | 21 | 115 |
| H | 32 | 111 |
| I | 37 | 102 |
| J | 42 | 107 |
| K | 50 | 105 |
| Computer Device | Attribute |
|---|---|
| Graphics card | Core speed, boost/turbo clock, memory speed, memory bus, process (architecture), price |
| CPU | Base clock, booster clock, cores/threads, process (architecture), price |
| Data storage | Capacity, reading speed, writing speed, price |
| Skyline Number | Graphics Card Models | Number of Models |
|---|---|---|
| 1 | AMD Radeon RX Vega 56, AMD Radeon RX 6600, NVIDIA Titan X Pascal, NVIDIA GeForce GTX 1080 Ti, AMD Radeon RX 6600 XT, AMD Radeon RX 6700 XT, AMD Radeon Pro W6800, NVIDIA GeForce RTX 3080, NVIDIA RTX A6000, NVIDIA GeForce RTX 3090 | 10 |
| 2 | AMD Radeon RX 5700 XT, NVIDIA GeForce RTX 2080, AMD Radeon RX 6900 XT, NVIDIA RTX A6000, NVIDIA GeForce RTX 3080 Ti | 5 |
| 3 | NVIDIA GeForce MX350, NVIDIA GeForce GTX 1050, NVIDIA Quadro RTX 6000, NVIDIA GeForce RTX 2080 Super, NVIDIA Titan RTX, AMD Radeon RX 6800 XT | 6 |
| 4 | ··· | 8 |
| Skyline Number | Data Storage Models | Number of Models |
|---|---|---|
| 1 | Intel SSD 320 Series SSDSA2CW300G310, SanDisk SD8SN8U1T001122, Samsung SSD 850 PRO 1TB, Samsung SSD SM951 512 GB MZHPV512HDGL, Acer Predator SSD GM7000 2TB, Samsung SSD SM961 1TB M.2 MZVKW1T0HMLH, ADATA XPG Gammix S70 1TB, Western Digital WD_BLACK SN850 WDS100T1X0E, Intel Optane 905P 480GB 2.5, Samsung SSD 980 Pro 1TB MZ-V8P1T0BW, Samsung PM9A1 MZVL22T0HBLB, Samsung SSD 980 Pro 2TB MZ-V8P2T0 | 12 |
| 2 | Plextor PX-256M5M, Toshiba XG6 KXG6AZNV1T02, Toshiba XG6 KXG60ZNV1T02, Samsung PM981a MZVLB2T0HALB, Samsung PM9A1 MZVL2512HCJQ, Corsair MP600, Samsung PM9A1 MZVL21T0HCLR | 7 |
| 3 | Toshiba THNSNC128GBSJ, Crucial MX300 CT525MX300SSD1, OCZ Agility 3 AGT3-25SAT3-120G, Crucial MX100 256 GB, Samsung SSD 850 EVO 1TB, Kingston SA1000M8240G, Intel SSD 660p 2TB SSDPEKNW020T8, Samsung SM961 MZVKW512HMJP m.2 PCI-e, SK Hynix Gold P31 2TB SHGP31-2000GM, Phison 1TB SM2801T24GKBB4S-E162, ADATA XPG Gammix S50 1TB, Phison 512GB SM280512GKBB4S-E162, Phison E12S-2TB-Phison-SSD-BICS4, Samsung SSD 970 Pro 1TB, Kioxia XG7 KXG7AZNV512G, Samsung SSD 970 EVO Plus 1TB, Samsung SSD 970 EVO Plus 2TB, SK Hynix BC711 1TB HFM001TD3JX016N, Samsung SSD 980 Pro 500GB MZ-V8P500BW, SK Hynix Gold P31 1TB SHGP31-1000GM-2 | 20 |
| 4 | ··· | 10 |
| Skyline Number | CPU Models | Number of Models |
|---|---|---|
| 1 | Intel Core i7-7740X, Intel Core i5-10600K, Intel Core i9-9900KS, AMD Ryzen 3800XT, Intel Core i9-10910 (10900), AMD Ryzen 3900X, AMD Ryzen 5900X, AMD Ryzen Threadripper Pro 3975WX, AMD Ryzen Threadripper Pro 3995WX | 9 |
| 2 | AMD FX-8350, AMD Ryzen 3100, Intel Core i7-6700K, AMD Ryzen 2700X, Intel Core i7-8086K, Intel Core i5-11600K, Intel Core i9-9900K, Intel Core i7-10700K, AMD Ryzen 3700X, Intel Core i9-10850K, Intel Core i9-10900K, AMD Ryzen 5800X, Intel Core i9-9980XE, AMD Ryzen 3950X, AMD Ryzen Threadripper 2970WX | 15 |
| 3 | AMD Ryzen 3300X, Intel Core i7-4790K, AMD Ryzen 2600X, AMD Ryzen 1800X, Intel Core i7-8700K, AMD Ryzen 5600X, Intel Core i5-12600K, AMD Ryzen Threadripper 2950X, Intel Core i9-10980XE, AMD Ryzen 5950X | 10 |
| 4 | ··· | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, S.-Y.; Kim, J.; Ihm, S.-Y. The Design and Construction of a Grid Skyline for Custom-Built PC Recommendations Based on a Multi-Attribute Model. Designs 2023, 7, 104. https://doi.org/10.3390/designs7050104
Jeong S-Y, Kim J, Ihm S-Y. The Design and Construction of a Grid Skyline for Custom-Built PC Recommendations Based on a Multi-Attribute Model. Designs. 2023; 7(5):104. https://doi.org/10.3390/designs7050104
Chicago/Turabian StyleJeong, Soo-Yeon, Junseok Kim, and Sun-Young Ihm. 2023. "The Design and Construction of a Grid Skyline for Custom-Built PC Recommendations Based on a Multi-Attribute Model" Designs 7, no. 5: 104. https://doi.org/10.3390/designs7050104
APA StyleJeong, S.-Y., Kim, J., & Ihm, S.-Y. (2023). The Design and Construction of a Grid Skyline for Custom-Built PC Recommendations Based on a Multi-Attribute Model. Designs, 7(5), 104. https://doi.org/10.3390/designs7050104