2. Materials and Methods
2.1. Participants
A total of N = 30 children, living and schooled in Italy were tested remotely using the MuLiMi screening web application. Children attended grades two (last months thereof), three, four and five of primary school, covering an age span of about three years. They had been recruited in schools located in different Italian regions that had accepted our invitation to collaborate in the study. N = 11 children were monolingual Italian. A total of n = 19 children were bilingual.
More precisely, n = 7 children spoke Mandarin in addition to Italian, attending an Italian mainstream school, while n = 12 children spoke English in addition to Italian and attended bilingual schools where they were schooled in English and Italian. All n = 11 monolingual Italian-speaking children also participated in the usability study. Furthermore, n = 10 Examiners who had administered the screenings remotely to children (including two of the authors, M.E. and G.M.) completed the online questionnaire on usability.
2.2. The MuLiMi Screening Platform
From a technical perspective, MuLiMi is a three-tier, RESTful system, developed following the MVC protocol. As anticipated in
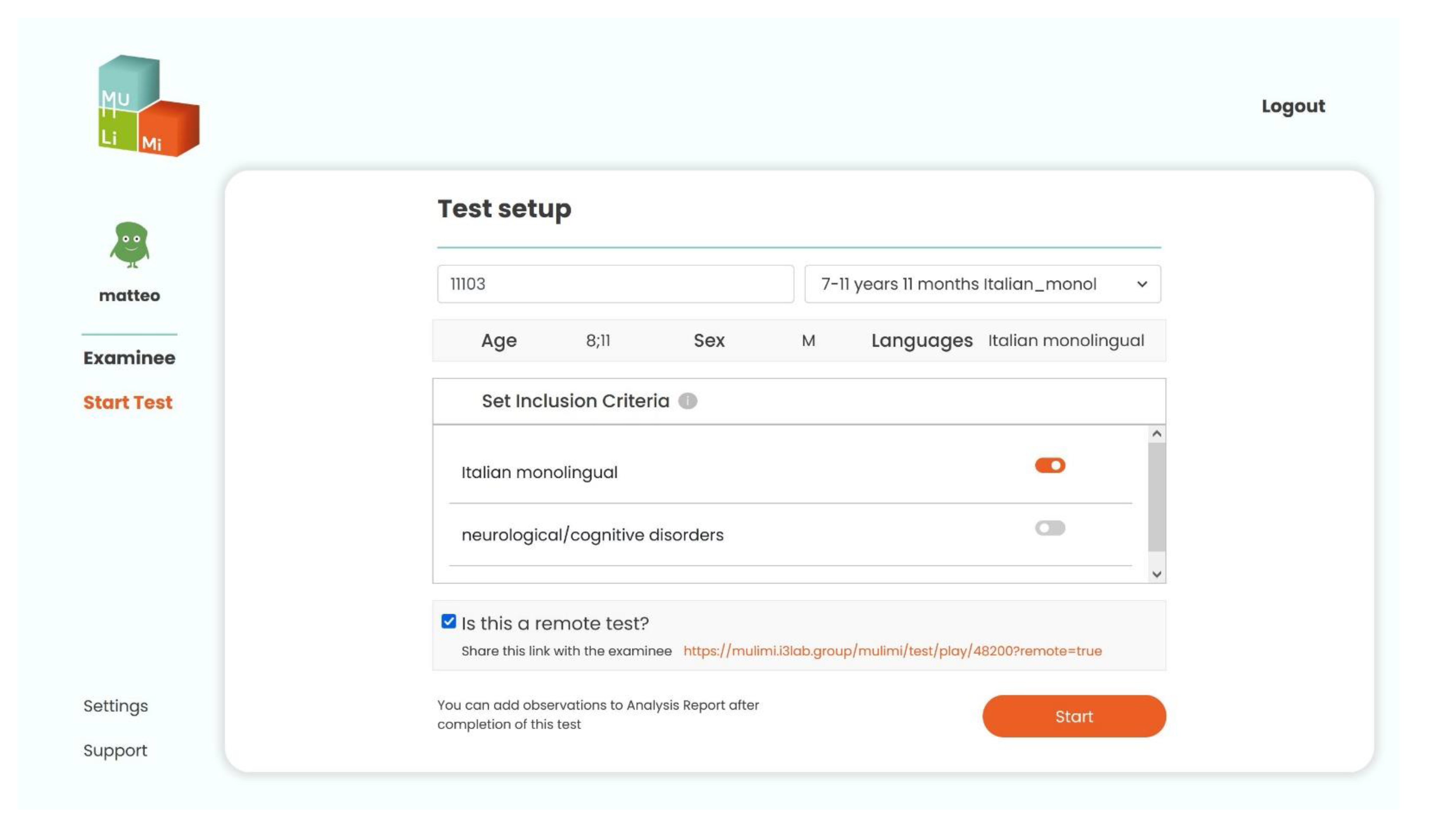
Section 1.2, MuLiMi provides different functionalities and interfaces for the three different categories of end-users: Examiner, Examinee and Administrator. Through the Examiner interface, the user can manage the personal data of their Examinees, play tests (either locally or remotely) and analyze the test results. The interface to launch a screening session is shown in
Figure 1. Selecting an Examinee will enable the tests suited for them. Then, the Inclusion Criteria must be selected according to the Examinee situation. Optionally, the test can be marked as a remote one, and a link to share with the Examinee will be generated.
To view the screening results, the Examiner will navigate among all the test sessions undergone by an Examinee and among the Tasks of individual test sessions. The Examiner can also download a spreadsheet containing all the answers recorded during a test session, write remarks for the entire session or specific for single tasks and visualize online aggregated data about the Examinee’s performance in each task. The interface for data analysis is shown in
Figure 2. The displayed data are:
The number of correct answers.
The number of wrong answers.
The total reaction time (in ms).
The average reaction time, excluding the fastest and slowest ones to reduce leverage.
The Examinee’s interface was designed considering their young age, ranging from 7 to 10 years. Each task type is rendered so that, using adequate multimedia elements (Contents), the experience for the child will be joyful and gamified (see
Figure 3 as an example). Another key aspect to improve enjoyability is to avoid boredom as the test goes on. This is achieved by inserting rewarding visual feedback in each of the instructions at the beginning of each task, which provides a reward for the child’s progression. A typical testing session starts with a Welcome page. Then, each task in the test is presented, preceded by the related instruction page (which is, by itself, configurable—using text, audio and video Contents—by the Administrators).
The Administrator interface enables the creation of new tests or the configuration of an existing one by supporting a standard workflow and facilitating the reuse of multimedia contents.
The workflow consists of the following steps: an Administrator first creates the Contents, which are primitives representing multimedia files (
Figure 4). Supported file types include audio, pictures, videos, plain text and Boolean values.
Contents are then used to create Items: they represent individual screens rendered during the testing session. Items are specific to one task type and can be used to compose Tasks of that type only, as the task type changes the semantic meaning conveyed by the contents inside the item (and consequently the logic used to render them).
A Task is a sequence of Items of the same type, preceded by an instruction page (which is provided in written form but additionally read aloud by a recorded voice and whose purpose is to explain to the Examinee what they will have to do during the task).
A sequence of Tasks can finally be combined to form a Test (
Figure 5), which represents what will be played during an entire Session. A Test is specific to a Language group (pair of L1 and L2) and an Age group (an interval of ages), and Examinees will perform a screening for risk identification of a language or reading disorder.
Tasks, Items and Contents can specify a target language. The possible values are dynamically selected among all the individual languages used to compose the Language groups stored into the platform, plus the Language Universal (LU) value. If a specific language is selected, the element can be used only into other elements of the same language, or LU. If LU is selected, the element can be used in any other element. Tasks can be used in Tests having their language present as either mother or societal language or in any Test if their language is LU.
MuLiMi Remote Testing
The platform also allows Examiners to perform tests remotely. These types of tests are identical to normal tests, considering tasks to be executed. What changes is the setting in which the test is performed since the Examiner is not physically with the Examinee. A connection is therefore required between the two devices used by the Examiner and the Examinee so that the former can always know how the user’s test is proceeding and can help him. The connection is established exploiting WebRTC to instantiate a peer-to-peer communication between the Examiner’s and the Examinee’s machines, allowing for real-time screen sharing and voice communication.
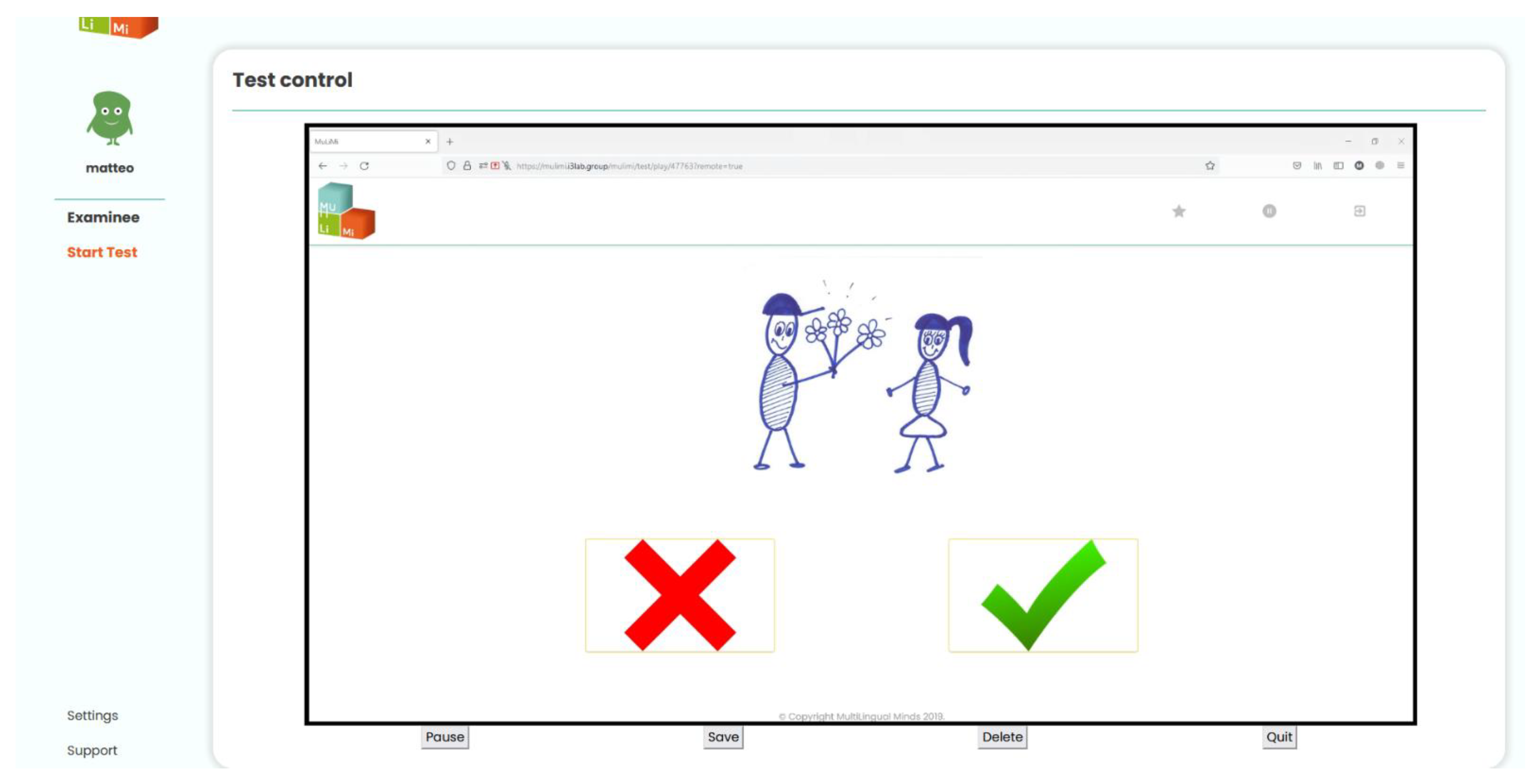
When the Examiner prepares the test to be run, they can specify to execute a remote test (
Figure 1). The platform will generate a link for the Examinee. Once the Examinee opens the link and allows screen sharing, the platform will establish the connection between the devices. Once the connection is established, the Examiner will be able to see the screen of the Examinee streamed on their own screen (
Figure 6).
2.3. Italian Screening Tasks
The Italian Screening Tasks was developed by some of the authors and their collaborators for a preliminary study on Chinese–Italian bilingual children [
28]. They have not yet been published nor standardized.
2.3.1. Reading Speed and Accuracy
Syllable Reading. The participants were required to read aloud as fast as they could a list of thirty (plus three for training) Consonant-Vowel syllables as in the example: “ba”. Syllables were presented one by one on the PC screen. The response/reading time (time elapsed between the presentations of two subsequent syllables) was automatically recorded (self-paced presentation by pressing the spacing bar). The accuracy was not tracked, but it was generally at-ceiling in pilot studies with typically developing children.
Sentence Reading. The participants were required to read aloud as fast as they could a list of five sentences (after one training sentence), presented one by one on the PC screen. The sentences increased in length and syntactic complexity, as in the following examples: “La farfalla vola sui fiori colorati” [the butterfly flies on the colored flowers]; “I gatti camminano lenti sul tetto del palazzo” [the cats walk slowly on the roof of the building]. Sentences were presented one by one on the PC screen. The response/reading time (time elapsed between the presentations of two subsequent sentences) was automatically recorded (self-paced presentation by pressing the spacing bar). The accuracy was not tracked, but it was generally at-ceiling in pilot studies with typically developing children.
Word Identification The participants were required to listen to an Italian pre-recorded word (natural voice, native speaker). Then, they had to select the right orthographic form among three visually presented stimuli on the PC screen. Two of those options were distractors (one phonological and one visual distractor). One grapheme was substituted with respect to the target in either case.
For example, they listened to the word “colto” [‘colto] [educated] and they had to select the correct orthographic form among the following: “colto” (target), “corto” [short] (phonological distractor) and “cotto” [cooked] (visual distractor). Eight items were presented after a brief training with three items. The response/reading time and accuracy were automatically measured. All targets and distractors were existing words.
Nonword Identification. The participants were required to listen to an Italian nonword (pre-recorded, natural voice and native speaker) and, as before, they had to select the correct orthographic form among three visually presented stimuli on the PC screen. Again, two of the options were distractors (one phonological and one orthographic distractor). For example, they listened to the nonword “penko”, and they had to select the correct orthographic form among the following: “penco” (target), “benco” (phonological distractor) and “pencio” (pronounced as “pencho”, orthographic distractor). Eight items were presented after a brief training with three items. The response/reading time and accuracy were automatically measured.
2.3.2. Phonological Awareness
Stressed Syllable Identification. The participants listened to an Italian three-syllabic word (pre-recorded, natural voice and native speaker). Then, the word was presented visually and segmented into syllables on the PC screen. They had to identify the stressed syllable among the three presented.
For example, they listened to the word “favola” [‘favola; “fairy tale”] and they had to select the stressed syllable among the following visually presented “FA”, “VO” and “LA” (the target was “FA”). Eight items were presented after a brief training with two items. Response/reading time and accuracy were automatically measured.
Phonological Blending. The participants listened to two audio stimuli (pre-recorded, natural voice and native speaker). The first one consisted of a series of phonemes, presented at a one-second rate. The second audio stimulus consisted of a whole word. Participants were invited to judge if the word (second audio) represented the correct result of the blended phonemes of the first audio or not, by pressing the corresponding buttons displayed on the screen (a green ✓ standing for correct and a red ✕ for incorrect phonological blending).
For example, they listened to the phoneme-by-phoneme segmented word “a-p-r-e”/a//p//r//e/(“he/she opens”), and then they listened to the word “arpe” [‘arpe] (“harp”); in this case, the blending is incorrect. Ten items were presented after a brief training with two items. A total of 50% of the items were correct, and the other ones contained an inversion of the phonemic sequence. All the targets and distractors were existing words. The response time and accuracy were automatically measured.
Syllabic Inversion. The participants were required to listen to two audio stimuli (pre-recorded, natural voice and native speaker). The first stimulus consisted of a bisyllabic word. The second stimulus consisted of the inversion of the two syllables. Participants were invited to judge if the inversion was correct or not by pressing the corresponding correct/incorrect buttons displayed on the screen.
For example, children listened to the word “dado” [‘dado], meaning “cube”, and then they listened to the correct sequence “doda” [‘doda] (resulting from the inversion of the two syllables) or to the incorrect sequence “donda” [‘donda] (both non-existing words). Ten items were presented after a brief training with two items. A total of 50% of the items were correct; the other items contained a violation of the graphemic/phonemic sequence. The response time and accuracy were automatically measured.
2.3.3. Grammatical Measures
Subject–Verb Agreement. The participants were required to listen to recorded sentences (pre-recorded, natural voice and native speaker) presented one by one and to judge their grammaticality by pressing the corresponding correct/incorrect buttons displayed on the screen. The sentences were taken from a previous experiment on morpho-syntactic processing in DD [
41].
Violations consisted of incorrect subject–verb agreement or incorrect auxiliary selection, as in the following examples: “Le galline grasse mangia* sul prato” [the fat hens eat* (singular) on the lawn] is incorrect because the required agreement between the Subject “Le galline grasse” (plural) and the Verb inflection “mangia” (singular) is not realized; the latter ought to be “mangiano” (plural). Ten items were presented (50% correct) after a brief training with two items. The response time and accuracy were automatically measured.
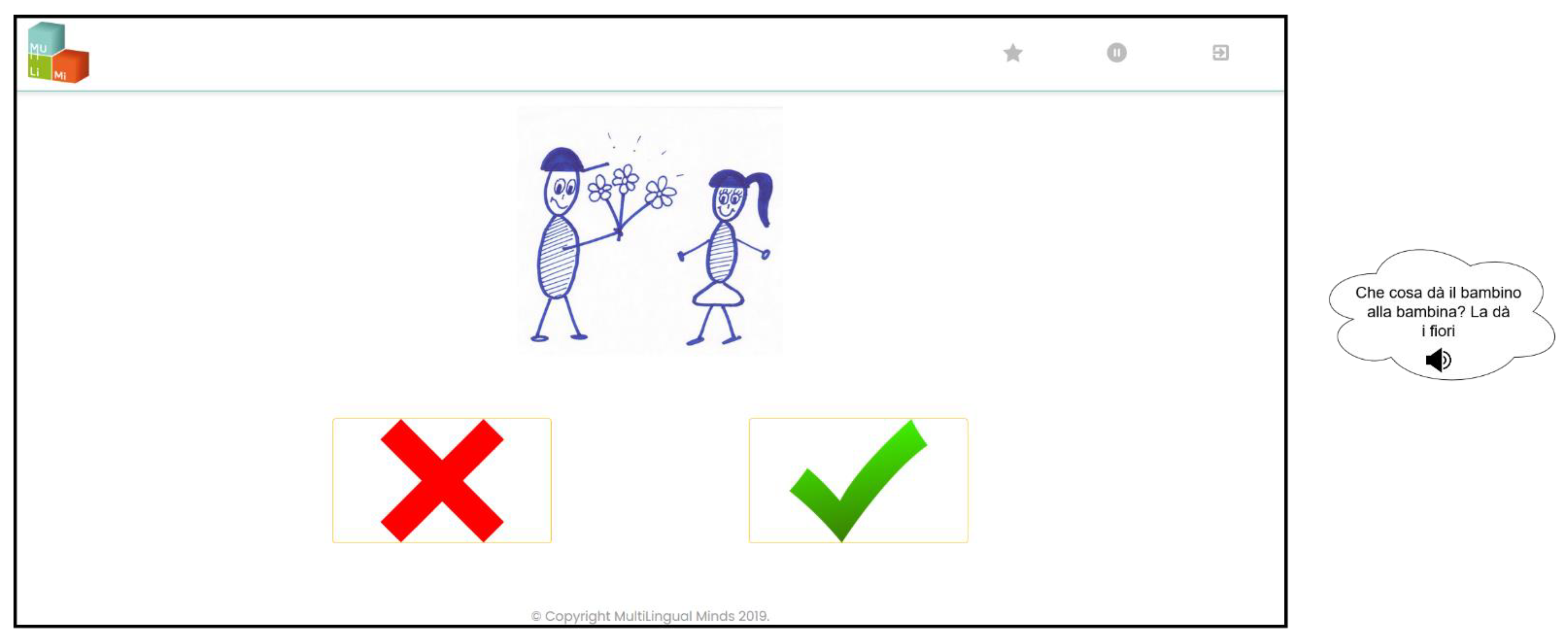
Clitic Pronouns. The participants were presented with line drawings shown on the PC screens, and they listened to questions and to the related answers containing a clitic pronoun. All questions and answers were pre-recorded (natural voice, native speaker). The picture remained on the PC screen until a response was provided. They were invited to judge the grammaticality of the answers by pressing the corresponding correct/incorrect buttons displayed on the screen. The violations consisted of the occurrence of an incorrect clitic pronoun.
For example, in the sentence “Che cosa fa il bambino alla bambina? La* dà i fiori” [What is the boy doing to the girl? He is giving her* flowers], the clitic pronoun “la” is incorrect, because the correct occurrence must be the dative-feminine clitic “le”, instead of the accusative-feminine “la”. Twelve items were presented (50% correct) after a brief training with one item. The response time and accuracy were automatically measured (see
Figure 3 in the Examinee and
Figure 6 in the Examiner interface).
2.4. Mandarin Screening Tasks
The Mandarin screening tasks consist of a Rapid Automatized Naming (RAN) test, two tasks on judgement of correctness of Chinese characters (Hu, unpublished) and three subtests investigating metaphonological skills [
48].
Rapid Automatized Naming (RAN). A series of Arabic numerals were presented in the center of the screen. The participant is asked to read aloud the number that appears as quickly as possible in Chinese and to press the spacebar on the keyboard to see the next number. In total, the test consists of 25 Arabic numerals (preceded by five training items), representing the random repetition of five numbers used to construct this test (2, 4, 6, 7 and 9). The response/reading time was automatically measured (self-paced presentation by pressing the spacing bar). The accuracy was not tracked, but it was at ceiling in pilot studies.
Radical Position. This task examines children’s ability to recognize correctness of the position of a radical (visual element) within a Chinese character [
49,
50]. One character at a time appears on the screen, and the child indicates whether they are presented correctly or not by pressing the corresponding correct/incorrect buttons displayed on the screen. Violations are obtained by changing the position of the radical in the character. The test consists of a total of 18 test items, preceded by two training items. The response/reading time and accuracy were automatically measured.
Left–Right Inversion. This task assesses the child’s ability to identify the correct orientation of the components of certain characters with a high frequency of use [
50]. One character at a time appears on the screen, and the child indicates whether it is spelled correctly or not by pressing the corresponding correct/incorrect buttons displayed on the screen. Violations are characterized by mirroring a radical contained in the character. The test consists of a total of 18 test items, preceded by two training items. The response/reading time and accuracy were automatically measured.
Tone Detection. Two practice trials and eight experimental trials were included. Each item was a Mandarin syllable. Each trial included four items: three with the same tone and one with a different tone. The participants were required to listen to the four audio stimuli and then select the syllable in which the lexical tone differs from the others. For example, they listened to the syllables huā, tán, luó and lán, and they had to select huā. The response time and accuracy were automatically measured.
Onset Detection. Two practice items and 16 experimental items were included. The participants listened to four Mandarin syllables and were asked to indicate among the three syllables, which one sounded different. For instance, among tán, tǐng, téng and luó, the syllables tán, tǐng and téng have the same onset “t”. Thus, participants were expected to select luó as the different one. The response time and accuracy were automatically measured.
Rhyme Detection. Two practice items and 12 experimental items were included. The participants listened to four Mandarin syllables and were asked to indicate which one sounded different. For instance, among tǎng, dáng, láng and qíng, the syllables tǎng, dáng and láng have the same rhyme “ang”. Thus, participants were expected to select qíng as the different one. The response time and accuracy were automatically measured.
2.5. English Screening Tasks
Rapid Automatized Naming (RAN) For the description of the task, see above in the section of Mandarin screening tasks. English-speaking children were asked to name the digits in English.
Sentence Reading. For the description of the task, see above in the section of Italian screening tasks. English-speaking children were asked to read out English sentences.
Orthographic Form Identification. Participants listened to a sentence (pre-recorded, natural voice and accent, for example “Every girl will dress up as a witch.”). The written word form of the last word of each sentence (“witch”) along with two distractors was displayed on the screen.
The children had to identify the word spelled correctly in the context of the sentence they had heard before. While one of the distractors was an existing word that was spelled differently but pronounced alike (“which”), the other was a non-existing word that could be pronounced in the same way as the target (“whitch”). Nine items were presented after a brief training with three items. The response/reading time and accuracy were automatically measured.
Phonological Form Identification. Participants were visually presented one sentence at a time containing one word that was highlighted (“In class, sometimes teachers project slideshows”, highlighted word: [pro’ject]). At the same time, the below three buttons were displayed. While one of the buttons represented the spoken word form of the highlighted word of the written sentence, the other were distractors (distractor 1: [‘project]; distractor 2: [pro’tect], pre-recorded words, natural voice and accent). The children indicated the correctly pronounced version of the highlighted written word presented in the context of a sentence. Eight items were presented after a brief training with three items. The response/reading time and accuracy were automatically measured.
Stressed Syllable Identification. For the description of the task, see above in the section of Italian screening tasks. English-speaking children instead were asked to indicate the word stress for bisyllabic English words.
Sound Deletion. Participants reacted to the questions like “What word would be left if the /b/-sound was taken away from/block/?” and listened to the two options “bock” (incorrect sound deletion) and “lock” (correct sound deletion, pre-recorded, natural voice and accent). Their task was to indicate which of the two options is the result of the correct sound deletion as requested by the question. Ten items were presented after a brief training with two items. The response/reading time and accuracy were automatically measured.
Tense Judgment. Participants reacted to the question “Who says it right?”, which was followed by one sentence in the past tense and one sentence in the present tense. Depending on the context of the sentence, either past or present tense use was correct (example: “Last summer it rained a lot.” vs. “Last summer it rains* a lot.”). Their task was to indicate which of the two options was correct. Twelve items were presented after a brief training with two items. The response/reading time and accuracy were automatically measured.
2.6. Standardized Reading Tests
Batteria per la Valutazione della Dislessia e della Disortografia Evolutiva-2 (DDE-2 [
29]). The DDE contains a word reading subtest including four vertically displayed lists of 28 words and a nonword reading subtest including three lists of 16 nonwords (non-existing words).
Chinese reading test (Hu, in preparation). A test including 150 two-character words, which were chosen from the sets of most popular Chinese language textbooks used in Chinese schools in Italy was presented on the screen. One point was assigned when both characters of each word were read correctly, and 0.5 point was assigned when one character of each word was read correctly. In the Chinese reading test, accuracy, but not reading speed was assessed for each single character presented. Characters included in the test increased in difficulty. Norms have not been published yet; therefore, raw scores (percent accuracy) were used.
Test of Word Reading Efficiency—Second Edition (TOWRE-2 [
30]). Children were presented with vertically displayed word lists and asked them to read out loud as accurately and as fast as possible. For both the word and nonword list, the child had 45 s to read as many items as possible. The Examiner interrupted the child when the 45 s were over.
2.7. Usability Questionnaires
In order to collect data on the usability of the screening platform as perceived by the Examiners and Examinees/child participants, questionnaire items that apply to the MuLiMi screening platform were selected from the commonly used usability measurement tools “System Usability Scale” [
51], Questionnaire for User Interface Satisfaction (QUIS [
52]) and Questionnaire of User Interface Satisfaction (QUIS [
53]) and translated into Italian and adapted when necessary.
A short online questionnaire containing twelve questions was designed for the children, investigating their opinion of the screening platform (see full questionnaire
Appendix A). Each questionnaire item (to be identified by an initial “P” for Participant) consisted of a statement, which was followed by a five-point scale with two extremes that the child could choose from.
A different version of the online questionnaire was designed to be filled by Examiners, investigating their opinion of the screening platform (see full questionnaire
Appendix B). Each questionnaire item (to be identified by an initial “E” for Examiner) consisted of a statement that was followed by a five- to nine-point scale with two extremes that the Examiner could choose from. The questionnaire consisted of 46 questions.
2.8. DSA Parent Questionnaire
The “DSA Questionnaire” (Lorusso and Milani, unpublished, where DSA stands for the Italian term “Disturbi Specifici di Apprendimento”—Specific Learning Disorders), used on the Institute’s online platform to collect information about the children’s problems and orient their clinical diagnostic pathway before admission to the clinic, was used here. In addition to questions on anagraphic data and information on the child’s language background, from which the children’s language dominance was derived, the questionnaire contained questions in the four different categories covering (1) school discomfort, (2) general learning difficulties and (3) in-depth analyses on learning difficulties for reading and writing acquisition and (4) math skills separately.
One point was assigned whenever parents responded with “yes” to a question related to a negatively connotated question. In a second step, compound scores on the four categories were created, and responses from online and pen-and-paper questionnaires were merged and translated into English for data processing.
2.9. Procedure
For bilingual children, standardized and screening tests were administered in two separate sessions lasting 45 to 60 min each, while the monolingual children who only received standardized and screening tasks in Italian (their native language) completed all tasks in a single session of approximately 90 min, with a 10-min break. All the children were tested remotely while the Examiner was connected via video conferencing and administered the standardized tasks through screen share. The screening was started using the remote feature of the MuLiMi screening platform requiring the sharing of the link with the child.
In order to simulate a realistic testing scenario, Examiners used their personal or work PC while children used the PC of the school when being tested at school and their families’ private computer when being tested at home. Since children were tested exclusively remotely, the standardized test administration procedure had to be adapted accordingly.
After the Examiner had verified that the size of the scanned version of the word lists was comparable to the original size of the characters in the standardized test, children were asked to read the words displayed on their screen through screen share as accurately and fast as possible row by row. The Examiner measured the reading time and scored the child’s reading performance after the test administration based on audio recordings as indicated in the test manual.
Since some collaborating schools had expressed preferences for either on- vs. offline formats of the parental questionnaires and to ensure that all the parents could fill in the questionnaires, several versions of the parental questionnaire were created and distributed. While, for the monolingual Italian and English–Italian children, parental questionnaires were implemented as online surveys using “Google Forms”, parents of Chinese–Italian children were administered a pen-and-paper version of the questionnaire. Parents of bilingual children had the option to choose whether they wanted to fill in the questionnaire in their L1 or in Italian. The usability questionnaires were also filled by Examinees/child participants and Examiners using “Google Forms”. The link to the online survey was shared with the user. Additionally, a pen-and-paper questionnaire was filled in by the teachers of bilingual children, judging the child’s Italian productive and receptive phonology, morphosyntax and vocabulary skills, and his/her reading performance on a 5-point-scale.
2.10. Data Analysis
In order to display varying degrees of reading skills irrespectively of the presence of an official diagnosis of DD, based on the results obtained in the DDE-2 and the reading tests in the children’s L1, a reading difficulty risk score was created for the bilingual children (for the monolingual children the information on DDE-2 performance is sufficient to identify the risk of DD). For the creation of this score, children were first assigned a point whenever they had z-scores at or below minus two standard deviations in speed and/or accuracy in the word and/or nonword reading subtests of the DDE-2.
The DDE-2 risk scores ranged between 0 (no risk in either of the two subtests), 1 (at or below minus two standard deviations in one of the two subtests) and 2 (at or below minus two standard deviations in the two subtests). In a second step, the risk for reading difficulties in the L1 was assessed. For the English-speaking children, the z-scores from the TOWRE-2 were processed equivalently to the DDE-2. For the Mandarin-speaking children instead, when the children were not able to read more than one-third (33.33%) of the Chinese words, a risk of 1 was assigned. In a third step, the sum of those two scores was created and led into the total compound risk score, ranging from 0 to 4.
In order to explore the associations between scores obtained in the different tests (standardized tests and screening tasks) it was necessary to analyze the results separately in the different language groups (due to different L1 characteristics), thus, reducing the sample size. In particular for the Mandarin-speaking subgroup, which included only seven children, extreme power reduction led us to the decision to consider correlations (Spearman’s rho) larger than 0.5, regardless of their significance level, merely regarding them as an indication of a possible tendency in the results, to be confirmed by future studies on larger samples.
For all analyses conducted to answer the research questions described in the introduction, no Bonferroni correction was applied (a-priori hypotheses). Similarly, no correction was applied when performing correlation analyses with highly inter-correlated variables. Whenever sample size, non-continuous variables or clear deviations from normality prevented application of parametric correlations, Spearman’s correlations were computed.
4. Discussion
The current study provides evidence that it is (a) possible and (b) useful to follow the recommendations suggested by various policy oriented projects [
18,
22]. Indeed, this study not only confirms that children tested by means of computerized reading screenings are pleased with the medium (cf. [
25]) but also adds direct evidence from a usability study.
4.1. Validity of the Screening Tasks
Similarly to previous studies (cf. [
27,
28]), performance in the screening tasks was found to be correlated with reading performance as measured by standardized reading tests [
41,
42]. In order to find out whether not only the word and nonword reading tests in Italian but also the L1 reading tests reflect bilingual children’s general reading skills, the associations between these two measures of reading ability were assessed and found to be significant.
The results in most, although not all reading tasks of the MuLiMi screening battery were significantly associated with the performance in (subtests of) the standardized/traditional reading tests, both in the whole group and in the different subgroups. This finding confirms what is usually found in terms of parallel development of reading abilities in the L1 and the L2 and of transfer between the two languages [
17,
18,
19].
Nonetheless, it should also be noted that the bilingual children in our sample were all schooled in both languages, either in mainstream school (English–Italian children) or in separate weekdays and weekend school (Mandarin–Italian children), so it is not possible to generalize this finding to the whole population of bilingual children. More precisely, the reading time scores measured in the self-paced syllable and sentence reading tasks along with performance in Word and Nonword Identification tasks of the Italian screening were significantly associated with the performance in the Italian standardized reading tests.
However, not only reading accuracy and reading speed in both languages (L1 and L2) but also other clinical markers proved to be useful for dyslexia risk identification, as suggested by previous studies [
19,
20,
25,
26,
27,
28,
29,
30,
31,
32,
33,
36,
37,
38,
39]. Indeed, Phonological Blending and grammaticality judgement tasks were all significantly and positively associated with the performance in the Italian standardized reading tests. For the two groups of bilingual children, this general pattern was confirmed when comparing the screening task results to the risk levels derived from the standardized L1 reading test.
Since the results obtained in these screening tasks are also significantly associated with the level of DD-risk as revealed in the parental questionnaires (with the exception of the clitic judgment task, for which negative correlations emerged), it can be concluded that the tasks are suitable for the identification of DD risk in mono- and bilingual children. Turning to the teacher questionnaire, even if the only significant association emerging was with accuracy in the Italian Word Identification, this result confirms the validity of the screening with respect to restricted but crucial reading abilities.
Not only performance in the Italian screening tasks but also the performance in screening tasks in the children’s L1 were significantly associated with standardized/traditional reading tests and risk scores. For the English screening tasks, similarly to the Italian screening tasks, reading time in the self-paced sentence reading task was significantly associated with word and nonword reading time in the English standardized reading test.
Furthermore, the associations between the standardized test scores and the English Orthographic Form Identification task as well as in the identification of correct tense marking suggest that also these screening tasks are suitable for the identification of DD-risk in English–Italian speaking children. This pattern was confirmed when comparing the children’s screening task performance to the risk level derived from Italian and English standardized reading tests.
The pronunciation and deletion tasks were shown to be contributing to the detection of DD-risk, even though to a much smaller extent. For the Mandarin screening tasks instead, performance in the Onset and Rhyme Detection tasks as well as the Left–Right Inversion and Radical Position judgement tasks were associated with the number of correctly read Mandarin characters.
Mandarin RAN (digits) was also found to be suitable for DD-risk identification in Mandarin–Italian-speaking children. This finding is in line with studies suggesting that phonemic awareness plays a central role in the development of reading abilities in both alphabetic and logographic orthographic systems, even if the relative weight may vary slightly [
21,
22,
29], and that naming deficits (RAN) as well as visual-perceptual skills play an additional role especially in transparent alphabetic orthographies, such as Italian or in logographic systems, such as Chinese.
Altogether, these results show that it is possible to automatically assess reading and reading-related skills in the child’s L1 without any requirement for the Examiner to speak the language of assessment. It is worth noting that this information cannot directly lead to the diagnosis of a specific learning disorder, but it highlights the presence of an increased risk of DD and the need of in-depth investigation for diagnostic purposes.
The associations between performance in standardized tests and scores obtained in some of the screening tasks have several practical implications. First, these associations show that, in general, it is possible to assess general reading abilities of mono- and bilingual children using computerized screening tasks implemented on the screening platform MuLiMi.
In order to better understand the use and usefulness of the application of such automated screenings, the requirements for measuring reading time and accuracy in task performance need to be discussed separately. The measurement of reading time, necessary to evaluate a child’s reading fluency, in clinical practice is usually achieved by manually measuring reading time using a stopwatch or similar and then calculating speed. The use of self-paced reading on the computer is a sufficiently proximal equivalent of this kind of measurement.
As for the measurement of accuracy, the usual practice for clinicians is to record and possibly classify each error produced by the child during reading and then assigning a score that may differ according to the type of error (e.g., DDE-2 scoring rules). Automatized tasks recording errors are not only less time consuming; however, they are often the only way to assess a child’s language and/or reading skills in L1 without speaking that language.
4.2. Usability of the Web-Platform and Screenings
The usability study highlighted very positive results, confirming that the screening platform and tasks are enjoyable, easy to use and useful. While previous studies had already highlighted the potential of (a) computerized screenings for the identification of risk for dyslexia [
27,
28] and (b) remote testing solutions [
14,
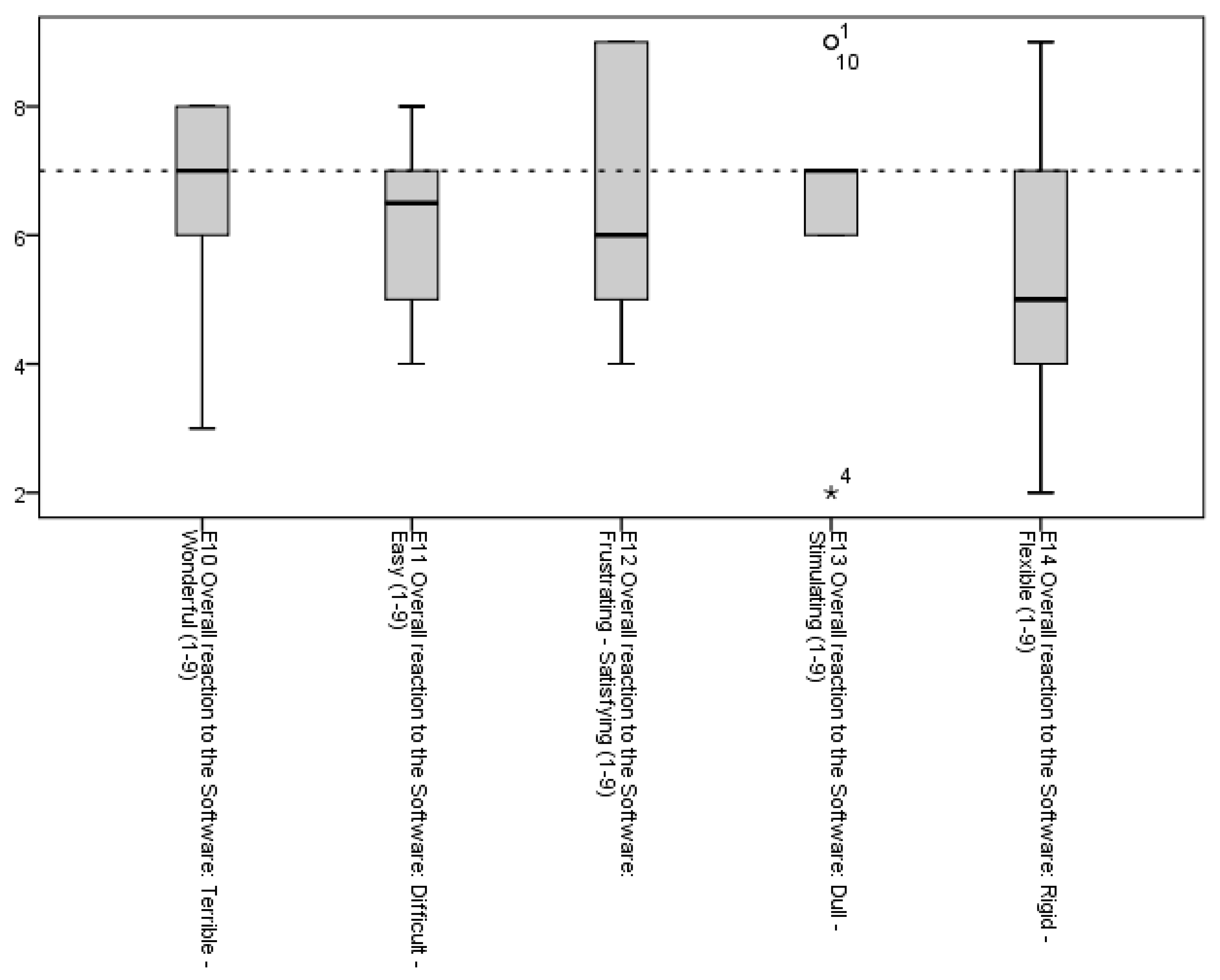
26], the application of the latter is often restricted in terms of devices, operating systems and testing languages. As shown by the results of the present study, the MuLiMi platform offers a very flexible solution that can easily be adapted to different needs, situations and devices. Nonetheless, the usability study also highlighted some issues that should be addressed in future work.
The first issue appears to be reaction speed, both for Examinees (P5) and Examiners (E19). Regarding the Examinee interface, preliminary analysis suggests that network latency could be the main cause of the slow reaction time of the platform The Examinee’s interface appears to be reactive enough on cabled networks when tested, and thus it is hypothesized that Examinees could use the platform from a slower network more often than we expected.
As to the slow loading of data to display into the tables in the Examinee interface, the cause of the delay is probably the method used to load the data: those are loaded in an eager way (all the data of the table are loaded at once and processed for rendering as well). A lazy loading method should drastically reduce the table’s loading times.
Some of the Examiners mentioned the lack of a feature that would allow them to select the starting task of a test. The need behind this request is to be able to resume a forcefully interrupted test session, a problem that manifested frequently especially in remote sessions and should be solved by finding a way for detecting a non-completed test session and allow the Examiners to resume it.
Furthermore, the platform is perceived as slightly rigid by the Examiners. This was expected, and the reason likely lies in the platform design itself: the freedom of the Examiner has been restricted to increase the safety of operations. A post-hoc statistical analysis highlighted a significant (n = 10, r = 0.837, p = 0.003) correlation between the two reported complaints, suggesting that the perceived rigidity is related to missing expected features. A resume feature could thus reduce the perceived rigidity.
Finally, the Examiners highlighted that the platform may not be suited for some levels of users. Some of the interviewed clarified that some of the tests appeared too hard for the target Examinees. This issue should be solved by the envisaged process of task and item selection, that will be performed based on the results of preliminary validation.
4.3. Limitations and Future Perspectives
Despite the potential of the screening platform revealed in the previous sections, there are limitations regarding the screening platform and the study. The remote testing feature revealed a particular limitation: the STUN protocol has issues with some network configurations, especially when the Examinee tries to connect by an institutional network (for example the one of a school), which are usually protected by strong firewalls. WebRTC offers TURN as a solution for this issue. However, the TURN protocol requires one or more support server processes, and the cost to deploy those processes is rather high compared to expected benefits.
Furthermore, samples of tested children were small, which only partly allows for a generalization of the results. Moreover, the degree to which the clinical value of the screening platform can be assessed is very limited due to the low number of children with known specific reading disorders or at-risk for the latter in the present sample. Conclusions on the potential in DD-risk evaluation were merely based on the risk that was inferred from performance on standardized tests, while no in-depth clinical investigation was conducted.
Therefore, the present study cannot be considered as a full validation study, but rather as a preliminary validation, which provided generally positive results for all aspects taken into consideration. Further studies need to be conducted in order to find out whether a combination of methods (indirect like parental and teacher questionnaires and direct testing of language performance in all languages spoken) can lead to risk detection better than single methods.
Based on these preliminary results, systematic item selection procedures in the most sensitive tasks should be conducted in order to further shorten the screening so as to improve its applicability further. This, combined with improved system speed/response, will facilitate future studies and the implementation of such screenings in classroom and clinical settings.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}