
Evolution and Trends in Sign Language Avatar Systems: Unveiling a 40-Year Journey via Systematic Review


Abstract
:1. Introduction
- RQ1: What is the bibliographic information of the existing SL avatars?
- ⚬
- SRQ1a: What are the most frequent keywords used and what is the related co-occurrence network?
- ⚬
- SRQ1b: What is the trend on the number of papers published per year?
- ⚬
- SRQ1c: What are the different publication venues used by the authors?
- ⚬
- SRQ1d: Which country is the most active in publishing in the area of sign language avatars? What is the collaboration relationship between countries?
- ⚬
- SRQ1e: Who are the most active authors? What is the trend of collaboration amongst authors?
- ⚬
- SRQ1f: What are the most relevant affiliations?
- ⚬
- SRQ1g: What is the sign language most studied for SL avatars?
- RQ2: What are the technologies used in developing SL avatars?
- ⚬
- SRQ2a: What are the methods used for SL synthesis?
- ⚬
- SRQ2b: What are the techniques used to animate SL avatars?
- ⚬
- SRQ2c: What are the characteristics of SL corpus and the annotation techniques used?
- ⚬
- SRQ2d: What are the techniques used for generating facial expressions?
- RQ3: What are the evaluation methods and metrics used to evaluate SL avatar systems?
2. Background
2.1. Sign Language Synthesis
2.2. Sign Language Databases
2.3. Animating SL Avatars
2.4. Facial Expressions
2.5. Evaluation of SL Avatars
3. Methodology
3.1. Eligibility Criteria
3.2. Information Sources
3.3. Search Strategy
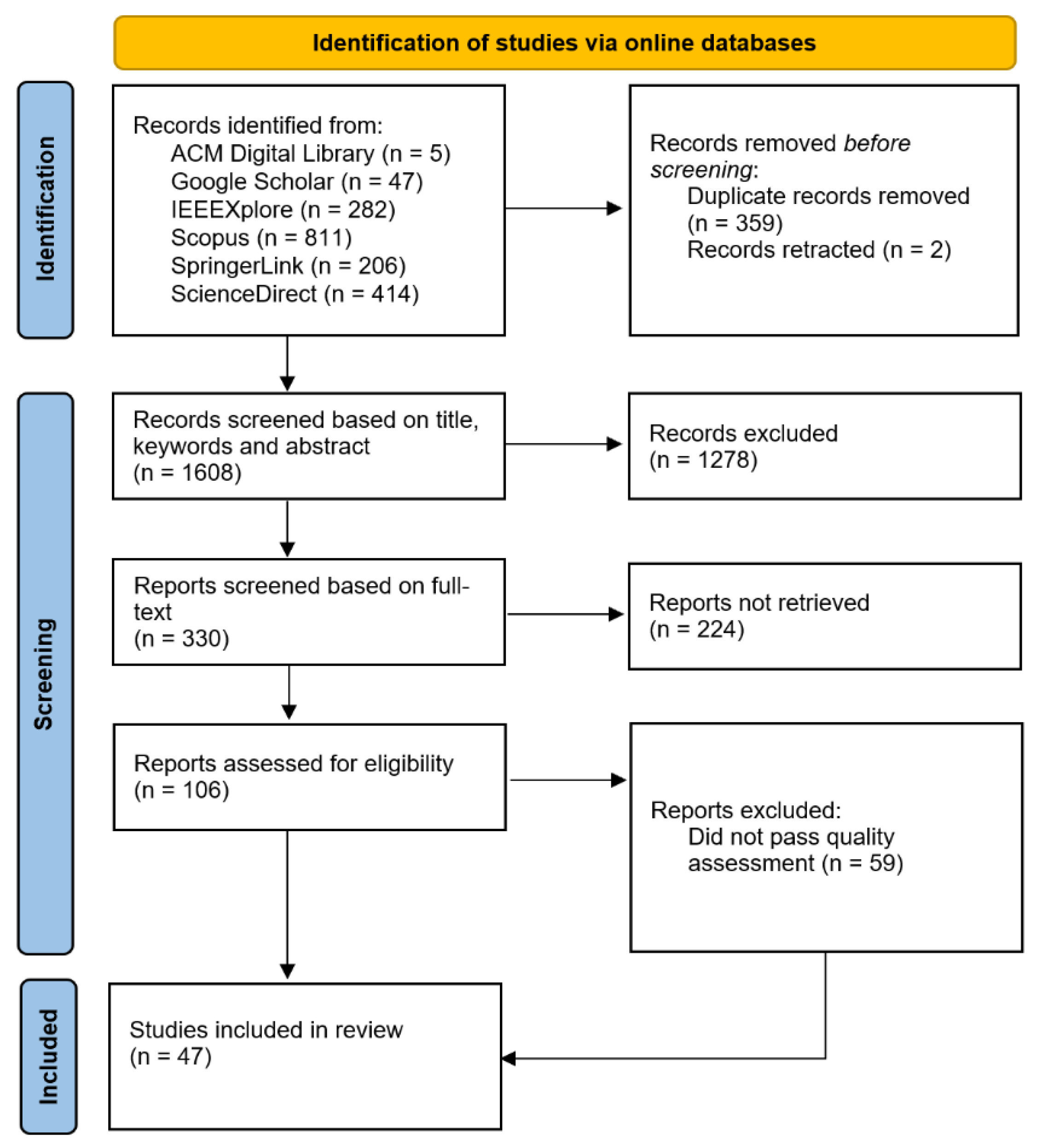
3.4. Selection Process
3.5. Quality Assessment
- Are the aims and research questions clearly stated and directed towards avatar technology and its production?
- Are all the study questions answered?
- Are the techniques/methodologies used in the study for avatar production fully defined and documented?
- Are the limitations of this study adequately addressed?
- How clear and coherent is the reporting?
- Are the measures used in the study the most relevant ones for answering the research questions?
- How well does the evaluation address its original aims and purpose?
4. Results and Discussion
4.1. Selected Studies
4.2. RQ1: Bibliometric Analysis of the Selected Studies
4.2.1. SRQ1a: Keyword Analysis
4.2.2. SRQ1b: Trend of Published Papers Per Year
4.2.3. SRQ1c: Publication Venues
4.2.4. SRQ1d: Country-Wise Analysis
4.2.5. SRQ1e: Author-Wise Analysis
4.2.6. SRQ1f: Relevant Affiliations
4.2.7. SRQ1g: Most Studied Sign Language for SL Avatars
4.3. RQ2: Technologies Used in Development of SL Avatars
4.3.1. SRQ2a: Sign Language Synthesis
4.3.2. SRQ2b: Sign Language Animation Techniques
4.3.3. SRQ2c: Sign Language Corpora Characteristics and Annotation Techniques
4.3.4. SRQ2d: Sign Language Facial Expressions Generation
4.4. RQ3: Evaluation Methods and Metrics of SL Avatars
5. Discussion
6. Conclusions
7. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Deafness and Hearing Loss. 27 February 2023. Available online: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 28 May 2023).
- United Nations. International Day of Sign Languages. Available online: https://www.un.org/en/observances/sign-languages-day (accessed on 28 May 2023).
- Yet, A.X.J.; Hapuhinne, V.; Eu, W.; Chong, E.Y.C.; Palanisamy, U.D. Communication methods between physicians and Deaf patients: A scoping review. Patient Educ. Couns. 2022, 105, 2841–2849. [Google Scholar] [CrossRef] [PubMed]
- Quandt, L.C.; Willis, A.; Schwenk, M.; Weeks, K.; Ferster, R. Attitudes toward Signing Avatars Vary Depending on Hearing Status, Age of Signed Language Acquisition, and Avatar Type. Front. Psychol. 2022, 13, 254. [Google Scholar] [CrossRef] [PubMed]
- Naert, L.; Larboulette, C.; Gibet, S. A survey on the animation of signing avatars: From sign representation to utterance synthesis. Comput. Graph. 2020, 92, 76–98. [Google Scholar] [CrossRef]
- Prinetto, P.; Tiotto, G.; Del Principe, A. Designing health care applications for the deaf. In Proceedings of the 2009 3rd International Conference on Pervasive Computing Technologies for Healthcare, London, UK, 1–3 April 2009; pp. 1–2. [Google Scholar] [CrossRef]
- Wolfe, R.; Mcdonald, J.C.; Efthimiou, E.; Fotinea, E.; Picron, F.; van Landuyt, D.; Sioen, T.; Braffort, A.; Filhol, M.; Ebling, S.; et al. The myth of signing avatars. In Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages, Virtual, 20 August 2021; Available online: https://www.academia.edu/download/76354340/2021.mtsummit-at4ssl.4.pdf (accessed on 1 June 2023).
- Wolfe, R. Special issue: Sign language translation and avatar technology. Mach. Transl. 2021, 35, 301–304. [Google Scholar] [CrossRef]
- Mori, M.; MacDorman, K.F.; Kageki, N. The uncanny valley. IEEE Robot. Autom. Mag. 2012, 19, 98–100. [Google Scholar] [CrossRef]
- Bragg, D.; Koller, O.; Bellard, M.; Berke, L.; Boudreault, P.; Braffort, A.; Caselli, N.; Huenerfauth, M.; Kacorri, H.; Verhoef, T.; et al. Sign language recognition, generation, and translation: An interdisciplinary perspective. In Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility, Pittsburgh, PA, USA, 28–30 October 2019; Association for Computing Machinery, Inc.: New York, NY, USA, 2019; pp. 16–31. [Google Scholar] [CrossRef]
- Kipp, M.; Heloir, A.; Nguyen, Q. Sign language avatars: Animation and comprehensibility. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6895, pp. 113–126. [Google Scholar] [CrossRef]
- Kahlon, N.K.; Singh, W. Machine translation from text to sign language: A systematic review. Univers. Access Inf. Soc. 2021, 22, 1–35. [Google Scholar] [CrossRef]
- Farooq, U.; Rahim, M.S.M.; Sabir, N.; Hussain, A.; Abid, A. Advances in machine translation for sign language: Approaches, limitations, and challenges. Neural Comput. Appl. 2021, 33, 14357–14399. [Google Scholar] [CrossRef]
- Rastgoo, R.; Kiani, K.; Escalera, S.; Sabokrou, M. Sign language production: A review. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3451–3461. Available online: https://openaccess.thecvf.com/content/CVPR2021W/ChaLearn/html/Rastgoo_Sign_Language_Production_A_Review_CVPRW_2021_paper.html (accessed on 31 May 2023).
- Wolfe, R.; McDonald, J.C.; Hanke, T.; Ebling, S.; Van Landuyt, D.; Picron, F.; Krausneker, V.; Efthimiou, E.; Fotinea, E.; Braffort, A. Sign Language Avatars: A Question of Representation. Information 2022, 13, 206. [Google Scholar] [CrossRef]
- Kacorri, H. TR-2015001: A Survey and Critique of Facial Expression Synthesis in Sign Language Animation. January 2015. Available online: https://academicworks.cuny.edu/gc_cs_tr/403 (accessed on 1 June 2023).
- Heloir, A.; Gibet, S.; Multon, F.; Courty, N. Captured motion data processing for real time synthesis of sign language. In Proceedings of the Gesture in Human-Computer Interaction and Simulation: 6th International Gesture Workshop, Berder Island, France, 18–20 May 2005; Springer: Berlin/Heidelberg, Germany, 2006; pp. 168–171. [Google Scholar] [CrossRef]
- Porta, J.; López-Colino, F.; Tejedor, J.; Colás, J. A rule-based translation from written Spanish to Spanish Sign Language glosses. Comput. Speech Lang. 2014, 28, 788–811. [Google Scholar] [CrossRef]
- Arvanitis, N.; Constantinopoulos, C.; Kosmopoulos, D. Translation of sign language glosses to text using sequence-to-sequence attention models. In Proceedings of the 15th International Conference on Signal Image Technology and Internet Based Systems, SISITS 2019, Sorrento, Italy, 26–29 November 2019; pp. 296–302. [Google Scholar] [CrossRef]
- McCarty, A.L. Notation Systems for Reading and Writing Sign Language. Anal. Verbal Behav. 2004, 20, 129–134. [Google Scholar] [CrossRef]
- Bouzid, Y.; Jemni, M. An avatar based approach for automatically interpreting a sign language notation. In Proceedings of the 2013 IEEE 13th International Conference on Advanced Learning Technologies, ICALT 2013, Beijing, China, 15–18 July 2013; pp. 92–94. [Google Scholar] [CrossRef]
- Kennaway, J.R.; Glauert, J.R.; Zwitserlood, I. Providing signed content on the Internet by synthesized animation. ACM Trans. Comput. Interact. 2007, 14, 15. [Google Scholar] [CrossRef]
- Filhol, M. Zebedee: A Lexical Description Model for Sign Language Synthesis. Internal, LIMSI. 2009. Available online: https://perso.limsi.fr/filhol/research/files/Filhol-2009-Zebedee.pdf (accessed on 7 June 2023).
- Havasi, L.; Szabó, H.M. A motion capture system for sign language synthesis: Overview and related issues. In Proceedings of the EUROCON 2005—The International Conference on Computer as a Tool, Belgrade, Serbia, 21–24 November 2005; pp. 445–448. [Google Scholar] [CrossRef]
- Grieve-Smith, A.B. SignSynth: A sign language synthesis application using Web3D and perl. In Gesture and Sign Language in Human-Computer Interaction: International Gesture Workshop; Springer: Berlin/Heidelberg, Germany, 2002; pp. 134–145. [Google Scholar] [CrossRef]
- Neidle, C.; Thangali, A.; Sclaroff, S. Challenges in development of the american sign language lexicon video dataset (asllvd) corpus. In Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon (LREC), Istanbul, Turkey, 21–27 May 2012; Available online: https://hdl.handle.net/2144/31899 (accessed on 2 March 2023).
- Forster, J.; Schmidt, C.; Hoyoux, T.; Koller, O.; Zelle, U.; Piater, J.H.; Ney, H. RWTH-PHOENIX-weather: A large vocabulary sign language recognition and translation corpus. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; pp. 3785–3789. Available online: http://www-i6.informatik.rwth-aachen.de/publications/download/773/forster-lrec-2012.pdf (accessed on 31 May 2023).
- Cabeza, C.; Garcia-Miguel, J.M.; García-Mateo, C.; Luis, J.; Castro, A. CORILSE: A Spanish sign language repository for linguistic analysis. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC ’16), Portorož, Slovenia, 23–28 May 2016; pp. 1402–1407. Available online: https://aclanthology.org/L16-1223/ (accessed on 31 May 2023).
- Preda, M.; Preteux, F. Insights into low-level avatar animation and MPEG-4 standardization. Signal. Process. Image Commun. 2002, 17, 717–741. [Google Scholar] [CrossRef]
- Lombardi, S.; Simon, T.; Saragih, J.; Schwartz, G.; Lehrmann, A.; Sheikh, Y. Neural Volumes: Learning Dynamic Renderable Volumes from Images. ACM Trans. Graph. 2019, 38, 3020. [Google Scholar] [CrossRef]
- Pranatio, G.; Kosala, R. A comparative study of skeletal and keyframe animations in a multiplayer online game. In Proceedings of the 2010 2nd International Conference on Advances in Computing, Control and Telecommunication Technologies, ACT 2010, Jakarta, Indonesia, 2–3 December 2010; pp. 143–145. [Google Scholar] [CrossRef]
- Gibet, S.; Lefebvre-Albaret, F.; Hamon, L.; Brun, R.; Turki, A. Interactive editing in French Sign Language dedicated to virtual signers: Requirements and challenges. Univers. Access Inf. Soc. 2016, 15, 525–539. [Google Scholar] [CrossRef]
- Wong, J.; Holden, E.; Lowe, N.; Owens, R.A. Real-Time Facial Expressions in the Auslan Tuition System. Comput. Graph. Imaging 2003, 7–12. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=da38d324052b63a8de2266fef7655bd545a82f56 (accessed on 30 May 2023).
- Gonçalves, D.A.; Todt, E.; Cláudio, D.P. Landmark-based facial expression parametrization for sign languages avatar animation. In Proceedings of the XVI Brazilian Symposium on Human Factors in Computing Systems (IHC 2017), Joinville, Brazil, 23–27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Papastratis, I.; Chatzikonstantinou, C.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Artificial Intelligence Technologies for Sign Language. Sensors 2021, 21, 5843. [Google Scholar] [CrossRef]
- Wolfe, R.; Braffort, A.; Efthimiou, E.; Fotinea, E.; Hanke, T.; Shterionov, D. Special issue on sign language translation and avatar technology. Univers. Access Inf. Soc. 2023, 1, 1–3. [Google Scholar] [CrossRef]
- Kipp, M.; Nguyen, Q.; Heloir, A.; Matthes, S. Assessing the deaf user perspective on sign language avatars. In Proceedings of the 13th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS ’11), Dundee, UK, 24–26 October 2011; ACM: New York, NY, USA, 2011; pp. 107–114. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. BMJ 2009, 339, 332–336. [Google Scholar] [CrossRef]
- Zotero | Your Personal Research Assistant. Available online: https://www.zotero.org/ (accessed on 30 May 2023).
- Kitchenham, B.; Charters, S. Guidelines for performing Systematic Literature Reviews in Software Engineering. 2007. Available online: Chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://www.elsevier.com/__data/promis_misc/525444systematicreviewsguide.pdf (accessed on 19 July 2023).
- Pezeshkpour, F.; Marshall, I.; Elliott, R.; Bangham, J.A. Development of a legible deaf-signing virtual human. In Proceedings of the International Conference on Multimedia Computing and Systems, Florence, Italy, 7–11 June 1999; pp. 333–338. [Google Scholar] [CrossRef]
- Losson, O.; Cantegrit, B. Generation of signed sentences by an avatar from their textual description. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Yasmine Hammamet, Tunisia, 6–9 October 2002; pp. 426–431. [Google Scholar] [CrossRef]
- Cox, S.; Lincoln, M.; Tryggvason, J.; Nakisa, M.; Wells, M.; Tutt, M.; Abbott, S. Tessa, a system to aid communication with deaf people. In Proceedings of the Fifth International ACM Conference on Assistive Technologies, Edinburgh, UK, 8–10 July 2002; p. 205. [Google Scholar] [CrossRef]
- Hou, J.; Aoki, Y. A Real-Time Interactive Nonverbal Communication System through Semantic Feature Extraction as an Interlingua. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2004, 34, 148–155. [Google Scholar] [CrossRef]
- Papadogiorgaki, M.; Grammalidis, N.; Makris, L. Sign synthesis from SignWriting notation using MPEG-4, H-Anim, and inverse kinematics techniques. Int. J. Disabil. Hum. Dev. 2005, 4, 191–204. [Google Scholar] [CrossRef]
- Adamo-Villani, N.; Carpenter, E.; Arns, L. An immersive virtual environment for learning sign language mathematics. In Proceedings of the ACM SIGGRAPH 2006 Educators Program, SIGGRAPH ’06, Boston, MA, USA, 30 July–3 August 2006; ACM: New York, NY, USA, 2006; p. 20. [Google Scholar] [CrossRef]
- San-Segundo, R.; Barra, R.; D’haro, L.F.; Montero, J.M.; Córdoba, R.; Ferreiros, J. A spanish speech to sign language translation system for assisting deaf-mute people. In Proceedings of the Ninth International Conference on Spoken Language Processing, Jeju, Republic of Korea, 17–21 September 2006; Available online: http://lorien.die.upm.es/~lfdharo/Papers/Spanish2SignLanguage_Interspeech2006.pdf (accessed on 18 June 2023).
- Van Zijl, L.; Fourie, J. The Development of a Generic Signing Avatar. In Proceedings of the IASTED International Conference on Graphics and Visualization in Engineering (GVE ’07), Clearwater, FL, USA, 3–5 January 2007; ACTA Press: Calgary, AB, Canada, 2007; pp. 95–100. [Google Scholar]
- Efthimiou, E.; Fotinea, S.-E.; Sapountzaki, G. Feature-based natural language processing for GSL synthesis. Sign Lang. Linguist. 2007, 10, 3–23. [Google Scholar] [CrossRef]
- Fotinea, S.E.; Efthimiou, E.; Caridakis, G.; Karpouzis, K. A knowledge-based sign synthesis architecture. Univers. Access Inf. Soc. 2008, 6, 405–418. [Google Scholar] [CrossRef]
- San-Segundo, R.; Barra, R.; Córdoba, R.; D’Haro, L.F.; Fernández, F.; Ferreiros, J.; Lucas, J.M.; Macías-Guarasa, J.; Montero, J.M.; Pardo, J.M. Speech to sign language translation system for Spanish. Speech Commun. 2008, 50, 1009–1020. [Google Scholar] [CrossRef]
- San-Segundo, R.; Montero, J.M.; Macías-Guarasa, J.; Córdoba, R.; Ferreiros, J.; Pardo, J.M. Proposing a speech to gesture translation architecture for Spanish deaf people. J. Vis. Lang. Comput. 2008, 19, 523–538. [Google Scholar] [CrossRef]
- Baldassarri, S.; Cerezo, E.; Royo-Santas, F. Automatic translation system to Spanish sign language with a virtual interpreter. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5726, pp. 196–199. [Google Scholar] [CrossRef]
- Anuja, K.; Suryapriya, S.; Idicula, S.M. Design and development of a frame based MT system for English-to-ISL. In Proceedings of the 2009 World Congress on Nature and Biologically Inspired Computing (NABIC 2009), Coimbatore, India, 9–11 December 2009; pp. 1382–1387. [Google Scholar] [CrossRef]
- Delorme, M.; Filhol, M.; Braffort, A. Animation generation process for sign language synthesis. In Proceedings of the 2nd International Conferences on Advances in Computer-Human Interactions (ACHI 2009), Cancun, Mexico, 1–7 February 2009; pp. 386–390. [Google Scholar] [CrossRef]
- San-Segundo, R.; López, V.; Martín, R.; Lufti, S.; Ferreiros, J.; Córdoba, R.; Pardo, J.M. Advanced Speech communication system for deaf people. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Lombardo, V.; Battaglino, C.; Damiano, R.; Nunnari, F. An avatar-based interface for the Italian sign language. In Proceedings of the International Conference on Complex, Intelligent and Software Intensive Systems (CISIS 2011), Seoul, Republic of Korea, 30 June–2 July 2011; pp. 589–594. [Google Scholar] [CrossRef]
- Gibet, S.; Courty, N.; Duarte, K.; Le Naour, T. The SignCom system for data-driven animation of interactive virtual signers. ACM Trans. Interact. Intell. Syst. 2011, 1, 1–23. [Google Scholar] [CrossRef]
- López-Colino, F.; Colás, J. Hybrid paradigm for Spanish Sign Language synthesis. Univers. Access Inf. Soc. 2012, 11, 151–168. [Google Scholar] [CrossRef]
- De Araújo, T.M.U.; Ferreira, F.L.S.; dos Santos Silva, D.A.N.; Lemos, F.H.; Neto, G.P.; Omaia, D.; de Souza Filho, G.L.; Tavares, T.A. Automatic generation of Brazilian sign language windows for digital TV systems. J. Braz. Comput. Soc. 2013, 19, 107–125. [Google Scholar] [CrossRef]
- Vera, L.; Coma, I.; Campos, J.; Martínez, B.; Fernández, M. Virtual Avatars Signing in Real Time for Deaf Students. In Proceedings of the International Conference on Computer Graphics Theory and Applications and International Conference on Information Visualization Theory and Applications (GRAPP-2013), Barcelona, Spain, 21–24 February 2013; pp. 261–266. [Google Scholar]
- Bouzid, Y.; El Ghoul, O.; Jemni, M. Synthesizing facial expressions for signing avatars using MPEG4 feature points. In Proceedings of the 2013 4th International Conference on Information and Communication Technology and Accessibility (ICTA 2013), Hammamet, Tunisia, 24–26 October 2013. [Google Scholar] [CrossRef]
- Morrissey, S.; Way, A. Manual labour: Tackling machine translation for sign languages. Mach. Transl. 2013, 27, 25–64. [Google Scholar] [CrossRef]
- Brega, J.R.F.; Rodello, I.A.; Dias, D.R.C.; Martins, V.F.; De Paiva Guimarães, M. A virtual reality environment to support chat rooms for hearing impaired and to teach Brazilian Sign Language (LIBRAS). Proceedings of IEEE/ACS International Conference on Computer Systems and Applications (AICCSA), Doha, Qatar, 10–13 November 2014; Volume 2014, pp. 433–440. [Google Scholar] [CrossRef]
- Del Puy Carretero, M.; Urteaga, M.; Ardanza, A.; Eizagirre, M.; García, S.; Oyarzun, D. Providing Accessibility to Hearing-disabled by a Basque to Sign Language Translation System. In Proceedings of the International Conference on Agents and Artificial Intelligence, Angers, France, 6–8 March 2014; pp. 256–263. [Google Scholar]
- Almeida, I.; Coheur, L.; Candeias, S. Coupling natural language processing and animation synthesis in Portuguese sign language translation. In Proceedings of the Fourth Workshop on Vision and Language, Lisbon, Portugal, 18 September 2015; pp. 94–103. [Google Scholar]
- Ebling, S.; Wolfe, R.; Schnepp, J.; Baowidan, S.; McDonald, J.; Moncrief, R.; Sidler-Miserez, S.; Tissi, K. Synthesizing the finger alphabet of Swiss German Sign Language and evaluating the comprehensibility of the resulting animations. In Proceedings of the SLPAT 2015: 6th Workshop on Speech and Language Processing for Assistive Technologies, Dresden, Germany, 11 September 2015; pp. 10–16. [Google Scholar]
- Ebling, S.; Glauert, J. Building a Swiss German Sign Language avatar with JASigning and evaluating it among the Deaf community. Univers. Access Inf. Soc. 2016, 15, 577–587. [Google Scholar] [CrossRef]
- Efthimiou, E.; Fotinea, S.E.; Dimou, A.L.; Goulas, T.; Kouremenos, D. From grammar-based MT to post-processed SL representations. Univers. Access Inf. Soc. 2015, 15, 499–511. [Google Scholar] [CrossRef]
- Heloir, A.; Nunnari, F. Toward an intuitive sign language animation authoring system for the deaf. Univers. Access Inf. Soc. 2016, 15, 513–523. [Google Scholar] [CrossRef]
- Ebling, S.; Johnson, S.; Wolfe, R.; Moncrief, R.; McDonald, J.; Baowidan, S.; Haug, T.; Sidler-Miserez, S.; Tissi, K. Evaluation of animated Swiss German sign language fingerspelling sequences and signs. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2017; Volume 10278, pp. 3–13. [Google Scholar] [CrossRef]
- Punchimudiyanse, M.; Meegama, R.G.N. Animation of fingerspelled words and number signs of the Sinhala Sign language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2017, 16, 2743. [Google Scholar] [CrossRef]
- De Martino, J.M.; Silva, I.R.; Bolognini, C.Z.; Costa, P.D.P.; Kumada, K.M.O.; Coradine, L.C.; da Silva Brito, P.H.; Amaral, W.M.D.; Benetti, B.; Poeta, E.T.; et al. Signing avatars: Making education more inclusive. Univers. Access Inf. Soc. 2017, 16, 793–808. [Google Scholar] [CrossRef]
- Quandt, L. Teaching ASL Signs using Signing Avatars and Immersive Learning in Virtual Reality. In Proceedings of the ASSETS 2020—22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual Event, Greece, 26–28 October 2020. [Google Scholar] [CrossRef]
- Sugandhi; Kumar, P.; Kaur, S. Sign Language Generation System Based on Indian Sign Language Grammar. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2020, 19, 1–26. [Google Scholar] [CrossRef]
- Das Chakladar, D.; Kumar, P.; Mandal, S.; Roy, P.P.; Iwamura, M.; Kim, B.G. 3D Avatar Approach for Continuous Sign Movement Using Speech/Text. Appl. Sci. 2021, 11, 3439. [Google Scholar] [CrossRef]
- Nguyen, L.T.; Schicktanz, F.; Stankowski, A.; Avramidis, E. Automatic generation of a 3D sign language avatar on AR glasses given 2D videos of human signers. In Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (AT4SSL), Virtual, 20 August 2021; Association for Machine Translation in the Americas: Cambridge, MA, USA, 2021; pp. 71–81. Available online: https://aclanthology.org/2021.mtsummit-at4ssl.8 (accessed on 10 August 2023).
- Krishna, S. SignPose: Sign Language Animation Through 3D Pose Lifting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, QC, Canada, 11–17 October 2021; pp. 2640–2649. [Google Scholar]
- Dhanjal, A.S.; Singh, W. An automatic machine translation system for multi-lingual speech to Indian sign language. Multimed. Tools Appl. 2022, 81, 4283–4321. [Google Scholar] [CrossRef]
- Yang, F.C.; Mousas, C.; Adamo, N. Holographic sign language avatar interpreter: A user interaction study in a mixed reality classroom. Comput. Animat. Virtual Worlds 2022, 33, e2082. [Google Scholar] [CrossRef]
- Partarakis, N.; Zabulis, X.; Foukarakis, M.; Moutsaki, M.; Zidianakis, E.; Patakos, A.; Adami, I.; Kaplanidi, D.; Ringas, C.; Tasiopoulou, E. Supporting Sign Language Narrations in the Museum. Heritage 2022, 5, 1. [Google Scholar] [CrossRef]
- Van Gemert, B.; Cokart, R.; Esselink, L.; De Meulder, M.; Sijm, N.; Roelofsen, F. First Steps Towards a Signing Avatar for Railway Travel Announcements in the Netherlands. In Proceedings of the 7th International Workshop on Sign Language Translation and Avatar Technology: The Junction of the Visual and the Textual: Challenges and Perspectives, Marseille, France, 24 June 2022; European Language Resources Association: Marseille, France, 2022; pp. 109–116. Available online: https://aclanthology.org/2022.sltat-1.17 (accessed on 3 September 2023).
- Kim, J.-H.; Hwang, E.J.; Cho, S.; Lee, D.H.; Park, J. Sign Language Production with Avatar Layering: A Critical Use Case over Rare Words. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; European Language Resources Association: Marseille, France, 2022; pp. 1519–1528. Available online: https://aclanthology.org/2022.lrec-1.163 (accessed on 3 September 2023).
- El Ghoul, O.; Othman, A. Virtual reality for educating Sign Language using signing avatar: The future of creative learning for deaf students. In Proceedings of the IEEE Global Engineering Education Conference (EDUCON), Tunis, Tunisia, 28–31 March 2022; pp. 1269–1274. [Google Scholar] [CrossRef]
- Sanaullah, M.; Ahmad, B.; Kashif, M.; Safdar, T.; Hassan, M.; Hasan, M.H.; Aziz, N. A real-time automatic translation of text to sign language. Comput. Mater. Contin. 2022, 70, 2471–2488. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. Visualizing Bibliometric Networks. In Measuring Scholarly Impact; Springer: Cham, Switzerland, 2014; pp. 285–320. [Google Scholar] [CrossRef]
- IBM Watson. Text to Speech. Available online: https://www.ibm.com/products/text-to-speech (accessed on 20 August 2023).
- NLTK. Natural Language Toolkit. NLTK Project. Available online: https://www.nltk.org/ (accessed on 20 August 2023).
- Maya Software. Available online: https://www.autodesk.ae/products/maya/overview?term=1-YEAR&tab=subscription&plc=MAYA (accessed on 20 August 2023).
- Poser. 3D Rendering & Animation Software. Available online: https://www.posersoftware.com/ (accessed on 20 August 2023).
- 3ds Max Software. Available online: https://www.autodesk.ae/products/3ds-max/overview?term=1-YEAR&tab=subscription&plc=3DSMAX (accessed on 20 August 2023).
- Blender. Blender—Free and Open 3D Creation Software. Available online: https://www.blender.org/ (accessed on 16 August 2023).
- Available online: http://www.makehumancommunity.org/ (accessed on 20 August 2023).
- Daz 3D. 3D Models and 3D Software. Available online: https://www.daz3d.com/ (accessed on 20 August 2023).
- Autodesk. MotionBuilder Software. Available online: https://www.autodesk.com/products/motionbuilder/overview?term=1-YEAR&tab=subscription&plc=MOBPRO (accessed on 20 August 2023).
- IDGS: Universität Hamburg. Available online: https://www.idgs.uni-hamburg.de/ (accessed on 20 August 2023).
- University of East Anglia. JASigning—Virtual Humans. Available online: https://vh.cmp.uea.ac.uk/index.php/JASigning (accessed on 20 August 2023).
- Huang, Z.; Eliëns, A.; Visser, C. STEP: A Scripting Language for Embodied Agents. In Life-Like Characters: Tools, Affective Functions, and Applications; Springer: Berlin/Heidelberg, Germany, 2004; pp. 87–109. [Google Scholar] [CrossRef]
- Baldassarri, S.; Cerezo, E.; Seron, F.J. Maxine: A platform for embodied animated agents. Comput. Graph. 2008, 32, 430–437. [Google Scholar] [CrossRef]
- Heloir, A.; Kipp, M. EMBR—A realtime animation engine for interactive embodied agents. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5773, pp. 393–404. [Google Scholar] [CrossRef]
- Matthes, S.; Hanke, T.; Regen, A.; Storz, J.; Worseck, S.; Efthimiou, E.; Dimou, A.L.; Braffort, A.; Glauert, J.; Safar, E. Dicta-sign-building a multilingual sign language corpus. In Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon. Satellite Workshop to the Eighth International Conference on Language Resources and Evaluation (LREC), Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS Spoken Language Systems Pilot Corpus. In Speech and Natural Language: Proceedings of the Workshop Held at Hidden Valley, Jefferson Township, PA, USA, 24–27 June 1990; Morgan Kaufmann Publishers, Inc.: San Mateo, CA, USA, 1990; Available online: https://aclanthology.org/H90-1021 (accessed on 3 September 2023).
- DFKI. The MARY Text-to-Speech System (MaryTTS). Available online: http://mary.dfki.de/ (accessed on 16 August 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Paper is on SL Avatar systems | Duplicate studies found in multiple databases |
| Paper is published between the years 1982 and 2022 | Full paper is not available |
| Paper is written in English | Paper is shorter than 4 pages. |
| Paper has full-text availability in the information sources | Paper is purely theoretical/adds to background only |
| Paper directly answers one or more of the research questions |
| Database | Link |
|---|---|
| ACM Digital Library | https://dl.acm.org/ (accessed on 2 February 2023) |
| Google Scholar | https://scholar.google.com/ (accessed on 2 February 2023) |
| IEEEXplore | https://ieeexplore.ieee.org/Xplore/home.jsp (accessed on 2 February 2023) |
| Scopus | https://www.scopus.com/ (accessed on 2 February 2023) |
| Springer Link | https://link.springer.com/ (accessed on 2 February 2023) |
| ScienceDirect | https://www.sciencedirect.com/ (accessed on 2 February 2023) |
| Category 1 | Category 2 |
|---|---|
| Avatar | Signing |
| Virtual | Sign language |
| Computer animations of humans | Signers |
| Online Database | Search String | Filters |
|---|---|---|
| ACM Digital Library | (“avatar*” OR “virtual” OR “computer animations of humans”) AND (“sign language*” OR “signer*” OR “signing”) |
|
| Google Scholar | allintitle:((“avatar*” OR “virtual” OR “computer animation of humans”) AND (“sign language*” OR “signing” OR “signer*”)) |
|
| IEEEXplore | ((“avatar*” OR “virtual” OR “computer animations of humans”) AND (“sign language*” OR “signer*” OR “signing”)) |
|
| Scopus | TITLE-ABS-KEY ((“avatar*” OR “virtual” OR „computer animation of humans”) AND (“sign language” OR “signing” OR “signer”)) AND PUBYEAR > 1981 AND PUBYEAR < 2023 AND (LIMIT-TO (DOCTYPE, “cp”) OR LIMIT-TO (DOCTYPE, “ar”)) |
|
| SpringerLink | “Sign language avatar” OR “signing avatar” OR “virtual signer” OR “computer animation of humans” |
using the key string with cat 1 and cat 2 resulted in 10 k+ results |
| ScienceDirect | ((“avatar” OR “virtual” OR “computer animations of humans”) AND (“sign language” OR “signer” OR “signing”)) |
|
| Ref. | Title | Year | Publication Venue | Cities | Avatar |
|---|---|---|---|---|---|
| [41] | Development of a legible deaf-signing virtual human | 1999 | conference | 1 |  Simon |
| [42] | Generation of signed sentences by an avatar from their textual description | 2002 | conference | 1 |  |
| [43] | TESSA, a system to aid communication with deaf people | 2002 | conference | 2 |  TESSA |
| [44] | A Real-Time Interactive Nonverbal Communication System through Semantic Feature Extraction as an Interlingua | 2004 | journal | 1 |  |
| [45] | Sign synthesis from SignWriting notation using MPEG-4, H-Anim, and inverse kinematics techniques | 2005 | journal | 1 | -- |
| [46] | An Immersive Virtual Environment for Learning Sign Language Mathematics | 2006 | conference | 1 |  MathSigner |
| [47] | A Spanish speech to sign language translation system for assisting deaf-mute people | 2006 | conference | 1 |  |
| [48] | The development of a generic signing avatar | 2007 | conference | 1 | -- |
| [22] | Providing signed content on the Internet by synthesized animation | 2007 | journal | 2 |  |
| [49] | Feature-based natural language processing for GSL synthesis | 2007 | journal | 2 |  |
| [50] Extension of [49] | A knowledge-based sign synthesis architecture | 2008 | journal | 1 | -- |
| [51] | Speech to sign language translation system for Spanish | 2008 | journal | 2 | Identical to [47] |
| [52] | Proposing a speech to gesture translation architecture for Spanish deaf people | 2008 | journal | 1 | Identical to [47] |
| [53] | Automatic Translation System to Spanish Sign Language with a Virtual Interpreter | 2009 | conference | 1 |  |
| [54] | Design and development of a frame based MT system for english-to-ISL | 2009 | conference | 1 | -- |
| [55] | Animation generation process for sign language synthesis | 2009 | conference | 1 |  |
| [56] | Advanced speech communication system for deaf people | 2010 | conference | 1 | Identical to [47] |
| [11] | Sign Language Avatars: Animation and Comprehensibility | 2011 | conference | 1 |  |
| [57] | An avatar-based interface for the Italian sign language | 2011 | conference | 1 | -- |
| [58] | The SignCom system for data-driven animation of interactive virtual signers: Methodology and evaluation | 2011 | journal | 1 |  |
| [59] | Hybrid paradigm for Spanish Sign Language synthesis | 2012 | journal | 1 |  Yuli |
| [60] | Automatic generation of Brazilian sign language windows for digital TV systems | 2013 | journal | 1 |  |
| [61] | Virtual avatars signing in real time for deaf students | 2013 | conference | 1 |  |
| [62] | Synthesizing facial expressions for signing avatars using MPEG4 feature points | 2013 | conference | 1 | -- |
| [63] | Manual labour: tackling machine translation for sign languages | 2013 | journal | 2 |  |
| [64] | A virtual reality environment to support chat rooms for hearing impaired and to teach Brazilian Sign Language (LIBRAS) | 2014 | conference | 4 |  |
| [65] | Providing accessibility to hearing-disabled by a basque to sign language translation system | 2014 | conference | 1 |  |
| [66] | Coupling Natural Language Processing and Animation Synthesis in Portuguese Sign Language Translation | 2015 | conference | 1 |  |
| [67] | Synthesizing the finger alphabet of swiss german sign language and evaluating the comprehensibility of the resulting animations | 2015 | conference | 3 |  |
| [68] | Building a Swiss German Sign Language avatar with JASigning and evaluating it among the Deaf community | 2016 | journal | 2 |  Anna |
| [69] | From grammar-based MT to post-processed SL representations | 2016 | journal | 1 | Identical to [68] |
| [70] | Toward an intuitive sign language animation authoring system for the deaf | 2016 | journal | 2 |  |
| [71] | Evaluation of Animated Swiss German Sign Language Fingerspelling Sequences and Signs | 2017 | conference | 2 | |
| [72] | Animation of fingerspelled words and number signs of the Sinhala Sign language | 2017 | journal | 1 |  |
| [73] | Signing avatars: making education more inclusive | 2017 | journal | 2 |  |
| [74] | Teaching ASL Signs Using Signing Avatars and Immersive Learning in Virtual Reality | 2020 | conference | 1 |  |
| [75] | Sign Language Generation System Based on Indian Sign Language Grammar | 2020 | journal | 1 |  |
| [76] | 3d avatar approach for continuous sign movement using speech/text | 2021 | journal | 3 |  |
| [77] | Automatic generation of a 3D sign language avatar on AR glasses given 2D videos of human signers | 2021 | conference | 1 |  |
| [78] | SignPose: Sign Language Animation Through 3D Pose Lifting | 2021 | conference | 1 |  |
| [79] | An automatic machine translation system for multi-lingual speech to Indian sign language | 2022 | journal | 1 |  |
| [80] | Holographic sign language avatar interpreter: A user interaction study in a mixed reality classroom | 2022 | journal | 1 |  |
| [81] | Supporting sign language narrations in the museum | 2022 | journal | 2 |  |
| [82] | First Steps Towards a Signing Avatar for Railway Travel Announcements in the Netherlands | 2022 | conference | 4 |  |
| [83] | Sign Language Production With Avatar Layering: A Critical Use Case over Rare Words | 2022 | conference | 2 |  |
| [84] | Virtual reality for educating Sign Language using signing avatar: The future of creative learning for deaf students | 2022 | conference | 1 |  BuHamad |
| [85] | A real-time automatic translation of text to sign language | 2022 | journal | 3 |  Marc |
| Metrics | Data |
|---|---|
| Publication years | 1982–2022 |
| Citation years | 40 |
| Papers | 47 |
| Citations | 783 |
| Average citations per year | 19.6 |
| Average citations per paper | 16.7 |
| Authors | 209 |
| Keywords | 150 |
| Countries | 21 |
| Authors per document | 4.4 |
| Documents per authors | 0.22 |
| Keyword | Occurrences | Percentage (%) |
|---|---|---|
| Sign language | 10 | 12 |
| Machine translation | 6 | 7 |
| Animation | 5 | 6 |
| Virtual reality | 4 | 5 |
| Sign language synthesis | 4 | 5 |
| Signing avatars | 4 | 5 |
| HamNoSys | 3 | 4 |
| Avatars | 3 | 4 |
| Deaf people | 3 | 4 |
| Spanish sign language | 3 | 4 |
| Virtual characters | 3 | 4 |
| Spanish sign language (LSE) | 3 | 4 |
| Brazilian sign language | 2 | 2 |
| Focus group | 2 | 2 |
| Indian sign language | 2 | 2 |
| Natural language processing | 2 | 2 |
| Sign languages | 2 | 2 |
| Signing avatar | 2 | 2 |
| Speech recognition | 2 | 2 |
| Speech to gesture translation | 2 | 2 |
| Spoken language translation | 2 | 2 |
| Virtual humans | 2 | 2 |
| Avatars | 2 | 2 |
| Deaf accessibility | 2 | 2 |
| 3D signing avatar | 2 | 2 |
| Indian sign language (ISL) | 2 | 2 |
| Sign language animation | 2 | 2 |
| Affiliation | Frequency |
|---|---|
| University of East Anglia | 5 |
| Purdue University | 2 |
| Universidad Politécnica de Madrid | 2 |
| Institute for Language and Speech Processing | 2 |
| University of Zurich | 2 |
| DePaul University | 2 |
| Ref. | Sign Synthesis Techniques |
|---|---|
| [41] | The paper utilized an elision component (Eliser) for language processing and providing sign streams to the avatar to sign. The Eliser component resolved lexical ambiguities and modified the input stream to a sign stream that can be easily signed. |
| [42] | The prototype takes an input sentence and divides it into two levels, lexical and grammatical levels. In the lexical level, the signs are represented by a set of formational components, and at the grammatical level, the signs are encoded using the sign dictionary. The encoded sentence is then sent to the animation to sign the sentence. |
| [43] | The proposed system in the paper used a speech recognizer to interpret speech which is then synthesized into the appropriate sequence of signs using an avatar. The recognizer is adapted to each user’s voice and stored. The system utilizes a phrase lookup approach for language translation. |
| [44] | The system takes as an input a natural language sentence. Each word in the sentence is translated into a set of action parameters. The action parameters are based on a sign language notation developed by the authors and based on the hand shape, hand location, and hand movement. The parameters are then transferred, decoded, and the animation of the avatar is generated using the relevant parameters. |
| [45] | The author proposed a sign synthesis system that takes the SignWriting notation as an input and converts it into MPEG-4 face and body animation parameters. |
| [47] | The sign synthesis system involves an HMM-based speech recognizer that converts natural speech into a sequence of words using acoustic and language models. The word sequence is then converted into a SiGML notation through the natural language translation module that consists of a rule-based translation strategy. The output of the system is a gesture sequence that describes the natural speech input. |
| [48] | The system consisted of three main modules; the first module known as the parser took an input of XML notation and converted it to an animation queue. The animation queue, containing animation sequences to be performed, is sent to the animator module that uses FIFO queue along with the avatar model definitions to build detailed animations containing joint data. These data are then sent to the final module in the system known as the renderer module that then renders the model on a 3D signing avatar. |
| [22] | The sign synthesis method utilized involves representing signing as a sequence of glosses. Sequences of glosses are constructed using a tool, and the SiGML script for a sequence is then extracted and embedded in a webpage using JavaScript. |
| [49] | The SL synthesis involved breaking down the phonological structure of GSL signs into features representing essential elements such as handshape, location, movement, and palm orientation. A library of sign notation features and linguistic principles were converted into motion parameters for a virtual avatar. Written Greek input was processed using a statistical parser, and the chunks were mapped onto GSL structures to generate sign string patterns. |
| [51] | The methods used for SL synthesis in the system were twofold. The first approach employs a rule-based translation strategy, wherein a set of translation rules, defined by an expert, guides the translation process. The second alternative relies on a statistical translation approach, utilizing parallel corpora for training language and translation models. These methods enable the conversion of spoken language into sign sequences, which are then animated using the eSIGN 3D avatar. |
| [52] | The methods used for SL synthesis in the paper involved four modules. The first module of speech recognition converted speech utterances into text words using IBM Via Voice software adapted to Spanish pronunciation. The second module of semantic analysis evaluated the text sentence and extracted the main concepts. The third module of gesture sequence generation processed semantic analysis output and assigned gestures to semantic concepts. Finally, the fourth module used an animated agent to represent sign language gestures. |
| [53] | The sign synthesis system involves morphosyntactic analysis that extracts morphological information and syntactical dependencies from the input phrase. The grammatical transformation generates glosses based on syntactic information and mood. The morphological transformation corrects glosses that may not directly correlate to LSE terms. Finally, the sign generation module translates appropriate glosses into a representation format for generating animations. |
| [54] | The methods used for SL synthesis included speech recognition, language processing, and 3D animation. The speech recognition module converts the clerk’s English speech into text. The language processing module involves various steps like input text parsing, eliminator, stemmer, and phrase reordering and ISL gloss generation to generate an ISL equivalent sentence. Finally, the 3D animation module creates animations from motion captured data for the virtual human character. |
| [55] | The paper discussed using a four-step process for the SL synthesis of the proposed system. First, signs are divided into postures and transitions, breaking down postures into kinematic chains, and processing each chain independently. Second, using inverse kinematics methods, postures are computed and merged for the avatar skeleton’s configuration. Third, interpolation is applied between postures to create smooth transitions. Finally, the data are converted to a suitable format for use in animation. |
| [56] | The SL synthesis system involved converting natural speech into text output using an HMM-based continuous speech recognition system. The text is then translated into sign sequence using example-based and rule-based approaches. Lastly, the signs are then represented on the SL avatar. |
| [11] | The synthesis process utilized the EMBRScript notation. The process used a gloss-based approach which involved the creation of a database of single gloss animations based on human signer videos, which were used to assemble utterances. The process included the use of the OpenMARY text-to-speech synthesis system to generate viseme. |
| [57] | The methods used for SL synthesis in the ATLAS project involve a symbolic representation of sign language input, known as the AEWLIS structure, which includes lemmas, syntactic information, and the corresponding signs. An animation system was used to generate real-time animation of the virtual interpreter based on the linguistic input. |
| [58] | The methods used for SL synthesis involve a data-driven animation system. The system combines motion elements retrieved from semantic and raw databases and employs multichannel composition to create comprehensible signed language sequences. The sequences are then sent to the animation and the rendering engine computes the final avatar image. |
| [59] | The SL synthesis process utilized the new input notation, HLSML, which allows the simple tagging of words or glosses for dictionary signs, along with options for defining sentence timing, sign dialect, and mood variations. |
| [60] | The authors used a text-to-gloss machine translation strategy based on specific transfer rules for converting text into sign language. The translation process includes tokenization, morphological-syntactic classification, lexical replacements, and dactylology replacement for proper names and technical terms. LIBRAS dictionaries are also used to store pre-rendered visual representations of signs, avoiding real-time sign rendering, and minimizing computational resources. |
| [61] | The sign synthesis system involves converting speech to text using a speech recognizer and converting PowerPoint presentation to text. The converted text is then adapted into sign language. The authors used two methods to achieve the translation from text to sign language, the rule-based method and the analogy method. The analogy method consists of searching for coincidences with pre-recorded sentences in the dictionary. The output of the module is sent to the avatar system module that then animates the virtual avatar. |
| [63] | The approach adopted by the authors involved using a MaTrEx machine translation engine. The process included aligning bilingual data, segmenting these data into words, matching source words to target words, and using a decoder to generate translations based on phrase alignments. |
| [64] | The machine translation system tokenized and classified input text into grammatical categories. Relevant tokens were translated into signs, while unfamiliar content triggered a fingerspelling system. This approach enabled generating sign language representations from Portuguese text. |
| [65] | The authors proposed a rule-based Machine Translation approach to automatically translate domain-specific content in Basque to LSE. The translation process involved linguistic analysis of the application domain, text pre-processing to reconstruct sentences, and sentence translation. The output generated a sequence of signs that followed LSE grammar and syntax. |
| [66] | The methods used for SL synthesis involved employing a gloss-based approach where words are saved with their corresponding glosses. The gloss order is calculated based on the structure transfer rules. Glosses are then converted into gestures based on the separate actions that compose it. The avatar is then animated given these individual actions. |
| [67] | The authors employed a process that included generating hand postures for each letter of the alphabet and transitions between letter pairs. The synthesis is based on similarities with the ASL manual alphabet, with modifications made to accommodate unique DSGS hand shapes. Collisions between fingers during hand shape transitions are addressed through the insertion of transition hand shapes to create necessary clearance. |
| [68] | The authors used the JASigning system that employed HamNoSys and its XML representation, SiGML. SiGML represented sign language elements including hand shape, position, location, and movement, as well as non-manual features like mouthing and gestures. SiGML was then transformed into motion data by an animation engine. |
| [69] | The SL synthesis method in the system included a rule-based approach with logical mapping rules for structure matching between the source and target languages. The system utilized linguistic resources, such as morphological lexicons, for accurate rule application. It offered two output forms, structured sign lemmas and HamNoSys coding for avatar presentation, alongside user-friendly GUI tools for post-processing. |
| [72] | The system converted Sinhala text into phonetic English using a VB.NET application and then fed these data to the Blender animation software. It compiled a sequence of sign gesture animations for characters, mathematically calculating transitional posture positions to ensure smooth animations. |
| [73] | The system utilized a two-module approach for SL synthesis. First, the Translation Module receives Brazilian Portuguese text and analyzes it based on rules and translation memory to create an Intermediary Language representation. This representation serves as an input for the second module, the Animation Module, which maps symbols from the Intermediary Language to signs in LIBRAS. The signs in the Animation Module are stored using a parametric description describing the sign movements and sequences. The synthesized output drives the signing avatar by concatenating the sequence of signs. |
| [75] | The methods used for SL synthesis involve converting English text into root words with associated morphological information. ISL rules based on ISL grammar are implemented for each input sentence, determining word order. The system retrieves corresponding HamNoSys symbols from a database for each root word. HamNoSys codes are then converted to SiGML representation, and the 3D avatar is animated accordingly. |
| [76] | The methods used for SL synthesis involve a combination of speech recognition and script generation techniques. The “IBM-Watson speech to text” service [87] is utilized to convert English audio recordings into text. The audio files are processed to yield corresponding text outputs. For SL synthesis, the Natural Language Toolkit [88] is employed to convert English sentences into ISL. A script generator then creates a script that generates an ISL sentence and a sequence tree, associating different gestures with avatar movements to maintain the order of motion for the avatar model. |
| [77] | The SL synthesis method utilized motion capture technology that extracts gestures and facial expressions from video frames signed by a professional interpreter. The extracted information is then transferred to an avatar’s skeleton using rotation vectors. |
| [78] | The method for SL synthesis involves using an image of sign language performance to generate a 3D pose for a human avatar. It starts with running a 2D pose estimation model on the performance image to obtain 2D key points. A model then converts these 2D key points into 3D poses, with separate models for the hands and body. The resulting 3D pose is compatible with the avatar used for animation. |
| [79] | The SL synthesis is achieved using the HamNoSys notation system, where textual HamNoSys scripts are generated and converted into the SiGML format. The JASigning application takes SiGML scripts as the input and generates 3D synthetic sign gestures using a virtual human avatar. |
| [81] | The paper also utilized mocap technology that captures full-body and hand gestures. These gestures were then mapped on an SL avatar model, with an emphasis on facial animation using a blend-shape system. For the text to be signed for mocap, Cultural Heritage (CH) professionals created a narrative based on research methods like archival research, ethnography, interviews, etc. Sign language translators then reviewed and optimized the narration text for sign language, including simplification and specialized CH term translation. |
| [82] | The method for SL synthesis involved developing a signing avatar system using the JASigning avatar engine, utilizing SiGML representations to generate avatar animation. The study obtained railway announcement templates and their Dutch Sign Language (NGT) translations. The signing avatar mimics NGT translations closely, allowing for the creation of multiple variations of announcement templates. |
| [83] | Initially, a Sign Language Translation (SLT) model generates Korean Sign Language (KSL) translations from input Korean text. Subsequently, this translation is structured into an animation data packet. Lastly, the animation player uses this data packet to generate a comprehensive sign language animation by layering avatars. |
| [85] | In Sign4PSL, the user inputs a sentence, which undergoes stemming and lemmatization, and is then converted into a sequence of PSL words. The system then accesses the knowledge base and adds available signs to the sequence. The PSL signs are converted into SiGML using HamNoSys Notation, which is then used to animate the SL avatar. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aziz, M.; Othman, A. Evolution and Trends in Sign Language Avatar Systems: Unveiling a 40-Year Journey via Systematic Review. Multimodal Technol. Interact. 2023, 7, 97. https://doi.org/10.3390/mti7100097
Aziz M, Othman A. Evolution and Trends in Sign Language Avatar Systems: Unveiling a 40-Year Journey via Systematic Review. Multimodal Technologies and Interaction. 2023; 7(10):97. https://doi.org/10.3390/mti7100097
Chicago/Turabian StyleAziz, Maryam, and Achraf Othman. 2023. "Evolution and Trends in Sign Language Avatar Systems: Unveiling a 40-Year Journey via Systematic Review" Multimodal Technologies and Interaction 7, no. 10: 97. https://doi.org/10.3390/mti7100097
APA StyleAziz, M., & Othman, A. (2023). Evolution and Trends in Sign Language Avatar Systems: Unveiling a 40-Year Journey via Systematic Review. Multimodal Technologies and Interaction, 7(10), 97. https://doi.org/10.3390/mti7100097