
Sharing Cultural Heritage—The Case of the Lodovico Media Library


Abstract
:1. Introduction
2. A Cross-Institutional and Multitenant Media Library: Birth of a Project
2.1. A Universal Library: The Legacy of Lodovico Antonio Muratori
2.2. Gathering Cultural Institutions
2.3. The Pilot Case
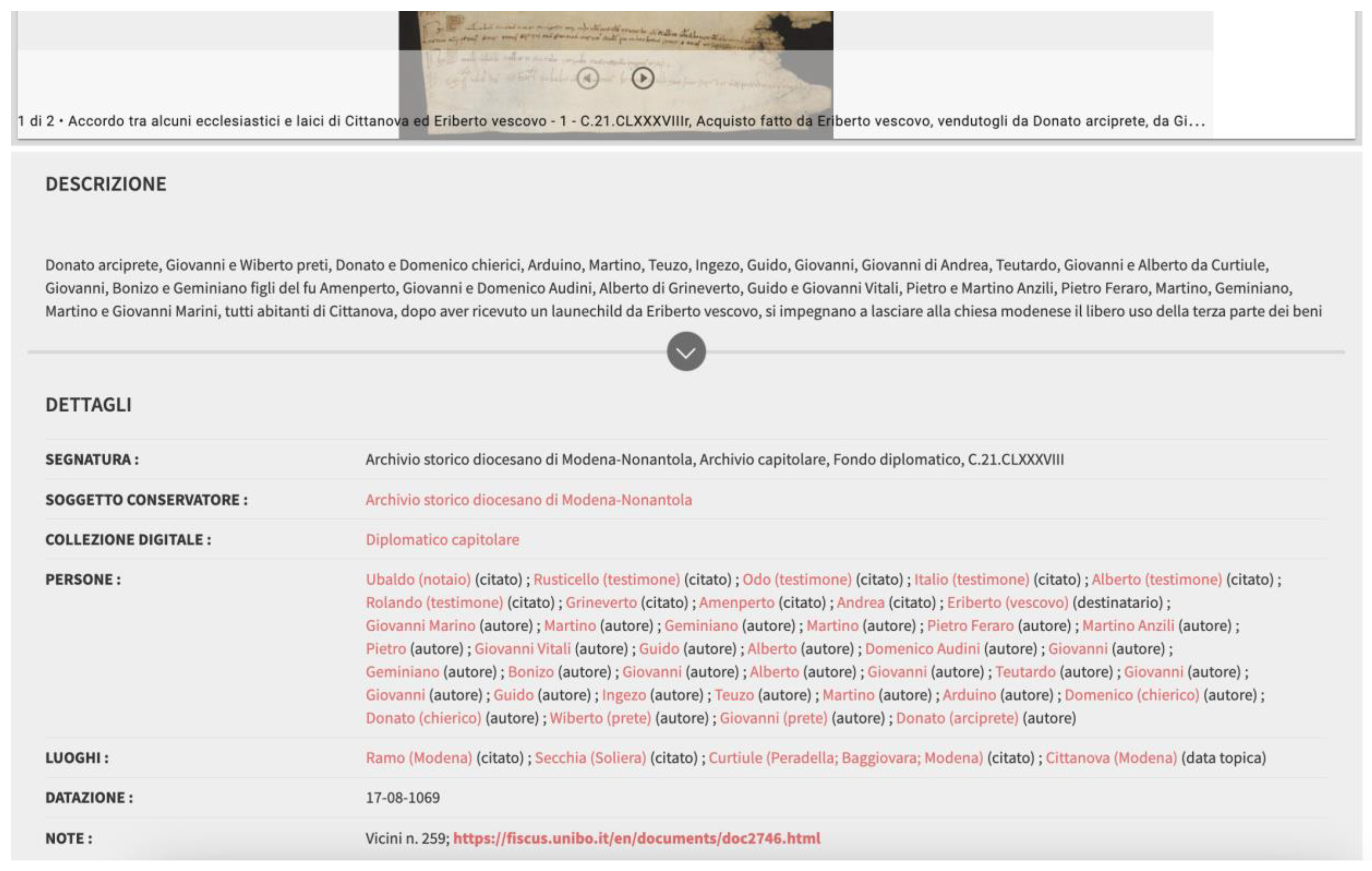
3. Cross-Typological Metadata for a Non-Specialist Public
3.1. Metadata Structure
3.2. A User-Friendly Medialibrary
3.3. Collecting and Producing Data
4. New Frontiers of Experimentation
4.1. Analysis of the Visual Characteristics
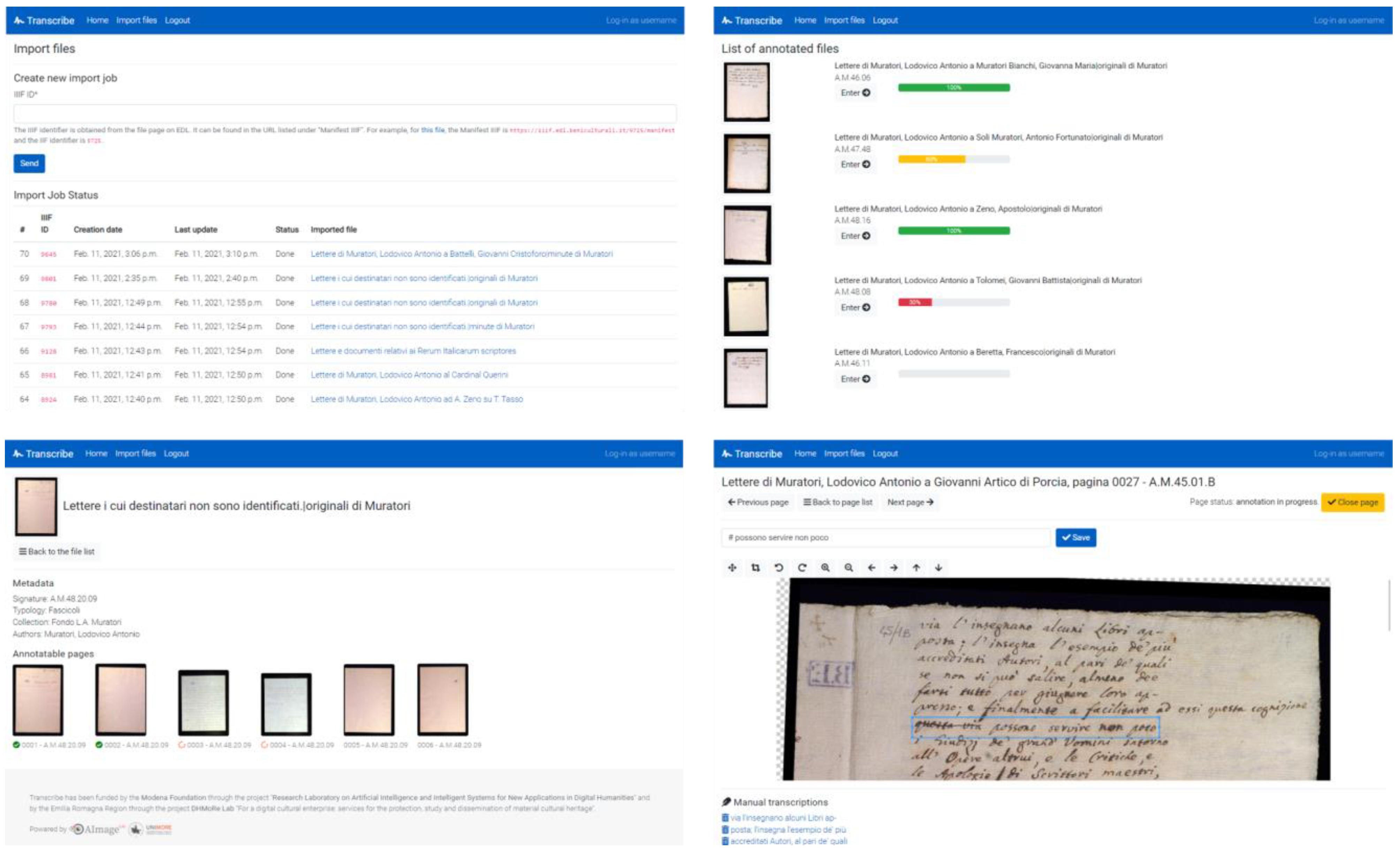
4.2. Data Annotation Strategy
4.3. A Short Background on Handwritten Text Recognition
4.4. HTR Algorithms Developed for Lodovico
5. Final Remarks
- -
- a common and potentially interoperable data architecture (based on the Dublin Core standard);
- -
- a metadata standardisation method shared by all partners;
- -
- the overcoming of barriers concerning the various types of cultural heritage (towards a cross-typological media library).
Author Contributions
Funding
Conflicts of Interest
References
- Burdick, A.; Lunenfeld, P.; Drucker, J. Digital_Humanities; MIT Press: Cambridge, MA, USA; London, UK, 2012. [Google Scholar]
- Hotson, H.; Wallnig, T. Reassembling the Republic of Letters in the Digital Age: Standards, Systems, Scholarship; Göttingen University Press: Göttingen, Germany, 2019. [Google Scholar]
- Edelstein, D.; Findlen, P.; Ceserani, G.; Winterer, C.; Coleman, N. Historical Research in a Digital Age: Reflections from the Mapping the Republic of Letters Project. Am. Hist. Rev. 2017, 122, 400–424. [Google Scholar] [CrossRef]
- Imbruglia, G. Muratori, Ludovico Antonio. In Dizionario Biografico Degli Italiani; Istituto della Enciclopedia Italiana: Rome, Italy, 2012; p. 77. [Google Scholar]
- Presner, T.; Johanson, C. The Promise of Digital Humanities: A Whitepaper. Available online: https://humanitiesblast.com/Promise%20of%20Digital%20Humanities.pdf (accessed on 20 November 2023).
- Levenberg, L.; Neilson, T.; Rheams, D. (Eds.) Research Methods for the Digital Humanities; Palgrave MacMillan: Cham, Switzerland, 2018. [Google Scholar]
- Signorotto, G.; Tongiorgi, D. (Eds.) Modena Estense. La Rappresentazione Della Sovranità; Edizioni di Storia e Letteratura: Rome, Italy, 2018. [Google Scholar]
- Fumagalli, E.; Signorotto, G. (Eds.) La Corte Estense Nel Primo Seicento. In Diplomazia e Mecenatismo Artistico; Viella: Rome, Italy, 2012. [Google Scholar]
- Folin, M. Rinascimento Estense. In Politica, Cultura, Istituzioni di un Antico Stato Italiano; Laterza: Rome, Italy; Bari, Italy, 2001. [Google Scholar]
- Marini, L. Lo Stato Estense; UTET: Torino, Italy, 1979. [Google Scholar]
- Di Pietro Lombardi, P. (Ed.) L’antico Fondo Della Biblioteca Estense Universitaria di Modena: I Manoscritti Latini (1–200); Istituto poligrafico e Zecca dello Stato-Libreria dello Stato: Rome, Italy, 2017. [Google Scholar]
- Bonacini, P. Il Registrum Comunis Mutine, 1299. In Politica e Amministrazione Corrente del Comune di Modena Alla Fine del XIII Secolo; Archivio Storico: Modena, Italy, 2002. [Google Scholar]
- Borsari, A. La Memoria Della Città: l’Archivio Storico del Comune di Modena; Archivio Storico, Comune, Assessorato Alla Cultura: Modena, Italy, 2001. [Google Scholar]
- Biondi, A. Per una storia dell’attività consiliare nel comune di Modena dal medio evo alla fine dell’antico regime (1796). In I Registri Delle Deliberazioni Consiliari del Comune di Modena dal XIV al XVIII Secolo; Liotti, C., Romagnoli, P., Eds.; Coptip: Modena, Italy, 1987; pp. 7–43. [Google Scholar]
- Bonacini, P. Terre d’Emilia. In Distretti Pubblici, Comunità Locali e Poteri Signorili Nell’esperienza di Una Regione Italiana, Secoli VIII–XII; Clueb: Bologna, Italy, 2001. [Google Scholar]
- Vigarani, G.; Baldelli, F. (Eds.) Inventario dei Manoscritti Dell’archivio Capitolare di Modena; Poligrafico Mucchi: Modena, Italy, 2003. [Google Scholar]
- Golinelli, P. Nuova Storia Illustrata di Modena; Pacini: Pisa, Italy, 2011. [Google Scholar]
- Previtali, G. Che Cosa Sono le Digital Humanities; Carocci: Rome, Italy, 2022. [Google Scholar]
- Ernst, W. Digital Memory and the Archive; University of Minnesota Press: Minneapolis, MN, USA, 2012. [Google Scholar]
- Burgio, V. Rumore Visivo. In Semiotica e Critica Dell’infografica; Mimesis: Milan, Italy, 2021. [Google Scholar]
- Spiro, L. This is why we fight: Defining the Value of the Digital Humanities. In Debates in the Digital Humanities; Gold, M.K., Ed.; University of Minnesota Press: Minneapolis, MN, USA, 2012; pp. 12–35. [Google Scholar]
- Mahomi, S.; Pierazzo, E. Teaching Skills or Teaching Methodology? In Digital Humanities Pedagogy: Practices, Principles and Politics; Hirsch, B.D., Ed.; Open Book Publishers: Cambridge, UK, 2012; pp. 215–225. [Google Scholar]
- Al Kalak, M.; Fumagalli, E. (Eds.) Collezionare Autografi. La Raccolta di Giuseppe Campori; Olschki: Florence, Italy, 2022. [Google Scholar]
- Baraldi, L.; Cornia, M.; Grana, C.; Cucchiara, R. Aligning text and document illustrations: Towards visually explainable digital humanities. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 1097–1102. [Google Scholar]
- Cascianelli, S.; Cornia, M.; Baraldi, L.; Piazzi, M.L.; Schiuma, R.; Cucchiara, R. Learning to Read L’Infinito: Handwritten Text Recognition with Synthetic Training Data. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Virtual, 28–30 September 2021; pp. 340–350. [Google Scholar]
- Toselli, A.; Juan, A.; Gonz, J.; Salvador, I.; Vidal, E.; Casacuberta, F.; Keysers, D.; Ney, H. Integrated handwriting recognition and interpretation using finite-state models. Int. J. Pattern Recognit. Artif. Intell. 2014, 18, 519–539. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. Adv. Neural Inf. Process. Syst. 2008, 21, 545–552. [Google Scholar]
- Zhang, Y.; Nie, S.; Liu, W.; Xu, X.; Zhang, D.; Shen, H.T. Sequence-to-sequence domain adaptation network for robust text image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2740–2749. [Google Scholar]
- Wigington, C.; Stewart, S.; Davis, B.; Barrett, B.; Price, B.; Cohen, S. Data augmentation for recognition of handwritten words and lines using a CNN-LSTM network. In Proceedings of the International Conference on Document Analysis and Recognition, Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 639–645. [Google Scholar]
- Zhong, Z.; Zhang, X.Y.; Yin, F.; Liu, C.L. Handwritten Chinese character recognition with spatial transformer and deep residual networks. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 3429–3434. [Google Scholar]
- Bhunia, K.; Das, A.; Bhunia, A.K.; Kishore, P.S.R.; Roy, P.P. Handwriting Recognition in Low-resource Scripts using Adversarial Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4767–4776. [Google Scholar]
- Cojocaru, I.; Cascianelli, S.; Baraldi, L.; Corsini, M.; Cucchiara, R. Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 6096–6103. [Google Scholar]
- Marti, U.-V.; Bunke, H. The iam-database: An english sentence database for offline handwriting recognition. Int. J. Doc. Anal. Recognit. 2002, 5, 39–46. [Google Scholar] [CrossRef]
- Augustin, E.; Carre, M.; Grosicki, E.; Brodin, J.-M.; Geoffrois, E.; Preteux, F. RIMES evaluation campaign for handwritten mail processing. In Proceedings of the International Workshop on Frontiers in Handwriting Recognition, La Baule, France, 23–26 October 2006; pp. 231–235. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. PAMI 2016, 39, 11. [Google Scholar] [CrossRef] [PubMed]
- Puigcerver, J.; Toselli, A.H.; Vidal, E. Querying out-of-vocabulary words in lexicon-based keyword spotting. Neural Comput. Appl. 2017, 28, 2373–2382. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lodovico Categories (Dublin Core Based) | Description | User/Research Questions |
|---|---|---|
| Header | Shelf mark (actual and old shelfmark, if any) | Where is preserved the original object? |
| Title | Original or attributed title for a short description of the digitised object | What is the digitised object? |
| Chronological date | Chronological extremes | When was the original object produced? |
| Physical description | Medium (type and material), dimensions (height, width, depth), and consistency (quantity, unit of measurement) of the digitised object | What are the material characteristics of the original object? |
| Content description | Summary or transcription of the contents | What is the content of the original object? |
| Persons | Author, recipient/addressee, people cited, possessor, donor (when persons) | Which persons are related to the original object? How (authors, addressees, cited, etc.)? |
| Entities | Author, recipient/addressee, entities/institutions cited, conservator (when entities) | Which entities are related to the original object? How (authors, addressees, cited, etc.)? |
| Places | Topical date, places cited | Where was the original object produced? What other places are mentioned? |
| Subject | Topic(s) related with the contents of the digitised object | What are the topics with which the original object and its contents can be associated? |
| Notes | Free-text field for additional information | Is there any other useful or necessary information to be given to the user/researcher? |
| Language | Language(s) used for the contents | What language is used in the original object? |
| Shi et al., 2016 [35] | Puigcerver et al., 2017 [36] | Shi et al., 2016 [35] + DefConv | Puigcerver et al., 2017 [36] + DefConv | |||||
|---|---|---|---|---|---|---|---|---|
| CER | WER | CER | WER | CER | WER | CER | WER | |
| ICFHR14 | 47.2 | 102.7 | 59.7 | 120.1 | 77.8 | 112.4 | 103.9 | 147.1 |
| ICFHR16 | 76.0 | 129.8 | 79.1 | 111.0 | 83.1 | 109.3 | 86.9 | 144.6 |
| IAM | 46.5 | 92.9 | 68.0 | 96.4 | 60.4 | 97.5 | 74.4 | 98.9 |
| RIMES | 43.4 | 88.0 | 73.9 | 103.9 | 72.8 | 100.0 | 69.5 | 97.1 |
| Leopardi | 35.9 | 86.4 | 38.5 | 93.9 | 40.2 | 92.1 | 36.3 | 94.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Kalak, M.; Baraldi, L. Sharing Cultural Heritage—The Case of the Lodovico Media Library. Multimodal Technol. Interact. 2023, 7, 115. https://doi.org/10.3390/mti7120115
Al Kalak M, Baraldi L. Sharing Cultural Heritage—The Case of the Lodovico Media Library. Multimodal Technologies and Interaction. 2023; 7(12):115. https://doi.org/10.3390/mti7120115
Chicago/Turabian StyleAl Kalak, Matteo, and Lorenzo Baraldi. 2023. "Sharing Cultural Heritage—The Case of the Lodovico Media Library" Multimodal Technologies and Interaction 7, no. 12: 115. https://doi.org/10.3390/mti7120115
APA StyleAl Kalak, M., & Baraldi, L. (2023). Sharing Cultural Heritage—The Case of the Lodovico Media Library. Multimodal Technologies and Interaction, 7(12), 115. https://doi.org/10.3390/mti7120115