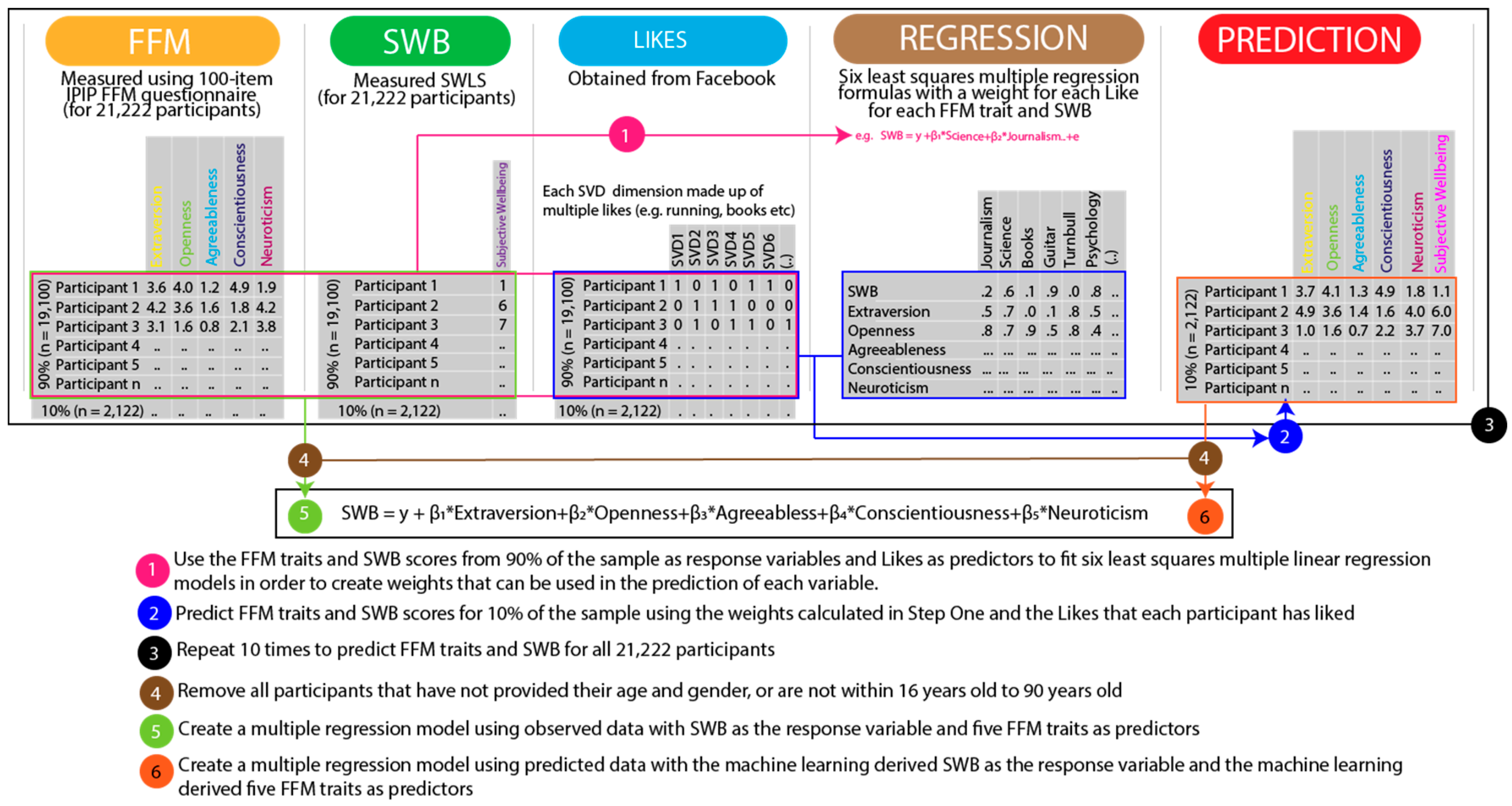
The current study aimed to replicate the relationship between the FFM of personality and SWB using simple machine learning techniques: singular value decomposition, k-folds validation, and multiple linear regression.
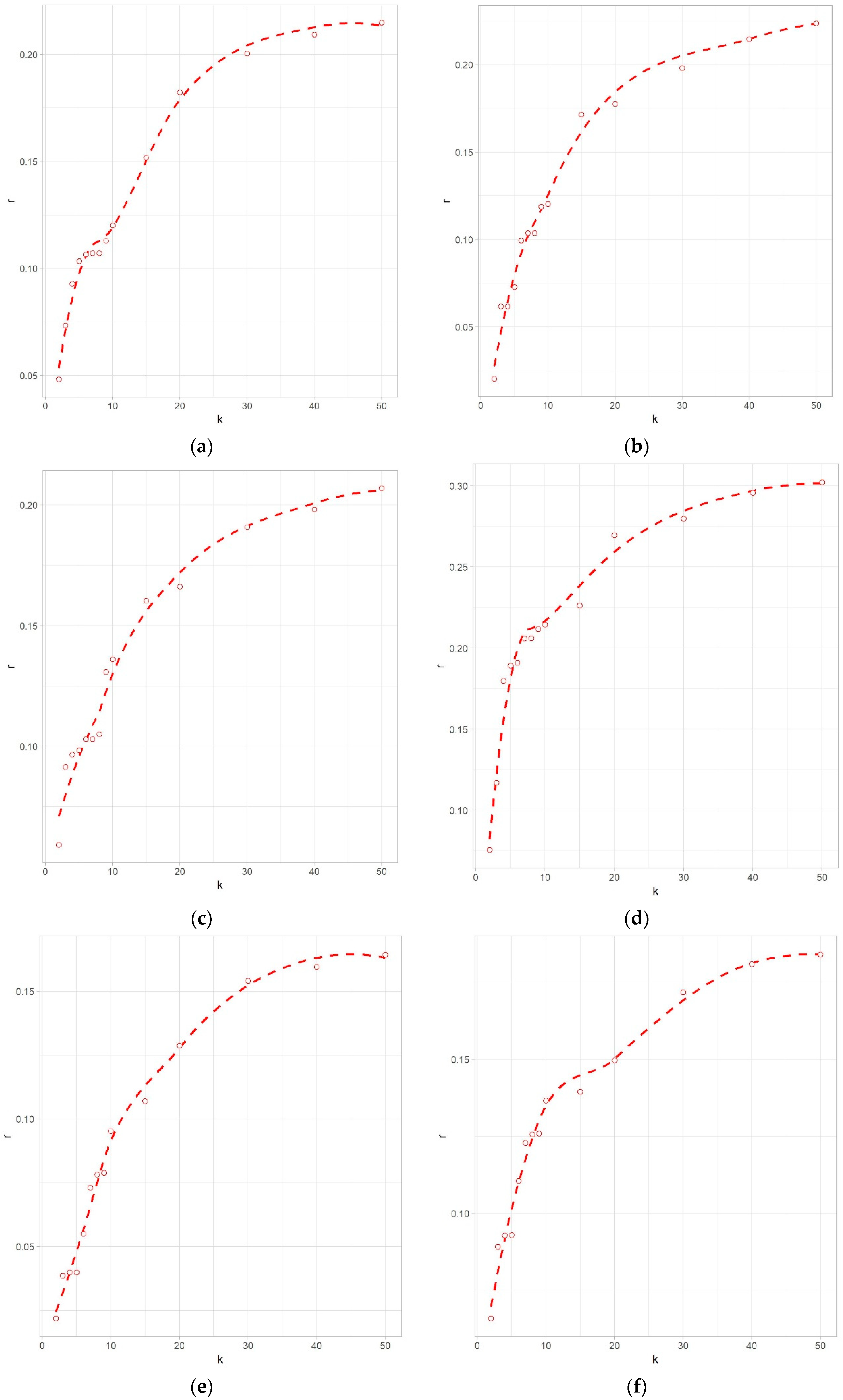
It was hypothesised that the machine learning model would accurately recreate the SWB and FFM variables. The results support this hypothesis to an extent. From the correlation analysis, the observed scores for extraversion (r = 0.21), neuroticism (r = 0.20), and openness (r = 0.31) were most accurately recreated in the machine learning model.
The second hypothesis postulated that the variables predicted through machine learning techniques would be capable of replicating the relationship between observed SWB and the FFM variables. Again, this hypothesis is partially supported. Higher scores for extraversion, agreeableness, conscientiousness, and neuroticism predicted a higher score for SWB; however, the openness to experience prediction reversed in the machine learning model. The openness to experience prediction reversed in direction, so in the machine learning model, an increase in openness to experience predicted a higher SWB. This may be attributed to the failure to recreate the variable in the first hypothesis. Based on the multiple regression analyses, openness to experience became positively correlated with SWB in the machine learning model, which could be attributed to reference group bias through the administration of the NEO-PI-R via Facebook [
24,
25]. A higher correlation was found between agreeableness and SWB, which is due to the unknowing use of identical digital behaviours to predict the variables or multicollinearity, which inflated the relationship. This suggests that using machine learning to recreate variables is likely to overestimate the relationship between variables.
Whilst the findings from this study pose additional evidence for the utility of using digital behaviour as data to produce prediction models, the accuracy of predictions for the currently investigated constructs is not high when relying solely on SVD and multiple linear regression. Kosinski, Wang, Lakkaraju and Leskovec [
2] seem to inflate the accuracy of the linear regression model to predict psychological constructs; while they achieved a high accuracy when predicting gender, personality was predicted with a relatively lower accuracy. Additionally, Kosinski, Stillwell and Graepel [
3] found prediction of personality constructs to range from
r = 0.17 to
r = 0.43, which are not necessarily high accuracies. The prediction for SWB (
r = 0.17) was very low in comparison to what was found for age (
r = 0.75) in their study. Further investigation within the psychological literature into more complex machine learning techniques that may increase the accuracy of predictions using social media data is required.
4.1. The Relationship between SWB and the FFM of Personality
The correlations between the SWB and FFM variables in both models (observed and machine learning-derived) partly replicated previous literature. A summary of correlations between the FFM traits and SWB from four studies in the literature is displayed in
Table 5. Extraversion and neuroticism were replicated with a reasonable accuracy and mirrored the findings of Steel, Schmidt and Shultz [
8] and Grant, Langan-Fox and Anglim [
33]. Openness to experience replicated the findings from Steel, Schmidt and Shultz [
8] and Grant, Langan-Fox and Anglim [
33] in the original model; however, the machine learning model did not accurately replicate the variable. To an extent, the observed variable of conscientiousness paralleled the findings from Anglim and Grant [
34], though the machine learning variable almost doubled in its correlation size and did not represent any previous findings in the literature. Agreeableness in both models did not represent or mirror any previous research.
None of the variables in either model replicated the findings from DeNeve and Cooper [
9], which could be attributed to the meta-analysis’ mean age of 53 years. The current study was predominantly young adult aged and therefore the different life stage may explain the discrepancy [
54,
55]. Only conscientiousness in the original model slightly mirrored Anglim and Grant [
34], which could be due to the different personality measure used, the 30-item Facet IPIP. The shorter scale may have exaggerated the scores for neuroticism and extraversion, as they are considerably higher in comparison to the other studies mentioned.
The correlations between the observed and machine learning predicted variables somewhat replicated the findings of Kosinski, Stillwell and Graepel [
3]. The highest correlation for the current study is for extraversion and the SWB correlation in the current study was almost the same as that found by the researchers (
r = 0.17). As Kosinski, Stillwell and Graepel [
3] did not specify the correlations for the other FFM variables (
r = 0.17 to
r = 0.30), conclusions regarding these variables are not complete. However, agreeableness, conscientiousness, and neuroticism were in the range stated by the researchers. These similarities are to be expected given that we have used the same initial dataset, but with different inclusion criteria.
Overall, for the original model with observed variable scores, high SWB was predicted by high extraversion, agreeableness, and conscientiousness, and low openness to experience and neuroticism. For the machine learning model, high SWB was predicted by high extraversion, openness to experience, conscientiousness, and agreeableness, and low neuroticism. Therefore, it could be concluded that high extraversion, conscientiousness, and agreeableness, and low neuroticism, are relatively consistent predictors of high SWB.
The greater prediction accuracy of the machine learning model linear regression compared to the observed data linear regression (
Table 4) may be due to the genuine nature of Facebook ‘likes’ used to train the machine learning algorithm, and thus their impact on the recreated variables. When considering the machine learning model to predict the variables, most variables recreated the observed variables with a relative accuracy with a large effect size according to Gignac and Szodorai [
53]. Using social media data to predict real life outcomes presents an important opportunity in psychology to further measure how individuals can be perceived and how they behave in a natural online environment [
24].
4.2. Implications, Limitations and Future Research
The basis of Facebook ‘likes’ is to record human behaviour through expressing positive opinions regarding online content. Technological advances have allowed big data to be extracted from social media websites and this data can be manipulated and analysed to further understand human behaviour [
32]. The amount of information that can be gathered through social media is significant and generates new areas and possibilities for future research. The current study had a large sample size of 21,112 participants (used to predict FFM traits and SWB for 13,497 participants aged 16–90) from 148 different countries, which exhibits the advantage of large samples allowing for high statistical power to be obtained [
2]. Despite previous authors praising the utility of social media to attract a less western population, the sample for this study was predominately western, as most participants were from Australia, Canada, the United Kingdom, or the United States, limiting the generalisability of the results. Future research should investigate non-westernised countries and the prediction models based off their Facebook ‘likes’, as they may be considerably different from the western population.
Although using the Internet and Facebook information in psychological research reduces reference group bias, some bias may be evident. Though the Internet provides a medium to observe human behaviour, individuals can still put on a façade and “fake good”. As of 2017, over two million applications exist (Apple and Android) to alter photos (similar to Adobe’s ‘Photoshop’), access social media sites, locate oneself on a map, order food delivery and transport, track health and exercise, and much more. Holland and Tiggemann [
56] systematically reviewed 20 studies and concluded that social networking website use, body image, and disordered eating are related (regardless of gender). Particularly viewing and uploading photos and attention seeking ‘status updates’ that received negative responses were damaging. Another study found, in a sample of adolescent females, that increased appearance exposure on Facebook, but not overall Facebook usage, was significantly correlated with weight dissatisfaction, thin ideal internalisation, and self-objectification [
57]. Our study has avoided many of these issues by utilising Facebook likes, rather than status updates or profile pictures. Although technology is growing, as is social media and its associated websites, individuals can be a different person online both physically and socially, which can impact their cognitive and mental functioning in detrimental ways.
The large increase (though due to multicollinearity) in agreeableness in the machine learning model should be inferred cautiously. Agreeableness is characterised by positive social relationships, friendliness, compassion, and cooperativeness [
3]. On the Internet, individuals can be whoever they want to be and may thus reinvent themselves as a highly agreeable individual. Other traits, such as conscientiousness, refer to an organised, reliable, and consistent individual who enjoys planning, seeking achievements, and pursuing long-term goals [
3]. These characteristics may not be evident through Facebook ‘likes’, as social media websites often do not focus on goals and organisation, but on networking friends and individuals. Facebook ‘likes’ are a basic, discrete digital behaviour that work well with linear regression models. While using natural language processing may allow for a greater understanding of machine learning in social media, it may suffer from significant error due to the complexity of language in statistical analysis [
26]. Due to the scope of this study, other aspects of Facebook behaviour were not analysed. Further research into the prediction of traits through machine learning could focus on other aspects of Facebook, such as ‘status updates’, friendship networks, and past events attended, as these online expressions may explain the variables more accurately.
As this is a relatively new area of research, ethical considerations must be addressed. No clear guidelines for conduct in online human subjects research currently exist and thus protocols related to designing online studies, data storage, and analysis of results are scarce, as well as contradictory [
24,
58]. Using the Internet and Facebook as a research tool poses new ethical dilemmas concerning consent, confidentiality, and competence. The researcher may not be in the same room as the participant, nor have met them, and thus the reliability and validity of results could be decreased or diminished. For the American population, the American Psychological Association lists three documents with guidelines governing how to conduct research utilising the internet, with the most recent from 2003 [
59,
60]. However, this is nearly fifteen years old and with the increase in Web 2.0-type websites (i.e., non-static pages), this may not be relevant or sufficient for the current state of Internet-based research. Recommendations from the Association of Internet Researchers (AoIR) Ethics Working Committee state that although no concrete guidelines have been set for internet-based research in America, policies and documents such as the UN Declaration of Human Rights, the Nuremburg Code, the Declaration of Helsinki, and the Belmont Report, apply to all types of research [
61]. The basics of these documents are to respect the dignity, autonomy, and rights of the human population and to avoid any possibility of harm. The Australian Psychological Society (APS) takes these fundamentals into account and addresses the key issues of technology, quality, control, and security when dealing with Internet-based research. In Australia, psychologists must abide by the International Guidelines on Computer-Based and Internet Delivered Testing [
62] and also abide by the APS ethical guidelines [
63]. Accordingly, the British Psychological Society has released Ethics Guidelines for Internet-mediated Research that mirror the APS ethical guidelines [
64]. Only three western countries’ ethical guidelines have been mentioned as they make up most of the sample for the current study. However, further investigation should inspect the ethical guidelines for other non-westernised countries, as it may be possible to conduct Internet research on these populations. Confidentiality, consent, potential limitations, and security of data collected are perhaps more important in Internet-based research due to the potential of hackers and insecure storing of private information. The ethics behind Internet-based research has not been clear in America due to the dated governing documents. This poses a limitation, as the data collected by the ‘myPersonality project’ is American-based and consists of predominantly American participants. Future research could limit the sample to Australian participants as the Australian ethical guidelines are comprehensive, though the ethics is still questionable due to the American-based project overall.
In terms of implications for SWB and the FFM of personality, this study creates new avenues of measurement for these constructs, as well as an additional understanding of what they constitute in the online world. Future research could alter the methodology to include regression trees, neural networks, or other algorithms in order to further consider the utility of other machine learning algorithms in the computational social sciences. Greater understanding of the variety of techniques available to psychology researchers, as informed by our data science and computer science colleagues, can only enhance research within the field. With the collaboration of researchers from these fields, a greater knowledge could be built upon to evaluate digital behaviours that are related to certain traits, and individuality can be further investigated using digital data and machine learning techniques.



{kind=link}
{kind=link}
{kind=link}


