3.1. Knowledge-Based Recommender System for B2B
In this research, we propose a novel approach to handle customer management and managerial decision support. We propose a knowledge-based and a text mining-based approach for developing a recommender system. In our domain, users of an RS are business decision-makers and items of interest are strategic business actions. In our domain, an item is understood as any combination of a number of of business strategies: price competitiveness, staff attitude, technician’s knowledge, etc.
3.1.1. Recommender System for B2B
The idea of applying a recommender system in the area of strategic business planning is quite novel and currently under-researched. On the other hand, the principles of the proposed approach are generalizable to multiple and diverse environments and applications. One of the proposed definition of a recommender system for B2B e-commerce was given in [
16]: “a software agent that can learn the interests, needs, and other important business characteristics of the business dealers and then make recommendations accordingly”. The systems use product/service knowledge—either hand-coded knowledge provided by experts or knowledge learned from the behavior of consumers—to guide the business dealers through the often overwhelming task of identifying actions that will maximize business metrics of the companies.
3.1.2. NPS-Based Recommendations
The goal of the recommendations is to improve customer loyalty, as measured by net promoter score (NPS)—a current standard metric for measuring customer satisfaction (NPS®, Net Promoter®, and Net Promoter® Score are registered trademarks of Satmetrix Systems, Inc., Bain and Company and Fred Reichheld). The idea of the NPS metric is based on categorizing a customer into one of the three categories: a promoter (a loyal customer), a passive, or a detractor (disloyal customer hurting the reputation of a company). The percentage NPS metric is calculated as the total percentage of promoters minus the total percentage of detractors.
3.1.3. Knowledge Discovery Techniques
The proposed approach for improving NPS is based on a novel technique in data mining, called action rule [
17], and aggregating results of multiple action rules to calculate the predicted NPS impact [
18]. Action rules are patterns mined from large sets of numerical customer feedback that provide aggregated knowledge about actions necessary to change the value of a decision attribute—in our domain, the label of customer status from a detractor to a promoter. The effect of multiple action rules is aggregated to generate recommendations with the goal to provide minimal sets of changes that bring the maximal expected impact on NPS improvement.
3.1.4. Sentiment Mining Techniques
Text mining can be useful to identify the frequency with which topics are mentioned and the sentiment associated with the topics.
Sentiment analysis is generally defined as analyzing people’s opinions, sentiments, evaluations, attitudes, and emotions from written language. We propose an algorithm for calculating the overall impact that additionally takes into account the results of text mining on text customer feedback related to the numerical scores. In particular, we propose an aspect-based sentiment analysis approach for text mining.
Aspect-based sentiment analysis is based on the idea that an opinion consists of sentiment (positive or negative) and a
target of the opinion, that is, a specific aspect or feature of the object [
19].
3.1.5. Data Visualizations Techniques
An important aspect to be considered in an RS is the output design and the presentation of the output—e.g., how to deliver the recommendations to the users, if the system explains the results to the user, etc. In this research, it is proposed to provide explainable output to allow the system’s users to make more informed and accurate decisions about which recommendations to utilize. To attain this goal, it is proposed to apply novel visualization web-based techniques to help business users understand the algorithms behind recommendations, compare recommendation options, provide for sensitivity analysis, and explore raw data behind recommendations [
20].
3.2. CLIRS: Data-Driven Customer Loyalty Improvement RS
The proposed data-driven approach for building a knowledge-based RS is based on a large dataset of customer feedback (around 300,000 records) collected from companies in the heavy equipment industry by a collaborating consulting company. Each record in the dataset represents a survey, with features describing the company and their particular service being assessed and the customer being surveyed. Feedback is represented by numerical scores in different areas and additional notes in the free-form text. Since there are limitations to a human (manual) approach to deriving novel insights or patterns from vast amounts of records, we propose applying data mining techniques with the goal to extract meaningful patterns about customer sentiment.
The results of data mining and text mining are incorporated into the framework of customer loyalty improvement recommender system (CLIRS) [
21]. The algorithm for generating recommendations includes the following steps (
Figure 1 and Algorithm 1):
- 1.
Data preprocessing. The original data are being pre-processed including standardization, missing values imputation, and feature extraction. The feature extraction was applied on geographic attributes describing companies. For example, an area code was extracted based on the Contact Phone, and County was added based on the Zip and Contact Phone columns. The comprehensive survey data are divided into single-company datasets.
- 2.
Semantic Similarity. We introduce the concept of semantic similarity between two companies, which is based on the distance between classification models extracted from the datasets of the companies. Companies are similar if the semantic categorization of promoter, passive, and detractor, as extracted by a classification model, is similar. Assuming that RC[1] and RC[2] are the sets of classification rules extracted from the single-client datasets (of clients C1 and C2):
, where the above three sets are collections of classification rules defining correspondingly: “Promoter”, “Passive” and “Detractor”:
In a similar way, we define:
.
By , we mean confidences of corresponding rules in a dataset for client .
We define as confidences of rules extracted from calculated for .
Analogously, are confidences of rules extracted from and are confidences of rules extracted from client calculated for client .
Based on the above, the concept of semantic similarity between clients
,
, denoted by
, is defined as follows:
The metric is used to find clients similar to a current client in semantic terms. It calculates the distance between each pair of clients. The smaller the distance is, the more similar the clients are.
- 3.
Clustering procedure. The single-company datasets are extended (merged with) datasets of companies that are semantically similar. The extension procedure aims at finding a “similar” company, which has a higher NPS. Therefore, knowledge from that company(s) can help the current client improve its NPS. We propose a hierarchical clustering algorithm for the procedure of forming “clusters” of semantically similar companies (called the “HAMIS” procedure—Hierarchical Agglomerative Method for Improving NPS [
22]). The algorithm uses the semantic similarity metric as defined above to create a hierarchical structure called “dendrogram”. The result of the procedure is single-client datasets expanded with their semantic neighbors based on the dendrogram structure. We developed an interactive visualization to display the resulting dendrogram structure (see
Figure 2).
- 4.
Actionable knowledge mining. The datasets expanded in the previous step are mined for actionable knowledge with the goal of improving NPS, by changing customers from detractors to promoters. In our domain, action rules show minimal sets of business changes needed to be undertaken in order to change a customer from being detractor or passive to being a promoter. Action rules are composed of so-called stable attributes, flexible attributes, and the target attribute. For stable attributes, characteristics of a survey type and a customer were chosen for the experimental setup. For flexible attributes, we chose benchmark questions from surveys, which represent areas of improvement in the customer satisfaction problem. We confined analysis only to core benchmarks, which were extracted using a feature selection method based on computing decision reducts. The target attribute which we desire to change is the NPS status (from a detractor to a promoter). Each such rule is characterized by the support and the confidence metric. Support of the rule is understood as the number of customers affected by this rule, that is, the greater is the support, the more customers there are who can potentially be changed from detractor to promoter. Confidence says how probable it is to change the promoter status.
An example of the extracted action rule is given in
Listing 1:
Listing 1.
A sample action rule pattern showing changes in benchmark scores leading to the change of customer status from a detractor to a promoter.
Listing 1.
A sample action rule pattern showing changes in benchmark scores leading to the change of customer status from a detractor to a promoter.
| ((B1: 2 -> 5), (B4: 7 -> 8), (B9: 9 -> 10)) => (Detractor -> Promoter) |
where B1, B4, and B9 denote codes of benchmark questions, and therefore specific areas of customer service. The interpretation of the rule is as follows: if the values of benchmark questions are changed from the value given on the left-side to the value as given on the right side, it is expected to change customer’s status from being detractor to become a promoter, with a given confidence.
- 5.
The text mining procedure is applied to the text comments that accompany numerical surveys. The algorithm is based on extracting sentiment towards different aspects of service (so-called
aspect-based sentiment analysis). This procedure involves text pre-processing (parsing and POS tagging), extracting sentiment based on opinion words list, aspect-based sentiment extraction (based on a pre-defined dictionary of features and their aspects), and text summarization.The details of the procedure and the results are described in [
23].
- 6.
NPS impact calculation. We combine results from action rule mining and text mining to generate recommendations and calculate an expected NPS impact. The procedure combines different aspects and checks its NPS effect calculated based on the support and confidence of corresponding action rules. NPS impact is calculated based on a multiplication of support and confidence (support × confidence), which provides information about the expected number of customers affected by changes. Only sets of aspects with the highest impact are presented to the business user.
- 7.
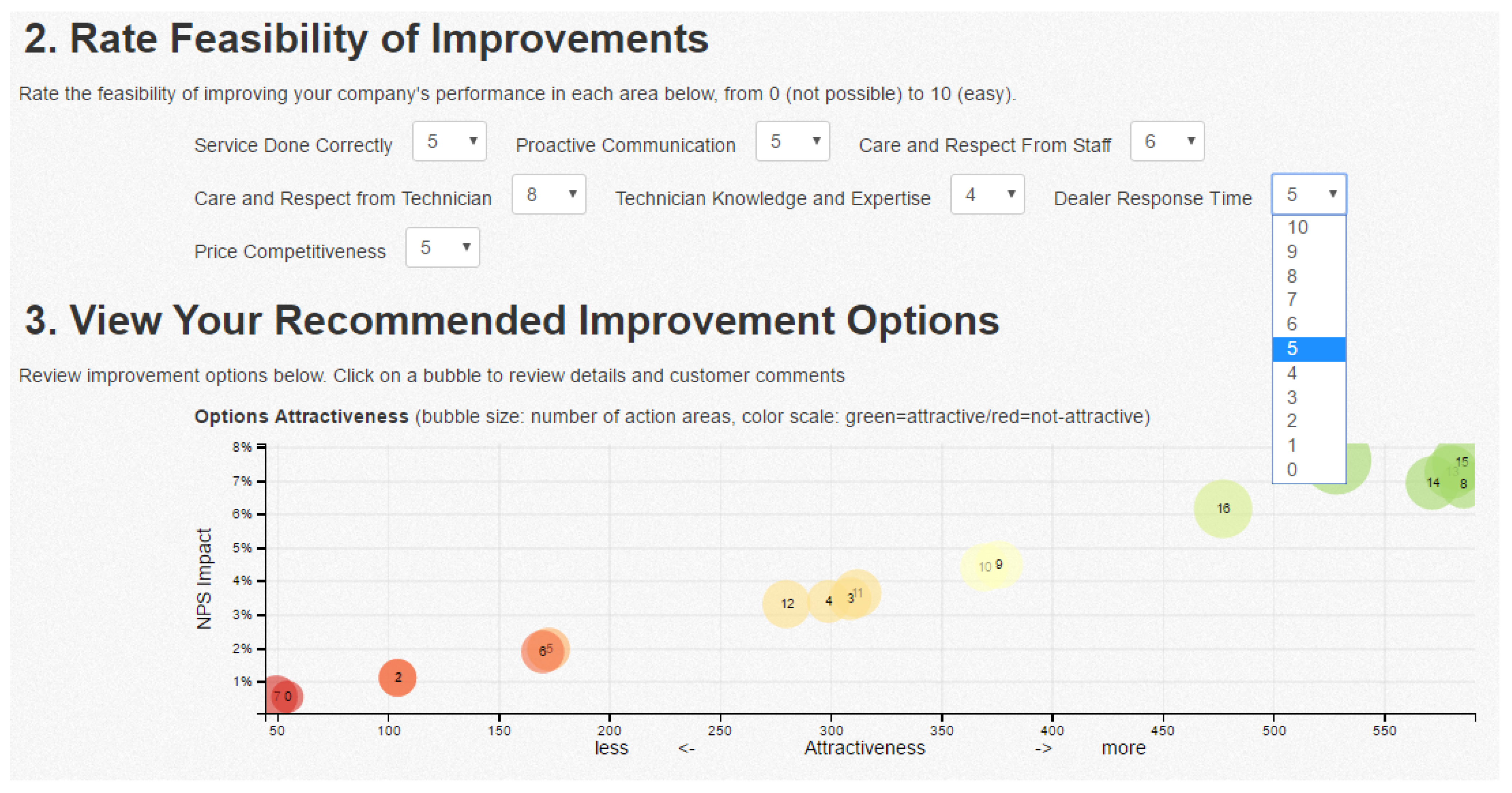
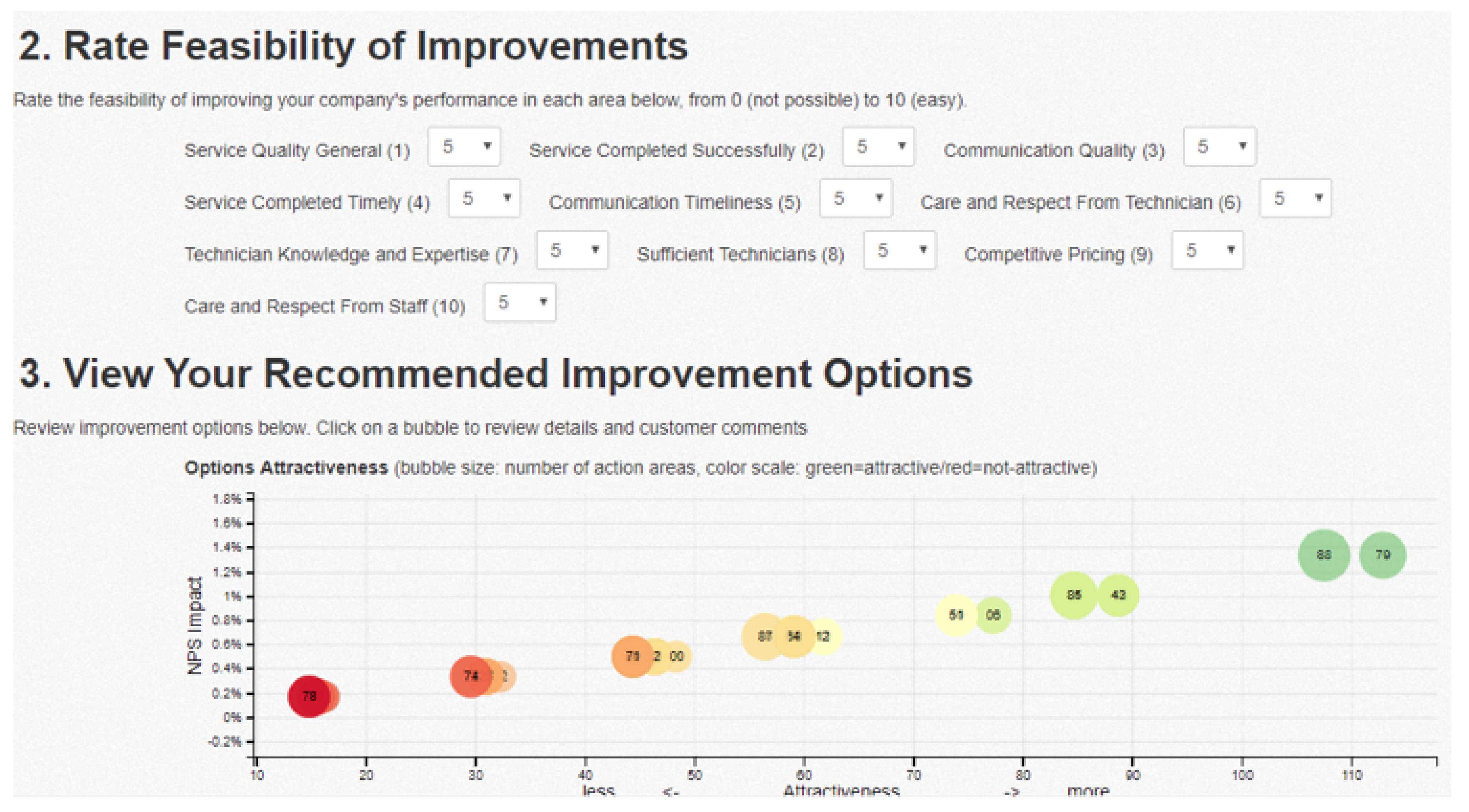
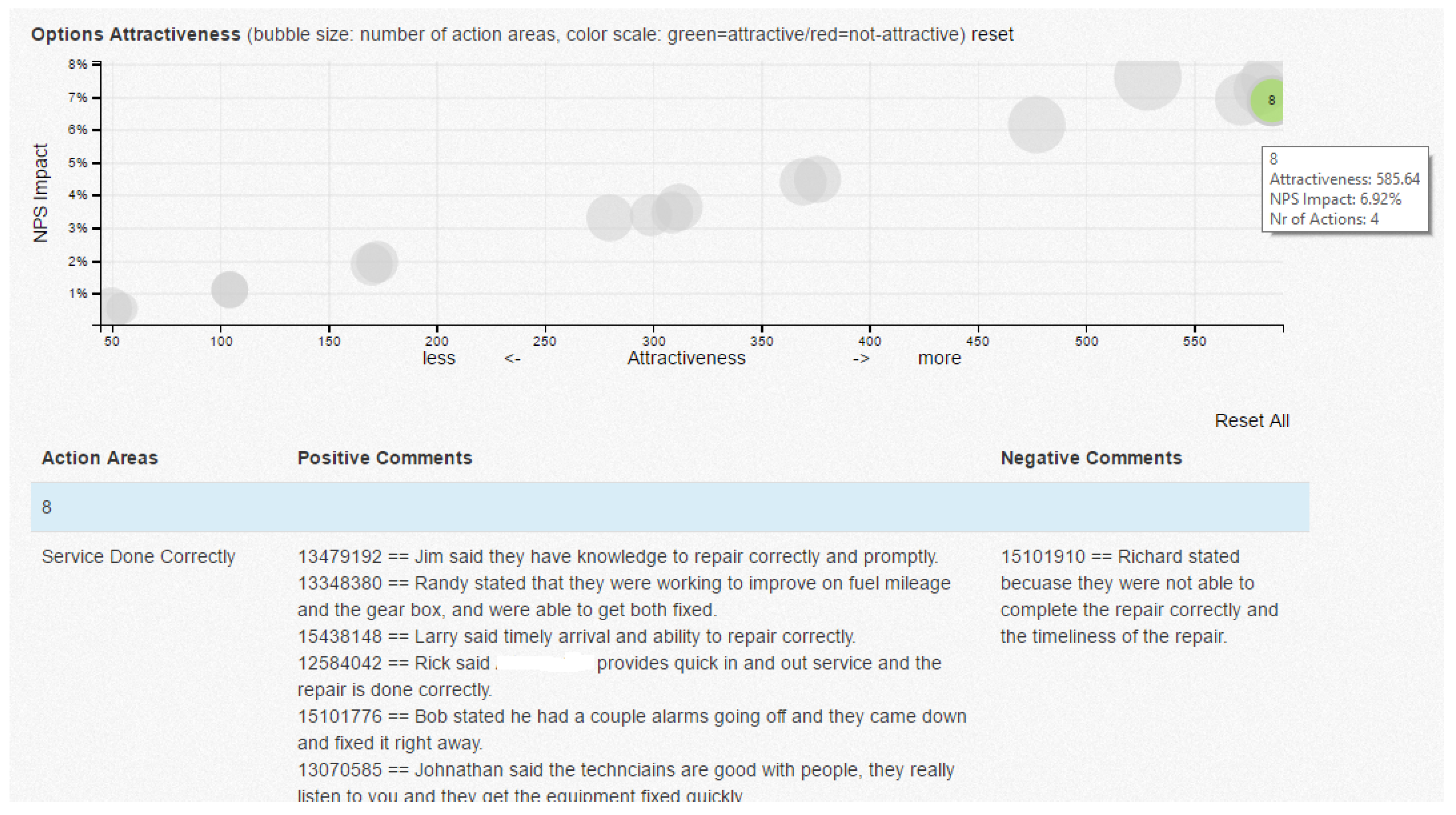
Visualization. Visualization techniques are proposed for displaying the recommendations in a web-based format. The visualization is interactive, and the set of recommendations changes based on the feasibility of aspects as assigned by the business user (
Figure 3). Each recommendable item (visualized as “bubble”) consists of a set of aspects that should be improved in order to impact NPS positively. Each recommendable item is characterized by an attractiveness (color-coded) presented in a two-dimensional chart as a function of NPS impact and feasibility, assigned by the user based on their business knowledge. Each recommendable item can be further analyzed by drilling down into the raw comments associated with aspects included in recommendations.
| Algorithm 1 Procedure for generating data-driven recommendations. |
- 1:
//Set current client’s ID and expand the client with HAMIS procedure - 2:
- 3:
- 4:
//Reformat the action rules extracted for the current client and its extensions - 5:
- 6:
//Explore the action rule set and collect all existing atomic actions. - 7:
- 8:
for clientName: clientIDmerged do - 9:
//Mine the meta-actions for each atomic action using comments in each file. - 10:
- 11:
- 12:
- 13:
- 14:
- 15:
- 16:
//Trigger action rules. - 17:
- 18:
- 19:
- 20:
- 21:
- 22:
//Group meta-actions and find the best groups of meta-actions. - 23:
- 24:
- 25:
end for
|
3.3. CLIRS2: Sentiment Analysis Based Customer Loyalty Improvement RS
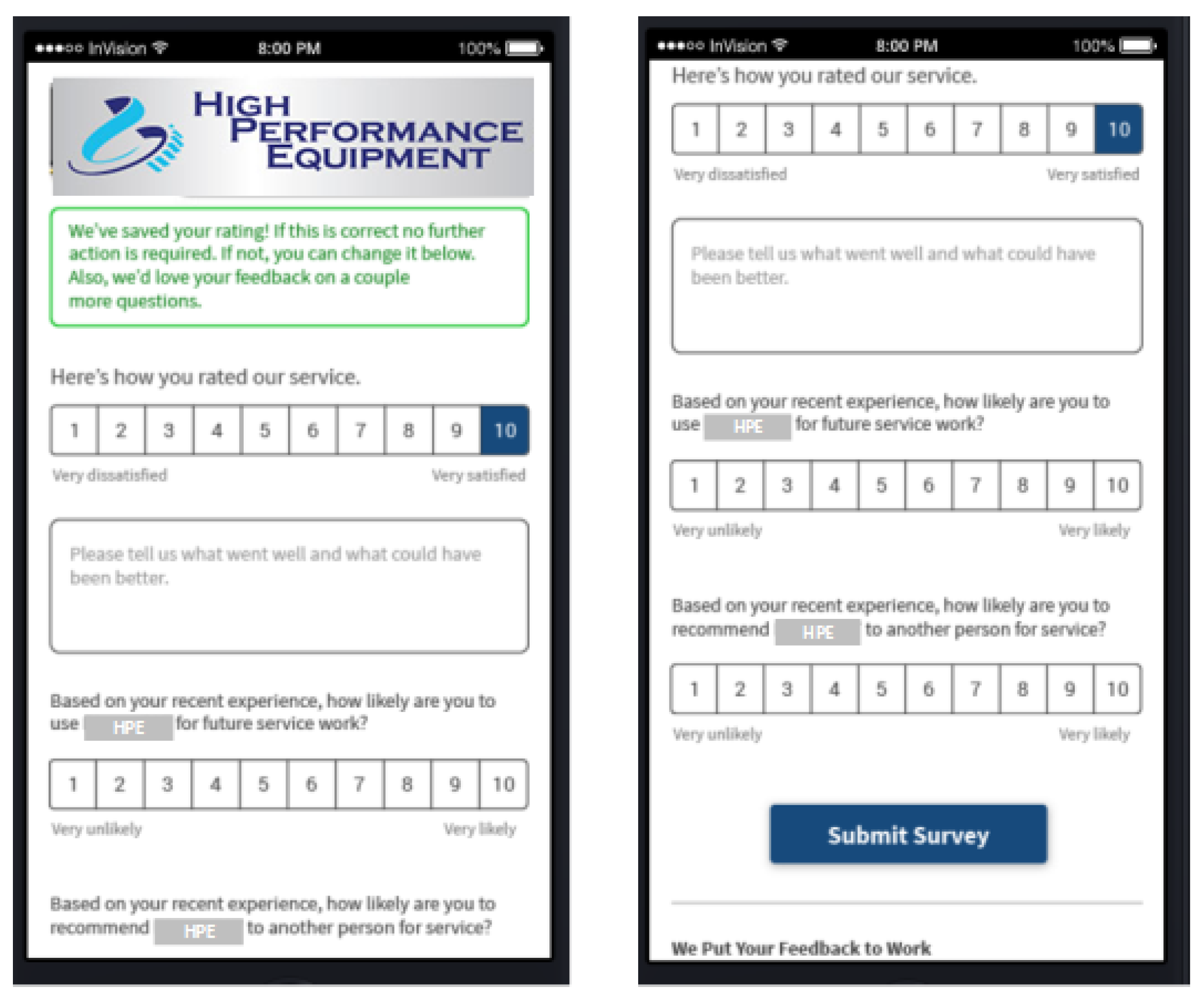
The business setting and requirements changed as we developed a data-driven version of a recommender system for improving customer loyalty (CLIRS). Namely, the business recognized that structured surveys conducted via calling end customers are taking too much time, and customers are reluctant or impatient to take time to complete these. The business decided to switch to a shorter version of surveys, consisting of 3–5 numerical questions, and mostly open-ended questions (see
Figure 4).
This represented a challenge for the research, as the version of the system was built mainly on numerical data, and using text comments only as an augmentation of the recommender algorithm. In the future, the dataset will reverse its structure, that is, the text feedback will be accompanied by a few numerical questions, with most insight provided by the free-form text.
The procedure for generating data-driven recommendations (as presented in
Figure 1) had to be revised since the structure of the primary source of customer feedback changed from the numerical format to text format. The new procedure (
Figure 5) for generating recommendations performs mining on the text first and contains an additional step of transforming text into a structured form.
Based on the revised procedure, a new version of Customer Loyalty Improvement Recommender System (CLIRS2) was developed. In general, this new version of the system presents a novel method for developing RS from solely text data. When comparing the procedure revised for text data (
Figure 5) with the previous process (
Figure 1), text mining is performed first to build a dataset suitable for action rule mining. In addition, the procedure for generating recommendations (meta nodes) has changed and is described in more detail later.
3.3.1. Opinion Mining
Our approach to aspect-based opinion mining consists of four steps:
Identify opinion sentences and their orientation with localization.
Summarize each opinion sentence using discovered dependency templates.
Summarize opinions based on identified feature (aspect) words.
Generate meta-actions with regard to given suggestions.
Our approach is dictionary-based, that is, we use pre-defined dictionaries of both opinion words and aspect words. The detailed procedure is presented in [
23]. This approach uses the recognition of opinion words, associating opinion words with aspect words, using Stanford lexical dependency patterns [
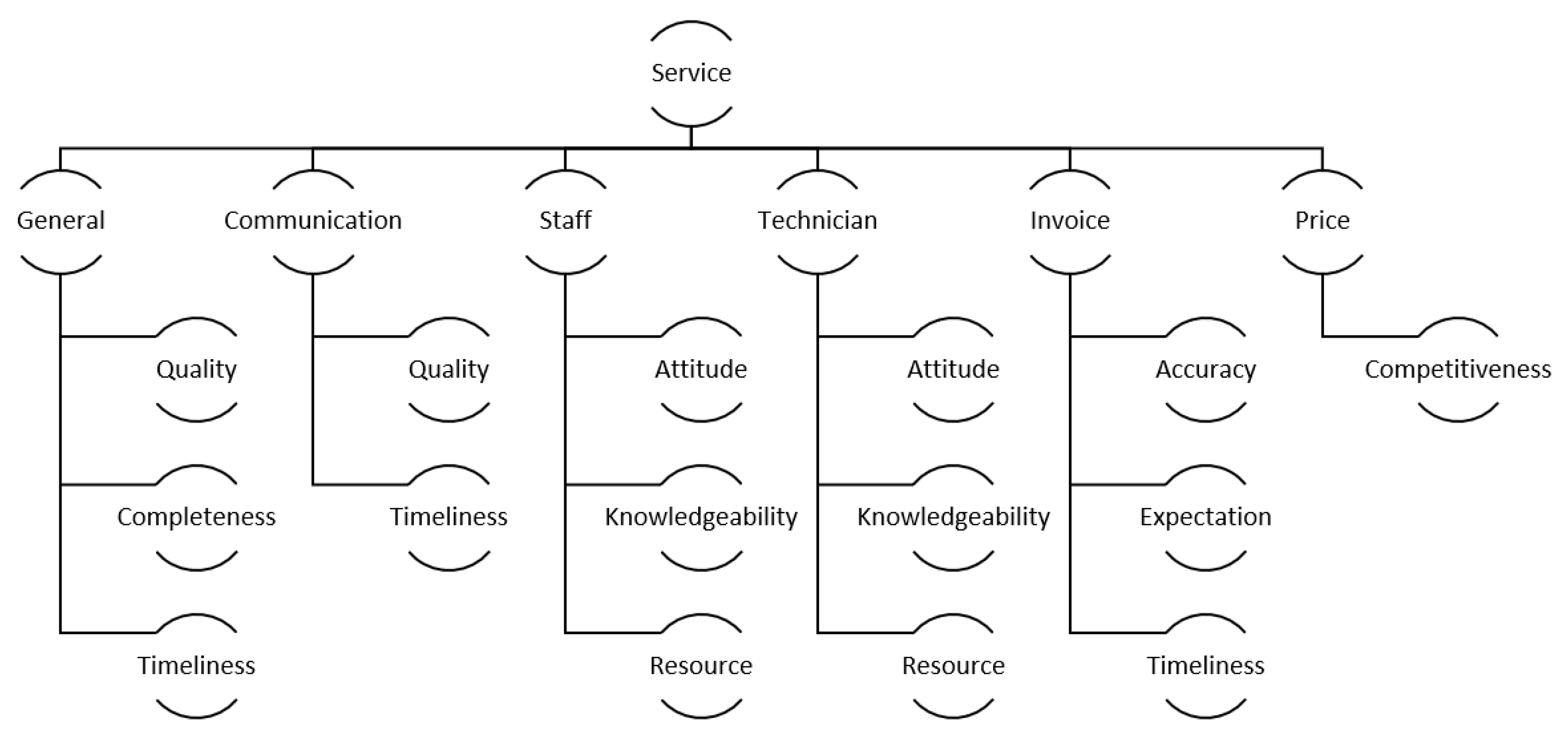
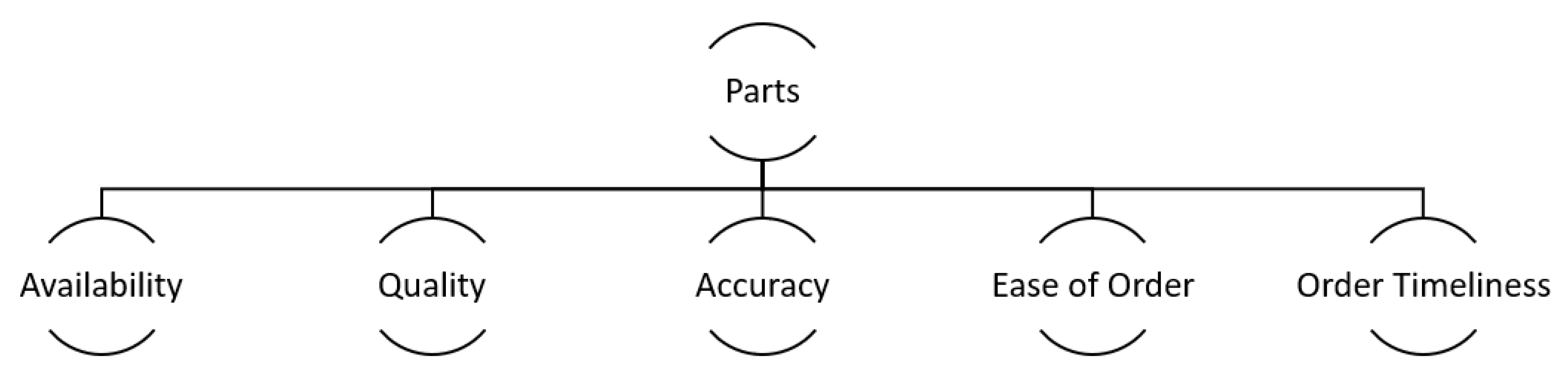
24], and clustering similar opinion–aspect pairs. We propose a two-level definition of aspects: general aspects (such as technician, staff, pricing), and more detailed aspects, such as technician knowledge, staff attitude, and pricing competitiveness (see
Figure 6 and
Figure 7).
3.3.2. Sentiment Table
The goal of this step is to build a data table, which will be in a format suitable for data mining algorithms. That way, we can adapt a new data format to our previous approach based on mining actionable knowledge to generate recommendations. The data table (as sample
Table 1) is built with the following procedure:
The attributes (columns) of the table are defined as aspects in the sentiment mining. Depending on whether we consider service surveys or parts surveys, we use the corresponding hierarchy of aspects (
Figure 6 or
Figure 7, correspondingly) to build table columns. We propose a two-level hierarchy of defining aspects, and only “leaf nodes” form columns of the table.
Each row represents a uniquely identified survey, in which feedback is given by an open-ended text.
Each cell represents a sentiment score detected towards an aspect given by a column in a survey given by the row.
3.3.3. Sentiment Score
We proposed to increase the scale of sentiment polarity from positive/negative to that in the range {−2, −1, 0, 1, 2}. We adopted a dictionary-based approach for detecting “opinion” words. We not only use simple lists of positive and negative words but also added dictionaries, such as SentiWordNet and AFINN, that assign a polarity score to words. We proposed the mapping of sentiment values assigned in the dictionaries to our discrete scale. For example, SentiWordNet uses a continuous scale <>, and the AFINN dictionary uses a discrete scale of <>. Therefore, standardization was added to our algorithm. We also added programmatically detection of words indicating strong opinions, such as “very” and “really”, to adjust the sentiment detected on opinion word. We assign polarity “0” (neutral) if the aspect is not mentioned in the comment, and the NULL value if an aspect is not applicable to the type of survey.
3.3.4. Action Rule Mining
In the constructed decision table, each survey is represented as an N-vector (where N is the number of aspects/columns) with values in the range <
>, denoting sentiment score detected in the survey towards the
nth aspect. The transformation produces a table with numerical values, which enables further to apply data mining algorithms, similarly to in the previous approach. Each survey is labeled with a category of NPS status—whether the customer expressing the opinion in the survey was labeled as a promoter, detractor, or passive. We propose to mine for action rules from the resulting “sentiment table”, with patterns in a format as given in the
Listing 2 below:
Listing 2.
A sample action rule mined from the decision table constructed based on sentiment analysis of qualitative customer feedback.
Listing 2.
A sample action rule mined from the decision table constructed based on sentiment analysis of qualitative customer feedback.
| (Service Quality: −2 -> −1), (Technician Knowledge: −1 -> 1), (Price Competitiveness: −1 -> 2) => (Detractor -> Promoter) |
The actionable patterns show how to change the customer from being an unfavorable detractor to a promoter given certain changes in sentiment towards certain aspects. We propose to combine the effects of such rules to affect the maximal number of customers given minimal business changes.
3.3.5. Recommendations and Predicted NPS Impact
The procedure of generating recommendations for improving NPS changed in comparison to the approach that used quantitative data. The recommendations are built as the sets of aspects that need to be addressed. The procedure creates the sets starting from minimal sets, adding a new aspect, and recalculating the NPS impact given action rules that contain that aspect. The revised procedure for generating recommendations (called “meta nodes”) is presented in Algorithm 2.
| Algorithm 2 Modified algorithm of generating recommendations based on text feedback data. |
- 1:
//Set current client’s ID and expand the client with HAMIS procedure - 2:
- 3:
- 4:
for clientName: clientIDmerged do - 5:
//Mine the meta-actions for each atomic action using comments in each file. - 6:
- 7:
- 8:
- 9:
- 10:
- 11:
- 12:
end for - 13:
//Build the opinion table. - 14:
- 15:
- 16:
//Reformat the action rules extracted for the current client and its extensions from the opinion table - 17:
- 18:
//Explore the action rule set and collect all existing atomic actions. - 19:
- 20:
//Iterate through rules to find meta actions associated with each rule rule: ruleset atomic: rule - 21:
for rule: ruleset do - 22:
for atomic: rule do - 23:
if then - 24:
- 25:
end if - 26:
end for - 27:
- 28:
end for - 29:
//Group meta-actions and find the best groups of meta-actions. - 30:
- 31:
|




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








