1. Introduction
In the last couple of decades, biomedical and smart healthcare research has witnessed a rapid amount of growth in terms of its presence in the literature, novel discoveries, and computational approaches, due to which a huge amount of experimental data has been generated and published (i.e., Big Data) to validate and to describe these innovations [
1]. The amount of data is so large that it is impossible for a human being to analyze and read the articles related to their desired field, and even the simple extraction of field-related published articles has become nearly impossible. As such, to utilize the information from scientific publications and articles, the increased use of automation due to the diversification and explosive growth in the healthcare literature as well as in the pharmaceutical industry is a clear representation of this growth. This is why attention has now been diverted and focused on the implementation and evolution of tools for knowledge-based discovery: the tremendous amount of biomedical research in the literature requires automation to extract, represent, interpret, and maintain this information in a refined manner.
Globally, there are different organizations that are working in the healthcare sector, with some examples being the World Health Organization (WHO), European Environment and Health Committee (EEHC), and Pan American Health Organization (PAHO). The motive of these organizations is to ensure patient safety, which is considered to be the of the highest priority, and, to achieve this purpose, these organizations are actively participating in taking legislative measures to control the adverse effects that can be avoided through the use of proper strategies and plans.
The Institute of Medicine (IOM) in the United States determined [
2,
3] that, annually, hundreds of thousands of patients die in hospitals due to quality of care issues, such as medication errors, lack of cleanliness, hospital-acquired infection, obstetrics, and DDIs that cause adverse drug reactions (ADRs) [
4,
5,
6,
7,
8]. Though there are well-established systems that are in place to maintain patient safety, the field of drug interactions require further research [
9] because recent reports indicate that drug reactions are one of a major cause of hospital-acquired conditions and readmissions [
10,
11,
12,
13,
14]. Pharmacovigilance, which was initiated by the WHO, is gaining more attention, with the literature showing that almost one tenth of the adverse reactions seen in ICU subjects are due to DDIs causing ADRs [
15,
16]. Different evaluation and automation systems are being used for ADR detection in different medicines, but, in most cases, reports of ADRs are investigated and revealed by the healthcare professionals quite a bit later.
The motive of this research is to create new strategies in already-working systems for the detection of DDIs from the medical literature, considering ‘big data’. By definition, one drug may decrease or increase the effect of another because of its mutual chemical formulation, a phenomenon known as a DDI [
17,
18,
19]. Information on DDIs is highly important and relevant for restricting the failures of therapeutic treatments and to prevent other strong ADRs. Though DDIs could be very dangerous, this is not true in all cases, and these interactions can be effective in certain cases where they provide a desirable synergistic effect [
20]. Therefore, we are interested in determining the severity of a DDI by processing the same text used for the detection of DDIs. This aspect will help clinical decision support systems in making more accurate and informed decisions by ensuring the safety of the patients. This would not only save the lives of humans, but it would also result in a huge decrease in healthcare costs as well.
DDI has an immense impact on patients’ safety and therefore it needs to be tackled seriously. There has been a rapid increase in the development of novel technologies and expert systems in the domain of healthcare and medicine. With the passage of time, the need for integrated approaches and evidence-based healthcare is increasing at a very high rate. On the flip side, size as well as heterogeneity and complexity of data generated by several sources are a big challenge to the computational approaches [
21,
22,
23,
24]. Making sense of huge biomedical text is a challenge for healthcare research [
25]. Unstructured text constitutes the most important form of data in the healthcare and medical domains. Though this form of data is very difficult to process, but it contains many elaborations, nuances, and details that could not be captured in the thesaurus of nomenclature, but this information could be very useful in decision-making [
26]. Dealing with this growing unstructured information requires machine learning techniques and methods in order to bring structure and extract meaningful insights [
27].
There are many specialized databases (i.e., Drug Bank, Micromedex, MEDLINE) which contain known DDIs. These DDI pairs are limited in coverage as new discoveries are made and published as research articles. Consequently, there is an ultimate need for extraction of newly discovered DDI in the scientific literature [
28,
29]. Text mining is known as one of the best available techniques that can be applied to achieve automatic relation extraction from the published literature and articles. Text mining is being used widely for relation extraction, for instance protein–protein interactions (PPIs) and gene–disease relationships, and therefore a corpus [
30] is formed specifically for the DDI extraction task [
31,
32,
33]. The DDI extraction task is very similar to relationship extraction studied in depth in the text-mining domain as shown in
Figure 1. This figure presents the working of the relationship extraction task with the demonstration of practical examples. In the processed sentence, each drug is labelled initially, such as subject and object. After obtaining pairs of drugs, the relationship among the drugs is investigated and if a pair of drugs is involved in increasing or decreasing the effect of the other, it would be classified as a positive DDI pair, as shown with solid lines in the presented example. While negative DDI pairs (i.e., drugs having no effect on each other) are shown with dotted lines.
In
Figure 1, the complex structure of DDIs is presented with two practical real examples including clauses of positive and negative DDIs represented with solid and dotted lines, respectively.
- (a)
Examples of positive DDIs with multiple subjects (drugs) to one object. In this scenario, subjects do not have any interaction with each other but only with the object.
- (b)
Represents one drug as a subject and two drugs as objects. In this case, there is surely a connection between the subject and object individually and to the cluster of objects, but no interaction between object drugs.
4. Data, Experimental Parameters, and Results
DDIExtraction-2013 corpus [
22] which is constituted with the prescriptions of Drug Bank and the abstracts of PubMed articles are stored in MEDLINE corpora. It constitutes with manually annotated 18,502 pharmacological substances along with 5028 DDI pairs; statistics of the dataset is shown in
Table 2.
The annotated representation of this corpus with sentences and all possible instances, i.e., drug pairs, is shown in
Figure 4. For a sentence, all instances may be ‘false’, as a drug pair is shown in
Figure 4 with a black dotted block. On the contrary, a reported interaction between a pair of drugs is indicated with ‘true’, as presented in
Figure 4 with a red rectangle block. There could be more than one ‘true’ and ‘false’ instance for a single sentence and all could be either true or false.
We used this corpus for training and testing of the model. The documents were initially pre-processed and stored in pickle files for training and testing of the model. The parameters of the DDI classification experiment are shown in
Table 3. The rest of the parameters which are not shown in the table are kept as default settings as in TensorFlow [
49].
Precision, recall and the f-measure are used for the DDI extraction task and are calculated by Formulas (6)–(8), respectively. The results of the DDI classification and severity identification are shown in
Table 4, and comparison with state-of-the-art systems is also presented.
Consequently, the task of extracting severity from the DDI’s text is applied. The severity prediction mechanism is applied by implementing Algorithm 1 and applying it on the DDIExtraction-2013 dataset. We collected 4672 sentences from the DrugBank corpora and 327 from MEDLINE involving 9000 distinct drugs and 4999 DDIs. In the algorithm, Pol
pos and Pol
neg represent the positive and negative polarity of the words, respectively. After summing up all the polarities of the words, the final polarity of the sentence is calculated by subtracting Pol
neg from Pol
pos. Based on the final polarity of sentence, each DDI instance is assigned with a label of severity, as elaborated in Algorithm 1. The performance of the system is shown in
Table 4, illustration of severity in
Table 5, while
Table 6 shows the categorized statistics of the DrugBank and MEDLINE corpus with the extracted degree of severity presented in the text.
| Algorithm 1: Severity Prediction in Drug–Drug Interaction. |
- 1:
The text is split for each DDI instance. Each sentence is addressed separately. - 2:
Each sentence is pre-processed and normalized using the NLTK tool kit. - 3:
Each sentence is processed using SentiWordNet and the polarity of words is extracted and summed into Pol pos and Pol neg for positive and negative polarity, respectively. - 4:
Final polarity is calculated as: Final-Polarity = Pol pos–Pol neg - 5:
The final polarity is split into two sets, i.e., Beneficial and Dangerous: - 6:
if Final-Polarity ≥ 0 then: - 7:
DDI instance is Beneficial. - 8:
else - 9:
DDI instance is Dangerous. - 10:
end if - 11:
Categorization of Beneficial and Dangerous instances into levels of severity. - 12:
For each instance in Beneficial: - 13:
if Final-Polarity is 0 to 0.2, then DDI is lightly beneficial. - 14:
else if Final-Polarity is 0.3 to 0.6, then DDI is moderately beneficial. - 15:
else DDI is highly beneficial. - 16:
end if - 17:
end for - 18:
For each instance in Dangerous: - 19:
if Final-Polarity is 0 to −0.2, then DDI is lightly dangerous. - 20:
else if Final-Polarity −0.3 to −0.6, then DDI is moderately dangerous. - 21:
else DDI is highly dangerous. - 22:
end if - 23:
end for
|
4.1. Results and Discussion
The performance of the model is compared with state-of-the-art models for the DDI extraction task in
Table 4. Our method outperformed in all three metrics of precision, recall and f-score. Each of these three metrics are critically important in biomedical-related tasks and particularly in DDI extraction, our model scored more than 80% in all three metrics, i.e., 83.81, 81.59, 82.68 in precision, recall and f-measure, respectively. To the best of our knowledge, none of the other systems achieved this milestone at the latest timepoint.
The improvement in the overall performance in the DDI-Extraction task, as mentioned in
Table 4, is due to addition of the attention mechanism and bidirectional LSTM. The attention mechanism provided better features in the training which were involved in most of the interactions, and the dominance of these words with respect to each candidate drug is also enhanced. Consequently, employment of LSTM from both ends of the sentence resolved the issue of bias which was critical in the DDI extraction task where most significant words could be anywhere in a sentence, i.e., before, after or around the subject. Every word in a sentence achieved equal dominance regardless of its placement in the sentence which was proven to attain more accurate prediction in DDI extraction and classification, as results illustrated.
In the severity extraction task, all the DDI-related sentences are categorized in mild, moderate, or severe levels of interaction.
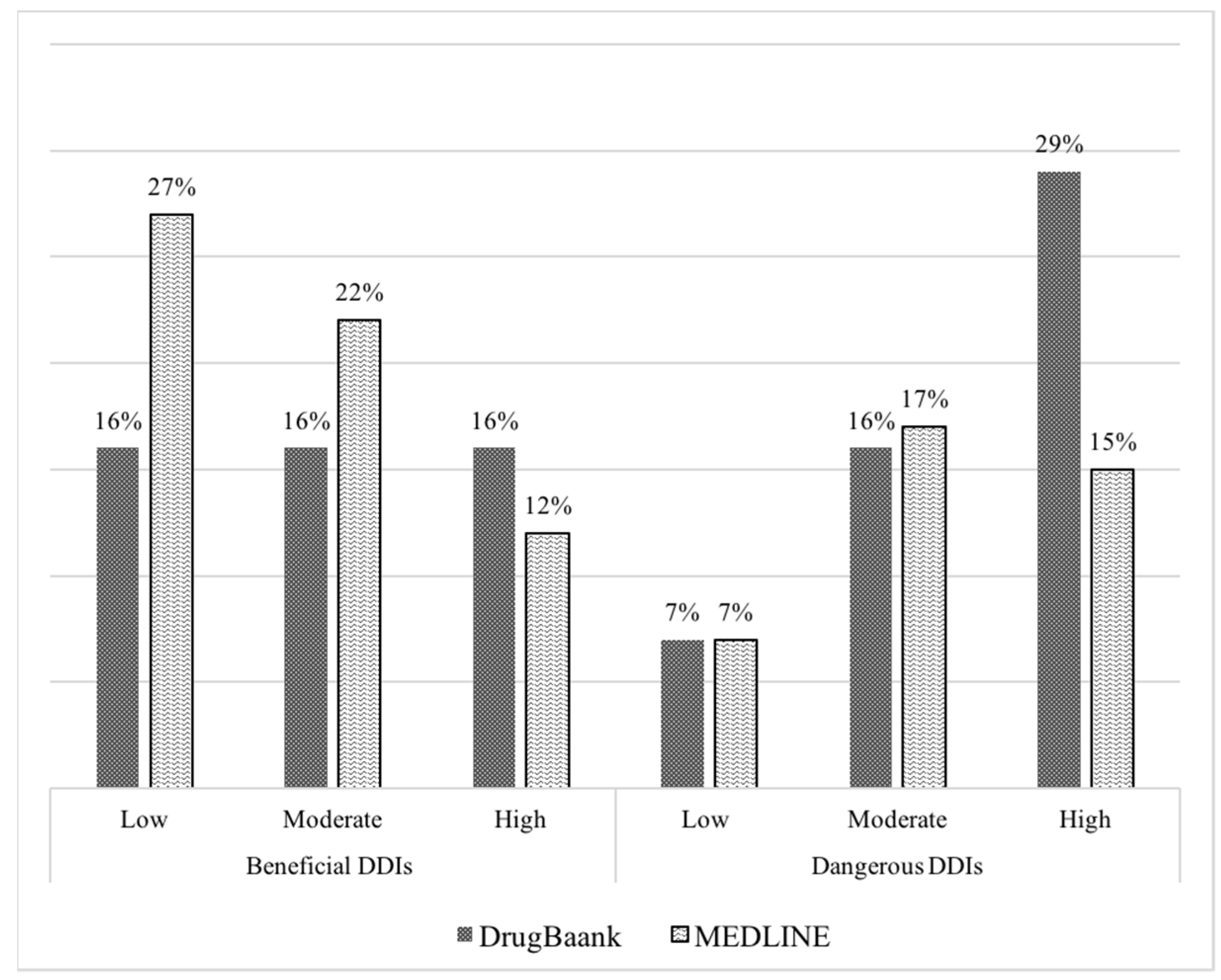
Table 5 illustrates the categorization of DDIs at a level or degree of severity where examples of DDIExtraction-2013 are shown with their degree of severity in an interaction based on the polarity of the sentences; positive sentiments in the DDI related sentence are considered to have mild interaction in which pharmacologists or experts recommended some drugs to be taken together for safety or curing some disease, whereas a moderate level of severity is allocated to those DDIs whose polarity was neutral, i.e., where the experts have described some mechanisms or a weak impact on other drugs. A severe level of interaction is derived from the negative sentiments where clinical experts showed danger and provided advice of careful monitoring or showed some significant effect of one drug on others. The DDI categorization statistics are shown in
Table 6.
We can claim this categorization is accurate by analyzing
Figure 5, which presents the statistics of the performance of the DDI classification task by existing systems on Drug Bank and MEDLINE separately. It clearly shows that the performance of all the models remains low on MEDLINE, as compared to the Drug Bank, and none of the existing models achieved better performance on MEDLINE than on DrugBank.
DrugBank has articles with less ambiguity and shows clear interaction in the text; many already implemented models showed excellent performance when applied only to the DrugBank corpus as compared to when applied to MEDLINE. Co-relating this emphasis with our extracted severity, our system categorized 36% DDIs of DrugBank as being highly interactive, whereas just 27% of the MEDLINE’s DDIs were reported to have high interactivity.
On the contrary, articles of MEDLINE corpora are less expressive and have quite long and complex sentence structuring in reporting an interaction. Many of the state-of-the-art systems showed very poor performance on the MEDLINE corpus as compared to on DrugBank.
Figure 6 shows statistical analysis regarding the performance of models on the corpuses of DrugBank and MEDLINE. It clearly shows that all the implemented models failed to achieve better performance on MEDLINE than on DrugBank, even some of the models showed very bad performance on MEDLINE, while showing excellent results on the corpus of DrugBank.
It proves that articles in the corpus of MEDLINE contain huge complexity in expressing the relationship of DDIs. That is why it always remained quite challenging for any model to perform better on the MEDLINE corpus for extraction and classification of DDIs.
Similarly, our severity extraction model also showed a much lower percentage of DDIs with high severity on both ends on the MEDLINE corpora than on DrugBank, i.e., 36% and 27% on DrugBank and MEDLINE, respectively. Alternatively, low and moderate levels of severity remained dominant in prediction with 34% and 39% of the MEDLINE corpus, compared with the predictions of DrugBank showing 22% and 32% of DDIs for mild and moderated levels of severity as shown in
Figure 6.
Prediction of the degree of severity on the overall DDIExtraction-2013 [
22] corpus is shown in
Table 7. In our extracted ratings, about 44% of the DDIs in DDIExtraction-2013 are highly interactive ones, 24% of them show low interactivity and 32% of the interactions are of a moderate level. These results may vary a little in the perspective of pharmaceutical interactions, because these interactions are categorized on the basic of polarity of the sentences, which were used to report an interaction or the consequences of the interaction of the articles.
The prediction and annotation of a DDI’s severity by a pharmaceutical and healthcare expert could vary a little from our prediction. However, it is quite challenging for an expert to categorize the huge number of pairs in the levels of severity. The addition of severity concerning the DDIs in clinical healthcare and pharmaceutical expert systems could be very promising in making more precise and accurate prescriptions. It could also be very beneficial in reducing ADRs, which is one of the major causes of healthcare costs and hospital-acquired conditions and readmissions.
5. Conclusions
In this paper, we propose a hierarchal attention-based LSTM neural network model to improve the classification performance of drug–drug interaction tasks. Our model outperformed all the existing methods in overall performance as well as recall metrics. The method achieved 83.81%, 81.59% and 82.68% in the evaluation metrics of precision, recall and f1-measure, respectively. To the best of our knowledge, none of the existing models achieved more than an 80% threshold in all three metrics when applied on the DDIExtraction-2013 benchmark.
Beyond improving accuracy, we employed severity extraction mechanism for the DDIs which are reported and classified as positive DDIs (true interactions) by our model. From the reported text of DDIs in the literature, we extracted severity of each interaction employing sentiment analysis strategy. We investigated the severity of interaction by calculating the polarity of the text used to report an interaction. This mechanism helped us to formulate a new dataset regarding the DDI’s severity extraction task. Consequently, the prediction of the severity extraction mechanism is evaluated and investigated by applying different analysis based on the DDI classification task applied on DrugBank and MEDLINE separately.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}