
We Know You Are Living in Bali: Location Prediction of Twitter Users Using BERT Language Model


Abstract
:1. Introduction
2. Related Work
3. Problem Formulation
4. Methodology
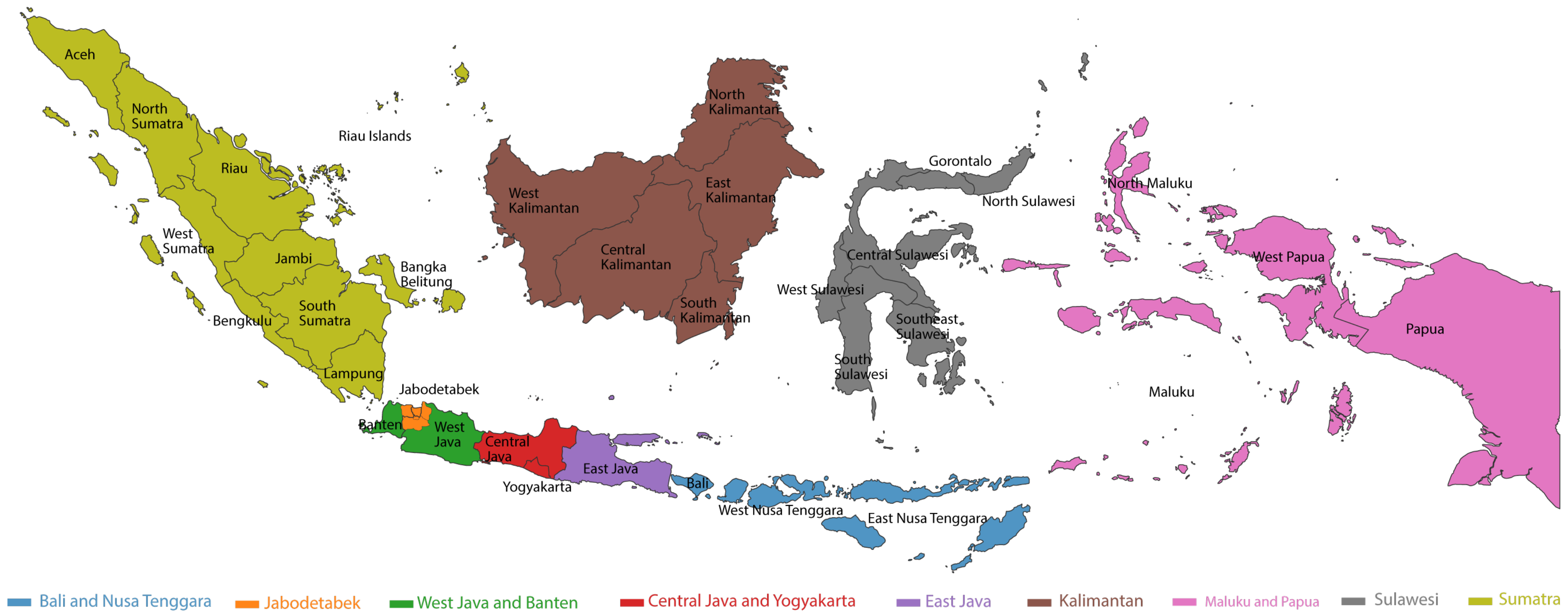
4.1. Data Collection and Annotation
4.2. Data Preprocessing
4.3. Feature Extraction
- Display nameThe display name can be used as a feature to predict users location. This is because in Indonesia, there are some cases where people’s names can identify their location. Here, people from the same islands/provinces can have similar names that are specific to that region. For example, people in Bali have a common naming system based on caste, gender, and birth order within the family [53]. For example, the name of a first child of the Sudra caste in Bali usually includes the word “Wayan” in his name. Another example is that some ethnic groups in several Indonesian regions including Sumatra, Sulawesi, Maluku, and Papua also use specific clan/family naming systems [54]. In this sense, people from the same ethnic group and from the same place can have the same surname. For example, Simanjuntak is a surname that comes from North Sumatra province, so someone with the surname Simanjuntak is more likely to live in Sumatra than other regions. Likewise, clans such as Wangkar, Tangkudung, and Sondakh tend to live in Sulawesi.In addition, the display names of nonperson accounts, such as local governments and businesses, in some cases also include location names. The @Sulselprov account, for example, includes the location name in its display name, i.e., Pemerintah Provinsi Sulawesi Selatan (South Sulawesi Provincial Government), where Sulawesi Selatan is a location entity. All of these cases indicate that display names may be useful for predicting the user’s home location.
- User descriptionThe user description can also be used as a feature for predicting users location. Nonperson, i.e., organization account, profiles usually contain a detailed description of their organization and their address. Consequently, user descriptions, particularly those for organizational accounts, are suitable to predict the user’s location.
- TweetA user tweet covering a wide range of topics may be able to describe the user’s general profile, including the user’s location. This is because users tend to post tweets about their activities, interests, and nearby events that may explicitly contain location information or implicitly provide information about where they live. Therefore, tweets are important features to a user’s location.
4.4. Model Building
4.4.1. Naïve Bayes
4.4.2. Support Vector Machine
4.4.3. Logistic Regression
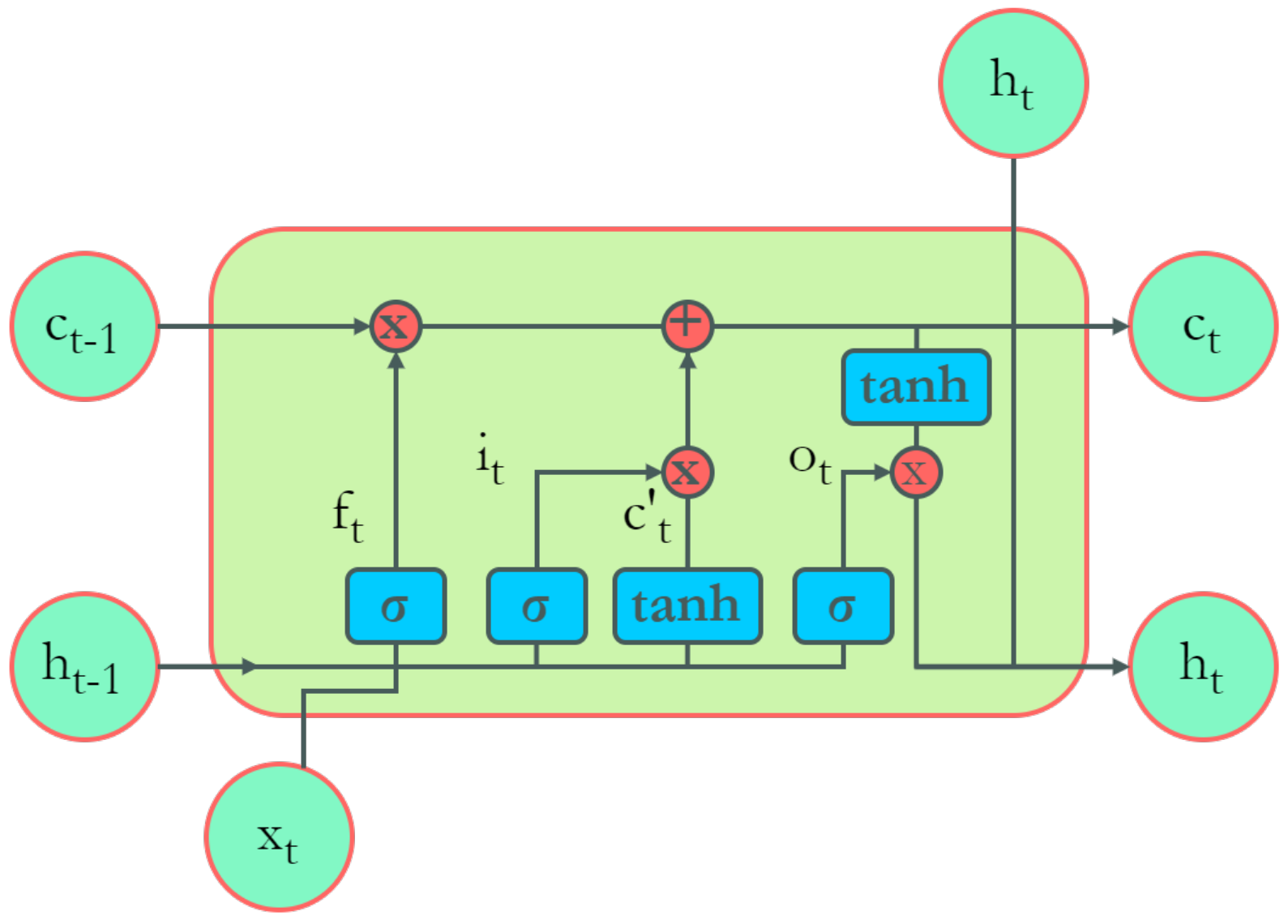
4.4.4. Long Short-Term Memory
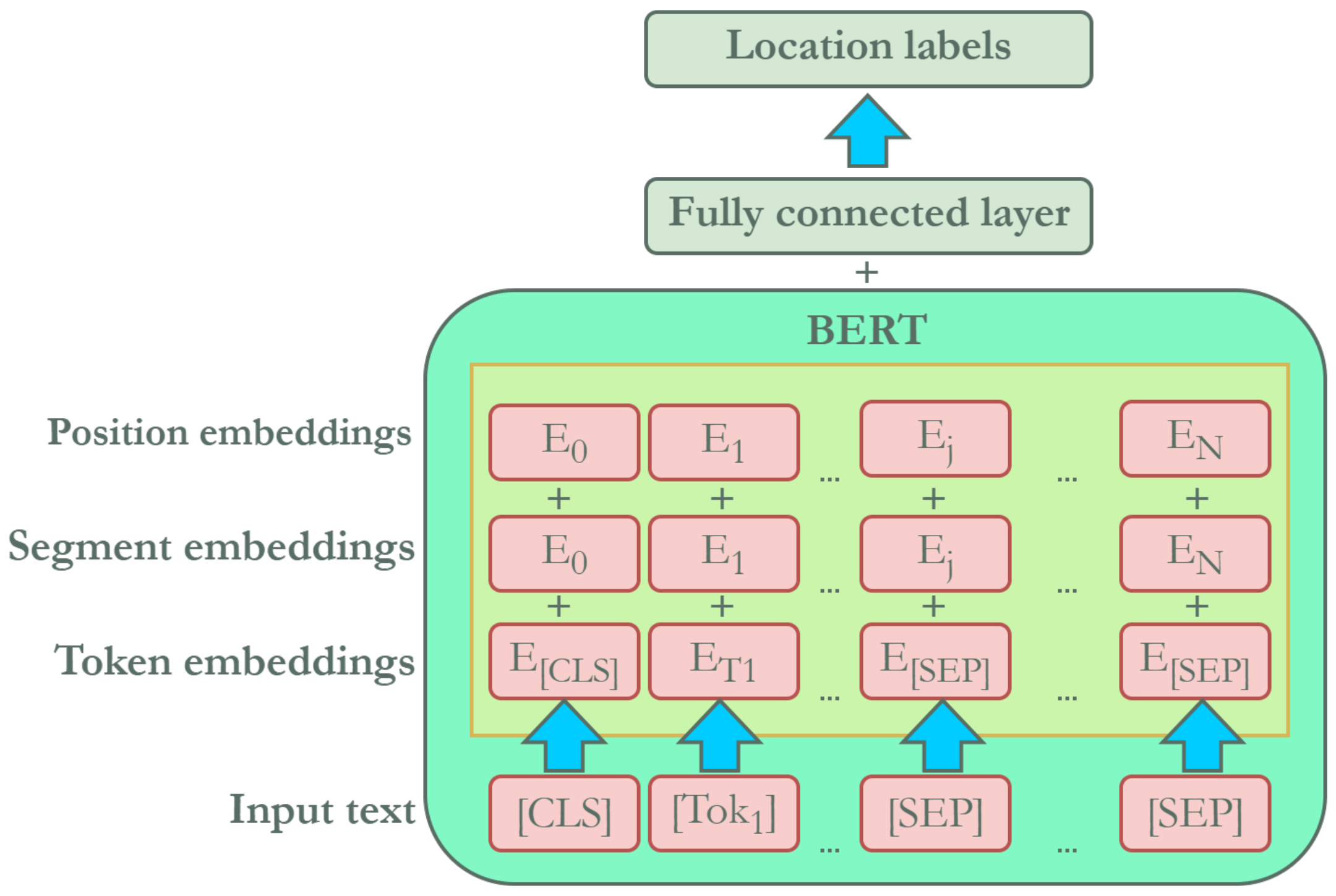
4.4.5. IndoBERT
5. Experiment
- (i)
- Display name experiment: Each display name was treated as a TF-IDF bag of word unigrams, and predictions were made with naïve Bayes, support vector machine, and logistic regression.
- (ii)
- User description experiment: As per the previous experiment, the user description was also treated as a TF-IDF bag of word unigrams and the same three machine learning algorithms were applied.
- (iii)
- Tweets experiment: In addition to the three machine learning algorithms, we also implemented LSTM and BERT, as mentioned in Section 4.3. In this step, we discuss two scenarios:
- (a)
- Majority vote: The location of the tweet was predicted separately and we determined the user’s location by majority vote.
- (b)
- Tweet aggregation as one: We aggregated all user tweets into one text for each user and then made user-level predictions.
- (iv)
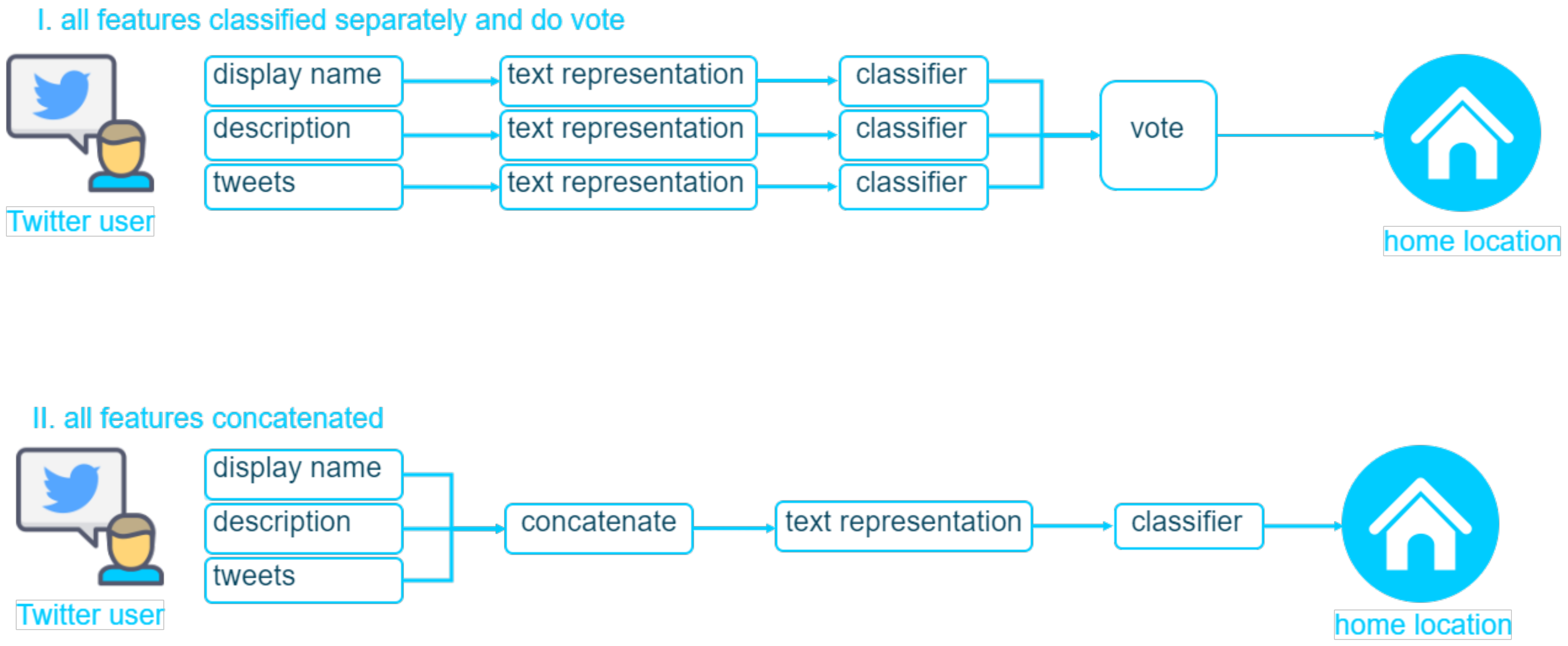
- All features experiment: Using all features, i.e., display name, user description, and user tweets, we applied two approaches to predict the user’s location.
- Predict and voteWe combined the best prediction results from display name experiment (i), description experiment (ii), and tweets experiment (iii). We stored the best prediction results with each experiment and had the majority vote as the final result. If the prediction results for the three experiments were different, we set the tweet prediction result as the default. For example, a user was predicted to be in Bali and Nusa Tenggara in display name experiment (i) and description experiment (ii), but in Maluku and Papua in tweet experiment (iii). Since the first two results indicate that the user is located in Bali and Nusa Tenggara, the majority voting result indicates that the user is in Bali and Nusa Tenggara.
- Concatenate and predictIn this experiment, we performed the concatenation of the display name, user description, and tweets to make predictions. Two approaches similar to the tweet-only experiments (iii) were used, namely, majority vote and tweet aggregation as one. The majority voting method combines each user’s display name, description, and tweet as a single text. The user’s home location was predicted for each text. Since there are 100 tweets for each user, there are 100 predictions for each user. We then determined the user’s location by applying the majority vote. On the other hand, the aggregation approach combines a user’s display name, description, and all aggregated tweets into a single text to enable user-level prediction. This results in one prediction for each user.Since we used IndoBERT and IndoBERTweet models that rely on the context in the text, before concatenating all the features (display name, description, and tweets), we made sure they had context information. The display name is a short text string containing only the user’s name, so we added context before combining the display name with the description and tweets. The context is “nama saya adalah ” (my name is ). The display name was then concatenated with the description and the tweet, which already has context. Each user’s display name, description, and individual tweet were treated as sentences separated by a period.
- (v)
- Experiment with NER: We extracted the named entities from each attribute in display name experiment (i), user description experiment (ii), and tweets experiment (iii). Each entity was duplicated and returned to the original text. We then performed classifications as in display name experiment (i), description (ii), tweet experiment (iii), and all features experiment (iv).
- (vi)
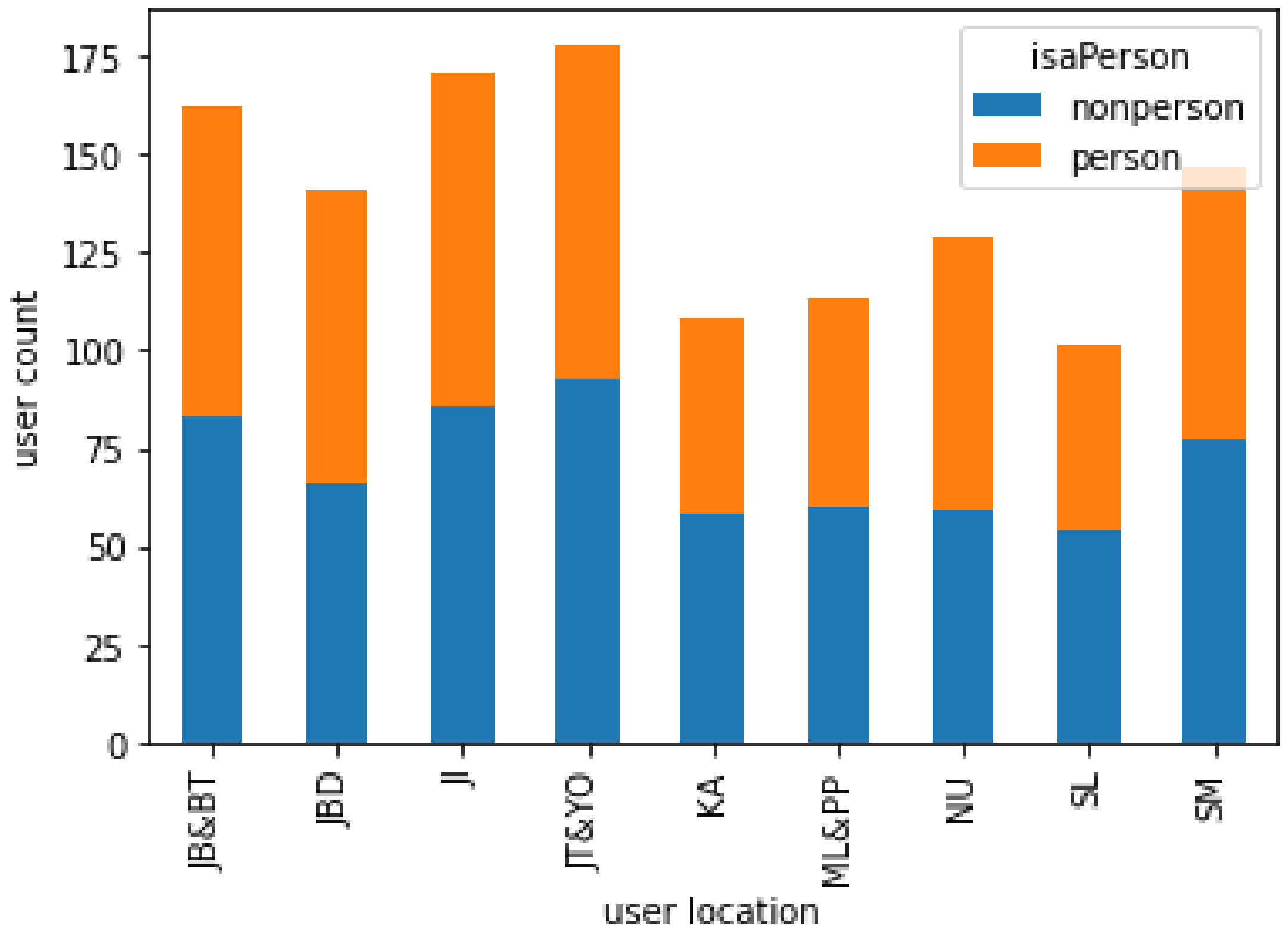
- Cross-testing experiment: Using the best results from the previous experiment, we attempted to determine the difference in location prediction between individuals and organizational users. We divided the data into three categories: (1) person, consisting of human user data only; (2) nonperson, consisting of organizational data only; and (3) all, consisting of both human and organizational data. We conducted training separately on person and nonperson data. We tested the training results for person data on nonperson and all data. We then performed the cross-test; i.e., we tested the results of nonperson on person and all.
6. Results
6.1. Results Using Only Display Name
6.2. Results Using Only User Description
6.3. Results Using Only User Tweets
6.3.1. Majority Vote
6.3.2. Tweet Aggregation into One Text
6.4. Results Using Display Name, User Description, and User Tweets
6.5. Results with NER
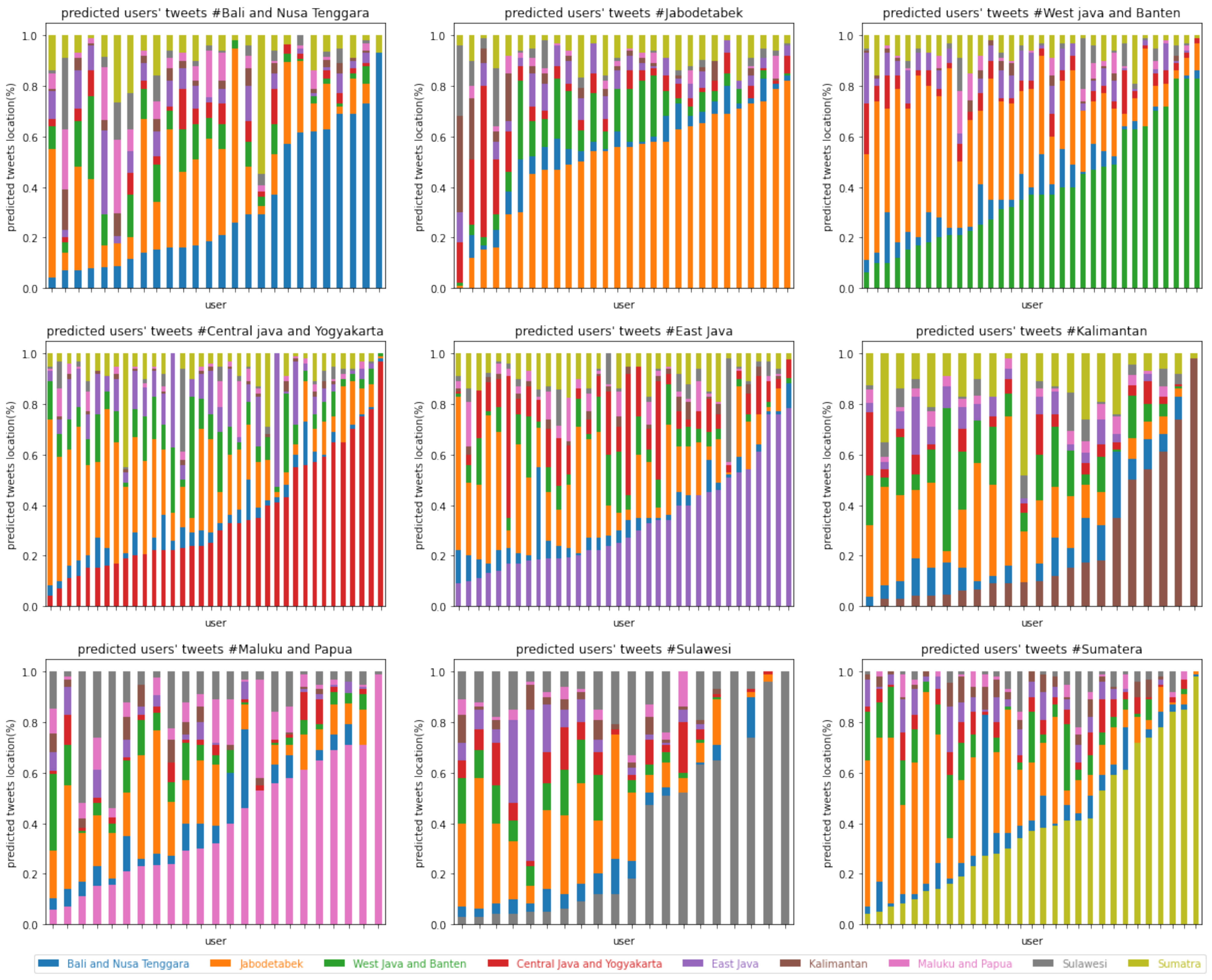
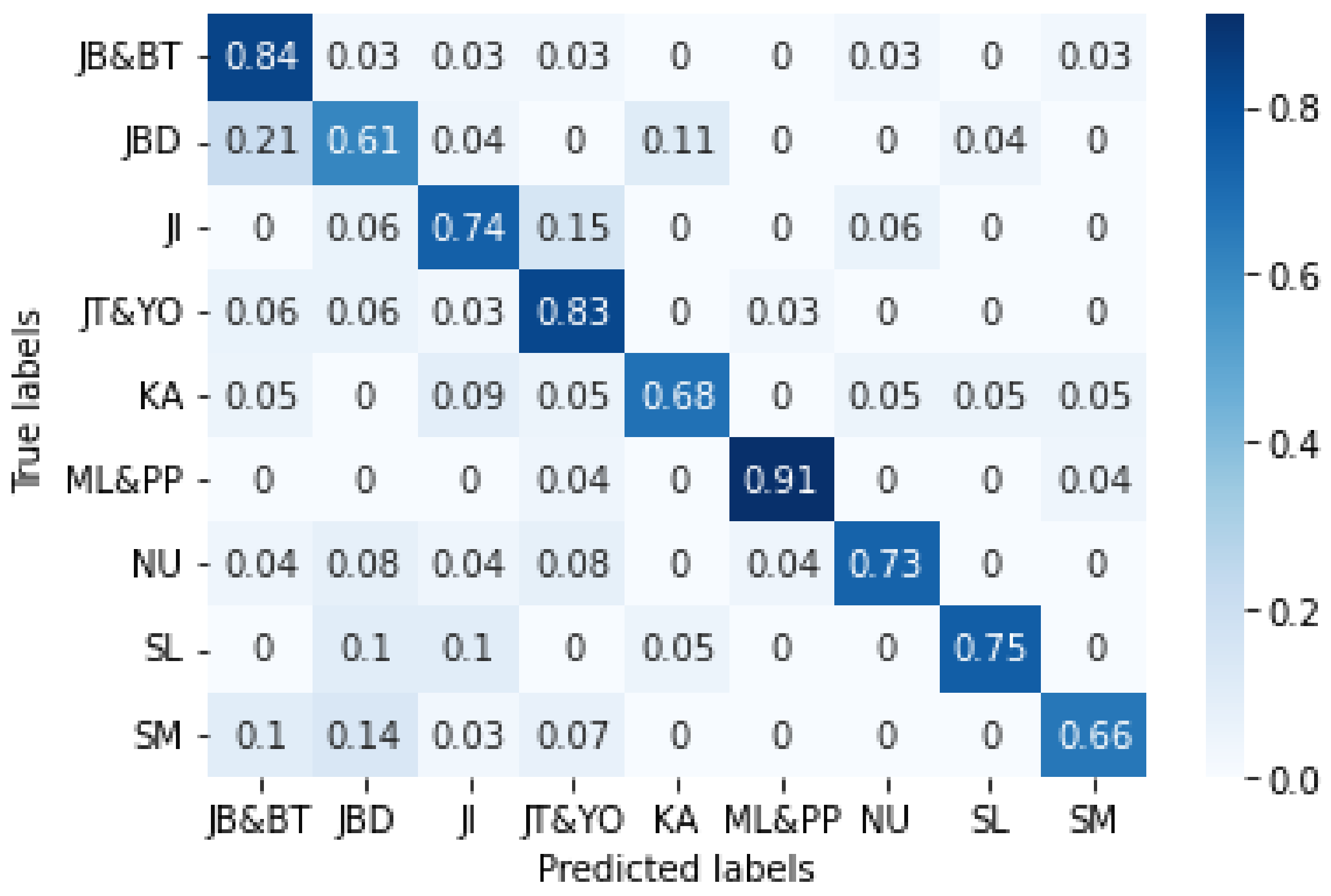
6.6. Cross-Testing Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Model Hyperparameters
Appendix A.1. Naïve Bayes
- alpha = 1.0
- fit_prior = True
- class_prior = None
Appendix A.2. Support Vector Machine
- C = 1.0
- gamma = ‘scale’
- kernel = ‘rbf’
Appendix A.3. Logistic Regression
- penalty = l2
- C = 1
- solver = ‘lbfgs’
- multi_class = ‘multinomial’
Appendix A.4. Long Short-Term Memory
- embedding size = 200
- batch size = 128
- drop out rate = 0.25
- optimizer = AdamW
- learning rate =
Appendix A.5. BERT
- max sequence length = 280 (majority vote), 512 (aggregate)
- batch size = 16
- epochs = 7
- attention drop out rate = 0.3
- hidden layers drop out rate = 0.3
- optimizer = AdamW
- learning rate =
References
- Most Popular Social Networks Worldwide as of January 2022, Ranked by Number of Monthly Active Users. Available online: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (accessed on 25 May 2022).
- Twitter Usage Statistics. Available online: https://www.internetlivestats.com/twitter-statistics/ (accessed on 20 November 2021).
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016); Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 1–18. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Sobhani, P.; Kiritchenko, S. Stance and Sentiment in Tweets. ACM Trans. Internet Technol. 2017, 17, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Anastasia, S.; Budi, I. Twitter sentiment analysis of online transportation service providers. In Proceedings of the 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; pp. 359–365. [Google Scholar]
- Kanugrahan, G.; Wicaksono, A.F. Sentiment Analysis of Face-to-face Learning during Covid-19 Pandemic using Twitter Data. In Proceedings of the 2021 8th International Conference on Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Bandung, Indonesia, 29–30 September 2021; pp. 1–6. [Google Scholar]
- Kaunang, C.P.S.; Amastini, F.; Mahendra, R. Analyzing Stance and Topic of E-Cigarette Conversations on Twitter: Case Study in Indonesia. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021; pp. 304–310. [Google Scholar]
- Nababan, A.H.; Mahendra, R.; Budi, I. Twitter stance detection towards Job Creation Bill. Procedia Comput. Sci. 2022, 197, 76–81. [Google Scholar] [CrossRef]
- Waseem, Z.; Hovy, D. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 88–93. [Google Scholar] [CrossRef]
- Watanabe, H.; Bouazizi, M.; Ohtsuki, T. Hate Speech on Twitter: A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech Detection. IEEE Access 2018, 6, 13825–13835. [Google Scholar] [CrossRef]
- Buntain, C.; Golbeck, J. Automatically Identifying Fake News in Popular Twitter Threads. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 208–215. [Google Scholar] [CrossRef] [Green Version]
- Ibrohim, M.O.; Budi, I. Multi-label Hate Speech and Abusive Language Detection in Indonesian Twitter. In Proceedings of the Third Workshop on Abusive Language Online; Association for Computational Linguistics: Florence, Italy, 2019; pp. 46–57. [Google Scholar] [CrossRef] [Green Version]
- Widaretna, T.; Tirtawangsa, J.; Romadhony, A. Hoax Identification on Tweets in Indonesia Using Doc2Vec. In Proceedings of the 2021 9th International Conference on Information and Communication Technology (ICoICT), Yogyakarta, Indonesia, 4–5 August 2021; pp. 456–461. [Google Scholar] [CrossRef]
- Faisal, D.R.; Mahendra, R. Two-Stage Classifier for COVID-19 Misinformation Detection Using BERT: A Study on Indonesian Tweets. arXiv 2022. [Google Scholar] [CrossRef]
- D’Andrea, E.; Ducange, P.; Lazzerini, B.; Marcelloni, F. Real-time detection of traffic from twitter stream analysis. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2269–2283. [Google Scholar] [CrossRef]
- Hanifah, R.; Supangkat, S.H.; Purwarianti, A. Twitter Information Extraction for Smart City. In Proceedings of the 2014 International Conference on ICT For Smart Society (ICISS), Bandung, Indonesia, 24–25 September 2014; pp. 295–299. [Google Scholar]
- Putra, P.K.; Mahendra, R.; Budi, I. Traffic and Road Conditions Monitoring System Using Extracted Information from Twitter. J. Big Data 2022, 9, 65. [Google Scholar] [CrossRef]
- Carley, K.M.; Malik, M.; Landwehr, P.M.; Pfeffer, J.; Kowalchuck, M. Crowd sourcing disaster management: The complex nature of Twitter usage in Padang Indonesia. Saf. Sci. 2016, 90, 48–61. [Google Scholar] [CrossRef] [Green Version]
- Interdonato, R.; Guillaume, J.L.; Doucet, A. A lightweight and multilingual framework for crisis information extraction from Twitter data. Soc. Netw. Anal. Min. 2019, 9, 65. [Google Scholar] [CrossRef]
- Alam, F.; Qazi, U.; Imran, M.; Ofli, F. HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks. In Proceedings of the Fifteenth International AAAI Conference on Web and Social Media, ICWSM, Virtually, 7–10 June 2021; AAAI Press: Palo Alto, CA, USA, 2021; pp. 933–942. [Google Scholar]
- Chen, E.; Lerman, K.; Ferrara, E. Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Dataset. JMIR Public Health Surveill. 2020, 6, e19273. [Google Scholar] [CrossRef]
- Chew, C.; Eysenbach, G. Pandemics in the Age of Twitter: Content Analysis of Tweets during the 2009 H1N1 Outbreak. PLoS ONE 2020, 5, e14118. [Google Scholar] [CrossRef]
- Nikam, R.; Bhokare, R.; Chavan, S.; Sonawane, R.; Adhav, D. Location Based Fake News Detection using Machine Learning. iJRASET 2021, 9, 1549–1553. [Google Scholar] [CrossRef]
- Wakamiya, S.; Kawai, Y.; Aramaki, E. Twitter-Based Influenza Detection After Flu Peak via Tweets with Indirect Information: Text Mining Study. JMIR Public Health Surveill. 2018, 4, e65. [Google Scholar] [CrossRef]
- Almatrafi, O.; Parack, S.; Chavan, B. Application of Location-Based Sentiment Analysis Using Twitter for Identifying Trends Towards Indian General Elections 2014. In Proceedings of the 9th International Conference on Ubiquitous Information Management and Communication, Bali, Indonesia, 8–10 January 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Yaqub, U.; Sharma, N.; Pabreja, R.; Chun, S.A.; Atluri, V.; Vaidya, J. Location-Based Sentiment Analyses and Visualization of Twitter Election Data. Digit. Gov. Res. Pract. 2020, 1, 1–19. [Google Scholar] [CrossRef]
- Arafat, T.A.; Budi, I.; Mahendra, R.; Salehah, D.A. Demographic Analysis of Candidates Supporter in Twitter During Indonesian Presidential Election 2019. In Proceedings of the 2020 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, 19–20 November 2020; pp. 1–6. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K. You Are Where You Tweet: A Content-Based Approach to Geo-Locating Twitter Users. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–5. [Google Scholar] [CrossRef]
- Roller, S.; Speriosu, M.; Rallapalli, S.; Wing, B.; Baldridge, J. Supervised Text-based Geolocation Using Language Models on an Adaptive Grid. In Proceedings of the the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 1500–1510. [Google Scholar]
- Han, B.; Cook, P.; Baldwin, T. Geolocation Prediction in Social Media Data by Finding Location Indicative Words. In Proceedings of the COLING, Mumbai, India, 8–15 December 2012; The COLING 2012 Organizing Committee: Mumbai, India, 2012; pp. 1045–1062. [Google Scholar]
- Han, B.; Rahimi, A.; Derczynski, L.; Baldwin, T. Twitter Geolocation Prediction Shared Task of the 2016 Workshop on Noisy User-generated Text. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 213–217. [Google Scholar]
- Leading Countries Based on Number of Twitter Users as of January 2022. Available online: https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/ (accessed on 30 May 2022).
- Han, B.; Cook, P.; Baldwin, T. Text-Based Twitter User Geolocation Prediction. J. Artif. Intell. Res. 2014, 49, 451–500. [Google Scholar] [CrossRef]
- Izbicki, M.; Papalexakis, V.; Tsotras, V. Geolocating Tweets in Any Language at Any Location. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 89–98. [Google Scholar] [CrossRef]
- Qian, C.; Yi, C.; Cheng, C.; Pu, G.; Liu, J. A Coarse-to-Fine Model for Geolocating Chinese Addresses. ISPRS Int. J. Geo-Inf. 2020, 9, 698. [Google Scholar] [CrossRef]
- Scherrer, Y.; Ljubešić, N. HeLju@VarDial 2020: Social Media Variety Geolocation with BERT Models. In Proceedings of the 7th Workshop on NLP for Similar Languages, Varieties and Dialects, Barcelona, Spain, 13 December 2020; International Committee on Computational Linguistics (ICCL): Praha, Czech Republic, 2020; pp. 202–211. [Google Scholar]
- Indira, K.; Brumancia, E.; Kumar, P.S.; Reddy, S.P.T. Location Prediction on Twitter Using Machine Learning Techniques. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 700–703. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Wilie, B.; Vincentio, K.; Winata, G.I.; Cahyawijaya, S.; Li, X.; Lim, Z.Y.; Soleman, S.; Mahendra, R.; Fung, P.; Bahar, S.; et al. IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 843–857. [Google Scholar]
- Koto, F.; Rahimi, A.; Lau, J.H.; Baldwin, T. IndoLEM and IndoBERT: A Benchmark Dataset and Pretrained Language Model for Indonesian NLP. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: Praha, Czech Republic, 2020; pp. 757–770. [Google Scholar] [CrossRef]
- Koto, F.; Lau, J.H.; Baldwin, T. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effective Domain-Specific Vocabulary Initialization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 10660–10668. [Google Scholar] [CrossRef]
- Hecht, B.; Hong, L.; Suh, B.; Chi, E.H. Tweets from Justin Bieber’s Heart: The Dynamics of the Location Field in User Profiles. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 237–246. [Google Scholar] [CrossRef]
- Rahimi, A.; Vu, D.; Cohn, T.; Baldwin, T. Exploiting Text and Network Context for Geolocation of Social Media Users. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1362–1367. [Google Scholar] [CrossRef] [Green Version]
- Rahimi, A.; Cohn, T.; Baldwin, T. A Neural Model for User Geolocation and Lexical Dialectology. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 209–216. [Google Scholar] [CrossRef]
- Miura, Y.; Taniguchi, M.; Taniguchi, T.; Ohkuma, T. A Simple Scalable Neural Networks based Model for Geolocation Prediction in Twitter. In Proceedings of the 2nd Workshop on Noisy User-generated Text (WNUT), Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 235–239. [Google Scholar]
- Miura, Y.; Taniguchi, M.; Taniguchi, T.; Ohkuma, T. Unifying Text, Metadata, and User Network Representations with a Neural Network for Geolocation Prediction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1260–1272. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Han, J.; Sun, A. A Survey of Location Prediction on Twitter. IEEE Trans. Knowl. Data Eng. 2018, 30, 1652–1671. [Google Scholar] [CrossRef] [Green Version]
- Total Population Projection Result by Province and Gender (Thousand People), 2018–2020. Available online: https://www.bps.go.id/indicator/12/1886/1/jumlah-penduduk-hasil-proyeksi-menurut-provinsi-dan-jenis-kelamin.html (accessed on 21 November 2021).
- Mahendra, R.; Putra, H.S.; Faisal, D.R.; Rizki, F. Gender Prediction of Indonesian Twitter Users Using Tweet and Profile Features. J. Ilmu Komput. Inf. 2022, 15, 131–141. [Google Scholar] [CrossRef]
- Kim, S.M.; Paris, C.; Power, R.; Wan, S. Distinguishing Individuals from Organisations on Twitter. In Proceedings of the 26th International Conference on World Wide Web Companion (WWW ’17 Companion), Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee: Canton of Geneva, Switzerland, 2017; pp. 805–806. [Google Scholar] [CrossRef] [Green Version]
- Wood-Doughty, Z.; Mahajan, P.; Dredze, M. Johns Hopkins or johnny-hopkins: Classifying Individuals versus Organizations on Twitter. In Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media, New Orleans, LA, USA, 6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 56–61. [Google Scholar] [CrossRef] [Green Version]
- Daouadi, K.E.; Rebaï, R.Z.; Amous, I. Organization vs. Individual: Twitter User Classification. In Proceedings of the International Workshop on Language Processing and Knowledge Management; LPKM: Sfax, Tunisia, 2018; pp. 1–8. [Google Scholar]
- Temaja, I.G.B.W.B. Sistem Penamaan Orang Bali. Dalam J. Humanika 2018, 24, 60–72. [Google Scholar] [CrossRef] [Green Version]
- Kurniawati, R.D.; Mulyani, S. Daftar Nama Marga/Fam, Gelar Adat dan Gelar Kebangsawanan Di Indonesia, 1st ed.; Perpustakaan Nasional RI: Jakarta, Indonesia, 2012; pp. 1–9. [Google Scholar]
- Liu, X.; Wei, F.; Zhang, S.; Zhou, M. Named entity recognition for tweets. ACM Trans. Intell. Syst. Technol. 2013, 4, 1–15. [Google Scholar] [CrossRef]
- Rachman, V.; Savitri, S.; Augustianti, F.; Mahendra, R. Named entity recognition on Indonesian Twitter posts using long short-term memory networks. In Proceedings of the 2017 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Bali, Indonesia, 28–29 October 2017; pp. 228–232. [Google Scholar]
- Munarko, Y.; Sutrisno, M.S.; Mahardika, W.A.I.; Nuryasin, I.; Azhar, Y. Named entity recognition model for Indonesian tweet using CRF classifier. IOP Conf. Ser. Mater. Sci. Eng. 2018, 403, 012067. [Google Scholar] [CrossRef]
- Pratama, B.Y.; Sarno, R. Personality Classification Based on Twitter Text Using Naïve Bayes, KNN and SVM. In Proceedings of the 2015 International Conference on Data and Software Engineering (ICoDSE), Yogyakarta, Indonesia, 25–26 November 2015; pp. 170–174. [Google Scholar] [CrossRef]
- Wongkar, M.; Angdresey, A. Sentiment Analysis Using Naïve Bayes Algorithm Of The Data Crawler: Twitter. In Proceedings of the 2019 Fourth International Conference on Informatics and Computing (ICIC), Semarang, Indonesia, 16–17 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Godara, J.; Aron, R.; Shabaz, M. Sentiment Analysis and Sarcasm Detection from Social Network to Train Health-Care Professionals. World J. Eng. 2021, 19, 124–133. [Google Scholar] [CrossRef]
- Joachims, T. Text Categorization with Support Vector Machines: Learning with Many Relevant Features. In Proceedings of the 10th European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar] [CrossRef] [Green Version]
- Mahkovec, Z. An Agent for Categorizing and Geolocating News Articles. Informatica 2004, 28, 371–374. [Google Scholar]
- Rout, D.; Bontcheva, K.; Preoţiuc-Pietro, D.; Cohn, T. Where’s @wally? A Classification Approach to Geolocating Users Based on Their Social Ties. In Proceedings of the 24th ACM Conference on Hypertext and Social Media, Paris, France, 1–3 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 11–20. [Google Scholar] [CrossRef]
- Milusheva, S.; Marty, R.; Bedoya, G.; Williams, S.; Resor, E.; Legovini, A. Applying Machine Learning and Geolocation Techniques to Social Media Data (Twitter) to Develop a Resource for Urban Planning. PLoS ONE 2021, 16, e0244317. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic Regression and Artificial Neural Network Classification Models: A Methodology Review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [Green Version]
- Wing, B.; Baldridge, J. Hierarchical Discriminative Classification for Text-Based Geolocation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 336–348. [Google Scholar] [CrossRef]
- Ebrahimi, M.; ShafieiBavani, E.; Wong, R.; Chen, F. Exploring Celebrities on Inferring User Geolocation in Twitter. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Jeju, Korea, 23–26 May 2017; Springer, Cham: Cham, Switzerland, 2017; pp. 395–406. [Google Scholar] [CrossRef]
- Understanding LSTM Networks. Reproduced with Permission from Christopher Olah, Understanding Lstm Networks; Published by Colah’s Blog. 2015. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 25 March 2022).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Population by Region and Religion. Available online: https://sp2010.bps.go.id/index.php/site/tabel?tid=321&wid=0 (accessed on 11 February 2022).
- ISO 3166—Codes for the Representation of Names of Countries and Their Subdivisions. Available online: https://www.iso.org/obp/ui/#iso:code:3166:ID (accessed on 30 March 2022).
- Barik, A.M.; Mahendra, R.; Adriani, M. Normalization of Indonesian-English Code-Mixed Twitter Data. In Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019), Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 417–424. [Google Scholar] [CrossRef] [Green Version]
- Yulianti, E.; Kurnia, A.; Adriani, M.; Duto, Y.S. Normalisation of Indonesian-English Code-Mixed Text and its Effect on Emotion Classification. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 674–685. [Google Scholar] [CrossRef]
- Nuranti, E.Q.; Yulianti, E.; Adriani, M.; Husin, H.S. Predicting the Category and the Length of Punishment in 2 Indonesian Courts Based on Previous Court Decision 3 Documents. Computers 2022, 11, 88. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Naïve Bayes | Support Vector Machine | Logistic Regression |
|---|---|---|---|
| Display name | 0.38 | 0.39 | 0.41 |
| User description | 0.32 | 0.31 | 0.39 |
| Models | ACC | F1 |
|---|---|---|
| Naïve Bayes | 0.42 | 0.40 |
| Support vector machine | 0.48 | 0.49 |
| LSTM | 0.46 | 0.50 |
| IndoBERT | 0.48 | 0.51 |
| IndoBERTweet | 0.56 | 0.58 |
| Logistic regression | 0.58 | 0.58 |
| Models | ACC | F1 |
|---|---|---|
| LSTM | 0.15 | 0.03 |
| IndoBERTweet | 0.37 | 0.30 |
| Naïve Bayes | 0.42 | 0.41 |
| Support vector machine | 0.51 | 0.50 |
| Logistic regression | 0.59 | 0.59 |
| IndoBERT | 0.75 | 0.76 |
| Features | Scenario | Scenario on Tweet | ACC | F1 |
|---|---|---|---|---|
| Tweet only | - | Majority vote | 0.58 | 0.58 |
| Aggregation | 0.75 | 0.76 | ||
| Display name, description, and tweets | Predict and vote | Majority vote | 0.50 | 0.51 |
| Aggregation | 0.58 | 0.58 | ||
| Concatenate and predict | Majority vote | 0.62 | 0.63 | |
| Aggregation | 0.77 | 0.78 |
| Cross-Testing Combination | ACC | F1 |
|---|---|---|
| Nonperson to nonperson | 0.84 | 0.84 |
| Nonperson to person | 0.54 | 0.57 |
| Nonperson to all | 0.60 | 0.62 |
| Person to person | 0.56 | 0.56 |
| Person to nonperson | 0.60 | 0.60 |
| Person to all | 0.68 | 0.71 |
| Tweet (Id) | Tweet (En Translation) | Actual Location | Predicted Location |
|---|---|---|---|
| Rahajeng Galungan Lan Kuningan Semeton | Happy Galungan and Kuningan pals | Bali and Nusa Tenggara | Bali and Nusa Tenggara |
| Selamat datang di Nusa Tenggara Timur Mas Menteri @nadiemmakarim | Welcome to East Nusa Tenggara Minister @nadiemmakarim | Bali and Nusa Tenggara | Bali and Nusa Tenggara |
| Semoga bisa cepat diselesaikan oleh pihak yang berwajib. Turut berduka cita untuk keluarga yang menjadi korban #PrayforJakarta | Hopefully this can be resolved quickly by the authorities. Condolences to the families of the victims #PrayforJakarta | Bali and Nusa Tenggara | Jabodetabek |
| Bosan ke Bali? Ke Lombok yuk! | Tired of going to Bali? Let’s go to Lombok! | Jabodetabek | Bali and Nusa Tenggara |
| Selamat Merayakan hari Galungan dan Kuningan 1 November 2017 | Happy Galungan and Kuningan Day 1 November 2017 | Maluku and Papua | Bali and Nusa Tenggara |
| Warga Bakunase II Gotong Royong Perbaiki Jalan | Bakunase II Residents Work Together to Repair Roads | Bali and Nusa Tenggara | Sulawesi |
| Sengketa Tanah di Pagar Panjang dan Danau Ina Final | Land Dispute in Pagar Panjang and Lake Ina has been resolved | Bali and Nusa Tenggara | Maluku and Papua |
| Deadline Validasi Data Kerusakan Rumah Akibat Seroja 26 April | Deadline for Data Validation of House Damage Due to Seroja 26 April | Bali and Nusa Tenggara | Jabodetabek |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simanjuntak, L.F.; Mahendra, R.; Yulianti, E. We Know You Are Living in Bali: Location Prediction of Twitter Users Using BERT Language Model. Big Data Cogn. Comput. 2022, 6, 77. https://doi.org/10.3390/bdcc6030077
Simanjuntak LF, Mahendra R, Yulianti E. We Know You Are Living in Bali: Location Prediction of Twitter Users Using BERT Language Model. Big Data and Cognitive Computing. 2022; 6(3):77. https://doi.org/10.3390/bdcc6030077
Chicago/Turabian StyleSimanjuntak, Lihardo Faisal, Rahmad Mahendra, and Evi Yulianti. 2022. "We Know You Are Living in Bali: Location Prediction of Twitter Users Using BERT Language Model" Big Data and Cognitive Computing 6, no. 3: 77. https://doi.org/10.3390/bdcc6030077
APA StyleSimanjuntak, L. F., Mahendra, R., & Yulianti, E. (2022). We Know You Are Living in Bali: Location Prediction of Twitter Users Using BERT Language Model. Big Data and Cognitive Computing, 6(3), 77. https://doi.org/10.3390/bdcc6030077