2.1. AI2VIS4BigData Reference Model
The AI2VIS4BigData Reference Model for visual Big Data Analysis defines logical relationships and terminologies and provides guidelines and reference implementations for IS incorporating AI. The relationship between AI and the IS could be using AI for data transformation, empowering its users, or enabling the design and definition of AI models themselves [
4]. It was derived by combining Bornschlegl’s IVIS4BigData Reference Model with the AI model system life cycle [
4]. It provides support for statistical AI,
Machine Learning (ML), as well as symbolic AI [
4] and aims to fulfill the user journey shown in
Figure 1.
The user journey in
Figure 1 is based on Fisher and Nakakoji’s multi-faceted architecture [
6] to support technically less skilled end users in effectively analyzing data [
5]. It consists of three steps:
- (a)
An end user shows the intention of visually analyzing data [
5]. The user is thereby not very confident and overstrained by the systems and data complexity [
5].
- (b)
The application of AI on the available information targets to identify areas of relevance or promising next data processing steps [
5].
- (c)
The AI-based result is presented to the user for empowerment [
5]. Visual and textual guidance supports the user in effectively using the IS [
5].
The authors of this paper detailed this user journey by introducing four user-empowering use cases with 19 potential application scenarios alongside the Big Data analysis pipeline [
7]. An example is the use case of AI-based data transformation with the application scenario of predicting analysis methods [
7]. As these use cases have been only theoretically introduced, no reference implementation exists. An initial study with nine professionals in the medial application domain positively validated the need for end-user empowerment in visual Big Data analysis [
8] and thus strengthened the demand for a reference implementation. Furthermore, no publication details the usage of symbolic AI and the required knowledge representation for the reference model.
2.2. Expert and Recommender Systems for AI-Based Recommendations
AI-based recommendations are essential to people’s private and professional digital lives. Examples of personal applications comprise product recommendations on e-commerce providers such as Amazon [
9], and the advice of suiting movies and shows by streaming providers such as Netflix, that analyze user’s preferences and usage data [
10]. Examples for professional applications include the selection of potential job candidates for HR [
10] and the support of employees through domain-specific recommendations, e.g., medical diagnosis recommendations or mechanical repair instructions [
11]. Two possible AI methods for recommendations are
Expert Systems (ES) [
9] and
Recommender Systems (RS) [
9,
10] as shown in
Figure 2.
ES have existed in AI research for approximately fifty years [
9,
11]. They are a method of AI that incorporates experts’ knowledge to solve problems for non-expert users [
9]. Problem-solving of ES comprises diagnosis, planning, classification, and others [
11]. ES as an application of symbolic AI potentially has the “
capability to review its reasoning and explain its decisions” [
11] and thus is suitable for
explainable AI (XAI). Villegas-Ch et al. present an exemplary application of an ES for recommendations with an ES that recommends activities to students to improve their academic performance [
12].
Figure 3 shows the five types of ES: “
Rule-based ES, Frame-based ES, Fuzzy-based ES, Neural ES, and Neuro-fuzzy ES” [
9]. They differ regarding their knowledge representation and logic concept. Rule-based ES encode domain knowledge as rules and facts and enable binary reasoning [
13]. Frame-based ES use the concept of frames that store knowledge as classes and instances of classes with attributes and values [
14]. Fuzzy ES can deal with imprecision and uncertainty instead of Boolean logic [
13]. They operate on “
a collection of fuzzy membership functions and rules” [
13]. Neural ES apply the machine learning approach of neural networks for decision-making [
13]. Neuro-Fuzzy ES combine the neural and fuzzy approaches.
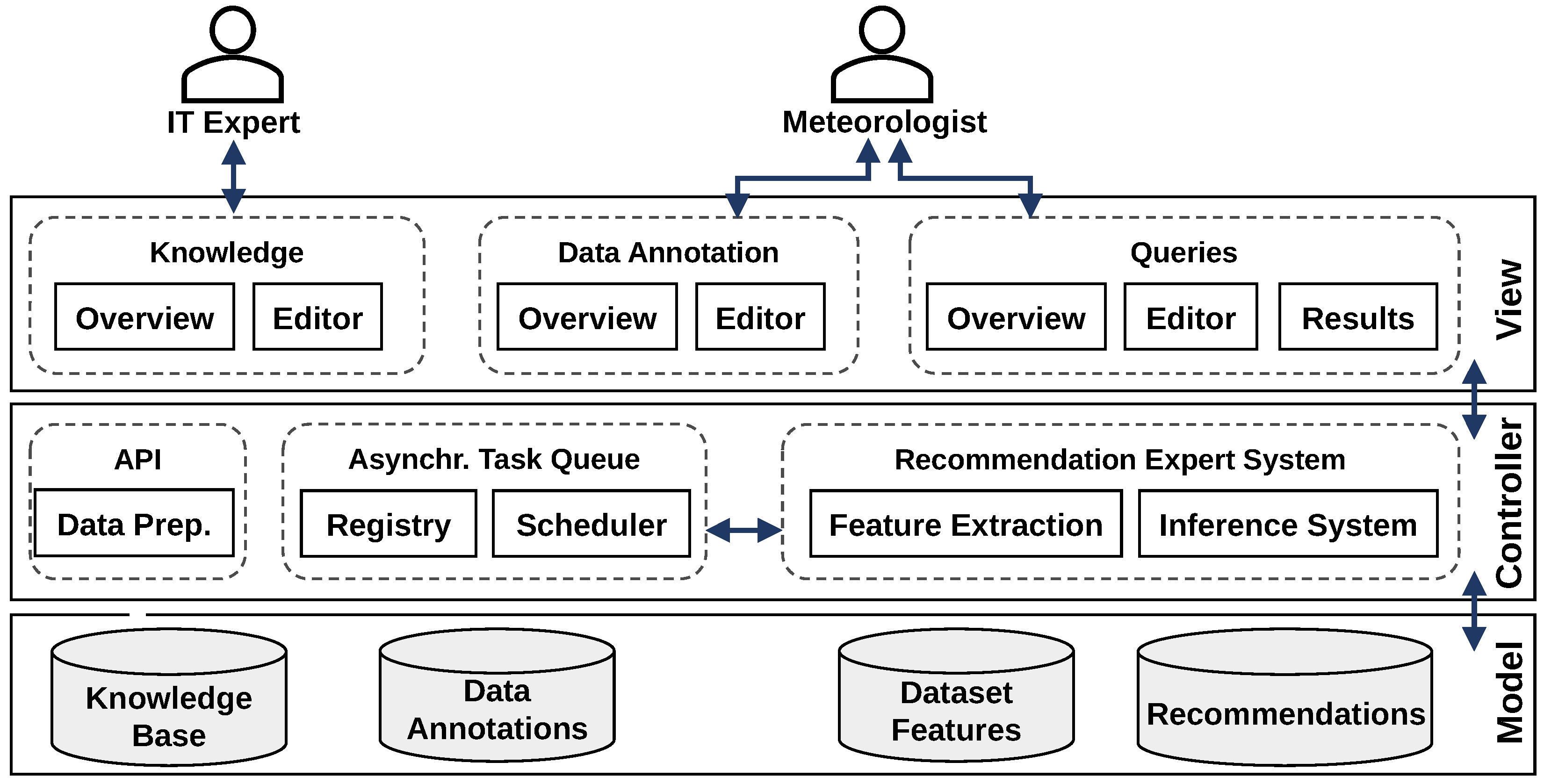
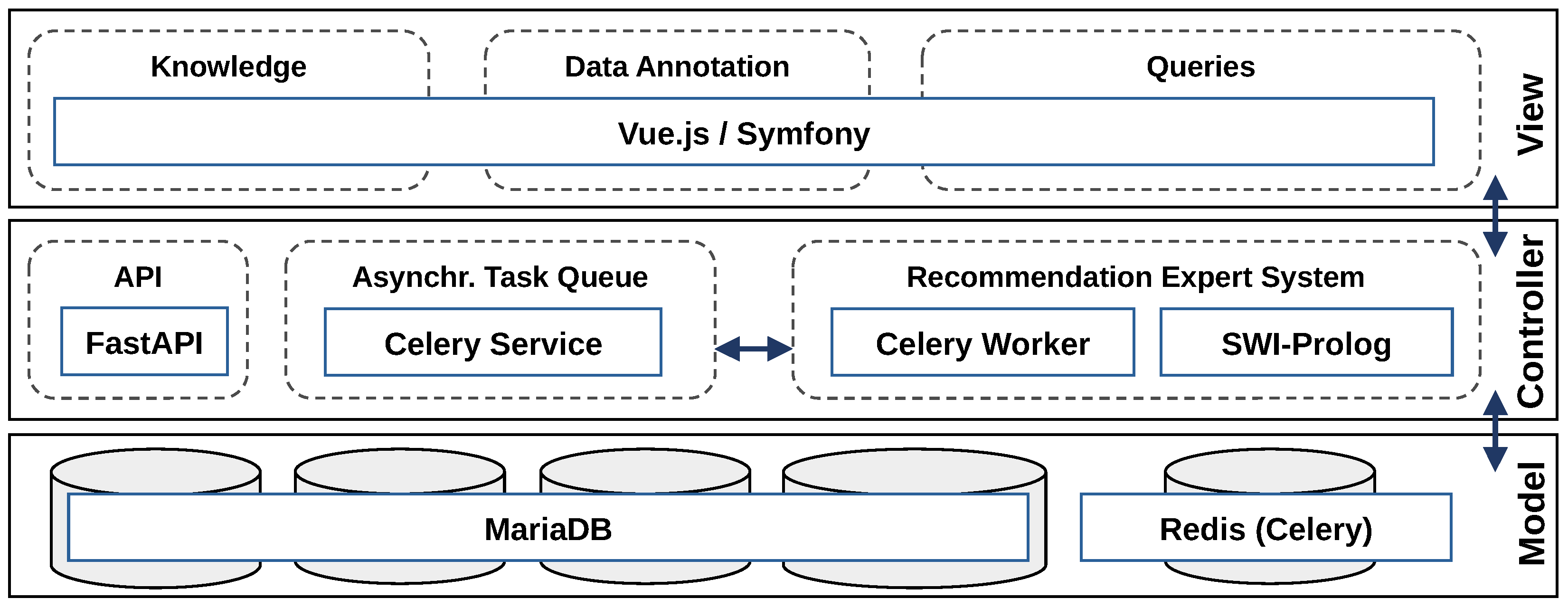
Figure 4 shows the essential components of an ES: the
Knowledge Base (KB), the inference engine, and the user interface. The KB consists of knowledge “
as both facts and heuristics” [
9] that was provided by expert users to the ES. The inference engine processes these facts and heuristics to validate an objective (backward chaining) or to infer new knowledge (forward chaining) [
9,
12]. Finally, a user interface presents the inference result to the system’s end users [
9,
12].
“
Recommender Systems provide suggestions to the users, tailored to their needs” [
9]. These suggestions relate to items, that are “
of use to a user” [
15]. For this purpose, RS internally apply statistical AI and ML [
9] on data the end users created. In contrast to this, ES only facilitate the expert users’ knowledge [
9]. Fewer dependencies on expert users reduces costs and maintenance effort and thus is a major advantage of RS [
9]. Another big success factor is the personalized nature of the recommendations. According to Sulikowski et al., personalized recommendations “
lead to high purchase intentions in e-commerce” [
15]. Despite these effects, there also exist non-personalized RS [
16]. These non-personalized RS suggest items based on the usage data of all customers [
16]. Consequently, all customers receive the same recommendations. Since this does not leverage the big advantages of RS, most applications create user profiles for individual users to provide personalized recommendations. These user profiles are “
based on user demographic data and his/her behavior and transactions” [
17].
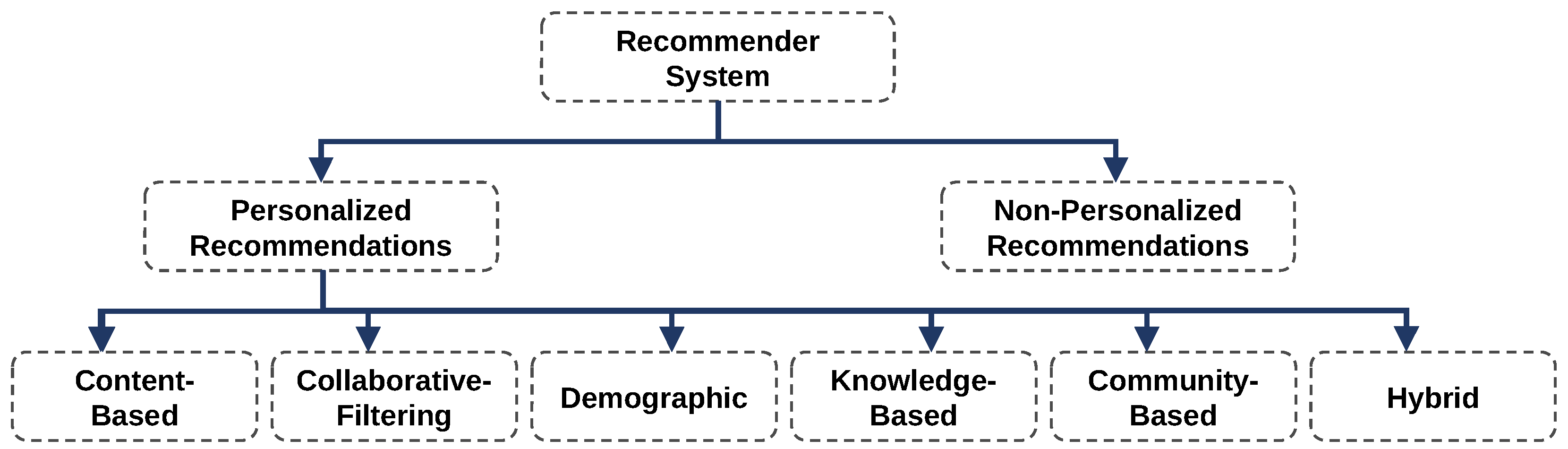
Personalized RS can be divided into content-based, collaborative-filtering, demographic, knowledge-based, community-based, and hybrid RS [
15]. Content-based RS aim at “presenting products similar to products the user liked in the past” [
17]. Collaborative-filtering RS are the most popular RS [
17]. They recommend items based on the preferences of other users with similar user profiles [
15]. Community-based RS suggest items based on the user’s friend’s preferences [
15]. Knowledge-based RS improve recommendations by applying domain knowledge provided by experts on the items [
15]. Demographic RS derive recommendations only based on demographic information within the user profiles [
15]. Depending on the granularity of demographic data, this could mitigate the benefits of personalization. Hybrid RS combine two or more recommendation strategies [
15].
Figure 5 shows the resulting taxonomy of RS.
Although the presented state of the art summarizes many practical applications of ES and RS [
10,
11,
15], it does not explain how an AI-based recommendation system for Big Data analysis in the domain of meteorology shall be designed.
2.3. Knowledge Representation and Symbolic AI
Knowledge represents connected, accumulated semantic information [
18] that is applied in a task or to solve a problem (also referred to as intelligence in this context) [
19]. The aggregated knowledge stored within an IS for expert-based symbolic AI is called KB [
14]. AI utilizes a KB to conclude (expert system) [
20] or to enhance or train AI models (Statistical AI, Machine Learning). Domain experts perform updates of the KB [
14]. At least four different approaches can represent knowledge: representation by using logic, by incorporating semantic networks, by using frames [
14], and by defining procedures [
19]. The first three approaches collect declarative knowledge, e.g., information about objects, relationships, and backgrounds. They can form a KB, whereas procedural knowledge focuses on directions about particular tasks and solutions for specific problems [
19] (implemented, e.g., through an algorithm). An example of declarative knowledge represented by logic is
First-Order Logic (FOL). The KB is formed in FOL by a set of statements (or rules) that enables validating hypotheses or drawing conclusions from it [
21].
The KB is the centerpiece of symbolic AI; it uses “
logical representations” [
20] within the KB to “
deduce a conclusion from a set of constraints” [
20]. The research focus shifted from the early introduction of symbolic AI in the 1950s toward statistical AI and ML (with the triumph of a deep convolutional neural network in the ImageNet challenge in 2012 as key milestone [
22]). Nevertheless, certain application domains such as planning or optimization still rely on it [
20]. Furthermore, the growing importance of XAI leads to a symbolic AI renaissance. Researchers rediscover symbolic AI models due to “
their capability to generate explanations about their processes” [
21] for sensitive domains or to fulfill regulatory requirements. Examples comprise avoiding gender, and ethnic biases in recruitment [
10] or enabling audits in financial risk management [
21]. Programming languages for symbolic AI comprise, e.g., Prolog, Datalog, and LISP [
21], capable of declarative, logical, and symbolic programming paradigms. Although symbolic AI and its knowledge representations have existed for a long time, the state of the art does not describe a KB for Big Data analysis methods.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}