


X-Wines: A Wine Dataset for Recommender Systems and Machine Learning




Abstract
:1. Introduction
2. Work Methodology
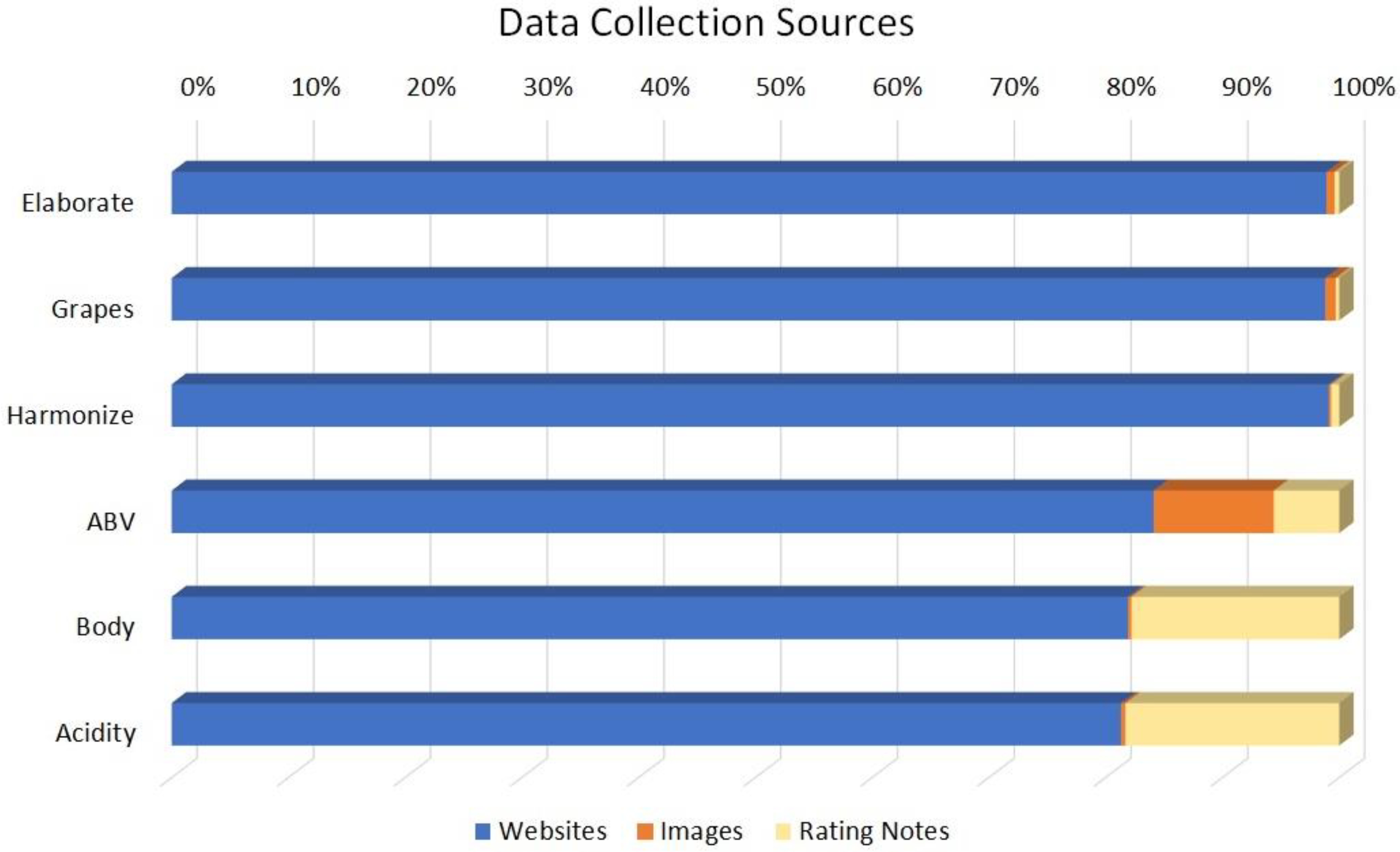
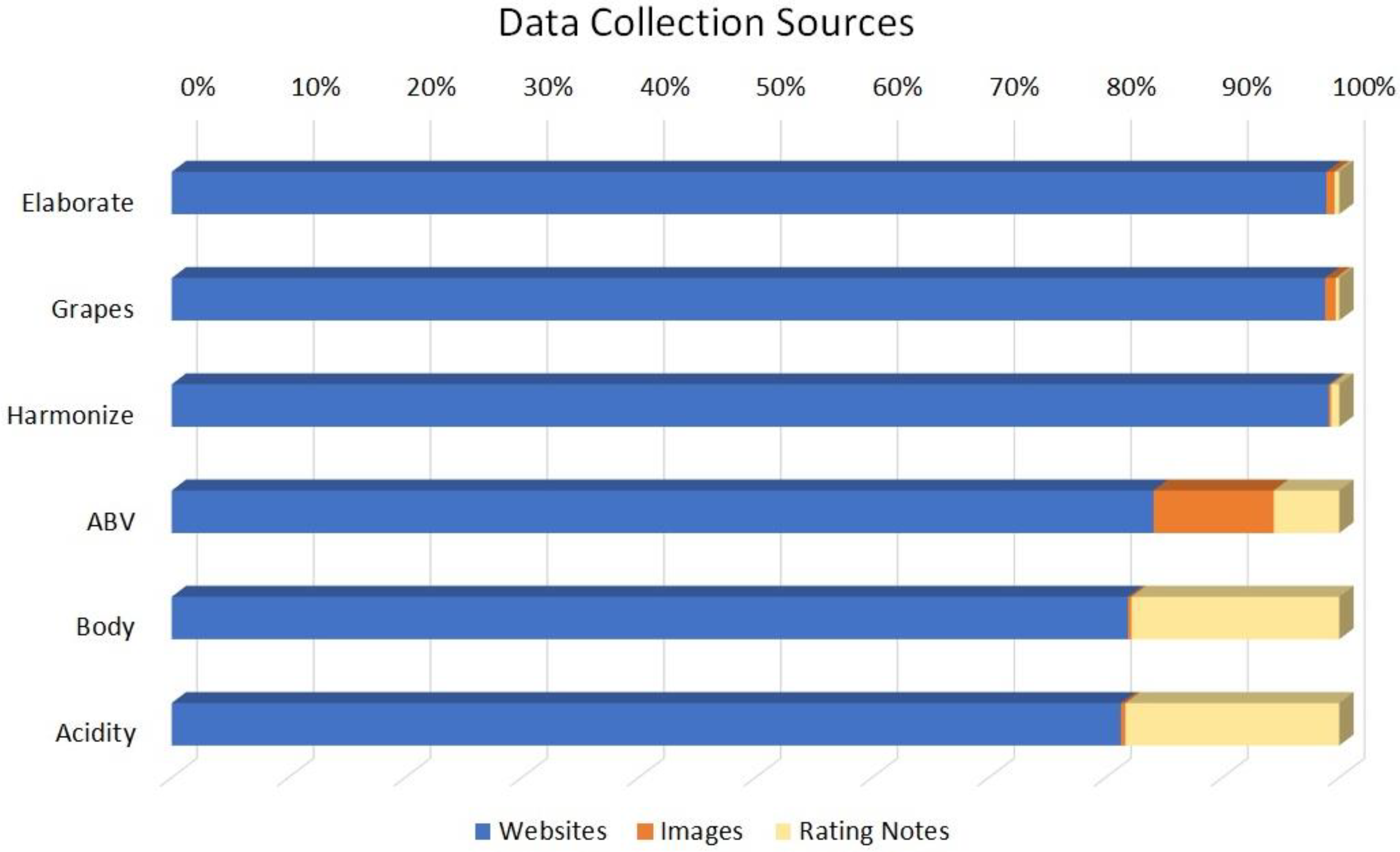
2.1. Data Collection Process
2.2. Dataset Description
2.2.1. XWines_100K_wines.csv File Description
- WineID: Integer. The wine primary key identification;
- WineName: String. The textual wine identification presented in the label;
- Type: String. The categorical type classification: Red, white or rosé for still wines, gasified sparkling or dessert for sweeter and fortified wines. Dessert/Port is a subclassification for liqueur dessert wines;
- Elaborate: String. Categorical classification between varietal or assemblage/blend. The most famous blends are also considered, such as Bordeaux red and white blend, Valpolicella blend and Portuguese red and white blend;
- Grapes: String list. It contains the grape varieties used in the wine elaboration. The original names found have been kept;
- Harmonize: String list. It contains the main dishes set that pair with the wine item. These are provided by producers but openly recommended on the internet by sommeliers and even consumers;
- ABV: Float. The alcohol by volume (ABV) percentage. According to [1], the value shown on the label may vary, and a tolerance of 0.5% per 100 volume is allowed, reaching 0.8% for some wines;
- Body: String. The categorical body classification: Very light-bodied, light-bodied, medium-bodied, full-bodied or very full-bodied based on wine viscosity [37];
- Acidity: String. The categorical acidity classification: Low, medium, or high, based on potential hydrogen (pH) score [38];
- Code: String. It contains the categorical international acronym of origin country of the wine production (ISO-3166);
- Country: String. The categorical origin country identification of the wine production (ISO-3166);
- RegionID: Integer. The foreign key of the wine production region;
- RegionName: String. The textual wine region identification. The appellation region name was retained when identified;
- WineryID: Integer. The foreign key of the wine production winery;
- WineryName: String. The textual winery identification;
- Website: String. The winery’s URL, when identified;
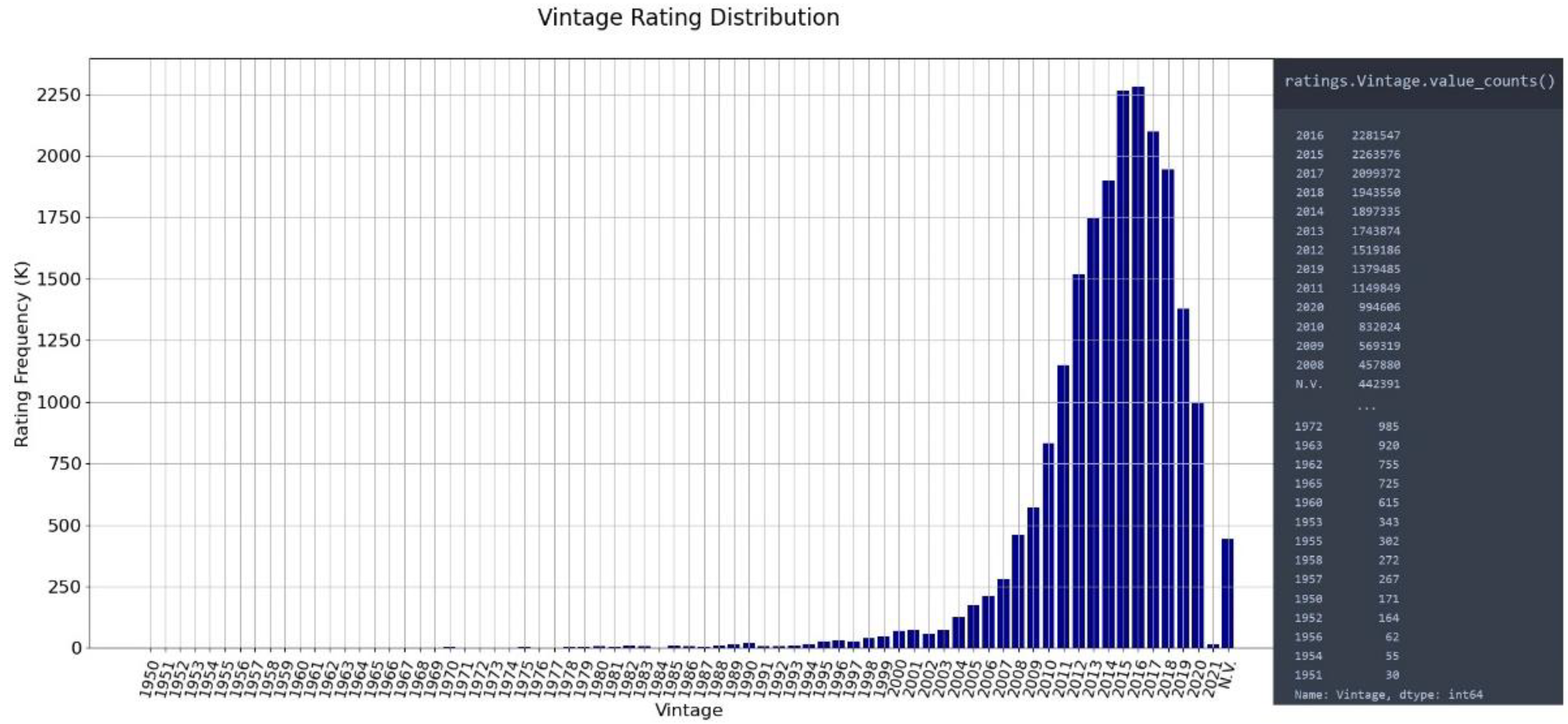
- Vintages: String list. It contains the list of integers that represent the vintage years or the abbreviation “N.V.” referring to “non-vintage”.
2.2.2. XWines_21M_ratings.csv File Description
- RatingID: Integer. The rating primary key identification;
- UserID: Integer. The sequential key without identifying the user’s private data;
- WineID: Integer. The wine foreign key to rated wine identification;
- Vintage: String. A rated vintage year or the abbreviation “N.V.” referring to “non-vintage”;
- Rating: Float. It contains the 5-stars (1–5) rating value ⊂ {1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5} performed by the user;
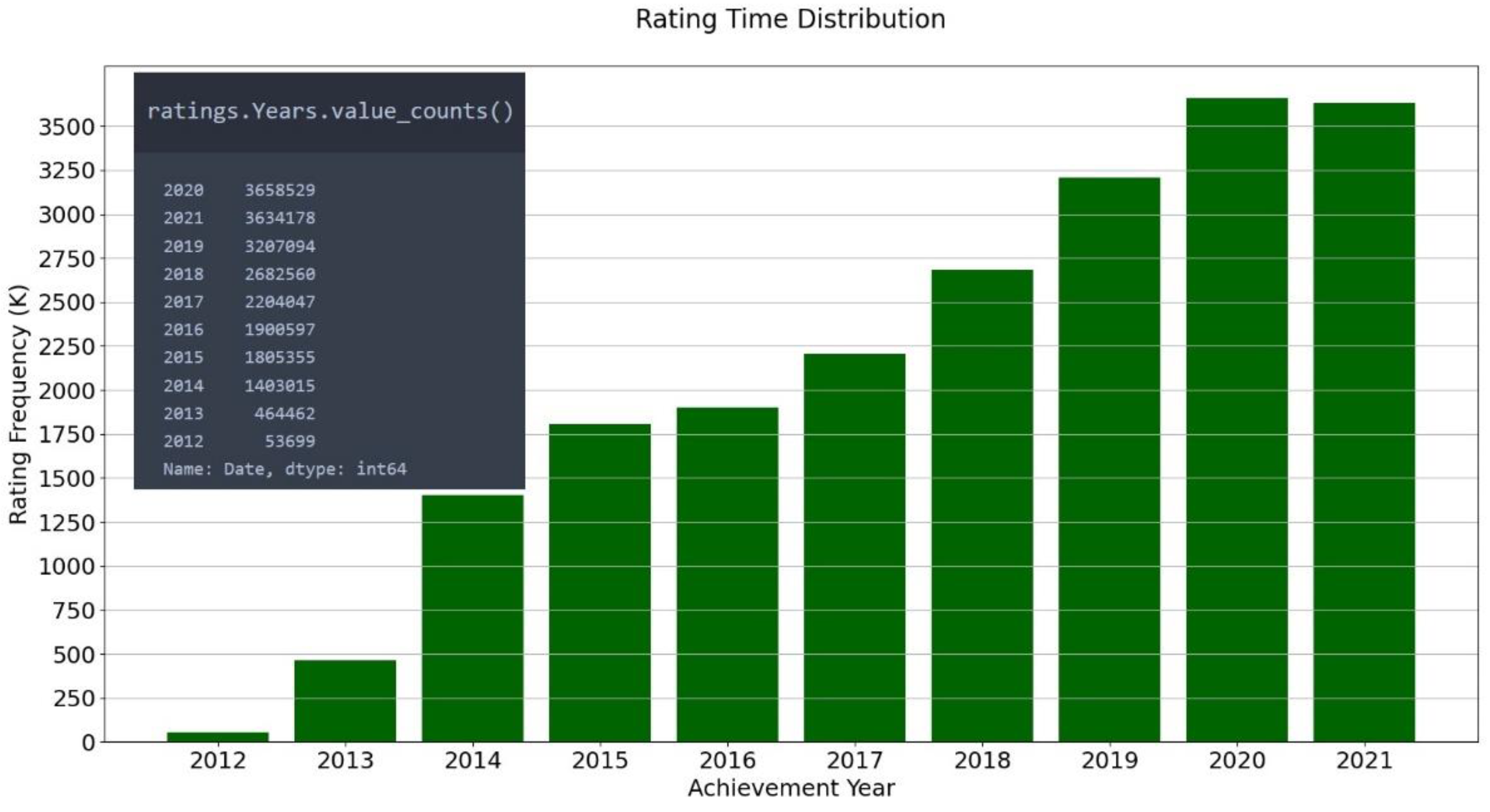
- Date: String. Datetime in the format YYYY-MM-DD hh:mm:ss informing when it was rated by the user. It can be easily converted to other formats.
2.3. Data Verification and Validation Process
- a.
- Only wine items that presented five or more ratings;
- b.
- Only ratings carried out by users with five or more wine reviews among the selected wines.
- a.
- Removal of duplicate records;
- b.
- Removal of records with some date inconsistencies in the relationship between wines–ratings–users. Thus, the calendar error in relation to the vintage of that wine was eliminated, for example, exclusion of ratings recorded in 2012 for a specific wine from the 2013 vintage;
- c.
- Adjusting the wine type to the international classification [1];
- d.
- Statistical rounding adjustment in numerical values to the 5-stars rating mostly used. For example, 3.9 to 4.0 and 4.6 to 4.5 in the rating column. This was necessary in less than 0.05% of the records found, with only 10,298 adjustments referring to 463 wines;
- e.
- Optionally, the URLs obtained referring to the winery websites or related to them were kept when their origin was validated, and some data were obtained from them. This was not possible for all wine items found.
- 100,646 wine instances containing 17 selected attributes;
- 21,013,536 5-stars rating instances, containing a date and a value in a 1–5 scale;
- 1,056,079 anonymized users.
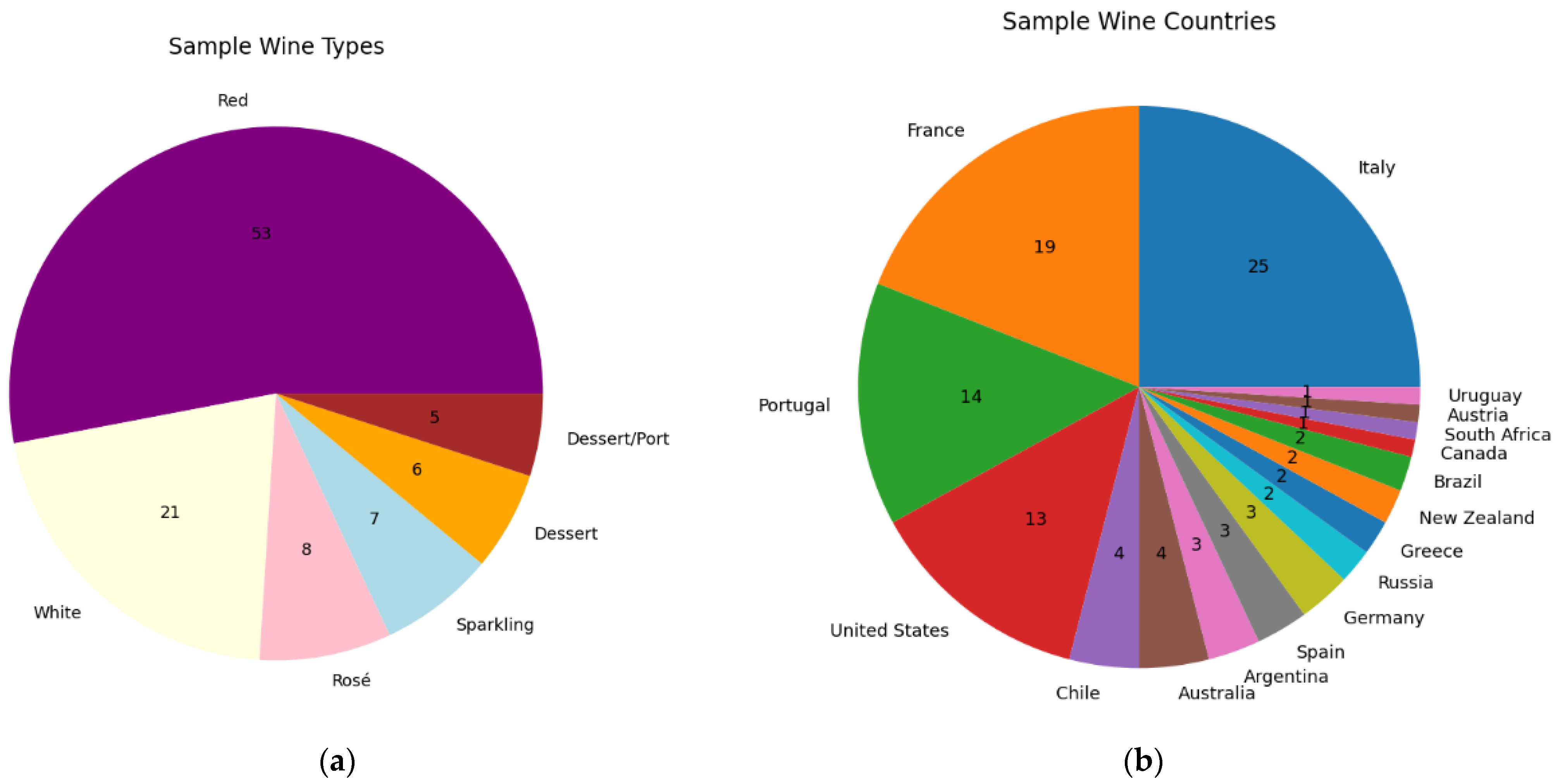
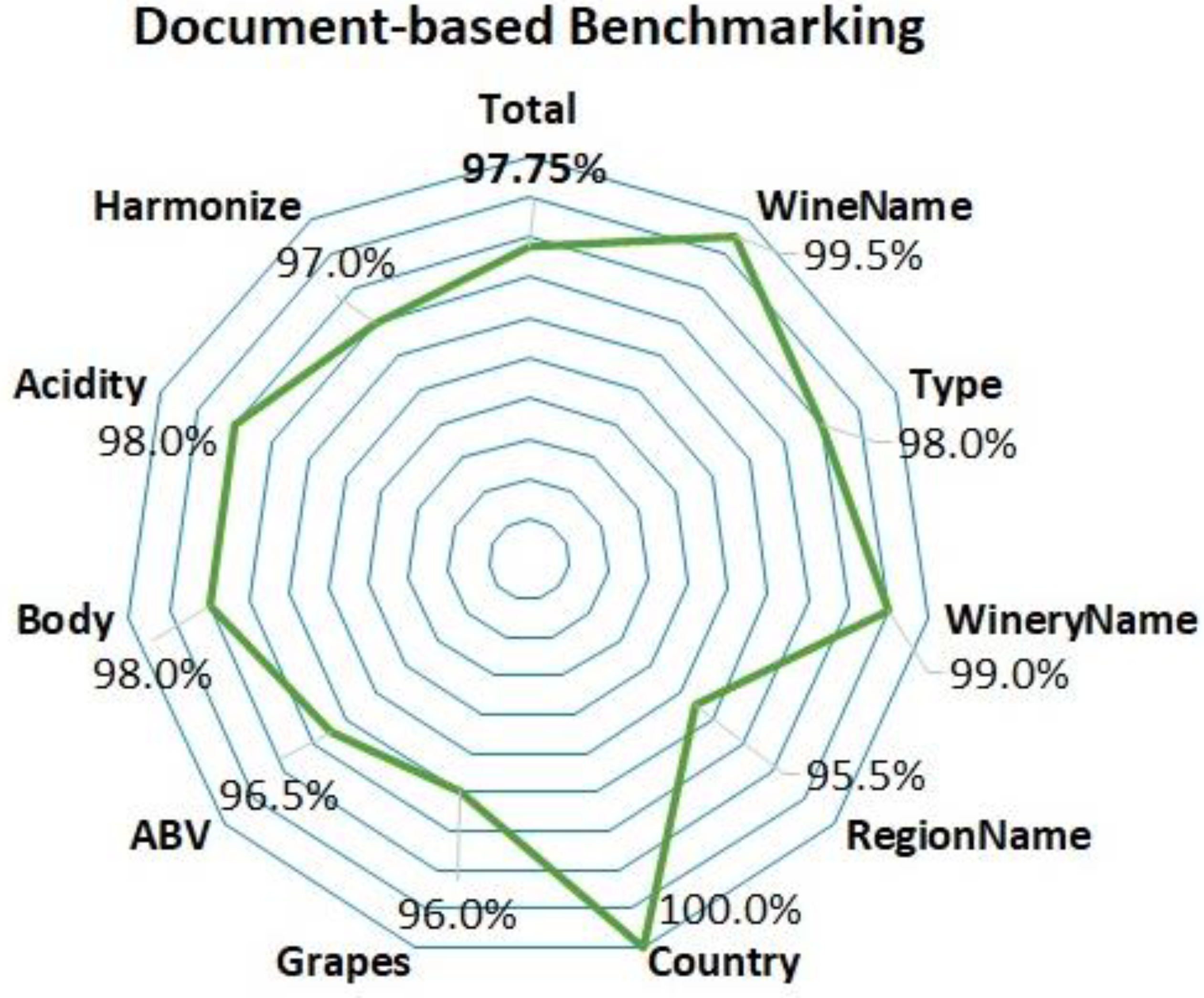
2.4. Statistical Analysis
- a.
- Five wines were randomly selected for each of the six types found, forming 30% of the sample;
- b.
- Seventy wines were randomly selected, regardless of any attribute, comprising 70% of the sample.
3. Classical Application of the Dataset in Machine Learning and Recommender Systems
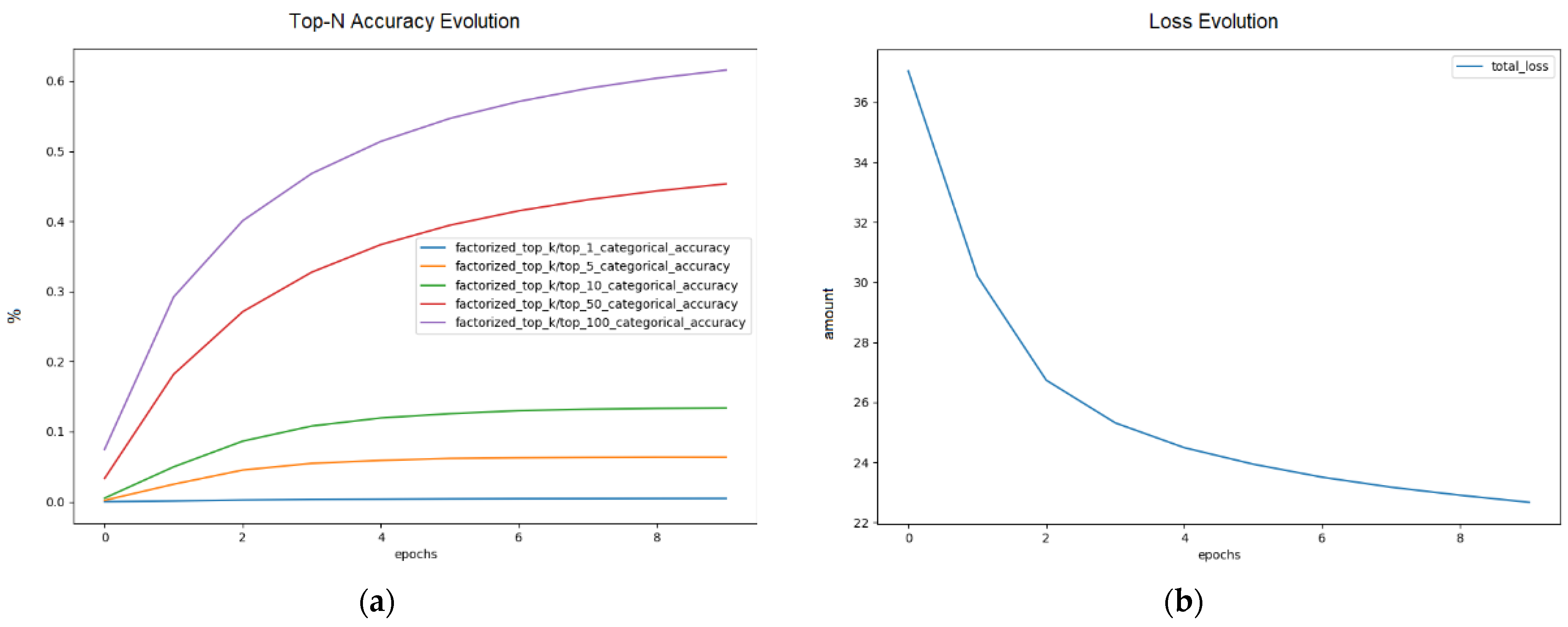
3.1. Experimental Applications in Wine Recommendation
- Pivot table construction for mapping user wine ratings, filling value 0 when there is no such relationship;
- Sparse matrix treatment where the csr_matrix package from the scipy library is used;
- Finally, the identification for each user’s neighborhood is processed by k-nearest neighbor (KNN) algorithms [51] over the input relationship matrix.
3.2. Study of Evaluation Metrics
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Juban, Y. International Standard for the Labelling of Wines; OIV-International Organization of Vine and Wine: Paris, France, 2022; ISBN 978-2-85038-042-6. Available online: https://www.oiv.int/what-we-do/standards (accessed on 11 November 2022).
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 2016, 5, 1–19. [Google Scholar] [CrossRef]
- Tianchi: Taobao Dataset. Available online: https://tianchi.aliyun.com/datalab/dataSet.html?dataId=649 (accessed on 9 October 2022).
- He, R.; McAuley, J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, Switzerland; pp. 507–517. [Google Scholar] [CrossRef] [Green Version]
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 9 October 2022).
- Ziegler, C.-N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving Recommendation Lists through Topic Diversification. In Proceedings of the 14th International Conference on World Wide Web—WWW ’05, Chiba, Japan, 10–14 May 2005; ACM Press: New York, NY, USA, 2005; p. 22. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, K.; Roeder, T.; Gupta, D.; Perkins, C. Eigentaste: A Constant Time Collaborative Filtering Algorithm. Inf. Retr. 2001, 4, 133–151. [Google Scholar] [CrossRef]
- Kaggle Open Datasets and Machine Learning Projects. Available online: https://www.kaggle.com/datasets (accessed on 9 December 2022).
- GitHub Data Packaged Core Datasets. Available online: https://github.com/datasets (accessed on 9 December 2022).
- Zhang, Q.; Lu, J.; Jin, Y. Artificial Intelligence in Recommender Systems. Complex Intell. Syst. 2021, 7, 439–457. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, D. (Xuejun) A Survey of Recommender Systems with Multi-Objective Optimization. Neurocomputing 2022, 474, 141–153. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating Collaborative Filtering Recommender Systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon.Com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Smith, B.; Linden, G. Two Decades of Recommender Systems at Amazon.Com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Hardesty, L. The History of Amazon’s Recommendation Algorithm. Available online: https://www.amazon.science/the-history-of-amazons-recommendation-algorithm (accessed on 2 October 2022).
- Zhao, T. Improving Complementary-Product Recommendations. Available online: https://www.amazon.science/blog/improving-complementary-product-recommendations (accessed on 2 October 2022).
- Geuens, S.; Coussement, K.; De Bock, K.W. A Framework for Configuring Collaborative Filtering-Based Recommendations Derived from Purchase Data. Eur. J. Oper. Res. 2018, 265, 208–218. [Google Scholar] [CrossRef]
- Schafer, J.B.; Konstan, J.A.; Riedl, J. E-Commerce Recommendation Applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Yang, X.; Dong, M.; Chen, X.; Ota, K. Recommender System-Based Diffusion Inferring for Open Social Networks. IEEE Trans. Comput. Soc. Syst. 2020, 7, 24–34. [Google Scholar] [CrossRef]
- Sperlì, G.; Amato, F.; Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Picariello, A. A Social Media Recommender System. Int. J. Multimed. Data Eng. Manag. IJMDEM 2018, 9, 36–50. [Google Scholar] [CrossRef]
- Baek, J.-W.; Chung, K.-Y. Multimedia Recommendation Using Word2Vec-Based Social Relationship Mining. Multimed. Tools Appl. 2021, 80, 34499–34515. [Google Scholar] [CrossRef]
- Yang, J.; Wang, H.; Lv, Z.; Wei, W.; Song, H.; Erol-Kantarci, M.; Kantarci, B.; He, S. Multimedia Recommendation and Transmission System Based on Cloud Platform. Future Gener. Comput. Syst. 2017, 70, 94–103. [Google Scholar] [CrossRef]
- Sahoo, A.K.; Pradhan, C.; Barik, R.K.; Dubey, H. DeepReco: Deep Learning Based Health Recommender System Using Collaborative Filtering. Computation 2019, 7, 25. [Google Scholar] [CrossRef] [Green Version]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Bashir, A.K.; Noor, F. Realizing an Efficient IoMT-Assisted Patient Diet Recommendation System Through Machine Learning Model. IEEE Access 2020, 8, 28462–28474. [Google Scholar] [CrossRef]
- Artemenko, O.; Kunanets, O.; Pasichnyk, V. E-Tourism Recommender Systems: A Survey and Development Perspectives. ECONTECHMOD Int. Q. J. Econ. Technol. Model. Process. 2017, 6, 91–95. Available online: https://bibliotekanauki.pl/articles/410644 (accessed on 2 July 2022).
- Fararni, K.A.; Nafis, F.; Aghoutane, B.; Yahyaouy, A.; Riffi, J.; Sabri, A. Hybrid Recommender System for Tourism Based on Big Data and AI: A Conceptual Framework. Big Data Min. Anal. 2021, 4, 47–55. [Google Scholar] [CrossRef]
- Kulkarni, N.H.; Srinivasan, G.N.; Sagar, B.M.; Cauvery, N.K. Improving Crop Productivity Through a Crop Recommendation System Using Ensembling Technique. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 20–22 December 2018; IEEE: New York, NY, USA, 2019; pp. 114–119. [Google Scholar] [CrossRef]
- Jaiswal, S.; Kharade, T.; Kotambe, N.; Shinde, S. Collaborative Recommendation System for Agriculture Sector. ITM Web Conf. 2020, 32, 03034. [Google Scholar] [CrossRef]
- Archana, K.; Saranya, K.G. Crop Yield Prediction, Forecasting and Fertilizer Recommendation Using Voting Based Ensemble Classifier. Int. J. Comput. Sci. Eng. 2020, 7, 1–4. [Google Scholar] [CrossRef]
- Lacasta, J.; Lopez-Pellicer, F.J.; Espejo-García, B.; Nogueras-Iso, J.; Zarazaga-Soria, F.J. Agricultural Recommendation System for Crop Protection. Comput. Electron. Agric. 2018, 152, 82–89. [Google Scholar] [CrossRef] [Green Version]
- Pytesseract: A Python wrapper for Google’s Tesseract-OCR. Available online: https://pypi.org/project/pytesseract (accessed on 20 October 2022).
- OpenCV: Open source library. Available online: https://opencv.org (accessed on 20 October 2022).
- Googletrans: Free Google Translate API for Python. Available online: https://pypi.org/project/googletrans (accessed on 20 October 2022).
- Spacy-langdetect: Fully Customizable Language Detection Pipeline for spaCy. Available online: https://pypi.org/project/spacy-langdetect (accessed on 20 October 2022).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Puckette, M.; Hammack, J. Wine Folly: The Essential Guide to Wine; Wine Folly LLC: New York, NY, USA, 2015; ISBN 978-0-399-57596-9. [Google Scholar]
- Macneil, K. The Wine Bible, 2nd ed.; Workman Publishing: New York, NY, USA, 2015; ISBN 978-0-7611-8715-8. [Google Scholar]
- Wine Encyclopedia Lexicon in the World. Available online: https://glossary.wein.plus (accessed on 15 September 2022).
- Martinez, A.D.; Del Ser, J.; Villar-Rodriguez, E.; Osaba, E.; Poyatos, J.; Tabik, S.; Molina, D.; Herrera, F. Lights and Shadows in Evolutionary Deep Learning: Taxonomy, Critical Methodological Analysis, Cases of Study, Learned Lessons, Recommendations and Challenges. Inf. Fusion 2021, 67, 161–194. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Maheswari, M.; Geetha, S.; Selvakumar, S. Adaptable and Proficient Hellinger Coefficient Based Collaborative Filtering for Recommendation System. Clust. Comput. 2019, 22, 12325–12338. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; Association for Computing Machinery: New York, NY, USA, 1994; pp. 175–186. [Google Scholar] [CrossRef]
- Shao, B.; Li, X.; Bian, G. A Survey of Research Hotspots and Frontier Trends of Recommendation Systems from the Perspective of Knowledge Graph. Expert Syst. Appl. 2021, 165, 113764. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Eberle, O.; Büttner, J.; Kräutli, F.; Müller, K.-R.; Valleriani, M.; Montavon, G. Building and Interpreting Deep Similarity Models. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1149–1161. [Google Scholar] [CrossRef]
- Hiriyannaiah, S.; Siddesh, G.M.; Srinivasa, K.G. Deep Visual Ensemble Similarity (DVESM) Approach for Visually Aware Recommendation and Search in Smart Community. J. King Saud Univ. Comput. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Gharahighehi, A.; Vens, C. Personalizing Diversity Versus Accuracy in Session-Based Recommender Systems. SN Comput. Sci. 2021, 2, 39. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1441–1450. [Google Scholar] [CrossRef]
- Ludewig, M.; Jannach, D. Evaluation of Session-Based Recommendation Algorithms. User Model. User-Adapt. Interact. 2018, 28, 331–390. [Google Scholar] [CrossRef] [Green Version]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- TensorFlow Recommenders. Available online: https://www.tensorflow.org/recommenders (accessed on 15 October 2022).
- Shani, G.; Gunawardana, A. Evaluating Recommendation Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: Boston, MA, USA, 2010; pp. 257–297. ISBN 978-0-387-85819-7. [Google Scholar] [CrossRef]
- Salah, A.; Truong, Q.-T.; Lauw, H.W. Cornac: A Comparative Framework for Multimodal Recommender Systems. J. Mach. Learn. Res. 2020, 21, 1–5. Available online: https://dl.acm.org/doi/abs/10.5555/3455716.3455811 (accessed on 7 September 2022).
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative Filtering for Implicit Feedback Datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar] [CrossRef]
- Koren, Y. Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 426–434. [Google Scholar] [CrossRef]
- Lara-Cabrera, R.; González-Prieto, Á.; Ortega, F. Deep Matrix Factorization Approach for Collaborative Filtering Recommender Systems. Appl. Sci. 2020, 10, 4926. [Google Scholar] [CrossRef]
- Cornac. A Comparative Framework for Multimodal Recommender Systems. Available online: https://github.com/PreferredAI/cornac (accessed on 15 December 2022).
- Liang, D.; Krishnan, R.G.; Hoffman, M.D.; Jebara, T. Variational Autoencoders for Collaborative Filtering. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; International World Wide Web Conferences Steering Committee: Republic and Canton of Geneva, Switzerland, 2018; pp. 689–698. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Version | # Wines | # Wine Types | # Wine Countries | # Users | # Ratings | Multiple User Wine Rating |
|---|---|---|---|---|---|---|
| Test | 100 | 6 | 17 | 636 | 1000 | No |
| Slim | 1007 | 6 | 31 | 10,561 | 150,000 | No |
| Full | 100,646 | 6 | 62 | 1,056,079 | 21,013,536 | Yes |
| AUC | MAP | MRR | nDCG @5 | nDCG @10 | nDCG @100 | Precision @5 | Precision @10 | Precision @100 | Recall @5 | Recall @10 | Recall @100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MF | 0.7254 | 0.0479 | 0.1540 | 0.0558 | 0.0598 | 0.1435 | 0.0534 | 0.0526 | 0.0349 | 0.0191 | 0.0453 | 0.2894 |
| WMF | 0.9350 | 0.0675 | 0.1198 | 0.0315 | 0.0421 | 0.2247 | 0.0298 | 0.0374 | 0.0507 | 0.0117 | 0.0424 | 0.5729 |
| SVD | 0.7232 | 0.0458 | 0.1406 | 0.0475 | 0.0562 | 0.1322 | 0.0441 | 0.0502 | 0.0322 | 0.0161 | 0.0442 | 0.2640 |
| UserKNN-Cosine | 0.6960 | 0.0162 | 0.0150 | 0.0000 | 0.0005 | 0.0374 | 0.0000 | 0.0005 | 0.0118 | 0.0000 | 0.0009 | 0.1025 |
| UserKNN-Pearson | 0.6723 | 0.0151 | 0.0143 | 0.0000 | 0.0006 | 0.0280 | 0.0000 | 0.0008 | 0.0098 | 0.0000 | 0.0005 | 0.0711 |
| AUC | MAP | MRR | nDCG @5 | nDCG @10 | nDCG @100 | Precision @5 | Precision @10 | Precision @100 | Recall @5 | Recall @10 | Recall @100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MF | 0.7478 | 0.0488 | 0.1628 | 0.0598 | 0.0583 | 0.1406 | 0.0585 | 0.0534 | 0.0355 | 0.0234 | 0.0397 | 0.2520 |
| WMF | 0.8333 | 0.0467 | 0.1261 | 0.0376 | 0.0385 | 0.1445 | 0.0367 | 0.0378 | 0.0406 | 0.0112 | 0.0235 | 0.2868 |
| SVD | 0.7545 | 0.0445 | 0.1540 | 0.0508 | 0.0512 | 0.1336 | 0.0478 | 0.0483 | 0.0349 | 0.0172 | 0.0343 | 0.2465 |
| UserKNN-Cosine | 0.7714 | 0.0341 | 0.0685 | 0.0150 | 0.0200 | 0.1047 | 0.0180 | 0.0225 | 0.0305 | 0.0072 | 0.0164 | 0.2174 |
| UserKNN-Pearson | 0.7620 | 0.0320 | 0.0603 | 0.0111 | 0.0155 | 0.0973 | 0.0138 | 0.0181 | 0.0287 | 0.0048 | 0.0126 | 0.2056 |
| MAE | RMSE | AUC | F1@10 | MAP | MRR | nDCG@10 | Precision@10 | Recall@10 | Train (s) | Test (s) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PMF (D) 1 | 0.3735 | 0.4218 | 0.8969 | 0.0454 | 0.0681 | 0.0731 | 0.0864 | 0.0259 | 0.2088 | 2.4346 | 2.9242 |
| PMF (M) 2 | 0.4100 | 0.4722 | 0.9179 | 0.0550 | 0.1132 | 0.1244 | 0.1340 | 0.0314 | 0.2524 | 4.3186 | 2.8105 |
| NMF (D) | 0.3918 | 0.4433 | 0.8631 | 0.0258 | 0.0530 | 0.0588 | 0.0556 | 0.0148 | 0.1178 | 0.4730 | 3.6310 |
| NMF (M) | 0.3541 | 0.4025 | 0.8953 | 0.0508 | 0.0903 | 0.0992 | 0.1109 | 0.0290 | 0.2348 | 3.3834 | 3.5685 |
| MMMF (D) | 2.8310 | 2.8665 | 0.8426 | 0.0136 | 0.0243 | 0.0273 | 0.0235 | 0.0078 | 0.0636 | 0.1575 | 3.5797 |
| MMMF (M) | 2.8310 | 2.8665 | 0.8796 | 0.0311 | 0.0548 | 0.0593 | 0.0639 | 0.0176 | 0.1494 | 0.9520 | 3.6344 |
| BPR (D) | 2.2315 | 2.2874 | 0.9026 | 0.0488 | 0.0673 | 0.0742 | 0.0954 | 0.0277 | 0.2329 | 0.2612 | 3.6313 |
| BPR (M) | 2.2503 | 2.3100 | 0.9200 | 0.0556 | 0.0956 | 0.1072 | 0.1206 | 0.0317 | 0.2581 | 1.3323 | 3.5726 |
| IBPR (D) | 2.8310 | 2.8665 | 0.9030 | 0.0251 | 0.0553 | 0.0620 | 0.0535 | 0.0144 | 0.1137 | 636.7179 | 3.1536 |
| IBPR (M) | 2.8310 | 2.8665 | 0.9111 | 0.0362 | 0.0709 | 0.0810 | 0.0789 | 0.0207 | 0.1654 | 896.7034 | 3.3106 |
| ItemKNN (D) | 0.4741 | 0.5357 | 0.4759 | 0.0004 | 0.0033 | 0.0038 | 0.0011 | 0.0002 | 0.0019 | 0.2050 | 6.7605 |
| ItemKNN (M) | 0.4712 | 0.5341 | 0.6247 | 0.0017 | 0.0078 | 0.0087 | 0.0032 | 0.0010 | 0.0081 | 0.2569 | 7.8847 |
| MLP (D) | 2.8310 | 2.8665 | 0.8916 | 0.0514 | 0.1087 | 0.1187 | 0.1269 | 0.0295 | 0.2335 | 182.0409 | 10.1129 |
| MLP (M) | 2.8310 | 2.8665 | 0.8975 | 0.0538 | 0.1054 | 0.1155 | 0.1277 | 0.0308 | 0.2470 | 182.7150 | 9.9000 |
| NeuMF/NCF (D) | 2.8310 | 2.8665 | 0.8936 | 0.0410 | 0.0850 | 0.0952 | 0.0953 | 0.0236 | 0.1834 | 187.7156 | 11.3031 |
| NeuMF/NCF (M) | 2.8310 | 2.8665 | 0.9069 | 0.0461 | 0.0991 | 0.1125 | 0.1122 | 0.0265 | 0.2070 | 229.4710 | 11.4913 |
| HFT (D) | 0.7179 | 0.8099 | 0.7332 | 0.0117 | 0.0277 | 0.0314 | 0.0251 | 0.0067 | 0.0525 | 2760.2964 | 3.0833 |
| HFT (M) | 0.4068 | 0.4615 | 0.8444 | 0.0326 | 0.0731 | 0.0799 | 0.0799 | 0.0186 | 0.1518 | 181.9239 | 3.1477 |
| CTR (D) | 2.7823 | 2.8220 | 0.6216 | 0.0043 | 0.0124 | 0.0139 | 0.0064 | 0.0025 | 0.0181 | 478.4666 | 3.2100 |
| CTR (M) | 1.7647 | 1.9052 | 0.8411 | 0.0459 | 0.0975 | 0.1095 | 0.1139 | 0.0262 | 0.2131 | 40.5894 | 3.2452 |
| VAECF (D) | 2.8310 | 2.8665 | 0.9224 | 0.0622 | 0.1385 | 0.1553 | 0.1620 | 0.0356 | 0.2843 | 36.1579 | 13.3041 |
| VAECF (M) | 2.8310 | 2.8665 | 0.9234 | 0.0646 | 0.1450 | 0.1622 | 0.1700 | 0.0370 | 0.2958 | 39.4341 | 12.5907 |
| BiVAECF (D) | 2.7008 | 2.7369 | 0.9145 | 0.0450 | 0.0788 | 0.0871 | 0.0970 | 0.0257 | 0.2090 | 68.9236 | 4.3243 |
| BiVAECF (M) | 2.5775 | 2.6160 | 0.9212 | 0.0631 | 0.1237 | 0.1386 | 0.1526 | 0.0360 | 0.2915 | 164.4968 | 4.4348 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Azambuja, R.X.; Morais, A.J.; Filipe, V. X-Wines: A Wine Dataset for Recommender Systems and Machine Learning. Big Data Cogn. Comput. 2023, 7, 20. https://doi.org/10.3390/bdcc7010020
de Azambuja RX, Morais AJ, Filipe V. X-Wines: A Wine Dataset for Recommender Systems and Machine Learning. Big Data and Cognitive Computing. 2023; 7(1):20. https://doi.org/10.3390/bdcc7010020
Chicago/Turabian Stylede Azambuja, Rogério Xavier, A. Jorge Morais, and Vítor Filipe. 2023. "X-Wines: A Wine Dataset for Recommender Systems and Machine Learning" Big Data and Cognitive Computing 7, no. 1: 20. https://doi.org/10.3390/bdcc7010020
APA Stylede Azambuja, R. X., Morais, A. J., & Filipe, V. (2023). X-Wines: A Wine Dataset for Recommender Systems and Machine Learning. Big Data and Cognitive Computing, 7(1), 20. https://doi.org/10.3390/bdcc7010020