


A Reasonable Effectiveness of Features in Modeling Visual Perception of User Interfaces




Abstract
:1. Introduction
- the AVA dataset had over 200,000 training and validation images, and the considered architectures demonstrated accuracy from 74.2% to 86.7%;
- the Photo.net dataset had about 12,500 training and validation images, and the considered architectures demonstrated accuracy from 59.9% to 81.0%.
- RQ1:
- Does feature engineering or automated feature extraction work better?
- RQ2:
- What is the effect of having more data?
- RQ3:
- What is the effect of using more features?
- RQ4:
- Does it matter which subjective visual impression we are predicting?
2. Methods and Related Work
2.1. Feature-Based UI Analysis
2.2. Deep Learning for UI Analysis
- What is being predicted. Even among the subjective dimensions of user experience, the achieved accuracies differ: e.g., over 60% for visual complexity, but only about 50% for aesthetic impressions. In [6], it was demonstrated that it also matters what domain a website relates to (culture, health, food, e-government, etc.)—especially for aesthetic assessment.
- Available volumes of data. Data have been credited with “unreasonable effectiveness” in ML; however, as explained above, HCI is not entirely satisfactory. In addition, some studies [28,29] suggest that the amount of data has a logarithmic relationship with the accuracy of DL models, which has seemingly been confirmed in practice: in [8], on a dataset about 16 times larger, the increase in the models’ accuracy was about 1.11 times. Considering that the cost of obtaining additional data via surveys increases almost linearly, one might want to start looking for more reasonable effectiveness.
- Architectures and features. The current race to propose and polish NN architectures in ML suggests that this factor plays an important role. HCI is no exception: for instance, in [27] (Tables 4 and 5) one can see that the mean squared error (MSE) in UI layouts aesthetic preferences prediction varies considerably, due to NN architectures. Previously, we have highlighted that DL models need data—but the reverse is also true: to make use of bigger datasets, one generally needs to rely on more sophisticated models [29].
3. Experiment Description
3.1. Data, Design and Hypotheses
- 1.
- 2.
- Dataset 2: 1531 screenshots of website homepages, belonging to one of the eight domains. We merged this dataset from several very different sub-datasets collected by different researchers throughout the past decade (see Table 2). We used this more diverse dataset (smaller average number of websites per domain) to explore the effect of the number of features (UI metrics).
- The NN model’s architecture: Architecture ∈ {ANN/CNN};
- The subjective visual impression scale: Scale ∈ {Complexity/Aesthetics/Orderliness};
- The number of features in the ANN models (detailed in the next sub-section), Features = 32 (resulting in ANN32 models) or Features = 42 (resulting in ANN42 models).
- MSE-ANN and MSE-CNN;
- Time-ANN and Time-CNN;
- MSE-ANN32 and MSE-ANN42.
3.2. The Material and the Models’ Input Data
- ANN models, with reduced Dataset 1 (2692 screenshots), and the basic 32 features;
- ANN32 models, with reduced Dataset 2 (1371 screenshots), and the basic 32 features;
- ANN42 models with reduced Dataset 2, and the 32 basic plus 10 additional features.
3.3. The Subjects and the Models’ Output Data
- 1.
- For Dataset 1: 137 participants (67 female, 70 male), of ages ranging from 17 to 46 (mean 21.18, SD = 2.68). The majority of the participants were Russians (89.1%), the rest being from Bulgaria, Germany and South Africa. In total, the participants provided 35,265 assessments for the 2692 screenshots from the six domains.
- 2.
- For Dataset 2: 96 participants (27 female, 69 male), of ages ranging from 19 to 25 (mean 21.02, SD = 1.30). The majority of the participants (93.8%) were Russian, with the others representing Uzbekistan. In total, the participants provided 24,114 assessments for the 1371 screenshots from the eight domains.
3.4. The ANN and CNN Models
- ANN: models;
- CNN: models;
- ANN32: models;
- ANN42: models.
- def build_model(hp):
- model = keras.Sequential()
- activation_choice = hp.Choice(’activation’, values= [’relu’,
- ↪ ’sigmoid’, ’tanh’, ’elu’, ’selu’])
- model.add(Dense(units=hp.Int(’units_input’, min_value=512,
- ↪ max_value=1024, step=32), activation=activation_choice)
- ↪)
- for i in range(2, 6):
- model.add(Dense(units=hp.Int(’units_’ + str(i), min_value
- ↪ =128, max_value=1024, step=32), activation=
- ↪ activation_choice))
- model.add(Dense(1))
- model.compile(optimizer="adam", loss=’mse’, metrics=[’mse’,
- ↪ coeff_determination])
- return model
4. Results
4.1. Descriptive Statistics
- between MSE-ANN and MSE-CNN: r189 = 0.341, p < 0.001;
- between Time-ANN and Time-CNN: r189 = 0.623, p < 0.001;
- between MSE-ANN32 and MSE-ANN42: r690 = 0.671, p < 0.001.
4.2. Dataset 1: The Models’ Training Time
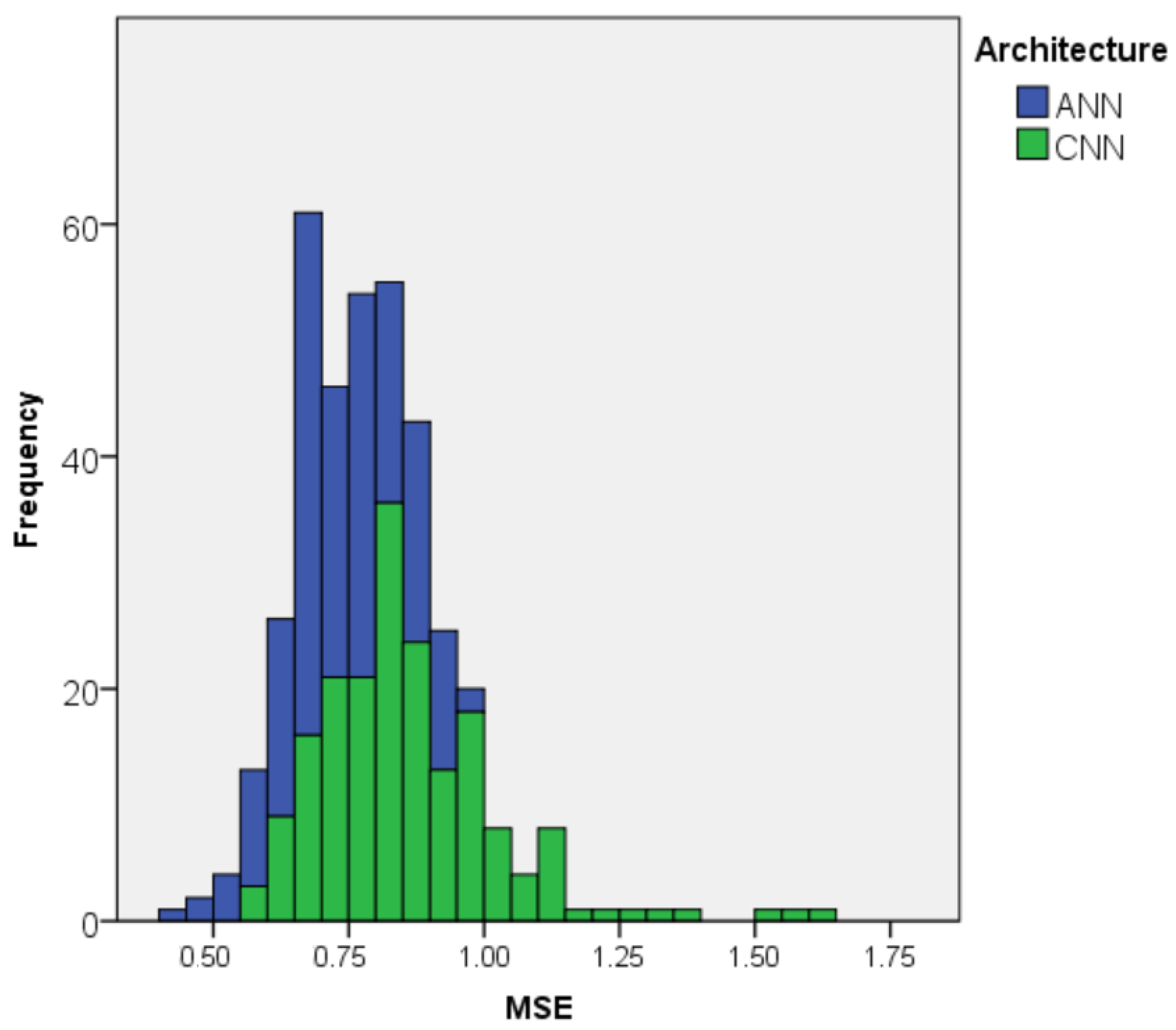
4.3. Comparison of the Models’ MSEs
4.3.1. Dataset 1
4.3.2. Dataset 2
4.4. Regression Analysis for MSE-CNN
5. Discussion and Conclusions
- RQ1:
- Feature-based models worked better for our datasets. There was significant difference () in the models’ MSEs per the architectures. The average MSE for the ANN architecture was 16.2% smaller than for the CNN architecture. There was also a significant difference in the models’ training time per the architectures, assuming that the features for the ANNs were pre-extracted: training a single CNN model took 0.696 h, which was 25 times longer than for an ANN model; however, extracting the features for the 2692 screenshots in Dataset 1 took about 43 h.
- RQ2:
- The size of the training dataset had a positive effect on the CNN models’ MSE.N significantly affected MSE-CNN (), but not MSE-ANN (): thus, at , the former should have become smaller than the latter, although we did not observe it in our study, due to the limited size of Dataset 1. Naturally, N also had a significant effect on the training time for both architectures.
- RQ3:
- The superficial increase in the number of features did not have a positive effect. There was no significant difference in MSE-ANN32 and MSE-ANN42, and even the average error was 1.23% better in the models with fewer features. Training the models with more features also took, on average 2.19%, more time. In accordance with the popular principle, features must not be multiplied beyond necessity: with respect to ML, the violation of this principle can lead to overfit and poor MSE on test data. On the other hand, if the increase in the number of features had been accompanied by a corresponding boost in the training data volume, the result might have been different. Another consideration is that ML models and algorithms have a kind of “saturation point”, after which they are not able to make good use of extra training data [29].
- RQ4:
- The particular dimension of the visual perception significantly affected the quality of the models; however, the ANN models were always superior to the CNN models. For the different values of Scale, the outcome of the models’ comparison varied: for Dataset 1, the Complexity models, on average, had 19.6% smaller MSE-ANN and 21.8% smaller MSE-CNN; moreover, N did not have a significant effect on the errors for Complexity, unlike for the other two scales; for Dataset 2, the average MSE for Aesthetics was even higher (32.2% worse than for Complexity), but the MSE for Orderliness had improved considerably. All in all, visual complexity appeared to be the most advantageous of the dimensions: thus, the widespread notion of using it as a mediator for aesthetic impression [32] appeared well-justified.
- 1.
- We found that on HCI-realistic datasets that included several hundred websites, feature-based NN models were reasonably (16.2%) more accurate at predicting users’ visual perception dimensions.
- 2.
- We provided an estimate of the training dataset size at which deep learning should start being advantageous: this estimation—about 3000 websites—assumed that the effect of N on MSE-CNN was linear.
- 3.
- We demonstrated that one should be reasonable with the number of features, as a superficial increase might actually be damaging for the ANN models.
- 4.
- We found that the results could vary, depending on the concrete subjective dimension being predicted: Complexity was confirmed as the most opportune one, while Aesthetics was predictably the most evasive.
- 5.
- We explored the time required for extracting the features and training the models. A deep learning approach that works with raw input data can save on the total time, only if several dozen models are built. Feature extraction means a considerable fixed time cost, but it enables better subsequent flexibility in exploring and tweaking the models.
- 6.
- We formalized a regression model (5) for estimating MSEs, based on the available training dataset size, the chosen architecture and the subjective user visual perception dimension being predicted.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Speicher, M.; Both, A.; Gaedke, M. TellMyRelevance! predicting the relevance of web search results from cursor interactions. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1281–1290. [Google Scholar]
- Huang, Y.; Yang, J.; Liu, S.; Pan, J. Combining facial expressions and electroencephalography to enhance emotion recognition. Future Internet 2019, 11, 105. [Google Scholar] [CrossRef]
- Nass, M.; Alégroth, E.; Feldt, R. Why many challenges with GUI test automation (will) remain. Inf. Softw. Technol. 2021, 138, 106625. [Google Scholar]
- Bakaev, M.; Speicher, M.; Jagow, J.; Heil, S.; Gaedke, M. We Don’t Need No Real Users?! Surveying the Adoption of User-less Automation Tools by UI Design Practitioners. In Proceedings of the International Conference on Web Engineering, Bari, Italy, 5–8 July 2022; Springer: Cham, Switzerland, 2022; pp. 406–414. [Google Scholar]
- Wan, H.; Ji, W.; Wu, G.; Jia, X.; Zhan, X.; Yuan, M.; Wang, R. A novel webpage layout aesthetic evaluation model for quantifying webpage layout design. Inf. Sci. 2021, 576, 589–608. [Google Scholar]
- Bakaev, M.; Speicher, M.; Heil, S.; Gaedke, M. I Don’t Have That Much Data! Reusing User Behavior Models for Websites from Different Domains. In Web Engineering; Bielikova, M., Mikkonen, T., Pautasso, C., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12128, pp. 146–162. [Google Scholar] [CrossRef]
- Dou, Q.; Zheng, X.S.; Sun, T.; Heng, P.A. Webthetics: Quantifying webpage aesthetics with deep learning. Int. J. Hum.-Comput. Stud. 2019, 124, 56–66. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, X.; He, L.; Lu, W. MSCAN: Multimodal Self-and-Collaborative Attention Network for image aesthetic prediction tasks. Neurocomputing 2021, 430, 14–23. [Google Scholar] [CrossRef]
- Reinecke, K.; Yeh, T.; Miratrix, L.; Mardiko, R.; Zhao, Y.; Liu, J.; Gajos, K.Z. Predicting users’ first impressions of website aesthetics with a quantification of perceived visual complexity and colorfulness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 2049–2058. [Google Scholar]
- Miniukovich, A.; De Angeli, A. Quantification of interface visual complexity. In Proceedings of the 2014 International Working Conference on Advanced Visual Interfaces, Como, Italy, 27–30 May 2014; pp. 153–160. [Google Scholar]
- Oulasvirta, A.; De Pascale, S.; Koch, J.; Langerak, T.; Jokinen, J.; Todi, K.; Laine, M.; Kristhombuge, M.; Zhu, Y.; Miniukovich, A.; et al. Aalto Interface Metrics (AIM) A Service and Codebase for Computational GUI Evaluation. In Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology Adjunct Proceedings, Berlin, Germany, 14–17 October 2018; pp. 16–19. [Google Scholar]
- Bakaev, M.; Heil, S.; Khvorostov, V.; Gaedke, M. Auto-Extraction and Integration of Metrics for Web User Interfaces. J. Web Eng. 2019, 17, 561–590. [Google Scholar] [CrossRef]
- Lima, A.L.d.S.; Gresse von Wangenheim, C. Assessing the visual esthetics of user interfaces: A ten-year systematic mapping. Int. J. Hum.-Comput. Interact. 2022, 38, 144–164. [Google Scholar]
- Bakaev, M.; Heil, S.; Chirkov, L.; Gaedke, M. Benchmarking Neural Networks-Based Approaches for Predicting Visual Perception of User Interfaces. In Proceedings of the International Conference on Human-Computer Interaction, Virtual Event, 26 June–1 July 2022; pp. 217–231. [Google Scholar]
- Bakaev, M.; Razumnikova, O. What Makes a UI Simple? Difficulty and Complexity in Tasks Engaging Visual-Spatial Working Memory. Future Internet 2021, 13, 21. [Google Scholar]
- Souza, O.T.; Souza, A.D.d.; Vasconcelos, L.G.; Baldochi, L.A. Usability Smells: A Systematic Review. In Proceedings of the ITNG 2021 18th International Conference on Information Technology-New Generations, Las Vegas, NV, USA, 10–14 April 2021; Springer: Cham, Switzerland, 2021; pp. 281–288. [Google Scholar]
- Yang, B.; Xing, Z.; Xia, X.; Chen, C.; Ye, D.; Li, S. Don’t do that! hunting down visual design smells in complex uis against design guidelines. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), Madrid, Spain, 22–30 May 2021; pp. 761–772. [Google Scholar]
- Stickel, C.; Ebner, M.; Holzinger, A. The XAOS metric–understanding visual complexity as measure of usability. In Proceedings of the HCI in Work and Learning, Life and Leisure: 6th Symposium of the Workgroup Human-Computer Interaction and Usability Engineering, USAB 2010, Klagenfurt, Austria, 4–5 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 278–290. [Google Scholar]
- Alemerien, K.; Magel, K. GUIEvaluator: A Metric-tool for Evaluating the Complexity of Graphical User Interfaces. In Proceedings of the SEKE, Vancouver, BC, Canada, 1–3 July 2014; pp. 13–18. [Google Scholar]
- Bakaev, M.; Heil, S.; Khvorostov, V.; Gaedke, M. HCI vision for automated analysis and mining of web user interfaces. In Proceedings of the International Conference on Web Engineering, Cáceres, Spain, 5–8 June 2018; Springer: Cham, Switzerland, 2018; pp. 136–144. [Google Scholar]
- Michailidou, E.; Eraslan, S.; Yesilada, Y.; Harper, S. Automated prediction of visual complexity of web pages: Tools and evaluations. Int. J. Hum.-Comput. Stud. 2021, 145, 102523. [Google Scholar]
- Chen, J.; Xie, M.; Xing, Z.; Chen, C.; Xu, X.; Zhu, L.; Li, G. Object detection for graphical user interface: Old fashioned or deep learning or a combination? In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, 8–13 November 2020; pp. 1202–1214. [Google Scholar]
- Deka, B.; Huang, Z.; Franzen, C.; Hibschman, J.; Afergan, D.; Li, Y.; Nichols, J.; Kumar, R. Rico: A mobile app dataset for building data-driven design applications. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, Québec City, QC, Canada, 22–25 October 2017; pp. 845–854. [Google Scholar]
- Kreinovich, V. From traditional neural networks to deep learning: Towards mathematical foundations of empirical successes. In Recent Developments and the New Direction in Soft-Computing Foundations and Applications; Springer: Cham, Switzerland, 2021; pp. 387–397. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar]
- Talebi, H.; Milanfar, P. NIMA: Neural image assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar]
- Xing, B.; Cao, H.; Shi, L.; Si, H.; Zhao, L. AI-driven user aesthetics preference prediction for UI layouts via deep convolutional neural networks. Cogn. Comput. Syst. 2022, 4, 250–264. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Zhu, X.; Vondrick, C.; Fowlkes, C.C.; Ramanan, D. Do we need more training data? Int. J. Comput. Vis. 2016, 119, 76–92. [Google Scholar]
- Kamath, C.N.; Bukhari, S.S.; Dengel, A. Comparative study between traditional machine learning and deep learning approaches for text classification. In Proceedings of the ACM Symposium on Document Engineering 2018, Halifax, NS, Canada, 28–31 August 2018; pp. 1–11. [Google Scholar]
- Miniukovich, A.; De Angeli, A. Computation of interface aesthetics. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 1163–1172. [Google Scholar]
- Miniukovich, A.; Marchese, M. Relationship between visual complexity and aesthetics of webpages. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Tuch, A.N.; Presslaber, E.E.; Stöcklin, M.; Opwis, K.; Bargas-Avila, J.A. The role of visual complexity and prototypicality regarding first impression of websites: Working towards understanding aesthetic judgments. Int. J. Hum.-Comput. Stud. 2012, 70, 794–811. [Google Scholar]
- KerasTuner. 2019. Available online: https://github.com/keras-team/keras-tuner (accessed on 5 December 2022).
- Carballal, A.; Santos, A.; Romero, J.; Machado, P.; Correia, J.; Castro, L. Distinguishing paintings from photographs by complexity estimates. Neural Comput. Appl. 2018, 30, 1957–1969. [Google Scholar] [CrossRef]
- López-Rubio, J.M.; Molina-Cabello, M.A.; Ramos-Jiménez, G.; López-Rubio, E. Classification of Images as Photographs or Paintings by Using Convolutional Neural Networks. In Proceedings of the International Work-Conference on Artificial Neural Networks, Virtual Event, 16–18 June 2021; Springer: Cham, Switzerland, 2021; pp. 432–442. [Google Scholar]
- Asim, M.N.; Ghani, M.U.; Ibrahim, M.A.; Mahmood, W.; Dengel, A.; Ahmed, S. Benchmarking performance of machine and deep learning-based methodologies for Urdu text document classification. Neural Comput. Appl. 2021, 33, 5437–5469. [Google Scholar]
- Bianco, S.; Celona, L.; Napoletano, P.; Schettini, R. Predicting image aesthetics with deep learning. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Lecce, Italy, 24–27 October 2016; Springer: Cham, Switzerland, 2016; pp. 117–125. [Google Scholar]


{kind=link}
| Domain | Description | Number of the Screenshots | |
|---|---|---|---|
| Collected | Used | ||
| Culture | Websites of museums, libraries, exhibition centers and other cultural institutions. | 807 | 746 (92.4%) |
| Food | Websites dedicated to food, cooking, healthy eating, etc. | 388 | 369 (95.1%) |
| Games | Websites dedicated to computer games. | 455 | 362 (79.6%) |
| Gov | E-government, non-governmental organization and foundation websites. | 370 | 346 (93.5%) |
| Health | Websites dedicated to health, hospitals, pharmacies and medicaments. | 565 | 541 (95.8%) |
| News | Online and offline news editions’ websites. | 347 | 328 (94.5%) |
| Total: | 2932 | 2692 (91.8%) | |
| Domain/ Sub-Dataset | Description | Year | Resolution, px | Number of Screenshots | |
|---|---|---|---|---|---|
| Nominal | Used | ||||
| AVI_14 | From [10] | 2014 | W: 1278-1294 H: 799-800 | 140 | 124 (88.6%) |
| Banks | Screenshots of banks’ websites * | 2022 | W: 1440 H: 960 | 304 | 287 (94.4%) |
| CHI_15 | From [31] | 2015 | W: 1280 H: 800 | 75 | 68 (90.7%) |
| CHI_20 | From [32] | 2020 | W: 720 H: 500-800 | 262 | 241 (92.0%) |
| E-Commerce | Screenshots of e-commerce websites * | 2022 | W: 1440 H: 960 | 156 | 148 (94.9%) |
| English | From [9] | 2013 | W: 1018-1024 H: 675-768 | 350 | 303 (86.6%) |
| Foreign | From [9] | 2013 | W: 1024 H: 768 | 60 | 51 (85.0%) |
| IJHCS | Part of the dataset from [33] via [32] | 2012 | W: 1000 H: 798-819 | 184 | 149 (81.0%) |
| Total | 1531 | 1371 (89.5%) | |||
| Service–Category | Metric |
|---|---|
| The basic 32 metrics | |
| Visual Analyzer (VA) quantitative | PNG filesize (in MB) |
| JPEG 100 filesize (in MB) | |
| No. of UI elements | |
| No. of UI elements’ types | |
| Visual complexity index | |
| AIM Color Perception | Unique RGB colors |
| HSV colors avg Hue | |
| HSV colors avg Saturation | |
| HSV colors std Saturation | |
| HSV colors avg Value | |
| HSV colors std Value | |
| HSV spectrum HSV | |
| HSV spectrum Hue | |
| HSV spectrum Saturation | |
| HSV spectrum Value | |
| Hassler Susstrunk dist A | |
| Hassler Susstrunk std A | |
| Hassler Susstrunk dist B | |
| Hassler Susstrunk std B | |
| Hassler Susstrunk dist RGYB | |
| Hassler Susstrunk std RGYB | |
| Hassler Susstrunk colorfulness | |
| Static clusters | |
| Dynamic CC clusters | |
| Dynamic CC avg cluster colors | |
| AIM Perceptual Fluency | Edge congestion |
| Quadtree Dec balance | |
| Quadtree Dec symmetry | |
| Quadtree Dec equilibrium | |
| Quadtree Dec leaves | |
| Whitespace | |
| Grid quality (no. of alignment lines) | |
| The additional 10 metrics | |
| AIM Color Perception | LABcolors (mean Lightness) |
| LABcolors (std Lightness) | |
| LABcolors (mean A) | |
| LABcolors (std A) | |
| LABcolors (mean B) | |
| LABcolors (std B) | |
| Luminance std | |
| AIM Perceptual Fluency | edge density |
| FG contrast | |
| pixel symmetry | |
| Domain/ Sub-Datasets | Complexity | Aesthetics | Orderliness | |||
|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | |
| Dataset 1 | ||||||
| Culture | 3.63 | 0.81 | 4.24 | 0.99 | 4.29 | 0.90 |
| Food | 3.66 | 0.81 | 4.70 | 0.94 | 4.66 | 0.87 |
| Games | 3.57 | 0.93 | 4.24 | 1.14 | 4.33 | 1.00 |
| Gov | 3.81 | 0.82 | 3.86 | 0.92 | 4.14 | 0.86 |
| Health | 3.73 | 0.79 | 4.15 | 0.90 | 4.40 | 0.82 |
| News | 4.16 | 0.86 | 3.80 | 0.83 | 4.16 | 0.82 |
| Total | 3.71 | 0.83 | 4.17 | 0.98 | 4.34 | 0.86 |
| Dataset 2 | ||||||
| AVI_14 | 3.15 | 0.85 | 4.15 | 1.15 | 4.32 | 0.97 |
| Banks | 3.20 | 0.78 | 4.33 | 0.95 | 4.81 | 0.81 |
| CHI_15 | 3.70 | 0.84 | 3.44 | 1.06 | 3.91 | 0.93 |
| CHI_20 | 3.52 | 0.77 | 3.62 | 0.96 | 4.14 | 0.73 |
| E-Comm | 2.93 | 0.62 | 4.38 | 0.93 | 4.63 | 0.75 |
| English | 3.68 | 0.93 | 3.05 | 0.94 | 3.78 | 0.83 |
| Foreign | 4.29 | 1.01 | 2.75 | 0.75 | 3.37 | 0.86 |
| IJHCS | 3.88 | 1.00 | 2.83 | 0.91 | 3.68 | 0.82 |
| Total | 3.47 | 0.91 | 3.65 | 1.13 | 4.18 | 0.93 |
| Scale | MSE-ANN | MSE-CNN |
|---|---|---|
| Complexity | 0.644 (0.081) | 0.750 (0.127) |
| Aesthetics | 0.772 (0.104) | 0.968 (0.182) |
| Orderliness | 0.769 (0.102) | 0.859 (0.122) |
| All | 0.739 (0.106) | 0.859 (0.170) |
| Scale | MSE-ANN | MSE-CNN |
|---|---|---|
| Complexity | 93.7 (17.4) | 3265.4 (1440.7) |
| Aesthetics | 107.2 (20.1) | 2704.4 (1560.0) |
| Orderliness | 101.3 (18.6) | 2650.6 (1495.8) |
| All | 100.7 (19.4) | 2506.8 (1511.3) |
| Scale | MSE-ANN32 | MSE-ANN42 |
|---|---|---|
| Complexity | 0.648 (0.122) | 0.654 (0.128) |
| Aesthetics | 0.864 (0.166) | 0.858 (0.168) |
| Orderliness | 0.654 (0.101) | 0.680 (0.141) |
| All | 0.722 (0.166) | 0.731 (0.172) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakaev, M.; Heil, S.; Gaedke, M. A Reasonable Effectiveness of Features in Modeling Visual Perception of User Interfaces. Big Data Cogn. Comput. 2023, 7, 30. https://doi.org/10.3390/bdcc7010030
Bakaev M, Heil S, Gaedke M. A Reasonable Effectiveness of Features in Modeling Visual Perception of User Interfaces. Big Data and Cognitive Computing. 2023; 7(1):30. https://doi.org/10.3390/bdcc7010030
Chicago/Turabian StyleBakaev, Maxim, Sebastian Heil, and Martin Gaedke. 2023. "A Reasonable Effectiveness of Features in Modeling Visual Perception of User Interfaces" Big Data and Cognitive Computing 7, no. 1: 30. https://doi.org/10.3390/bdcc7010030
APA StyleBakaev, M., Heil, S., & Gaedke, M. (2023). A Reasonable Effectiveness of Features in Modeling Visual Perception of User Interfaces. Big Data and Cognitive Computing, 7(1), 30. https://doi.org/10.3390/bdcc7010030