



Textual Feature Extraction Using Ant Colony Optimization for Hate Speech Classification

 , , and
, , and 
Abstract
1. Introduction
Motivation
- (1)
- Implement the framework using Ant Colony Optimization (ACO) for feature selection to improve the AI models.
- (2)
- Evaluate these selected features on textual and numerical datasets.
- (3)
- Evaluate and analyze the Logistic Regression (LR), K-Nearest Neighbor (KNN), Stochastic Gradient Descent (SGD), and Random Forest (RF) machine learning algorithms.
2. Literature Review

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Summary | Feature Engineering Techniques Used | Performance Measures | Limitations |
|---|---|---|---|---|
| [10] | Proposes an ACO-based pipeline to improve text categorization performance. | Bag of Words, Information gain, Chi-square | 89.08 Micro-F1 and 78.42 Macro-F1 | - Fails to compare the results with any numerical-based dataset. - Does not cover the limitation of text features while performing the experiment. |
| [5] | Used the ACO algorithm to select the best feature using classifiers C4.5, naïve Bayes, and KNN. | Tagged terms, Bag of Terms, Title Tags, URLs | 0.98 F-measure | - Do not discuss the impact of optimization algorithms on multi-class classification. |
| [16] | Introduced a novel approach to the ACO algorithm with two fuzzy controllers. | Information gain | 98.8% Accuracy | - Does provide a comparative analysis of ten benchmark datasets; However, none of the datasets contain textual data, which is a possible limitation. |
| [17] | Proposes a Multi-Objective Function-Based Ant Colony Optimization (MONACO) procedure for opinion classification. | Term Frequency–Inverse Document Frequency, Information gain | 90.89% Accuracy | - Multi-class classification is not taken into account. |
| [18] | Boosts the Ant Colony Optimization algorithm performance by using the Bayesian classification method. | None | 0.86 Avg TPR and 0.99 Avg TNR | - Comparative analysis with statistical methods, such as information gain and Chi-square, has not been explored. |
| [20] | Proposes Ant Colony Optimization for classification tasks. | None | 96.56% Accuracy | - Does propose a unique feature selection method but fails to shed light on the performance with text data. |
| [10] | Proposes an embedded approach to feature selection using the Chi-square approach for filtering the features. | Term Frequency–Inverse Document Frequency, Chi-square | 89.08 Micro-F1 and 78.42 Macro-F1 | - Does not discuss the effectiveness of the approach on another textual dataset as well as its impact on the data having numerical columns. |
| [22] | Discusses a combined SVM-ACO pipeline for choosing more relevant features from large datasets. | None | 95.90% Accuracy | - Fails to cover text classification and its impact on feature selection algorithms. |
| [23] | Presents the hybridization of ACO and genetic algorithm for feature selection. | None | 99.93% Accuracy | -Multi-class classification of text data not performed, and no comparison with standard feature selection methods. |
| [24] | Proposes a hybrid strategy for feature subset selection using the classifier ensemble with ACO algorithm. | Information gain, Gain ratio | 97.33% Accuracy | -Not tested on text data and lacks comparison with standard feature selection methods. |
| [25] | Introduces FACO algorithm developed for feature selection. | FACO | 96% Accuracy | - Lacks discussion of data type used in the experiment. |
| [19] | Proposes spam classification using Naive Bayes’s classifier for improved results. | Ant Colony Optimization | 84% Accuracy | - Only one classifier has been used for classification. |
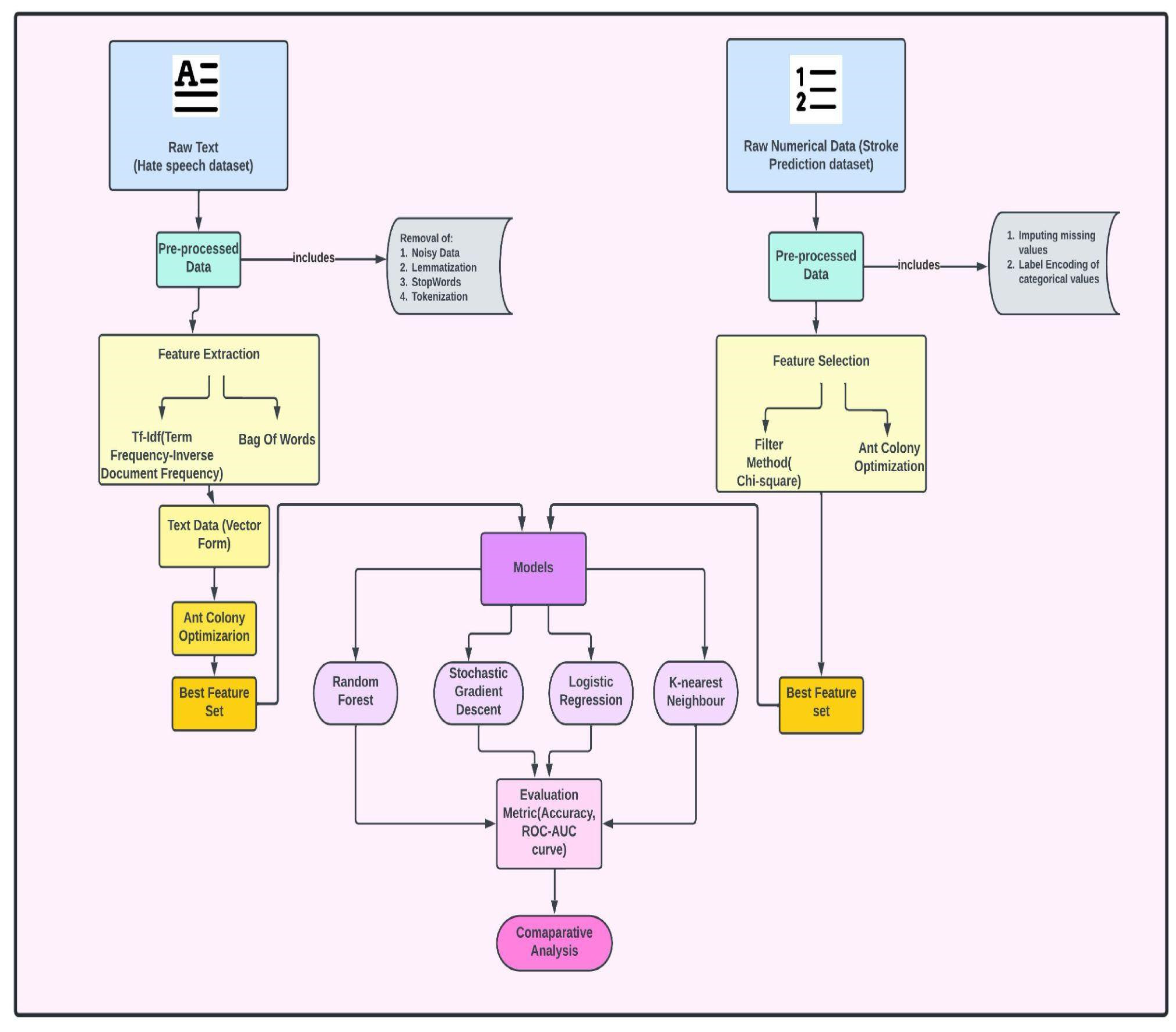
3. Data and Methodology
3.1. Data Acquisition
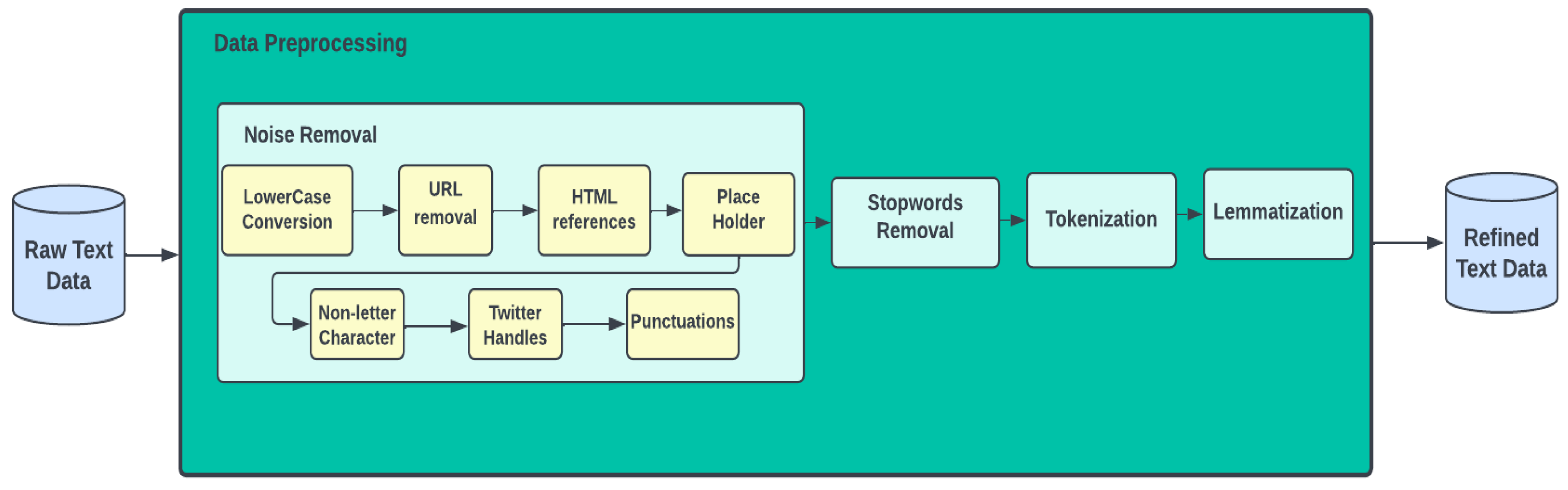
3.2. Data Preprocessing
3.2.1. Stroke Dataset
3.2.2. Hate Speech Dataset
3.3. Feature Engineering Techniques
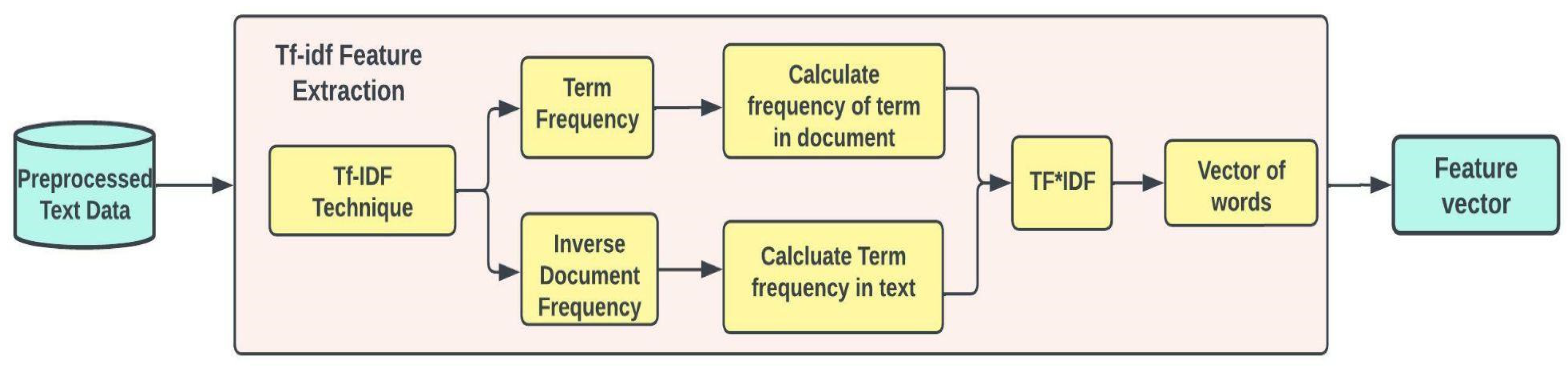
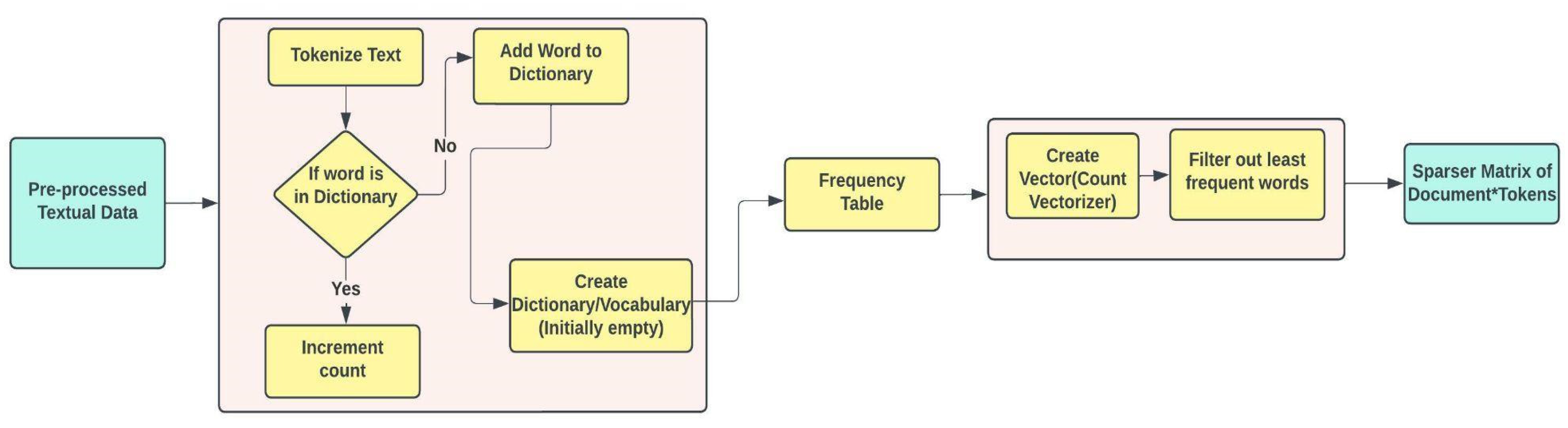
3.3.1. Feature Extraction
- A list of terms (vocabulary) that are well-known.
- A metric for determining the existence of vocabulary.
- Tokenization of text.
- Building a vocabulary of words by scanning the dictionary for every token and adding them to the dictionary. If a word is not present, the frequency table is updated with a new frequency count.
- Lastly, text vectorization is performed to get the most frequent words in the numerical form.
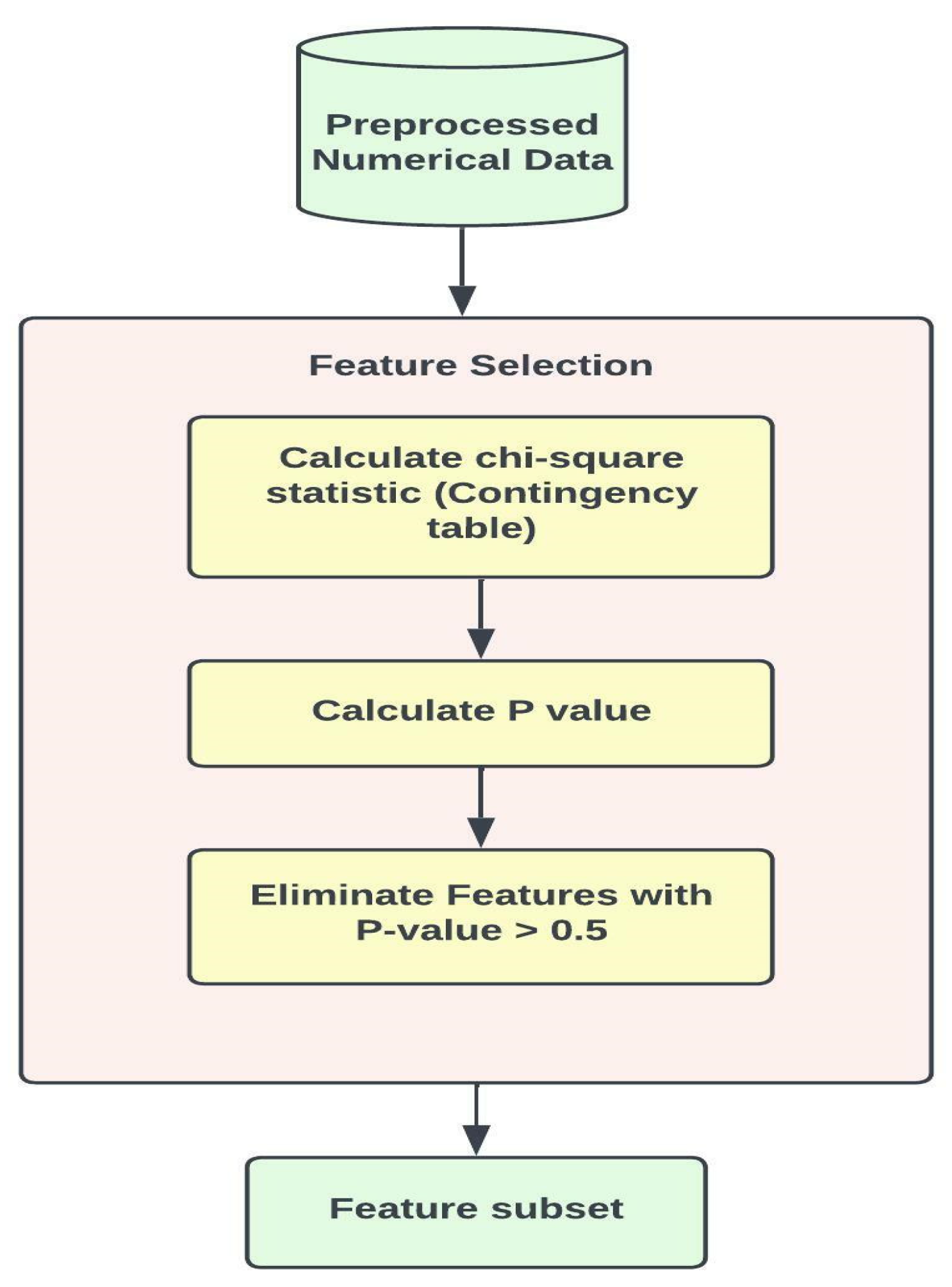
3.3.2. Feature Selection
- Filter Method—A typical data preparation approach, the filter method combines ranking techniques with standard measures and selects variables using sorting strategies. The ranking approach removes irrelevant features before beginning the classification process [36]. Filter methods can be of two types: global and local, which depend upon whether the score is single or multi-class. A globalization policy is required in the case of local feature selection methods to combine various local values into a single global score. When using global feature selection techniques, the scores can be used to rank features directly. The features are ranked in ascending order, with the top-N features being included in the feature set, with N being an empirically determined number [37]. The feature selection method can include information gain (IG), correlation, Chi-square (CHI), Gini Index, and SVM. Chi-square is the one we are interested in for this particular study.
- Chi-square—The Chi-square test is among the most helpful statistical tests. It offers information not only on the critical difference observed, but also on the differences between categories. It helps to determine the correlation between the variables in the data. The formula employed for performing the Chi-square test could be observed as shown in Equation (2).where c is the degree of freedom, and O and E are the observed and the expected value, respectively [38].
- Check data distribution according to a well-known theoretical probability distribution such as the Normal or Poisson distribution.
- The Chi-squared test can evaluate the quality of fit of your trained model on the train, validation, and test dataset.
4. Machine Learning Models
4.1. Logistic Regression
4.2. K-Nearest Neighbor
4.3. Random Forest
4.4. Stochastic Gradient Descent
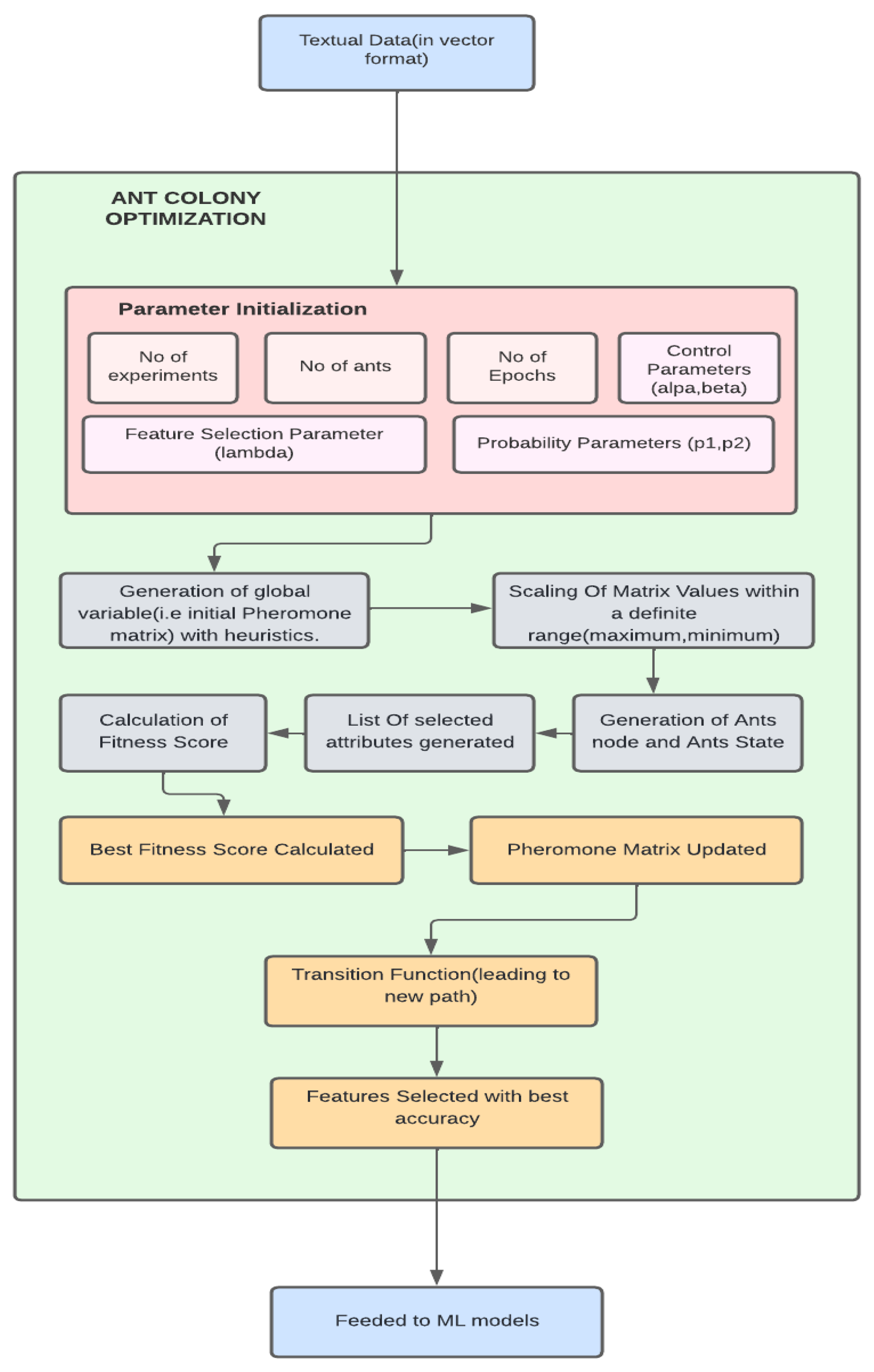
5. Ant Colony Optimization Algorithm
5.1. Optimization Algorithm
5.2. Ant Colony Optimization
5.3. Architecture
6. Proposed Architecture
7. Experimental Setup
7.1. Dataset
- Keyword: the keyword used for the extraction of the tweets;
- Datetime: the date on which the tweet was posted;
- Tweet-id: unique id for each tweet posted;
- Text: it contained the actual tweets posted by the user;
- Username: it contained the name of the user who posted the tweet.
7.2. Parameter Settings
7.3. Evaluation Metrics
8. Results and Discussion
9. Conclusions and Future Scope
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, S.R.; Bakar, A.A.; Yaakub, M.R. Ant colony optimization for text feature selection in sentiment analysis. Intell. Data Anal. 2019, 23, 133–158. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Saraç, E.; Özel, S.A. An ant colony optimization based feature selection for web page classification. Sci. World J. 2014, 2014, 649260. [Google Scholar] [CrossRef]
- Gao, S.; Ng, Y.K. Generating extractive sentiment summaries for natural language user queries on products. ACM SIGAPP Appl. Comput. Rev. 2022, 22, 5–20. [Google Scholar] [CrossRef]
- Fan, C.; Chen, M.; Wang, X.; Wang, J.; Huang, B. A Review on Data Preprocessing Techniques Toward Efficient and Reliable Knowledge Discovery from Building Operational Data. Front. Energy Res. 2021, 9, 652801. [Google Scholar] [CrossRef]
- Kumar, V.; Minz, S. Feature selection: A literature review. SmartCR 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings 1992; Morgan Kaufmann: San Mateo, CA, USA, 1992; pp. 249–256. [Google Scholar] [CrossRef]
- Aghdam, M.H.; Ghasem-Aghaee, N.; Basiri, M.E. Text feature selection using ant colony optimization. Expert Syst. Appl. 2009, 36, 6843–6853. [Google Scholar] [CrossRef]
- Kumar, S.R.; Singh, K.D. Nature-Inspired Optimization Algorithms: Research Direction and Survey. arXiv 2021, arXiv:2102.04013. [Google Scholar]
- Rodrigues, D.; Yang, X.S.; de Souza, A.N.; Papa, J.P. Binary Flower Pollination Algorithm and Its Application to Feature Selection. In Recent Advances in Swarm Intelligence and Evolutionary Computation; Studies in Computational Intelligence; Yang, X.S., Ed.; Springer: Cham, Switzerland, 2015; Volume 585. [Google Scholar] [CrossRef]
- Banati, H.; Bajaj, M. Fire Fly Based Feature Selection Approach. Int. J. Comput. Sci. Issues 2011, 8, 473–480. [Google Scholar]
- Kashef, S.; Nezamabadi-pour, H. An advanced ACO algorithm for feature subset selection. Neurocomputing 2015, 147, 271–279. [Google Scholar] [CrossRef]
- Alghamdi, H.S.; Tang, H.; Alshomrani, S. Hybrid ACO and TOFA feature selection approach for text classification. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, Brisbane, QLD, Australia, 10–12 June 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, G.; Chen, H.; Zhao, Z.; Zhu, X.; Liu, Z. An adaptive fuzzy ant colony optimization for feature selection. J. Comput. Inf. Syst. 2011, 7, 1206–1213. [Google Scholar]
- Renukadevi, N.T.; Karunakaran, S.; Saraswathi, K. Multi ant colony optimization for opinion classification. Int. J. Sci. Technol. Res. 2020, 9, 4554–4560. [Google Scholar]
- Aghdam, M.H.; Tanha, J.; Naghsh-Nilchi, A.R.; Basiri, M.E. Combination of ant colony optimization and Bayesian classification for feature selection in a bioinformatics dataset. J. Comput. Sci. Syst. Biol. 2009, 2, 186–199. [Google Scholar] [CrossRef]
- Renuka, D.K.; Visalakshi, P.; Sankar, T.J.I.J.C.A. Improving E-mail spam classification using ant colony optimization algorithm. Int. J. Comput. Appl. 2015, 22, 26. [Google Scholar]
- Sabeena, S.; Balakrishnan, S. Optimal Feature Subset Selection using Ant Colony Optimization. Indian J. Sci. Technol. 2015, 8, 1–8. [Google Scholar] [CrossRef]
- Imani, M.B.; Keyvanpour, M.R.; Azmi, R. A novel embedded feature selection method: A comparative study in the application of text categorization. Appl. Artif. Intell. 2013, 27, 408–427. [Google Scholar] [CrossRef]
- Dwivedi, R.; Kumar, R.; Jangam, E.; Kumar, V. An ant colony optimization based feature selection for data classification. Int. J. Recent Technol. Eng. 2019, 7, 35–40. [Google Scholar]
- Suresh, G.; Balasubramanian, R. An ensemble feature selection model using fast convergence ant colony optimization algorithm. Int. J. 2020, 8, 1417–1423. [Google Scholar] [CrossRef]
- Naseer, A.; Shahzad, W.; Ellahi, A. A hybrid approach for feature subset selection using ant colony optimization and multi-classifier ensemble. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 306–313. [Google Scholar] [CrossRef]
- Peng, H.; Ying, C.; Tan, S.; Hu, B.; Sun, Z. An improved feature selection algorithm based on ant colony optimization. IEEE Access 2018, 6, 69203–69209. [Google Scholar] [CrossRef]
- Tazin, T.; Alam, M.N.; Dola, N.N.; Bari, M.S.; Bourouis, S.; Monirujjaman Khan, M. Stroke Disease Detection and Prediction Using Robust Learning Approaches. J. Healthc. Eng. 2021, 2021, 7633381. [Google Scholar] [CrossRef] [PubMed]
- Kaur, J.; Buttar, P.K. Stopwords removal and its algorithms based on different methods. Int. J. Adv. Res. Comput. Sci. 2018, 9, 81–88. [Google Scholar] [CrossRef]
- Selvaraj, S.; Choi, E. Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks. Sensors 2021, 21, 3196. [Google Scholar] [CrossRef]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. On stopwords, filtering and data sparsity for sentiment analysis of twitter. In Proceedings of the LREC 2014, Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Mullen, L.A.; Benoit, K.; Keyes, O.; Selivanov, D.; Arnold, J. Fast, consistent tokenization of natural language text. J. Open Source Softw. 2018, 3, 655. [Google Scholar] [CrossRef]
- Grefenstette, G. Tokenization. In Syntactic Wordclass Tagging. Text, Speech and Language Technology; van Halteren, H., Ed.; Springer: Dordrecht, The Netherlands, 1999; Volume 9. [Google Scholar] [CrossRef]
- Camacho-Collados, J.; Pilehvar, M.T. On the role of text preprocessing in neural network architectures: An evaluation study on text categorization and sentiment analysis. arXiv 2017, arXiv:1707.01780. [Google Scholar] [CrossRef]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text feature extraction based on deep learning: A review. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 1–12. [Google Scholar] [CrossRef]
- Soumya George, K.; Joseph, S. Text classification by augmenting bag of words (BOW) representation with co-occurrence feature. IOSR J. Comput. Eng. 2014, 16, 34–38. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Huljanah, M.; Rustam, Z.; Utama, S.; Siswantining, T. Feature selection using random forest classifier for predicting prostate cancer. IOP Conf. Ser. Mater. Sci. Eng. 2019, 546, 052031. [Google Scholar] [CrossRef]
- Uysal, A.K. An improved global feature selection scheme for text classification. Expert Syst. Appl. 2016, 43, 82–92. [Google Scholar] [CrossRef]
- Liu, Y.; Ju, S.; Wang, J.; Su, C. A new feature selection method for text classification based on independent feature space search. Math. Probl. Eng. 2020, 2020, 6076272. [Google Scholar] [CrossRef]
- Choudhury, A.; Eksioglu, B. Using predictive analytics for cancer identification. In Proceedings of the 2019 IISE Annual Conference, Orlando, FL, USA, 18–21 May 2019; Romeijn, H.E., Schaefer, A., Thomas, R., Eds.; IISE: Orlando, FL, USA, 2019. [Google Scholar]
- Maalouf, M. Logistic regression in data analysis: An overview. Int. J. Data Anal. Tech. Strateg. 2011, 3, 281–299. [Google Scholar] [CrossRef]
- Park, H.A. An introduction to logistic regression: From basic concepts to interpretation with particular attention to nursing domain. J. Korean Acad. Nurs. 2013, 43, 154–164. [Google Scholar] [CrossRef]
- Ma, S.; Liu, F.; Ma, C.; Ouyang, X. Integrating logistic regression with ant colony optimization for smart urban growth modelling. Front. Earth Sci. 2020, 14, 77–89. [Google Scholar] [CrossRef]
- Schober, P.; Vetter, T.R. Logistic regression in medical research. Anesth. Analg. 2021, 132, 365. [Google Scholar] [CrossRef]
- Hu, L.Y.; Huang, M.W.; Ke, S.W.; Tsai, C.F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef]
- Surya, V.B.; Haneen, P.; Ahmad, A.A.; Omar, B.A.; Ahmad, L. Effects of Distance Measure Choice on KNN Classifier Performance—A Review; Mary Ann Liebert: New Rochelle, NY, USA, 2019. [Google Scholar] [CrossRef]
- Zhang, Z. Introduction to machine learning: K-nearest neighbors. Ann. Transl. Med. 2016, 4, 218. [Google Scholar] [CrossRef]
- Hassanat, A.B.; Abbadi, M.A.; Altarawneh, G.A.; Alhasanat, A.A. Solving the problem of the K parameter in the KNN classifier using an ensemble learning approach. arXiv 2014, arXiv:1409.0919. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Cui, X.; Zhang, W.; Tüske, Z.; Picheny, M. Evolutionary stochastic gradient descent for optimization of deep neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Yazdani, M.; Jolai, F. Lion optimization algorithm (LOA): A nature-inspired metaheuristic algorithm. J. Comput. Des. Eng. 2016, 3, 24–36. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Abdel-Fatah, L.; Sangaiah, A.K. Metaheuristic algorithms: A comprehensive review. In Computational Intelligence for Multimedia Big Data on the Cloud with Engineering Applications; Elsevier: Amsterdam, The Netherlands, 2018; pp. 185–231. [Google Scholar] [CrossRef]
- Amelio, A.; Bonifazi, G.; Corradini, E.; Ursino, D.; Virgili, L. A Multilayer Network-Based Approach to Represent, Explore and Handle Convolutional Neural Networks. Cogn. Comput. 2022. [Google Scholar] [CrossRef]
- Amelio, A.; Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Ursino, D.; Virgili, L. Representation and compression of Residual Neural Networks through a multilayer network based approach. Expert Syst. Appl. 2023, 215, 119391. [Google Scholar] [CrossRef]
- Al-Ani, A. Ant Colony Optimization for Feature Subset Selection. In Proceedings of the WEC (2), Istanbul, Turkey, 25–27 February 2005; pp. 35–38. [Google Scholar]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Nayyar, A.; Singh, R. Ant Colony Optimization—Computational swarm intelligence technique. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1493–1499. [Google Scholar]
- Okonta, C.I.; Kemp, A.H.; Edopkia, R.O.; Monyei, G.C.; Okelue, E.D. A heuristic based ant colony optimization algorithm for energy efficient smart homes. In Proceedings of the ICCE 2016: 5th International Conference & Exhibition on Clean Energy, Montreal, QC, Canada, 22–24 August 2016; pp. 1–12. [Google Scholar]
- Dorigo, M. Ant colony optimization. Scholarpedia 2007, 2, 1461. [Google Scholar] [CrossRef]
- Fidanova, S. Ant Colony Optimization. In Ant Colony Optimization and Applications; Springer: Cham, Switzerland, 2021; pp. 3–8. [Google Scholar]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. Using kNN model for automatic text categorization. Soft Comput. 2006, 10, 423–430. [Google Scholar] [CrossRef]
- Sanyal, D.; Bosch, N.; Paquette, L. Feature Selection Metrics: Similarities, Differences, and Characteristics of the Selected Models. In Proceedings of the 13th International Conference on Educational Data Mining (EDM), Online, 10–13 July 2020. [Google Scholar]
- Ashokan, S.; Narayanan, S.G.; Mandresh, S.; Vidhyasagar, B.; Anand, G.P. An Effective Stroke Prediction System using Predictive Models. Int. Res. J. Eng. Technol. (IRJET) 2020, 7, 3979–3985. [Google Scholar]
- Kaur, C.; Sharma, A. COVID-19 Sentimental Analysis Using Machine Learning Techniques. In Progress in Advanced Computing and Intelligent Engineering; Springer: Singapore, 2021; pp. 153–162. [Google Scholar] [CrossRef]
- Wei, X. Parameters Analysis for Basic Ant Colony Optimization Algorithm in TSP. Int. J. u-e-Serv. Sci. Technol. 2014, 7, 159–170. [Google Scholar] [CrossRef]
- Hamori, S.; Kawai, M.; Kume, T.; Murakami, Y.; Watanabe, C. Ensemble learning or deep learning? Application to default risk analysis. J. Risk Financ. Manag. 2018, 11, 12. [Google Scholar] [CrossRef]
- Carter, J.V.; Pan, J.; Rai, S.N.; Galandiuk, S. ROC-ing along: Evaluation and interpretation of receiver operating characteristic curves. Surgery 2016, 159, 1638–1645. [Google Scholar] [CrossRef]
- Kou, G.; Yang, P.; Peng, Y.; Xiao, F.; Chen, Y.; Alsaadi, F.E. Evaluation of feature selection methods for text classification with small datasets using multiple criteria decision-making methods. Appl. Soft Comput. 2020, 86, 105836. [Google Scholar] [CrossRef]
- Sailasya, G.; Kumari, G.L.A. Analyzing the performance of stroke prediction using ML classification algorithms. Int. J. Adv. Comput. Sci. Appl 2021, 12, 539–545. [Google Scholar] [CrossRef]
- Khan, M.; Khan, M.S.; Alharbi, Y. Text Mining Challenges and Applications—A Comprehensive Review. Int. J. Comput. Sci. Netw. Secur. 2020, 20, 138. [Google Scholar] [CrossRef]
- Kabir, M.; Shahjahan, M.; Murase, K.; Barbosa, H.J.C. Ant colony optimization toward feature selection. In Ant Colony Optimization-Techniques and Applications; IntechOpen: London, UK, 2013; pp. 1–43. [Google Scholar]
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 9. [Google Scholar] [CrossRef]













| Name of Dataset | Number of Samples | Balanced/ Unbalanced | Resampling Technique | No. of Labels | Name of Labels |
|---|---|---|---|---|---|
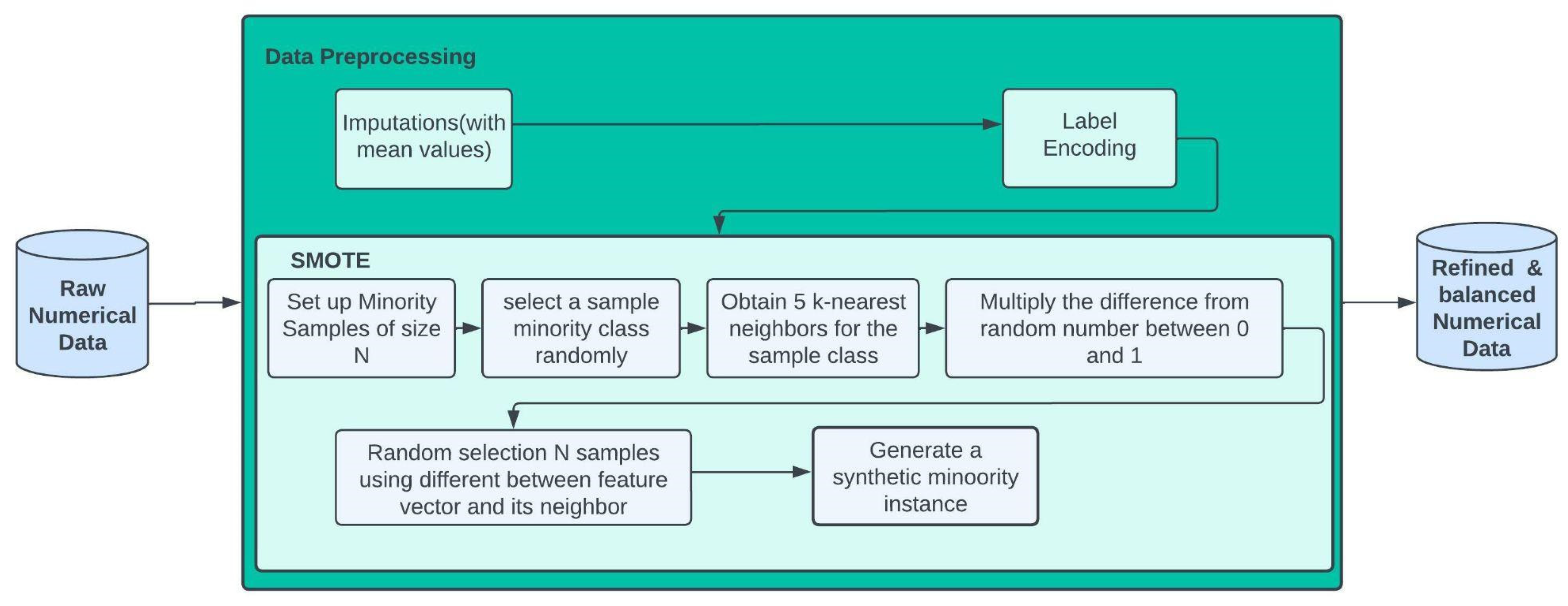
| Stroke Prediction (Numerical Data) | 5110 | Unbalanced | SMOTE Oversampling | 2 | Stroke and No stroke |
| Stroke: 249 | |||||
| No stroke: 4861 | |||||
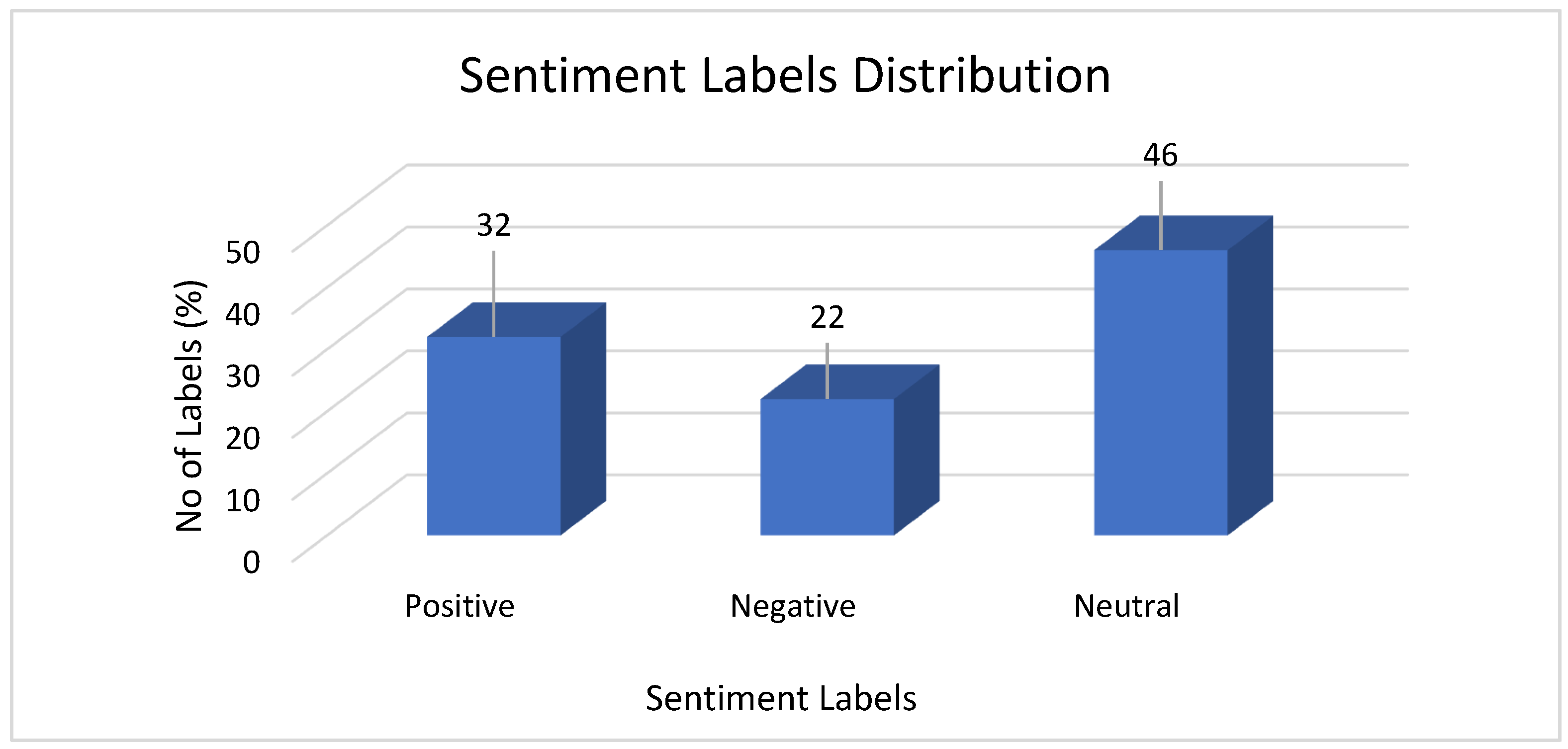
| Twitter Data on Extremism (Text Data) | 93,501 | Balanced | None | 3 | Positive, Negative, and Neutral |
| Positive (2): 29,652 | |||||
| Negative (0): 33,880 | |||||
| Neutral (1): 29,969 |
| Dataset | Feature Extraction Technique | Optimization Algorithm | Population | Iteration | Epoch | Alpha | Beta |
|---|---|---|---|---|---|---|---|
| Hate Speech dataset | TF-IDF | Ant Colony Optimization | 40 | 1 | 2 | 1 | 0.2 |
| Bag of Words | Ant Colony Optimization | 80 | 1 | 2 | 1 | 0.02 | |
| Stroke dataset | SMOTE | Ant Colony Optimization | 20 | 1 | 5 | 1 | 0.2 |
| Dataset | Feature Engineering Technique | Optimization Algorithm | Models | Accuracy |
|---|---|---|---|---|
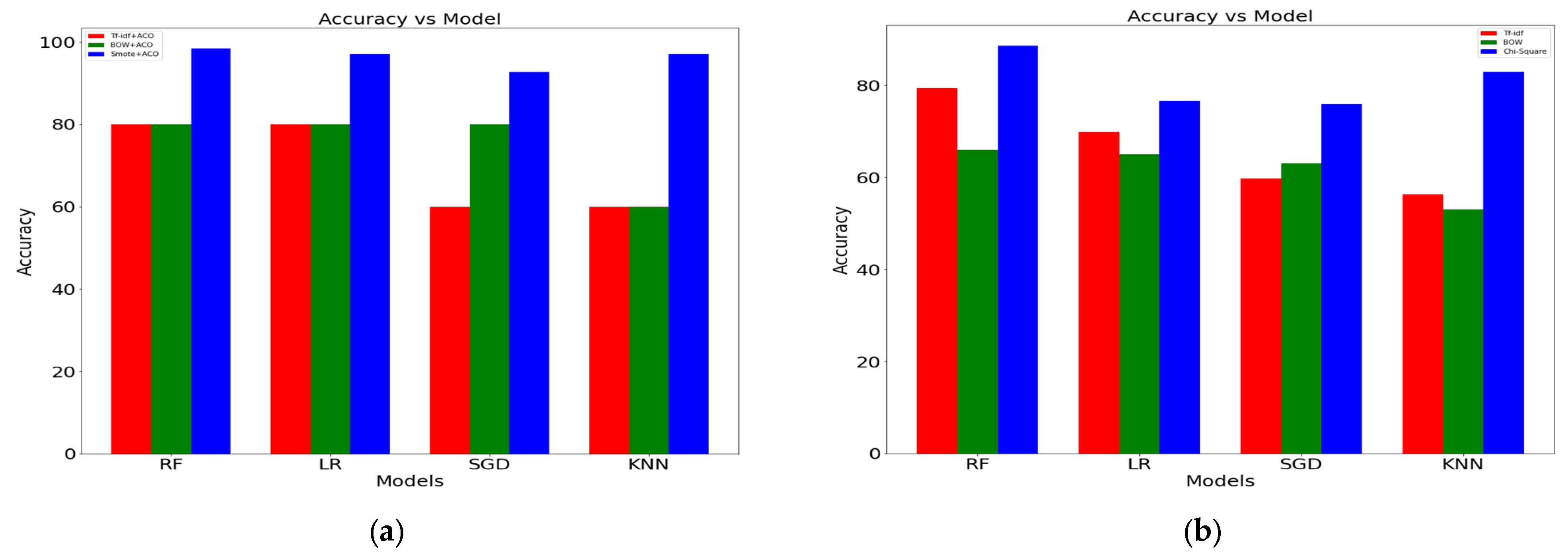
| Hate Speech Dataset (Textual) | Tf-idf | ACO | Random Forest | 80% |
| LR | 80% | |||
| SGD | 60% | |||
| KNN | 60% | |||
| BoW | ACO | Random Forest | 80% | |
| SGD | 80% | |||
| LR | 80% | |||
| KNN | 60% | |||
| Tf-idf | None | LR | 79.33% | |
| Random Forest | 69.93% | |||
| SGD | 59.83% | |||
| KNN | 56.38% | |||
| BoW | None | Random Forest | 66% | |
| LR | 65% | |||
| SGD | 63% | |||
| KNN | 53% | |||
| Stroke Prediction Dataset (Numerical) | SMOTE | ACO | Random Forest | 98.43% |
| SGD | 92.76% | |||
| LR | 97.06% | |||
| KNN | 97.16% | |||
| SMOTE + Filter Method (chi-square) | None | Random Forest | 88.6% | |
| KNN | 83% | |||
| LR | 76.6% | |||
| SGD | 75.9% |
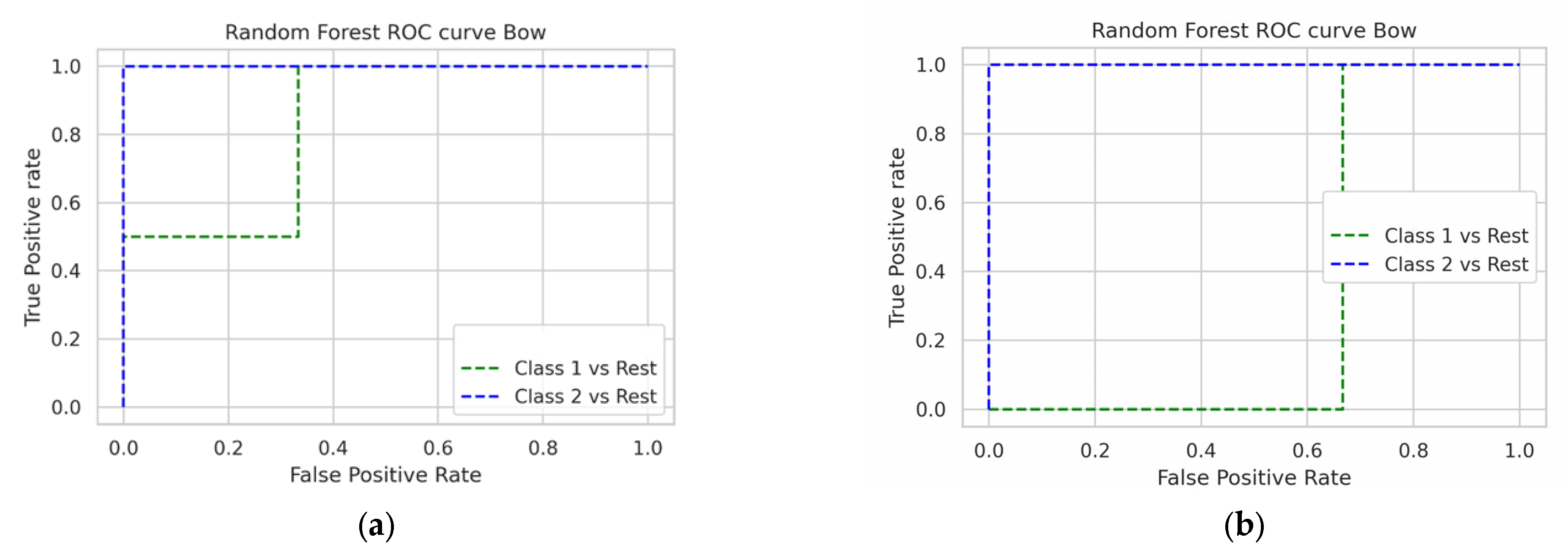
| Model | Methodology | Dataset Type | Accuracy | ROC-AUC Score |
|---|---|---|---|---|
| Random Forest, Logistic Regression | TF-IDF + ACO | Text | 80% | 0.88 |
| Random Forest, Stochastic Gradient Descent | Bag of Words + ACO | Text | 80% | 0.77 |
| Random Forest | SMOTE + ACO | Numerical | 98.43% | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gite, S.; Patil, S.; Dharrao, D.; Yadav, M.; Basak, S.; Rajendran, A.; Kotecha, K. Textual Feature Extraction Using Ant Colony Optimization for Hate Speech Classification. Big Data Cogn. Comput. 2023, 7, 45. https://doi.org/10.3390/bdcc7010045
Gite S, Patil S, Dharrao D, Yadav M, Basak S, Rajendran A, Kotecha K. Textual Feature Extraction Using Ant Colony Optimization for Hate Speech Classification. Big Data and Cognitive Computing. 2023; 7(1):45. https://doi.org/10.3390/bdcc7010045
Chicago/Turabian StyleGite, Shilpa, Shruti Patil, Deepak Dharrao, Madhuri Yadav, Sneha Basak, Arundarasi Rajendran, and Ketan Kotecha. 2023. "Textual Feature Extraction Using Ant Colony Optimization for Hate Speech Classification" Big Data and Cognitive Computing 7, no. 1: 45. https://doi.org/10.3390/bdcc7010045
APA StyleGite, S., Patil, S., Dharrao, D., Yadav, M., Basak, S., Rajendran, A., & Kotecha, K. (2023). Textual Feature Extraction Using Ant Colony Optimization for Hate Speech Classification. Big Data and Cognitive Computing, 7(1), 45. https://doi.org/10.3390/bdcc7010045