
Is My Pruned Model Trustworthy? PE-Score: A New CAM-Based Evaluation Metric



Abstract
:1. Introduction
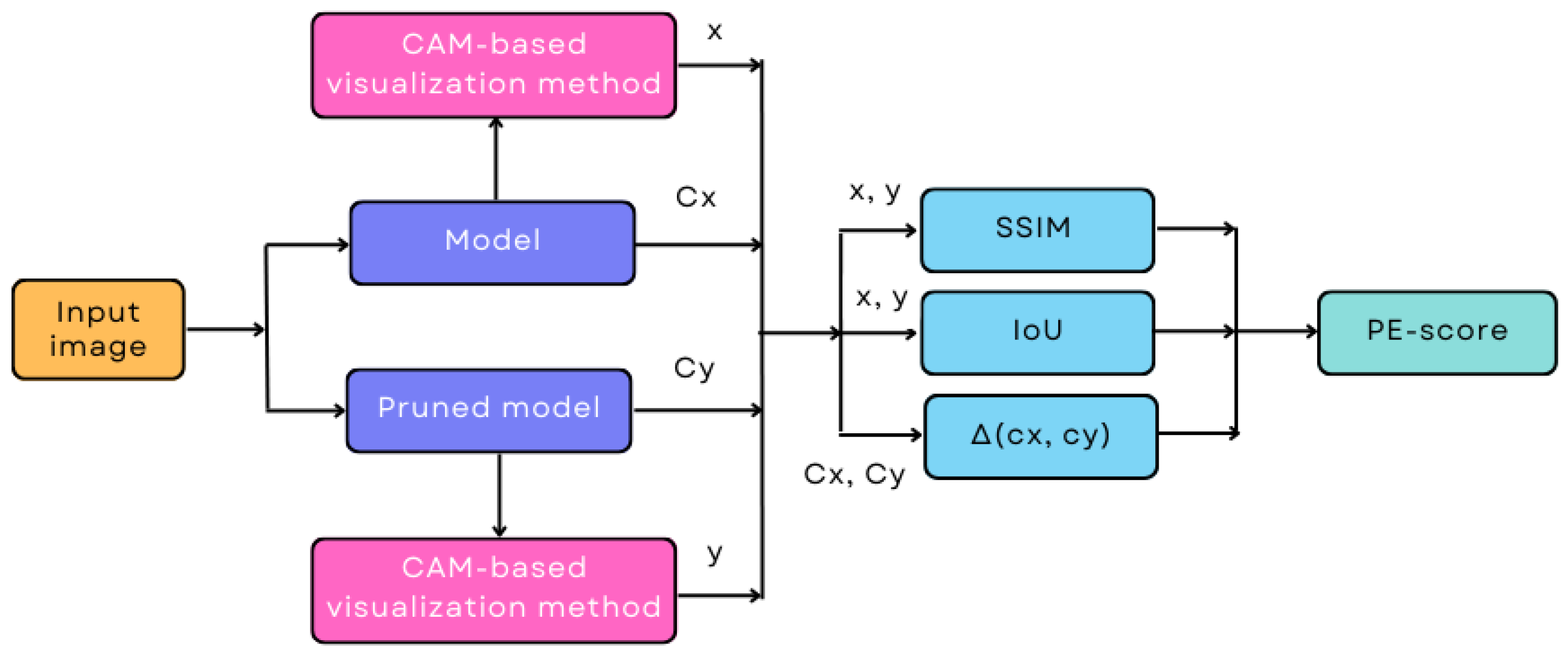
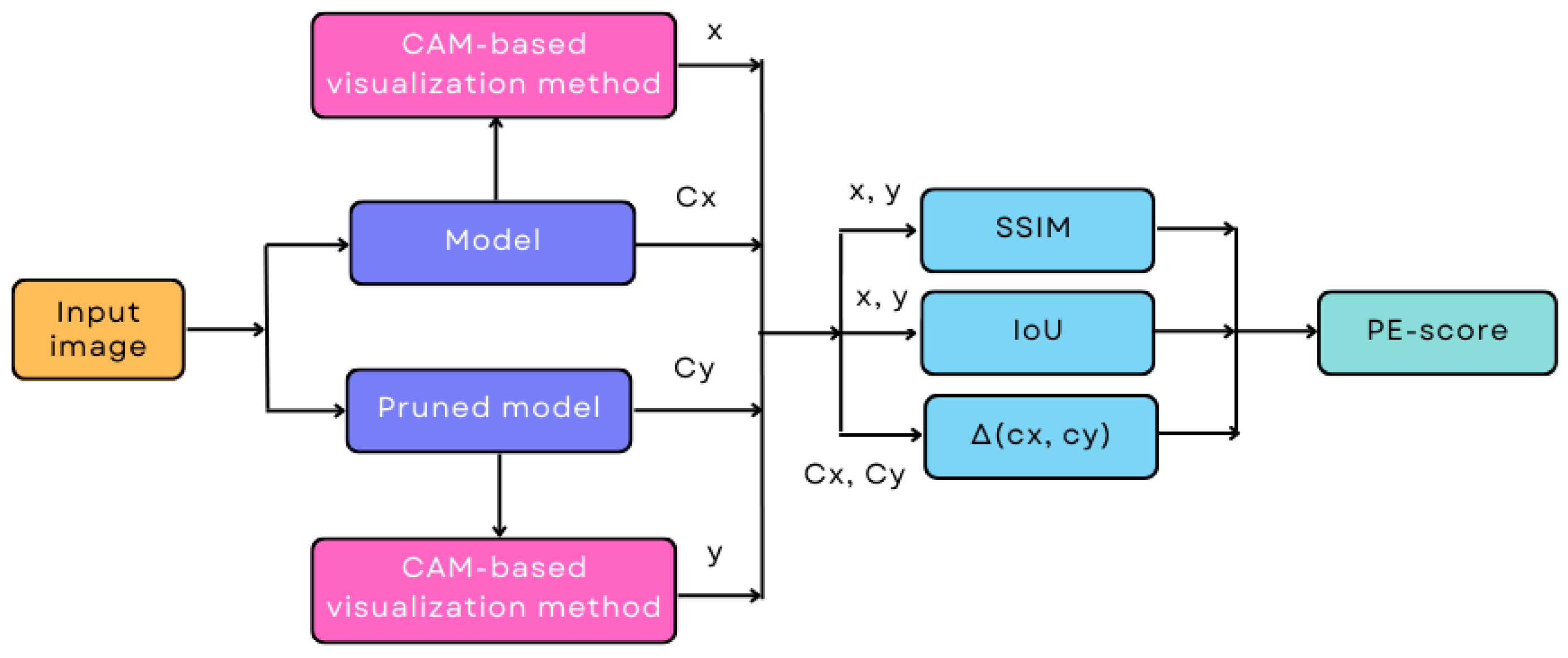
- A metric to evaluate the reliability of pruned models that is independent of both the criterion and the pruning rate is proposed (PE-score). This metric is calculated from two similarity measures ( and ) and from the confidence variance of the class. The (Structural Similarity Index Measure) and (Intersection over Union) are computed between the class activation maps of the original and pruned models, using a CAM (Class Activation Map) type method, such as Grad-CAM++ [23].
- The importance of the PE-score is shown through a reliability analysis of the pruned models. Two different pruning methods (Weight and SeNPIS-Faster) are evaluated for two sets of images (CIFAR10 and COVID-19), concluding that a reliable pruned model is not only the one that preserves the accuracy of the original model, but also the one that performs image classification based on the same patterns (pixels) as the unpruned model.
- A procedure for selecting the PR (pruning rate) value is also provided, to ensure that the pruned model is trustworthy.
2. Background
2.1. Accuracy in Image Classification Models
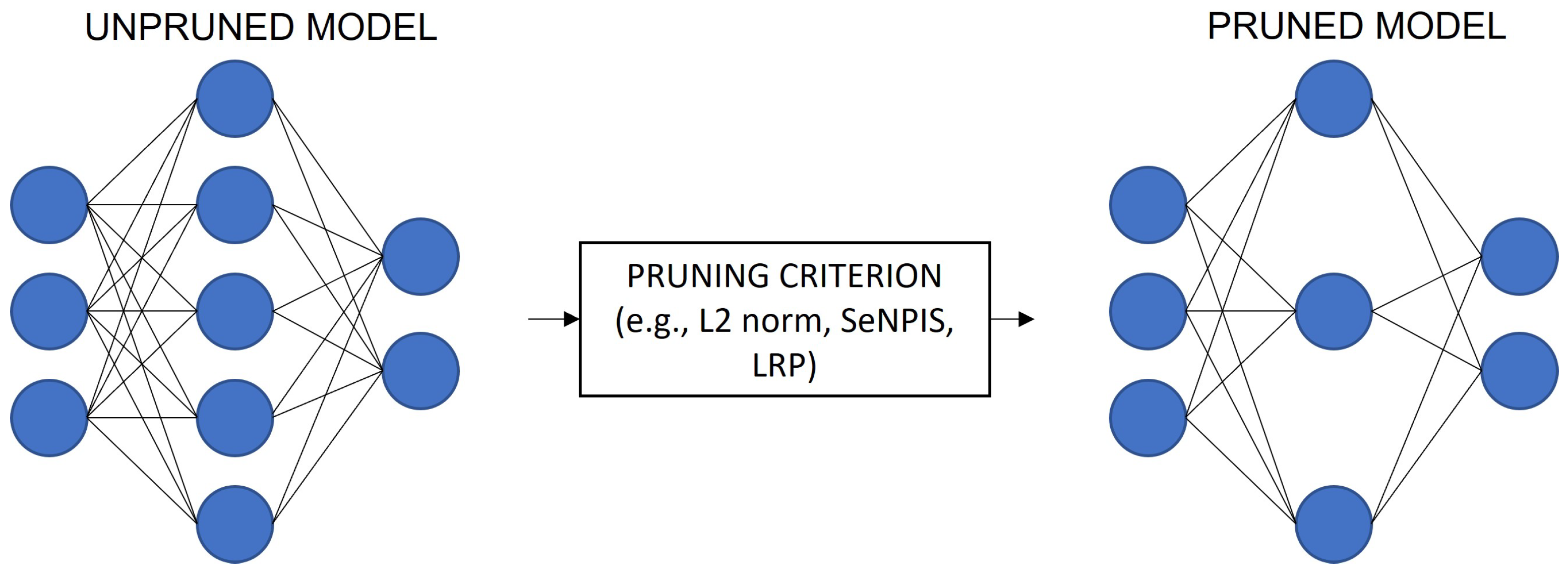
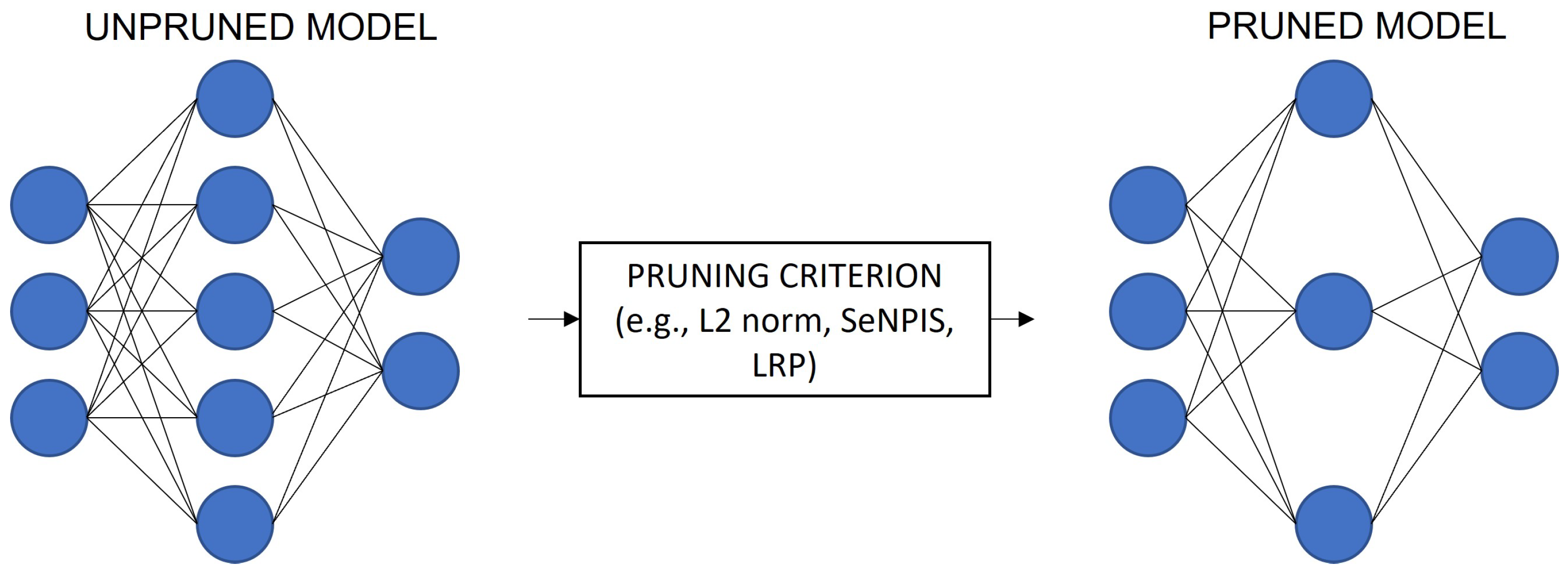
2.2. Pruning
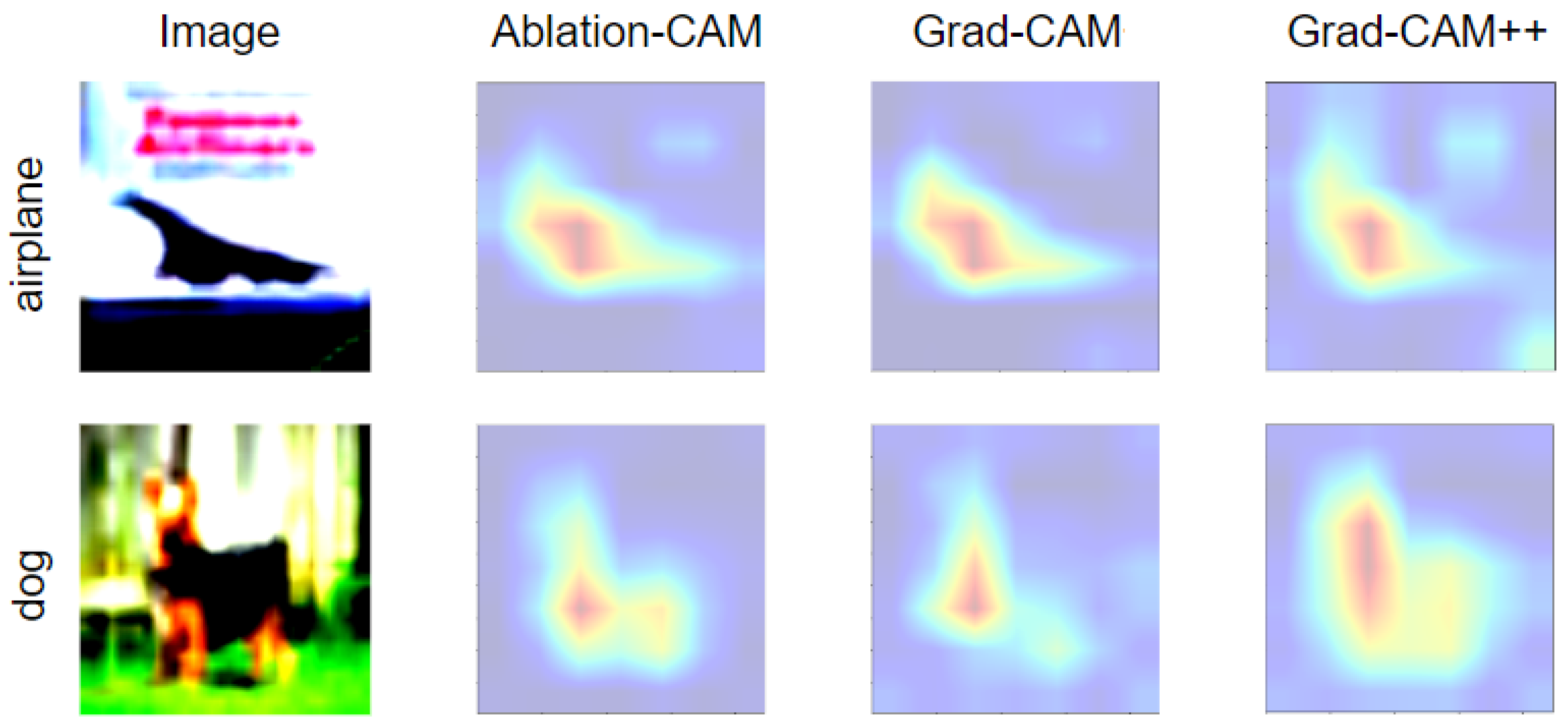
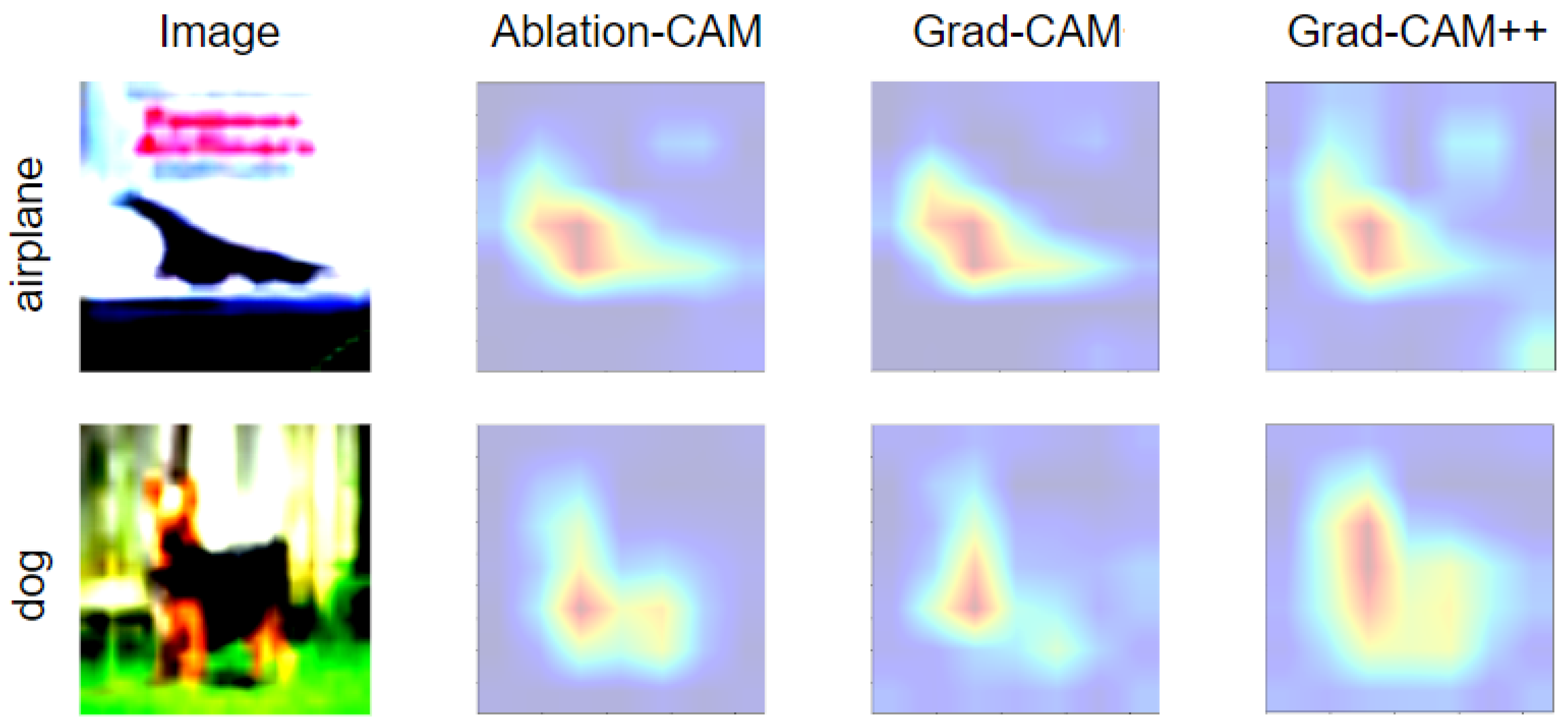
2.3. Visualization Methods
3. Materials and Methods
- Calculate the PE-score for each image of each class of the test dataset. In particular, a is obtained, where k varies from 1 to the number of classes K, and i varies from 1 to the number of images of the specific class, i.e., .
- Calculate the average PE-score per class, i.e.,
- Weight the PE-score obtained by each class, taking into account its weight () within the dataset, as follows: .
4. Results
4.1. Complexity of the Dataset
- Determine whether there is a direct relationship between the decrease in model accuracy and the decrease in PE-score as PR increases;
- Determine why, in some datasets, there is a fluctuation in accuracy as PR increases and PE decreases.
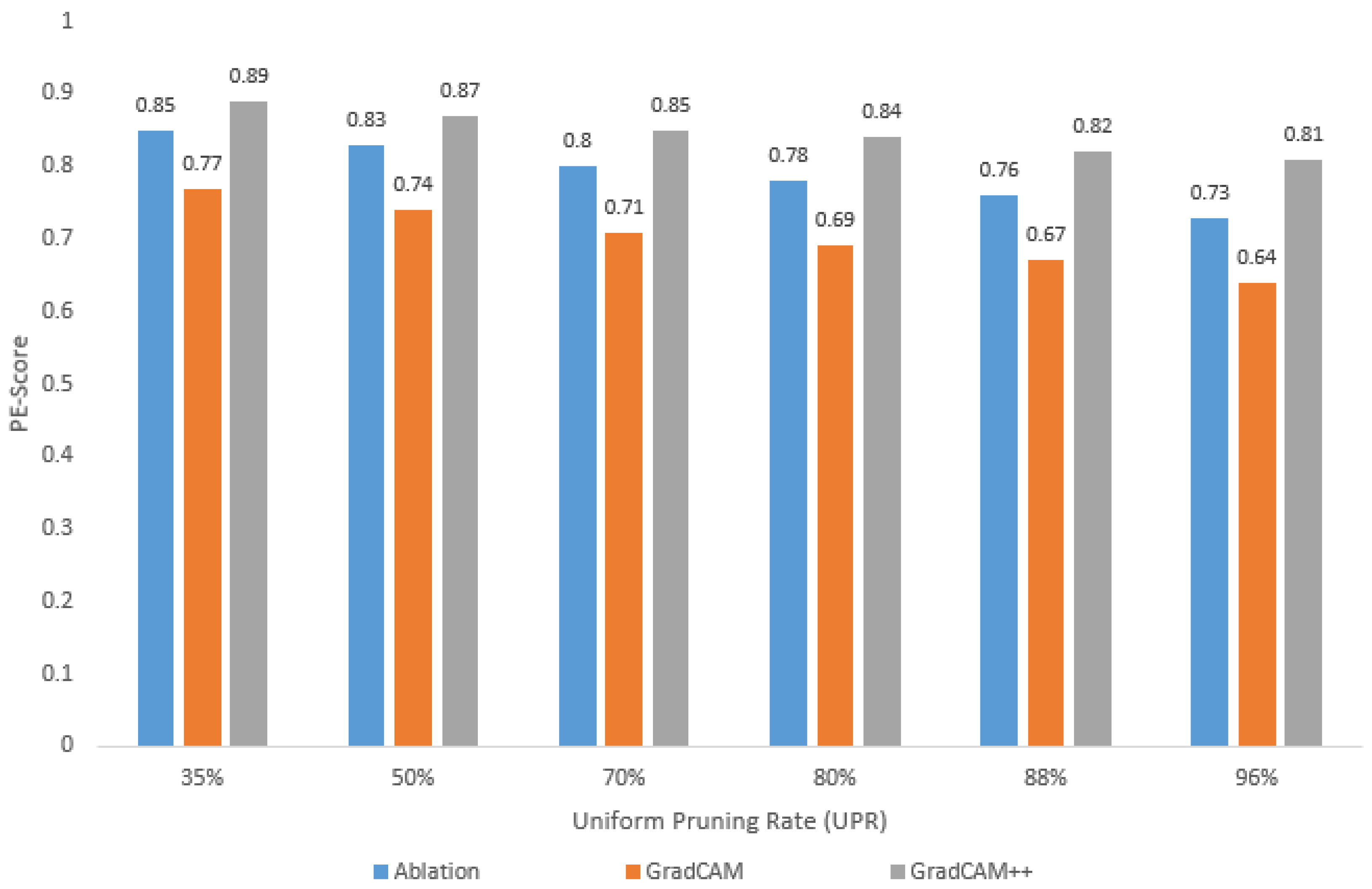
4.2. Trustworthiness of Pruned Models: Case of the CIFAR10 Dataset
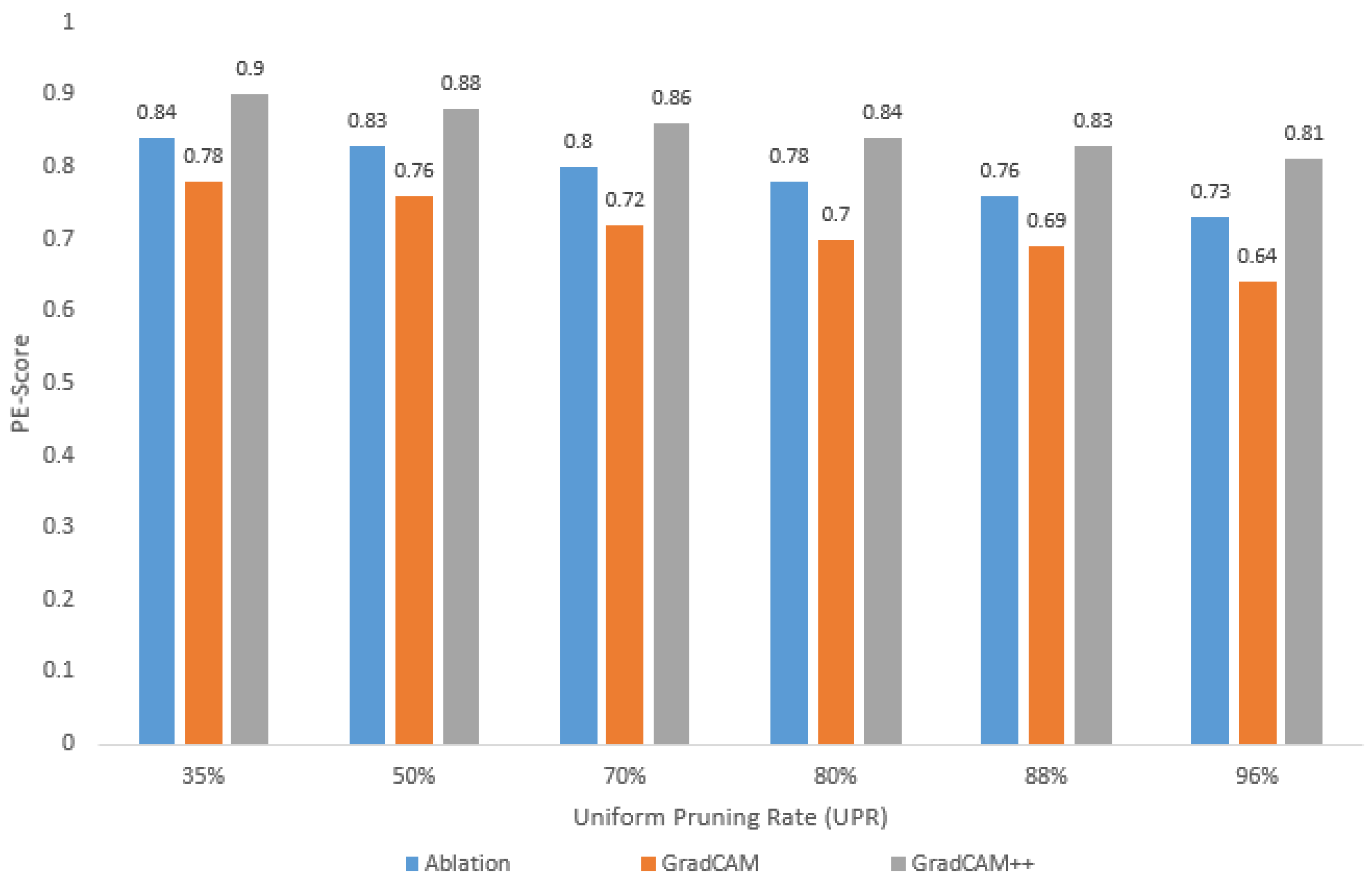
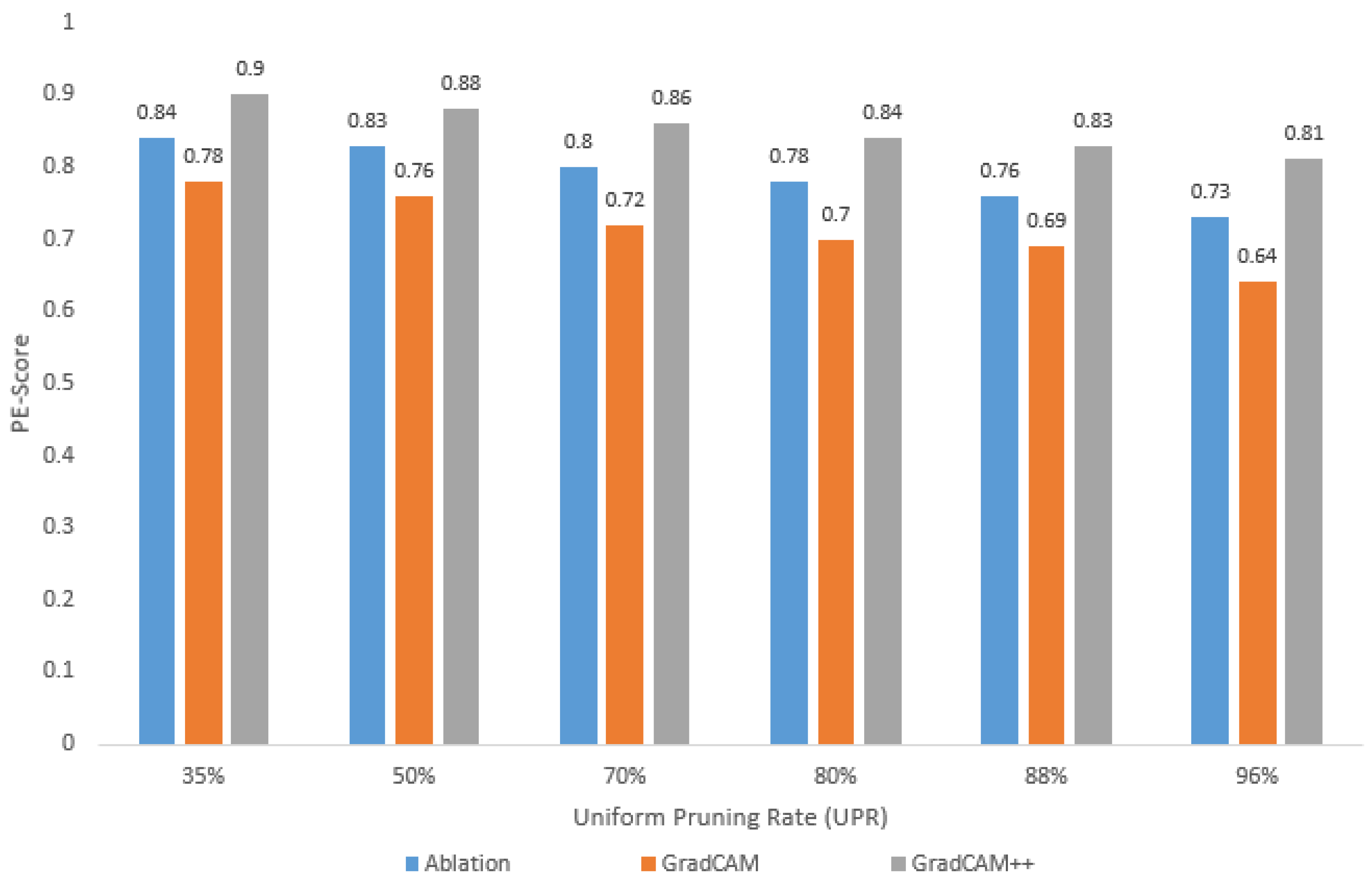
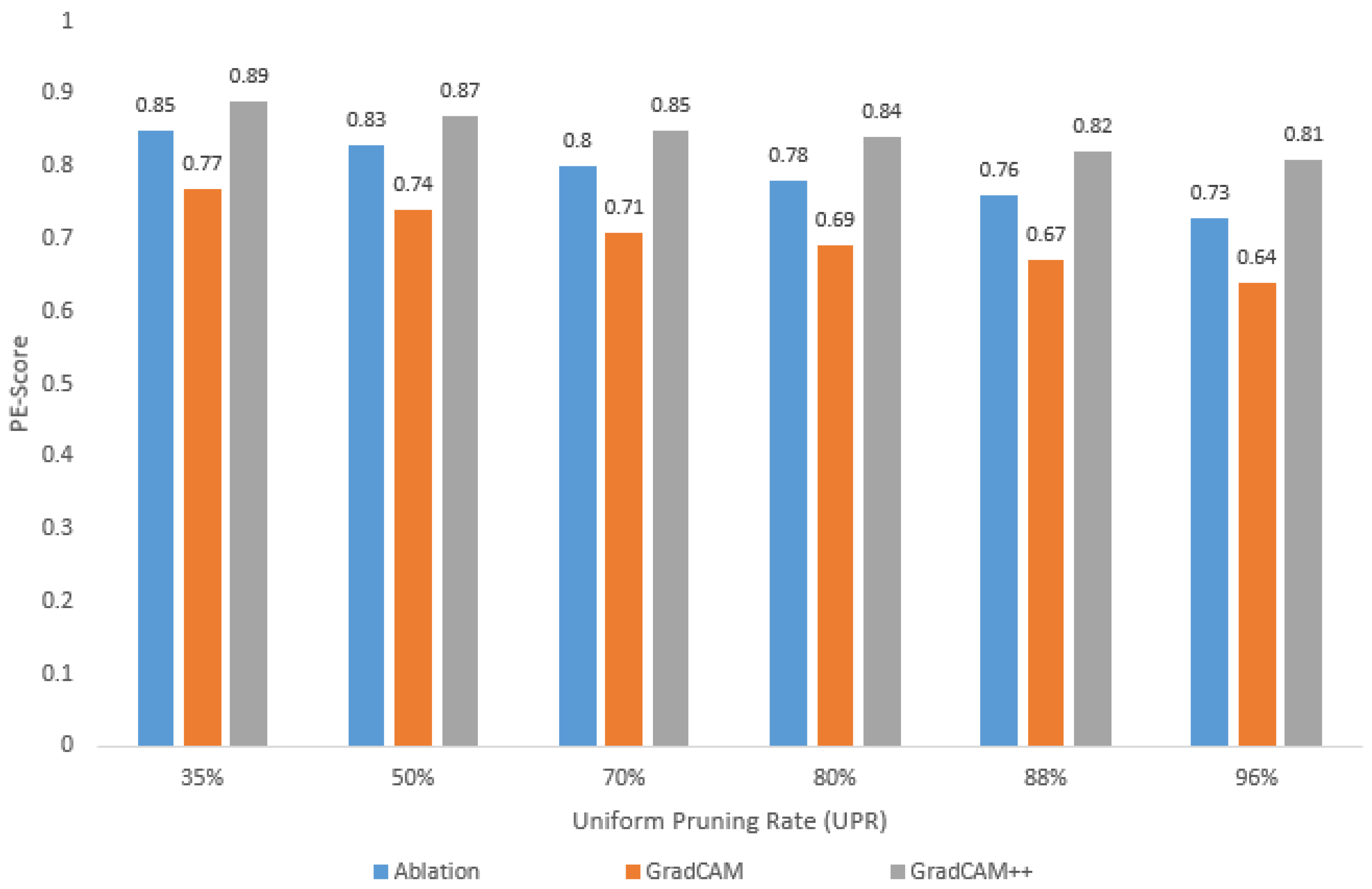
- As the UPR increases, the PE-sore decreases, regardless of the visualization method selected for and calculation;
- For the different UPR values, the highest PE-score is obtained with GradCAM++, while the lowest value corresponds to GradCAM, i.e., depending on the visualization method used, the PE-score varies for the same pruned model;
- Using GradCAM++, a loss in accuracy of less than 1% implies a PE-score greater than 0.87 (in this case, a UPR of up to 50%);
- Using GradCAM++, a loss in accuracy of around 10% implies a PE-score around 0.81 (in this case, a UPR = 96%).
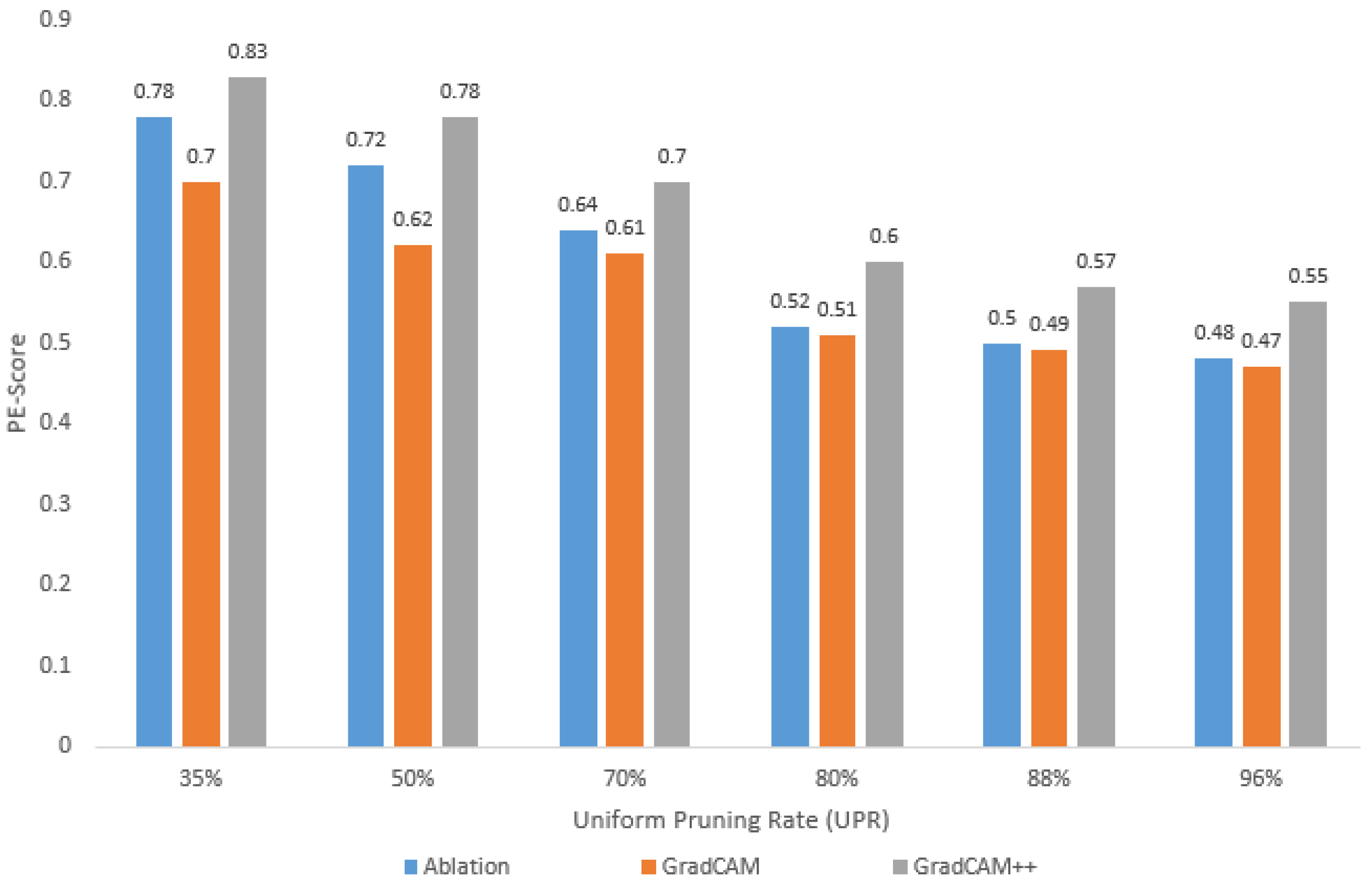
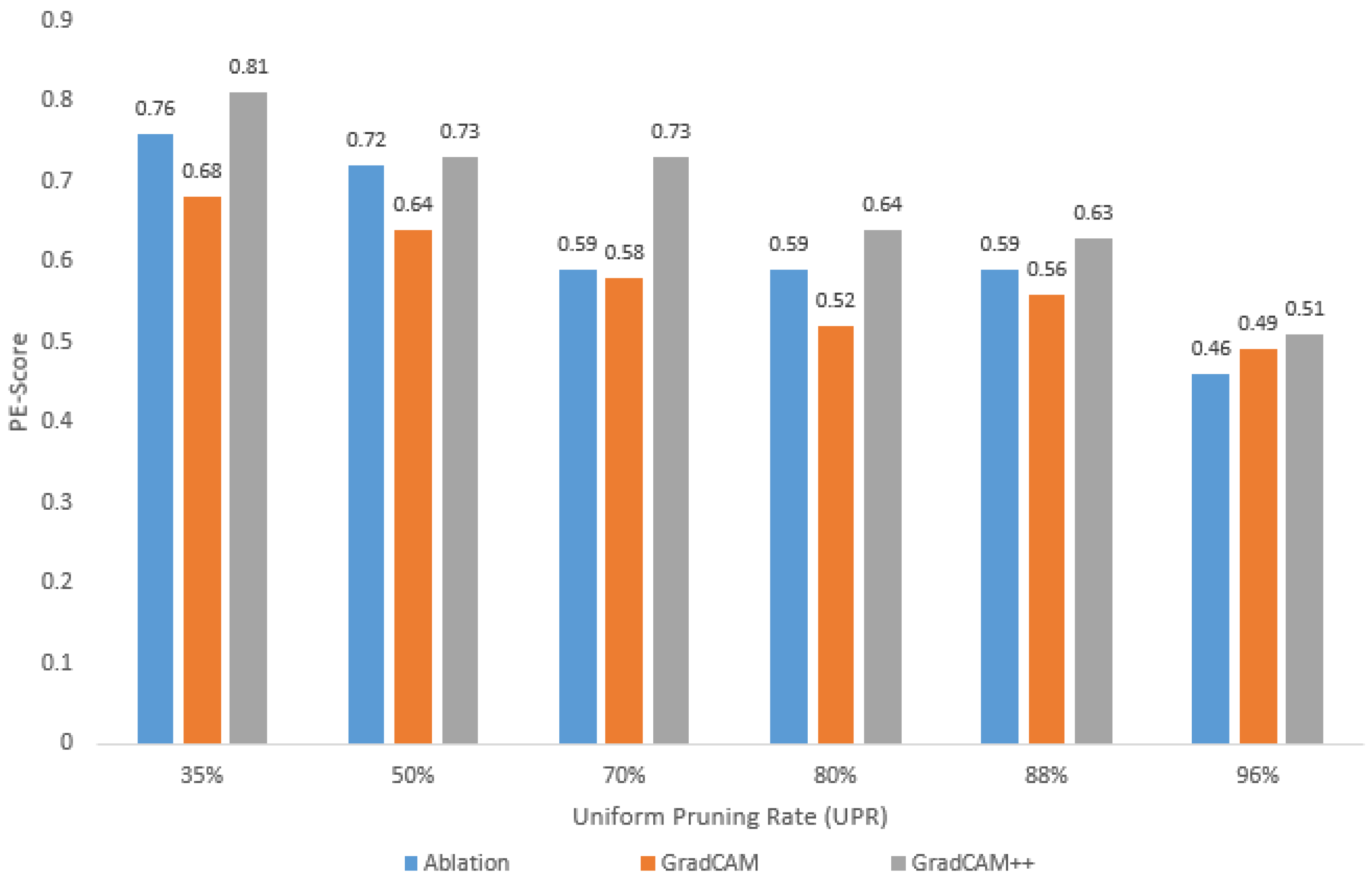
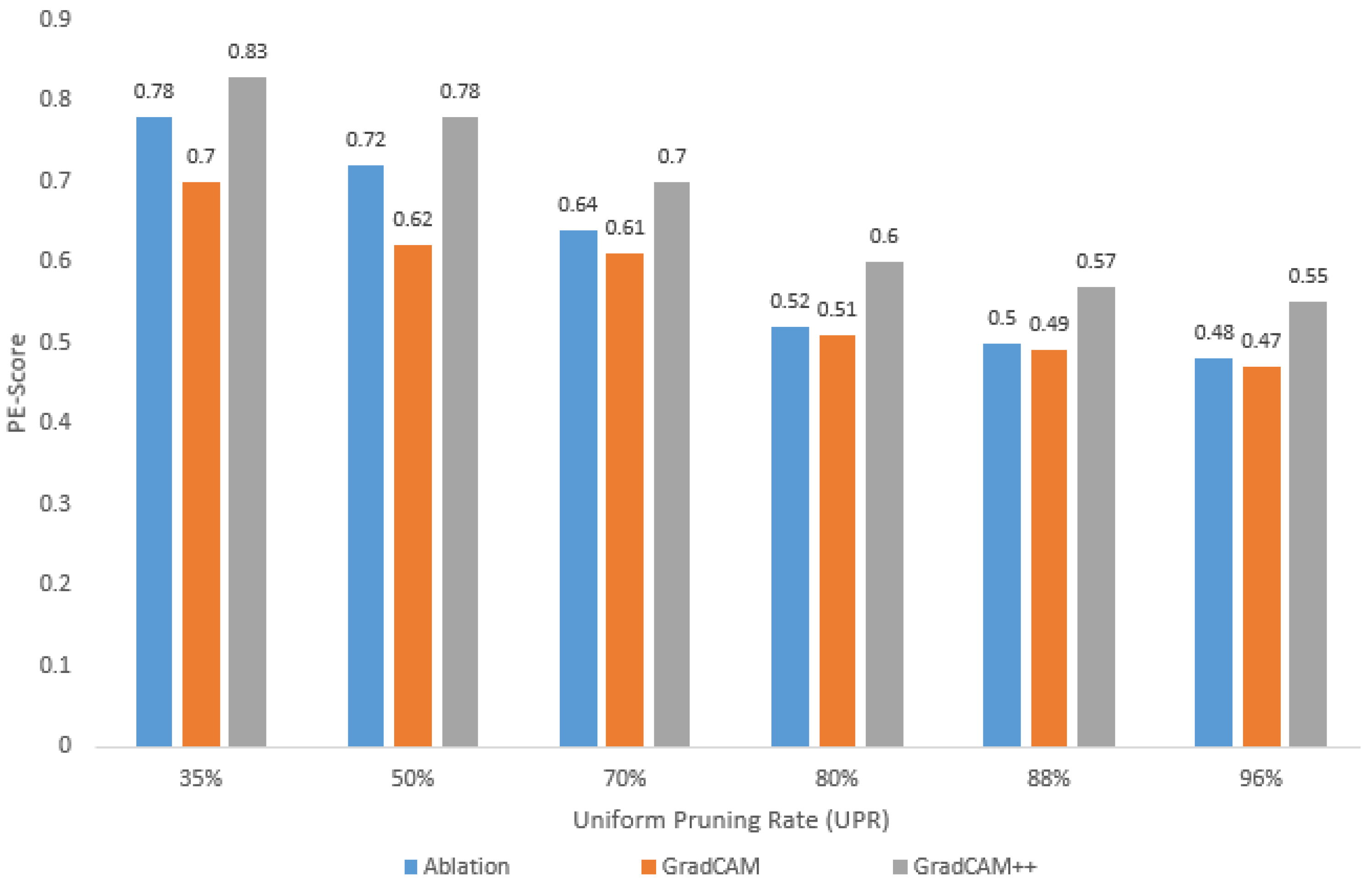
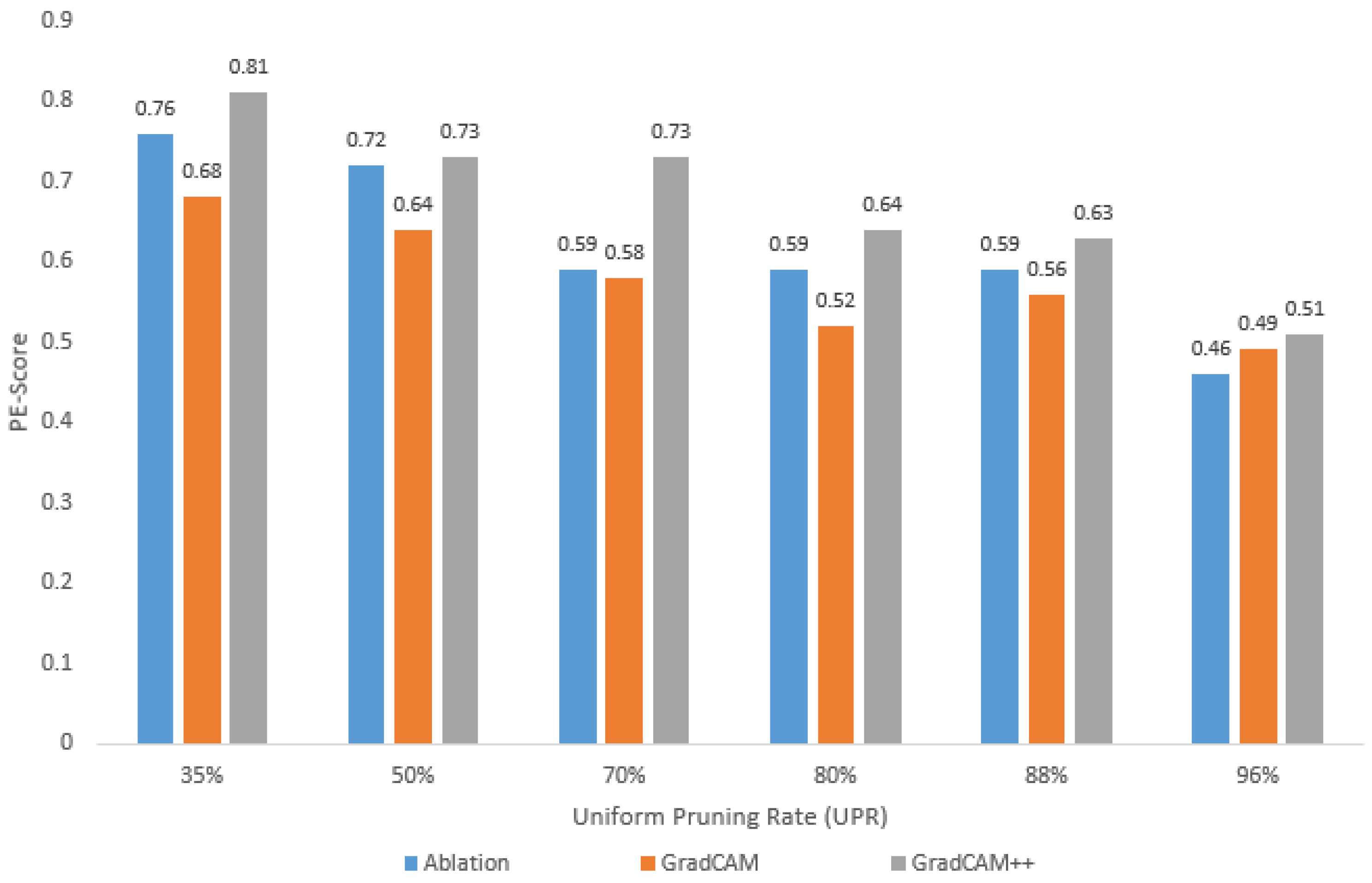
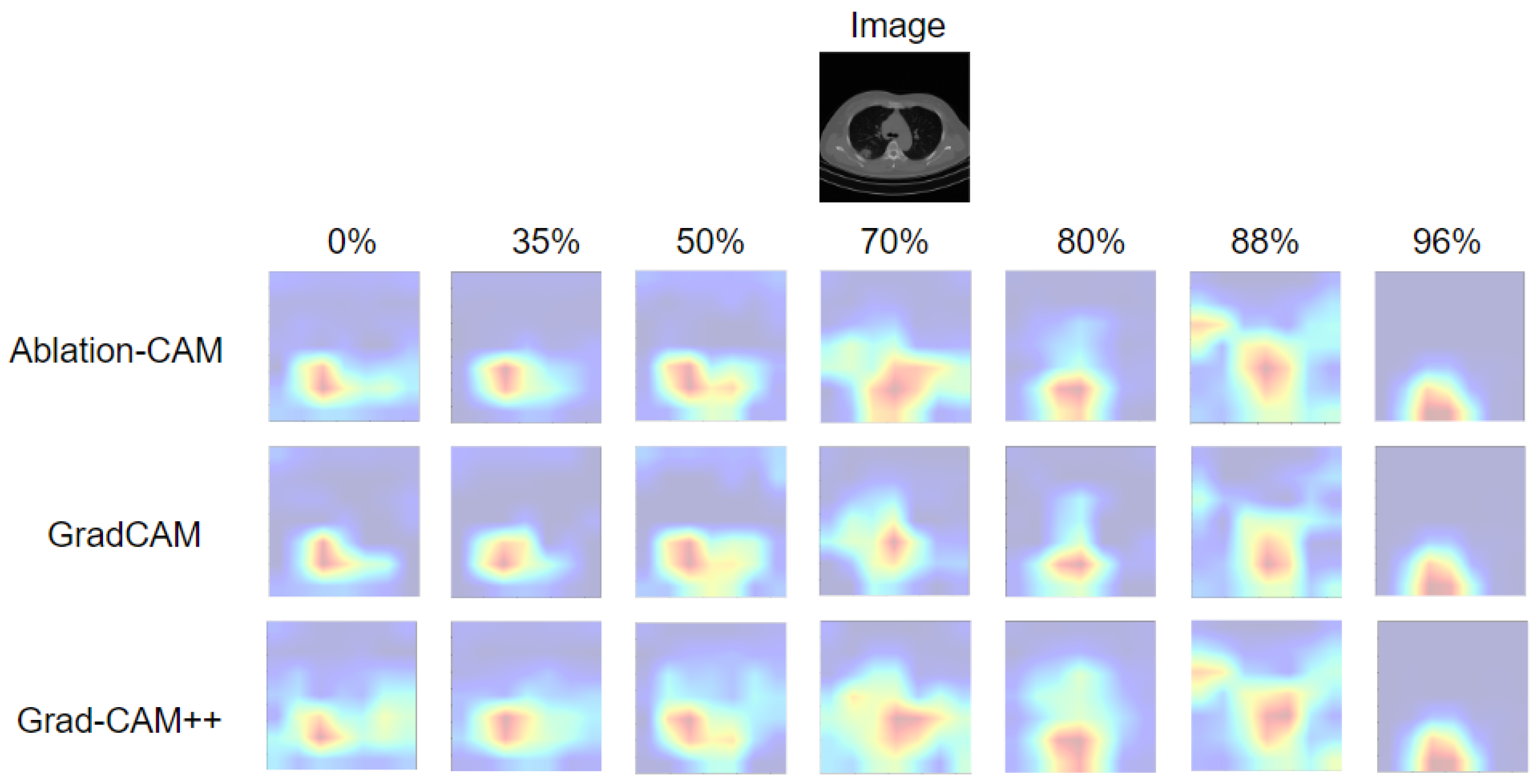
4.3. Trustworthiness of Pruned Models: Case of the COVID-19 Dataset
5. Discussion
- Train the network on the dataset to be classified, obtaining the unpruned model.
- Prune the model with a low PR value. It can be uniform (UPR) or adaptive (APR). Measure the accuracy of the pruned model and the PE-score, taking into account what is described in Section 3 of this paper.
- Repeat step 2 with different values of PR. In all cases, use the same fine-tuning hyperparameters (e.g., epochs, optimizer, learning rate). Calculate the PE-score and the accuracy value for each PR value.
- Check that both the PE-score and accuracy decrease as the PR increases. If so, select the PR value at which the model drops to 1% (or the accuracy reduction criterion for the selected application).
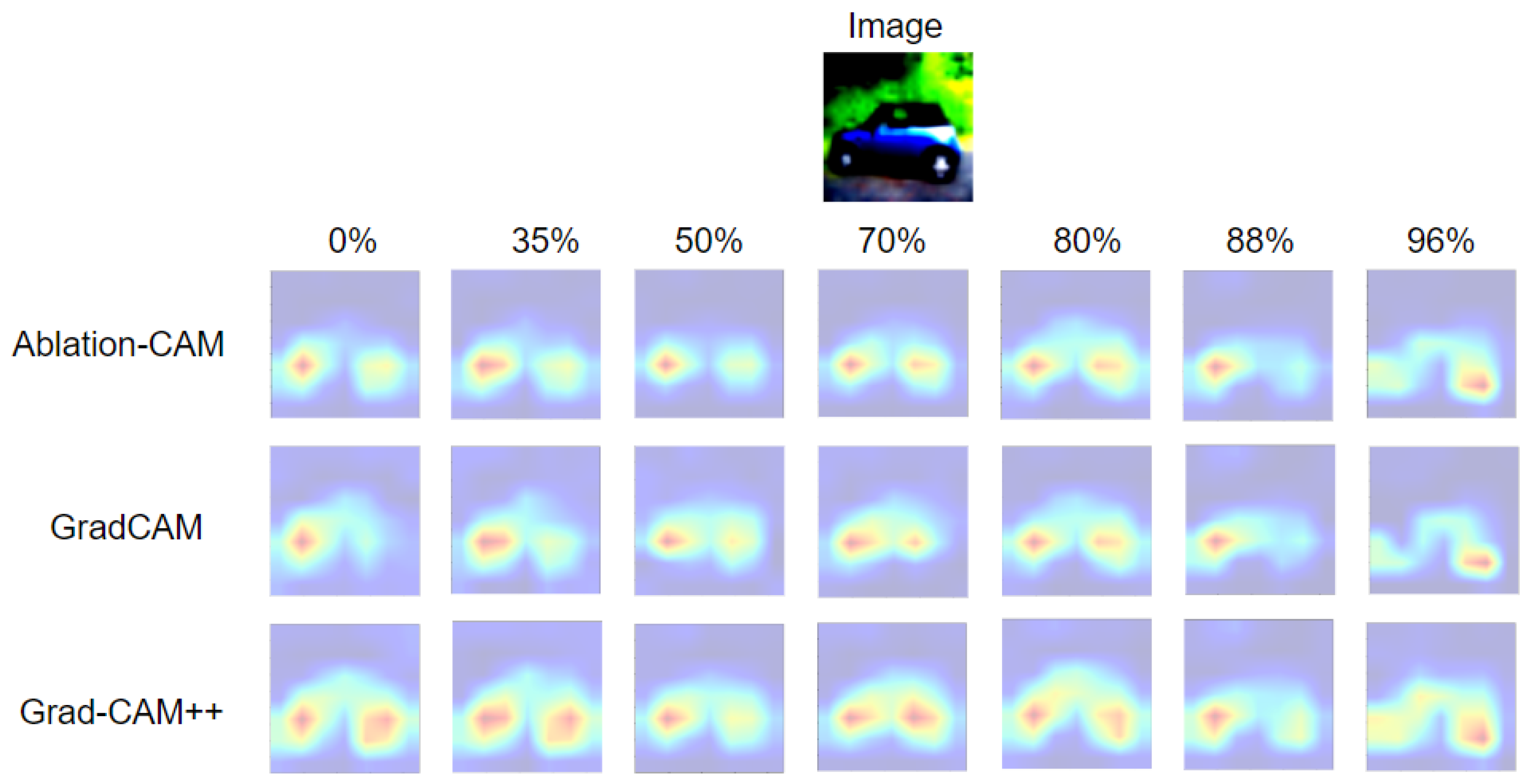
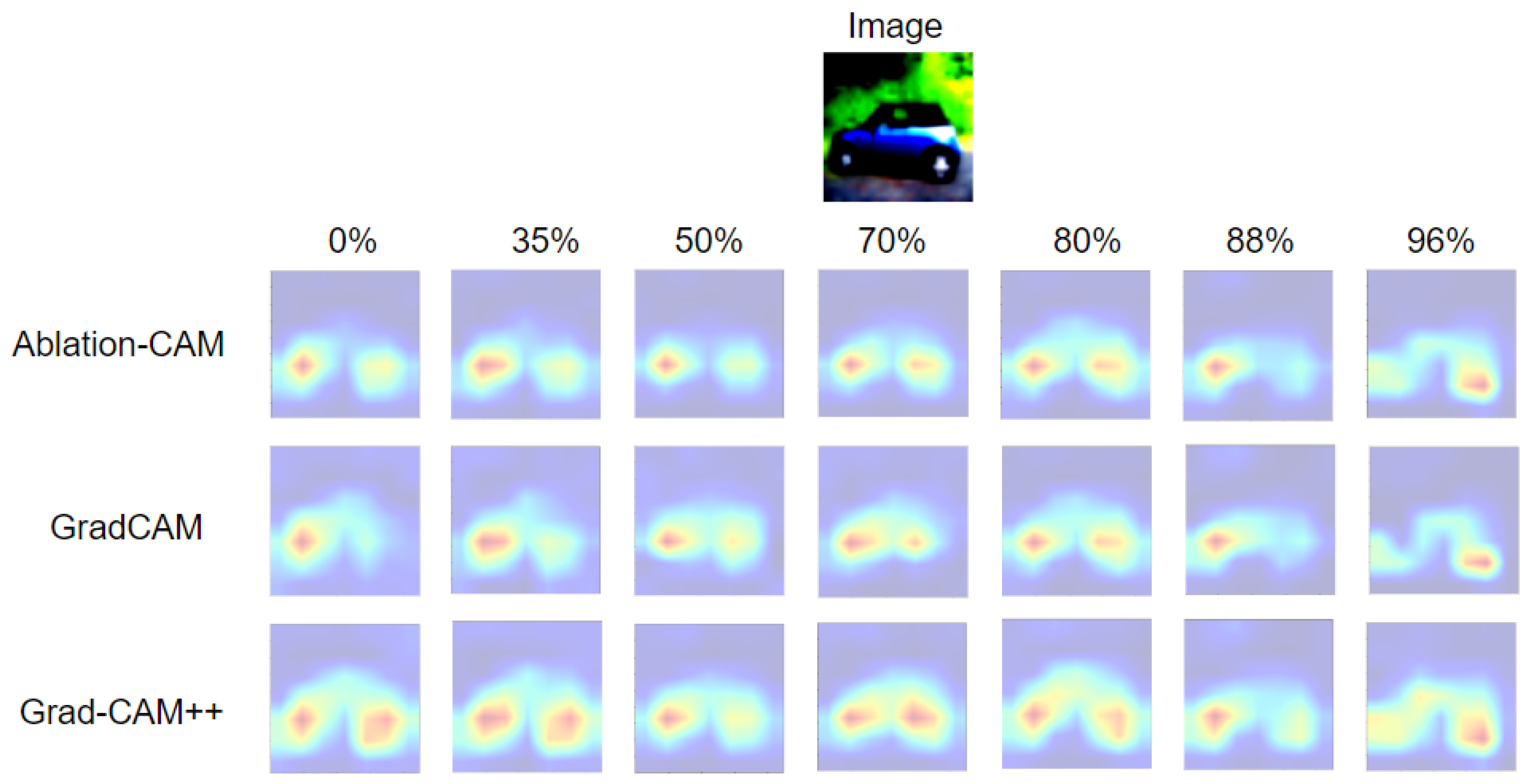
- Otherwise, if the accuracy has a fluctuating behavior (e.g., increases, decreases, increases) as the PR increases and the PE-score decreases, then it is mandatory to check the explanation maps for each of the PR values. The maximum PR for which the pruned model can be trusted is the one for which its explanation map is very similar to that of the unpruned model.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| ACC | Accuracy |
| APR | Adaptive Pruning Rate |
| UPR | Uniform Pruning Rate |
| PR | Pruning Rate |
| PE | Pruning Efficiency |
| NN | Neural Network |
References
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 2021, 461, 370–403. [Google Scholar] [CrossRef]
- Marinó, G.C.; Petrini, A.; Malchiodi, D.; Frasca, M. Deep neural networks compression: A comparative survey and choice recommendations. Neurocomputing 2023, 520, 152–170. [Google Scholar] [CrossRef]
- Alqahtani, A.; Xie, X.; Jones, M.W. Literature review of deep network compression. Informatics 2021, 8, 77. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Kumar, A.; Shaikh, A.M.; Li, Y.; Bilal, H.; Yin, B. Pruning filters with L1-norm and capped L1-norm for CNN compression. Appl. Intell. 2021, 51, 1152–1160. [Google Scholar] [CrossRef]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4340–4349. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Sun, X.; Ren, X.; Ma, S.; Wang, H. meprop: Sparsified back propagation for accelerated deep learning with reduced overfitting. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 3299–3308. [Google Scholar]
- Liu, C.; Wu, H. Channel pruning based on mean gradient for accelerating convolutional neural networks. Signal Process. 2019, 156, 84–91. [Google Scholar] [CrossRef]
- Joo, D.; Baek, S.; Kim, J. Which Metrics for Network Pruning: Final Accuracy? Or Accuracy Drop? In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1071–1075. [Google Scholar] [CrossRef]
- Luo, J.H.; Zhang, H.; Zhou, H.Y.; Xie, C.W.; Wu, J.; Lin, W. Thinet: Pruning cnn filters for a thinner net. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2525–2538. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Ni, B.; Zhang, J.; Zhao, Q.; Zhang, W.; Tian, Q. Variational convolutional neural network pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2780–2789. [Google Scholar]
- Li, Q.; Li, H.; Meng, L. Feature map analysis-based dynamic cnn pruning and the acceleration on fpgas. Electronics 2022, 11, 2887. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Pachón, C.G.; Ballesteros, D.M.; Renza, D. SeNPIS: Sequential Network Pruning by class-wise Importance Score. Appl. Soft Comput. 2022, 129, 109558. [Google Scholar] [CrossRef]
- Yeom, S.K.; Seegerer, P.; Lapuschkin, S.; Binder, A.; Wiedemann, S.; Müller, K.R.; Samek, W. Pruning by explaining: A novel criterion for deep neural network pruning. Pattern Recognit. 2021, 115, 107899. [Google Scholar] [CrossRef]
- Yang, C.; Liu, H. Channel pruning based on convolutional neural network sensitivity. Neurocomputing 2022, 507, 97–106. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Yang, W.; Li, K.; Li, K. LAP: Latency-aware automated pruning with dynamic-based filter selection. Neural Netw. 2022, 152, 407–418. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Ding, X.; Ding, G.; Guo, Y.; Han, J.; Yan, C. Approximated oracle filter pruning for destructive cnn width optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Beach, CA, USA, 9–15 June 2019; pp. 1607–1616. [Google Scholar]
- Gamanayake, C.; Jayasinghe, L.; Ng, B.K.K.; Yuen, C. Cluster pruning: An efficient filter pruning method for edge ai vision applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 802–816. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 839–847. [Google Scholar] [CrossRef] [Green Version]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Ghimire, D.; Kil, D.; Kim, S.H. A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration. Electronics 2022, 11, 945. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Desai, S.S.; Ramaswamy, H.G. Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 983–991. [Google Scholar]
- Ballesteros, D.M.; Rodriguez-Ortega, Y.; Renza, D.; Arce, G. Deep4SNet: Deep learning for fake speech classification. Expert Syst. Appl. 2021, 184, 115465. [Google Scholar] [CrossRef]
- Branchaud-Charron, F.; Achkar, A.; Jodoin, P.M. Spectral metric for dataset complexity assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3215–3224. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy | FLOPs Reduction | Parameter Reduction |
|---|---|---|---|
| LRP [17] | 93.37% | 35.89% | 33.59% |
| Gradient [8] | 92.98% | 46.80% | 27.53% |
| Taylor [8] | 93.24% | 47.45% | 27.56% |
| Weight [4] | 93.31% | 24.47% | 44.49% |
| Variational [13] | 93.18% | 39.10% | 73.34% |
| SeNPIS [16] | 93.74% | 50.74% | 51.05% |
| Method | Accuracy Drop | FLOPs Reduction |
|---|---|---|
| Channel pruning [18] | 0.01% | 42.9% |
| Channel pruning [18] | 0.53% | 54.1% |
| Channel pruning [18] | 1.46% | 65.8% |
| LAP [19] | 1.31% | 76.0% |
| Dataset | Accuracy * | CSG | Complexity |
|---|---|---|---|
| MNIST | 99.68% | 0.1306 | Very low |
| COVID-19 | 99.50% | 0.1938 | Very low |
| Fashion-MNIST | 96.91% | 0.5424 | Low |
| CIFAR10 | 95.55% | 4.0676 | Medium |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pachon, C.G.; Renza, D.; Ballesteros, D. Is My Pruned Model Trustworthy? PE-Score: A New CAM-Based Evaluation Metric. Big Data Cogn. Comput. 2023, 7, 111. https://doi.org/10.3390/bdcc7020111
Pachon CG, Renza D, Ballesteros D. Is My Pruned Model Trustworthy? PE-Score: A New CAM-Based Evaluation Metric. Big Data and Cognitive Computing. 2023; 7(2):111. https://doi.org/10.3390/bdcc7020111
Chicago/Turabian StylePachon, Cesar G., Diego Renza, and Dora Ballesteros. 2023. "Is My Pruned Model Trustworthy? PE-Score: A New CAM-Based Evaluation Metric" Big Data and Cognitive Computing 7, no. 2: 111. https://doi.org/10.3390/bdcc7020111
APA StylePachon, C. G., Renza, D., & Ballesteros, D. (2023). Is My Pruned Model Trustworthy? PE-Score: A New CAM-Based Evaluation Metric. Big Data and Cognitive Computing, 7(2), 111. https://doi.org/10.3390/bdcc7020111