



A Mixed Malay–English Language COVID-19 Twitter Dataset: A Sentiment Analysis

 , , ,
, , ,
Abstract
:1. Introduction
1.1. Existing Work
1.2. Motivation and Contributions
- We collected 108,246 tweets to provide a multilingual dataset on COVID-19-related tweets posted in Malaysia. The dataset has been published on Github [38] and made publicly available for further research work.
- We manually annotated sentiments on 11,568 tweets in terms of three classes of sentiments (positive, negative, and neutral) for two different languages: Malay and English.
- This study contributes to the field of sentiment analysis by demonstrating the effectiveness of incorporating BPE tokens into MBERT and text-to-image CNN models for sentiment analysis in low-resource languages such as Malay.
2. Methodology
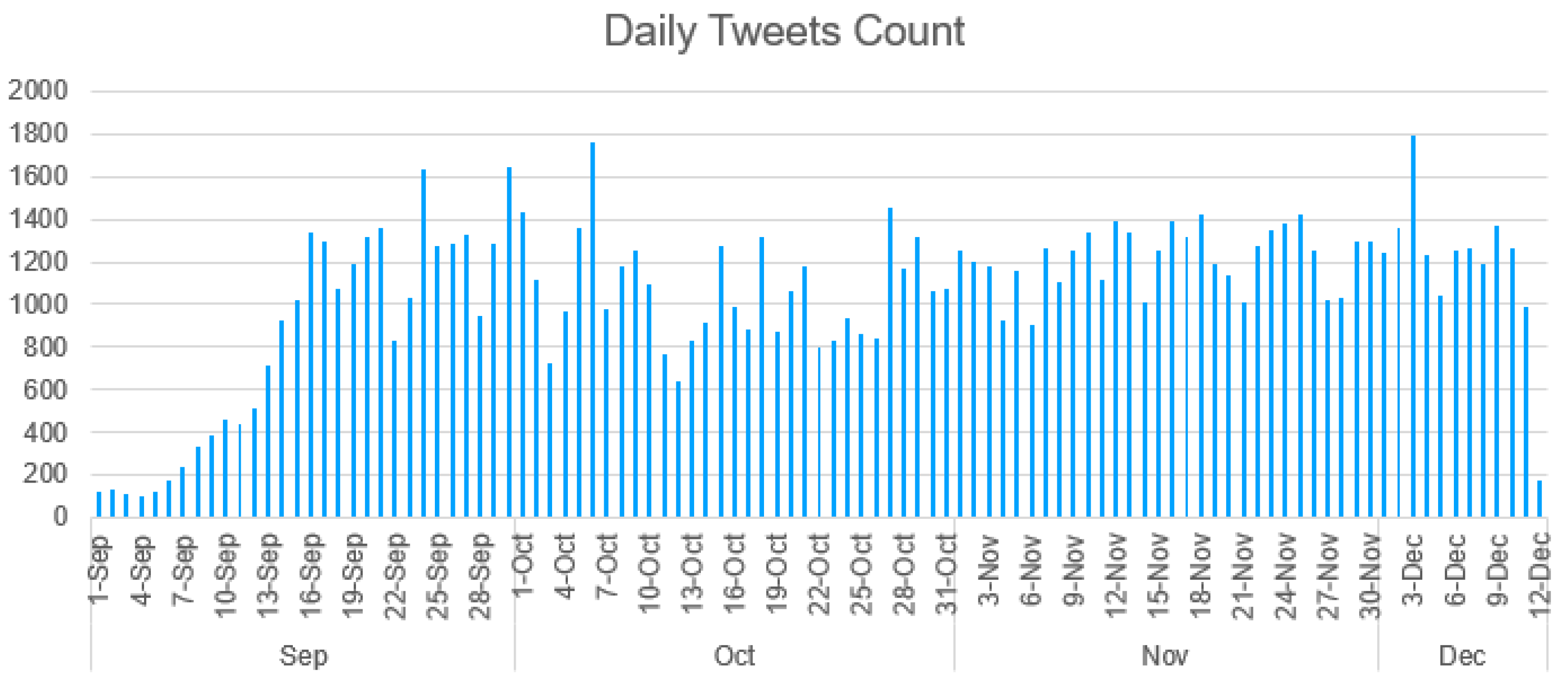
2.1. Dataset Collection Method
2.2. Dataset Description (MyCovid-Senti)
2.3. Manual Sentiment Annotation Method
- (Q1)
- What best describes the speaker’s emotional state? (The following emotional states are used in the following questions as well).
- (a)
- positive state: there is an explicit or implicit clue in the text suggesting that the speaker is in a positive state, i.e., happy, excited, task completion, festive greetings, hope for better, advise, recovering, taken positive actions (e.g., booster shots done), good intention, and make plans, etc.
- (b)
- negative state: there is an explicit or implicit clue in the text suggesting that the speaker is in a negative state, i.e., sad, angry, disappointed, demanding, questioning, doubt, worry, forcing, ill intention, impatience, etc.
- (c)
- neutral state: there is no explicit or implicit indicator of the speaker’s emotional state, i.e., news that purely reports about daily statistics on COVID-19 cases, notices of meeting/webinars date time, describing guidelines, and information.
- (Q2)
- When speaker’s emotional state is absence, identify the Primary Target of Opinion (PTO) attitude, it can be towards a person, group, object, events, or actions. If there are more than one opinions, select the stronger sentiment of opinions.
- (Q3)
- If the entire text is a quote from another person (the original author) and the speaker’s attitude is not clear, then select the original author as the speaker.
- (Q4)
- What best describes how the majority of individuals feel or public opinion about the PTO?
2.4. BPE-Text-to-Image-CNN Method
- Task 1: Text Pre-processing. We applied case-folding to lowercase words and the removal of stop words, white spaces, @mentions, and URLs from the tweets. The list of stop words was obtained in English from scikit-learn, a python library. The list had 317 English words that were converted into Malay words to build Malay stop words for the removal. We removed the duplicates as well as the retweets with the same wordings. However, we kept emojis and emoticons, as the model might learn from these features.
- Task 2: BPE Tokenization. We created another set of text using the tokens generated by BPE. BPE is a data-compression method that selects the most occurring pair of characters and replaced them with a character that does not exist within the data [41]. BPE tokenization was chosen, as the algorithm deals with the unknown word problem, which is very common with the usage of short forms on text postings on online social media. BPE can also reduce or increase the dataset’s vocabulary size by changing the value of the maximum vocabulary size during the BPE tokenization process. In a very recent study [4], the authors found that in a 10k opinion dataset, when the vocabulary size increased beyond 8000, the accuracy score dropped. Another study [42] concurred that the best performance was achieved with small (30K) to medium (1.3M) data sizes, at an 8000 vocabulary size. Our dataset has around 11K tweets and is a comparable dataset size to the previous research findings in terms of optimal vocabulary size. The total count of unique tokens of the MyCovid-Senti dataset was 19,185. In our experiments, we tested a few vocabulary sizes for BPE tokens by setting it to 1000, 2000, 4000, 8000, 12,000, 16,000, the original token size (19,185), and 24,000.
- Task 3: Text-to-image Conversion. With the tweet text limit at a maximum of 280 characters, we reshaped texts from one-row vector into a matrix size of 5 rows × 56 columns. In other words, we arranged the texts on an image with only 56 characters in a row. Then, the next characters were moved to a new line. In the final step of the conversion, we used the print function in Matlab to export the matrix into image form, as shown in Figure 3.

- 4.
- Task 4: CNN. We fed the images as features input into a deep-learning neural architecture with 32 layers. The images were augmented to reduce their size by half, i.e., from 188 × 500 to 94 × 250. In our image pre-processing phase, we converted the images from a Red, Green, Blue (RGB) components format to grayscale (where each pixel contains only one data point with a value ranging from 0 to 255). According to [43], gray-scaling is performed so that the number of data that can be represented or need to be processed in each pixel is lower in comparison with a colored image (where each pixel contains three data components for the RGB format). Thus, with the reduced data in each pixel, it naturally reduces the processing power and time required. For the CNN experiments, the dataset was split randomly by 80–20%, with for training and for testing. The CNN model used in the experiment contains seven sets of convolutional layers, a batch normalization layer, and a Rectified Linear Unit (ReLU) layer, as shown in Figure 4. In between the seven sets, there were 2-D max pooling layers before the convolution layer and after the ReLU layer to divide the input by half. After learning features in the seven sets of layers, the CNN architecture shifted to classification. A dropout layer with a dropout probability of 0.5 was applied before the fully connected layer that outputs a vector of K dimensions, where K is the number of classes that the network predicts. Finally, a softmax function with the classification layer was used as the final layer. For the training options, we used the Stochastic Gradient Descent with Momentum (SGDM) optimizer and set the initial learning rate to 0.001. Then, we reduced the learning rate by a factor of 0.2 every five epochs. The training was run for a maximum of 15 epochs with a mini-batch of 64 observations at each iteration.
2.5. BPE-M-BERT
3. Results and Analysis
- F1-micro. Count the total of true positive samples (), false negative samples (), and false positive samples () to determine the F1-score globally. The expression is given bywhereand is the cardinality of the class .
- F1-macro. Calculate F1-score for each class, and find the mean of all F1-score per class. However, this metric disregards the class imbalance. The expression is given bywhere
- F1-weighted. Calculate the F1-score for each class, and find the mean of all F1-score per class while considering each class weight. The weight is proportional to the number of samples in each class. This allows ‘macro’ to account for class imbalance. The expression is given bywhereand is the weight for class i.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saud, M.; Mashud, M.; Ida, R. Usage of social media during the pandemic: Seeking support and awareness about COVID-19 through social media platforms. J. Public Aff. 2020, 20, e2417. [Google Scholar] [CrossRef]
- Samuel, J.; Rahman, M.M.; Ali, G.M.N.; Samuel, Y.; Pelaez, A.; Chong, P.H.J.; Yakubov, M. Feeling positive about reopening? New normal scenarios from COVID-19 US reopen sentiment analytics. IEEE Access 2020, 8, 142173–142190. [Google Scholar] [CrossRef] [PubMed]
- Mourad, A.; Srour, A.; Harmanani, H.; Jenainati, C.; Arafeh, M. Critical impact of social networks infodemic on defeating coronavirus COVID-19 pandemic: Twitter-based study and research directions. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2145–2155. [Google Scholar] [CrossRef]
- Agathangelou, P.; Katakis, I. Balancing between holistic and cumulative sentiment classification. Online Soc. Netw. Media 2022, 29, 100199. [Google Scholar] [CrossRef]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine learning-based sentiment analysis for twitter accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef] [Green Version]
- Mao, Y.; Menchen-Trevino, E. Global news-making practices on Twitter: Exploring English-Chinese language boundary spanning. J. Int. Intercult. Commun. 2019, 12, 248–266. [Google Scholar] [CrossRef]
- Junaini, S.N.; Hwey, A.L.T.; Sidi, J.; Rahman, K.A. Development of Sarawak Malay local dialect online translation tooL. In Proceedings of the 2009 International Conference on Computer Technology and Development, Kota Kinabalu, Malaysia, 13–15 November 2009; pp. 459–462. [Google Scholar]
- Hijazi, M.H.A.; Libin, L.; Alfred, R.; Coenen, F. Bias aware lexicon-based Sentiment Analysis of Malay dialect on social media data: A study on the Sabah Language. In Proceedings of the 2016 2nd International Conference on Science in Information Technology (ICSITech), Balikpapan, Indonesia, 26–27 October 2016; pp. 356–361. [Google Scholar]
- Khaw, Y.M.J.; Tan, T.P. Hybrid approach for aligning parallel sentences for languages without a written form using standard Malay and Malay dialects. In Proceedings of the 2014 International Conference on Asian Language Processing (IALP), Kuching, Malaysia, 20–22 October 2014; pp. 170–174. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the AACL HLT 2019 Conference of the North American Chapter of the Association for Computational Linguistic Humanity Language Technology, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Fujihira, K.; Horibe, N. Multilingual Sentiment Analysis for Web Text Based on Word to Word Translation. In Proceedings of the 9th International Congress on Advanced Applied Informatics (IIAI-AAI), Kitakyushu, Japan, 1–15 September 2020; pp. 74–79. [Google Scholar]
- Baliyan, A.; Batra, A.; Singh, S.P. Multilingual sentiment analysis using RNN-LSTM and neural machine translation. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 17–19 March 2021; pp. 710–713. [Google Scholar]
- Afroz, N.; Boral, M.; Sharma, V.; Gupta, M. Sentiment Analysis of COVID-19 nationwide lockdown effect in India. In Proceedings of the International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 710–713. [Google Scholar]
- Marathe, A.; Mandke, A.; Sardeshmukh, S.; Sonawane, S. Leveraging Natural Language Processing Algorithms to Understand the Impact of the COVID-19 Pandemic and Related Policies on Public Sentiment in India. In Proceedings of the 2021 International Conference on Communication information and Computing Technology (ICCICT), Mumbai, India, 25–27 June 2021; pp. 1–5. [Google Scholar]
- Pellert, M.; Lasser, J.; Metzler, H.; Garcia, D. Dashboard of sentiment in Austrian social media during COVID-19. Front. Big Data 2020, 3, 32. [Google Scholar] [CrossRef] [PubMed]
- Jayasurya, G.G.; Kumar, S.; Singh, B.K.; Kumar, V. Analysis of public sentiment on COVID-19 vaccination using twitter. IEEE Trans. Comput. Soc. Syst. 2021, 9, 1101–1111. [Google Scholar] [CrossRef]
- Aygun, I.; Kaya, B.; Kaya, M. Aspect Based Twitter Sentiment Analysis on Vaccination and Vaccine Types in COVID-19 Pandemic with Deep Learning. IEEE J. Biomed. Health Inform. 2021, 26, 2360–2369. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Sornlertlamvanich, V. Public Perception of COVID-19 Vaccine by Tweet Sentiment Analysis. In Proceedings of the 2021 International Electronics Symposium (IES), Surabaya, Indonesia, 29–30 September 2021; pp. 151–155. [Google Scholar]
- Alharbi, A.; de Doncker, E. Twitter Sentiment Analysis with a Deep Neural Network: An Enhanced Approach using User Behavioral Information. Cogn. Syst. Res. 2018, 54, 50–61. [Google Scholar] [CrossRef]
- Jacovi, A.; Shalom, O.S.; Goldberg, Y. Understanding convolutional neural networks for text classification. arXiv 2018, arXiv:1809.08037. [Google Scholar]
- Merdivan, E.; Vafeiadis, A.; Kalatzis, D.; Hanke, S.; Kroph, J.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R.; et al. Image-based Text Classification using 2D Convolutional Neural Networks. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; pp. 144–149. [Google Scholar]
- Srivastava, A.; Singh, V.; Drall, G.S. Sentiment analysis of twitter data: A hybrid approach. Int. J. Healthc. Inf. Syst. Inform. (IJHISI) 2019, 14, 1–16. [Google Scholar] [CrossRef]
- Suri, V.; Arora, B. A Review on Sentiment Analysis in Different Language. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 1–9. [Google Scholar]
- Abu Bakar, M.F.R.; Idris, N.; Shuib, L.; Khamis, N. Sentiment Analysis of Noisy Malay Text: State of Art, Challenges and Future Work. IEEE Access 2020, 8, 24687–24696. [Google Scholar] [CrossRef]
- Al-Saffar, A.; Awang, S.; Tao, H.; Omar, N.; Al-Saiagh, W.; Al-Bared, M. Malay sentiment analysis based on combined classification approaches and Senti-lexicon algorithm. PLoS ONE 2018, 13, e0194852. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chekima, K.; Alfred, R. Sentiment analysis of Malay social media text. In Proceedings of the International Conference on Computational Science and Technology, Kuala Lumpur, Malaysia, 29–30 November 2017; pp. 205–219. [Google Scholar]
- Zabha, N.I.; Ayop, Z.; Anawar, S.; Hamid, E.; Abidin, Z.Z. Developing cross-lingual sentiment analysis of Malay Twitter data using lexicon-based approach. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 346–351. [Google Scholar] [CrossRef] [Green Version]
- Bakar, M.F.R.A.; Idris, N.; Shuib, L. An Enhancement of Malay Social Media Text Normalization for Lexicon-Based Sentiment Analysis. In Proceedings of the 2019 International Conference on Asian Language Processing (IALP), Shanghai, China, 15–17 November 2019; pp. 211–215. [Google Scholar]
- bin Rodzman, S.B.; Rashid, M.H.; Ismail, N.K.; Abd Rahman, N.; Aljunid, S.A.; Abd Rahman, H. Experiment with Lexicon Based Techniques on Domain-Specific Malay Document Sentiment Analysis. In Proceedings of the 2019 IEEE 9th Symposium on Computer Applications & Industrial Electronics (ISCAIE), Kota Kinabalu, Malaysia, 27–28 April 2019; pp. 330–334. [Google Scholar]
- Nabiha, A.; Mutalib, S.; Ab Malik, A.M. Sentiment Analysis for Informal Malay Text in Social Commerce. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Data Sciences (AiDAS), Virtual, 8–9 September 2021; pp. 1–6. [Google Scholar]
- Yilmaz, S.F.; Kaynak, E.B.; Koç, A.; Dibeklioğlu, H.; Kozat, S.S. Multi-Label Sentiment Analysis on 100 Languages with Dynamic Weighting for Label Imbalance. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 331–343. [Google Scholar] [CrossRef] [PubMed]
- Sazzed, S.; Jayarathna, S. A Sentiment Classification in Bengali and Machine Translated English Corpus. In Proceedings of the 2019 IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), Los Angeles, CA, USA, 30 July–1 August 2019; pp. 107–114. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics. Florence, Italy, 28 July–2 August 2019; pp. 4996–5001. [Google Scholar]
- Islam, M.S.; Amin, M.R. Sentiment analysis in Bengali via transfer learning using multi-lingual BERT. In Proceedings of the 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; pp. 19–21. [Google Scholar]
- Sabri, N.; Edalat, A.; Bahrak, B. Sentiment Analysis of Persian-English Code-mixed Texts. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–4. [Google Scholar]
- Fimoza, D.; Amalia, A.; Harumy, T.H.F. Sentiment Analysis for Movie Review in Bahasa Indonesia Using BERT. In Proceedings of the 2021 International Conference on Data Science, Artificial Intelligence, and Business Analytics (DATABIA), Medan, Indonesia, 11–12 November 2021; pp. 27–34. [Google Scholar]
- Le, A.P.; Vu Pham, T.; Le, T.V.; Huynh, D.V. Neural Transfer Learning For Vietnamese Sentiment Analysis Using Pre-trained Contextual Language Models. In Proceedings of the 2021 IEEE International Conference on Machine Learning and Applied Network Technologies (ICMLANT), Soyapango, El Salvador, 16–17 December 2021; pp. 1–5. [Google Scholar]
- Kong, J. MyCovid-Senti. 2022. Available online: https://github.com/z3fei/Malaysia-COVID-19-Tweet-ID/tree/main/MyCovid-Senti (accessed on 20 December 2022).
- Schlosser, S.; Toninelli, D.; Cameletti, M. Comparing methods to collect and geolocate tweets in Great Britain. J. Open Innov. Technol. Mark. Complex. 2021, 7, 44. [Google Scholar] [CrossRef]
- Mohammad, S. A practical guide to sentiment annotation: Challenges and solutions. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, San Diego, CA, USA, 16 June 2016; pp. 174–179. [Google Scholar]
- Gage, P. A new algorithm for data compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Gowda, T.; May, J. Finding the optimal vocabulary size for neural machine translation. arXiv 2020, arXiv:2004.02334. [Google Scholar]
- Kumar, A.; Singh, T.; Vishwakarma, D.K. Intelligent Transport System: Classification of Traffic Signs Using Deep Neural Networks in Real Time. In Advances in Manufacturing and Industrial Engineering; Springer: Singapore, 2021; pp. 207–219. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How multilingual is multilingual BERT? arXiv 2019, arXiv:1906.01502. [Google Scholar]
- Jose, N.; Chakravarthi, B.R.; Suryawanshi, S.; Sherly, E.; McCrae, J.P. A survey of current datasets for code-switching research. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 136–141. [Google Scholar]
- Willingham, D. Transformer Models. Github. 2022. Available online: https://github.com/matlab-deep-learning/transformer-models/releases/tag/1.2 (accessed on 4 January 2022).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English | Malay | Chinese | Tamil | Tracing Date |
|---|---|---|---|---|
| vaccination | vaksinasi | 接种 |  | 2021-09-01 |
| vaccine | vaksin | 疫苗 |  | 2021-09-01 |
| delta variant | varian delta | 增量变体 |  | 2021-09-01 |
| booster | penggalak | 助推器 |  | 2021-09-01 |
| covid | covid | 新冠 |  | 2021-09-01 |
| mask | topeng | 口罩 |  | 2021-09-01 |
| quarantine | kuarantin | 隔离 |  | 2021-09-01 |
| Movement control order | Perintah kawalan pergerakan | 行动管制令 |  | 2021-09-01 |
| mkn, jkjav, kitajagakita, mysejahtera, icu, pcr, mco, pkp, az | 2021-09-01 | |||
| endemic | endemik | 地方病 |  | 2021-09-06 |
| oximeter | oksimeter | 血氧计 |  | 2021-09-08 |
| hospital | hospital | 医院 |  | 2021-09-08 |
| pandemic | pandemik | 大流行 |  | 2021-09-10 |
| Astrazeneca | Astrazeneca | 阿斯利康 |  | 2021-09-10 |
| Pfizer | Pfizer | 辉瑞 |  | 2021-09-10 |
| Sinovac | Sinovac | 华兴 |  | 2021-09-10 |
| test kit | kit ujian | 测试套件 |  | 2021-09-15 |
| pneumonia | pneumonia | 肺炎 |  | 2021-10-06 |
| ivermectin | ivermektin | 伊维菌素 |  | 2021-10-22 |
| wuhan | wuhan | 武汉 |  | 2021-10-22 |
| comorbidity | komorbiditi | 合并症 |  | 2021-10-22 |
| comirnaty | comirnaty | 共同体 |  | 2021-10-22 |
| panadol | panadol | 帕纳多 |  | 2021-10-31 |
| PICK (Program Imunisasi COVID-19 Kebangsaan), CITF (COVID-19 Immunisation Special Task Force) | 2021-11-04 | |||
| TRIIS (Test, Report, Isolate, Inform, Seek) | 2021-11-12 | |||
| Omicron | Omicron | 奥米克戎 |  | 2021-11-29 |
| Geocodes | |||
|---|---|---|---|
| (Latitude,Longitude) | Radius | City | State |
| 1.8548,102.9325 | 30 km | Batu Pahat | Johor |
| 1.4655,103.7578 | 3 km | Johor Bahru | Johor |
| 1.6006,103.6419 | 30 km | Senai | Johor |
| 6.12104,100.36014 | 50 km | Alor Setar | Kedah |
| 6.13328,102.2386 | 50 km | Kota Bahru | Kelantan |
| 3.1412,101.68653 | 70 km | Kuala Lumpur | Federal Territories |
| 2.196,102.2405 | 50 km | Malacca | Malacca |
| 3.8077,103.326 | 50 km | Kuantan | Pahang |
| 5.41123,100.33543 | 30 km | George Town | Penang |
| 4.5841,101.0829 | 50 km | Ipoh | Perak |
| 5.9749,116.0724 | 50 km | Kota Kinabalu | Sabah |
| 5.8402,118.1179 | 50 km | Sandakan | Sabah |
| 4.24482,117.89115 | 50 km | Tawau | Sabah |
| 3.16667,113.03333 | 50 km | Bintulu | Sarawak |
| 1.55,110.33333 | 50 km | Kuching | Sarawak |
| 4.4148,114.0089 | 20 km | Miri | Sarawak |
| 2.3,111.81667 | 50 km | Sibu | Sarawak |
| 5.3302,103.1408 | 50 km | Kuala Terengganu | Terengganu |
| MyCovid-Senti | 3-Class | 2-Class |
|---|---|---|
| Negative | 5655 | 5655 |
| Neutral | 2728 | - |
| Positive | 3185 | 5913 |
| Total | 11,568 | 11,568 |
| Methods | BPE Vocabulary Size | Dataset 3-Class(neg., pos., Neutral) | Dataset 2-Class(neg., pos.+Neutral) | ||||
|---|---|---|---|---|---|---|---|
| F1-Micro | F1-Macro | F1-Weighted | F1-Micro | F1-Macro | F1-Weighted | ||
| BPE-Text-to -Image-CNN | 24,000 | 0.5752 | 0.5047 | 0.5383 | 0.6268 | 0.6265 | 0.6264 |
| Original Text (19,185) | 0.5823 | 0.5103 | 0.5452 | 0.6250 | 0.6247 | 0.6247 | |
| 16,000 | 0.5755 | 0.5053 | 0.5388 | 0.6222 | 0.6218 | 0.6217 | |
| 12,000 | 0.5771 | 0.5110 | 0.5437 | 0.6295 | 0.6299 | 0.6294 | |
| 8000 | 0.5713 | 0.5065 | 0.5391 | 0.6236 | 0.6233 | 0.6232 | |
| 4000 | 0.5684 | 0.4950 | 0.5298 | 0.6259 | 0.6254 | 0.6251 | |
| 2000 | 0.5664 | 0.4931 | 0.5281 | 0.6078 | 0.6075 | 0.6075 | |
| 1000 | 0.5608 | 0.4831 | 0.5201 | 0.6086 | 0.6082 | 0.6081 | |
| BPE-M-BERT | 24,000 | 0.6595 | 0.6250 | 0.6466 | 0.7104 | 0.7094 | 0.7093 |
| Original Text (19,185) | 0.6517 | 0.6161 | 0.6391 | 0.7170 | 0.7165 | 0.7165 | |
| 16,000 | 0.6557 | 0.6177 | 0.6407 | 0.7118 | 0.7108 | 0.7110 | |
| 12,000 | 0.6645 | 0.6308 | 0.6517 | 0.7053 | 0.7040 | 0.7042 | |
| 8000 | 0.6536 | 0.6163 | 0.6390 | 0.6992 | 0.6988 | 0.6988 | |
| 4000 | 0.6411 | 0.6020 | 0.6255 | 0.6945 | 0.6940 | 0.6938 | |
| 2000 | 0.6300 | 0.5831 | 0.6095 | 0.6825 | 0.6804 | 0.6807 | |
| 1000 | 0.6068 | 0.5629 | 0.5880 | 0.6633 | 0.6627 | 0.6628 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, J.T.H.; Juwono, F.H.; Ngu, I.Y.; Nugraha, I.G.D.; Maraden, Y.; Wong, W.K. A Mixed Malay–English Language COVID-19 Twitter Dataset: A Sentiment Analysis. Big Data Cogn. Comput. 2023, 7, 61. https://doi.org/10.3390/bdcc7020061
Kong JTH, Juwono FH, Ngu IY, Nugraha IGD, Maraden Y, Wong WK. A Mixed Malay–English Language COVID-19 Twitter Dataset: A Sentiment Analysis. Big Data and Cognitive Computing. 2023; 7(2):61. https://doi.org/10.3390/bdcc7020061
Chicago/Turabian StyleKong, Jeffery T. H., Filbert H. Juwono, Ik Ying Ngu, I. Gde Dharma Nugraha, Yan Maraden, and W. K. Wong. 2023. "A Mixed Malay–English Language COVID-19 Twitter Dataset: A Sentiment Analysis" Big Data and Cognitive Computing 7, no. 2: 61. https://doi.org/10.3390/bdcc7020061