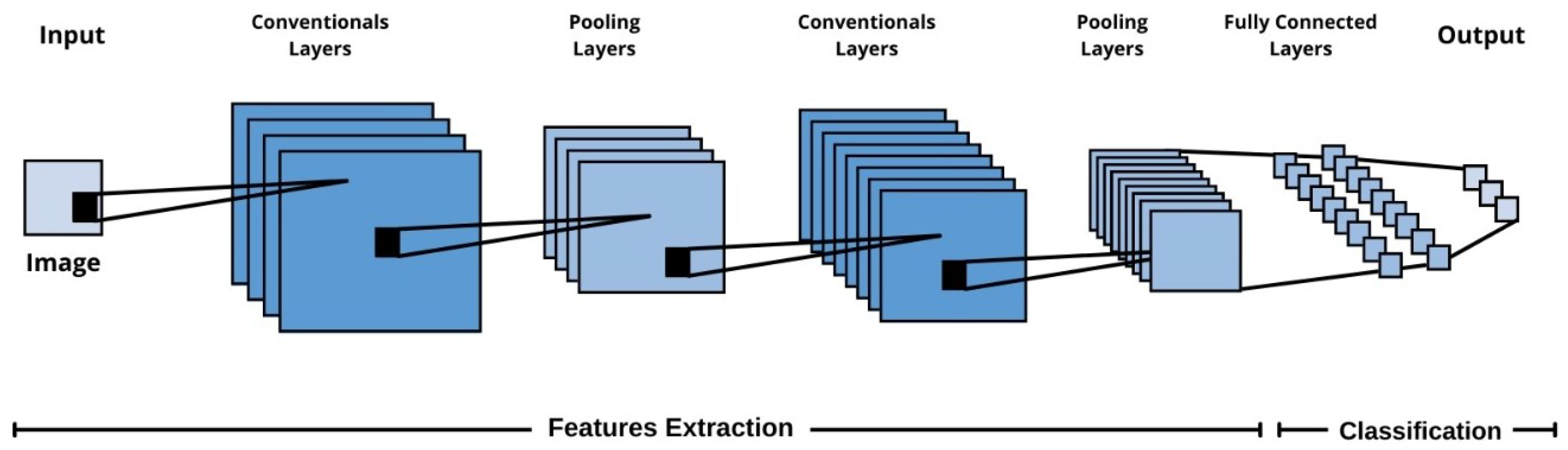
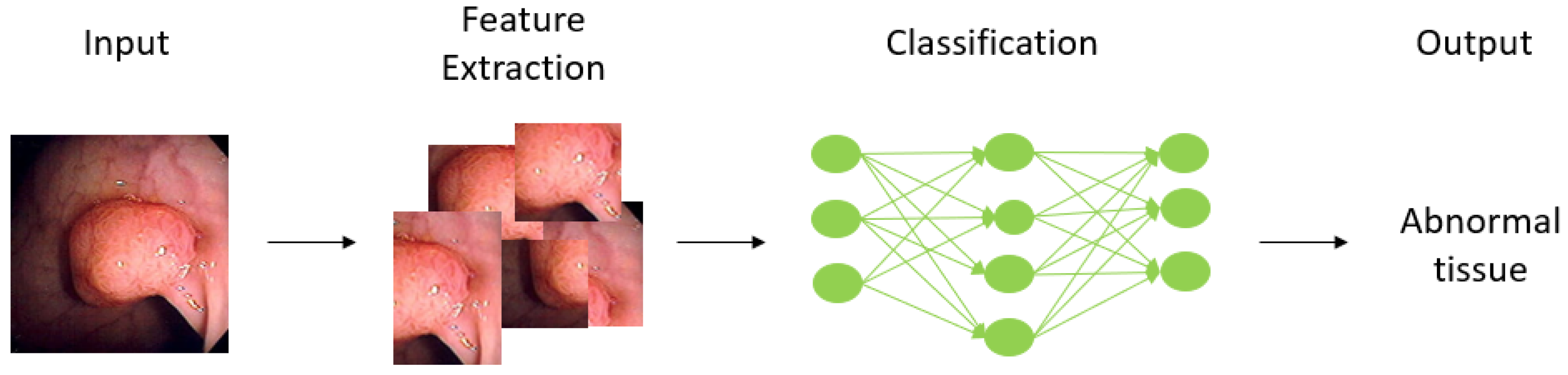
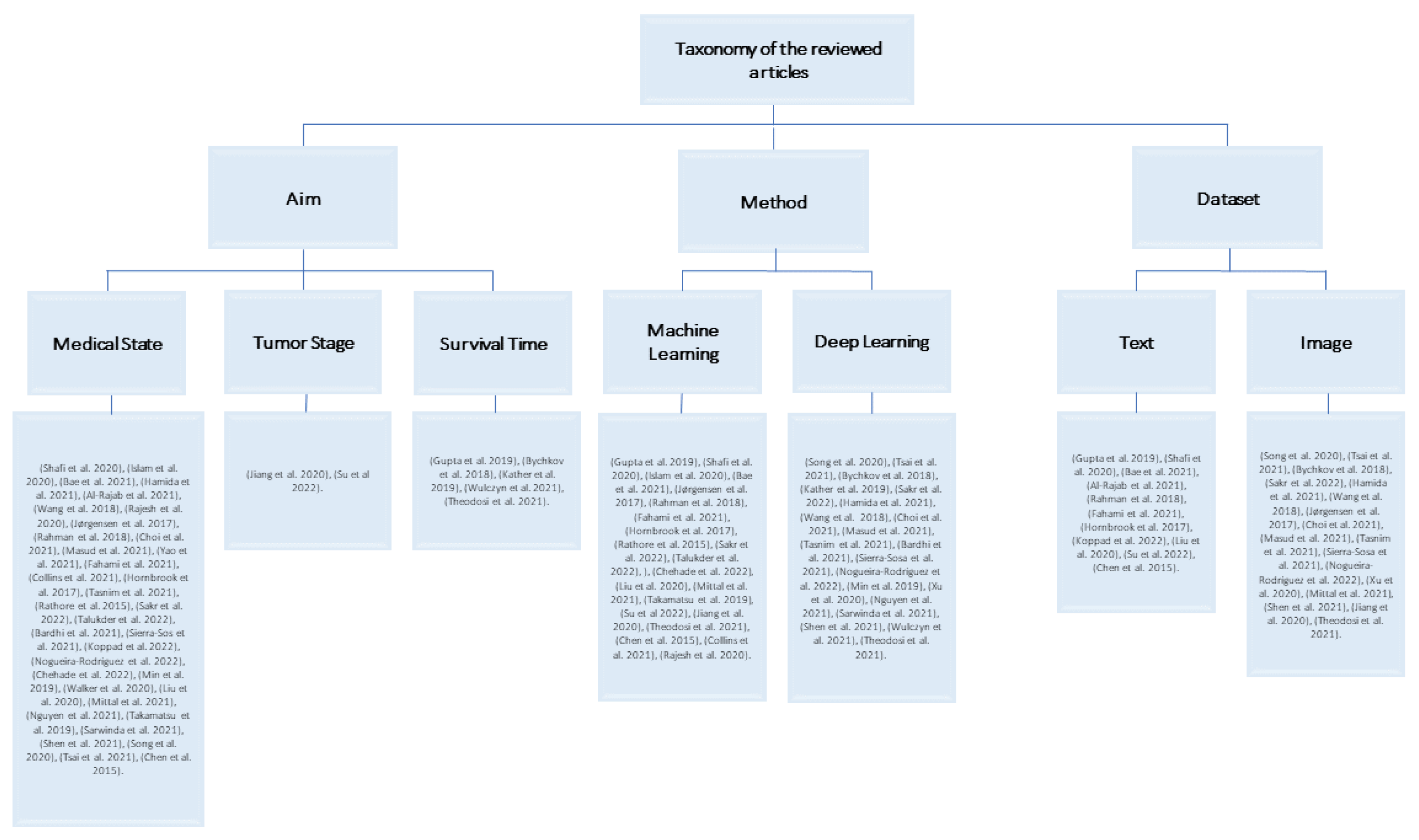
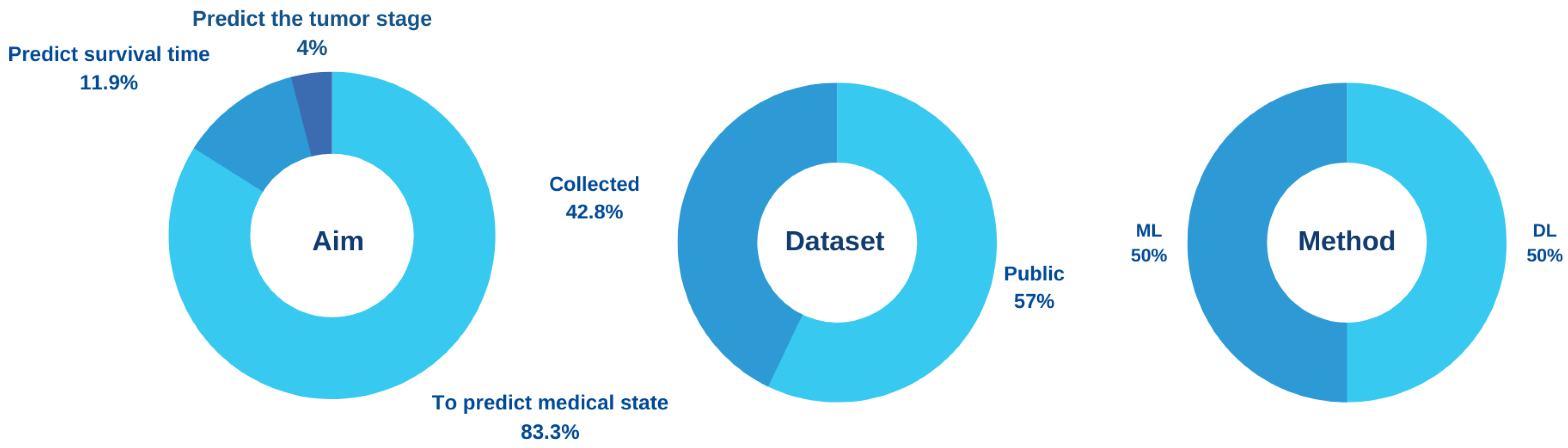
Most AI models for the prediction of colorectal cancer are classified in terms of the aim of building the model into (1) predicting the state of patients, whether normal or abnormal, (2) predicting the tumor stage, and (3) predicting survival time. The first aim targets the early detection of colorectal cancer, and the other two aims target patients who have been diagnosed with colorectal cancer.
4.1.1. Aim 1: To Predict Medical State
In [
38], the authors used ML algorithms and feature selection techniques to detect colon cancer. The Malondialdehyde (MDA) and maximum degree greedy (MDG) algorithms were used for feature selection. The RF, SVM, logistic regression (LR), AdaBoost, and KNN algorithms have been applied to a public dataset that is made up of 62 cases and 2000 genes. There are 40 abnormal and 22 normal patients among them. The result showed that the RF algorithm with the feature selection method achieved the highest accuracy with 95.161%. The model deals only with genes as features.
In [
39], the study aims to classify tissues into normal and abnormal using an ensemble classifier method. The feature selection methods that were used are filtering and wrapping. ML algorithms, which are RF, KSVM, eXtreme Gradient Boosting (XGB), KNN, and ensemble, were applied to 62 patients and 1200 gene expressions at the Bioinformatics Research Group of Pablo de Olavide University. There are 40 abnormal and 22 normal patients among them. The finding of this model was that the ensemble method achieved a higher accuracy of 91.67%.
In [
40], the authors looked at the problem of detecting the presence of colorectal cancer. The main algorithm applied was the modified Harmony Search Algorithm (Z-FS-KM-MHS). A total of 2000 genes from the Princeton University Gene Expression Project were used. The results showed that Z-FS-KM-MHS achieved accuracy up to 94.36%. The model used a large number of genes. Unlike other studies, this method can be applied to diseases related to genes, such as breast cancer.
Hamida et al. proposed a model for classifying colon images into normal or non-normal using the convolutional neural networks (CNN) algorithm. The main models applied were the UNET and SEGNET models for 100,000 histopathological images in Germany. SEGNET reached a high-performance accuracy of 99.5%. The authors concluded that DL is better for classifying images than ML for handling large-scale images. Unlike [
38,
39,
40], images were used to classify colon cancer [
41].
In [
42], the authors improved the diagnosis of colon cancer. The model applied ML algorithms, which are SVM, naive Bayes (NB), decision trees (DT), and KNN to two public datasets containing 9457 genes and 98 samples. KNN and DT were the best in classification using the first dataset, and NB was the best in classification when using the second dataset.
In [
43], the authors consider the problem of not detecting polyps through colonoscopy. The main method applied was DL in 1290 patients and 27,113 colonoscopy images from the Endoscopy Center of Sichuan Provincial People’s Hospital. The algorithm achieved a per-image sensitivity of 91.64%. However, the algorithm detects only polyps.
Rajesh et al. proposed a Density-Based Spatial Clustering of Applications with Noise (DB-SCAN) algorithm for colon tumor detection from biopsy samples by categorizing the normal or harmful cells. The algorithm was tested on 100 images collected from Zendo repositories. The results showed that the model achieved 99% accuracy, 85.4% sensitivity, and 87.6% specificity in detecting colon tumors [
44].
Jørgensen et al. used cell nuclei to extract information for the detection of cancerous tissue, whether it is benign or cancerous. This algorithm consists of RF, color deconvolution, k-means clustering, local adaptive thresholding, and cell separation within the region of interest (ROI) on 87 colon tissue slides. As a result, the algorithm obtained an area under the curve (AUC), sensitivity, specificity, and accuracy of 0.96, 0.88, 0.92, and 0.91, respectively, [
45].
Akizor and Ravi proposed a model for classifying lung and colon cancer using ANNs by applying a feature selection method. In this model, authors have used a public dataset consisting of 2000 genes and 62 instances. The classification accuracy reached 98.4% for the two classes of normal and cancer. In addition, the authors have found that using the feature selection method may increase the classification accuracy of the model. However, the sample size was small [
46].
Choi et al. built a computer-aided diagnosis (CAD) system by applying a DL model to predict four categories: normal, low-grade dysplasia, high-grade dysplasia, and adenocarcinoma of the pathologic histology of colorectal adenoma. The model applied CNN’s algorithm using 3400 computed tomography (CT) images collected from Korea Anam University Hospital (KUMC) and a CAD to develop a diagnostic system that predicts tissue adenoma of the colon and rectum. Then, the authors compared the results of the system with the results of the experts. The results showed a classification with a specificity of 92.42% and a sensitivity of 77.25%. In addition, it was close to the results of the experts. One of the limitations the authors faced is that there are not enough samples to assess the validity of their model [
47].
Yao et al. proposed automated classification and segmentation of colorectal images based on the self-speed transmission network into three classes: normal tissue, polyps, and tumors. A pre-trained network on ImageNet was first applied to improve the result, and then it was applied to 3061 images. For segmentation, the Unet network framework was used, and then the trained Self-paced Transfer VGG (STVGG) network model was used for colorectal classification. The model has obtained high accuracy for both classification and segmentation. This paper is distinguished from the rest of the studies in that it combined two objectives, namely classification and segmentation. It also used self-learning to solve the problem of imbalance, learn the difficult sample, and raise performance [
48].
Masud et al. proposed a classification framework using digital image processing (DIP) and modern DL. Features were extracted from 25,000 pathological histological images using DIP. After that, features were collected and categorized using the CNN model. The classification of lung and colon cancer demonstrated an accuracy of 96.33%, a precision of 96.39%, a recall of 96.37%, and an f-Measure of 96.38%. This study mentioned in detail an important point, which is to process the images before implementing the algorithm using two techniques, and this may help to raise the accuracy of the results [
49].
Fahami et al. proposed a model to detect the most effective genes for colon cancer patients in their vital status by using ML methods such as neural networks, KNN, and DT. As a result, DT has high accuracy when using the HTSeq-FPKM-UQ public dataset [
50].
Collins et al. discussed how to detect colorectal and esophagogastric cancer tissue using an automatic CAD tool via an optical image. The dataset is from a public university hospital in Leipzig and includes 10 patients with Esophagogastric cancer and 12 patients with colon cancer. After studying the receiver operator curve–area under the curve (ROC–AUC) performance in the colon dataset in different models such as radial basis function (RBF)–SVM, MLP, and 3-dimensional convolutional neural network (3D CNN), it has been concluded that the 3D CNN model achieved a more accurate performance to detect colon cancer with an accuracy of 93% [
20].
Hornbrook et al. suggested that in the United States (US), a community-based, insured adult population can detect colorectal cancer by using ML and making a diagnosis based on gender, age, and complete blood count data. The dataset used is Kaiser Permanente Northwest Region’s Tumor Registry (KPNW), which includes 439 females and 461 males. The result of high-risk detection with colorectal cancer was 99% [
51].
Chen et al. developed an innovative deep learning algorithm for shallow neural networks (SNN). They present an SNN model with a set of parameters in the supervised model, and they decompose its computational process into a number of positive parts that work smoothly together to produce a superior outcome. It produces consistently high-quality results, on par with those of deep neural networks. In addition to describing the algorithm, this paper analyzes it.
In [
52], the authors improved an approach that takes around a minute to identify colon cancer from the input picture using a CNN algorithm with the max pooling and average pooling layers and MobileNetV2 models. The dataset contains 25,000 images taken from the Kaggle platform. The accuracy results were 97.49% and 95.48%. Moreover, the MobileNetV2 model has the highest accuracy rate of 99.67%.
Rathore et al. developed a model for predicting cancer in colon tissues using a Hybrid Feature Space-Based Colon Classification (HFS-CC) technique and the k-means algorithm for clustering. 68 colon biopsy samples were taken from randomly selected patients at Rawalpindi Medical College (RMC). The result showed that the HFS-CC technique achieves 98.07% accuracy [
53].
In [
22], the authors proposed a new efficient method for the detection of colon cancer using DL. In order to detect colon cancer, the CNN algorithm with the LC25000 Lung and Colon Histopathological Image dataset has been used. The result showed that the CNN algorithm provides a high accuracy of 99.50%. However, this paper did not employ optimization techniques to select the best features from the extracted deep features.
In [
54], the authors developed a hybrid ensemble feature extraction model to efficiently identify lung and colon cancer. The method that has been used is feature extraction and ML algorithms with the LC25000 Lung and Colon Histopathological Image dataset. The accuracy rate for lung cancer detection was 99.05% and for colon cancer it was 100%; for lung and colon cancers, it was 99.30%. Even though the outcome of detecting lung and colon cancer has high accuracy, the model needs to be evaluated using a different dataset to see how it performs.
The authors in [
55] used the combination of CNN and autoencoders on the CVC-ColonDB, CVC-ClinicDB, and ETIS-LaribPolypDB datasets. The proposed model achieved 96.7% accuracy, which is better than the models compared to it: the deep CNNs model, which has an accuracy of 96.4% and the AI-Assisted Polyp Detection model, which has an accuracy of 76.5%, although not very significant.
In [
56], the application of DL techniques for the detection and segmentation of colon polyps in colonoscopies has been presented. The authors used region-based convolutional neural networks (R-CNN), path aggregation network (PA-Net), Cascade R-CNN, and Hybrid Task Cascade (HTC) with ClinicDB, ETIS, and Deusto University e-Vida research group datasets. The outcome showed that the best detection rate was acquired when training the model with all the datasets and using PANet architecture. The best segmentation accuracy was acquired when using HTC architecture trained with the merged dataset and tested on the CVC-CLINIC dataset. On the other hand, the model needs a framework for real-time processing of the live feed from the colonoscopy.
In [
57], the study set out to identify genes’ associations with colorectal cancer using a cyclic redundancy check (CRC) that can potentially be used as diagnostic markers in translational research. Different algorithms were implemented, which are Adaboost, ExtraTrees, LR, NB, RF, and XGB on the GSE44861, GSE20916, and GSE113513 datasets. The findings showed that 34 genes with high accuracy can be used as a diagnostic panel for CRC. Furthermore, RF achieved an accuracy of 98.2% and had the best performance among all classifiers when using GSE44861 as training data and GSE20916 as test data. The results of this research can aid in the identification of risk factors for colorectal cancer; while ensuring the clinical utility of the indicators discovered, it will help doctors make more informed decisions about treating colorectal cancer. However, specific trials are needed to validate the findings of this study.
The authors in [
58] tested a previously published polyp detection model with ten public colonoscopy image datasets. The You Only Look Once version 3 (YOLOv3) model has been used with ten datasets, which are: CVC-ClinicDB, CVC-ColonDB, CVC-PolypHD, ETIS-Larib, Kvasir-SEG, CVC- ClinicVideoDB, PICCOLO, KUMC dataset, SUN, and LDPolypVideo. The paper showed that when evaluating the recently published model on a private test partition, the F1-score was 0.88. When tested on ten public datasets, it decayed by 13.65% on average. The authors pointed out the interest in comparing intradataset performances (i.e., a performance evaluation on a test split of the dataset used for model development, either private or public) versus interdataset performances (i.e., a performance evaluation on a dataset different from the one used for model development). The authors in [
59] constructed an automated system that can accurately classify the subtypes of colon and lung cancer. They used the Lung and Colon Histopathological Image (LC25000) datasets with ML, feature engineering, and image processing approaches. According to the results, the XGBoost has an F1 score of 98.8% and an accuracy of 99%.
Min et al. built a computer-aided diagnosis (CAD) system by applying linked color imaging (LCI) images to predict the histological results of polyps, whether they are adenomatous or non-adenomatous. The CAD system was trained and tested in this study with a dataset from the Hospital of the Academy of Military Medical Sciences. There were 389 images and 203 patients in the dataset. Due to the small size of the dataset, the authors used a Gaussian mixture model (GMM) to train the system. The system was therefore accurate to 78.4%, a specificity of 70.1%, a sensitivity of 83.3%, and PPV of 82.6%. The accuracy of the CAD system was comparable to that of expert endoscopists when compared to them [
60].
In [
61], the authors proposed a model for colorectal cancer detection based on DL. The main algorithm applied is CNNs in 322 images from St. Paul’s Hospital. The CNN algorithm achieved an accuracy of 91.64% for normal slides and 94.8% for cancer slides. In training, heavy data augmentation was performed to increase the robustness of the model.
In [
62], the authors aimed to identify the fundamental transcript factors (TFs) associated with the clinical outcomes of colon cancer patients by combining the random forest algorithm with the traditional Cox proportional hazard (Cox PH) method. The system used public datasets from the GEO database, which include 925 patients with colon cancer. As a result, the authors were able to construct a predictive model for the prognosis signature of colon cancer and successfully identify five TF signatures.
Mittal et al. developed a new classification method that, by combining MALDI-MSI with supervised ML, can accurately predict lymph node metastasis (LNM) status for patients with primary endometrial cancer (EC) and differentiate between colorectal cancer (CRC) and normal tissue. In this model, the authors classified by using neural networks (NN). The study made use of a dataset from the PRIDE partner repository, which contained 15 TMAs and 302 patients’ images related to CRC and EC. The model correctly identified the metastasis stage of approximately 80% of the EC spectra and 98% of the CRC spectra as being derived from normal or tumorous tissue [
63].
In [
10], the researchers aimed to use DL technology to identify medical images to increase the accuracy of the identification due to the automatic classification of tumor types. The authors used CNN with the NCT-CRC-HE-100K, Kather-texture-2016-image, and CRC-VAL-HE-7K datasets. The study’s findings showed an accuracy rate of 99.69% when using NCT-CRC-HE-100K and a rate of 99.32% when using CRC-VAL-HE-7K.
The goal of [
9] was to establish a semantic segmentation model for the diagnosis of colorectal adenomas. The dataset was obtained from the Chinese People’s Liberation Army (PLA) General Hospital (PLAGH), the Cancer Hospital, the Chinese Academy of Medical Sciences (CH), and the China–Japan Friendship Hospital (CJFH) and used with deep CNN. The results revealed that accuracy had reached 90%.
In [
64], this study aims to classify colorectal tissue images, including tumor versus normal tissues and other tissue types, by TMA core images, which is a treasure trove for artificial intelligence applications. Using DL techniques, TMA tissue cores can be classified into five classification flows: the two first classification flows, each NN (VGG16 and CapsNet), and the three other classification flows are based on ensemble methods. The performance metrics used are recall, precision, F1-score, and accuracy. In another hand, the dataset contains 770 patients from three different cohorts, which included 410 Swiss patients, 89 German patients, and 271 Canadian patients, along with 54 TMA slides. The best results achieved in this paper were from a Soft Voting Ensemble comprising one VGG and one CapsNet model, with a prediction accuracy of 0.939, 0.982, and 0.947 for tumor, normal, and “other”, respectively.
In [
65], the aim was to develop a prediction model of lymph node metastasis (LNM) based on ML. The dataset used in this study is available in the Figshare repository. For the training dataset, which consisted of 277 slide images, a random forest algorithm was used, and 120 slide images were used for the test. The findings demonstrate that ML has a high predictive value of 0.938 AUCs.
Sarwinda et al. proposed a model for the detection of colorectal cancer. The method of the model is DL using residual network (ResNet). There are two classifiers, which are ResNet-18 and Resnet-50. The authors have trained ResNet-18 and ResNet-50 on colon gland images to distinguish colorectal cancer from benign and malignant. The dataset from a Warwick-QU consists of 165 images, including 74 benign tumor images and 91 malignant tumor images. ResNet-50 achieved the highest accuracy of 88% when testing data values of 20% and 25%. When the training data increase, the accuracy of the model increases [
66].
Ref. [
67] suggested a high-throughput system to precisely identify tumor areas on colorectal cancer histology slides. The methodology that has been used is a CNN model and a Monte Carlo (MC) adaptive sampling method with three datasets of colorectal cancer from The Cancer Genome Atlas (TCGA). The result achieved an accuracy of 98.90%.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}