

SQL and NoSQL Database Software Architecture Performance Analysis and Assessments—A Systematic Literature Review


Abstract
1. Introduction
- Schema-less structure
- Permitting data representations to grow effectively and dynamically
- Scaling horizontally, by data replication collections and sharding, over massive clusters.
- Volume: Data at rest—Terabytes to exabytes of existing data to process.
- Velocity: Data in motion—Streaming data, milliseconds to seconds to respond.
- Variability: Data in many forms—structured, unstructured, text, etc.
- Veracity: Data in doubt—uncertainty due to latency, deception, ambiguities, etc.
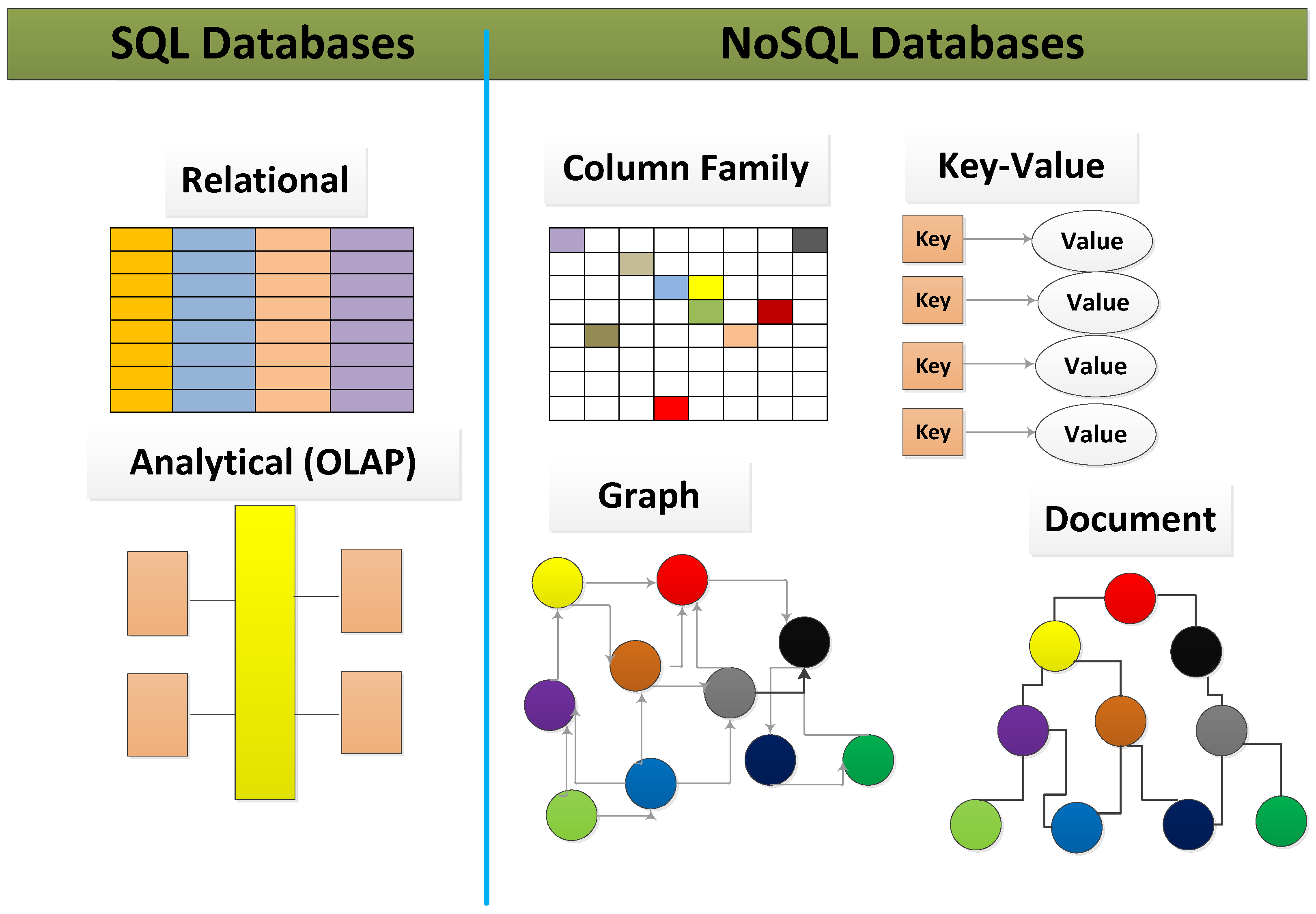
- Not built on tables and does not employ SQL to manipulate data.
- Schema comprises key-value, document, columnar, graph, etc.
- Alternative to traditional relational databases.
- Database to handle unstructured, messy, and unpredictable data.
- Helpful for working with large sets of distributed data.
- This SLR is related to the SQL and NoSQL database architecture assessments, scaling capabilities, and performance analysis, particularly Oracle RDBMS and NoSQL Document Database (MongoDB). In addition, data movement among various databases across multiple cloud platforms is explored.
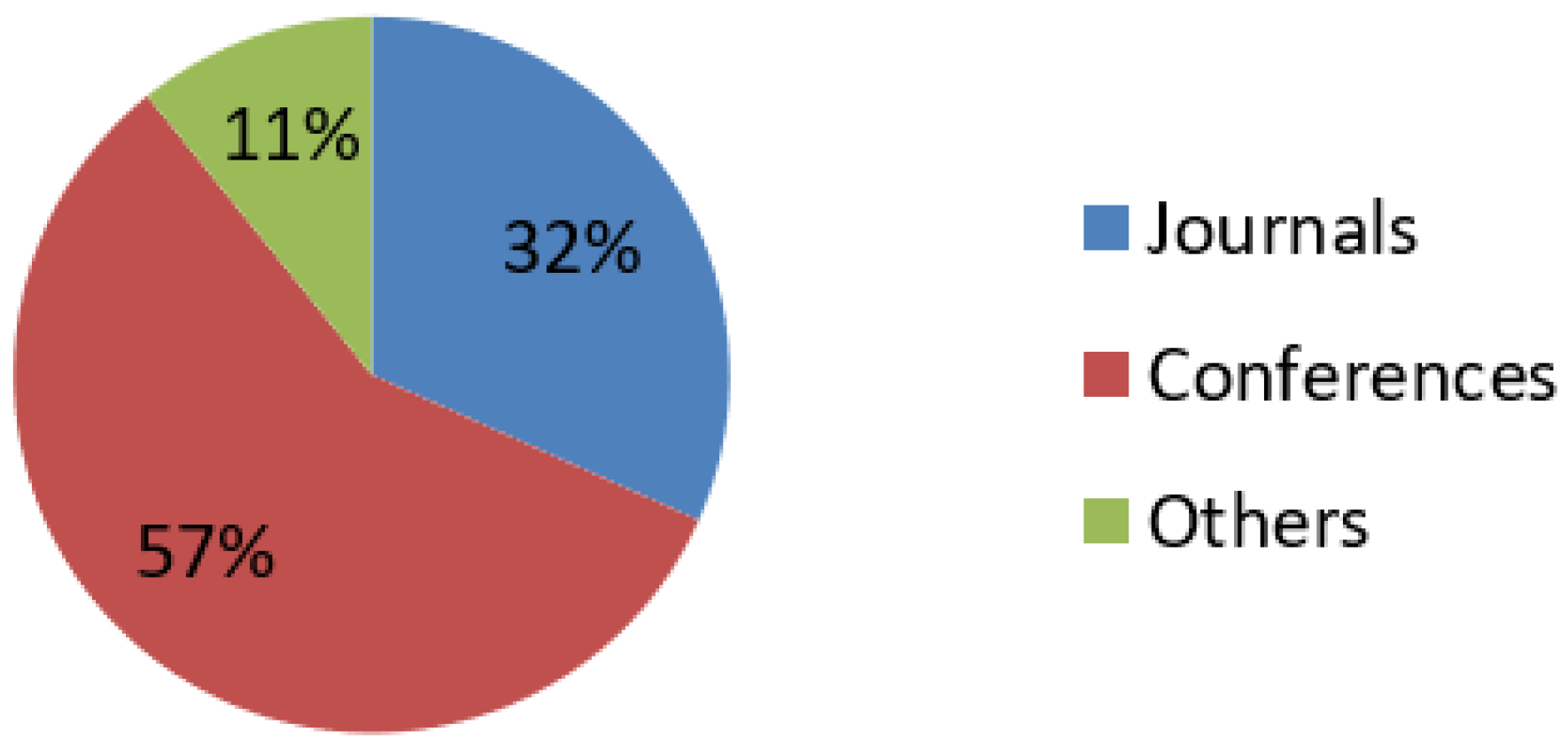
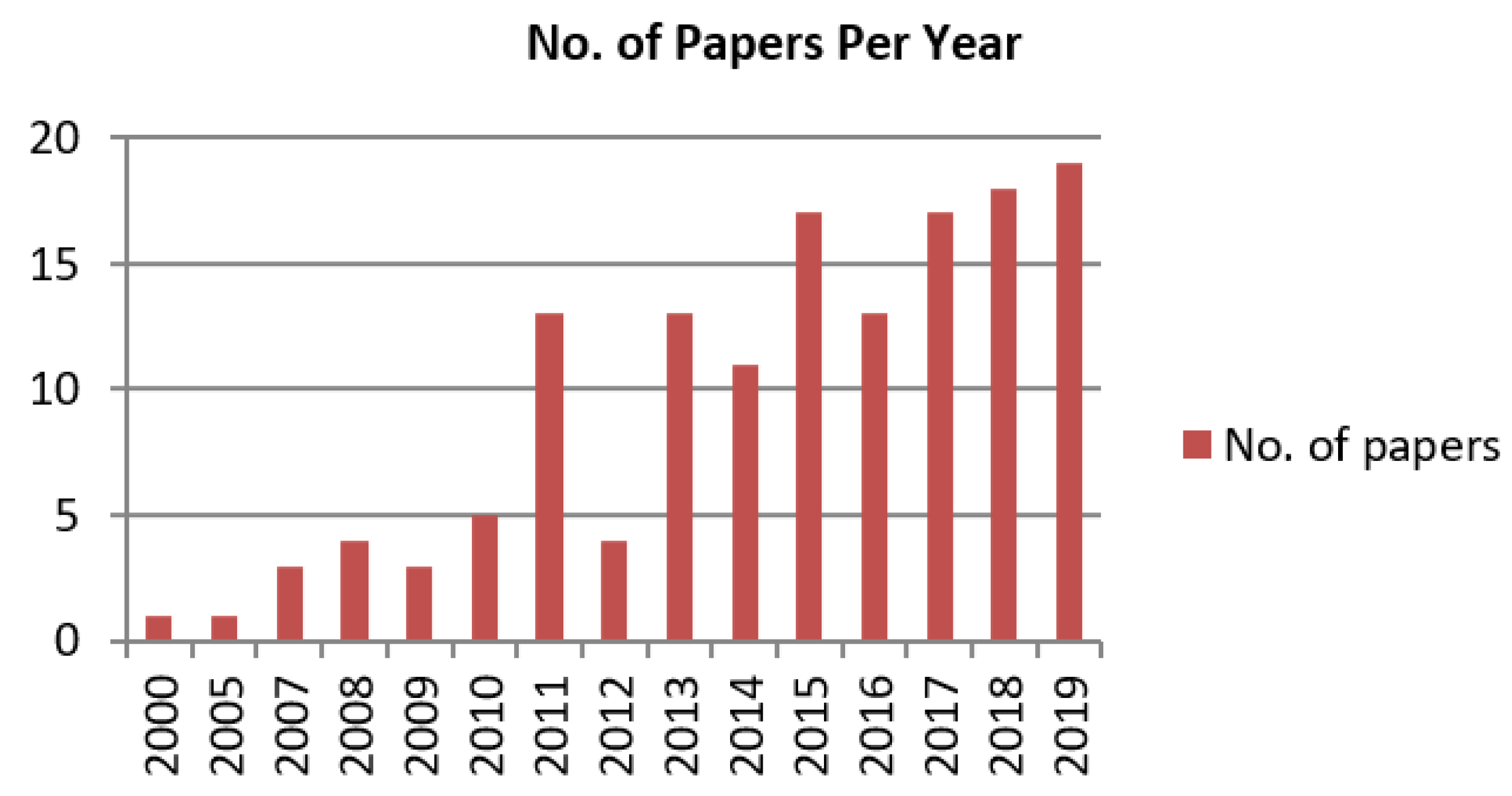
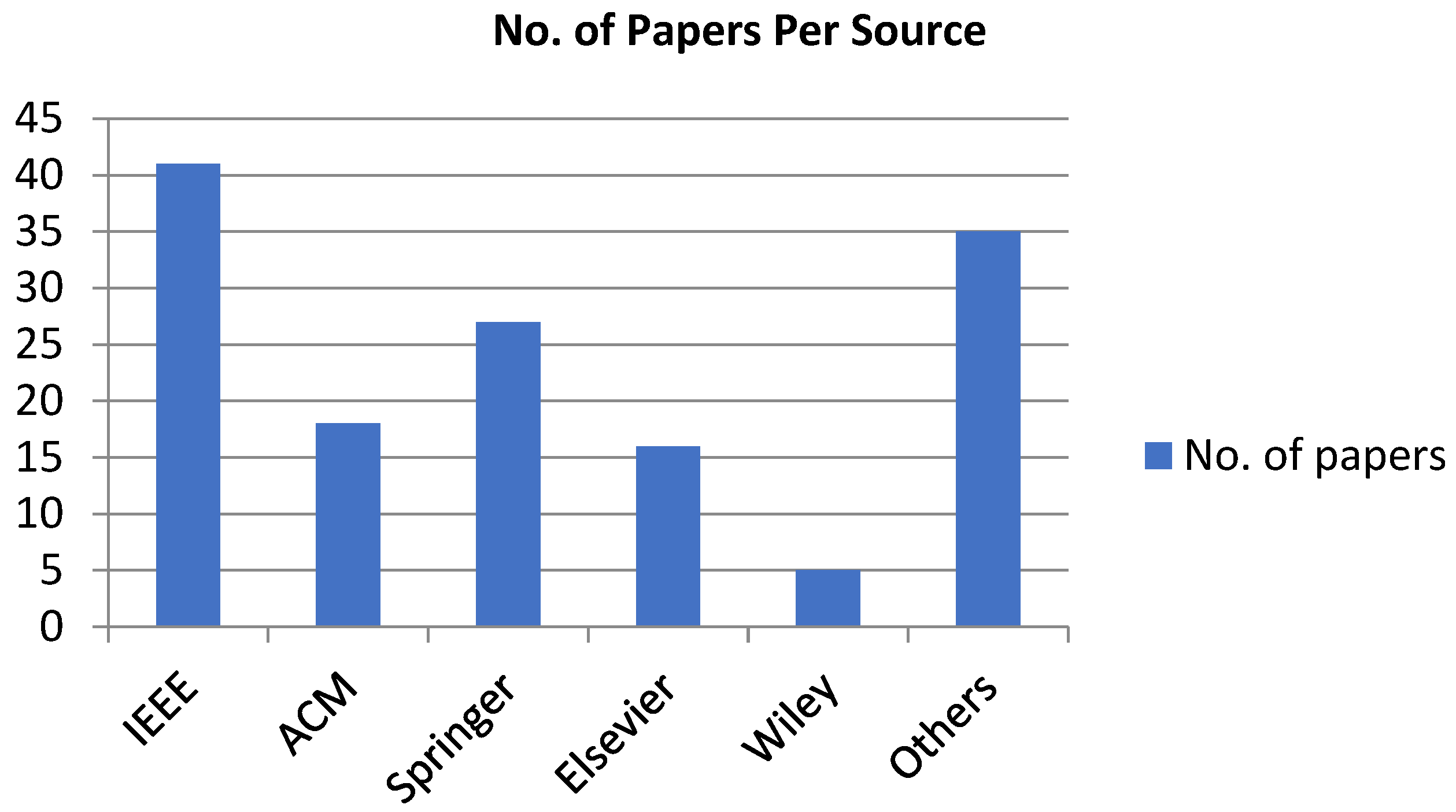
- A total of 142 studies have been analyzed to accomplish the research goals mentioned earlier.
- This article identifies the research gaps in the associated architectures and their causes.
1.1. State of the Problem
1.2. Method
2. Objectives and Research Questions
- Address the existing SQL and NoSQL document approaches and techniques by considering big data processing.
- Perform a systematic literature review associated with SQL and NoSQL databases.
- Review selected study subsets in depth.
- Assess the strength and weaknesses of SQL and NoSQL databases on the basis of the evidence collected and analyzed from these studies.
- Highlight the research gap in the area.
- Identify future research directions.
- Formulate the following research questions to achieve the main objective of our study:
- Considering big data (structured and unstructured data): What is the need for NoSQL?
- Why does the NoSQL database follow the BASE property instead of the SQL database ACID property?
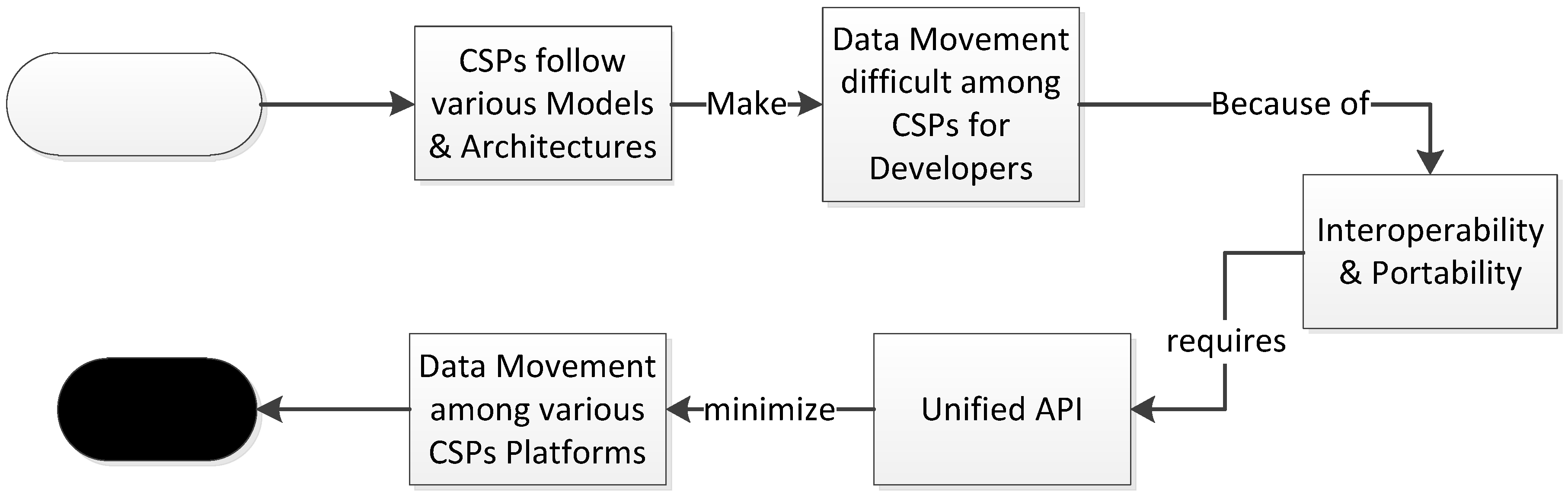
- Does DBaaS tackle data interoperability and portability efficiently in various NoSQL databases?
2.1. Search Criteria
2.1.1. Search Resources
- DBLP
- IEEExplore Digital Library (ieeexplore.ieee.org)
- Google Scholar
- ACM Digital Library (dl.acm.org)
- Springer (Springerlink.com)
- Elsevier (sciencedirect.com)
- Wiley Online Library (onlinelibrary.wiley.com)
2.1.2. Search Strategy
- “SQL and NoSQL”
- “SQL or NoSQL”
- “Relational Database and Document Database”
- “Relational Database or Document Database”
- “Relational Database and NoSQL Document Database”
- “Relational Databases and MongoDB”
- “Relational Databases or MongoDB”
- “Oracle and MongoDB Comparison”
- “SQL and NoSQL Database Comparisons”
- “Advantages of MongoDB over RDBMS”
- “Relational and Non-relational Databases”
- “Cloud Data Portability and Interoperability”
2.2. Selection Process and Criteria
- Step1: Total number of documents based on:
- Papers Titles.
- Papers Abstract.
- Associated papers full reading
- (1)
- Check the quality and impact of related papers
- ✓
- Check the article in the catalogue to avoid repetition
- ✓
- Add item to the finalized papers catalogue
- (2)
- Manual search and snowballing
- (3)
- Repeat the entire process, go to Step1
- Research purpose
- Associated literature and supported theories
- Hypothesis measurement
- Proposed method, design, approach, dimension, and data collection
- Data result analysis
- Conclusion
2.2.1. Inclusion Criteria
- IC1: related SLRs and survey papers
- IC2: new proposed techniques and approaches relevant to our proposed SLR
- IC3: effective research methods presented in the proposed study
2.2.2. Exclusion Criteria
- EC1: papers not related to the mentioned domain
- EC2: irrelevant papers
- EC3: some papers based on the title and abstract
- EC4: non-peer-reviewed materials and papers
- EC4: articles not written in English and duplicated articles
2.3. Data Collection and Extraction
- Title of paper
- Abstract of paper
- Paper source (journal or conference)
- Publication year
- Paper classification (type, scope)
- Relatedness to the proposed SLR
- Proposed SLR objectives and research question issues
- Paper summary and method
2.4. Data Analysis and Classification
- Considering big data (structured and unstructured data): What is the need for NoSQL?
- Why does the NoSQL database follow the BASE property instead of the SQL database ACID property?
- Does DBaaS tackle data interoperability and portability efficiently in various NoSQL databases?
2.5. Validity Threats and Evaluations
3. Results
Empirical Studies Analysis
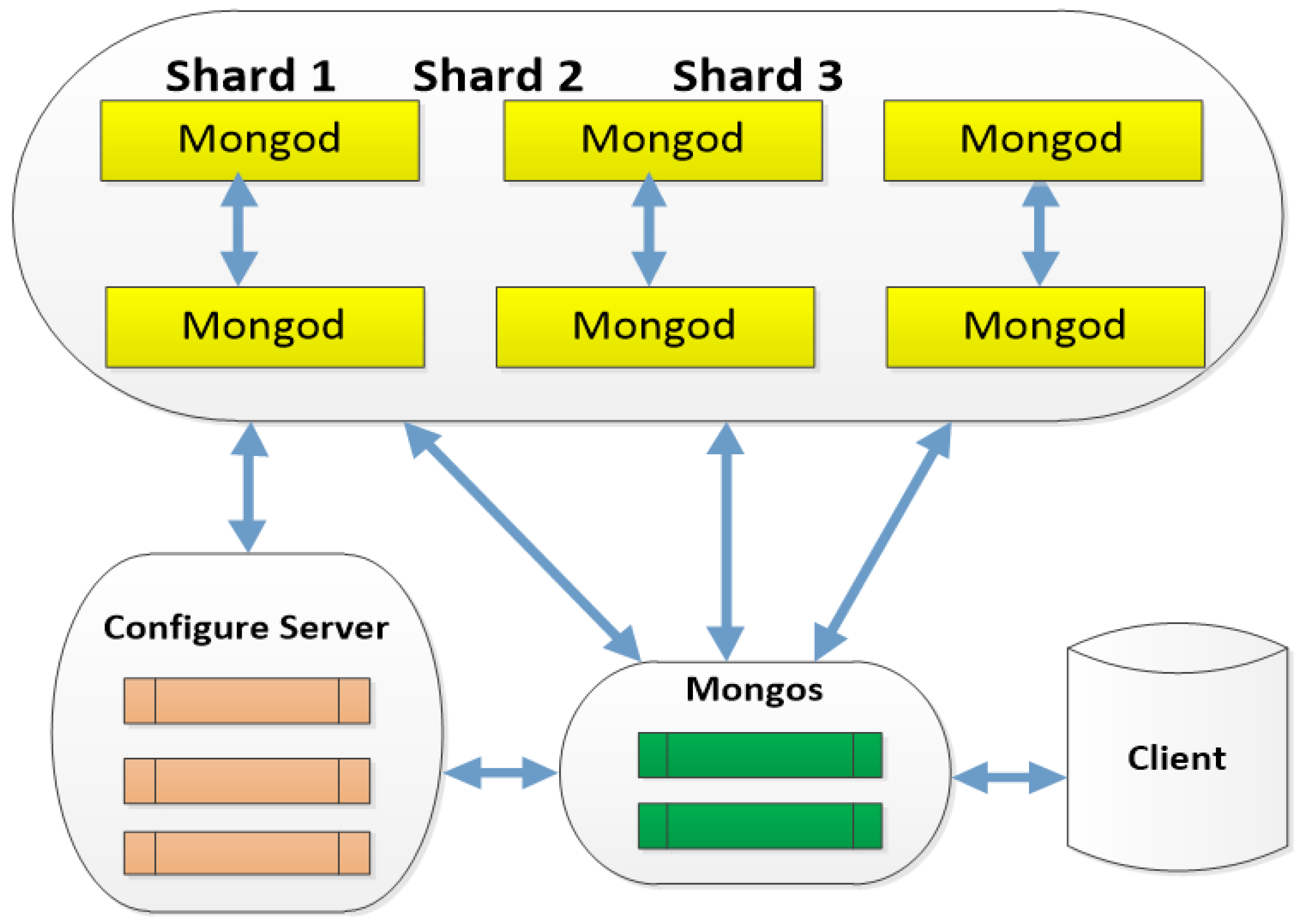
NoSQL MongoDB Data Modeling
4. Discussion and Classification
4.1. Research Gap
4.2. Prediction and Occurrences of DBMSs against a Particular DBMS
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Publication Year | Journal/Conference Name | Category |
|---|---|---|---|
| Optimization of linear recursive queries in SQ | 2009 | IEEE Transaction on Knowledge and Data Engineering | Journal |
| Building scalable databases: Denormalization, the NoSQL movement and Digg | 2009 | NA | Other |
| NoSQL–NOT ONLY SQL | 2013 | International Journal of Enterprise Computing and Business Systems | Journal |
| Towards robust distributed systems | 2000 | ACM- Principal on Distributed Computing | Conference |
| A study on data storage security issues in cloud computing | 2016 | 2nd International Conference on Intelligent Computing, Communication & Convergence | Conference |
| CloudDBGuard: A framework for encrypted data storage in NoSQL wide column stores | 2019 | Data & Knowledge Engineering | Journal |
| Survey on NoSQL database | 2011 | 6th international conference on pervasive computing and applications | Conference |
| RDBMS to NoSQL: reviewing some next-generation non-relational database’s | 2011 | INTERNATIONAL JOURNAL OF ADVANCED ENGINEERING SCIENCES AND TECHNOLOGIES | Journal |
| SQL databases v. NoSQL databases | 2010 | Communication of the ACM | Journal |
| The transition from rdbms to nosql. a comparative analysis of three popular non-relational solutions: Cassandra, mongodb and couchbase | 2014 | Database Systems Journal | Journal |
| The battle between NoSQL Databases and RDBMS | 2019 | NA | Other |
| Ten years of critical review on database forensics research | 2019 | Digital Investigation | Journal |
| Big data processing tools: an experimental performance evaluation | 2019 | Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery | Journal |
| MongoDB NoSQL injection analysis and detection | 2016 | 3rd International Conference on Cyber Security and Cloud Computing (CSCloud) | Conference |
| A comparative study: MongoDB vs. MySQL | 2015 | 13th International Conference on Engineering of Modern Electric Systems (EMES) | Conference |
| Comparing nosql mongodb to an sql db | 2013 | In Proceedings of the 51st ACM Southeast Conference | Conference |
| Using MongoDB to implement textbook management system instead of MySQL | 2011 | IEEE 3rd International Conference on Communication Software and Networks | Conference |
| MongoDB vs Oracle--database comparison | 2012 | third international conference on emerging intelligent data and web technologies | Conference |
| A performance comparison of SQL and NoSQL databases | 2013 | IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM) | Conference |
| SQL database with physical database tuning technique and NoSQL graph database comparisons | 2019 | In Proceedings of 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference, ITNEC | Conference |
| Predictive Performance Comparison Analysis of Relational & NoSQL Graph Databases | 2017 | IJACSA | Journal |
| Comparative study of relational and non-relations database performances using Oracle and MongoDB systems | 2014 | Journal Impact Factor | Journal |
| A comparison of a graph database and a relational database: a data provenance perspective | 2010 | In Proceedings of the 48th annual Southeast regional conference | Conference |
| SQL support over MongoDB using metadata | 2013 | International Journal of Scientific and Research Publications | Journal |
| Comparative analysis of nosql (mongodb) with mysql database | 2015 | International Journal of Modern Trends in Engineering and Research | Journal |
| A comprehensive comparison of SQL and MongoDB databases | 2015 | International Journal of Scientific and Research Publications | Journal |
| Performance comparison of in-memory and disk-based databases using transaction processing performance council (TPC) benchmarking | 2018 | Journal of Internet and Information. Systems | Journal |
| ANALYSIS AND COMPARISON OF DOCUMENT-BASED DATABASES WITH SQL RELATIONAL DATABASES: MONGODB VS MYSQL | 2018 | Proceedings of the International Conference onInformation Technologies | Conference |
| Performance Analysis of RDBMS and No SQL Databases: PostgreSQL, MongoDB and Neo4 | 2018 | 3rd International Conference and Workshops on Recent Advances and Innovations in Engineering (ICRAIE) | Conference |
| Comparison of query performance in relational a non-relation databases | 2019 | 13th International Scientific Conference on Sustainable, Modern and Safe Transport(TRANSCOM) | Conference |
| Closing the functional and performance gap between SQL and NoSQL | 2016 | In Proceedings of the 2016 International Conference on Management of Data | Conference |
| Migration from rdbms to column-oriented nosql: Lessons learned and open problems | 2018 | In Proceedings of the 7th International Conference on Emerging Databases | Conference |
| A performance evaluation of open source graph databases | 2014 | In Proceedings of the first workshop on Parallel programming for analytics applications | Conference |
| Labeled Property Graphs: SQL or NoSQL? | 2019 | Ivannikov Memorial Workshop (IVMEM) | Conference |
| Graph Schema Storage in SQL Object-Relational Database and NoSQL Document-Oriented Database: A Comparative Study, | 2019 | in International Conference Europe Middle East & North Africa Information Systems and Technologies to Support Learning | Conference |
| Graph-Based Denormalization for Migrating Big Data from SQL Database to NoSQL Database | 2019 | In Intelligent Communication Technologies and Virtual Mobile Networks | Conference |
| The use of a graph-based system to improve bibliographic information retrieval: System design, implementation, and evaluation | 2017 | Journal of the Association for Information Science and Technology | Journal |
| A study on data input and output performance comparison of MongoDB and PostgreSQL in the big data environment | 2015 | In 2015 8th International Conference on Database Theory and Application (DTA) | Conference |
| Comparison of SQL, NoSQL and NewSQL databases for internet of things | 2016 | IEEE Bombay Section Symposium (IBSS) | Conference |
| Data Migration from Relational Database to MongoDB | 2019 | Global Journal of Computer Science and Technology | Journal |
| Modeling MongoDB with relational model | 2013 | In 2013 Fourth International Conference on Emerging Intelligent Data and Web Technologies | Conference |
| Automatic mapping of MySQL databases to NoSQL MongoDB | 2016 | in 2016 Federated Conference on Computer Science and Information Systems (FedCSIS) | Conference |
| Migrating from SQL to NOSQL Database: Practices and Analysis | 2018 | in 2018 International Conference on Innovations in Information Technology (IIT) | Conference |
| Data adapter for querying and transformation between SQL and NoSQL database | 2016 | Future Generation Computer Systems. | Journal |
| Migration of healthcare relational database to NoSQL cloud database for healthcare analytics and management | 2019 | Healthcare Data Analytics and Management, | Other |
| A framework for migrating relational datasets to NoSQL | 2015 | International Conference On Computational Science | Conference |
| Transformation of SQL system to NoSQL system and performing data analytics using SVM | 2017 | In 2017 International Conference on Trends in Electronics and Informatics (ICEI) | Conference |
| Correlation Aware Technique for SQL to NoSQL Transformation | 2014 | 7th International Conference on Ubi-Media Computing and Workshops | Conference |
| SQL to NoSQL transformation system using data adapter and analytics | 2017 | IEEE International Conference on Technological Innovations in Communication, Control and Automation (TICCA) | Conference |
| Integration and virtualization of relational SQL and NoSQL systems including MySQL and MongoDB | 2014 | International Conference on Computational Science and Computational Intelligence | Conference |
| NoSQL real-time database performance comparison | 2018 | International Journal of Parallel, Emergent and Distributed Systems | Journal |
| MongoDB and Oracle NoSQL: A technical critique for design decisions | 2016 | International Conference on Emerging Trends in Engineering, Technology and Science (ICETETS) | Conference |
| Nosql database: New era of databases for big data analytics-classification, characteristics and comparison | 2013 | ARVIX | NA |
| Query Response Time Comparison NOSQLDB MONGODB with SQLDB Oracle | 2015 | Jurnal Ilmiah Teknologi Informasi | Journal |
| Relative scalability of NoSQL databases for genotype data manipulation. | 2018 | Revista de Informática Teórica e Aplicada - RITA | Journal |
| Scalable SQL and NoSQL data stores | 2011 | ACM Sigmod Record | Other |
| SQL-to-NoSQL schema denormalization and migration: a study on content management systems | 2015 | IEEE International Conference on Systems, Man, and Cybernetics | Conference |
| SQL & NoSQL Databases | 2019 | Other | Other |
| Integration of Relational and NoSQL Databases | 2018 | In Asian Conference on Intelligent Information and Database Systems. | Other |
| Literature Review on Database Design Testing Techniques | 2019 | Advances in Intelligent Systems and Computing | Other |
| Database engines: Evolution of greenness | 2018 | Journal of Software: Evolution and Process | Conference |
| BASE analysis of NoSQL database | 2015 | Future Generation Computer Systems | Journal |
| Evaluation of ACE properties of traditional SQL and NoSQL big data systems | 2019 | In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing | Conference |
| Adaptive trade-off between consistency and performance in data replication | 2017 | Software: Practice and Experience | Other |
| Automatic SQL-to-NoSQL schema transformation over the MySQL and HBase databases | 2015 | IEEE International Conference on Consumer Electronics-Taiwan | Conference |
| Analyzing and Comparison of NoSQL DBMS | 2018 | International Scientific-Practical Conference Problems of Infocommunications | Conference |
| A performance evaluation of in-memory databases | 2017 | Journal of King Saud University Computer and Information Science | Journal |
| MapReduce: simplified data processing on large clusters | 2008 | Communications of the ACM | Journal |
| Database technologies in the world of big data | 2015 | In Proceedings of the 16th International Conference on Computer Systems and Technologies | Conference |
| Map-reduce-merge: simplified relational data processing on large clusters | 2007 | In Proceedings of the 2007 ACM SIGMOD international conference on Management of data | Conference |
| MRShare: sharing across multiple queries in MapReduce | 2010 | Proceedings of the VLDB Endowment | Conference |
| A Comparison of NoSQL and SQL Databases over the Hadoop and Spark Cloud Platforms using Machine Learning Algorithms | 2018 | IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW) | Conference |
| Performance Analysis of Hadoop-Based SQL and NoSQL for Processing Log Data | 2015 | International Conference on Database Systems for Advanced Applications | Conference |
| The impact of columnar file formats on SQL-on-hadoop engine performance: A study on ORC and Parquet | 2019 | Concurrency and Computation: Practice and Experience | Journal |
| Working with NoSQL Alternatives | 2018 | In Cloud Data Design, Orchestration, and Management Using Microsoft Azure | Conference |
| Evaluation of relational and NoSQL approaches for patient cohort identification from heterogeneous data sources | 2017 | IEEE International Conference on Bioinformatics and Biomedicine (BIBM) | Conference |
| Comparison of NoSQL Database and Traditional Database-An emphatic analysis | 2018 | International Journal on Informatics Visualization | Journal |
| Performance Comparison of Two Database Management Systems MySQL vs MongoDB | 2018 | Other | Other |
| The Comparison of Processing Efficiency of Spatial Data for PostGIS and MongoDB Databases | 2019 | In International Conference: Beyond Databases, Architectures and Structures | Conference |
| Geospatial big data: challenges and opportunities | 2015 | Big Data Research | Journal |
| Considerations on geospatial big data | 2016 | IOP Conf. Series: Earth and Environmental Science | Conference |
| Using convolutional networks and satellite imagery to identify patterns in urban environments at a large scale | 2017 | In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining | Conference |
| Report on the Seventh International Workshop on Location and the Web (LocWeb 2017) | 2017 | IEEE International Conference on Big Data | Conference |
| Internet of things as a methodological concept | 2013 | Fourth International Conference on Computing for Geospatial Research and Application | Conference |
| Twitter under crisis: Can we trust what we RT? | 2010 | In Proceedings of the first workshop on social media analytics, | Conference |
| Speeding up the clock in remote sensing: identifying the ‘black spots’ in exposure dynamics by capitalizing on the full spectrum of joint high spatial and temporal resolution | 2017 | Natural Hazards | Journal |
| Geospatial Big Data and archaeology: Prospects and problems too great to ignore | 2017 | Journal of Archaeological Science | Journal |
| How Poor Is the ‘Poor Man’s Search Engine’? | 2018 | in International Conference: Beyond Databases, Architectures and Structures | Conference |
| Performance aspects of migrating a web application from a relational to a NoSQL database | 2015 | In International Conference: Beyond Databases, Architectures and Structures | Conference |
| MySQL and NoSQL database comparison for IoT application | 2016 | IEEE International Conference on Advances in Computer Applications (ICACA), | Conference |
| A proposed performance evaluation of NoSQL databases in the field of IoT | 2018 | 8th International Conference on Computer Science and Information Technology (CSIT) | Conference |
| SQL or NoSQL? Contrasting approaches to the storage, manipulation and analysis of spatio-temporal online social network data | 2014 | International Conference on Computational Science and Its Applications | Conference |
| Comparative analysis of relational and non-relational databases in the context of performance in web applications | 2017 | International Conference: Beyond Databases, Architectures and Structures | Conference |
| Evaluation of XPath queries over XML documents using SparkSQL framework | 2017 | International Conference: Beyond Databases, Architectures and Structures, 2017 | Conference |
| The multi-model databases–a review | 2017 | International Conference: Beyond Databases, Architectures and Structures | Conference |
| 1.06 GIS Databases and NoSQL Databases | 2017 | Comprehensive Geographic Information Systems | Other |
| Geographic information systems and science | 2005 | Other | Other |
| Computational model for efficient processing of geofield queries | 2009 | Man-Machine Interactions, Springer | Other |
| A data model for heterogeneous data integration architecture | 2014 | International Conference: Beyond Databases, Architectures and Structures | Conference |
| Efficient storage of big-data for real-time gps applications | 2014 | Fourth International Conference on Big Data and Cloud Computing | Conference |
| An attempt to automate the simplification of building objects in multiresolution databases | 2015 | International Conference: Beyond Databases, Architectures and Structures | Conference |
| The extended structure of multi-resolution database, | 2014 | International Conference: Beyond Databases, Architectures and Structures | Conference |
| GISB: a benchmark for geographic map information extraction | 2015 | International Conference: Beyond Databases, Architectures and Structures | Conference |
| The importance of contextual topology in the process of harmonization of the spatial databases on example BDOT500 | 2016 | Baltic Geodetic Congress (BGC Geomatics) | Conference |
| A Big Data processing strategy for hybrid interpretation of flood embankment multisensor data | 2016 | Geology, Geophysics and Environment | Journal |
| Evaluation of relational and NoSQL database architectures to manage genomic annotations | 2016 | Journal of Biomedical Informatics | Journal |
| SQL or NoSQL? Which Is the Best Choice for Storing Big Spatio-Temporal Climate Data? | 2018 | International Conference on Conceptual Modeling | Conference |
| Mysql spatial and postgis–implementations of spatial data standards | 2011 | Electronic Journal of Polish Agricultural Universities (EJPAU) | Journal |
| Pro oracle spatial for oracle database 11 | 2008 | Dreamtech Press | Other |
| SQL versus NoSQL databases for geospatial applications | 2017 | IEEE International Conference on Big Data (Big Data) | Conference |
| Exploring the Design Needs for the New Database Era | 2018 | Enterprise, Business-Process and Information Systems Modeling | Other |
| Forensic investigation framework for the document store NoSQL DBMS: MongoDB as a case study | 2016 | Digital Investigation | Journal |
| Performance Analysis of Not Only SQL Semi-Stream Join Using MongoDB for Real-Time Data Warehousing | 2019 | IEEE Acces | Journal |
| Security issues in nosql databases | 2011 | IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications | Conference |
| Cdport: A portability framework for nosql datastores | 2015 | Arabian Journal for Science and Engineering | Journal |
| SeCloudDB: A Unified API for Secure SQL and NoSQL Cloud Databases | 2019 | In Proceedings of the 2019 3rd International Conference on Cloud and Big Data Computing, | Conference |
| A Survey on Approaches for Interoperability and Portability of Cloud Computing Services | 2014 | the proceedings of the 4th International Conference on Cloud Computing and Services Science (CLOSER 2014) | Conference |
| Design patterns to enable data portability between clouds’ databases | 2012 | 12th International Conference on Computational Science and Its Applications | Conference |
| Cdport: A framework of data portability in cloud platforms | 2014 | Proceedings of the 16th International Conference on Information Integration and Web-based Applications & Services | Conference |
| Internet of things data storage infrastructure in the cloud using NoSQL databases | 2017 | EEE Latin America Transactions | Journal |
| Data management in cloud environments: NoSQL and NewSQL data stores | 2013 | Journal of Cloud Computing: Advances, Systems and Applications | Journal |
| Cloud computing—The business perspective | 2011 | Decision Support System | Journal |
| The cloudmdsql multistore system | 2016 | Proceedings of the 2016 International Conference on Management of Data | Conference |
| A semantic interoperability framework for cloud platform as a service | 2011 | IEEE Third International Conference on Cloud Computing Technology and Science | Conference |
| Cloud Computing Interoperability Approaches-Possibilities and Challenges | 2012 | Local Proceedings of the Fifth Balkan Conference in Informatics | Conference |
| Cloud computing interoperability: the state of play | 2011 | IEEE Third International Conference on Cloud Computing Technology and Science | Conference |
| UML model of a standard API for cloud computing application development | 2019 | 9th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE) | Conference |
| Experiences in building a mOSAIC of clouds | 2013 | Journal of Cloud Computing, Advances, Systems and Applications | Journal |
| Supporting the development and operation of multi-cloud applications: The modaclouds approach | 2013 | 15th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing | Conference |
| Portability and interoperability between clouds: challenges and case study | 2011 | European Conference on a Service-Based Internet | Conference |
| Simplifying MapReduce data processing | 2013 | International Journal of Computational Science and Engineering | Journal |
| A common API for delivering services over multi-vendor cloud resources | 2013 | Journal of Systems and Software | Journal |
| A survey of large scale data management approaches in cloud environments | 2011 | IEEE Communications Surveys and Tutorials | Conference |
| Relational cloud: A database-as-a-service for the cloud | 2011 | MIT | Journal |
| Database as a service (DBaaS) | 2010 | IEEE 26th International Conference on Data Engineering (ICDE 2010) | Conference |
| Private table database virtualization for dbaas | 2011 | Fourth IEEE International Conference on Utility and Cloud Computing | Conference |
| Performance Comparisons | NoSQL Databases |
|---|---|
| Relational Databases | [3,5,6,7,8,9,10,12,13,14,16,17,20,25,27,28,30,37,38,47,56,108] |
| Properties | Oracle RDBMS | MongoDB |
|---|---|---|
| ACID | X | |
| BASE | X | |
| Large Data Scalability | X | |
| Data Sharding | X | X |
| Partitioning | X | X |
| Replication | X | X |
| Distributed | X | X |
| Vertical/Horizontal | Vertical | Horizontal |
| Schema | Rigid Schema | Schema-less/dynamic schema |
| Full SQL | X | |
| Indexing | X | X |
| Uni-Code Characters | X | X |
| Built-in MapReduce | X | |
| Maximum Value Size | 4 KB | 16 MB |
| Sharing Support | X | |
| Open Source/Licensed | Licensed | Open Source |
| PID | Discussion/Performance Evaluations/Comparisons/Characteristics of SQL & NoSQL Databases |
|---|---|
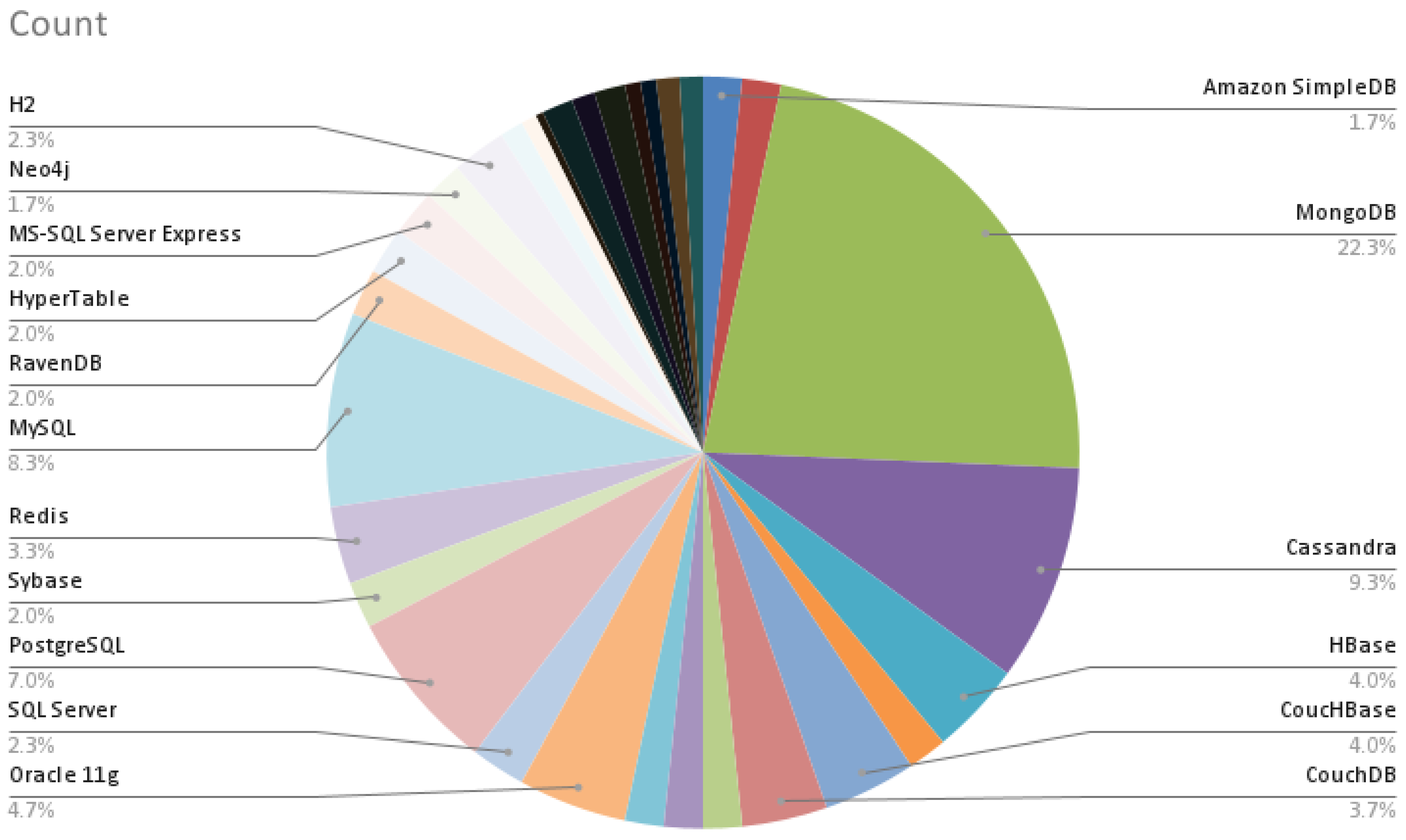
| [11] | Google Big Table, Amazon SimpleDB, Apache CouchDB, MongoDB, Cassandra, Hbase |
| [13] | Cassandra, MongoDB, Couchbase |
| [14] | SQL, Cassandra, CouchDB, DynamoDB, MongoDB, GraphDB |
| [15] | MySQL, Oracle, SQL Server, PostgreSQL, Sybase, MongoDB, Redis |
| [23] | MongoDB |
| [24] | MySQL, MongoDB |
| [25] | SQL Server, MongoDB |
| [26] | MongoDB, MySQL |
| [27] | MongoDB, Oracle |
| [28] | MongoDB, RavenDB, CouchDB, Cassandra, HyperTable, CouchBase, MS-SQL Server Express |
| [29] | Oracle, Neo4j |
| [30] | Neo4j, Oracle |
| [31] | Oracle, MongoDB |
| [32] | MySQL, Neo4j |
| [34] | MongoDB, MySQL |
| [36] | SQL Server, In-memory TPC databases via HammerDB |
| [37] | MongoDB, MySQL |
| [38] | PostgreSQL, MongoDB, Neo4j |
| [39] | SQL and NoSQL databases |
| [40] | Oracle 12c, JSON, BSON, OSON |
| [42] | Open Source Graph Databases |
| [43] | PostgreSQL, H2 (Open Source lightweight Java RDMS), HBase, JanusGraph |
| [44] | Oracle 11g, MongoDB |
| [46] | Neo4j, MySQL |
| [47] | MongoDB, PostgreSQL |
| [48] | MongoDB, MySQL, VoltDB for IoT data used in sensor |
| [49] | MySQL, MongoDB |
| [50] | SQL to NoSQL MongoDB Migration |
| [51] | MySQL, MongoDB |
| [52] | MySQL, MongoDB |
| [54] | MySQL, MongoDB |
| [55] | MySQL, MongoDB |
| [56] | MySQL to MongoDB transformation |
| [58] | MySQL (JDBC driver), Cassandra (Simba’s Cassandra JDBC and ODBC) |
| [59] | MySQL, MongoDB |
| [60] | CouchBase, RethinkDB, MongoDB |
| [61] | MongoDB and Oracle NoSQL |
| [62] | Dynamo (Amazon), Voldmart (LinkedIn), Redis, BerkeleyDB, Riak, MongoDB, CouchDB, SimpleDB (Amazon), DynamoDB, Neo4j, InfoGrid, Sones GraphDB, Infinite Graph |
| [63] | MongoDB, Oracle |
| [64] | CAP, ACID, BASE |
| [65] | SQL and NoSQL databases characteristics |
| [67] | CAP, ACID, BASE, NoSQL database categories discussions |
| [69] | Literature Review on Database Design Testing Techniques (SQL & NoSQL databases) |
| [71] | ACID Model Databases |
| [72] | NoSQL BASE Analysis |
| [73] | SQL & NoSQL Availability, Consistency and Efficiency properties |
| [74] | SQL ACID & NoSQL BASE properties are discussed |
| [75] | MySQL, Hbase databases |
| [76] | NoSQL DBMSs, CAP, Aerospike, Cassandra, CouchDB, MongoDB |
| [77] | In memory databases: MongoDB, Redis, Memcached, Cassandra, H2 |
| [82] | SQL to NoSQL databases over Hadoop and spark cloud |
| [83] | PostgreSQL, MongoDB, MariaDB, Hbase Hadoop based analysis |
| [84] | SQL on Hadoop, Columnar file format, Hive, SparkSQL |
| [86] | MySQL, MongoDB, Cassandra, 8 de-identified patients datasets |
| [96] | MySQL, MongoDB, Cassandra |
| [97] | SQL and NoSQL databases characteristics, IoT, MySQL & MongoDB comparisons |
| [98] | BASE, IoT, RDBMS, MongoDB, Cassandra |
| [99] | PostGIS and MongoDB comparisons for spatial data |
| [100] | PostgreSQL, Oracle, MongoDB in cloud platform for spatial data |
| [101] | PostgreSQL, MongoDB, Cassandra for web applications |
| [103] | ArangoDB, OrientDB, Couchbase server characteristics & comparisons, ACID, BASE |
| [104] | Various databases models for geospatial data |
| [105] | Heterogeneous data integration models and architectures have been investigated |
| [108] | Efficient storage data model for GPS application |
| [110] | Spatial databases, MRDB, Topographic database and WGS have been discussed |
| [113] | GISB: Geo-information extraction framework |
| [114] | Spatial databases inconsistencies |
| [115] | Big geospatial data processing strategies |
| [116] | MySQL, PostgreSQL, MongoDB, DbSNP database for genomic annotations. |
| [117] | Investigated general data management platform for high-dimensional spatio-temporal data |
| [118] | Spatial data standards: OGC OpenGIS and SQL/MM – PostgreSQL +PostGIS & MySQL Spatial |
| [119] | Oracle 11g database for spatial data |
| [120] | Azure SQL database, PostGIS, MongoDB, Azure DocumentDB, DBaaS for spatial data |
| [121] | ACID, BASE, Database modeling & Design, SQL & NoSQL databases characteristics |
| [122] | NoSQL MongoDB Case study |
| [123] | Synthetic dataset, NoSQL MongoDB (semi-structured & structured data) |
| [124] | Security features of MongoDB and Cassandra |
| [125] | Cloud data portability framework (Unified APIs) for various NoSQL databases |
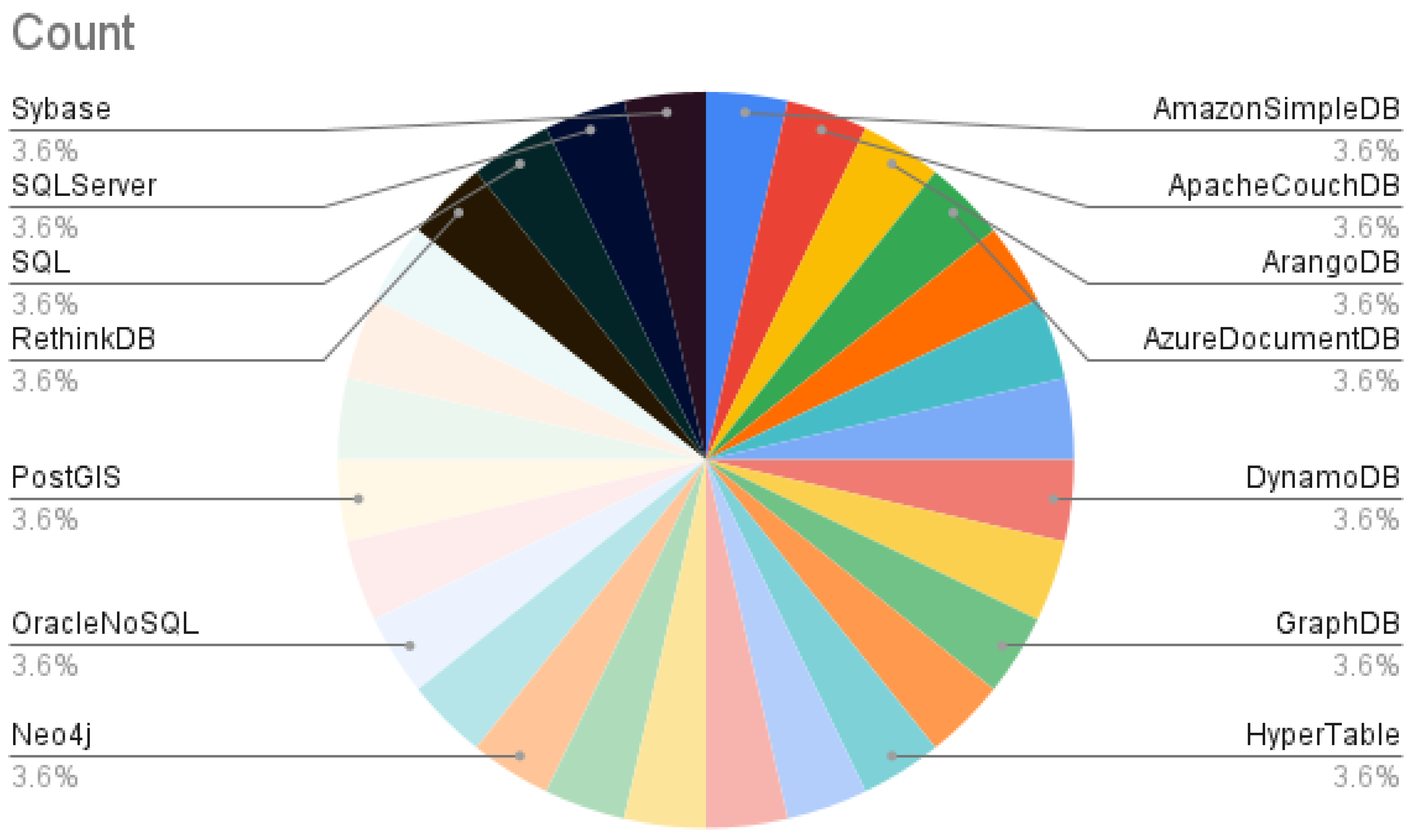
| DBMSID | DBMS-Name |
|---|---|
| 0 | AmazonSimpleDB |
| 1 | ApacheCouchDB |
| 2 | ArangoDB |
| 3 | AzureDocumentDB |
| 4 | AzureSQLdatabase |
| 5 | Cassandra |
| 6 | CoucHBase |
| 7 | CouchDB |
| 8 | DynamoDB |
| 9 | GoogleBigTable |
| 10 | GraphDB |
| 11 | H2 |
| 12 | HBase |
| 13 | HyperTable |
| 14 | JanusGraph |
| 15 | MS-SQLServerExpress |
| 16 | MariaDB |
| 17 | Memcached |
| 18 | MongoDB |
| 19 | MySQL |
| 20 | Neo4j |
| 21 | Oracle11g |
| 22 | OracleNoSQL |
| 23 | OrientDB |
| 24 | PostGIS |
| 25 | PostgreSQL |
| 26 | RavenDB |
| 27 | Redis |
| 28 | RethinkDB |
| 29 | SQL |
| 30 | SQLServer |
| 31 | Sybase |
| DBMSID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | Predicted Result |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.05 | 0.05 | 0.01 | 0.01 | 0.02 | 0.10 | 0.05 | 0.05 | 0.03 | 0.08 | 0.03 | 0.01 | 0.07 | 0.04 | 0.00 | 0.04 | 0.00 | 0.02 | 0.21 | 0.01 | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.01 | MongoDB |
| 1 | 0.05 | 0.05 | 0.01 | 0.01 | 0.01 | 0.10 | 0.05 | 0.05 | 0.03 | 0.07 | 0.03 | 0.01 | 0.07 | 0.03 | 0.00 | 0.04 | 0.00 | 0.02 | 0.21 | 0.01 | 0.00 | 0.00 | 0.00 | 0.05 | 0.03 | 0.01 | MongoDB |
| 2 | 0.05 | 0.05 | 0.01 | 0.01 | 0.01 | 0.10 | 0.05 | 0.05 | 0.03 | 0.06 | 0.03 | 0.01 | 0.06 | 0.03 | 0.01 | 0.03 | 0.00 | 0.02 | 0.20 | 0.01 | 0.00 | 0.00 | 0.00 | 0.07 | 0.03 | 0.01 | MongoDB |
| 3 | 0.05 | 0.05 | 0.01 | 0.01 | 0.01 | 0.10 | 0.05 | 0.05 | 0.02 | 0.06 | 0.03 | 0.01 | 0.06 | 0.03 | 0.01 | 0.03 | 0.00 | 0.02 | 0.20 | 0.01 | 0.00 | 0.00 | 0.00 | 0.08 | 0.03 | 0.01 | MongoDB |
| 4 | 0.05 | 0.05 | 0.01 | 0.01 | 0.01 | 0.10 | 0.05 | 0.05 | 0.02 | 0.05 | 0.02 | 0.01 | 0.06 | 0.03 | 0.01 | 0.03 | 0.00 | 0.01 | 0.20 | 0.01 | 0.00 | 0.00 | 0.00 | 0.08 | 0.03 | 0.01 | MongoDB |
| 5 | 0.04 | 0.04 | 0.01 | 0.01 | 0.01 | 0.11 | 0.05 | 0.05 | 0.02 | 0.05 | 0.02 | 0.02 | 0.06 | 0.03 | 0.01 | 0.03 | 0.00 | 0.02 | 0.20 | 0.02 | 0.00 | 0.00 | 0.00 | 0.06 | 0.03 | 0.02 | MongoDB |
| 6 | 0.04 | 0.04 | 0.01 | 0.01 | 0.01 | 0.11 | 0.05 | 0.05 | 0.02 | 0.04 | 0.02 | 0.02 | 0.06 | 0.03 | 0.01 | 0.03 | 0.00 | 0.02 | 0.21 | 0.02 | 0.00 | 0.00 | 0.00 | 0.04 | 0.03 | 0.02 | MongoDB |
| 7 | 0.04 | 0.04 | 0.01 | 0.01 | 0.01 | 0.11 | 0.05 | 0.05 | 0.02 | 0.04 | 0.02 | 0.02 | 0.06 | 0.03 | 0.01 | 0.03 | 0.00 | 0.02 | 0.21 | 0.03 | 0.00 | 0.00 | 0.00 | 0.02 | 0.03 | 0.03 | MongoDB |
| 8 | 0.04 | 0.04 | 0.01 | 0.01 | 0.01 | 0.12 | 0.05 | 0.05 | 0.02 | 0.03 | 0.02 | 0.02 | 0.05 | 0.03 | 0.01 | 0.03 | 0.00 | 0.02 | 0.22 | 0.04 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.04 | MongoDB |
| 9 | 0.04 | 0.03 | 0.01 | 0.01 | 0.01 | 0.12 | 0.05 | 0.05 | 0.02 | 0.03 | 0.02 | 0.02 | 0.05 | 0.03 | 0.01 | 0.03 | 0.01 | 0.02 | 0.22 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.04 | MongoDB |
| 10 | 0.03 | 0.03 | 0.01 | 0.01 | 0.01 | 0.12 | 0.05 | 0.05 | 0.02 | 0.03 | 0.02 | 0.02 | 0.05 | 0.03 | 0.01 | 0.03 | 0.01 | 0.02 | 0.22 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.05 | MongoDB |
| 11 | 0.03 | 0.03 | 0.01 | 0.01 | 0.01 | 0.12 | 0.05 | 0.05 | 0.02 | 0.02 | 0.02 | 0.03 | 0.05 | 0.03 | 0.01 | 0.03 | 0.01 | 0.02 | 0.22 | 0.06 | 0.00 | 0.01 | 0.00 | 0.00 | 0.02 | 0.06 | MongoDB |
| 12 | 0.03 | 0.02 | 0.01 | 0.01 | 0.01 | 0.12 | 0.05 | 0.04 | 0.02 | 0.02 | 0.02 | 0.03 | 0.05 | 0.03 | 0.01 | 0.03 | 0.01 | 0.02 | 0.23 | 0.07 | 0.00 | 0.01 | 0.00 | 0.00 | 0.02 | 0.07 | MongoDB |
| 13 | 0.02 | 0.02 | 0.01 | 0.01 | 0.01 | 0.12 | 0.04 | 0.04 | 0.02 | 0.02 | 0.02 | 0.03 | 0.05 | 0.02 | 0.01 | 0.03 | 0.01 | 0.02 | 0.23 | 0.08 | 0.00 | 0.02 | 0.00 | 0.00 | 0.02 | 0.07 | MongoDB |
| 14 | 0.02 | 0.02 | 0.01 | 0.01 | 0.01 | 0.11 | 0.04 | 0.04 | 0.02 | 0.01 | 0.02 | 0.03 | 0.04 | 0.02 | 0.01 | 0.02 | 0.01 | 0.01 | 0.23 | 0.09 | 0.00 | 0.02 | 0.00 | 0.00 | 0.02 | 0.08 | MongoDB |
| 15 | 0.02 | 0.01 | 0.01 | 0.01 | 0.01 | 0.11 | 0.04 | 0.04 | 0.02 | 0.01 | 0.02 | 0.03 | 0.04 | 0.02 | 0.01 | 0.02 | 0.01 | 0.01 | 0.23 | 0.10 | 0.00 | 0.03 | 0.00 | 0.00 | 0.01 | 0.09 | MongoDB |
| 16 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.11 | 0.04 | 0.04 | 0.02 | 0.01 | 0.02 | 0.03 | 0.04 | 0.02 | 0.01 | 0.02 | 0.01 | 0.01 | 0.22 | 0.11 | 0.01 | 0.04 | 0.00 | 0.00 | 0.01 | 0.09 | MongoDB |
| 17 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.10 | 0.04 | 0.04 | 0.02 | 0.01 | 0.01 | 0.03 | 0.04 | 0.02 | 0.01 | 0.02 | 0.02 | 0.01 | 0.22 | 0.11 | 0.02 | 0.05 | 0.00 | 0.00 | 0.01 | 0.10 | MongoDB |
| 18 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.99 | 0.00 | 0.00 | 0.00 | OracleNoSQL |
| 19 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.09 | 0.04 | 0.03 | 0.01 | 0.01 | 0.01 | 0.03 | 0.03 | 0.02 | 0.01 | 0.02 | 0.02 | 0.01 | 0.21 | 0.12 | 0.04 | 0.07 | 0.00 | 0.00 | 0.01 | 0.10 | MongoDB |
| 20 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 | 0.08 | 0.03 | 0.03 | 0.01 | 0.00 | 0.01 | 0.03 | 0.03 | 0.01 | 0.01 | 0.01 | 0.02 | 0.01 | 0.21 | 0.12 | 0.06 | 0.08 | 0.00 | 0.00 | 0.01 | 0.10 | MongoDB |
| 21 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 | 0.08 | 0.03 | 0.03 | 0.01 | 0.00 | 0.01 | 0.03 | 0.03 | 0.01 | 0.01 | 0.01 | 0.02 | 0.01 | 0.20 | 0.12 | 0.06 | 0.09 | 0.00 | 0.00 | 0.01 | 0.10 | MongoDB |
| 22 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 | 0.07 | 0.03 | 0.03 | 0.01 | 0.00 | 0.01 | 0.02 | 0.03 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.21 | 0.12 | 0.06 | 0.10 | 0.00 | 0.00 | 0.01 | 0.09 | MongoDB |
| 23 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 | 0.07 | 0.03 | 0.03 | 0.01 | 0.00 | 0.01 | 0.02 | 0.03 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.21 | 0.12 | 0.05 | 0.10 | 0.00 | 0.00 | 0.01 | 0.09 | MongoDB |
| 24 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 | 0.07 | 0.03 | 0.03 | 0.01 | 0.00 | 0.01 | 0.02 | 0.03 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.22 | 0.12 | 0.03 | 0.11 | 0.00 | 0.00 | 0.00 | 0.09 | MongoDB |
| 25 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 | 0.07 | 0.03 | 0.02 | 0.01 | 0.00 | 0.01 | 0.02 | 0.03 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.22 | 0.11 | 0.02 | 0.11 | 0.00 | 0.00 | 0.00 | 0.09 | MongoDB |
| DBMSID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | Predicted Result |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.02 | 0.00 | 0.03 | 0.03 | 0.03 | 0.04 | 0.04 | 0.03 | GoogleBigTable |
| 1 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.04 | 0.04 | 0.03 | GoogleBigTable |
| 2 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.04 | 0.04 | 0.03 | CouchDB |
| 3 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.03 | 0.04 | 0.04 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.04 | CouchDB |
| 4 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | CouchDB |
| 5 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | CouchDB |
| 6 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.01 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 7 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.04 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 8 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 9 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 10 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.01 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 11 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.01 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 12 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.01 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 13 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.01 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 14 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 15 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 16 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 17 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 18 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 19 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 20 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 21 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 22 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 23 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 24 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
| 25 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.01 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 | 0.03 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 | 0.02 | 0.03 | 0.04 | 0.03 | 0.03 | 0.03 | 0.04 | PostgreSQL |
References
- Siddiqa, A.; Hashem, I.A.T.; Yaqoob, I.; Marjani, M.; Shamshirband, S.; Gani, A.; Nasaruddin, F. A survey of big data management: Taxonomy and state-of-the-art. J. Netw. Comput. Appl. 2016, 71, 151–166. [Google Scholar] [CrossRef]
- Kong, X.; Shi, Y.; Yu, S.; Liu, J.; Xia, F. Academic social networks: Modeling, analysis, mining and applications. J. Netw. Comput. Appl. 2019, 132, 86–103. [Google Scholar] [CrossRef]
- Ordonez, C. Optimization of Linear Recursive Queries in SQL. IEEE Trans. Knowl. Data Eng. 2009, 22, 264–277. [Google Scholar] [CrossRef]
- Obasanjo, D. Building scalable Databases: Denormalization, the NoSQL movement and Digg. 2009. [Google Scholar]
- Strozzi, C. NoSQL—A Relational Database Management System. 2007–2010. Available online: http//www.strozzi.it/cgi-bin/CSA/tw7/I/en_US/nosql/Home%20Page (accessed on 13 November 2019).
- George, S. NoSQL—NOT ONLY SQL. Int. J. Enterp. Comput. Bus. Syst. 2013, 2. [Google Scholar]
- Brewer, E.A. Towards robust distributed systems. In PODC; Inktomi: Foster City, CA, USA, 2000; Volume 7. [Google Scholar]
- Díaz, M.; Martín, C.; Rubio, B. State-of-the-art, challenges, and open issues in the integration of Internet of things and cloud computing. J. Netw. Comput. Appl. 2016, 67, 99–117. [Google Scholar] [CrossRef]
- Rao, B.T. A Study on Data Storage Security Issues in Cloud Computing. Procedia Comput. Sci. 2016, 92, 128–135. [Google Scholar]
- Mansouri, Y.; Prokhorenko, V.; Babar, M.A. An automated implementation of hybrid cloud for performance evaluation of distributed databases. J. Netw. Comput. Appl. 2020, 167, 102740. [Google Scholar] [CrossRef]
- Ravi, K.; Khandelwal, Y.; Krishna, B.S.; Ravi, V. Analytics in/for cloud-an interdependence: A review. J. Netw. Comput. Appl. 2018, 102, 17–37. [Google Scholar] [CrossRef]
- Wiese, L.; Waage, T.; Brenner, M. CloudDBGuard: A framework for encrypted data storage in NoSQL wide column stores. Data Knowl. Eng. 2019, 126, 101732. [Google Scholar] [CrossRef]
- Ribas, M.; Furtado, C.; de Souza, J.N.; Barroso, G.C.; Moura, A.; Lima, A.S.; Sousa, F.R. A Petri net-based decision-making framework for assessing cloud services adoption: The use of spot instances for cost reduction. J. Netw. Comput. Appl. 2015, 57, 102–118. [Google Scholar] [CrossRef]
- Kumari, A.; Tanwar, S.; Tyagi, S.; Kumar, N.; Parizi, R.M.; Choo, K.-K.R. Fog data analytics: A taxonomy and process model. J. Netw. Comput. Appl. 2019, 128, 90–104. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Keele University: Keele, UK, 2007. [Google Scholar]
- Dyba, T.; Kitchenham, B.A.; Jorgensen, M. Evidence-based software engineering for practitioners. IEEE Softw. 2005, 22, 58–65. [Google Scholar] [CrossRef]
- Hosseinzadeh, S.; Rauti, S.; Laurén, S.; Mäkelä, J.-M.; Holvitie, J.; Hyrynsalmi, S.; Leppänen, V. Diversification and obfuscation techniques for software security: A systematic literature review. Inf. Softw. Technol. 2018, 104, 72–93. [Google Scholar] [CrossRef]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Badampudi, D.; Wohlin, C.; Petersen, K. Experiences from using snowballing and Database searches in systematic literature studies. In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering, Nanjing, China, 27–29 April 2015; p. 17. [Google Scholar]
- Petersen, K.; Gencel, C. Worldviews, research methods, and their relationship to validity in empirical software engineering research. In Proceedings of the 2013 Joint Conference of the 23rd International Workshop on Software Measurement and the 8th International Conference on Software Process and Product Measurement, Ankara, Turkey, 23–26 October 2013; pp. 81–89. [Google Scholar]
- Maxwell, J. Understanding and validity in qualitative research. Harv. Educ. Rev. 1992, 62, 279–301. [Google Scholar] [CrossRef]
- Alsolai, H.; Roper, M. A systematic literature review of machine learning techniques for software maintainability prediction. Inf. Softw. Technol. 2020, 119, 106214. [Google Scholar] [CrossRef]
- Rodrigues, M.; Santos, M.Y.; Bernardino, J. Big data processing tools: An experimental performance evaluation. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1297. [Google Scholar] [CrossRef]
- Hou, B.; Qian, K.; Li, L.; Shi, Y.; Tao, L.; Liu, J. MongoDB NoSQL injection analysis and detection. In Proceedings of the 2016 IEEE 3rd International Conference on Cyber Security and Cloud Computing (CSCloud), Beijing, China, 25–27 June 2016; pp. 75–78. [Google Scholar]
- Padhy, R.P.; Patra, M.R.; Satapathy, S.C. RDBMS to NoSQL: Reviewing some next-generation non-relational Database’s. Int. J. Adv. Eng. Sci. Technol. 2011, 11, 15–30. [Google Scholar]
- Győrödi, C.; Győrödi, R.; Pecherle, G.; Olah, A. A comparative study: MongoDB vs MySQL. In Proceedings of the 2015 13th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 11–12 June 2015; pp. 1–6. [Google Scholar]
- Băzăr, C.; Iosif, C.S. The transition from rdbms to nosql. a comparative analysis of three popular non-relational solutions: Cassandra, mongodb and couchbase. Database Syst. J. 2014, 5, 49–59. [Google Scholar]
- Mukherjee, S. The Battle between NoSQL Databases and RDBMS; University of the Cumberlands: Williamsburg, KY, USA, 2019. [Google Scholar]
- Chopade, R.; Pachghare, V.K. Ten years of critical review on database forensics research. Digit. Investig. 2019, 29, 180–197. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, P. A systematic review of systematic review process research in software engineering. Inf. Softw. Technol. 2013, 55, 2049–2075. [Google Scholar] [CrossRef]
- Imam, A.A.; Basri, S.; Ahmad, R.; González-Aparicio, M.T. Literature Review on Database Design Testing Techniques. In Proceedings of the Computer Science Online Conference, Faro, Portugal; 2019; pp. 1–13. [Google Scholar]
- Han, J.; Haihong, E.; Le, G.; Du, J. Survey on NoSQL Database. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Port Elizabeth, South Africa, 26–28 October 2011; pp. 363–366. [Google Scholar]
- Stonebraker, M. SQL Databases v. NoSQL Databases. Commun. ACM 2012, 53, 10–11. [Google Scholar] [CrossRef]
- Parker, Z.; Poe, S.; Vrbsky, S.V. Comparing nosql mongodb to an sql db. In Proceedings of the 51st ACM Southeast Conference, Savannah, GA, USA, 4–6 April 2013; p. 5. [Google Scholar]
- Wei-Ping, Z.; Ming-Xin, L.I.; Huan, C. Using MongoDB to implement textbook management system instead of MySQL. In Proceedings of the 2011 IEEE 3rd International Conference on Communication Software and Networks, Xian, China, 27–29 May 2011; pp. 303–305. [Google Scholar]
- Boicea, A.; Radulescu, F.; Agapin, L.I. MongoDB vs. Oracle-Database comparison. In Proceedings of the 2012 Third International Conference on Emerging Intelligent Data and Web Technologies, Bucharest, Romania, 19–21 September 2012; pp. 330–335. [Google Scholar]
- Li, Y.; Manoharan, S. A performance comparison of SQL and NoSQL Databases. In Proceedings of the 2013 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 27–29 August 2013; pp. 15–19. [Google Scholar]
- Khan, W.; Ahmad, W.; Luo, B.; Ahmed, E. SQL Database with physical Database tuning technique and NoSQL graph Database comparisons. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar] [CrossRef]
- Khan, W.; Shahzad, W. Predictive Performance Comparison Analysis of Relational & NoSQL Graph Databases. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 523–530. [Google Scholar]
- Faraj, A.; Rashid, B.; Shareef, T. Comparative study of relational and non-relations Database performances using Oracle and MongoDB systems. J. Impact Factor 2014, 5, 11–22. [Google Scholar]
- Vicknair, C.; Macias, M.; Zhao, Z.; Nan, X.; Chen, Y.; Wilkins, D. A comparison of a graph Database and a relational Database: A data provenance perspective. In Proceedings of the 48th annual Southeast regional conference, Oxfrod, MS, USA, 15–17 April 2010; p. 42. [Google Scholar]
- Khan, S.; Mane, V. SQL support over MongoDB using metadata. Int. J. Sci. Res. Publ. 2013, 3, 1–5. [Google Scholar]
- Kumar, L.; Rajawat, S.; Joshi, K. Comparative analysis of nosql (mongodb) with mysql Database. Int. J. Mod. Trends Eng. Res. 2015, 2, 120–127. [Google Scholar]
- Aghi, R.; Mehta, S.; Chauhan, R.; Chaudhary, S.; Bohra, N. A comprehensive comparison of SQL and MongoDB Databases. Int. J. Sci. Res. Publ. 2015, 5, 1–3. [Google Scholar]
- Ayub, M.B.; Ali, N. Performance comparison of in-memory and disk-based Databases using transaction processing performance council (TPC) benchmarking. J. Internet Inf. Syst. 2018, 8, 1–8. [Google Scholar] [CrossRef]
- Deari, R.; Zenuni, X.; Ajdari, J.; Ismaili, F.; Raufi, B. Analysis and Comparison of Document-Based Databases with Sql Relational Databases: Mongodb vs Mysql. In Proceedings of the International Conference on Information Technologies (InfoTech-2018), Varna, Bulgaria, 20–21 September 2018. [Google Scholar]
- Sharma, M.; Sharma, V.D.; Bundele, M.M. Performance Analysis of RDBMS and No SQL Databases: PostgreSQL, MongoDB and Neo4j. In Proceedings of the 2018 3rd International Conference and Workshops on Recent Advances and Innovations in Engineering (ICRAIE), Rajasthan, India, 22–25 November 2018; pp. 1–5. [Google Scholar]
- Čerešňák, R.; Kvet, M. Comparison of query performance in relational a non-relation Databases. Transp. Res. Procedia 2019, 40, 170–177. [Google Scholar] [CrossRef]
- Liu, Z.H.; Hammerschmidt, B.; McMahon, D.; Liu, Y.; Chang, H.J. Closing the functional and performance gap between SQL and NoSQL. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 227–238. [Google Scholar]
- Kim, H.-J.; Ko, E.-J.; Jeon, Y.-H.; Lee, K.-H. Migration from rdbms to column-oriented nosql: Lessons learned and open problems. In Proceedings of the 7th International Conference on Emerging Databases, Panevezys, Lithuania, 26–27 April 2018; pp. 25–33. [Google Scholar]
- McColl, R.C.; Ediger, D.; Poovey, J.; Campbell, D.; Bader, D.A. A performance evaluation of open source graph Databases. In Proceedings of the First Workshop on Parallel Programming for Analytics Applications, Orlando, FL, USA, 16 February 2014; pp. 11–18. [Google Scholar]
- Anikin, D.; Borisenko, O.; Nedumov, Y. Labeled Property Graphs: SQL or NoSQL? In Proceedings of the 2019 Ivannikov Memorial Workshop (IVMEM), Velikiy Novgorod, Russia, 13–14 September 2019; pp. 7–13. [Google Scholar]
- El Mouden, Z.A.; Jakimi, A.; Hajar, M.; Boutahar, M. Graph Schema Storage in SQL Object-Relational Database and NoSQL Document-Oriented Database: A Comparative Study. In Proceedings of the International Conference Europe Middle East & North Africa Information Systems and Technologies to Support Learning, Marrakech, Morocco, 21–23 November 2019; pp. 176–183. [Google Scholar]
- Rathika, V. Graph-Based Denormalization for Migrating Big Data from SQL Database to NoSQL Database. In Proceedings of the Intelligent Communication Technologies and Virtual Mobile Networks, Tirunelveli, India, 14–15 February 2019; pp. 546–556. [Google Scholar]
- Zhu, Y.; Yan, E.; Song, I. The use of a graph-based system to improve bibliographic information retrieval: System design, implementation, and evaluation. J. Assoc. Inf. Sci. Technol. 2017, 68, 480–490. [Google Scholar] [CrossRef]
- Jung, M.-G.; Youn, S.-A.; Bae, J.; Choi, Y.-L. A study on data input and output performance comparison of MongoDB and PostgreSQL in the big data environment. In Proceedings of the 2015 8th International Conference on Database Theory and Application (DTA), Jeju Island, Republic of Korea, 28–25 November 2015; pp. 14–17. [Google Scholar]
- Fatima, H.; Wasnik, K. Comparison of SQL, NoSQL and NewSQL Databases for internet of things. In Proceedings of the 2016 IEEE Bombay Section Symposium (IBSS), Maharashtra, India, 21–22 December 2016; pp. 1–6. [Google Scholar]
- Ray, P.P.; Dash, D.; De, D. Edge computing for Internet of Things: A survey, e-healthcare case study and future direction. J. Netw. Comput. Appl. 2019, 140, 1–22. [Google Scholar] [CrossRef]
- Singh, A. Data Migration from Relational Database to MongoDB. Glob. J. Comput. Sci. Technol. 2019. [Google Scholar]
- Zhao, G.; Huang, W.; Liang, S.; Tang, Y. Modeling MongoDB with relational model. In Proceedings of the 2013 Fourth International Conference on Emerging Intelligent Data and Web Technologies, Washington, DC, USA, 9–11 September 2013; pp. 115–121. [Google Scholar]
- Stanescu, L.; Brezovan, M.; Burdescu, D.D. Automatic mapping of MySQL Databases to NoSQL MongoDB. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; pp. 837–840. [Google Scholar]
- Yassine, F.; Awad, M.A. Migrating from SQL to NOSQL Database: Practices and Analysis. In Proceedings of the 2018 International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 18–19 November 2018; pp. 58–62. [Google Scholar]
- Liao, Y.-T.; Zhou, J.; Lu, C.-H.; Chen, S.-C.; Hsu, C.-H.; Chen, W.; Jiang, M.-F.; Chung, Y.-C. Data adapter for querying and transformation between SQL and NoSQL database. Futur. Gener. Comput. Syst. 2016, 65, 111–121. [Google Scholar] [CrossRef]
- Tomar, D.; Bhati, J.P.; Tomar, P.; Kaur, G. Migration of healthcare relational Database to NoSQL cloud Database for healthcare analytics and management. In Healthcare Data Analytics and Management; Elsevier: Amsterdam, The Netherlands, 2019; pp. 59–87. [Google Scholar]
- Rocha, L.; Vale, F.; Cirilo, E.; Barbosa, D.; Mourão, F. A Framework for Migrating Relational Datasets to NoSQL 1. Procedia Comput. Sci. 2015, 51, 2593–2602. [Google Scholar] [CrossRef]
- Ghule, S.; Vadali, R. Transformation of SQL system to NoSQL system and performing data analytics using SVM. In Proceedings of the 2017 International Conference on Trends in Electronics and Informatics (ICEI), Tirunelveli, India, 11–12 May 2017; pp. 883–887. [Google Scholar]
- Hsu, J.C.; Hsu, C.H.; Chen, S.C.; Chung, Y.C. Correlation Aware Technique for SQL to NoSQL Transformation. In Proceedings of the 2014 7th International Conference on Ubi-Media Computing and Workshops, Washington, DC, USA, 12–14 July 2014; pp. 43–46. [Google Scholar]
- Solanke, G.B.; Rajeswari, K. SQL to NoSQL transformation system using data adapter and analytics. In Proceedings of the 2017 IEEE International Conference on Technological Innovations in Communication, Control and Automation (TICCA), Chennai, India, 6 April 2017; pp. 59–63. [Google Scholar]
- Lawrence, R. Integration and virtualization of relational SQL and NoSQL systems including MySQL and MongoDB. In Proceedings of the 2014 International Conference on Computational Science and Computational Intelligence, Kunming, China, 15–16 November 2014; Volume 1, pp. 285–290. [Google Scholar]
- Pereira, D.A.; de Morais, W.O.; Pignaton de Freitas, E. NoSQL real-time Database performance comparison. Int. J. Parallel Emergent Distrib. Syst. 2018, 33, 144–156. [Google Scholar] [CrossRef]
- Anand, V.; Rao, C.M. MongoDB and Oracle NoSQL: A technical critique for design decisions. In Proceedings of the 2016 International Conference on Emerging Trends in Engineering, Technology and Science (ICETETS), Pudukkottai, India, 24–16 April 2016; pp. 1–4. [Google Scholar]
- Moniruzzaman, A.B.M.; Hossain, S.A. Nosql Database: New era of Databases for big data analytics-classification, characteristics and comparison. arXiv 2013, arXiv:1307.0191. [Google Scholar]
- Simanjuntak, H.T.A.; Simanjuntak, L.; Situmorang, G.; Saragih, A. Query Response Time Comparison NOSQLDB MONGODB with SQLDB Oracle. JUTI J. Ilm. Teknol. Inf. 2015, 13, 95–105. [Google Scholar] [CrossRef]
- Almeida, A.L.; Schettino, V.J.; Barbosa, T.J.R.; Freitas, P.F.; Guimarães, P.G.S.; Arbex, W.A. Relative scalability of NoSQL Databases for genotype data manipulation. Embrapa Gado Leite-Artig. Periódico Indexado 2018, 25, 93–100. [Google Scholar] [CrossRef]
- Cattell, R. Scalable SQL and NoSQL data stores. ACM SIGMOD Rec. 2011, 39, 12–27. [Google Scholar] [CrossRef]
- Lee, C.-H.; Zheng, Y.-L. SQL-to-NoSQL schema denormalization and migration: A study on content management systems. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 2022–2026. [Google Scholar]
- Meier, A.; Kaufmann, M.; Meier, A.; Kaufmann, M. Nosql databases. In SQL & NoSQL Databases: Models, Languages, Consistency Options and Architectures for Big Data Management; Springer Vieweg: Wiesbaden, Germany, 2019; pp. 201–218. [Google Scholar]
- Pokorný, J. Integration of Relational and NoSQL Databases. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Dong Hoi, Vietnam, 19–21 March 2018; pp. 35–45. [Google Scholar]
- Miranskyy, A.V.; Al-zanbouri, Z.; Godwin, D.; Bener, A.B. Database engines: Evolution of greenness. J. Softw. Evol. Process. 2017, 30, e1915. [Google Scholar] [CrossRef]
- Chapple, M. The Acid Model. Available online: http//Databases.about.com/od/specificproducts/a/acid.htm (accessed on 26 February 2020).
- Chandra, D.G. BASE analysis of NoSQL database. Futur. Gener. Comput. Syst. 2015, 52, 13–21. [Google Scholar] [CrossRef]
- Gonzalez-Aparicio, M.T.; Younas, M.; Tuya, J.; Casado, R. Evaluation of ACE properties of traditional SQL and NoSQL big data systems. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 1988–1995. [Google Scholar]
- Sun, H.; Xiao, B.; Wang, X.; Liu, X. Adaptive trade-off between consistency and performance in data replication. Softw. Pract. Exp. 2017, 47, 891–906. [Google Scholar] [CrossRef]
- Lee, C.-H.; Zheng, Y.-L. Automatic SQL-to-NoSQL schema transformation over the MySQL and HBase Databases. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics-Taiwan, Taipei, Taiwan, 6–8 June 2015; pp. 426–427. [Google Scholar]
- Kuzochkina, A.; Shirokopetleva, M.; Dudar, Z. Analyzing and Comparison of NoSQL DBMS. In Proceedings of the 2018 International Scientific-Practical Conference Problems of Infocommunications. Science and Technology (PIC S&T), Kharkov, Ukraine, 9–12 October 2018; pp. 560–564. [Google Scholar]
- Kabakus, A.T.; Kara, R. A performance evaluation of in-memory databases. J. King Saud Univ. Inf. Sci. 2017, 29, 520–525. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Pokorný, J. Database technologies in the world of big data. In Proceedings of the 16th International Conference on Computer Systems and Technologies, Dublin, Ireland, 25–26 June 2015; pp. 1–12. [Google Scholar]
- Yang, H.; Dasdan, A.; Hsiao, R.-L.; Parker, D.S. Map-reduce-merge: Simplified relational data processing on large clusters. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2007; pp. 1029–1040. [Google Scholar]
- Nykiel, T.; Potamias, M.; Mishra, C.; Kollios, G.; Koudas, N. MRShare: Sharing across multiple queries in MapReduce. Proc. VLDB Endow. 2010, 3, 494–505. [Google Scholar] [CrossRef]
- Lee, C.-H.; Shih, Z.-W. A Comparison of NoSQL and SQL Databases over the Hadoop and Spark Cloud Platforms using Machine Learning Algorithms. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taichung, Taiwan, 19–21 May 2018; pp. 1–2. [Google Scholar]
- Son, S.; Gil, M.-S.; Moon, Y.-S.; Won, H.-S. Performance Analysis of Hadoop-Based SQL and NoSQL for Processing Log Data. In Proceedings of the International Conference on Database Systems for Advanced Applications, Hanoi, Vietnam, 20–23 April 2015; pp. 293–299. [Google Scholar]
- Ivanov, T.; Pergolesi, M. The impact of columnar file formats on SQL-on-hadoop engine performance: A study on ORC and Parquet. Concurr. Comput. Pract. Exp. 2019, 32, e5523. [Google Scholar] [CrossRef]
- Diaz, F.; Freato, R. Working with NoSQL Alternatives. In Cloud Data Design, Orchestration, and Management Using Microsoft Azure; Springer: Cham, Switzerland, 2018; pp. 169–262. [Google Scholar]
- Zeng, N.; Zhang, G.-Q.; Li, X.; Cui, L. Evaluation of relational and NoSQL approaches for patient cohort identification from heterogeneous data sources. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1135–1140. [Google Scholar]
- Lee, J.-G.; Kang, M. Geospatial Big Data: Challenges and Opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, H.; Wang, C. Considerations on Geospatial Big Data. IOP Conf. Series: Earth Environ. Sci. 2016, 46, 012058. [Google Scholar] [CrossRef]
- Albert, A.; Kaur, J.; Gonzalez, M.C. Using Convolutional Networks and Satellite Imagery to Identify Patterns in Urban Environments at a Large Scale. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1357–1366. [Google Scholar]
- Ahlers, D.; Wilde, E. Report on the Seventh International Workshop on Location and the Web (LocWeb 2017). ACM SIGIR Forum 2017, 51, 52–57. [Google Scholar] [CrossRef]
- Bari, N.; Mani, G.; Berkovich, S. Internet of things as a methodological concept. In Proceedings of the 2013 Fourth International Conference on Computing for Geospatial Research and Application, San Jose, CA, USA, 22–24 July 2013; pp. 48–55. [Google Scholar]
- Mendoza, M.; Poblete, B.; Castillo, C. Twitter under crisis: Can we trust what we RT? In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25 July 2010; pp. 71–79. [Google Scholar]
- Aubrecht, C.; Meier, P.; Taubenböck, H. Speeding up the clock in remote sensing: Identifying the ‘black spots’ in exposure dynamics by capitalizing on the full spectrum of joint high spatial and temporal resolution. Nat. Hazards 2017, 86, 177–182. [Google Scholar] [CrossRef]
- McCoy, M.D. Geospatial Big Data and archaeology: Prospects and problems too great to ignore. J. Archaeol. Sci. 2017, 84, 74–94. [Google Scholar] [CrossRef]
- Burzańska, M.; Wiśniewski, P. How Poor Is the ‘Poor Man’s Search Engine’? In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Poznań, Poland, 18–20 September 2018; pp. 294–305. [Google Scholar]
- Harezlak, K.; Skowron, R. Performance aspects of migrating a web application from a relational to a NoSQL Database. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustroń, Poland, 26–29 May 2015; pp. 107–115. [Google Scholar]
- Rautmare, S.; Bhalerao, D.M. MySQL and NoSQL Database comparison for IoT application. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 235–238. [Google Scholar]
- Aya, A.-S.; Qattous, H.; Hijjawi, M. A proposed performance evaluation of NoSQL Databases in the field of IoT. In Proceedings of the 2018 8th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 11–12 July 2018; pp. 32–37. [Google Scholar]
- Bartoszewski, D.; Piorkowski, A.; Lupa, M. The comparison of processing efficiency of spatial data for PostGIS and MongoDB databases. In Proceedings of the Beyond Databases, Architectures and Structures. Paving the Road to Smart Data Processing and Analysis: 15th International Conference, BDAS 2019, Ustroń, Poland, 28–31 May 2019; pp. 291–302. [Google Scholar]
- Tear, A. SQL or NoSQL? In Contrasting approaches to the storage, manipulation and analysis of spatio-temporal online social network data. In Proceedings of the International Conference on Computational Science and Its Applications, Guimaraes, Portugal, 30 June–3 July 2014; pp. 221–236. [Google Scholar]
- Fraczek, K.; Plechawska-Wojcik, M. Comparative analysis of relational and non-relational Databases in the context of performance in web applications. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustroń, Poland, 30 May–2 June 2017; pp. 153–164. [Google Scholar]
- Hricov, R.; Šenk, A.; Kroha, P.; Valenta, M. Evaluation of XPath queries over XML documents using SparkSQL framework. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustroń, Poland, 30 May–2 June 2017; pp. 28–41. [Google Scholar]
- Płuciennik, E.; Zgorzałek, K. The multi-model Databases–A review. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustroń, Poland, 30 May–2 June 2017; pp. 141–152. [Google Scholar]
- Yue, P.; Tan, Z. 1.06 GIS Databases and NoSQL Databases. Compr. Geogr. Inf. Syst. 2017, 50. [Google Scholar]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Systems and Science; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Bajerski, P.; Kozielski, S. Computational model for efficient processing of geofield queries. In Man-Machine Interactions; Springer: Cham, Switzerland, 2009; pp. 573–583. [Google Scholar]
- Chromiak, M.; Stencel, K. A data model for heterogeneous data integration architecture. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustron, Poland, 27–30 May 2014; pp. 547–556. [Google Scholar]
- Akulakrishna, P.K.; Lakshmi, J.; Nandy, S.K. Efficient storage of big-data for real-time gps applications. In Proceedings of the 2014 IEEE Fourth International Conference on Big Data and Cloud Computing, Sydney, Australia, 3–5 December 2014; pp. 1–8. [Google Scholar]
- Lupa, M.; Kozioł, K.; Leśniak, A. An attempt to automate the simplification of building objects in multiresolution Databases. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustroń, Poland, 26–29 May 2015; pp. 448–459. [Google Scholar]
- Kozioł, K.; Lupa, M.; Krawczyk, A. The extended structure of multi-resolution Database. In Proceedings of the International Conference: Beyond Databases, Architectures and Structures, Ustron, Poland, 27–30 May 2014; pp. 435–443. [Google Scholar]
- Wyszomirski, M. Przegląd możliwości zastosowania wybranych baz danych NoSQL do zarządzania danymi przestrzennymi. Rocz. Geomatyki-Ann. Geomat. 2018, 16, 55–69. [Google Scholar]
- Czerepicki, A. Perspektywy zastosowania baz danych NoSQL w inteligentnych systemach transportowych. Pr. Nauk. Politech. Warsz. Transp. 2013, 92, 29–38. [Google Scholar]
- Martins, P.; Cecílio, J.; Abbasi, M.; Furtado, P. GISB: A benchmark for geographic map information extraction. In Beyond Databases, Architectures and Structures. Advanced Technologies for Data Mining and Knowledge Discovery; Springer: Cham, Switzerland, 2015; pp. 600–609. [Google Scholar]
- Inglot, A.; Koziol, K. The importance of contextual topology in the process of harmonization of the spatial Databases on example BDOT500. In Proceedings of the 2016 Baltic Geodetic Congress (BGC Geomatics), Gdansk, Poland, 2–4 June 2016; pp. 251–256. [Google Scholar]
- Chuchro, M.; Franczyk, A.; Dwornik, M.; Leśniak, A. A Big Data processing strategy for hybrid interpretation of flood embankment multisensor data. Geol. Geophys. Environ. 2016, 42, 269–277. [Google Scholar] [CrossRef][Green Version]
- Schulz, W.L.; Nelson, B.G.; Felker, D.K.; Durant, T.J.S.; Torres, R. Evaluation of relational and NoSQL Database architectures to manage genomic annotations. J. Biomed. Inform. 2016, 64, 288–295. [Google Scholar] [CrossRef] [PubMed]
- Lian, J.; Miao, S.; McGuire, M.; Tang, Z. SQL or NoSQL? In Which Is the Best Choice for Storing Big Spatio-Temporal Climate Data? In Proceedings of the International Conference on Conceptual Modeling, Xi’an, China, 22–25 October 2018; pp. 275–284. [Google Scholar]
- Piórkowski, A. Mysql spatial and postgis–implementations of spatial data standards. EJPAU 2011, 14, 3. [Google Scholar]
- Kothuri, R.; Godfrind, A.; Beinat, E. Pro Oracle Spatial for Oracle Database 11g; Dreamtech Press: New Delhi, India, 2008. [Google Scholar]
- Baralis, E.; Dalla Valle, A.; Garza, P.; Rossi, C.; Scullino, F. SQL versus NoSQL Databases for geospatial applications. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3388–3397. [Google Scholar]
- Roy-Hubara, N.; Sturm, A. Exploring the Design Needs for the New Database Era. In Enterprise, Business-Process and Information Systems Modeling; Springer: Cham, Switzerland, 2018; pp. 276–290. [Google Scholar]
- Yoon, J.; Jeong, D.; Kang, C.-H.; Lee, S. Forensic investigation framework for the document store NoSQL DBMS: MongoDB as a case study. Digit. Investig. 2016, 17, 53–65. [Google Scholar] [CrossRef]
- Mehmood, E.; Anees. T. Performance Analysis of Not Only SQL Semi-Stream Join Using MongoDB for Real-Time Data Warehousing. IEEE Access 2019, 7, 134215–134225. [Google Scholar] [CrossRef]
- Okman, L.; Gal-Oz, N.; Gonen, Y.; Gudes, E.; Abramov, J. Security issues in nosql databases. In Proceedings of the 2011 IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, Changsha, China, 16 November 2011; pp. 541–547. [Google Scholar]
- Alomari, E.; Barnawi, A.; Sakr, S. CDPort: A Portability Framework for NoSQL Datastores. Arab. J. Sci. Eng. 2015, 40, 2531–2553. [Google Scholar] [CrossRef]
- Alomari, E.; Noaman, A. SeCloudDB: A Unified API for Secure SQL and NoSQL Cloud Databases. In Proceedings of the 2019 3rd International Conference on Cloud and Big Data Computing, Oxford, UK, 28–30 August 2019; pp. 38–42. [Google Scholar]
- Stravoskoufos, K.; Preventis, A.; Sotiriadis, S.; Petrakis, E.G.M. A Survey on Approaches for Interoperability and Portability of Cloud Computing Services. In CLOSER; Technical University of Crete: Chania, Greece, 2014; pp. 112–117. [Google Scholar]
- Shirazi, M.N.; Kuan, H.C.; Dolatabadi, H. Design patterns to enable data portability between clouds’ Databases. In Proceedings of the 2012 12th International Conference on Computational Science and Its Applications, Salvador, Bahia, 18–21 June 2012; pp. 117–120. [Google Scholar]
- Alomari, E.; Barnawi, A.; Sakr, S. Cdport: A framework of data portability in cloud platforms. In Proceedings of the 16th International Conference on Information Integration and Web-based Applications & Services, Singapore, 28–30 November 2014; pp. 126–133. [Google Scholar]
- Indu, I.; PM, R.A.; Bhaskar, V. Encrypted token based authentication with adapted SAML technology for cloud web services. J. Netw. Comput. Appl. 2017, 99, 131–145. [Google Scholar]
- Vanelli, B.; da Silva, M.P.; Manerichi, G.; Pinto, A.S.R.; Dantas, M.A.R.; Ferrandin, M.; Boava, A. Internet of Things Data Storage Infrastructure in the Cloud Using NoSQL Databases. IEEE Lat. Am. Trans. 2017, 15, 737–743. [Google Scholar] [CrossRef]
- Grolinger, K.; Higashino, W.A.; Tiwari, A.; Capretz, M.A. Data management in cloud environments: NoSQL and NewSQL data stores. J. Cloud Comput. Adv. Syst. Appl. 2013, 2, 22. [Google Scholar] [CrossRef]
- Marston, S.; Li, Z.; Bandyopadhyay, S.; Zhang, J.; Ghalsasi, A. Cloud computing—The business perspective. Decis. Support Syst. 2011, 51, 176–189. [Google Scholar] [CrossRef]
- Kolev, B.; Bondiombouy, C.; Valduriez, P.; Jiménez-Peris, R.; Pau, R.; Pereira, J. The cloudmdsql multistore system. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 2113–2116. [Google Scholar]
- Loutas, N.; Kamateri, E.; Tarabanis, K. A semantic Interoperability framework for cloud platform as a service. In Proceedings of the 2011 IEEE Third International Conference on Cloud Computing Technology and Science, Washington, DC, USA, 29 November–1 December 2011; pp. 280–287. [Google Scholar]
- Zhou, L.; Fu, A.; Yu, S.; Su, M.; Kuang, B. Data integrity verification of the outsourced big data in the cloud environment: A survey. J. Netw. Comput. Appl. 2018, 122, 1–15. [Google Scholar] [CrossRef]
- Kostoska, M.; Gusev, M.; Ristov, S.; Kiroski, K. Cloud Computing Interoperability Approaches-Possibilities and Challenges. In BCI; Ss. Cyril and Methodius University: Skopje, Macedonia, 2012; pp. 30–34. [Google Scholar]
- Loutas, N.; Kamateri, E.; Bosi, F.; Tarabanis, K. Cloud computing Interoperability: The state of play. In Proceedings of the 2011 IEEE Third International Conference on Cloud Computing Technology and Science, Washington, DC, USA, 29 November–1 December 2011; pp. 752–757. [Google Scholar]
- Escalera, M.F.P.; Chavez, M.A.L. UML model of a standard API for cloud computing application development. In Proceedings of the 2012 9th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), Mexico City, Mexico, 26–28 September 2012; pp. 1–8. [Google Scholar]
- Petcu, D.; Martino, B.D.; Venticinque, S.; Rak, M.; Máhr, T.; Lopez, G.; Brito, F.; Cossu, R.; Stopar, M.; Šperka, S.; et al. Experiences in building a mOSAIC of clouds. J. Cloud Comput. Adv. Syst. Appl. 2013, 2, 12. [Google Scholar] [CrossRef]
- Di Nitto, E.; da Silva, M.A.A.; Ardagna, D.; Casale, G.; Craciun, C.D.; Ferry, N.; Muntes, V.; Solberg, A. Supporting the development and operation of multi-cloud applications: The modaclouds approach. In Proceedings of the 2013 15th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 23–26 September 2013; pp. 417–423. [Google Scholar]
- Petcu, D. Portability and Interoperability between clouds: Challenges and case study. In Proceedings of the European Conference on a Service-Based Internet, Poznan, Poland, 26–28 October 2011; pp. 62–74. [Google Scholar]
- Liao, C.-S.; Shih, J.-M.; Chang, R.-S. Simplifying MapReduce data processing. Int. J. Comput. Sci. Eng. 2013, 8, 219–226. [Google Scholar] [CrossRef]
- Silva, L.A.B.; Costa, C.; Oliveira, J.L. A common API for delivering services over multi-vendor cloud resources. J. Syst. Softw. 2013, 86, 2309–2317. [Google Scholar] [CrossRef]
- Sakr, S.; Liu, A.; Batista, D.M.; Alomari, M. A Survey of Large Scale Data Management Approaches in Cloud Environments. IEEE Commun. Surv. Tutorials 2011, 13, 311–336. [Google Scholar] [CrossRef]
- Curino, C.; Jones, E.P.; Popa, R.A.; Malviya, N.; Wu, E.; Madden, S.; Balakrishnan, H.; Zeldovich, N. Relational Cloud: A Database-as-a-Service for the Cloud; MIT Libraries: Boston, MA, USA, 2011. [Google Scholar]
- Lehner, W.; Sattler, K.-U. Database as a service (DBaaS). In Proceedings of the 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), Long Beach, CA, USA, 1–6 March 2010; pp. 1216–1217. [Google Scholar]
- Kiefer, T.; Lehner, W. Private table Database virtualization for dbaas. In Proceedings of the 2011 Fourth IEEE International Conference on Utility and Cloud Computing, Melbourne, Austalia, 5–8 December 2011; pp. 328–329. [Google Scholar]
- Zafar, R.; Yafi, E.; Zuhairi, M.F.; Dao, H. Big data: The NoSQL and RDBMS review. In Proceedings of the 2016 International Conference on Information and Communication Technology (ICICTM), Kuala Lumpur, Malaysia, 16–17 May 2016; pp. 120–126. [Google Scholar]
- Sahatqija, K.; Ajdari, J.; Zenuni, X.; Raufi, B.; Ismaili, F. Comparison between relational and NOSQL Databases. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 216–221. [Google Scholar]
- Alias, N.; Suhari, N.N.; Saipol, H.F.; Dahawi, A.A.; Saidi, M.M.; Hamlan, H.A.; Teh, C.R. Parallel computing of numerical schemes and big data analytic for solving real life applications. Jurnal Teknologi. 2016, 78. [Google Scholar] [CrossRef]
- Chang, M.-L.E.; Chua, H.N. SQL and NoSQL Database Comparison. In Proceedings of the Future of Information and Communication Conference, Vienna, Austria, 4–6 December 2018; pp. 294–310. [Google Scholar]
- Frizzo-Barker, J.; Chow-White, P.A.; Mozafari, M.; Ha, D. An empirical study of the rise of big data in business scholarship. Int. J. Inf. Manag. 2016, 36, 403–413. [Google Scholar] [CrossRef]
- Chickerur, S.; Goudar, A.; Kinnerkar, A. Comparison of relational Database with document-oriented Database (mongodb) for big data applications. In Proceedings of the 2015 8th International Conference on Advanced Software Engineering & Its Applications (ASEA), Jeju Isalnd, Republic of Korea, 25–28 November 2015; pp. 41–47. [Google Scholar]
- Kumar, M.S. Comparison of NoSQL Database and Traditional Database-An emphatic analysis. JOIV Int. J. Informatics Vis. 2018, 2, 51–55. [Google Scholar] [CrossRef]
- Ansari, H. Performance Comparison of Two Database Management Systems MySQL vs. MongoDB; Umeå University: Umeå, Sweden, 2018. [Google Scholar]
- Khan, W.; Raj, K.; Kumar, T.; Roy, A.M.; Luo, B. Introducing Urdu Digits Dataset with Demonstration of an Efficient and Robust Noisy Decoder-Based Pseudo Example Generator. Symmetry 2022, 14, 1976. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. A Deep Learning Enabled Multi-Class Plant Disease Detection Model Based on Computer Vision. AI 2021, 2, 413–428. [Google Scholar] [CrossRef]
- Roy, A.M. An efficient multi-scale CNN model with intrinsic feature integration for motor imagery EEG subject classification in brain-machine interfaces. Biomed. Signal Process. Control. 2022, 74, 103496. [Google Scholar] [CrossRef]
- Singh, A.; Raj, K.; Kumar, T.; Verma, S.; Roy, A.M. Deep Learning-Based Cost-Effective and Responsive Robot for Autism Treatment. Drones 2023, 7, 81. [Google Scholar] [CrossRef]
- Dhasade, S.D. Nosql Database. Available online: https://www.irjmets.com/uploadedfiles/paper/issue_10_october_2022/30598/final/fin_irjmets1665589950.pdf (accessed on 11 November 2022).













| Consistency | Availability | Partition Tolerance |
|---|---|---|
|
|
|
| Search Source | Based on Title (Phase II) | Based on Abstract (Phase III) | Based on Full Reading of Papers (Phase IV) |
|---|---|---|---|
| Total No. of Papers | 1126 | 326 | 142 |
| SQL | MongoDB |
|---|---|
| Rigid schema | Flexible schema |
| Table | Collection |
| Row | Document |
| Column | Field |
| Multiple joins are required to obtain the complete detail of a single person, student, or customer, which causes slow data accessibility. | Data accessibility is very fast, as all data are stored in one single document |
| Vertical scalability | Horizontal scalability |
| Complex data sharding | Data sharding becomes simpler |
| Considers data storage efficiency | Considers the speed, performance, developer time |
| Performs well in aggregation | Performs better in a retrieval |
| Does not perform read/write very quickly in big data analytics | Performs read/write very quickly because of memory mapping function in big data analytics. |
| Supports relational algebra [60] | Supports relational algebra [60] |
| Database | Oracle | PostGIS | Azure SQL | MongoDB | DocumentDB |
|---|---|---|---|---|---|
| Geometry Objects Supported | Point, LineString, Polygon, MultiPoint, MultiLinePoint, MultiPolygon, GeometryCollection | Point, LineString, Polygon, MultiPoint, MultiLinePoint, MultiPolygon, GeometryCollection | Point, LineString, Polygon, MultiPoint, MultiLinePoint, MultiPolygon, GeometryCollection | Point, LineString, Polygon, MultiPoint, MultiLinePoint, MultiPolygon, GeometryCollection | Point, LineString, Polygon, MultiPoint, MultiLinePoint, MultiPolygon, GeometryCollection |
| Geometry Functionalities Supported | For geometry instances, Oracle has the support of Open Geospatial Consortium (OGC) | For geometry instances, PostGIS has the support of Open Geospatial Consortium (OGC) | For geometry instances, Azure SQL has the support of Open Geospatial Consortium (OGC) | Inclusion, Intersection, Distance/Proximity | Inclusion, Distance/Proximity |
| Spatial Indexes Supported | B-Trees, Parallel index builds for spatial R-tree indexes | GiST index, R-Tree index, B-Tree index | B-Trees, 2D plane index | 2D index, 2D sphere index | 2D plane index, quadtree |
| GeoServer Compatibility | Yes | Yes | Yes | Yes | Yes |
| DBaaS | Yes | No | Yes (Cloud Computing Platform) | Yes | Yes |
| Horizontal Scalability | No | No | No | Yes | Yes |
| DBMSs | Features | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Data | Schema | Scalability | Compliance | Architecture | Consistency | Query Language | Performance | Best Suited For | |
| RDBMS | S | Fixed | Vertical | ACID | Centralized | Strict | SQL | Slow | BFT |
| NoSQL | SUSm | Dynamic | Horizontal | BASE | Distributed | Eventual | OO API, SQL Like | Fast | LSWA, SD |
| Challenges with reliability and availability (CA): This database design places a priority on data consistency and accessibility using a replication approach. Parts of the database do not care about partition tolerance. If the nodes are partitioned, the data will go out of sync. Vertica, Greenplum, and relational database management systems are examples of this type of database. |
| There are problems with consistency and partition tolerance (CP) that must be fixed. The primary objective of such a database management system is to ensure the integrity of the data it stores. However, high availability is no longer supported. The data are stored in the various nodes, and when a node crashes, it causes the data that ensures consistency between them to become unavailable. It maintains partition tolerance by blocking data resynchronization. Hypertable, BigTable, and HBase are only a few examples of the database systems that are CP-aware. |
| In this type of database, providing data availability and partition tolerance (AP) is a top priority. If there is a communication breakdown among nodes, it does not affect the status of any individual node. After a partition is resolved, data are resynchronized but consistency is not ensured. These principles are followed by databases such as Riak, CouchDB, and KAI. |
| When one element of a database goes down but the others keep running, that section of the database is said to be “basically available.” In the event of a node failure, the operation will continue by replicating the data among the remaining nodes. |
| In a soft state, data are subject to change over time depending on factors such as the level of participation of the user. The usefulness of such information may also deteriorate after a certain period has passed. Therefore, it is necessary to either update or obtain the data for the information to be useful in the system. |
| According to eventual consistency, after every data modification, the data do not instantly become consistent throughout the entire system, but they will become consistent eventually. The data, it is said, will continue to be accurate into the foreseeable future. |
| Database Name | Database Category | Database Architecture | Database Type | Written in |
|---|---|---|---|---|
| MongoDB | NoSQL-Document Store | Distributed Multi-Model | Open Source | C++, Go, JavaScript, Python |
| MySQL | SQL | Open Source | C, C++ | |
| Oracle | SQL | Not | Assembly language, C, C++ | |
| SQL Server | SQL | Not | C, C++ | |
| Neo4j | NoSQL-Graph Family | Open Source | Java | |
| Couchbase | NoSQL-Document Store | Distributed Multi-Model | Open Source | C++, Erlang, C, Go |
| CouchDB | NoSQL-Document Store | Distributed Multi-Model | Open Source | Erlang, JavaScript, C, C++ |
| Cassandra | NoSQL-Column Based | Distributed Multi-Model | Open Source | Java |
| Rethink | NoSQL-Document Store | Distributed Multi-Model | Open Source | C++, Python, Java, JavaScript, Bash |
| MariaDB | SQL | Open Source | C, C++, Perl, Bash | |
| RavenDB | NoSQL-Document Store | Open Source | C# | |
| BigTable | NoSQL-Column Based | Not | C++ (core), Java, Python, Go, Ruby | |
| DynamoDB | NoSQL-Key/Value Store | Not | Java | |
| SimpleDB | NoSQL-Key/Value Store | Distributed Database | Not | Erlang |
| PostgreSQL | SQL | Open Source | C | |
| PostGIS | SQL | Open Source | C | |
| Hbase | NoSQL-Column Based | Distributed Multi-Model | Open Source | Java |
| GraphDB | NoSQL-Graph Family | Distributed Database | ||
| Sybase | SQL | Not | SQL | |
| Redis | NoSQL- Key/Value Store | Open Source | ANSI C | |
| HyperTable | NoSQL-Column Based | Open Source | C++ | |
| JenusGraph | NoSQL-Graph Family | Open Source | Java | |
| VoltDB | in-memory DBMS | Open Source | Java, C++ | |
| VoldeMort | NoSQL-Key/Value Store | Distributed datastore | Open Source | Java |
| Infogrid | NoSQL-Graph Family | Open Source | Java | |
| H2 | SQL | Open Source | Java | |
| ArangoDB | NoSQLDB | Open Source | C++, JavaScript | |
| OrientDB | NoSQLDB | Open Source | Java | |
| Azure SQL | SQL | Open Source | C, C++ | |
| Azure DocumentDB | NoSQL-Document Store | Open Source | SQL (Core) API |
| If your applications simply need to store and retrieve data items that are transparent to the DBMS and can be identified by a key, a key-value store may be the best option for you. In contrast, the software crashes if it tries to perform a database query based on a value for an attribute other than the key. Furthermore, it is impossible to update or obtain just one field from a document’s key-value store. |
| When applications require granular control over which records to obtain, which fields within a record to change, and which fields to retrieve based on criteria other than the primary key, document databases are an excellent option. Document data stores provide more query flexibility than key-value stores. |
| When applications need to store data with hundreds or thousands of fields but need to access only a subset of these fields in most queries, column-family data stores are an efficient solution. Such data repositories are well suited for massive data sets. |
| Graph databases are ideally suited for use cases that include storing and analyz-ing data on entities with complex relationships to one another. In a graph data-base, the importance of entities and their connections is treated equally. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, W.; Kumar, T.; Zhang, C.; Raj, K.; Roy, A.M.; Luo, B. SQL and NoSQL Database Software Architecture Performance Analysis and Assessments—A Systematic Literature Review. Big Data Cogn. Comput. 2023, 7, 97. https://doi.org/10.3390/bdcc7020097
Khan W, Kumar T, Zhang C, Raj K, Roy AM, Luo B. SQL and NoSQL Database Software Architecture Performance Analysis and Assessments—A Systematic Literature Review. Big Data and Cognitive Computing. 2023; 7(2):97. https://doi.org/10.3390/bdcc7020097
Chicago/Turabian StyleKhan, Wisal, Teerath Kumar, Cheng Zhang, Kislay Raj, Arunabha M. Roy, and Bin Luo. 2023. "SQL and NoSQL Database Software Architecture Performance Analysis and Assessments—A Systematic Literature Review" Big Data and Cognitive Computing 7, no. 2: 97. https://doi.org/10.3390/bdcc7020097
APA StyleKhan, W., Kumar, T., Zhang, C., Raj, K., Roy, A. M., & Luo, B. (2023). SQL and NoSQL Database Software Architecture Performance Analysis and Assessments—A Systematic Literature Review. Big Data and Cognitive Computing, 7(2), 97. https://doi.org/10.3390/bdcc7020097