

Empowering Short Answer Grading: Integrating Transformer-Based Embeddings and BI-LSTM Network

 , and
, and
Abstract
:1. Introduction
- A.
- The most appropriate pretrained model was identified for embedding all student answers and model answers in the North Texas data structure dataset.
- B.
- The developed neural network was experimentally evaluated with the North Texas data structure dataset, and the most advanced results in this task for this dataset were achieved.
- C.
- The optimal preprocessing techniques that can be utilized for this task was determined.
2. Literature Review
3. Methodology
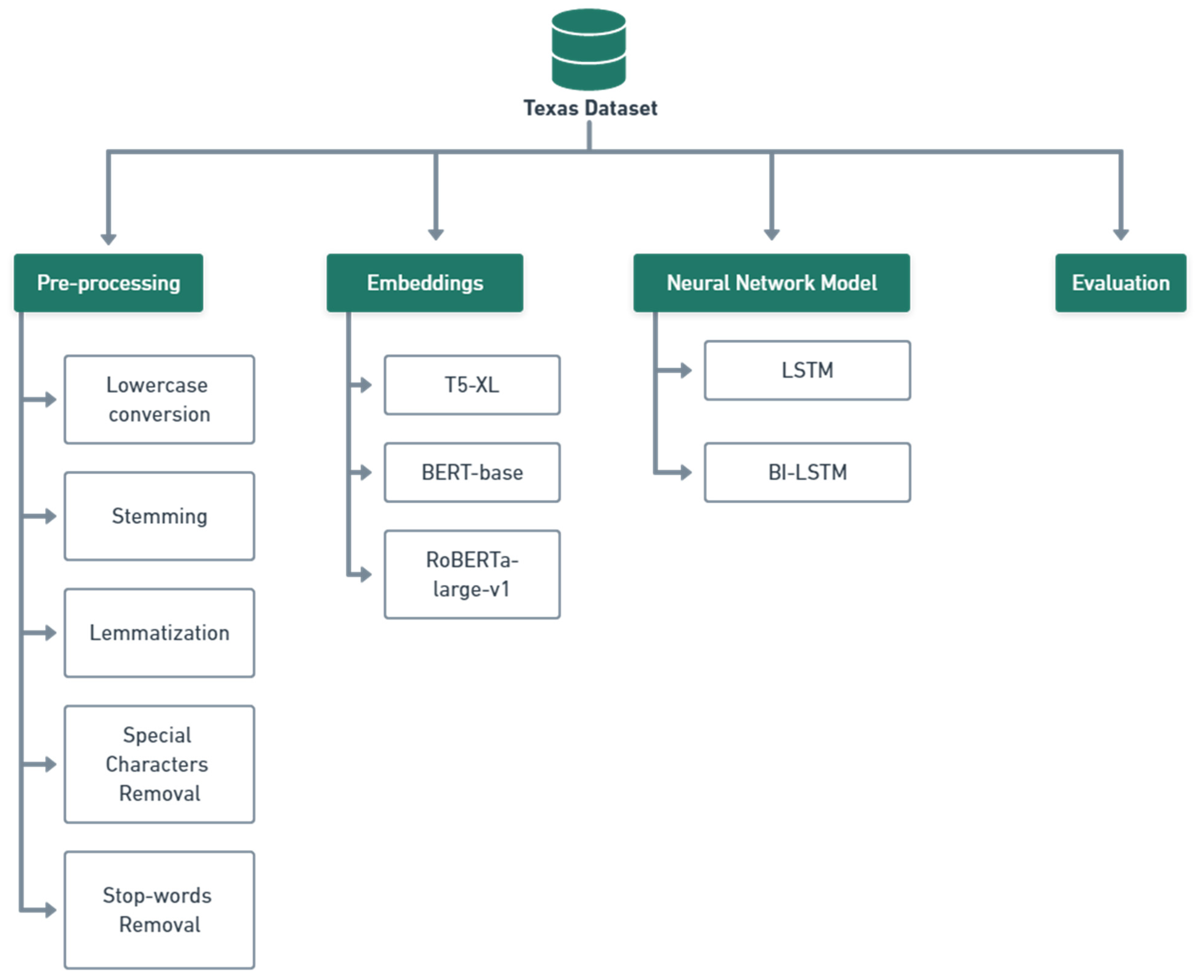
3.1. Preprocessing Stage
3.2. Embedding Stage
3.3. Neural Network Architecture
3.4. Predicting and Evaluating the Grade
4. Results and Discussion
4.1. Evaluation Metrics
4.2. Experimental Results
- No. of layers = 8
- No. of dropout layers = 2
- No. of hidden dense layers = 4
- Batch size = 3
- Learning rate = 0.0001
- Activation function = ReLu
- -
- No. of layers = 8
- -
- No. of dropout layers = 2
- -
- No. of hidden dense layers = 4
- -
- Batch size = 3
- -
- Learning rate = 0.0001
- -
- Activation function = ReLu
- -
- Model user = T5
- -
- Split Size = 0.2
- -
- Input layer = BI-LSTM
4.3. Comparing the Obtained Results with Previous Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saeed, M.M.; Gomaa, W.H. An Ensemble-Based Model to Improve the Accuracy of Automatic Short Answer Grading. In Proceedings of the 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022; pp. 337–342. [Google Scholar]
- Sawatzki, J.; Schlippe, T.; Benner-Wickner, M. Deep Learning Techniques for Automatic Short Answer Grading: Predicting Scores for English and German Answers. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence in Education Technology, Dali, China, 18–20 June 2021. [Google Scholar]
- Saha, S.; Dhamecha, T.I.; Marvaniya, S.; Sindhgatta, R.; Sengupta, B. Sentence Level or Token Level Features for Automatic Short Answer Grading?: Use Both. In Proceedings of the International Conference on Artificial Intelligence in Education, London, UK, 23–30 June 2018. [Google Scholar]
- Gaddipati, S.K.; Nair, D.; Plöger, P.G. Comparative Evaluation of Pretrained Transfer Learning Models on Automatic Short Answer Grading. arXiv 2020, arXiv:2009.01303. [Google Scholar]
- Süzen, N.; Gorban, A.N.; Levesley, J.; Mirkes, E.M. Automatic short answer grading and feedback using text mining methods. Procedia Comput. Sci. 2020, 169, 726–743. [Google Scholar] [CrossRef]
- Bookstein, A.; Kulyukin, V.A.; Raita, T. Generalized hamming distance. Inf. Retr. 2002, 5, 353–375. [Google Scholar] [CrossRef]
- Gomaa, W.H.; Fahmy, A.A. Ans2vec: A scoring system for short answers. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications (AMLTA2019), Cairo, Egypt, 28–30 March 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 586–595. [Google Scholar]
- Pribadi, F.S.; Permanasari, A.E.; Adji, T.B. Short answer scoring system using automatic reference answer generation and geometric average normalized-longest common subsequence (gan-lcs). Educ. Inf. Technol. 2018, 23, 2855–2866. [Google Scholar] [CrossRef]
- Hassan, S.; Fahmy, A.A.; El-Ramly, M. Automatic short answer scoring based on paragraph embeddings. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 397–402. [Google Scholar] [CrossRef] [Green Version]
- Hindocha, E.; Yazhiny, V.; Arunkumar, A.; Boobalan, P. Short-text Semantic Similarity using GloVe word embedding. Int. Res. J. Eng. Technol. 2019, 6, 553–558. [Google Scholar]
- Sánchez Rodríguez, I. Text Similarity by Using GloVe Word Vector Representations. 2017. Available online: https://riunet.upv.es/handle/10251/90045 (accessed on 5 January 2021).
- Kenter, T.; De Rijke, M. Short text similarity with word embeddings. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1411–1420. [Google Scholar]
- Roy, S.; Dandapat, S.; Nagesh, A.; Narahari, Y. Wisdom of students: A consistent automatic short answer grading technique. In Proceedings of the 13th International Conference on Natural Language Processing, Varanasi, India, 17–20 December 2016; pp. 178–187. [Google Scholar]
- Magooda, A.E.; Zahran, M.; Rashwan, M.; Raafat, H.; Fayek, M. Vector based techniques for short answer grading. In Proceedings of the Twenty-Ninth International Flairs Conference, Key Largo, FL, USA, 16–18 May 2016. [Google Scholar]
- Lofi, C. Measuring semantic similarity and relatedness with distributional and knowledge-based approaches. Inf. Media Technol. 2015, 10, 493–501. [Google Scholar]
- Bonthu, S.; Rama Sree, S.; Krishna Prasad, M.H.M. Automated Short Answer Grading Using Deep Learning: A Survey. In Machine Learning and Knowledge Extraction; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; CD-MAKE 2021; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; Volume 12844. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, Y.; Yang, X.; Yu, S.; Zhuang, F. An automatic short-answer grading model for semi-open-ended questions. Interact. Learn. Environ. 2022, 30, 177–190. [Google Scholar] [CrossRef]
- Xia, L.; Guan, M.; Liu, J.; Cao, X.; Luo, D. Attention-Based Bidirectional Long Short-Term Memory Neural Network for Short Answer Scoring. In Machine Learning and Intelligent Communications, Proceedings of the 5th International Conference, MLICOM 2020, Shenzhen, China, 26–27 September 2020; Proceedings 5; Springer International Publishing: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Gong, T.; Yao, X. An Attention-based Deep Model for Automatic Short Answer Score. Int. J. Comput. Sci. Softw. Eng. 2019, 8, 127–132. [Google Scholar]
- Salam, M.A.; El-Fatah, M.A.; Hassan, N.F. Automatic grading for Arabic short answer questions using optimized deep learning model. PLoS ONE 2022, 17, e0272269. [Google Scholar] [CrossRef]
- Ni, J.; Abrego, G.H.; Constant, N.; Ma, J.; Hall, K.; Cer, D.; Yang, Y. Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. arXiv 2021, arXiv:2108.08877. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Gomaa, W.H.; Fahmy, A.A. Short answer grading using string similarity and corpus-based similarity. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2012. [Google Scholar] [CrossRef] [Green Version]
- Gomaa, W.H.; Fahmy, A.A. Arabic short answer scoring with effective feedback for students. Int. J. Comput. Appl. 2014, 86, 35–41. [Google Scholar]
- Gomaa, W.H.; Fahmy, A.A. Automatic scoring for answers to Arabic test questions. Comput. Speech Lang. 2014, 28, 833–857. [Google Scholar] [CrossRef]
- Shah, N.; Pareek, J. Automatic Evaluation of Free Text Answers: A Review. In Advancements in Smart Computing and Information Security, Proceedings of the First International Conference, ASCIS 2022, Rajkot, India, 24–26 November 2022; Revised Selected Papers, Part II; Springer: Cham, Switzerland, 2023; pp. 232–249. [Google Scholar]
- Susanti, M.N.I.; Ramadhan, A.; Warnars, H.L.H.S. Automatic essay exam scoring system: A systematic literature review. Procedia Comput. Sci. 2023, 216, 531–538. [Google Scholar] [CrossRef] [PubMed]
- Schlippe, T.; Stierstorfer, Q.; Koppel, M.T.; Libbrecht, P. Explainability in Automatic Short Answer Grading. In Artificial Intelligence in Education Technologies: New Development and Innovative Practices, Proceedings of the 2022 3rd International Conference on Artificial Intelligence in Education Technology, Birmingham, UK, 21–23 October 2022; Springer: Singapore, 2023; pp. 69–87. [Google Scholar]
- Firoz, N.; Beresteneva, O.G.; Vladimirovich, A.S.; Tahsin, M.S.; Tafannum, F. Automated Text-based Depression Detection using Hybrid ConvLSTM and Bi-LSTM Model. In Proceedings of the 2023 Third International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 2–4 February 2023; pp. 734–740. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Year | Approach | Correlation Score |
|---|---|---|---|
| [5] | 2020 | Clustering and regression analysis: Apply different approaches such as calculating hamming distance, applying regression classification, and applying clustering too. | 81% |
| [2] | 2022 | Embedding and transformers: Convert student and model answers using the Ans2Vec approach [7], and then fine-tune the BERT model and add a linear layer to predict the student grade. | 78% |
| [1] | 2022 | Embedding and text similarity techniques: Compare student answers to model answers using various string, semantic, and embedding techniques. | 65.12% |
| [7] | 2019 | Embedding: Embed the student and model answers using skip-thought vectors, and then obtain the similarity between them. | 63% |
| [13] | 2016 | Embedding and text similarity techniques: Use Disco, Block distance, Jiang-Conrath, and Lesk similarity techniques between the student and model answer vectors. | 58.6% |
| [3] | 2018 | Embedding and similarity techniques: Apply some new feature extraction techniques and combine them to predict a student grade. | 57% |
| [9] | 2018 | Embedding and deep learning: Convert student and model answers into vectors using paragraph embedding, and then apply cosine similarity between them. | 56.9% |
| [14] | 2016 | Embedding and deep learning: Apply corpus and knowledge-based similarity techniques, and then calculate the similarity using Word2Vec and Glove model. | 55.0% |
| [4] | 2020 | Embedding and text similarity techniques: Use an embedding pretrained model to convert student and model answers into vectors, and then calculate the cosine similarity between them | 48.5% |
| [8] | 2018 | Text similarity techniques: Use the maximum marginal relevance technique to create a reference response from a student’s answer, and then use a GAN longest common substring to compute the similarity between the student and model answer. | 46.8% |
| Model | Architecture | Training Corpus Size | Pretraining Task | Layers | Total Parameters |
|---|---|---|---|---|---|
| T5-XL | Transformer | 750 GB (C4 Common Crawl) | Denoising autoencoder | Customizable (ranges from small (6 layers) to 3B (24 layers)) | Customizable (ranges from 60 M to 11 B) |
| BERT-base | Transformer | 16 GB (BooksCorpus and English Wikipedia) | Masked language model | 12 | 125 M |
| Roberta-large-v1 | Transformer | 160 GB (Common Crawl News dataset, BooksCorpus, and English Wikipedia, etc.) | Masked language model with dynamic masking | 24 | 355 M |
| Model No. | Split Size | Input Layer | Val_mse | Testing Corr. |
|---|---|---|---|---|
| 1-T5 | 0.2 | BI-LSTM | 0.109 | 92.80% |
| 2-T5 | 0.3 | BI-LSTM | 0.194 | 85.20% |
| 3-T5 | 0.4 | BI-LSTM | 0.307 | 80.00% |
| 4-T5 | 0.2 | LSTM | 0.109 | 81.67% |
| 5-T5 | 0.3 | LSTM | 0.194 | 74.72% |
| 6-T5 | 0.4 | LSTM | 0.307 | 65.80% |
| 7-bert base | 0.2 | BI-LSTM | 0.183 | 89.10% |
| 8-bert base | 0.3 | BI-LSTM | 0.183 | 70.90% |
| 9-bert base | 0.4 | BI-LSTM | 0.183 | 69.90% |
| 10-bert base | 0.2 | LSTM | 0.766 | 71.25% |
| 11-bert base | 0.3 | LSTM | 0.760 | 57.43% |
| 12-bert base | 0.4 | LSTM | 0.797 | 57.98% |
| 13-all-distilroberta-v1 | 0.2 | BI-LSTM | 0.177 | 88.20% |
| 14-all-distilroberta-v1 | 0.3 | BI-LSTM | 0.109 | 88.20% |
| 15-all-distilroberta-v1 | 0.2 | LSTM | 0.705 | 71.68% |
| 16-all-distilroberta-v1 | 0.3 | LSTM | 0.760 | 57.43% |
| 17-all-distilroberta-v1 | 0.4 | LSTM | 0.797 | 57.98% |
| Lower Case | Lemmatization | Stemming | Remove Stop Words | Remove Special Characters | Testing Corr. |
|---|---|---|---|---|---|
| √ | - | - | - | - | 92.8% |
| √ | √ | - | - | √ | 92.1% |
| - | - | - | - | √ | 91.3% |
| √ | - | - | - | √ | 91.2% |
| - | √ | - | - | √ | 90.8% |
| √ | √ | - | - | - | 90.7% |
| - | √ | - | √ | - | 89.9% |
| √ | - | √ | - | √ | 89.5% |
| - | - | √ | - | - | 89% |
| - | - | √ | - | √ | 88.5% |
| - | - | √ | √ | √ | 88.2% |
| √ | - | √ | √ | √ | 87.4% |
| √ | √ | - | √ | - | 87.1% |
| - | - | - | √ | - | 86.8% |
| - | √ | - | - | - | 86.0% |
| - | - | - | - | - | 86% |
| √ | - | √ | - | - | 85.5% |
| - | √ | - | √ | √ | 85.4% |
| - | - | √ | √ | - | 84.9% |
| - | - | - | √ | √ | 84.6% |
| √ | √ | - | √ | √ | 84.5% |
| √ | - | √ | √ | - | 84.5% |
| √ | - | - | √ | - | 83.7% |
| √ | - | - | √ | √ | 82.1% |
| References | Year | Approach | Correlation Score |
|---|---|---|---|
| - | 2022 | Proposed system (embedding + deep learning) | 92.8% |
| [5] | 2020 | Clustering and regression analysis | 81% |
| [2] | 2022 | Embedding and transformers | 78% |
| [1] | 2022 | Embedding and text similarity techniques | 65.12% |
| [7] | 2019 | Embedding | 63% |
| [13] | 2016 | Embedding and text similarity techniques | 58.6% |
| [3] | 2018 | Embedding and similarity techniques | 57% |
| [9] | 2018 | Embedding and deep learning | 56.9% |
| [14] | 2016 | Embedding and deep learning | 55.0% |
| [4] | 2020 | Embedding and text similarity techniques | 48.5% |
| [8] | 2018 | Text similarity techniques | 46.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomaa, W.H.; Nagib, A.E.; Saeed, M.M.; Algarni, A.; Nabil, E. Empowering Short Answer Grading: Integrating Transformer-Based Embeddings and BI-LSTM Network. Big Data Cogn. Comput. 2023, 7, 122. https://doi.org/10.3390/bdcc7030122
Gomaa WH, Nagib AE, Saeed MM, Algarni A, Nabil E. Empowering Short Answer Grading: Integrating Transformer-Based Embeddings and BI-LSTM Network. Big Data and Cognitive Computing. 2023; 7(3):122. https://doi.org/10.3390/bdcc7030122
Chicago/Turabian StyleGomaa, Wael H., Abdelrahman E. Nagib, Mostafa M. Saeed, Abdulmohsen Algarni, and Emad Nabil. 2023. "Empowering Short Answer Grading: Integrating Transformer-Based Embeddings and BI-LSTM Network" Big Data and Cognitive Computing 7, no. 3: 122. https://doi.org/10.3390/bdcc7030122
APA StyleGomaa, W. H., Nagib, A. E., Saeed, M. M., Algarni, A., & Nabil, E. (2023). Empowering Short Answer Grading: Integrating Transformer-Based Embeddings and BI-LSTM Network. Big Data and Cognitive Computing, 7(3), 122. https://doi.org/10.3390/bdcc7030122