
EnviroStream: A Stream Reasoning Benchmark for Environmental and Climate Monitoring

 , ,
, ,  ,
,  ,
,  and
and
Abstract
:1. Introduction
2. The EnviroStream Benchmark
2.1. Main Features
- •
- require to manage time-based windows of varying size;
- •
- require to explicitly reason over time;
- •
- require to express various forms of aggregation across time slots and windows;
- •
- are supposed to be continuously processed over streams;
- •
- are both expressed in natural language and formally translated into a logic-based language for stream reasoning;
- •
- thanks to the translation and the availability of an actual system they come with proper means for correctness checking and baseline comparison.
- •
- they are continuously injected in real-time;
- •
- they are periodically incrementally updated and made available, thus fostering scalability, variety and continuous maintenance of data;
- •
- they are available in different formats, in order to foster the applicability of the benchmark also to different contexts, and grant consumer agnosticism [7];
- •
- besides static datasets, EnviroStream comes with a generator for tuning streams, thus allowing custom testing scenarios.
2.2. EnviroStream in the Context of SR Benchmarks
2.3. Data
- wind speed in m/s (meters per second);
- wind direction in degrees;
- relative humidity percentage;
- external temperature in C (Celsius degrees);
- noise in dB(A) (A—weighted decibels);
- PM, i.e., concentration of particulate matter of diameter in g/m (micro-grams per cubic meter of air);
- PM, i.e., concentration of particulate matter of diameter 10 in g/m;
- atmospheric pressure in Kpa (Kilo-pascal);
- optical rainfall in mm (millimeters).
2.4. Queries
2.4.1. Air Quality
- Query 1
- Determination of the average of PM and PM measurements in the last 10 min and raise an alert if the PM average is greater than or equal to 50 and/or the PM average is greater than or equal to 25. The thresholds refer to the current European recommendation (https://environment.ec.europa.eu/topics/air/air-quality/eu-air-quality-standards_en (accessed on 1 May 2023)). The more the concentration of particulate matter in the air exceed these thresholds, the greater the health risks.
- Query 2
- Determination of the cities in which the PM and PM averages are maximum.
2.4.2. Noise Pollution
- Query 3
- Determination of the number of noise measurements exceeding the threshold recommended by the World Health Organisation (WHO) in the last hour. The WHO generally defines 65 dB(A) as the threshold during the day (from 6 a.m. to 10 p.m.) and 55 dB(A) at night (from 10 p.m. to 6 p.m.) (https://www.who.int/europe/news-room/fact-sheets/item/noise (accessed on 1 May 2023)).
- Query 4
- Determination of the cities in which a noise above 85 dB(A) was observed continuously for one hour. In fact, the WHO recommends that noise exposure should not exceed 85 dB(A) within an hour to avoid hearing impairment (https://apps.who.int/iris/bitstream/handle/10665/39458/9241540729-eng.pdf (accessed on 1 May 2023)).
2.4.3. Heat
- Query 5
- Alert when the Humidex is currently greater than 2 and has been above 2 at least 3 times in the last 30 min.
- Query 6
- Determination of the cities in which the Humidex results are always above 2 in the last 30 min.
2.4.4. Rain Intensity
- Query 7
- Monitoring of the total millimeters of rain in the last hour and the classification of the rain intensity as light, moderate, or heavy. Rain is considered light if less than 25 mm fell in one hour, moderate if more than 25 mm and less than 76 mm fell in one hour, heavy if more than 76 mm fell in one hour (https://glossary.ametsoc.org/wiki/Rain (accessed on 1 May 2023)).
- Query 8
- Identification of the least rainy cities, i.e., those in which less millimeters of rain fell in the last hour.
2.4.5. Wind Force
- Query 9
- Alert when the Beaufort level computed over the average wind speed in the last 10 min is above 6.
- Query 10
- Suppose L represents the current Beaufort level, this query determines, for each city, the duration in minutes for which the level has remained at L.
3. Modelling EnviroStream via the I-DLV-sr Language
3.1. The I-DLV-sr Language
c(Z) :- b(X), a(X), &sum(X,Y;Z). d(X) :- c(X) at least 1 in [1 sec].
where c(Z), b(X), a(X), and d(X) are predicate atoms, c(X) at least 1 in [1 sec] is a streaming literal, and &sum(X,Y;Z) is an external literal, whose meaning could be, for instance, defined via the following Python function:- def
- sum(a, b):return a+b
occurring_time_a(X,Y) :- a(X,@now).
allows one to infer occurring_time_a(3,15).3.2. Design of EnviroStream Queries
3.2.1. Query 1
r1: last_pm10(C,X) :- pm10(C,X) in [10 min]. r2: tot_pm10(C,Tot) :- station(C), #sum{X,C: last_pm10(C,X)} = Tot. r3: count_pm10(C,Count) :- station(C), #count{X,C: last_pm10(C,X)} = Count. r4: avg_pm10(C,Avg) :- tot_pm10(C,Tot), count_pm10(C,Count), Avg = Tot/Count r5: too_high_pm10(C) :- avg_pm10(C,A), A>=X, maximum_allowed_pm10(X).
r6: last_pm2_5(C,X) :- pm2_5(C,X) in [10 min]. r7: tot_pm2_5(C,Tot) :- station(C), #sum{X,C: last_pm2_5(C,X)} = Tot. r8: count_pm2_5(C,Count) :- station(C), #count{X,C: last_pm2_5(C,X)} = Count. r9: avg_pm2_5(C,Avg) :- tot_pm2_5(C,Tot), count_pm2_5(C,Count), Avg = Tot/Count r10: too_high_pm2_5(C) :- avg_pm2_5(C,A), A>=X, maximum_allowed_pm2_5(X).
3.2.2. Query 2
r11: max_avg_pm10(MAX) :- MAX = #max{X: avg_pm10(C,X)}. r12: most_polluted_area_pm10(C) :- avg_pm10(C,MAX), max_avg_pm10(MAX).
r13: max_avg_pm2_5(MAX) :- MAX = #max{X: avg_pm2_5(C,X)}. r14: most_polluted_area_pm2_5(C) :- avg_pm2_5(C,MAX), max_avg_pm2_5(MAX).
3.2.3. Query 3
r15: day :- @now.hour>=6, @now.hour<22. r16: night :- not day. r17: above_threshold(C) :- noise(C,N), day_threshold(T), day, &geq(N,T;). r18: above_threshold(C) :- noise(C,N), night_threshold(T), night, &geq(N,T;). r19: number_of_high_detections(C,X) :- above_threshold(C) count X in [60 min].
3.2.4. Query 4
r20: above_threshold_1_h(C) :- noise(C,N), threshold_1_hour(T), &geq(N,T;). r21: noise(C) :- noise(C,N). r22: above_threshold_1_h(C) :- above_threshold_1_h(C) in {1}, not noise(C). r23: noise_pollution(C) :- above_threshold_1_h(C) always in [60 min].
3.2.5. Query 5
r24: humidex(C,Hi) :- temperature(C,T), humidity(C,H), &compute_humidex(T,H;Hi). r25: humidex_level(C,1) :- humidex(C,Hi), Hi>=20, Hi<30. r26: humidex_level(C,2) :- humidex(C,Hi), Hi>=30, Hi<40. r27: humidex_level(C,3) :- humidex(C,Hi), Hi>=40, Hi<45. r28: humidex_level(C,4) :- humidex(C,Hi), Hi>=45. r29: disconfort(C,L) :- humidex_level(C,L), L>2, humidex_level(C,L) at least 3 in [30 min].
3.2.6. Query 6
r30: temperature(C) :- temperature(C,T). r31: humidex_level(C,L) :- humidex_level(C,L) in {1}, not temperature(C). r32: always_high_humidex(C,L) :- humidex_level(C,L), L>2, humidex_level(C,L) always in [30 min].
3.2.7. Query 7
r34: rain_now(Sensor,Rain,@now) :- rain(Sensor, Rain). r35: rain_1_hour(Sensor, Rain, X) :- rain_now(Sensor, Rain, X) in [60 min].
r36: precedes(C,T1,T2) :- rain_1_hour(C,R1,T1), rain_1_hour(C,R2,T2), T1<T2. r37: successor(C,T1,T2) :- precedes(C,T1,T2), not inBetween(C,T1,T2). r38: inBetween(C,T1,T2) :- precedes(C,T1,T3), precedes(C,T3,T2). r39: first(C,T) :- rain_1_hour(C,R,T), not hasPredecessor(C,T). r40: last(C,T) :- rain_1_hour(C,R,T), not hasSuccessor(C,T). r41: hasPredecessor(C,T2) :- successor(C,T1,T2). r42: hasSuccessor(C,T1) :- successor(C,T1,T2). r43: partialSum(C,T,R) :- first(C,T), rain_1_hour(C,R,T). r44: partialSum(C,T2,R3) :- successor(C,T1,T2), rain_1_hour(C,R2,T2), partialSum(C,T1,PS), &sum(PS,R2;R3). r45: mm_rain_1_hour(C,R) :- last(C,T), partialSum(C,T,R).
r46: light_rain(C) :- mm_rain_1_hour(C,R), >(R,0;), light_rain_threshold(LTh), &leq(R,LTh;). r47: moderate_rain(C) :- mm_rain_1_hour(C,R), ligh_rain_threshold(LTh), heavy_rain_threshold(HTh), >(R,LTh;), &leq(R,HTh;). r48: heavy_rain(C) :- mm_rain_1_hour(C,R), heavy_rain_threshold(HTh), >(R,HTh;).
3.2.8. Query 8
r49: precedes_rain(M1,M2) :- mm_rain_1_hour(S1,M1), mm_rain_1_hour(S2,M2), S1!=S2, <(M1,M2;). r50: successor_rain(X,Y) :- precedes_rain(X,Y), not inBetween_rain(X,Y). r51: inBetween_rain(X,Y) :- precedes_rain(X,Z), precedes_rain(Z,Y). r52: min_mm_rain_1_hour(M) :- mm_rain_1_hour(S,M), not hasPredecessor_rain(M). r53: least_rainy_city(C) :- mm_rain_1_hour(C,M), min_mm_rain_1_hour(M).
3.2.9. Query 9
r55: wind_now(C,W,@now) :- wind_speed(C,W). r56: wind_10_min(C,W,T) :- wind_now(C,W,T) in [10 min].
r57: precedes(C,T1,T2) :- wind_10_min(C,W1,T1), wind_10_min(C,W2,T2), T1<T2. r58: successor(C,T1,T2) :- precedes(C,T1,T2), not inBetween(C,T1,T2). r59: inBetween(C,T1,T2) :- precedes(C,T1,T3), precedes(C,T3,T2). r60: first(C,T) :- wind_10_min(C,W,T), not hasPredecessor(C,T). r61: last(C,T) :- wind_10_min(C,W,T), not hasSuccessor(C,T). r62: hasPredecessor(C,T1) :- successor(S,T2,T1). r63: hasSuccessor(C,T2) :- successor(C,T2,T1). r64: partialSum(C,T,W) :- first(C,T), wind_10_min(C,W,T). r65: partialSum(C,T2,W3) :- successor(C,T1,T2), wind_10_min(C,W2,T2), partialSum(C,T1,PS), &sum(PS,W2;W3). r66: tot_wind_speed(C,W) :- last(C,T), partialSum(C,T,W). r67: count_wind_speed(C,Count) :- #count{T: wind_10_min(C,W,T)} = Count, station(C). r68: avg_wind_speed(C,Avg) :- &div(Tot,Count;Avg), tot_wind_speed(C,Tot), count_wind_speed(C,Count).
r69: beaufort_level(C,L) :- avg_wind_speed(C,A), &beaufort_scale(A;L). r70: wind_alert(C) :- beaufort_level(C,L), L>6.
3.2.10. Query 10
r71: duration(C,XNext,DNext,@now,L) :- duration(C,X1,D1,T1,L) in {1}, D=@now-T1, DNext=D1+D, XNext=X1+1, beaufort_level(C,L), beaufort_level(C,L) in {1}. r72: duration(C,1,1,@now,L1) :- beaufort_level(C,L1), beaufort_level(C,L2) in {1}, L1!=L2. r73: computed_beaufort_level(C) :- beaufort_level(C,_) in {1}. r74: duration(C,1,1,@now,X) :- beaufort_level(C,X), not computed_beaufort_level(C). r75: duration(C,D,L) :- duration(C,_,D,_,L), beaufort_level(C,L).
3.2.11. Query 4 in LARS
s1: above_threshold_1_h(C) at T1 :- city(C), number(N), threshold_1_hour(T), noise(C,N) at T1 in [1 min], N>=T. s2: noise_copy(C) at T :- city(C), number(N), noise(C,N) at T in [1 min]. s3: above_threshold_1_h(C) at T1 :- city(C), above_threshold_1_h(C) at T in [1 min], not noise_copy(C) at T1 in [1 min], T=T1-1. s4: noise_pollution(C) :- city(C), above_threshold_1_h(C) always [60 min].
4. Baseline Experiments
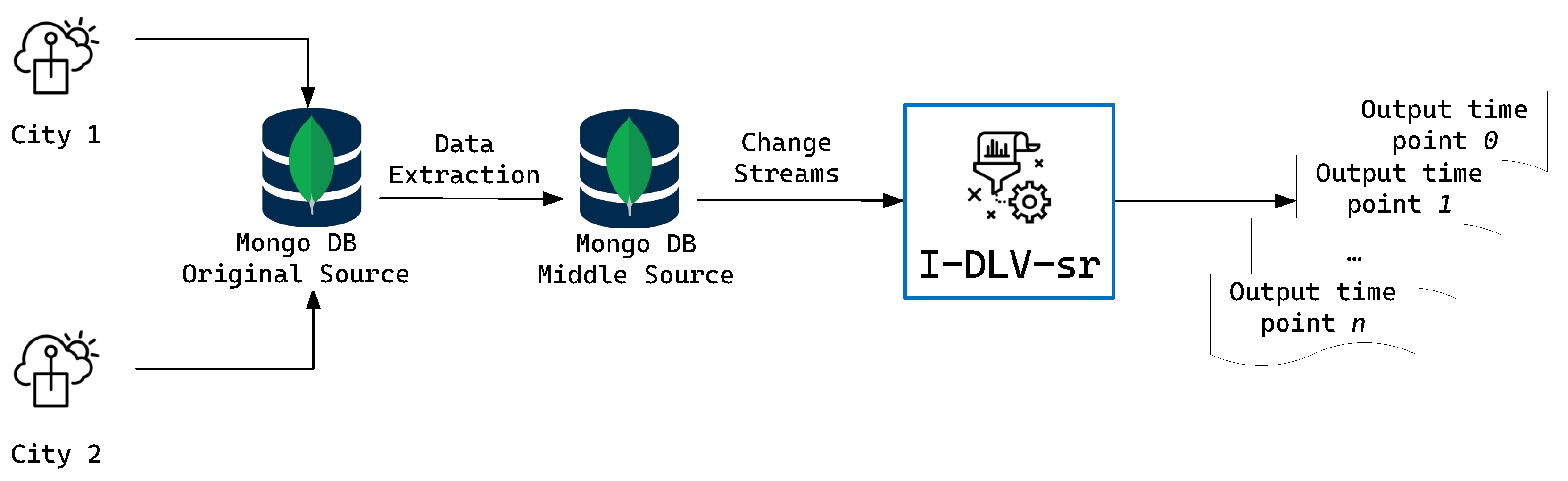
4.1. Experimental Setting
- java –jar I–DLV–sr.jar \
- ––program=path/to/query/encoding \
- ––py–script=path/to/external.py \
- ––mongodb \
- ––mongodb–config=path/to/mongodb/config.yaml \
- ––t–unit=min ––windows–unit=min ––now–format=min,
- java –jar I–DLV–sr.jar \
- ––program=EnviroStream/queries/program/q4.idlvsr \
- ––py-script=EnviroStream/queries/script/external.py \
- ––mongodb \
- ––mongodb–config=EnviroStream/queries/config/q4.yaml \
- ––t–unit=min ––windows-unit=min ––now–format=min.
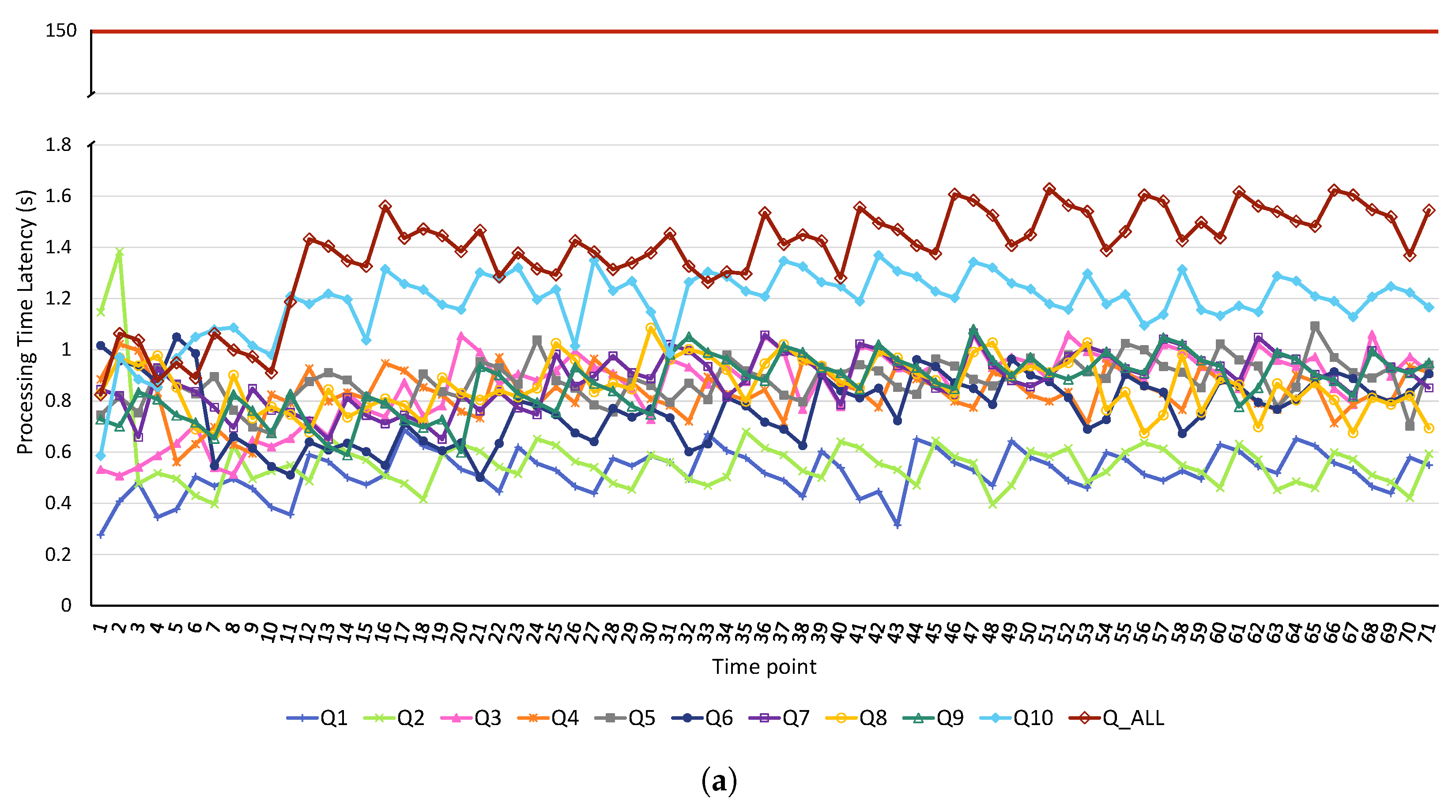
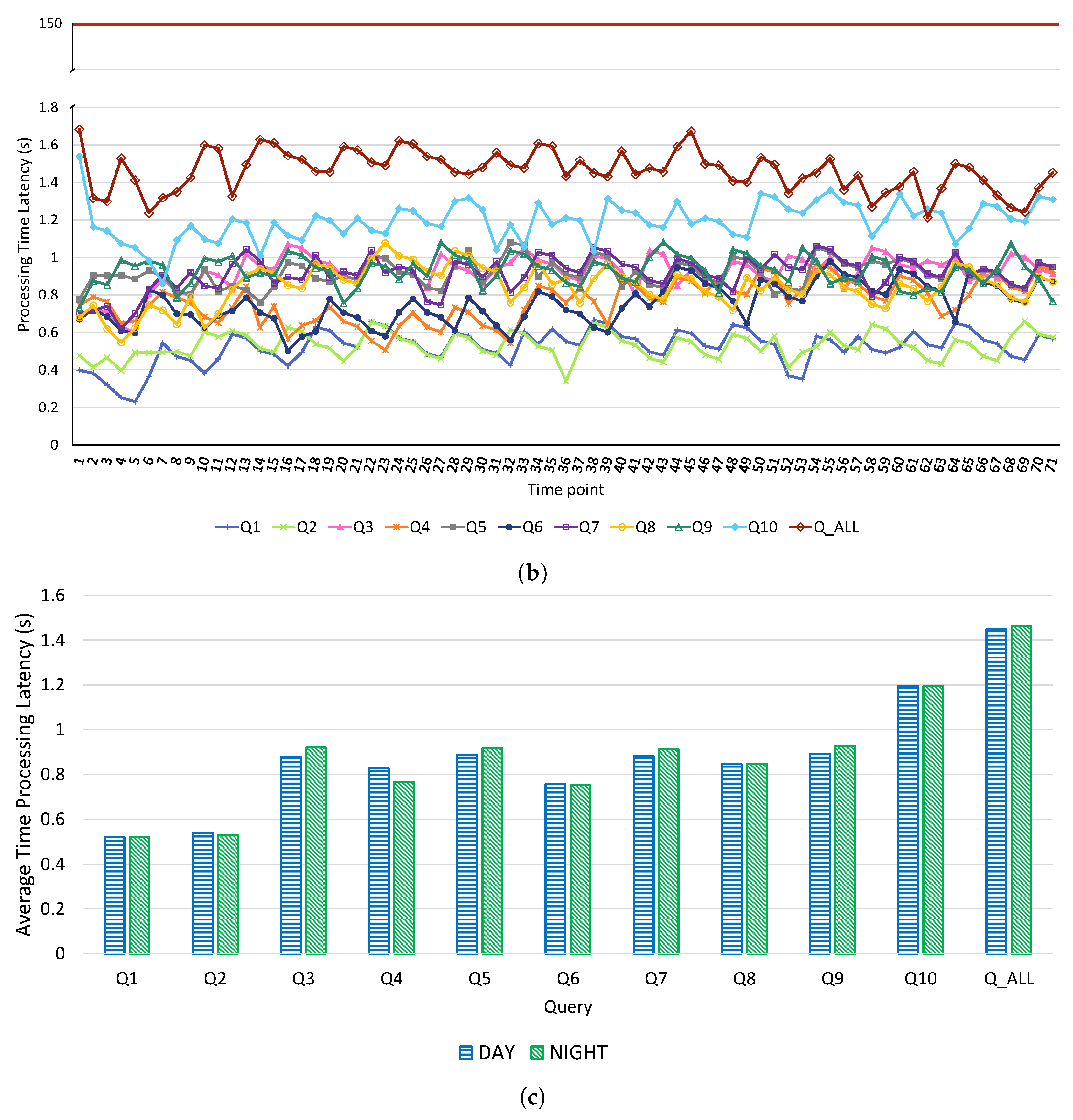
4.2. Results
5. Online Reasoning over EnviroStream via the I-DLV-sr System
- average PM emissions in the last 10 min;
- average PM emissions in the last 10 min;
- number of noise measures above the recommended WHO thresholds (i.e., 65 during day and 55 during night);
- current Humidex level;
- total millimeters of rain fallen in the last hour;
- current Beaufort level on the basis of the average wind speed in the last 10 min.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASP | Answer Set Programming |
| SR | Stream Reasoning |
| SP | Stream Processing |
| CEP | Complex Event Processing |
| KRR | Knowledge Representation and Reasoning |
| PM | Particulate Matter |
References
- Dell’Aglio, D.; Valle, E.D.; van Harmelen, F.; Bernstein, A. Stream reasoning: A survey and outlook. Data Sci. 2017, 1, 59–83. [Google Scholar] [CrossRef] [Green Version]
- Mileo, A.; Dao-Tran, M.; Eiter, T.; Fink, M. Stream Reasoning. In Encyclopedia of Database Systems, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Barbieri, D.F.; Braga, D.; Ceri, S.; Valle, E.D.; Grossniklaus, M. C-SPARQL: A Continuous Query Language for RDF Data Streams. Int. J. Semantic Comput. 2010, 4, 3–25. [Google Scholar] [CrossRef] [Green Version]
- Phuoc, D.L.; Dao-Tran, M.; Parreira, J.X.; Hauswirth, M. A Native and Adaptive Approach for Unified Processing of Linked Streams and Linked Data. In International Semantic Web Conference; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7031, pp. 370–388. [Google Scholar]
- Hoeksema, J.; Kotoulas, S. High-Performance Distributed Stream Reasoning Using s4. In Ordring Workshop at ISWC; 2011; Available online: http://iswc2011.semanticweb.org/fileadmin/iswc/Papers/Workshops/OrdRing/paper_8.pdf (accessed on 1 May 2023).
- Pham, T.; Ali, M.I.; Mileo, A. C-ASP: Continuous ASP-Based Reasoning over RDF Streams. In Logic Programming and Nonmonotonic Reasoning; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11481, pp. 45–50. [Google Scholar]
- Schneider, P.; Alvarez-Coello, D.; Le-Tuan, A.; Duc, M.N.; Phuoc, D.L. Stream Reasoning Playground. In Proceedings of the 19th European Semantic Web Conference, Hersonissos, Greece, 29 May–2 June 2022; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13261, pp. 406–424. [Google Scholar]
- Phuoc, D.L.; Dao-Tran, M.; Pham, M.; Boncz, P.A.; Eiter, T.; Fink, M. Linked Stream Data Processing Engines: Facts and Figures. In Proceedings of the 11th International Semantic Web Conference, Hangzhou, China, 23–27 October 2022; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2012; Volume 7650, pp. 300–312. [Google Scholar]
- Nguyen, T.N.; Siberski, W. SLUBM: An Extended LUBM Benchmark for Stream Reasoning. In Proceedings of the 2nd International Workshop on Ordering and Reasoning, OrdRing 2013, Co-located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, 22 October 2013; Volume 1059, pp. 43–54. [Google Scholar]
- Ali, M.I.; Gao, F.; Mileo, A. CityBench: A Configurable Benchmark to Evaluate RSP Engines Using Smart City Datasets. In International Semantic Web Conference; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9367, pp. 374–389. [Google Scholar]
- Tommasini, R.; Balduini, M.; Valle, E.D. Towards a Benchmark for Expressive Stream Reasoning. In Proceedings of the 2nd RDF Stream Processing (RSP 2017) and the Querying the Web of Data (QuWeDa 2017) Workshops Co-Located with 14th ESWC 2017 (ESWC 2017), Portoroz, Slovenia, 28–29 May 2017; Volume 1870, pp. 26–36. [Google Scholar]
- Pitsikalis, M.; Artikis, A.; Dreo, R.; Ray, C.; Camossi, E.; Jousselme, A. Composite Event Recognition for Maritime Monitoring. In Proceedings of the 13th ACM International Conference on Distributed and Event-Based Systems, Darmstadt, Germany, 24–28 June 2019; ACM: Boston, MA, USA, 2019; pp. 163–174. [Google Scholar]
- Calimeri, F.; Manna, M.; Mastria, E.; Morelli, M.C.; Perri, S.; Zangari, J. I-DLV-sr: A Stream Reasoning System based on I-DLV. Theory Pract. Log. Program. 2021, 21, 610–628. [Google Scholar] [CrossRef]
- Huler, S. Defining the Wind: The Beaufort Scale and How a 19th-Century Admiral Turned Science into Poetry; Crown: New York, NY, USA, 2007. [Google Scholar]
- Gelfond, M.; Lifschitz, V. Classical Negation in Logic Programs and Disjunctive Databases. New Gener. Comput. 1991, 9, 365–386. [Google Scholar] [CrossRef] [Green Version]
- Brewka, G.; Eiter, T.; Truszczynski, M. Answer set programming at a glance. Commun. ACM 2011, 54, 92–103. [Google Scholar] [CrossRef]
- Lifschitz, V. Answer Set Programming; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Calimeri, F.; Ianni, G.; Pacenza, F.; Perri, S.; Zangari, J. ASP-based Multi-shot Reasoning via DLV2 with Incremental Grounding. In Proceedings of the 24th International Symposium on Principles and Practice of Declarative Programming, Tbilisi, Georgia, 20–22 September 2022; ACM: Boston, MA, USA, 2022; pp. 2:1–2:9. [Google Scholar]
- Ianni, G.; Pacenza, F.; Zangari, J. Incremental maintenance of overgrounded logic programs with tailored simplifications. Theory Pract. Log. Program. 2020, 20, 719–734. [Google Scholar] [CrossRef]
- Beck, H.; Eiter, T.; Folie, C. Ticker: A system for incremental ASP-based stream reasoning. Theory Pract. Log. Program. 2017, 17, 744–763. [Google Scholar] [CrossRef] [Green Version]
- Eiter, T.; Ogris, P.; Schekotihin, K. A Distributed Approach to LARS Stream Reasoning (System paper). Theory Pract. Log. Program. 2019, 19, 974–989. [Google Scholar] [CrossRef] [Green Version]
- Beck, H.; Dao-Tran, M.; Eiter, T. LARS: A Logic-based framework for Analytic Reasoning over Streams. Artif. Intell. 2018, 261, 16–70. [Google Scholar] [CrossRef]





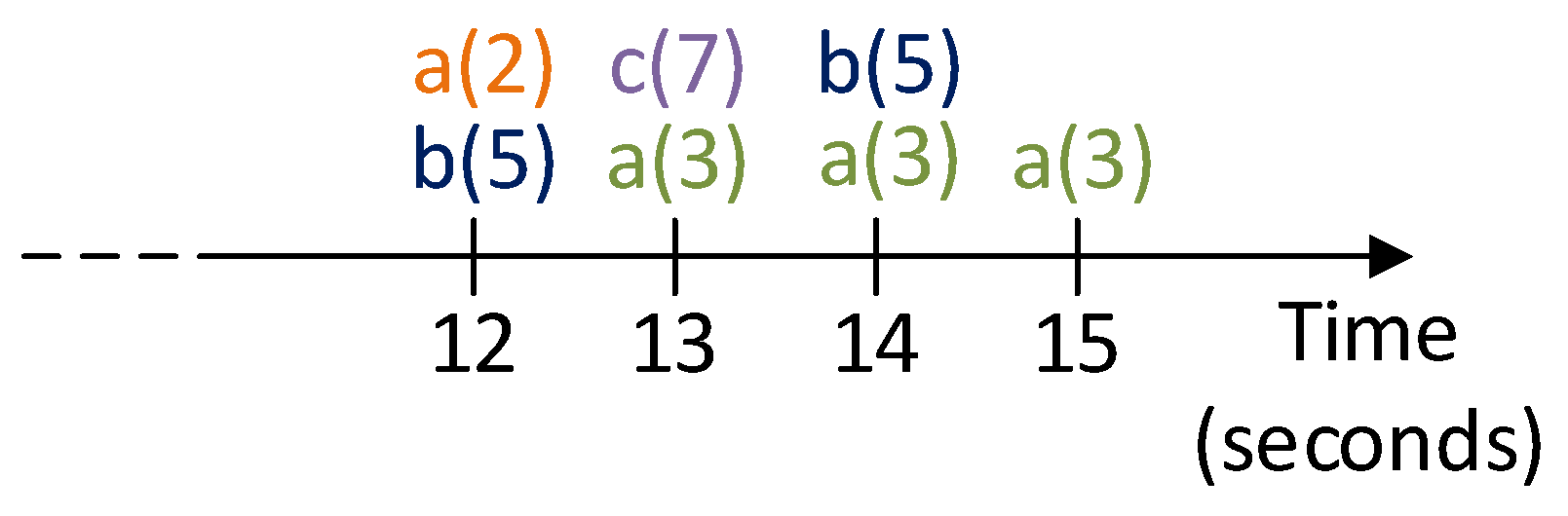{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive Literal | Holds | Negative Literal | Holds |
|---|---|---|---|
| b(5) always in [2 sec] | No | not b(5) always in [2 sec] | Yes |
| a(3) always in [2 sec] | Yes | not a(3) always in [2 sec] | No |
| a(3) always in {0,2,3} | No | not a(3) always in {0,2,3} | Yes |
| b(5) count 2 in [2 sec] | No | not b(5) count 2 in [2 sec] | Yes |
| b(5) count 1 in [2 sec] | Yes | not b(5) count 1 in [2 sec] | No |
| b(5) count 1 in {1,3} | No | not b(5) count 1 in {1,3} | Yes |
| b(5) at least 2 in [2 sec] | No | not b(5) at least 2 in [2 sec] | Yes |
| b(5) at least 1 in [2 sec] | Yes | not b(5) at least 1 in [2 sec] | No |
| b(5) at least 2 in {1,3} | Yes | not b(5) at least 1 in {1,3} | No |
| a(3) at most 2 in [2 sec] | No | not a(3) at most 2 in [2 sec] | Yes |
| b(5) at most 1 in [2 sec] | Yes | not b(5) at most 1 in [2 sec] | No |
| b(5) at most 1 in {0,2} | Yes | not b(5) at most 1 in {0,2} | No |
| Type | Atom | Meaning |
|---|---|---|
| Static | station(C) | Weather station of city C |
| maximum_allowed_pm10(X) | X is the maximum PM allowed | |
| maximum_allowed_pm2_5(X) | X is the maximum PM allowed | |
| day_threshold(X) | X is the noise limit during day | |
| night_threshold(X) | X is the noise limit during night | |
| threshold_1_hour(X) | X is the noise exposure limit over a hour | |
| light_rain_threshold(X) | X is the light rain threshold over a hour | |
| heavy_rain_threshold(X) | X is the heavy rain threshold over a hour | |
| Dynamic | pm10(C,V) | V is the current PM level in city C |
| pm2_5(C,V) | V is the current PM level in city C | |
| noise(C,V) | V is the current noise in city C | |
| temperature(C,V) | V is the current temperature in city C | |
| humidity(C,V) | V is the current humidity in city C | |
| rain(C,V) | V is the current rain in city C | |
| wind_speed(C,V) | V is the current wind speed in city C |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mastria, E.; Pacenza, F.; Zangari, J.; Calimeri, F.; Perri, S.; Terracina, G. EnviroStream: A Stream Reasoning Benchmark for Environmental and Climate Monitoring. Big Data Cogn. Comput. 2023, 7, 135. https://doi.org/10.3390/bdcc7030135
Mastria E, Pacenza F, Zangari J, Calimeri F, Perri S, Terracina G. EnviroStream: A Stream Reasoning Benchmark for Environmental and Climate Monitoring. Big Data and Cognitive Computing. 2023; 7(3):135. https://doi.org/10.3390/bdcc7030135
Chicago/Turabian StyleMastria, Elena, Francesco Pacenza, Jessica Zangari, Francesco Calimeri, Simona Perri, and Giorgio Terracina. 2023. "EnviroStream: A Stream Reasoning Benchmark for Environmental and Climate Monitoring" Big Data and Cognitive Computing 7, no. 3: 135. https://doi.org/10.3390/bdcc7030135
APA StyleMastria, E., Pacenza, F., Zangari, J., Calimeri, F., Perri, S., & Terracina, G. (2023). EnviroStream: A Stream Reasoning Benchmark for Environmental and Climate Monitoring. Big Data and Cognitive Computing, 7(3), 135. https://doi.org/10.3390/bdcc7030135