
Classification and Recognition of Lung Sounds Using Artificial Intelligence and Machine Learning: A Literature Review


Abstract
:1. Introduction
2. Methodology Overview
- The article must be published in a highly cited and recognized academic journal or conference, such as IEEE, Springer, ScienceDirect, etc.
- The article must have a clear methodology, experimental results, and conclusions.
- Priority is given to articles published within the past five years to ensure the timeliness of the review.
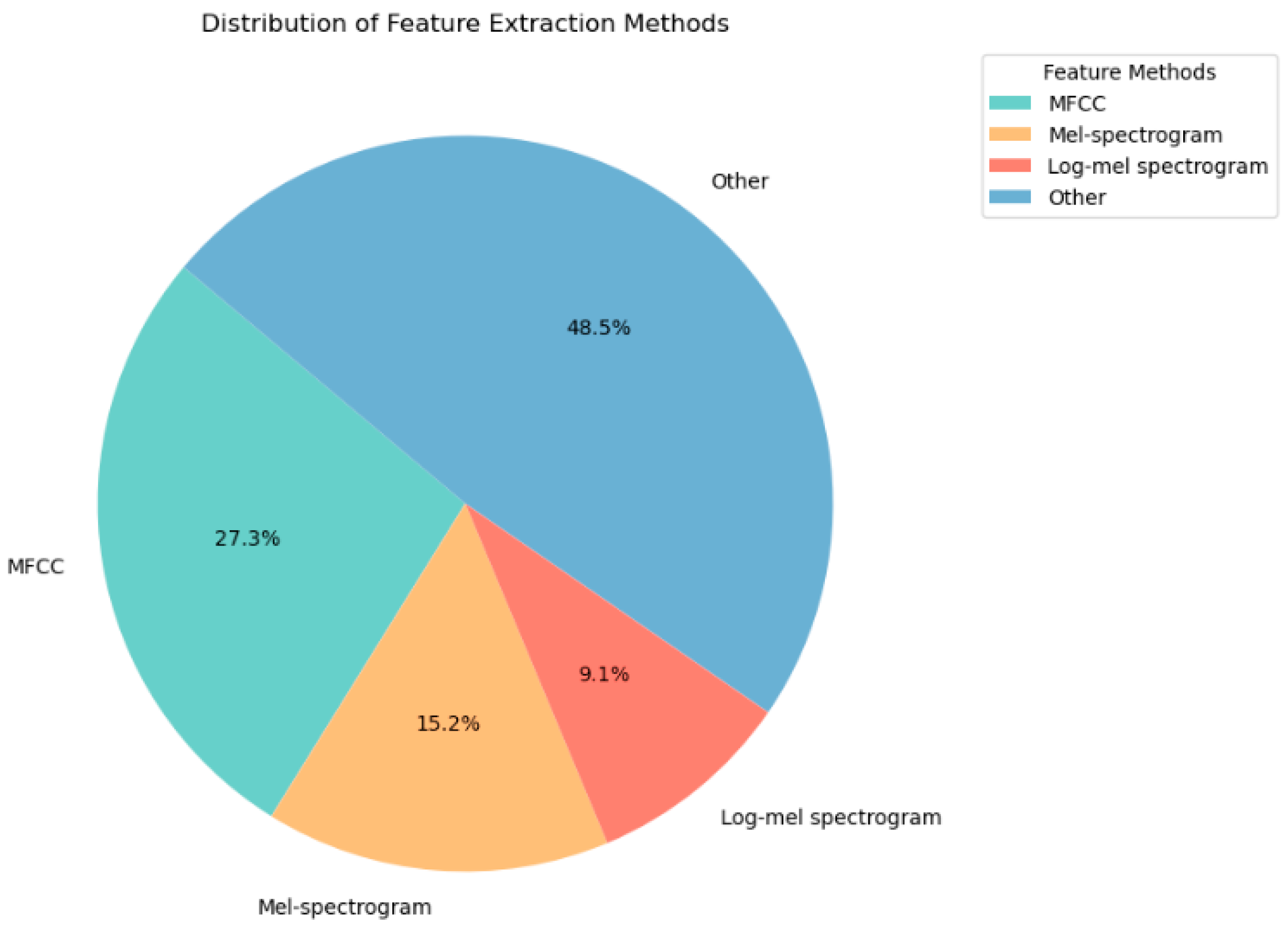
2.1. Feature Extraction Methods for Lung Sounds
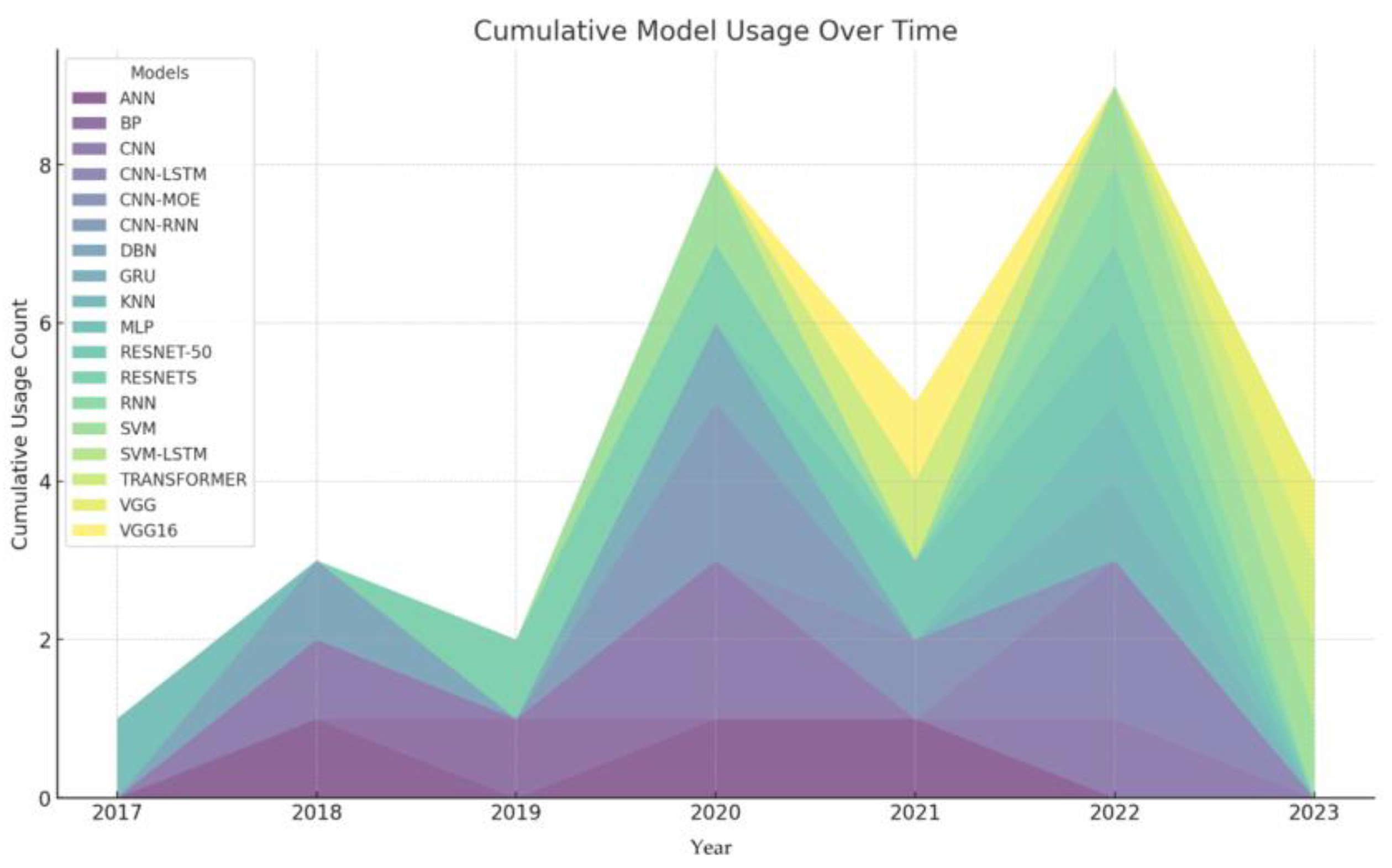
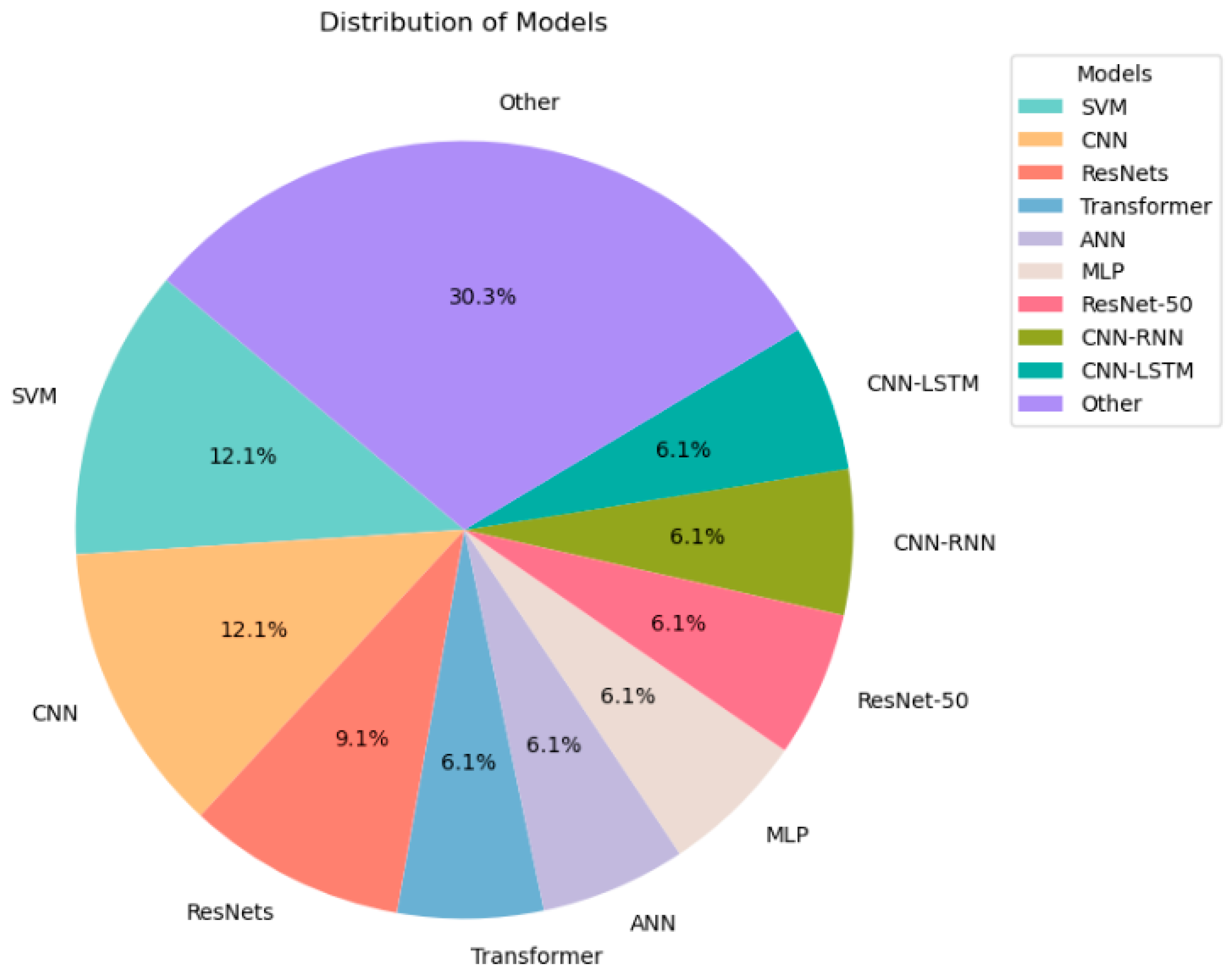
2.2. Machine Learning Methods for Lung Sounds
2.3. Other Methods
3. Shortcomings of Current Research
4. Future Research Direction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lehrer, S. Understanding Lung Sounds; W.B. Saunders Company: Philadelphia, PA, USA, 2018. [Google Scholar]
- Gurung, A.; Scrafford, C.G.; Tielsch, J.M.; Levine, O.S.; Checkley, W. Computerized lung sound analysis as diagnostic aid for the detection of abnormal lung sounds: A systematic review and meta-analysis. Respir. Med. 2011, 105, 1396–1403. [Google Scholar] [CrossRef] [PubMed]
- Palaniappan, R.; Sundaraj, K.; Ahamed, N.U. Machine learning in lung sound analysis: A systematic review. Biocybern. Biomed. Eng. 2013, 33, 129–135. [Google Scholar] [CrossRef]
- Pasterkamp, H.; Brand, P.L.; Everard, M.; Garcia-Marcos, L.; Melbye, H.; Priftis, K.N. Towards the standardisation of lung sound nomenclature. Eur. Respir. J. 2016, 47, 724–732. [Google Scholar] [CrossRef] [PubMed]
- Walker, H.K.; Hall, W.D.; Hurst, J.W. (Eds.) Clinical Methods: The History, Physical, and Laboratory Examinations, 3rd ed.; Butterworths: London, UK, 1990. [Google Scholar]
- Gern, J.E. The ABCs of rhinoviruses, wheezing, and asthma. J. Virol. 2010, 84, 7418–7426. [Google Scholar] [CrossRef]
- Yang, I.A.; Brown, J.L.; George, J.; Jenkins, S.; McDonald, C.F.; McDonald, V.M.; Phillips, K.; Smith, B.J.; Zwar, N.A.; Dabscheck, E. COPD-X Australian and New Zealand guidelines for the diagnosis and management of chronic obstructive pulmonary disease: 2017 update. Med. J. Aust. 2017, 207, 436–442. [Google Scholar] [CrossRef]
- Cottin, V.; Cordier, J.-F. Velcro crackles: The key for early diagnosis of idiopathic pulmonary fibrosis? Eur. Respir. J. 2012, 40, 519–521. [Google Scholar] [CrossRef]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Banerjee, A.; Nilhani, A. A residual network based deep learning model for detection of COVID-19 from cough sounds. arXiv 2021, arXiv:2106.02348. [Google Scholar]
- Islam, M.A.; Bandyopadhyaya, I.; Bhattacharyya, P.; Saha, G. Multichannel lung sound analysis for asthma detection. Comput. Methods Programs Biomed. 2018, 159, 111–123. [Google Scholar] [CrossRef] [PubMed]
- Demirci, B.A.; Koçyiğit, Y.; Kızılırmak, D.; Havlucu, Y. Adventitious and Normal Respiratory Sound Analysis with Machine Learning Methods. Celal Bayar Univ. J. Sci. 2021, 18, 169–180. [Google Scholar] [CrossRef]
- Demir, F.; Ismael, A.M.; Sengur, A. Classification of lung sounds with CNN model using parallel pooling structure. IEEE Access 2020, 8, 105376–105383. [Google Scholar] [CrossRef]
- Islam, M.A.; Bandyopadhyaya, I.; Bhattacharyya, P.; Saha, G. Classification of normal, Asthma and COPD subjects using multichannel lung sound signals. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Perna, D. Convolutional neural networks learning from respiratory data. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Acharya, J.; Basu, A. Deep neural network for respiratory sound classification in wearable devices enabled by patient specific model tuning. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 535–544. [Google Scholar] [CrossRef] [PubMed]
- Meng, F.; Shi, Y.; Wang, N.; Cai, M.; Luo, Z. Detection of respiratory sounds based on wavelet coefficients and machine learning. IEEE Access 2020, 8, 155710–155720. [Google Scholar] [CrossRef]
- Rani, S.; Chaurasia, A.; Dutta, M.K.; Myska, V.; Burget, R. Machine learning approach for automatic lungs sound diagnosis from pulmonary signals. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Virtual, 26–28 July 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Paraschiv, E.-A.; Rotaru, C.-M. Machine learning approaches based on wearable devices for respiratory diseases diagnosis. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Abdullah, S.; Demosthenous, A.; Yasin, I. Comparison of Auditory-Inspired Models Using Machine-Learning for Noise Classification. Int. J. Simul.—Syst. Sci. Technol. 2020, 21. [Google Scholar] [CrossRef]
- Xue, H.; Salim, F.D. Exploring self-supervised representation ensembles for COVID-19 cough classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021. [Google Scholar]
- Kim, Y.; Hyon, Y.; Jung, S.S.; Lee, S.; Yoo, G.; Chung, C.; Ha, T. Respiratory sound classification for crackles, wheezes, and rhonchi in the clinical field using deep learning. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Q.; Sun, W.; Chen, F.; Lin, D.; Chen, F. Research on lung sound classification model based on dual-channel CNN-LSTM algorithm. Biomed. Signal Process. Control. 2024, 94, 106257. [Google Scholar] [CrossRef]
- Zhu, H.; Lai, J.; Liu, B.; Wen, Z.; Xiong, Y.; Li, H.; Zhou, Y.; Fu, Q.; Yu, G.; Yan, X.; et al. Automatic pulmonary auscultation grading diagnosis of Coronavirus Disease 2019 in China with artificial intelligence algorithms: A cohort study. Comput. Methods Programs Biomed. 2021, 213, 106500. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.; Pernkopf, F. Lung Sound Classification Using Co-tuning and Stochastic Normalization. IEEE Trans. Biomed. Eng. 2022, 69, 2872–2882. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, X.; Li, Y. LungRN+ NL: An Improved Adventitious Lung Sound Classification Using Non-Local Block ResNet Neural Network with Mixup Data Augmentation. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Altan, G.; Kutlu, Y.; Pekmezci, A.; Nural, S. Deep learning with 3D-second order difference plot on respiratory sounds. Biomed. Signal Process. Control. 2018, 45, 58–69. [Google Scholar] [CrossRef]
- Petmezas, G.; Cheimariotis, G.-A.; Stefanopoulos, L.; Rocha, B.; Paiva, R.P.; Katsaggelos, A.K.; Maglaveras, N. Automated Lung Sound Classification Using a Hybrid CNN-LSTM Network and Focal Loss Function. Sensors 2022, 22, 1232. [Google Scholar] [CrossRef]
- Chen, H.; Yuan, X.; Pei, Z.; Li, M.; Li, J. Triple-classification of respiratory sounds using optimized s-transform and deep residual networks. IEEE Access 2019, 7, 32845–32852. [Google Scholar] [CrossRef]
- Basu, V.; Rana, S. Respiratory diseases recognition through respiratory sound with the help of deep neural network. In Proceedings of the 2020 4th International Conference on Computational Intelligence and Networks (CINE), Kolkata, India, 27–29 February 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Shi, Y.; Li, Y.; Cai, M.; Zhang, X.D. A lung sound category recognition method based on wavelet decomposition and BP neural network. Int. J. Biol. Sci. 2019, 15, 195–207. [Google Scholar] [CrossRef] [PubMed]
- Kwon, A.M.; Kang, K. A temporal dependency feature in lower dimension for lung sound signal classification. Sci. Rep. 2022, 12, 7889. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.X.; Yang, Y.; Chen, Y.H. Lung sound classification based on Hilbert-Huang transform features and multilayer perceptron network. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. (CSUR) 2020, 55, 1–28. [Google Scholar] [CrossRef]
- Dubey, R.; Bodade, R.M.; Dubey, D. Efficient classification of the adventitious sounds of the lung through a combination of SVM-LSTM-Bayesian optimization algorithm with features based on wavelet bi-phase and bi-spectrum. Res. Biomed. Eng. 2023, 39, 349–363. [Google Scholar] [CrossRef]
- Abera Tessema, B.; Nemomssa, H.D.; Lamesgin Simegn, G. Acquisition and classification of lung sounds for improving the efficacy of auscultation diagnosis of pulmonary diseases. Med. Devices Evid. Res. 2022, 15, 89–102. [Google Scholar] [CrossRef] [PubMed]
- Lal, K.N. A lung sound recognition model to diagnoses the respiratory diseases by using transfer learning. Multimed. Tools Appl. 2023, 82, 36615–36631. [Google Scholar] [CrossRef]
- Pham, L.; Phan, H.; Palaniappan, R.; Mertins, A.; McLoughlin, I. CNN-MoE based framework for classification of respiratory anomalies and lung disease detection. IEEE J. Biomed. Health Inform. 2021, 25, 2938–2947. [Google Scholar] [CrossRef]
- Amose, J.; Manimegalai, P. Classification of Adventitious Lung Sounds: Wheeze, Crackle using Machine Learning Techniques. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 1143–1152. [Google Scholar]
- Levy, J.; Naitsat, A.; Zeevi, Y.Y. Classification of audio signals using spectrogram surfaces and extrinsic distortion measures. EURASIP J. Adv. Signal Process. 2022, 2022, 100. [Google Scholar] [CrossRef]
- Rocha, B.M.; Filos, D.; Mendes, L.; Vogiatzis, I.; Perantoni, E.; Kaimakamis, E.; Natsiavas, P.; Oliveira, A.; Jácome, C.; Marques, A.; et al. A respiratory sound database for the development of automated classification. In Precision Medicine Powered by pHealth and Connected Health: ICBHI 2017, Thessaloniki, Greece, 18–21 November 2017; Springer: Singapore, 2018. [Google Scholar]
- Zhao, G.; Sonsaat, S.; Silpachai, A.; Lucic, I.; Chukharev-Hudilainen, E.; Levis, J.; Gutierrez-Osuna, R. L2-ARCTIC: A non-native English speech corpus. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Kapoor, T.; Pandhi, T.; Gupta, B. Cough Audio Analysis for COVID-19 Diagnosis. SN Comput. Sci. 2022, 4, 125. [Google Scholar] [CrossRef]
- Khanzada, A.; Wilson, T. Virufy COVID-19 Open Cough Dataset, Github (2020). 2021. Available online: https://github.com/virufy/virufy-data (accessed on 12 September 2024).
- Siebert, J.N.; Hartley, M.-A.; Courvoisier, D.S.; Salamin, M.; Robotham, L.; Doenz, J.; Barazzone-Argiroffo, C.; Gervaix, A.; Bridevaux, P.-O. Deep learning diagnostic and severity-stratification for interstitial lung diseases and chronic obstructive pulmonary disease in digital lung auscultations and ultrasonography: Clinical protocol for an observational case–control study. BMC Pulm. Med. 2023, 23, 191. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Loizou, P.C. Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun. 2006, 49, 588–601. [Google Scholar] [CrossRef] [PubMed]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8. [Google Scholar]
- Ellis, D.P.W. Gammatone-like Spectrograms. 2009. Available online: https://www.ee.columbia.edu/~dpwe/resources/matlab/gammatonegram/ (accessed on 12 September 2024).
- Kou, Z.; You, K.; Long, M.; Wang, J. Stochastic normalization. Adv. Neural Inf. Process. Syst. 2020, 33, 16304–16314. [Google Scholar]
- Jiang, Y.; Li, X.; Luo, H.; Yin, S.; Kaynak, O. Quo vadis artificial intelligence? Discov. Artif. Intell. 2022, 2, 4. [Google Scholar] [CrossRef]

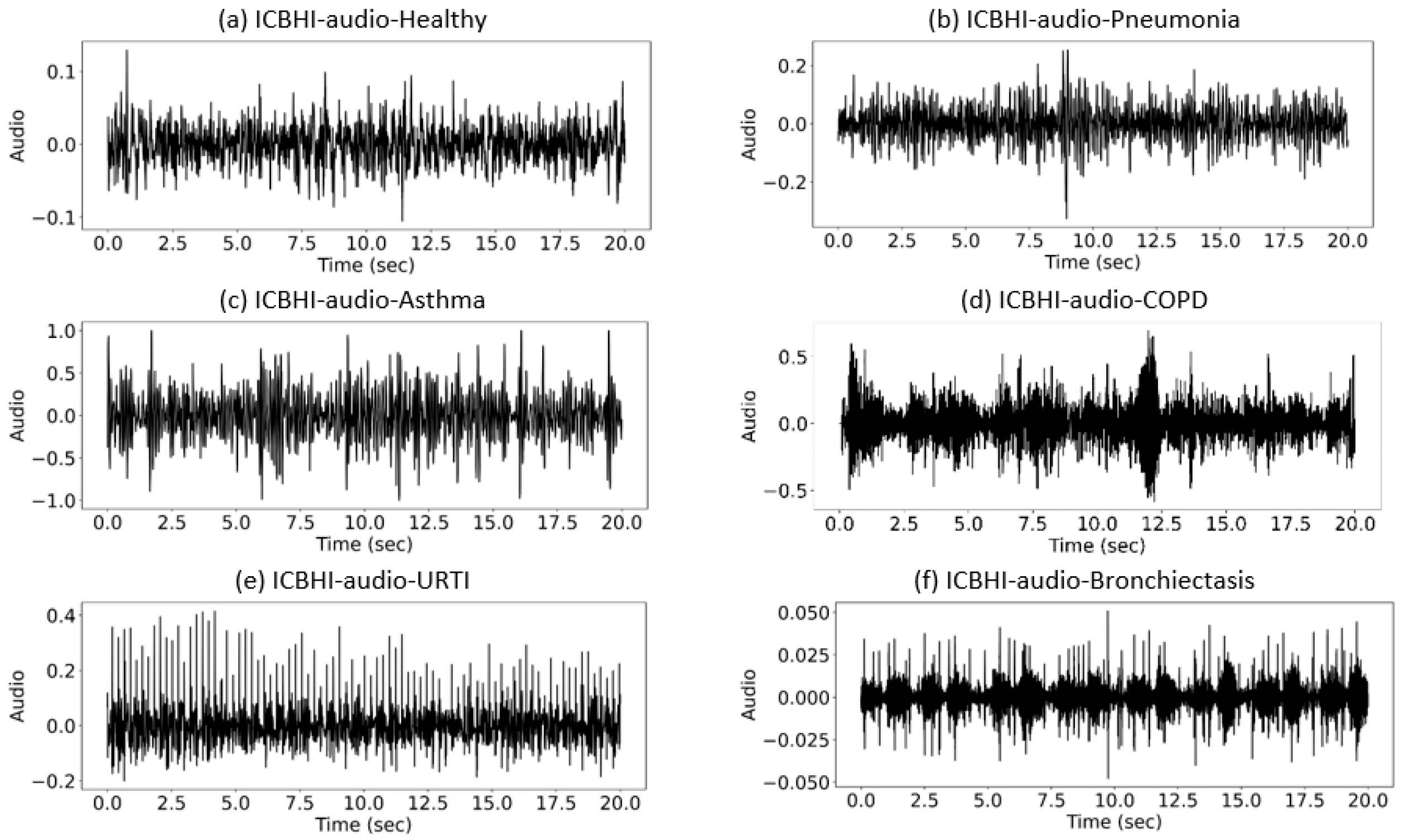

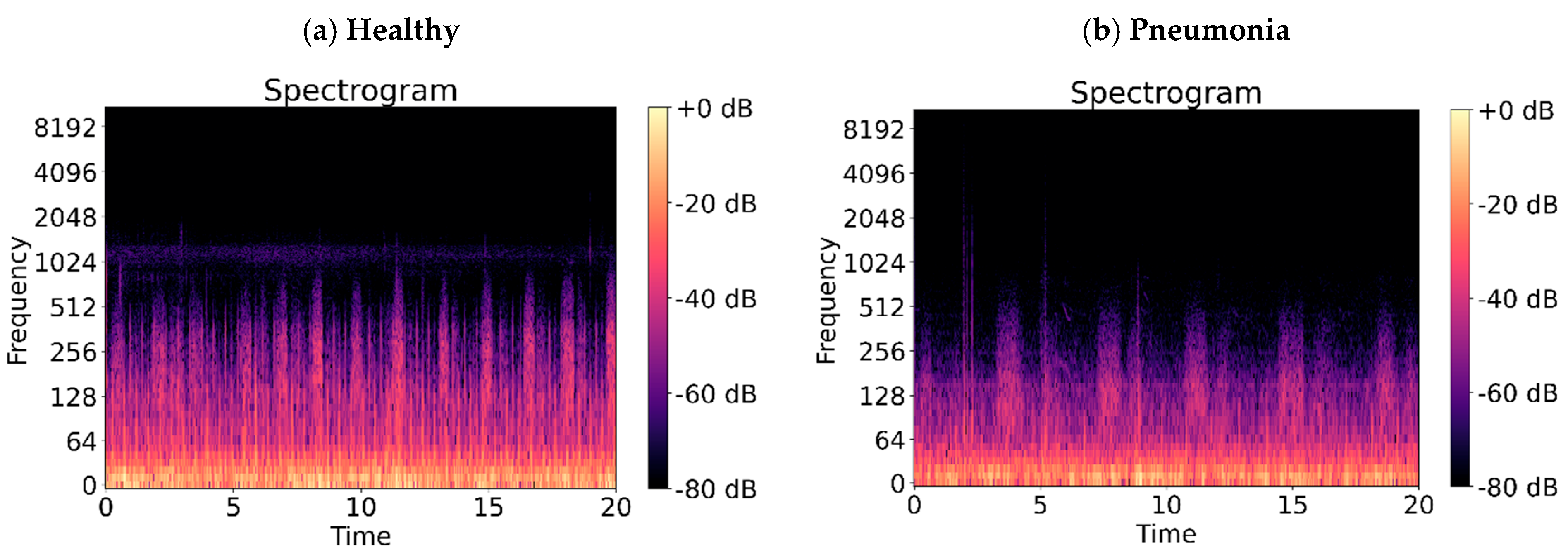
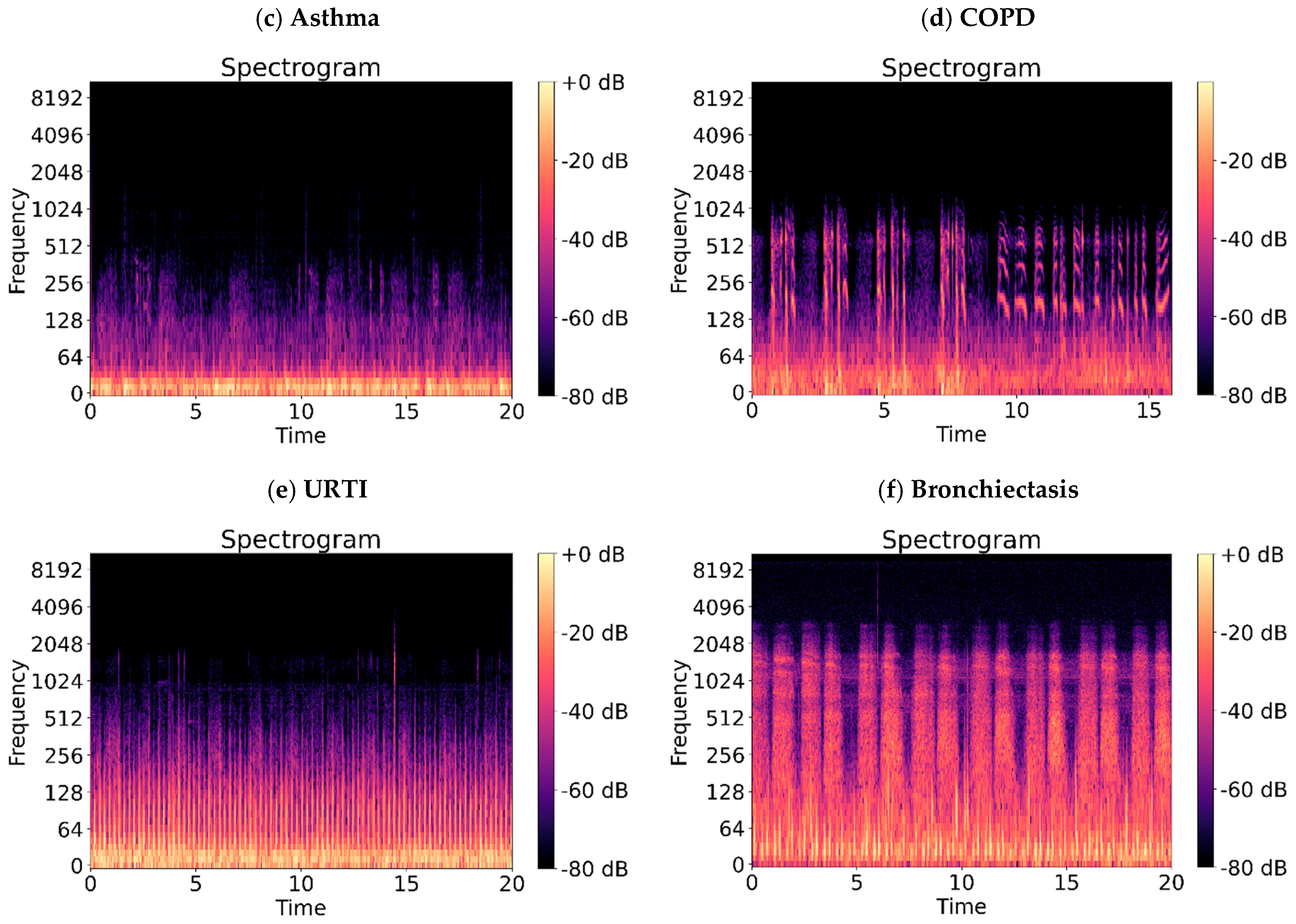
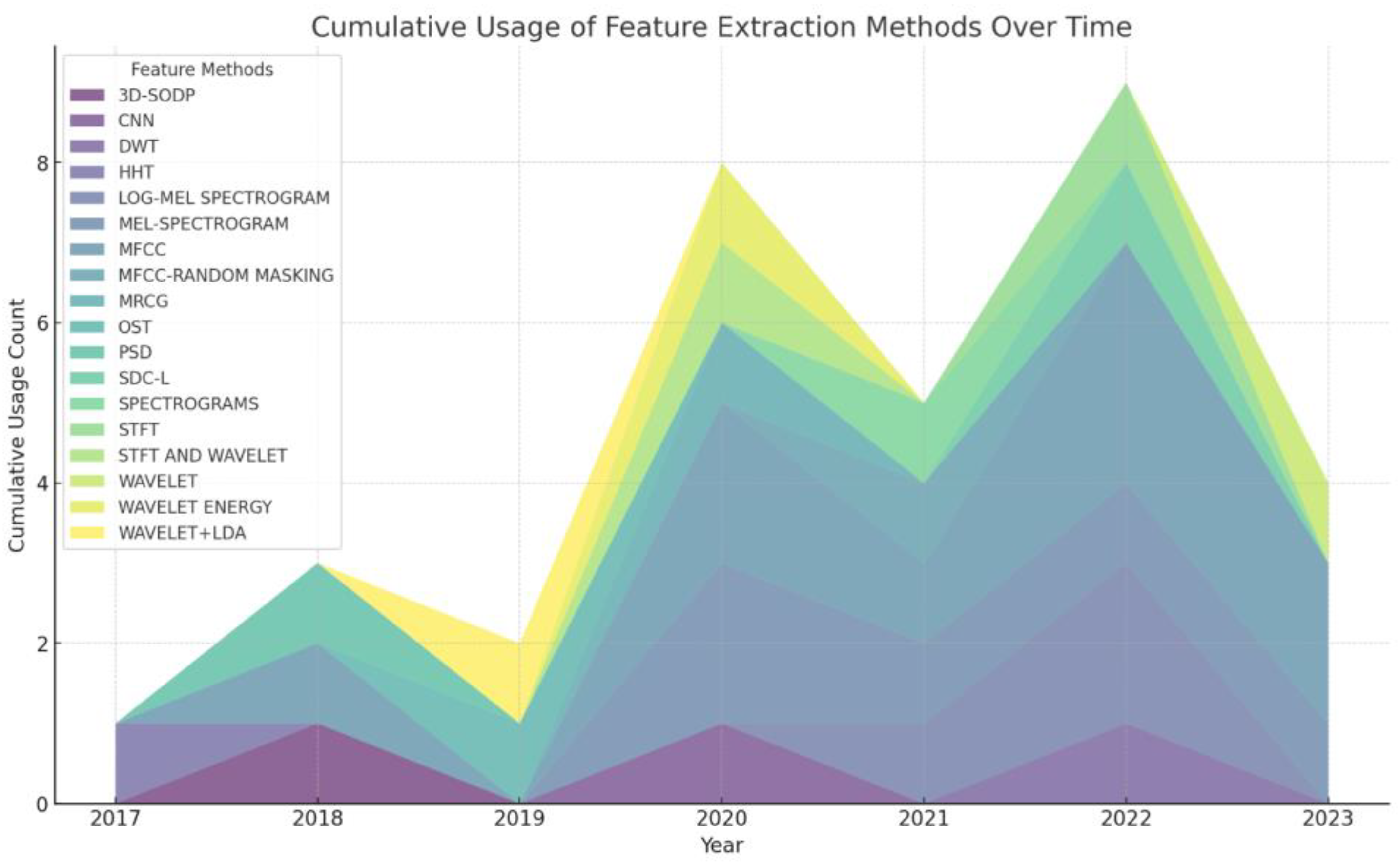

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abnormal Lung Sounds | Sound Characteristics | Common Diseases |
|---|---|---|
| Rhonchus | Low-pitched sonorous sound | Chronic obstructive pulmonary disease (COPD) |
| Wheeze | High-pitched whistling sound | Asthma or bronchoconstriction |
| Coarse crackle | Low-pitched popping or crackling sound | Bronchiectasis or pneumonia |
| Thin crackle | High-pitched fine or soft crackling sound | Interstitial lung disease or atelectasis |
| Ref | Sounds | Dataset | Feature Extraction | Method | Outcome |
|---|---|---|---|---|---|
| [11] | Asthma | 4 channels to collect 60 people | Spectral sub-band | ANN, SVM | The SVM yields better classification performance. The best classification accuracies of 2-channel and 3-channel combinations in ANN and SVM classifiers reach 89.2% and 93.3%, respectively. The proposed multi-channel asthma detection method outperforms commonly used lung sound classification methods. |
| [12] | Rhonchus wheeze | 25 healthy and 25 patients | EMD, MFCC, WT | ANN, SVM, KNN | The best accuracy is 98.8% by using Mel-frequency cepstral coefficients with the k-nearest neighbor method. |
| [14] | Asthma, COPD | 4 channels collect 60 people | PSD | ANN | When information from all four channels is used together, the proposed multi-channel-based multi-class classification system achieves reasonable classification accuracy, well above theoretical and empirical chance levels. |
| [17] | Crackle rhonchi | 130 patients | RWE, WE | SVM, ANN, KNN | The feature vector in this article was the combination of wavelet signal similarity, relative wavelet energy, and wavelet entropy. The SVM, ANN, and KNN all have average classification accuracies of 69.50, 85.43, and 68.51%, respectively. |
| [18] | Bronchial, crepitation, wheeze | 233 records | MFCC | ANN | Because lung sounds mainly lie between 100 Hz and 500 Hz, we use amplitude normalization and frequency filtering, where frequencies above 500 Hz in the signal are removed. Using data augmentation techniques such as white noise addition and sound shifting improves the model’s robustness to sound recognition in noisy environments. These techniques help the model better adapt to various noise conditions that may be encountered in practical applications. The 5-fold ANN accuracy rate is 95.6%. |
| [20] | Speech | NOIZEUS [46] | AIM, MRCG | SVM | The MRCG method processes sound to create time–frequency representations at multiple resolutions, capturing both the local and broader spectral–temporal context. The AIM simulates peripheral and central auditory processing to capture the fine temporal structure of sounds through the process of converting neural activity patterns into stable auditory images. AIM generally performs worse than MRCG. Using the MRCG model combined with the SVM, the classification accuracy was higher than 80% in most test environments, with an average accuracy of 89.8%. |
| [33] | Lung sound | 51 pieces | HHT | MLP | Through the Hilbert–Huang transform, the sound signal is decomposed into different intrinsic mode functions (intrinsic mode functions, IMFs). These IMFs can better express the essential characteristics of the original signal. Feature extraction involves extracting relevant features from individual IMFs that reflect specific properties of lung sounds. Together with the multilayer perceptron, it achieved an accuracy of 95.84%. |
| [36] | Lung sound | Jimma University Medical Center (JUMC) and ICBHI 2017 [41] | DWT | SVM | This study attempts to classify lung disease sounds using several different features. Different features can help classify different lung diseases. Lung sounds were analyzed using wavelet multiresolution analysis. To select the most relevant features, one-way ANOVA was used for feature selection. Using the optimized Fine Gaussian SVM classifier, the test classification accuracy for seven lung diseases was 99%, the specificity was 99.2%, and the sensitivity was 99.04%. |
| [39] | Crackle, wheeze | From the Kaggle website, comprising 920 annotated sounds from 126 individuals | MFCC | SVM | The article discusses the use of machine learning techniques to classify wheezes and rales during lung auscultation. Specifically, the study used two classifiers, the support vector machine (SVM) and decision tree (DT) classifiers. Experimentally, the SVM classifier showed higher accuracy than the decision tree; therefore, the SVM is a more efficient choice for such audio signal classification. The accuracy of the SVM is 80%; for the decision tree, it is 65%. |
| [40] |
Lung sound,
speech sound | ICBHI 2017 [41], The L2-Arctic database [42] | Overlap discrete wavelet transform (MODWT) and a Mel spectrogram | RNN | In the article, the specific method of feature extraction is by representing the one-dimensional audio signal as a two-dimensional manifold surface embedded in a three-dimensional space. Geometric properties of these surfaces, such as surface curvature and distance measures, are used to extract features from the signal. The specific method is called geometric feature extraction. The benchmark model used in this article is RNN. This model uses the adaptive block coordinate descent (ABCD) algorithm to optimize mapping, with a specific accuracy rate of up to 88%. |
| [43] | COVID-19 | COVID-19 cough dataset [44] | MFCC | MLP | The study employed a MLP, a CNN, an RNN, and an SVM to classify cough audio samples for COVID-19 diagnosis, utilizing MFCC feature extraction methods and a multilayer perceptron model for effective classification. The model’s performance was evaluated based on accuracy (96%), precision, and recall, demonstrating its potential in aiding COVID-19 diagnosis. |
| Ref | Sounds | Dataset | Feature Extraction | Method | Outcome |
|---|---|---|---|---|---|
| [10] | COVID-19 coughs | DiCOVA Challenge | log–Mel spectrogram | ResNet-50 | A 98.88% average validation was found for the AUC. In addition, the model was applied to the blind test set released by the DiCOVA Challenge, and the test AUC reached 75.91%, the test specificity reached 62.50%, and the test sensitivity reached 80.49%. |
| [15] | Lung sound | ICBHI 2017 [41] | MFCC | CNN | Using undersampling techniques means limiting the number of instances of underrepresented classes to just a few samples. The accuracy rate of two classifications is 0.83, and the accuracy rate of three classifications is 0.82. |
| [16] | Wheeze, crackle | ICBHI 2017 [41] | Mel spectrograms | CNN–RNN | With 10-fold cross-validation, the average score obtained is 66.43. The newly introduced technique for weight quantization effectively reduces the total memory usage by approximately fourfold without compromising performance. This approach of retraining with a focus on individual patient data proves highly beneficial for the development of dependable, long-term automated monitoring systems, particularly in wearable health technologies. |
| [19] | Lung sound | ICBHI 2017 [41] | MFCC | CNN | This paper uses a combination of Mel-frequency cepstral coefficients and convolutional neural networks to classify lung sounds with an accuracy of 90.21%. |
| [22] | Lung sound | ICBHI 2017 [41] | Mel spectrogram | VGG16 | The lung sound signal is converted into a Mel spectrogram as input data and then trained using the VGG16 model. The accuracy rate is 92%. |
| [24] | Crackle, wheeze, phlegm sound | 172 COVID-19 records | CNN | The lightweight neural network module has an accuracy rate of more than 95%; the four-category deep neural network model based on the residual structure has an accuracy rate of more than 95%; it can diagnose and identify abnormalities such as rales, wheezing, and sputum sounds in the lungs. When it comes to lung sounds, a high accuracy rate of more than 95% is obtained. | |
| [25] | Lung sound | ICBHI 2017 [41] | log–Mel spectrogram | ResNet-50 | Knowledge from pre-trained models, derived from various ResNet architectures, is harnessed using standard fine-tuning through innovative methods such as co-tuning and stochastic normalization, both individually and in combination. Additionally, to enhance the system’s robustness, techniques like spectral correction and flipped data augmentation have been implemented. Performance evaluations for the classification of Class 3 and Class 2 respiratory diseases yielded average accuracies of 92.72 ± 1.30% and 93.77 ± 1.41%, respectively. |
| [23] | Lung sound | ICBHI 2017 [41] | MFCC | CNN–LSTM | A method is proposed to extract the spatial features of data by using CNN, while LSTM captures the features of the time dimension. The data is processed through data enhancement and sampling techniques, and finally 5054 data are obtained. |
| [28] | Lung sound | ICBHI 2017 [41] | STFT | CNN–LSTM | The model achieved an accuracy of 76.39% using interpatient 10-fold cross-validation. Additionally, using leave-one-out cross-validation, it reached a sensitivity of 60.29% and an accuracy of 74.57%. |
| [29] | Lung sound | ICBHI 2017 [41] | OST | ResNets | The study utilizes an optimized S-transform (OST) alongside deep residual networks (ResNets) to distinguish between wheezes, crackles, and normal respiratory sounds. The experimental findings indicate outstanding multi-classification performance of these respiratory sounds, demonstrating an accuracy of 98.79%, a sensitivity of 96.27%, and a specificity of 100%. |
| [32] | Lung sound | ICBHI 2017 [41] | SDC-L | CNN–LSTM | δ-cepstral coefficients in lower subspace (SDC-L) are used as a novel feature for lung sound classification. The accuracy is 0.94. |
| [37] | Lung sound | ICBHI 2017 [41] | Mel spectrogram | VGG | The proposed solution involves a lung sound recognition algorithm that integrates the VGGish network with a stacked bidirectional gated recurrent unit (BiGRU) neural network. This approach merges the capabilities of VGGish for feature extraction with the sequential data processing strengths of the stacked BiGRU. |
| Ref | Sounds | Dataset | Feature Extraction | Method | Outcome |
|---|---|---|---|---|---|
| [13] | Lung sound | ICBHI2017 [41] | CNN | LDA–RSE | A novel CNN model is introduced to extract deep features, incorporating both average and max pooling layers in parallel within the CNN architecture to enhance classification effectiveness. These deep features are then utilized as inputs for a linear discriminant analysis (LDA) classifier, employing the stochastic subspace ensemble (RSE) method. The highest performance achieved with this setup is 71.15%. |
| [21] | Respiration | Coswara [45] | MFCC random masking | Transformer–CP | Transformer-based feature encoders are pre-trained to process unlabeled data in a self-supervised manner. Furthermore, the random masking mechanism works together with the Transformer feature encoder. Experimental results show that a random masking rate of 50% achieves the best performance. |
| [26] | Lung sound | ICBHI2017 [41] | STFT, wavelet | LungRN+NL | The model LungRN+NL neural network inserts a non-local layer between the ResNet-II layers to break the local time and frequency constraints of the convolutional neural network, which means that the non-local layer calculates the time domain and frequency domain of a position and other positions. Finally, after the signal is propagated through ResNet-II, four different classes are obtained. |
| [27] | COPD | 120 lung sounds | 3D-SODP | DBN | The combined use of 3D–SODP (third order difference plot) quantitative features with DBN (deep belief networks) separated lung sounds from different levels of COPD with classification performances of 95.84%, 93.34%, and 93.65% for accuracy, sensitivity, and specificity, respectively. |
| [30] | Lung sound | ICBHI2017 [41] | MFCC | GRU | GRU (gated recurrent unit) layers are used to solve the vanishing gradient problem in standard recurrent neural networks. Accuracy: 95.67 ± 0.77%. |
| [31] | Lung sound | From hospital | Wavelet+LDA | BP neural network | Wavelet de-noised and reduced the dimension of linear discriminant analysis. Accuracy: 92.5%. |
| [35] | Lung sound | RALE database | Wavelet | SVM–LSTM | Research suggests that external sounds have non-linear characteristics. Therefore, the two feature sets of wavelets, bi-spectrum and bi-phasic, are analyzed through the SVM–LSTM Bayesian optimization algorithm model. The results show the SVM accuracy is 94.086%, the SVM–LSTM accuracy is 94.684%, the LSTM Bayesian optimization accuracy of WBS is 95.699%, and the LSTM accuracy is 95.161% and WBP, respectively. |
| [38] | Lung sound | ICBHI2017 [41] | Spectrograms | CNN–MoE | Initially, respiratory cycles or complete audio recordings are converted into spectrogram representations, which are then segmented into equal-sized image patches for training, incorporating mix-up data augmentation. Four types of spectrograms—log–Mel, Gammatone filter bank (Gamma), stacked Mel-frequency cepstral coefficients (MFCCs), and rectangular constant Q transform (CQT)—are analyzed. The Gamma spectrogram is found to be the most effective for classifying anomaly cycles, while the log–Mel spectrogram is superior for respiratory disease detection. The deep learning framework is augmented by a mixture-of-experts (MoEs) strategy, leading to the development of the CNN–MoE architecture. This architecture leverages the first six convolutional blocks to convert image patch inputs into high-level features, which a dense block then processes, consisting of a fully connected layer and a Softmax function. Additionally, the MoE block architecture incorporates multiple experts linked to a gating network that dictates the contribution of each expert based on the specific characteristics of the input. |
| [45] | Idiopathic pulmonary fibrosis (IPF), non-specific interstitial pneumonia (NSIP), and chronic obstructive pulmonary disease (COPD) | The study plans to enroll patients with ILD, COPD, and control subjects, each providing ten 30 s audio recordings. | MFCC | CNN, LSTM, Transformer | Each patient provided 10 recordings from various anatomical sites. These recordings were pre-processed by applying a band-pass filter, transforming them into Mel frequency cepstral coefficients (MFCCs) and employing data augmentation techniques like amplitude scaling and pitch shift. The processed data were then analyzed using deep learning models, including CNNs, LSTMs, and transformer architectures, to perform binary classification for diagnostic purposes. Additionally, clinical data were integrated into the analysis to enhance predictive accuracy. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Sankar, R. Classification and Recognition of Lung Sounds Using Artificial Intelligence and Machine Learning: A Literature Review. Big Data Cogn. Comput. 2024, 8, 127. https://doi.org/10.3390/bdcc8100127
Xu X, Sankar R. Classification and Recognition of Lung Sounds Using Artificial Intelligence and Machine Learning: A Literature Review. Big Data and Cognitive Computing. 2024; 8(10):127. https://doi.org/10.3390/bdcc8100127
Chicago/Turabian StyleXu, Xiaoran, and Ravi Sankar. 2024. "Classification and Recognition of Lung Sounds Using Artificial Intelligence and Machine Learning: A Literature Review" Big Data and Cognitive Computing 8, no. 10: 127. https://doi.org/10.3390/bdcc8100127
APA StyleXu, X., & Sankar, R. (2024). Classification and Recognition of Lung Sounds Using Artificial Intelligence and Machine Learning: A Literature Review. Big Data and Cognitive Computing, 8(10), 127. https://doi.org/10.3390/bdcc8100127