
Combining Semantic Matching, Word Embeddings, Transformers, and LLMs for Enhanced Document Ranking: Application in Systematic Reviews
 , , ,
, , ,  and
and 
Abstract
:1. Introduction
2. Related Works
3. Methodology
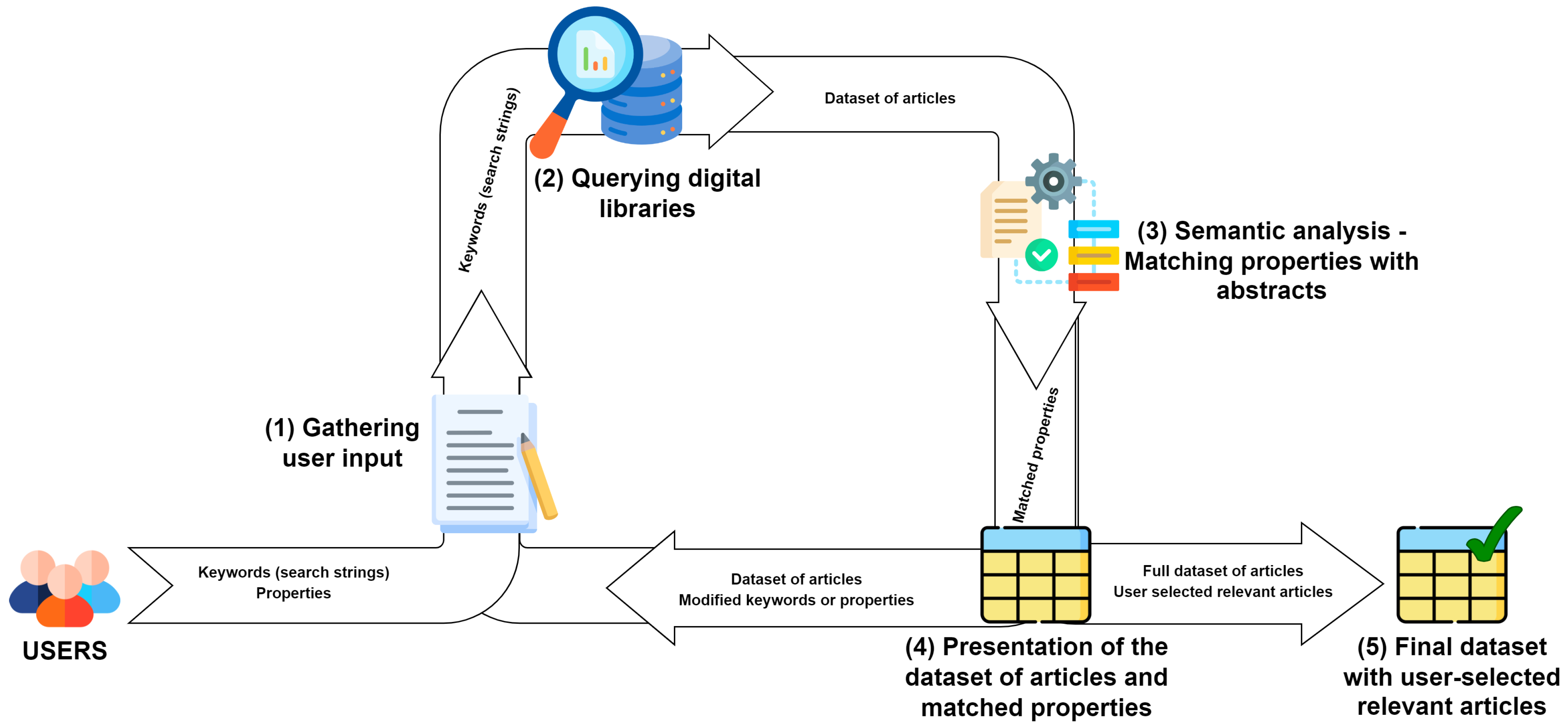
3.1. Framework for User-Driven Dataset Generation
- Gathering user input: The initial phase involves close collaboration with researchers who aim to conduct SLRs in specific domains. Leveraging their domain-specific knowledge and the topic of their investigation, these researchers first identify and define keywords, which serve as search strings to query digital libraries of articles. Subsequently, they provide us with properties and property groups. Properties consist of words or phrases that are used to search the titles and abstracts of articles to assess their relevance. Property groups are thematically or semantically organized collections of properties which enable a more comprehensive presentation of the results.
- Dataset compilation: After collecting the user input, we proceed with querying the digital libraries of articles. Users can select which library options to query from, such as IEEE Xplore, Springer, MDPI, PubMed, and ScienceDirect. Using the keywords provided by the user, we construct search strings and the tool generates a dataset of articles in the form of an Excel file, including information like DOI, title, abstract, authors, affiliations, and other relevant details.
- Semantic analysis: In this step, the title and the abstract of each paper in the dataset are subject to the tokenization of sentences [31,32], English stop words removal, stemming, and lemmatization [31] using the NLTK library [33] for Python. The exact process is applied to each defined property as well. Then, the stemmed and lemmatized properties are searched in the cleaned abstract and title, and the article is tagged with the properties it contains, as described in Section 3.2.1
- Result presentation: The refined dataset is presented to the user, where the articles are in randomized order but supplemented with the properties found in the previous step available to be used as facet filters. These filters aid the user in easily and efficiently navigating the dataset, allowing them to sort and group the articles based on matched properties.
- 5
- Final user selection: The final step is where users provide feedback on the selected articles. This feedback is critical for our work to investigate and improve the relevance of the search results. In this step, users decide on the most relevant articles to their research objectives. Once this step is completed, we have a new dataset that includes all the provided articles and those specifically selected by the users.
3.2. Similarity Estimation Methods
3.2.1. Semantic Matching
3.2.2. TF-IDF
3.2.3. N-Gram
3.2.4. SpaCy Word Embeddings
3.2.5. MiniLM v2
3.2.6. E5 Mistral-7B
3.2.7. Weighted Semantic Matching + MiniLM
3.3. Evaluation Metrics
3.3.1. Global Metrics
Top at K
Precision at K
Recall at K
Average Rank
Median Rank
3.3.2. Pairwise Algorithm Comparison
Higher Rank Count
Average Rank Difference
- (i)
- Obtain rank A (given by algorithm A) and rank B (given by algorithm B).
- (ii)
- Calculate the difference between rank A and B (). This equation may produce positive and negative values. A positive value means algorithm B performs better, and a negative value means that algorithm A performs better.
- (iii)
- Calculate the average value of all rank differences computed in step (ii) using the following equation:
Median rank difference
- (i)
- Complete step (i) and step (ii) precisely as we do for average rank difference.
- (ii)
- Calculate the median for all rank differences using the same equation (Equation (9)) as we use for Median Rank.
4. Results and Discussion
4.1. Datasets
- Driving healthcare monitoring with IoT and wearable devices: A systematic review—This dataset is obtained from a systematic review aimed at exploring the use of the IoT and wearable devices in monitoring drivers’ health.
- Ambient Assisted Living (AAL): Scoping Review of Artificial Intelligence (AI) Models, Domains, Technology, and Concerns [42]—This dataset originates from a comprehensive scoping review to identify, analyze, and extract the literature on AI models in AAL.
- Mobile and wearable technologies for the analysis of Ten Meter Walk Test: A concise, systematic review [43]—This dataset is derived from a concise, systematic review related to the use of mobile or wearable devices to measure physical parameters while administering the Ten Meter Walk Test for the analysis of the performance of the test.
- Venture Capital: A Bibliometric Analysis—This dataset is derived from a meticulous bibliometric and structural review, emphasizing three primary topical areas: environment, social, governance (ESG), innovation, and exit strategies.
- Automating feature extraction from Entity-Relation models: Experimental evaluation of machine learning methods for relational learning [44]—This dataset is curated following a study that included a comprehensive review of the existing literature in the field of relational learning and proceeded with further exploring.
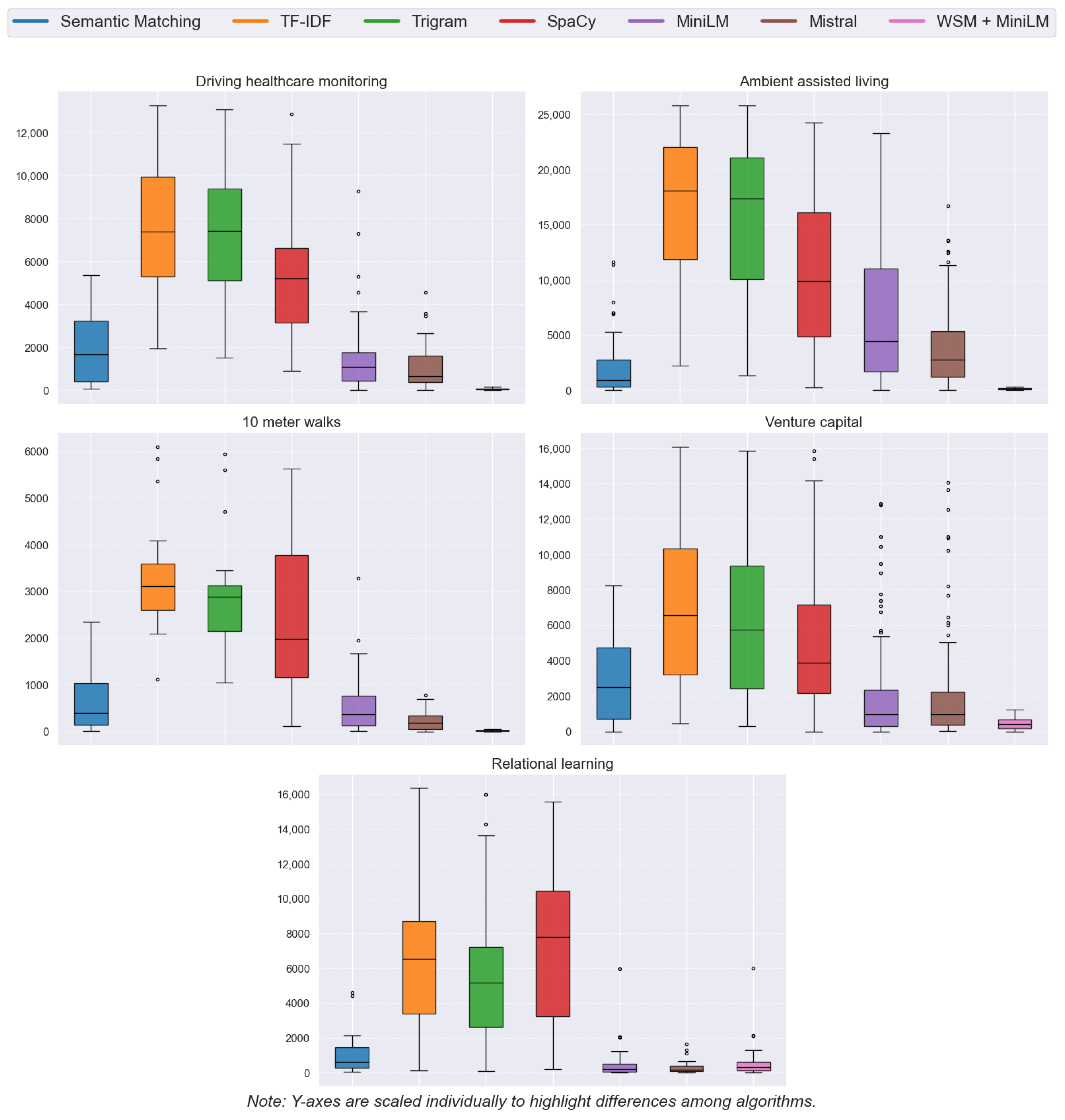
4.2. Rank Distribution
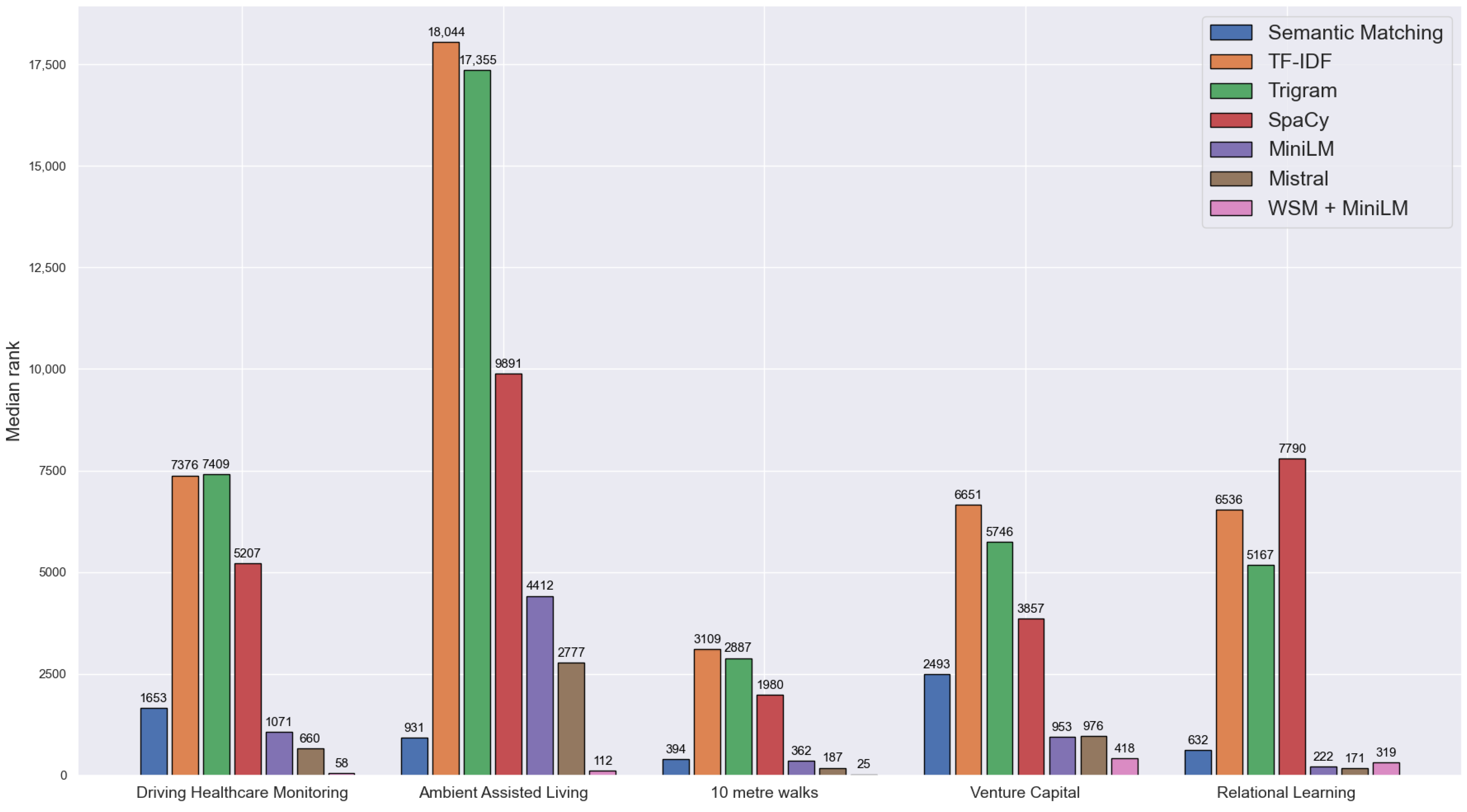
4.3. Median Rank
4.4. Metrics
4.4.1. Global Metrics
4.4.2. Pairwise Algorithm Comparison
4.5. Dataset Availability
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bornmann, L.; Haunschild, R.; Mutz, R. Growth rates of modern science: A latent piecewise growth curve approach to model publication numbers from established and new literature databases. Humanit. Soc. Sci. Commun. 2021, 8, 224. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; University of Durham: Durham, UK, 2007. [Google Scholar]
- Michelson, M.; Reuter, K. The significant cost of systematic reviews and meta-analyses: A call for greater involvement of machine learning to assess the promise of clinical trials. Contemp. Clin. Trials Commun. 2019, 16, 100443. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Stewart, L.; Shekelle, P. All in the Family: Systematic reviews, rapid reviews, scoping reviews, realist reviews, and more. Syst. Rev. 2015, 4, 183. [Google Scholar] [CrossRef] [PubMed]
- Alla, A.; Zdravevski, E.; Trajkovik, V. Framework for Aiding Surveys by Natural Language Processing. In Proceedings of the ICT Innovations 2017Web Proceedings, Skopje, Macedonia, 18–23 September 2017; pp. 11–21. [Google Scholar]
- Zdravevski, E.; Lameski, P.; Trajkovik, V.; Chorbev, I.; Goleva, R.; Pombo, N.; Garcia, N.M. Automation in Systematic, Scoping and Rapid Reviews by an NLP Toolkit: A Case Study in Enhanced Living Environments. In Enhanced Living Environments: Algorithms, Architectures, Platforms, and Systems; Ganchev, I., Garcia, N.M., Dobre, C., Mavromoustakis, C.X., Goleva, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–18. [Google Scholar] [CrossRef]
- Carver, J.C.; Hassler, E.; Hernandes, E.; Kraft, N.A. Identifying Barriers to the Systematic Literature Review Process. In Proceedings of the 2013 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Baltimore, MD, USA, 10–11 October 2013; pp. 203–212. [Google Scholar] [CrossRef]
- Cohen, A.; Hersh, W.; Peterson, K.; Yen, P.Y. Reducing Workload in Systematic Review Preparation Using Automated Citation Classification. J. Am. Med Informatics Assoc. 2006, 13, 206–219. [Google Scholar] [CrossRef] [PubMed]
- O’Mara-Eves, A.; Thomas, J.; McNaught, J.; Miwa, M.; Ananiadou, S. Using text mining for study identification in systematic reviews: A systematic review of current approaches. Syst. Rev. 2015, 4, 5. [Google Scholar] [CrossRef]
- van Dinter, R.; Tekinerdogan, B.; Catal, C. Automation of systematic literature reviews: A systematic literature review. Inf. Softw. Technol. 2021, 136, 106589. [Google Scholar] [CrossRef]
- Sundaram, G.; Berleant, D. Automating Systematic Literature Reviews with Natural Language Processing and Text Mining: A Systematic Literature Review. arXiv 2022. [Google Scholar] [CrossRef]
- Zala, K.; Acharya, B.; Mashru, M.; Palaniappan, D.; Gerogiannis, V.C.; Kanavos, A.; Karamitsos, I. Transformative Automation: AI in Scientific Literature Reviews. Int. J. Adv. Comput. Sci. Appl. 2024, 15. [Google Scholar] [CrossRef]
- Cierco Jimenez, R.; Lee, T.; Rosillo, N.; Cordova, R.; Cree, I.A.; Gonzalez, A.; Indave Ruiz, B.I. Machine learning computational tools to assist the performance of systematic reviews: A mapping review. BMC Med. Res. Methodol. 2022, 22, 322. [Google Scholar] [CrossRef]
- Johnson, E.E.; O’Keefe, H.; Sutton, A.; Marshall, C. The Systematic Review Toolbox: Keeping up to date with tools to support evidence synthesis. Syst. Rev. 2022, 11, 258. [Google Scholar] [CrossRef]
- Gates, A.; Johnson, C.; Hartling, L. Technology-assisted title and abstract screening for systematic reviews: A retrospective evaluation of the Abstrackr machine learning tool. Syst. Rev. 2018, 7, 45. [Google Scholar] [CrossRef] [PubMed]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Augustin, C.; Bethel, A.; Gill, D.; Anzaroot, S.; Brun, J.; DeWilde, B.; Minnich, R.; Garside, R.; Masuda, Y.; et al. Using machine learning to advance synthesis and use of conservation and environmental evidence. Conserv. Biol. 2018, 32, 762–764. [Google Scholar] [CrossRef] [PubMed]
- Thomas, J.; Brunton, J.; Graziosi, S. EPPI-Reviewer 4.0: Software for research synthesis. In EPPI-Centre Software; Social Science Research Unit, Institute of Education: London, UK, 2010. [Google Scholar]
- Przybyła, P.; Brockmeier, A.J.; Kontonatsios, G.; Le Pogam, M.; McNaught, J.; von Elm, E.; Nolan, K.; Ananiadou, S. Prioritising references for systematic reviews with RobotAnalyst: A user study. Res. Synth. Methods 2018, 9, 470–488. [Google Scholar] [CrossRef] [PubMed]
- van de Schoot, R.; de Bruin, J.; Schram, R.; Zahedi, P.; de Boer, J.; Weijdema, F.; Kramer, B.; Huijts, M.; Hoogerwerf, M.; Ferdinands, G.; et al. An open source machine learning framework for efficient and transparent systematic reviews. Nat. Mach. Intell. 2021, 3, 125–133. [Google Scholar] [CrossRef]
- Howard, B.E.; Phillips, J.; Tandon, A.; Maharana, A.; Elmore, R.; Mav, D.; Sedykh, A.; Thayer, K.; Merrick, B.A.; Walker, V.; et al. SWIFT-Active Screener: Accelerated document screening through active learning and integrated recall estimation. Environ. Int. 2020, 138, 105623. [Google Scholar] [CrossRef]
- Wagner, G.; Lukyanenko, R.; Paré, G. Artificial intelligence and the conduct of literature reviews. J. Inf. Technol. 2022, 37, 209–226. [Google Scholar] [CrossRef]
- Atkinson, C.F. Cheap, Quick, and Rigorous: Artificial Intelligence and the Systematic Literature Review. Soc. Sci. Comput. Rev. 2024, 42, 376–393. [Google Scholar] [CrossRef]
- Ma, Y. Text classification on imbalanced data: Application to systematic reviews automation. Masters Abstr. Int. 2007, 46, 1578. [Google Scholar] [CrossRef]
- Ros, R.; Bjarnason, E.; Runeson, P. A Machine Learning Approach for Semi-Automated Search and Selection in Literature Studies. In Proceedings of the 21st International Conference on Evaluation and Assessment in Software Engineering, New York, NY, USA, 15–16 June 2017; EASE ’17. pp. 118–127. [Google Scholar] [CrossRef]
- Cohen, A.; Ambert, K.; McDonagh, M. Cross-Topic Learning for Work Prioritization in Systematic Review Creation and Update. J. Am. Med Informatics Assoc. 2009, 16, 690–704. [Google Scholar] [CrossRef]
- Gonzalez-Toral, S.; Freire, R.; Gualán, R.; Saquicela, V. A ranking-based approach for supporting the initial selection of primary studies in a Systematic Literature Review. In Proceedings of the 2019 XLV Latin American Computing Conference (CLEI), Panama City, Panama, 30 September–4 October 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Khraisha, Q.; Put, S.; Kappenberg, J.; Warraitch, A.; Hadfield, K. Can large language models replace humans in systematic reviews? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages. Res. Synth. Methods 2024, 15, 616–626. [Google Scholar] [CrossRef] [PubMed]
- Alshami, A.; Elsayed, M.; Ali, E.; Eltoukhy, A.E.E.; Zayed, T. Harnessing the Power of ChatGPT for Automating Systematic Review Process: Methodology, Case Study, Limitations, and Future Directions. Systems 2023, 11, 351. [Google Scholar] [CrossRef]
- Qureshi, R.; Shaughnessy, D.; Gill, K.; Robinson, K.; Li, T.; Agai, E. Are ChatGPT and large language models "the answer" to bringing us closer to systematic review automation? Syst. Rev. 2023, 12, 72. [Google Scholar] [CrossRef]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; Bontcheva, K., Zhu, J., Eds.; pp. 55–60. [Google Scholar] [CrossRef]
- Webster, J.J.; Kit, C. Tokenization as the initial phase in NLP. In Proceedings of the 14th Conference on Computational Linguistics, Nantes, France, 14–16 August 1992; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992. [Google Scholar] [CrossRef]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. arXiv 2002. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. (Eds.) TF–IDF. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 986–987. [Google Scholar] [CrossRef]
- Ramos, J.E. Using TF-IDF to Determine Word Relevance in Document Queries. In Proceedings of the First Instructional Conference on Machine Learning, Los Angeles, CA, USA, 23–24 June 2003. [Google Scholar]
- Honnibal, M.; Montani, I. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. Appear 2017, 7, 411–420. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. arXiv 2020. [Google Scholar] [CrossRef]
- Wang, W.; Bao, H.; Huang, S.; Dong, L.; Wei, F. MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers. arXiv 2020. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023. [Google Scholar]
- Wang, L.; Yang, N.; Huang, X.; Yang, L.; Majumder, R.; Wei, F. Improving Text Embeddings with Large Language Models. arXiv 2024. [Google Scholar]
- Jovanovic, M.; Mitrov, G.; Zdravevski, E.; Lameski, P.; Colantonio, S.; Kampel, M.; Tellioglu, H.; Florez-Revuelta, F. Ambient Assisted Living: Scoping Review of Artificial Intelligence Models, Domains, Technology, and Concerns. J. Med. Internet Res. 2022, 24, e36553. [Google Scholar] [CrossRef]
- Gabriel, C.L.; Pires, I.M.; Coelho, P.J.; Zdravevski, E.; Lameski, P.; Mewada, H.; Madeira, F.; Garcia, N.M.; Carreto, C. Mobile and wearable technologies for the analysis of Ten Meter Walk Test: A concise systematic review. Heliyon 2023, 9, e16599. [Google Scholar] [CrossRef]
- Stanoev, B.; Mitrov, G.; Kulakov, A.; Mirceva, G.; Lameski, P.; Zdravevski, E. Automating Feature Extraction from Entity-Relation Models: Experimental Evaluation of Machine Learning Methods for Relational Learning. Big Data Cogn. Comput. 2024, 8, 39. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Dataset | Papers Provided | Papers Selected |
|---|---|---|
| Driving Healthcare Monitoring | 13,518 | 30 |
| Ambient Assisted Living [42] | 26,331 | 108 |
| 10 Metre Walks [43] | 6708 | 22 |
| Venture Capital | 17,133 | 150 |
| Relational Learning [44] | 18,711 | 23 |
| Dataset | Algorithm | Top 100 | Precision@100 | Recall@100 | Top 500 | Precision@500 | Recall@500 |
|---|---|---|---|---|---|---|---|
| Driving Healthcare Monitoring | Semantic Matching | 1 | 0.01 | 0.033 | 9 | 0.018 | 0.3 |
| TF-IDF | 0 | 0 | 0 | 0 | 0 | 0 | |
| Trigram | 0 | 0 | 0 | 0 | 0 | 0 | |
| SpaCy | 0 | 0 | 0 | 0 | 0 | 0 | |
| MiniLM | 3 | 0.03 | 0.1 | 8 | 0.016 | 0.266 | |
| E5 Mistral | 1 | 0.01 | 0.033 | 10 | 0.02 | 0.333 | |
| WSM + MiniLM | 25 | 0.25 | 0.833 | 30 | 0.06 | 1 | |
| Ambient Assisted Living | Semantic Matching | 8 | 0.08 | 0.074 | 39 | 0.078 | 0.361 |
| TF-IDF | 0 | 0 | 0 | 0 | 0 | 0 | |
| Trigram | 0 | 0 | 0 | 0 | 0 | 0 | |
| SpaCy | 0 | 0 | 0 | 1 | 0.002 | 0.009 | |
| MiniLM | 4 | 0.04 | 0.037 | 15 | 0.03 | 0.138 | |
| E5 Mistral | 5 | 0.05 | 0.046 | 11 | 0.022 | 0.102 | |
| WSM + MiniLM | 50 | 0.45 | 0.462 | 108 | 0.216 | 1 | |
| 10 m Walks | Semantic Matching | 5 | 0.05 | 0.227 | 13 | 0.026 | 0.59 |
| TF-IDF | 0 | 0 | 0 | 0 | 0 | 0 | |
| Trigram | 0 | 0 | 0 | 0 | 0 | 0 | |
| SpaCy | 0 | 0 | 0 | 1 | 0.002 | 0.045 | |
| MiniLM | 4 | 0.04 | 0.181 | 12 | 0.024 | 0.545 | |
| E5 Mistral | 7 | 0.07 | 0.318 | 17 | 0.034 | 0.773 | |
| WSM + MiniLM | 22 | 0.22 | 1 | 22 | 0.044 | 1 | |
| Venture Capital | Semantic Matching | 5 | 0.05 | 0.033 | 26 | 0.052 | 0.173 |
| TF-IDF | 0 | 0 | 0 | 2 | 0.004 | 0.013 | |
| Trigram | 0 | 0 | 0 | 5 | 0.01 | 0.033 | |
| SpaCy | 3 | 0.03 | 0.02 | 12 | 0.024 | 0.08 | |
| MiniLM | 19 | 0.19 | 0.126 | 54 | 0.108 | 0.36 | |
| E5 Mistral | 9 | 0.09 | 0.06 | 45 | 0.09 | 0.3 | |
| WSM + MiniLM | 31 | 0.31 | 0.206 | 87 | 0.174 | 0.58 | |
| Relational Learning | Semantic Matching | 1 | 0.01 | 0.043 | 10 | 0.02 | 0.434 |
| TF-IDF | 0 | 0 | 0 | 3 | 0.006 | 0.13 | |
| Trigram | 1 | 0.01 | 0.043 | 3 | 0.006 | 0.13 | |
| SpaCy | 0 | 0 | 0 | 1 | 0.002 | 0.043 | |
| MiniLM | 7 | 0.07 | 0.3 | 17 | 0.034 | 0.739 | |
| E5 Mistral | 6 | 0.06 | 0.261 | 18 | 0.036 | 0.783 | |
| WSM + MiniLM | 2 | 0.02 | 0.086 | 13 | 0.026 | 0.565 |
| Dataset | Algorithm | Top 1000 | Precision@1000 | Recall@1000 | AverageRank | MedianRank |
|---|---|---|---|---|---|---|
| Driving Healthcare Monitoring | Semantic Matching | 12 | 0.012 | 0.4 | 1958 | 1653 |
| TF-IDF | 0 | 0 | 0 | 7479 | 7376 | |
| Trigram | 0 | 0 | 0 | 7248 | 7409 | |
| SpaCy | 1 | 0.001 | 0.03 | 5578 | 5207 | |
| MiniLM | 15 | 0.015 | 0.5 | 1764 | 1071 | |
| E5 Mistral | 17 | 0.017 | 0.567 | 1171 | 660 | |
| WSM + MiniLM | 30 | 0.03 | 1 | 60 | 58 | |
| Ambient Assisted Living | Semantic Matching | 56 | 0.056 | 0.518 | 1884 | 931 |
| TF-IDF | 0 | 0 | 0 | 16,573 | 18,044 | |
| Trigram | 0 | 0 | 0 | 15,594 | 17,355 | |
| SpaCy | 6 | 0.006 | 0.055 | 10,794 | 9891 | |
| MiniLM | 20 | 0.02 | 0.185 | 6645 | 4412 | |
| E5 Mistral | 23 | 0.023 | 0.213 | 3914 | 2777 | |
| WSM + MiniLM | 108 | 0.108 | 1 | 128 | 112 | |
| 10 m Walks | Semantic Matching | 16 | 0.016 | 0.727 | 645 | 394 |
| TF-IDF | 0 | 0 | 0 | 3292 | 3109 | |
| Trigram | 0 | 0 | 0 | 2960 | 2887 | |
| SpaCy | 5 | 0.005 | 0.227 | 2530 | 1980 | |
| MiniLM | 19 | 0.019 | 0.864 | 631 | 362 | |
| E5 Mistral | 22 | 0.022 | 1 | 257 | 187 | |
| WSM + MiniLM | 22 | 0.022 | 1 | 24 | 25 | |
| Venture Capital | Semantic Matching | 44 | 0.044 | 0.293 | 2964 | 2493 |
| TF-IDF | 8 | 0.008 | 0.053 | 6996 | 6561 | |
| Trigram | 12 | 0.012 | 0.08 | 6255 | 5746 | |
| SpaCy | 20 | 0.02 | 0.133 | 4858 | 3857 | |
| MiniLM | 77 | 0.077 | 0.513 | 1878 | 953 | |
| E5 Mistral | 76 | 0.076 | 0.507 | 1921 | 976 | |
| WSM + MiniLM | 138 | 0.138 | 0.92 | 454 | 418 | |
| Relational Learning | Semantic Matching | 13 | 0.013 | 0.565 | 1149 | 632 |
| TF-IDF | 3 | 0.003 | 0.130 | 6938 | 6536 | |
| Trigram | 3 | 0.003 | 0.130 | 6014 | 5167 | |
| SpaCy | 1 | 0.001 | 0.043 | 7376 | 7790 | |
| MiniLM | 19 | 0.019 | 0.826 | 686 | 222 | |
| E5 Mistral | 20 | 0.02 | 0.87 | 354 | 171 | |
| WSM + MiniLM | 19 | 0.019 | 0.826 | 761 | 319 |
| Algorithm A | Algorithm B | Dataset | HRC A | HRC B | ARD | MRD |
|---|---|---|---|---|---|---|
| Driving Healthcare Monitoring | 12 | 18 | +193 | +219 | ||
| Ambient Assisted Living | 81 | 27 | −4761 | −2902 | ||
| Semantic Matching | MiniLM | 10 m Walks | 11 | 11 | +13 | −38 |
| Venture Capital | 49 | 101 | +1086 | +1067 | ||
| Relational Learning | 8 | 15 | +462 | +351 | ||
| Driving Healthcare Monitoring | 8 | 22 | +786 | +354 | ||
| Ambient Assisted Living | 85 | 23 | −2031 | −1758 | ||
| Semantic Matching | E5 Mistral | 10 m Walks | 5 | 17 | +387 | +178 |
| Venture Capital | 46 | 104 | +1042 | +1030 | ||
| Relational Learning | 3 | 20 | +794 | +524 | ||
| Driving Healthcare Monitoring | 14 | 16 | +593 | +201 | ||
| Ambient Assisted Living | 40 | 68 | +2730 | +1352 | ||
| MiniLM | E5 Mistral | 10 m Walks | 6 | 16 | +374 | +188 |
| Venture Capital | 79 | 71 | −44 | −38 | ||
| Relational Learning | 10 | 13 | +331 | +119 | ||
| Driving Healthcare Monitoring | 0 | 30 | +1898 | +1600 | ||
| Ambient Assisted Living | 9 | 98 | +1756 | +875 | ||
| Semantic Matching | WSM + MiniLM | 10 m Walks | 0 | 22 | +620 | +374 |
| Venture Capital | 20 | 130 | +2509 | +2101 | ||
| Relational Learning | 9 | 14 | +388 | +250 | ||
| Driving Healthcare Monitoring | 0 | 30 | +1704 | +1013 | ||
| Ambient Assisted Living | 0 | 108 | +6516 | +4300 | ||
| MiniLM | WSM + MiniLM | 10 m Walks | 0 | 22 | +606 | +337 |
| Venture Capital | 4 | 146 | +1423 | +535 | ||
| Relational Learning | 21 | 2 | −75 | −95 | ||
| Driving Healthcare Monitoring | 0 | 30 | +1111 | +581 | ||
| Ambient Assisted Living | 2 | 106 | +3786 | +2666 | ||
| E5 Mistral | WSM + MiniLM | 10 m Walks | 2 | 20 | +232 | +172 |
| Venture Capital | 26 | 124 | +1466 | +545 | ||
| Relational Learning | 16 | 7 | −407 | −217 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitrov, G.; Stanoev, B.; Gievska, S.; Mirceva, G.; Zdravevski, E. Combining Semantic Matching, Word Embeddings, Transformers, and LLMs for Enhanced Document Ranking: Application in Systematic Reviews. Big Data Cogn. Comput. 2024, 8, 110. https://doi.org/10.3390/bdcc8090110
Mitrov G, Stanoev B, Gievska S, Mirceva G, Zdravevski E. Combining Semantic Matching, Word Embeddings, Transformers, and LLMs for Enhanced Document Ranking: Application in Systematic Reviews. Big Data and Cognitive Computing. 2024; 8(9):110. https://doi.org/10.3390/bdcc8090110
Chicago/Turabian StyleMitrov, Goran, Boris Stanoev, Sonja Gievska, Georgina Mirceva, and Eftim Zdravevski. 2024. "Combining Semantic Matching, Word Embeddings, Transformers, and LLMs for Enhanced Document Ranking: Application in Systematic Reviews" Big Data and Cognitive Computing 8, no. 9: 110. https://doi.org/10.3390/bdcc8090110