
Acoustic-Based UAV Detection Using Late Fusion of Deep Neural Networks



Abstract
1. Introduction
- Reinforce the viability of utilizing deep neural networks for the detection of multirotor UAVs with acoustic signals;
- Investigate which model architecture (CNN, CRNN, or RNN) performs the best for acoustic UAV identification;
- Evaluate the performance of late fusion networks compared with solo models and determine the most suitable voting mechanism in this study.
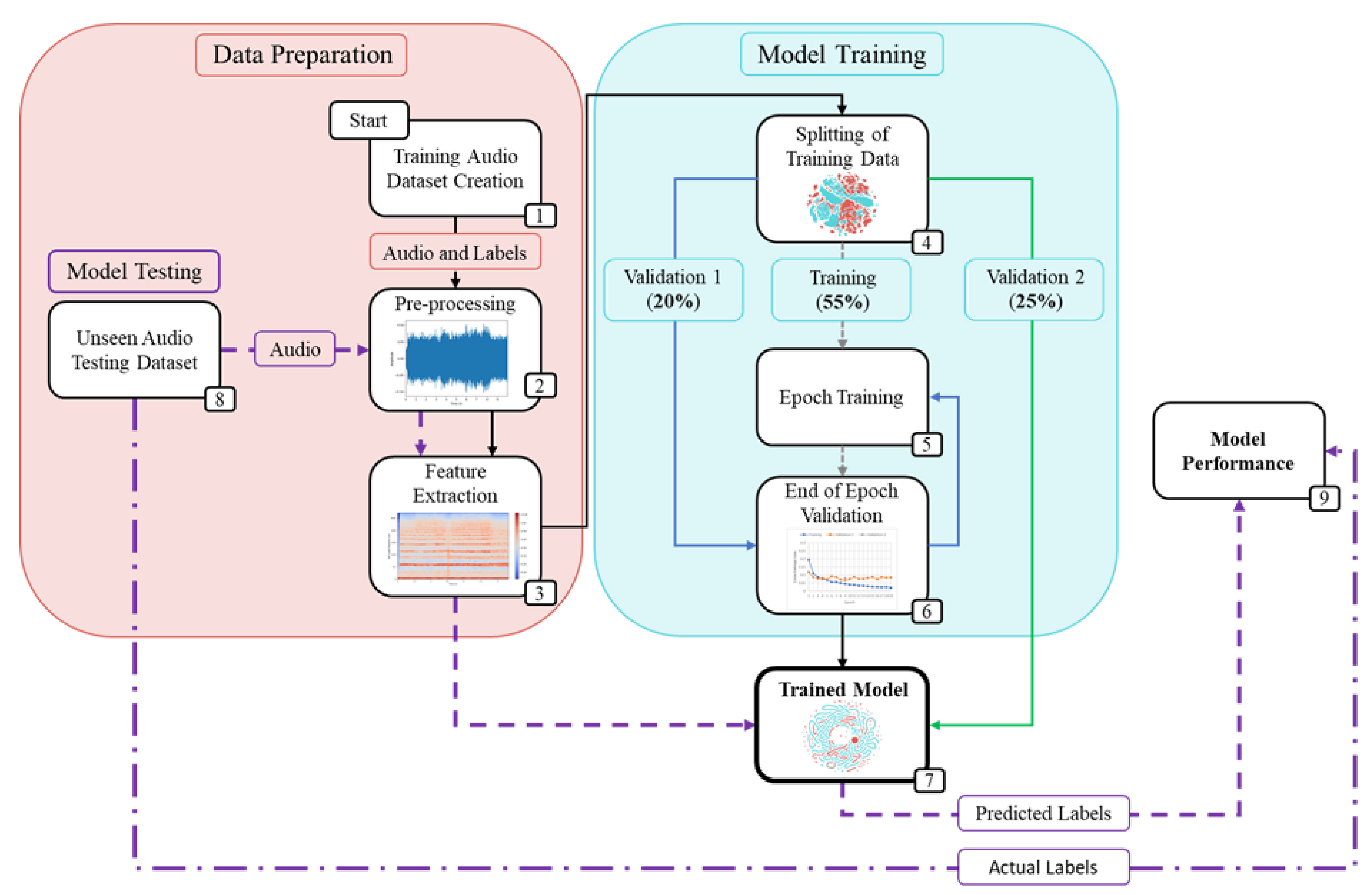
2. Methodology
2.1. Data Preparation
2.1.1. Training Audio Dataset
2.1.2. Unseen Audio Testing Datasets
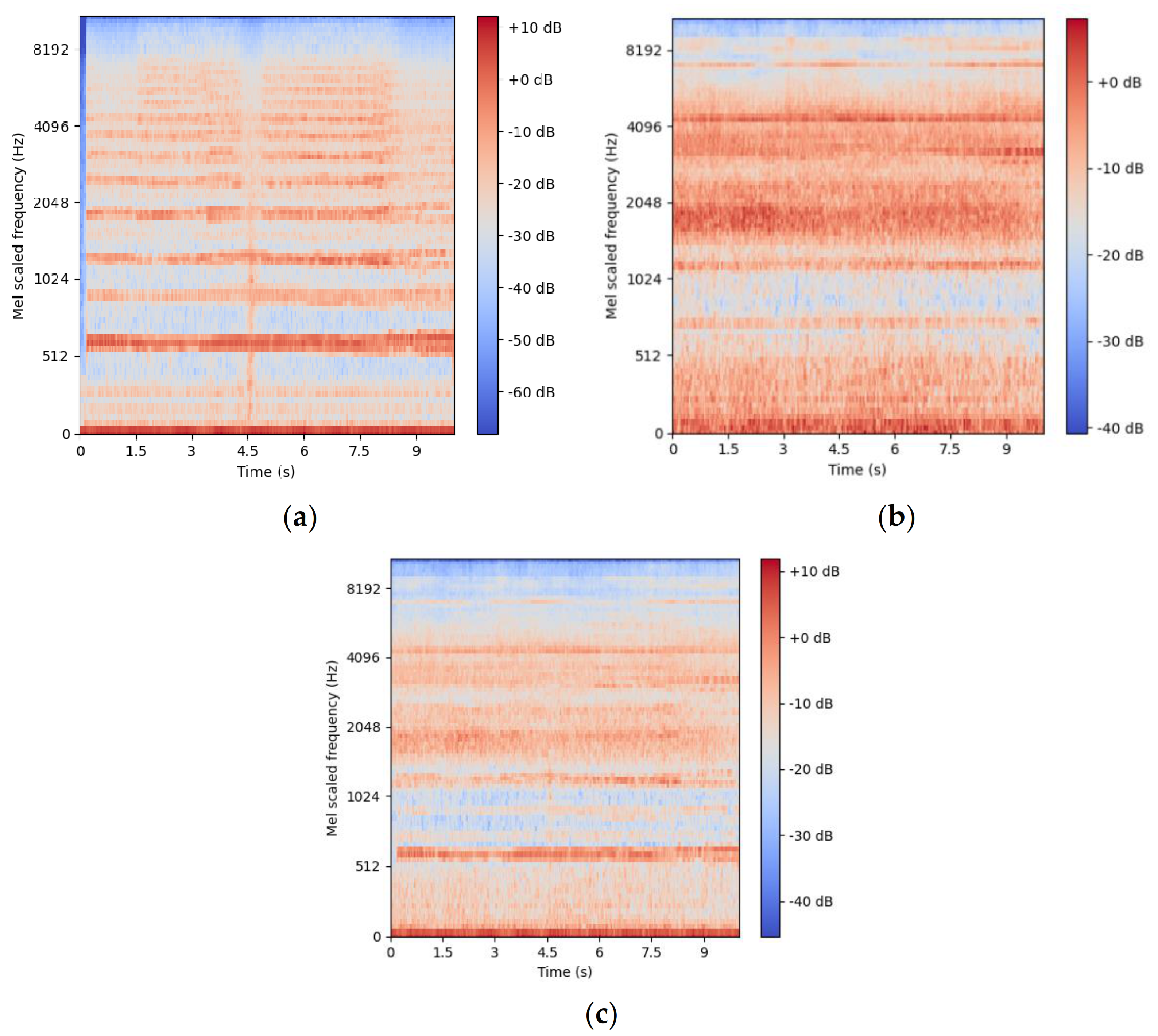
2.1.3. Audio Pre-Processing and Feature Extraction
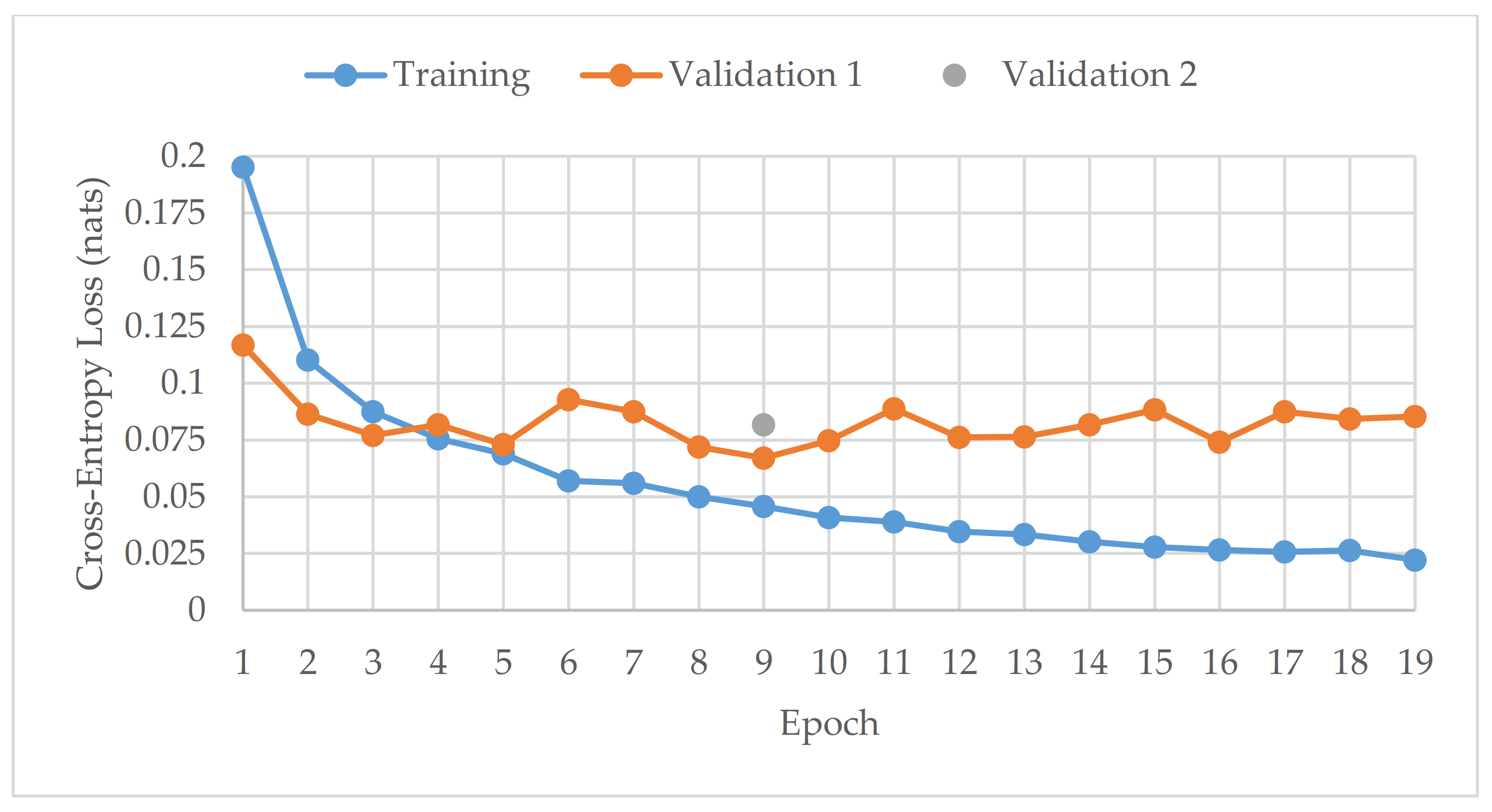
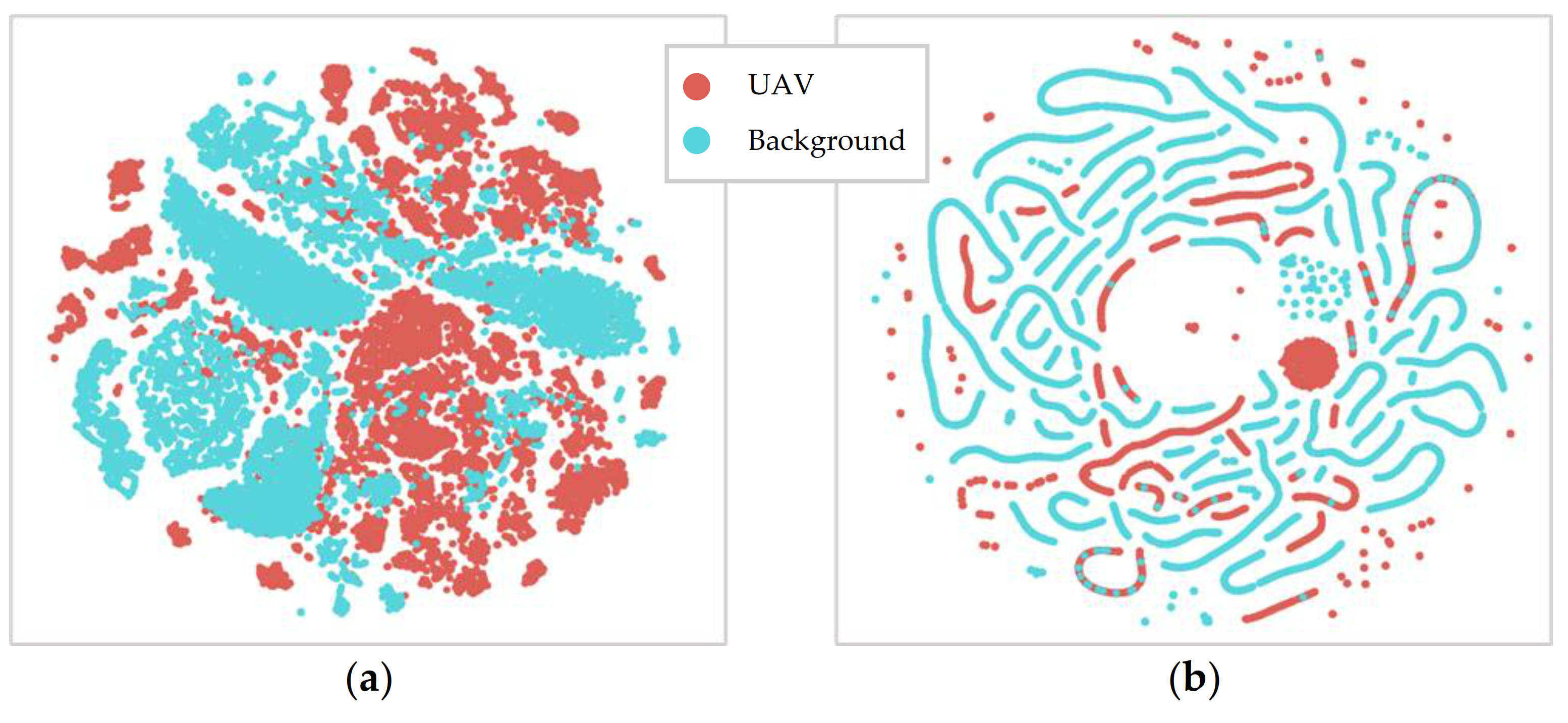
2.2. Model Training
2.3. Optimised Solo Models
2.4. Late Fusion Networks
2.4.1. Hard Voting Setup
2.4.2. Weighted Soft Voting Setup
2.5. Model Evaluation
3. Results
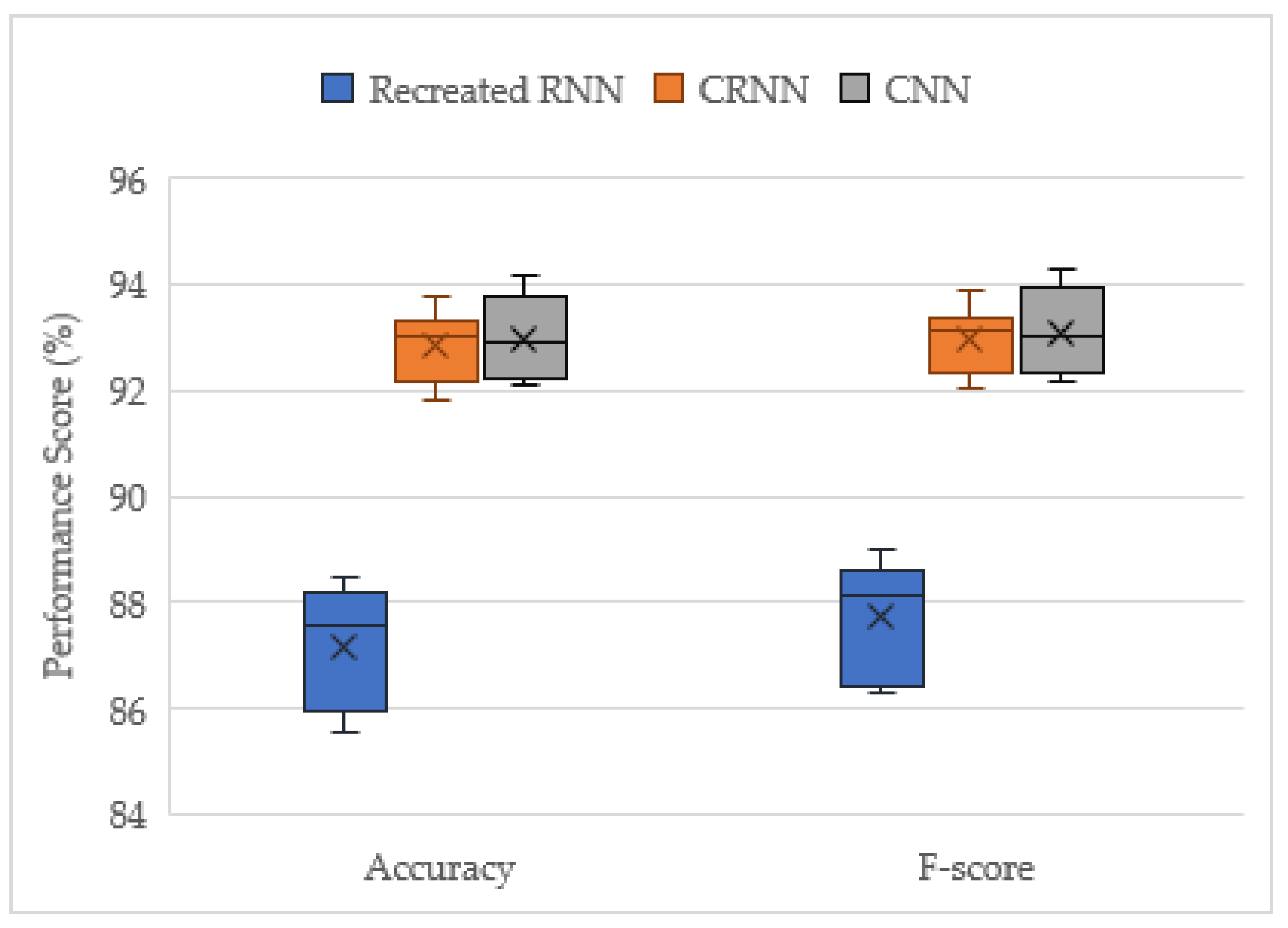
3.1. Solo Model Performance Evaluation on the Unseen Augmented Dataset
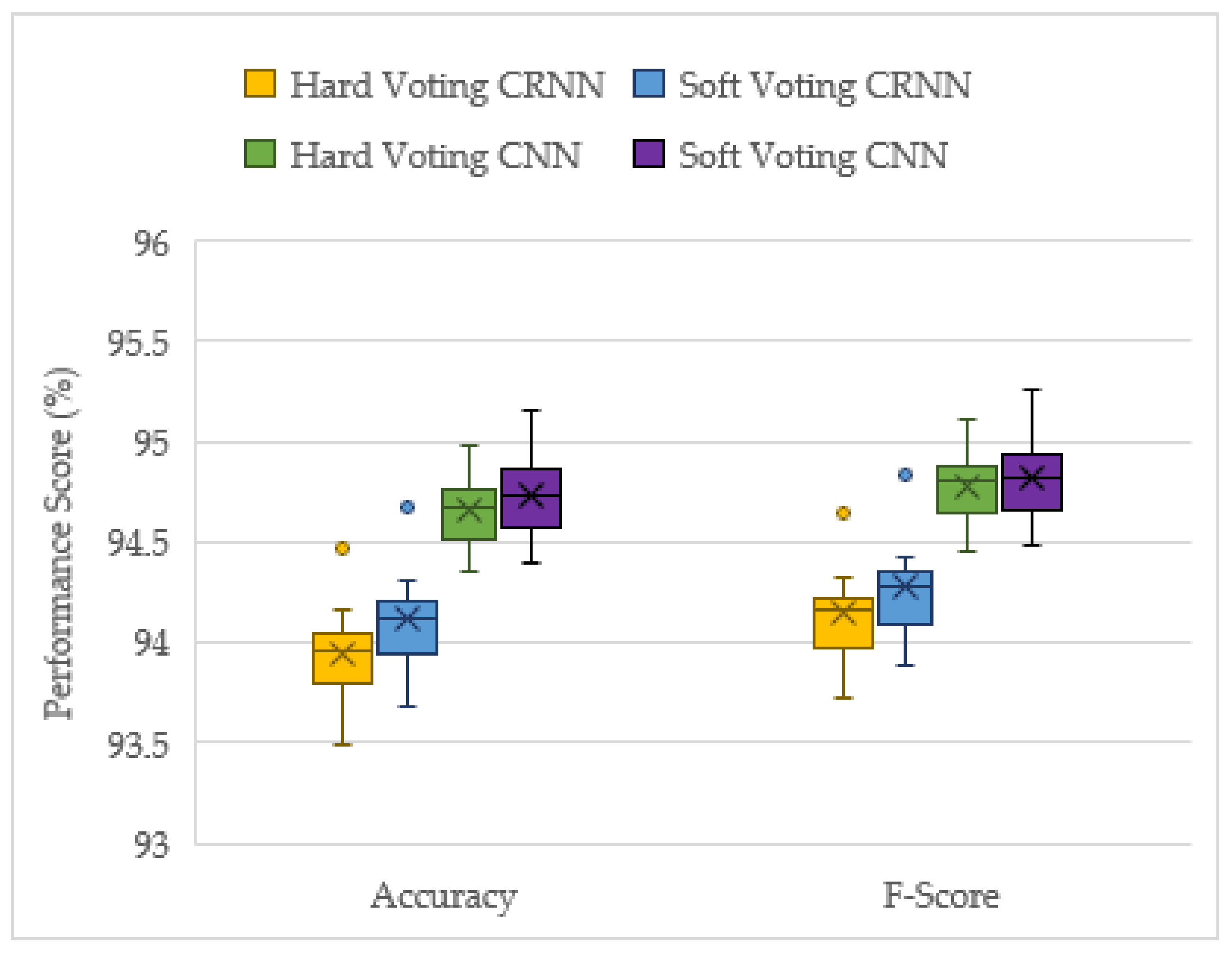
3.2. Late Fusion Networks’ Performance Evaluation on the Unseen Augmented Dataset
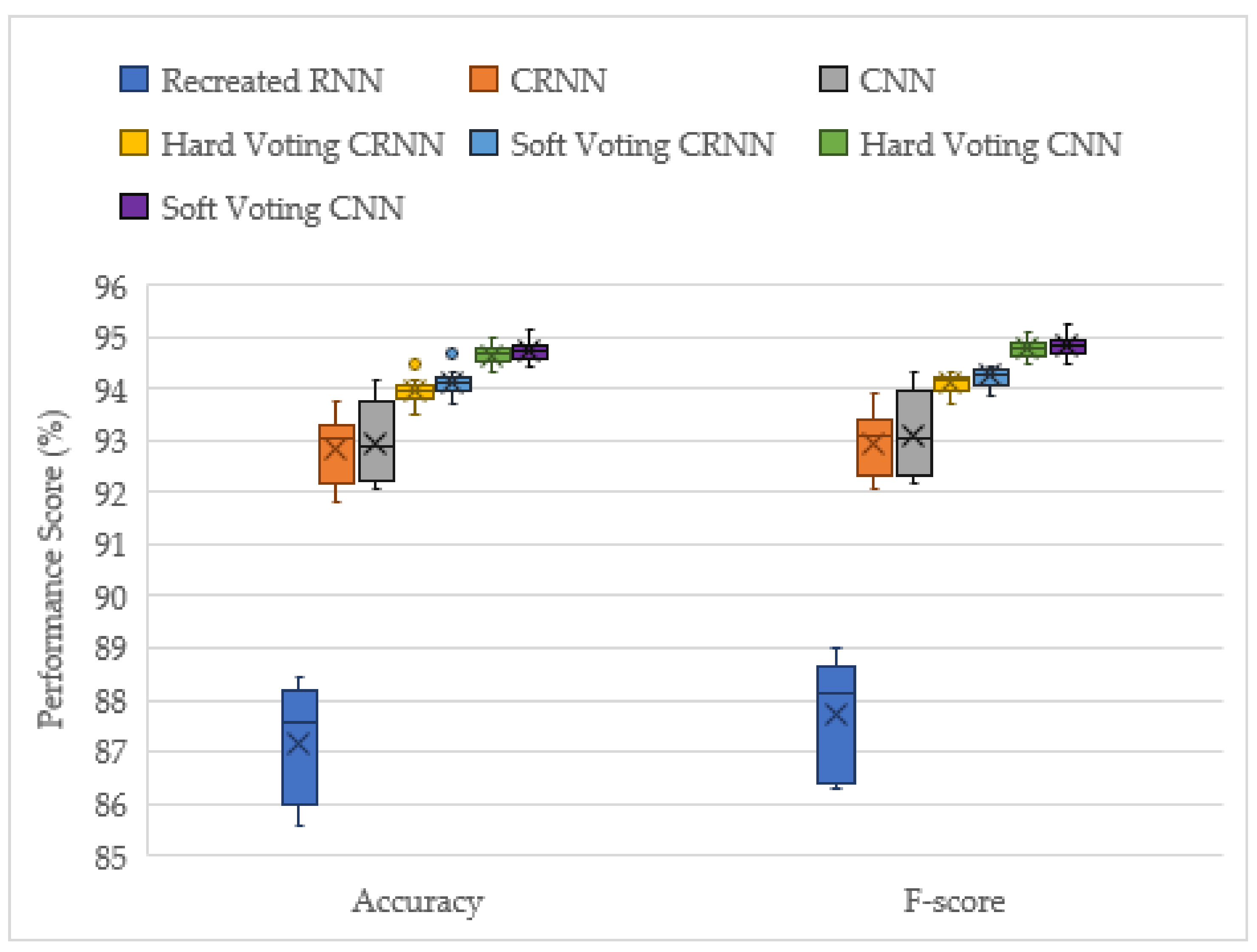
3.3. All Models Performance Comparison
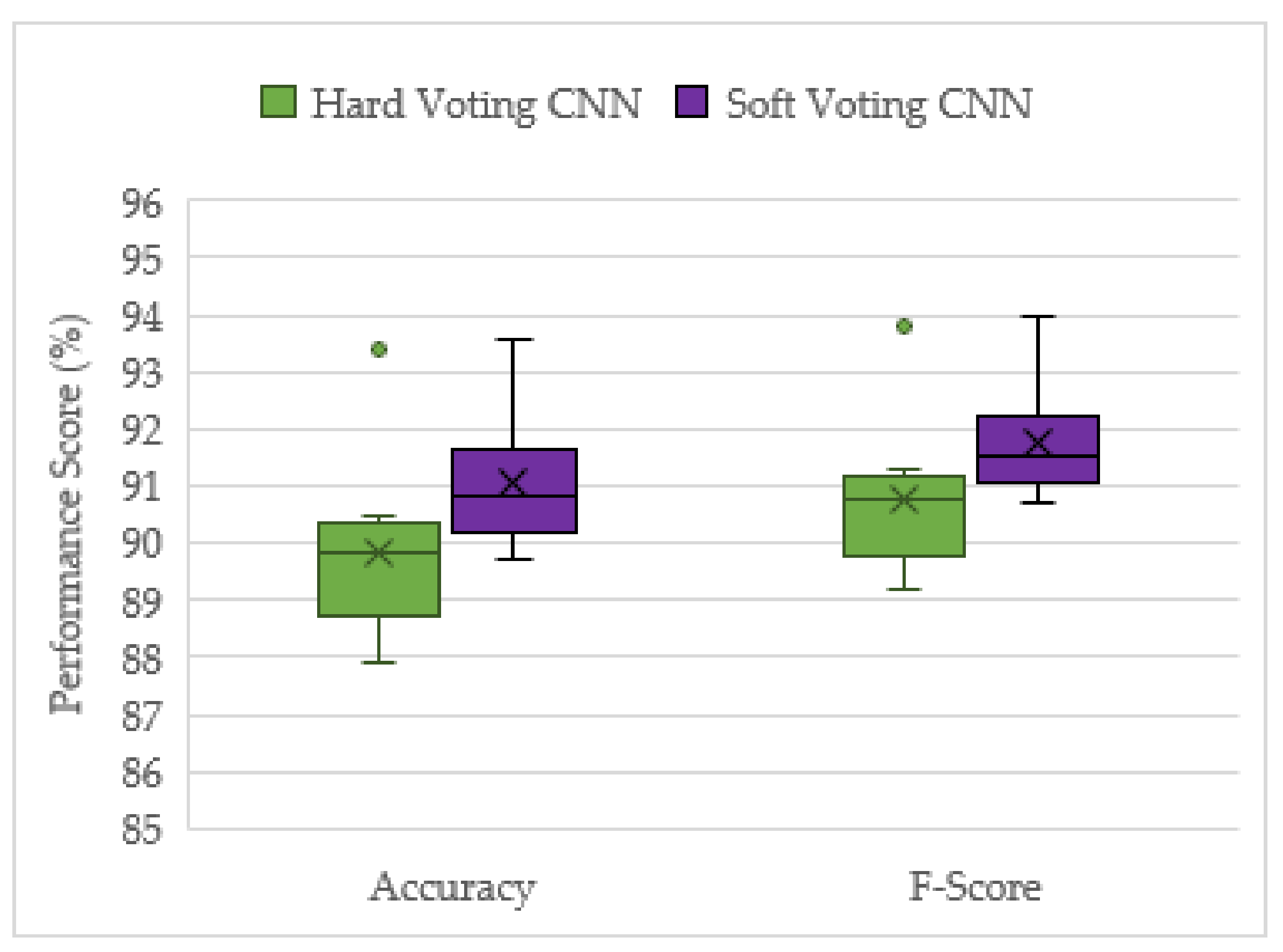
3.4. Top Performing Models on Real-World Unseen Dataset
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vemula, H.C. Multiple Drone Detection and Acoustic Scene Classification with Deep Learning. Master’s Thesis, Wright State University, Dayton, OH, USA, 2018. [Google Scholar]
- Choi-Fitzpatrick, A. Drones for Good: Technological Innovations, Social Movements, and the State. J. Int. Aff. 2014, 68, 19. [Google Scholar]
- Whelan, I. What Happens When a Drone Hits an Airplane Wing? Aviation International News, 3 October 2018. [Google Scholar]
- Geelvink, N. Drones Still a Problem Even with Little Traffic. DFS Deutsche Flugsicherung GmbH, 18 January 2021. [Google Scholar]
- DJI Mini 2. DJI. Available online: https://www.dji.com/uk/mini-2?from=store-product-page (accessed on 29 December 2020).
- Mandal, S.; Chen, L.; Alaparthy, V.; Cummings, M. Acoustic Detection of Drones through Real-Time Audio Attribute Prediction. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; pp. 1–13. [Google Scholar] [CrossRef]
- Baron, V.; Bouley, S.; Muschinowski, M.; Mars, J.; Nicolas, B. Drone Localization and Identification Using an Acoustic Array and Supervised Learning. Int. Soc. Opt. Photonics 2019, 2019, 13. [Google Scholar] [CrossRef]
- Bernardini, A.; Mangiatordi, F.; Pallotti, E.; Capodiferro, L. Drone Detection by Acoustic Signature Identification. Electron. Imaging 2017, 2017, 60–64. [Google Scholar] [CrossRef]
- Anwar, M.Z.; Kaleem, Z.; Jamalipour, A. Machine Learning Inspired Sound-Based Amateur Drone Detection for Public Safety Applications. IEEE Trans. Veh. Technol. 2019, 68, 2526–2534. [Google Scholar] [CrossRef]
- Rabaoui, A.; Kadri, H.; Lachiri, Z.; Ellouze, N. One-Class SVMs Challenges in Audio Detection and Classification Applications. Eurasip J. Adv. Signal Process. 2008, 2008, 1–22. [Google Scholar] [CrossRef][Green Version]
- Zahid, S.; Hussain, F.; Rashid, M.; Yousaf, M.H.; Habib, H.A. Optimized Audio Classification and Segmentation Algorithm by Using Ensemble Methods. Math. Probl. Eng. 2015, 2015, 209814. [Google Scholar] [CrossRef]
- Eklund, V. Data Augmentation Techniques for Robust Audio Analysis. Master’s Thesis, Tampere University, Tampere, Finland, 2019. [Google Scholar]
- Mezei, J.; Molnar, A. Drone Sound Detection by Correlation. In Proceedings of the SACI 2016—11th IEEE International Symposium on Applied Computational Intelligence and Informatics, Timisoara, Romania, 12–14 May; pp. 509–518. [CrossRef]
- Han, Y.; Park, J.; Lee, K. Convolutional Neural Networks with Binaural Representations and Background Subtraction for Acoustic Scene Classification. In Proceedings of the DCASE 2017-Workshop on Detection and Classification of Acoustic Scenes and Events, Munich, Germany, 16–17 November 2017; Volume 2. [Google Scholar]
- Al-Emadi, S.; Al-Ali, A.; Mohammad, A.; Al-Ali, A. Audio Based Drone Detection and Identification Using Deep Learning. In Proceedings of the 2019 15th International Wireless Communications and Mobile Computing Conference, IWCMC 2019, Tangier, Morocco, 24–28 June 2019; pp. 459–464. [Google Scholar] [CrossRef]
- Jeon, S.; Shin, J.W.; Lee, Y.J.; Kim, W.H.; Kwon, Y.H.; Yang, H.Y. Empirical Study of Drone Sound Detection in Real-Life Environment with Deep Neural Networks. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1858–1862. [Google Scholar]
- Nordby, J. Audio Classification Using Machine Learning. In Proceedings of the EuroPython Conference, Basel, Switzerland, 8–14 July 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Martinez-Garcia, M.; Latimer, A. Selecting Optimal Features for Cross-Fleet Analysis and Fault Diagnosis of Industrial Gas Turbines. In Proceedings of the ASME Turbo Expo 2018: Turbomachinery Technical Conference and Exposition, Oslo, Norway, 11–15 June 2018. [Google Scholar] [CrossRef]
- Purwins, H.; Li, B.; Virtanen, T.; Schlüter, J.; Chang, S.Y.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Sel. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef]
- Choi, K.; Fazekas, G.; Sandler, M.; Cho, K. A Comparison of Audio Signal Preprocessing Methods for Deep Neural Networks on Music Tagging. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1870–1874. [Google Scholar] [CrossRef]
- Li, J.; Dai, W.; Metze, F.; Qu, S.; Das, S. A Comparison of Deep Learning Methods for Environmental Sound Detection. In Proceedings of the 2017 IEEE International conference on acoustics, speech and signal processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Martinez-Garcia, M.; Zhang, Y.-D.; Suzuki, K.; Zhang, Y.-D. Deep Recurrent Entropy Adaptive Model for System Reliability Monitoring. IEEE Trans. Ind. Inform. 2021, 17, 839–848. [Google Scholar] [CrossRef]
- Shao, H.; Xia, M.; Han, G.; Zhang, Y.; Wan, J. Intelligent Fault Diagnosis of Rotor-Bearing System Under Varying Working Conditions with Modified Transfer Convolutional Neural Network and Thermal Images. IEEE Trans. Ind. Inform. 2021, 17, 3488–3496. [Google Scholar] [CrossRef]
- Bergstra, J.; Casagrande, N.; Erhan, D.; Eck, D.; Kégl, B. Aggregate Features and ADABOOST for Music Classification. Mach. Learn. 2006, 65, 473–484. [Google Scholar] [CrossRef]
- Xie, J.; Zhu, M. Handcrafted Features and Late Fusion with Deep Learning for Bird Sound Classification. Ecol. Inform. 2019, 52, 74–81. [Google Scholar] [CrossRef]
- Du Boisberranger, J.; van den Bossche, J.; Estève, L.; Fan, T.J.; Gramfort, A.; Grisel, O.; Halchenko, Y.; Hug, N.; Jalali, A.; Lemaitre, G.; et al. Scikit-Learn. Available online: https://scikit-learn.org/stable/about.html (accessed on 17 June 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) 2016, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th python in science conference 2015, Austin, TX, USA, 6–12 July 2015; pp. 18–24. [Google Scholar] [CrossRef]
- Svanstrm, F.; Englund, C.; Alonso-Fernandez, F. Real-Time Drone Detection and Tracking with Visible, Thermal and Acoustic Sensors. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2020. [Google Scholar]
- Sigtia, S.; Dixon, S. Improved Music Feature Learning with Deep Neural Networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Rahul, R.K.; Anjali, T.; Menon, V.K.; Soman, K.P. Deep Learning for Network Flow Analysis and Malware Classification. In Proceedings of the International Symposium on Security in Computing and Communication, Manipal, India, 13–16 September 2017; pp. 226–235. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting Small Batch Training for Deep Neural Networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: London, UK, 2016. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Audio | Time (s) | Total Time (s) |
|---|---|---|---|---|
| Training | UAV | Multirotor UAV-1 | 3410 | 39,940 |
| Multirotor UAV-1 + Background-1 | 16,560 | |||
| No UAV | Background-1 | 16,560 | ||
| Extra Background-2 | 3410 | |||
| Unseen Augmented Testing | UAV | DJI Mini 2 drone + Background-3 | 12,810 | 51,240 |
| RED5 drone + Background-3 | 12,810 | |||
| No UAV | Background-3 | 12,810 | ||
| Extra Background-4 | 12,810 | |||
| Unseen Real-World Testing | UAV | DJI Mini 2 drone with a helicopter flying over | 60 | 546 |
| DJI Mini 2 drone near a road | 213 | |||
| No UAV | Same road | 273 |
| Layer Type | Kernels | Kernel Size | Kernel Stride Size | # of Neurons | Rate | Activation |
|---|---|---|---|---|---|---|
| 2D Convolutional | 8 | 5 5 | - | - | - | ReLU |
| 2D Max Pooling | - | 5 5 | 2 | - | - | - |
| Batch Normalization | - | - | - | - | - | - |
| 2D Convolutional | 32 | 5 5 | - | - | - | ReLU |
| 2D Max Pooling | - | 5 5 | 2 | - | - | - |
| Batch Normalization | - | - | - | - | - | - |
| Flatten | - | - | - | - | - | - |
| Dense | - | - | - | 32 | - | ReLU |
| Dropout | - | - | - | - | 0.3 | - |
| Dense (Output) | - | - | - | 2 | - | Softmax |
| Layer Type | Kernels | Kernel Size | Kernel Stride Size | Memory Units | # of Neurons | Rate | Activation |
|---|---|---|---|---|---|---|---|
| 2D Convolutional | 16 | 5 5 | - | - | - | - | ReLU |
| 2D Max Pooling | - | 5 5 | 2 | - | - | - | - |
| Batch Normalization | - | - | - | - | - | - | - |
| Reshape for LSTM | - | - | - | - | - | - | - |
| LSTM | - | - | - | 32 | - | - | - |
| Flatten | - | - | - | - | - | - | - |
| Dense | - | - | - | - | 32 | ReLU | |
| Dropout | - | - | - | - | - | 0.4 | - |
| Dense (Output) | - | - | - | - | 2 | - | Softmax |
| Layer Type | Memory Units | # of Neurons | Rate | Activation |
|---|---|---|---|---|
| Bidirectional LSTM | 100 | - | - | - |
| Bidirectional LSTM | 100 | - | - | - |
| Bidirectional LSTM | 100 | - | - | - |
| Dense | - | 100 | - | ReLU |
| Dropout | - | - | 0.5 | - |
| Dense (Output) | - | 2 | - | Softmax |
| Score (%) | Recreated RNN | Optimised CRNN | Optimised CNN | Hard Voting CRNN | Soft Voting CRNN | Hard Voting CNN | Soft Voting CNN |
|---|---|---|---|---|---|---|---|
| Accuracy | 87.147 | 92.847 | 92.957 | 93.947 | 94.118 | 94.654 | 94.725 |
| F-score | 87.723 | 92.962 | 93.089 | 94.142 | 94.274 | 94.773 | 94.815 |
| Score (%) | Hard Voting CNN | Soft Voting CNN |
|---|---|---|
| Accuracy | 89.835 | 91.044 |
| F-score | 90.741 | 91.747 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casabianca, P.; Zhang, Y. Acoustic-Based UAV Detection Using Late Fusion of Deep Neural Networks. Drones 2021, 5, 54. https://doi.org/10.3390/drones5030054
Casabianca P, Zhang Y. Acoustic-Based UAV Detection Using Late Fusion of Deep Neural Networks. Drones. 2021; 5(3):54. https://doi.org/10.3390/drones5030054
Chicago/Turabian StyleCasabianca, Pietro, and Yu Zhang. 2021. "Acoustic-Based UAV Detection Using Late Fusion of Deep Neural Networks" Drones 5, no. 3: 54. https://doi.org/10.3390/drones5030054
APA StyleCasabianca, P., & Zhang, Y. (2021). Acoustic-Based UAV Detection Using Late Fusion of Deep Neural Networks. Drones, 5(3), 54. https://doi.org/10.3390/drones5030054