1. Introduction
Multirotor Unmanned Aerial Vehicles (UAVs) are a type of UAV propelled by more than one rotor. In this paper, the terms
UAV and
drone will be used interchangeably to refer to multirotor UAVs. While UAVs’ initial use was limited to the military sector [
1], private owners and companies are presently utilizing them in a growing number of applications such as art, cinematography, documentary productions and deliveries. Additionally, governments are increasing drone use for public health and safety purposes, such as supporting firefighters, ambulance services and search-and-rescue operations [
2]. The lists continue to expand as UAV technology advances, improving their performance while reducing their price. However, this widespread use of drones has drawn significant attention to the security risks, especially those associated with airspace breaches and drone-to-aircraft collisions.
In 2018, researchers at the University of Dayton Research Institute studied the effect of a drone striking a plane’s wing during flight. They discovered that the UAV could fully penetrate the wing’s leading edge and could cause catastrophic damage at higher speeds [
3]. Germany has warned of a recent increase in drone interference, after reporting 92 drone-related incidents in their airspace during 2020, with one third of the cases resulting in air traffic being severely disrupted [
4]. Even with reduced air traffic due to the pandemic, drone related disruptions continue to rise. Unwelcome UAV activity has proven to be severely costly and dangerous, and methods for their identification must be implemented and improved.
Hostile drone intrusions need to be detected as early as possible to ensure that countermeasures can be taken to neutralize them. The four detection methods currently in use are visual-, radar-, radio- and acoustic-based. With UAVs getting smaller and camouflaging more with the surrounding environment (for example: DJI Mini 2 [
5]), cameras can sometimes fail to identify their presence [
6]. Radars also struggle to reflect signals from small targets, and autonomous drones can bypass radio detection [
7]. Thus, this project focuses on the acoustic detection of multirotor UAVs, through the use of deep learning methods, which can then be used together with the other detection techniques to improve the rate of success in UAV identification.
Standard classification models through supervised learning have been established by published research studying audio signals [
6,
8,
9,
10,
11,
12]. In this paper, the supervised learning methodology focuses on the binary classification of
UAV and
background. Any mix of sounds comprising drones is labelled as
UAV, while all the other sounds are labelled as
background.
Most published research on acoustic drone identification has used raw audio formatted in mono-channel, with a 16-bit resolution and a sampling frequency of 44.1 kHz [
1,
13,
14]. There are a multitude of different pre-processing and feature extraction parameters to choose from, such as which time-frequency features to extract, what audio clip length to use, or if there should be overlap between clips [
15,
16,
17]. Hence, a sensitivity study is needed to obtain the optimum pre-processing and feature extraction parameters for acoustic UAV detection. Additionally, there is a lack of publicly available datasets of drones in different real-world environments. To counteract this, some studies have artificially augmented the collected drone audio clips with other environmental sounds [
1,
15,
16].
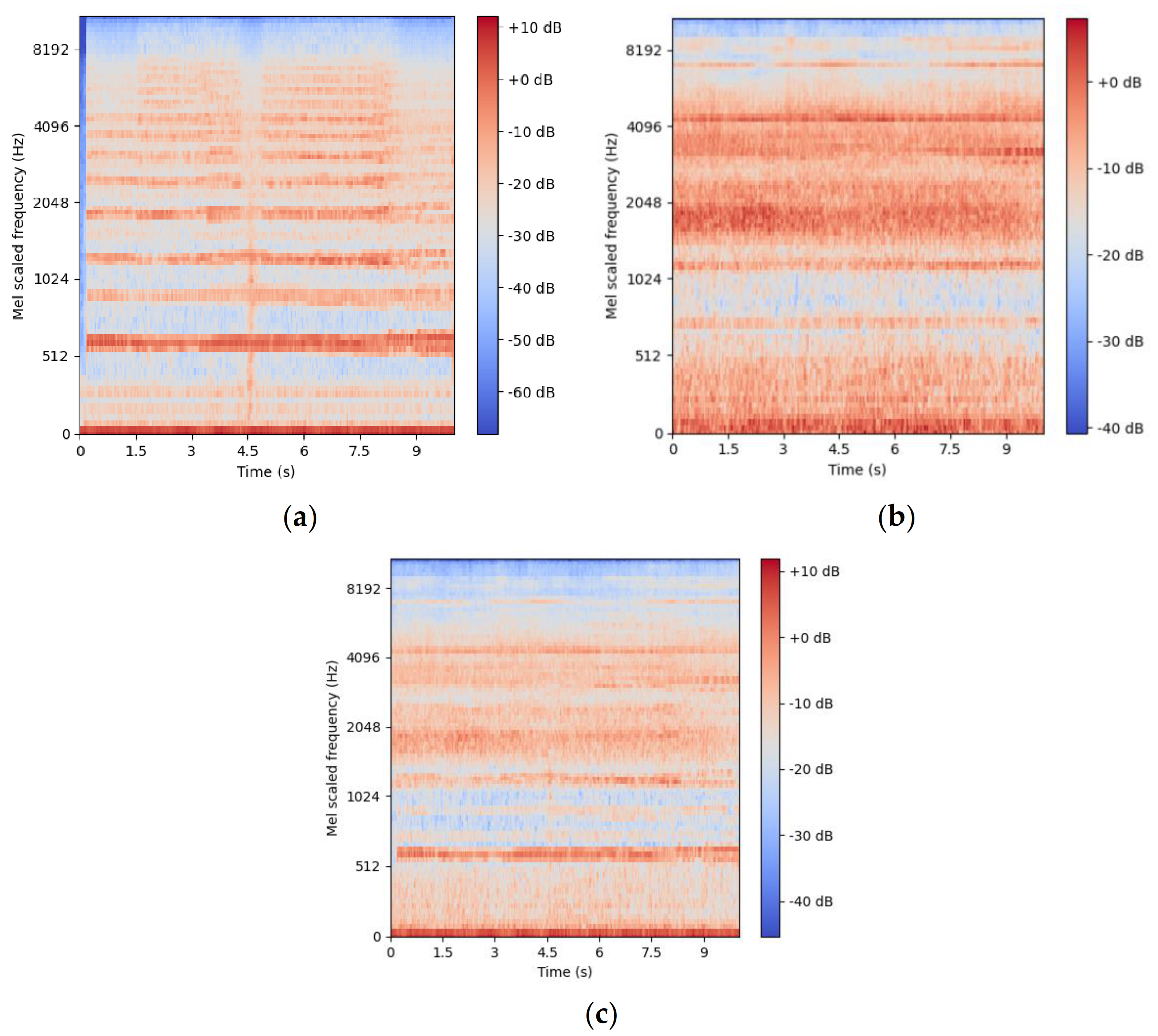
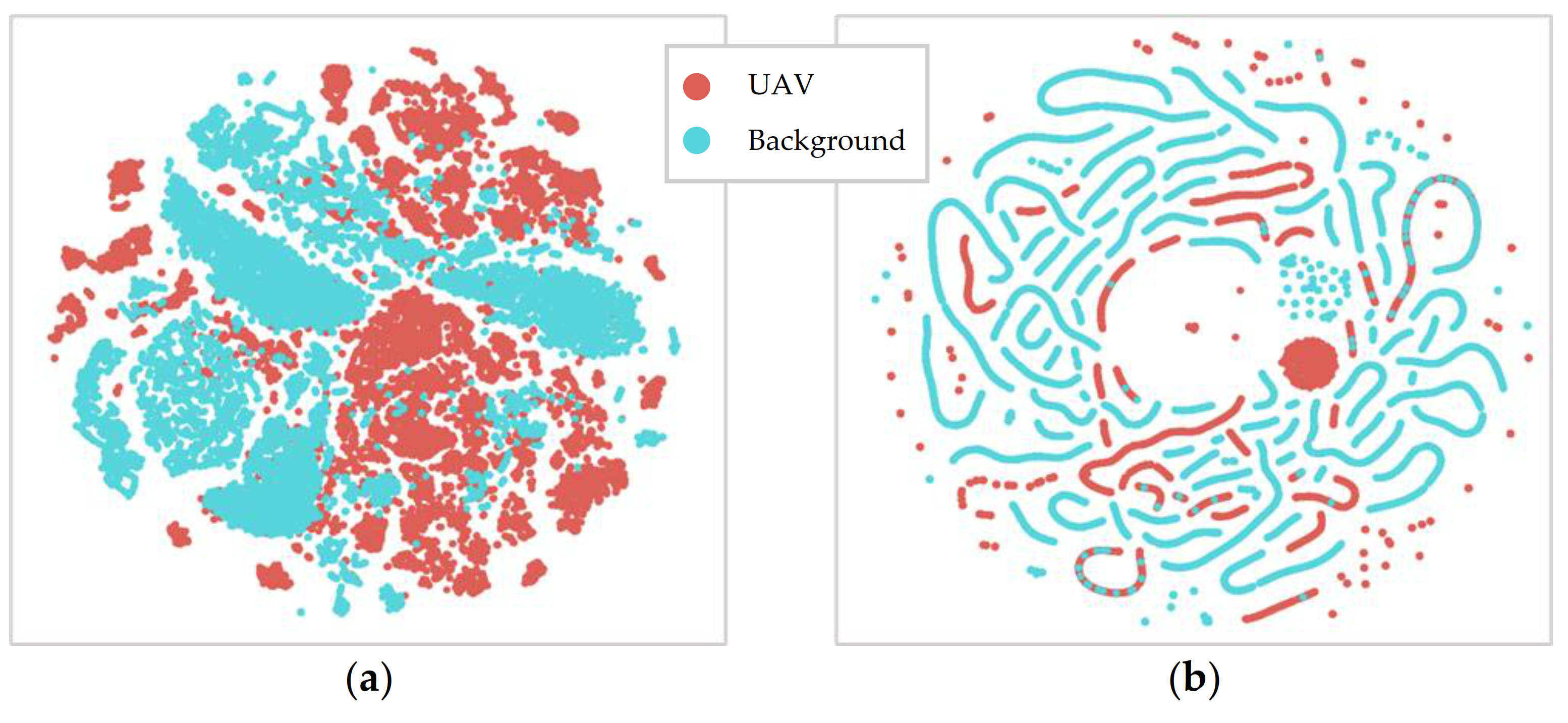
Features from the raw audio are extracted for model training with the aim to reduce the dimensionality of the data, disregarding redundant information and simplifying the training task [
12]. For traditional machine learning, an extensive list of features must be manually extracted and optimized to fine-tune the algorithm. If such features are not optimal for the classification objective (e.g., drone detection), the performance of the model will be limited. Hence, extracting features becomes an additional challenge, as there is no guarantee that they are optimized for the classification objective [
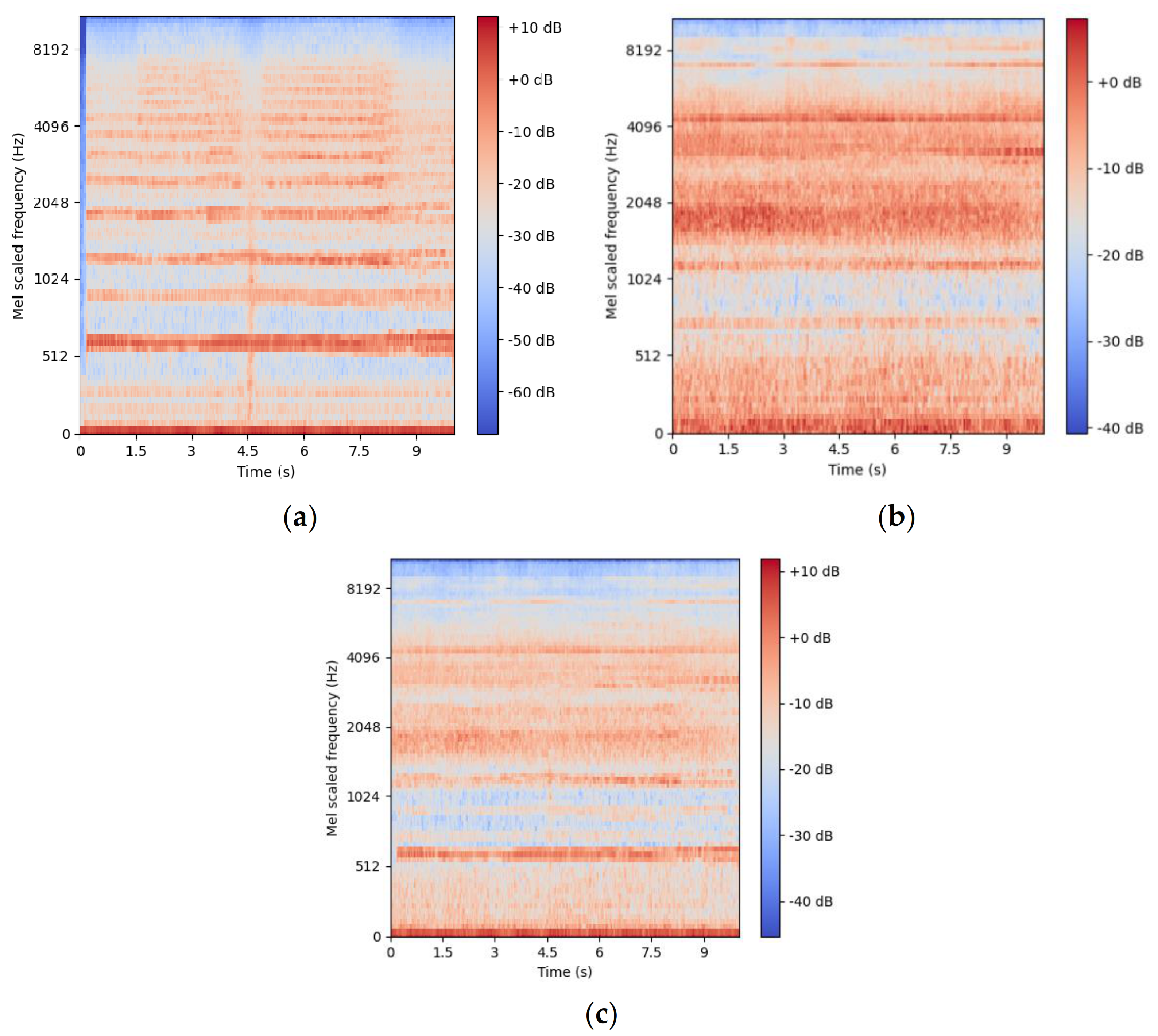
18]. Feature extraction is less of a problem when working with deep learning models, which perform best with features closer to the original audio signals, such as mel-spectrograms [
19]. The neural network layers can then extract important information from the more general features, training themselves for the objective [
20].
The state-of-the-art deep learning architectures used in audio classification models include Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) and Convolutional Recurrent Neural Networks (CRNNs) [
14,
15,
16,
21]. CRNNs are an early fusion of the two networks, where the RNN processes the output of the CNN [
19]. Eklund [
12] states that the classification task and the type of data fed to the model may drive the decision on which model architectures to use. In general, RNNs perform better in natural language processing applications, whereas CNNs are best suited for image processing tasks. This is because RNNs contain the memory elements for context on the previous inputs of the time series [
22], while CNNs possess the filtering property of the visual system for processing images [
23]. Since the features extracted from raw audios are stored in a graphic format, CNNs should outperform RNNs, as confirmed by Al-Emadi et al. [
15]. Despite Jeon et al. [
16] concluding the opposite, possibly due to a difference in the construction of the models and their layers, both papers have confirmed the validity of utilizing deep learning for acoustic drone detection.
This report aims to investigate which model architecture (CNN, CRNN or RNN) shows the highest performance for the acoustic identification of UAVs, and then to introduce a form of late fusion of a network ensemble for acoustically detecting drones. Inspired by the conventional ensemble methods, such as random forest and AdaBoost [
24], it is believed that an ensemble of classification models would perform better than the solo models. To the best of the authors knowledge, hard voting and weighted soft voting methods have not been tested for the acoustic identification of drones, although similar forms of late fusion networks have given promising results for other audio classification problems [
21,
25]. Therefore, the main contributions of this paper are as follows:
Reinforce the viability of utilizing deep neural networks for the detection of multirotor UAVs with acoustic signals;
Investigate which model architecture (CNN, CRNN, or RNN) performs the best for acoustic UAV identification;
Evaluate the performance of late fusion networks compared with solo models and determine the most suitable voting mechanism in this study.
The remainder of this article is structured as follows:
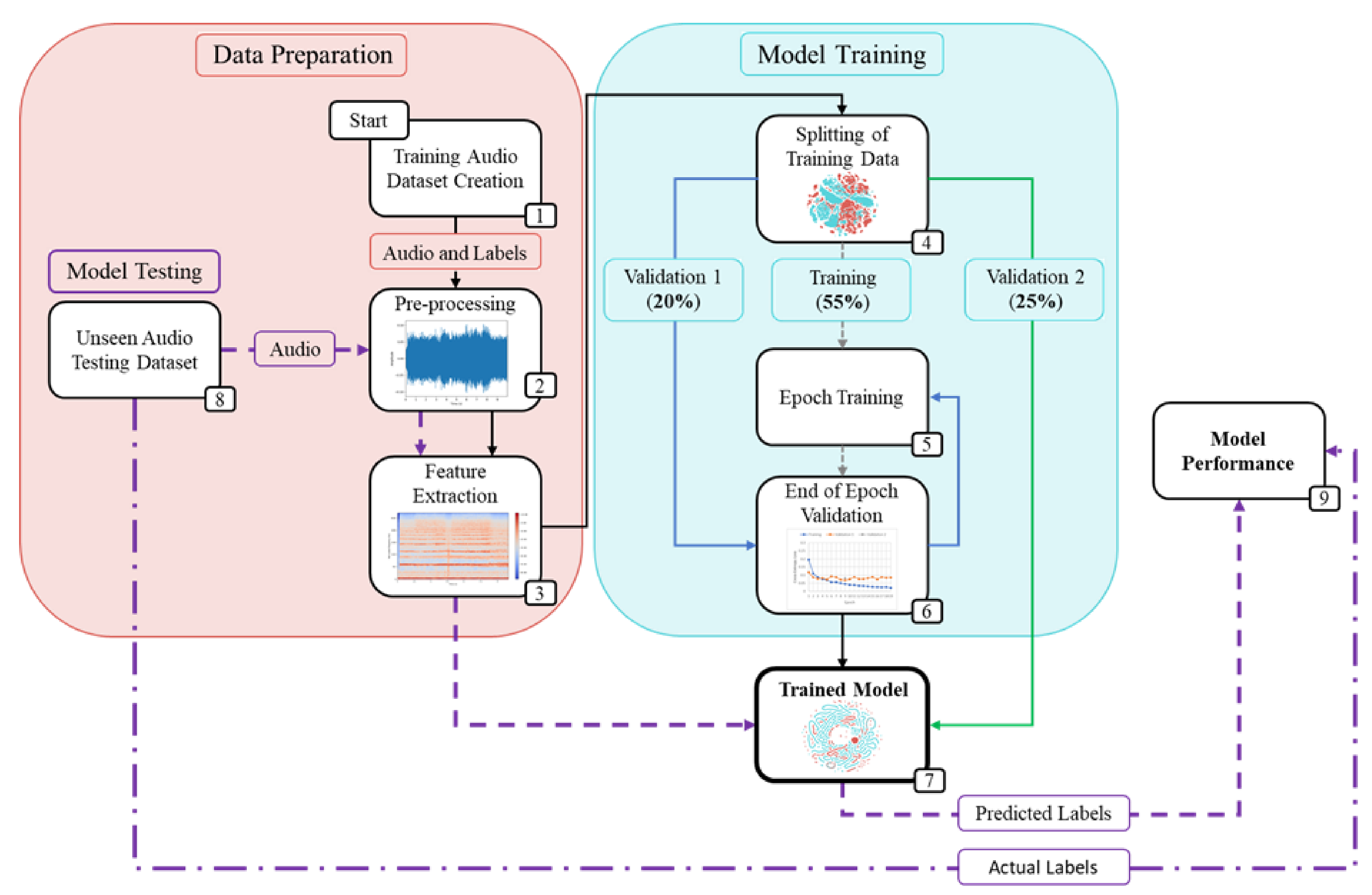
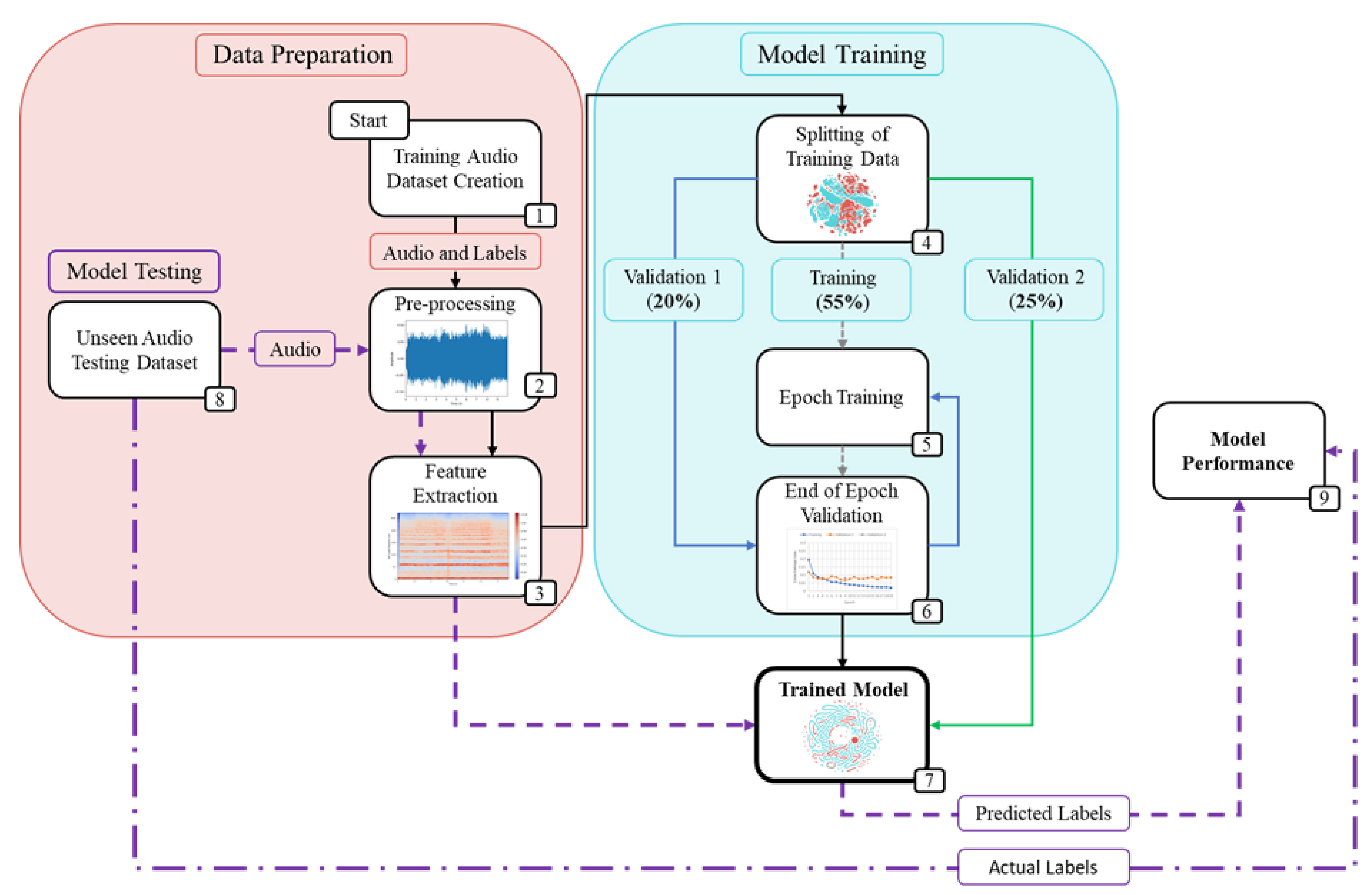
Section 2 discusses the methodology used for this project, detailing the data preparation, model training setup and model constructions.
Section 3 provides and discusses the experimental results, comparing the performance of all the created models and detailing how the findings compare to previous research.
Section 4 summarizes the conclusions and recommends future work.
4. Conclusions
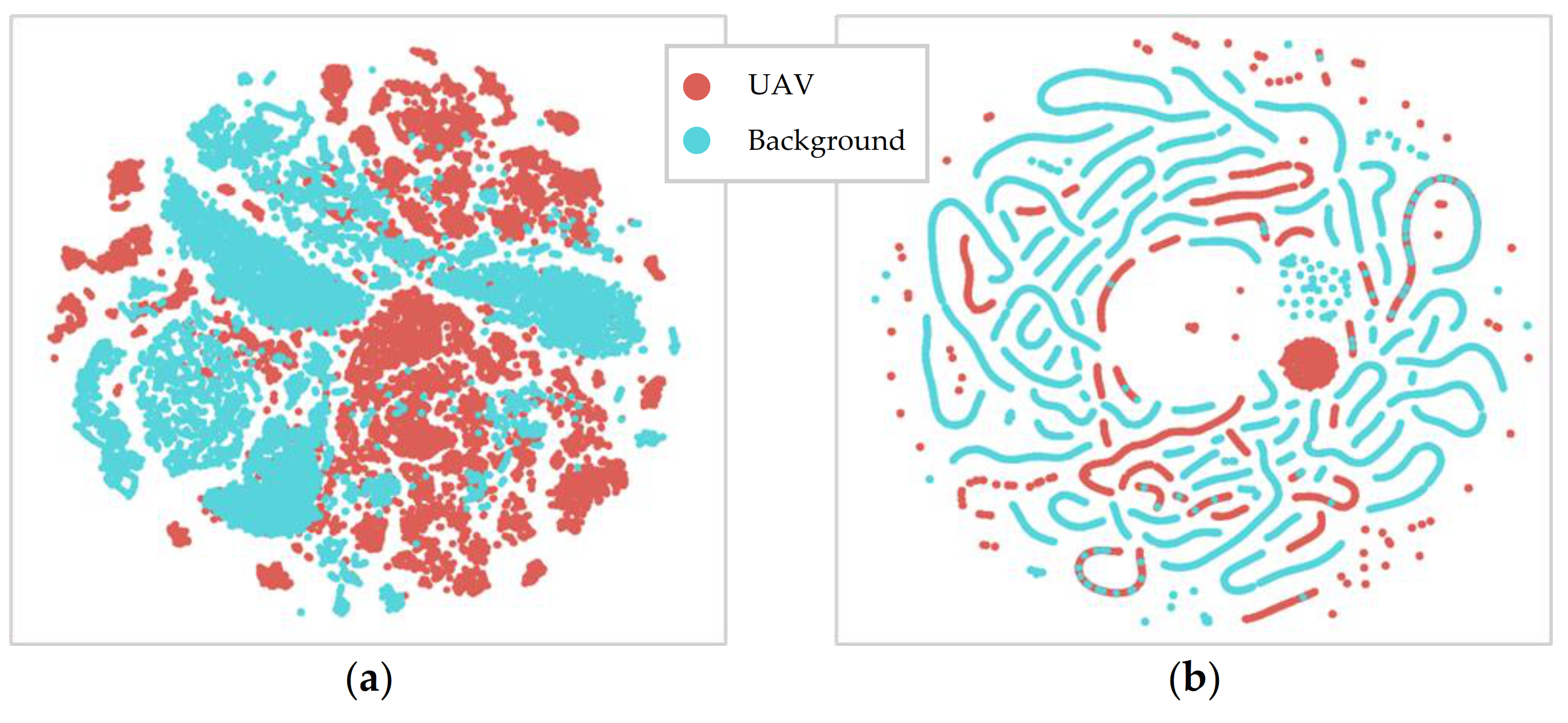
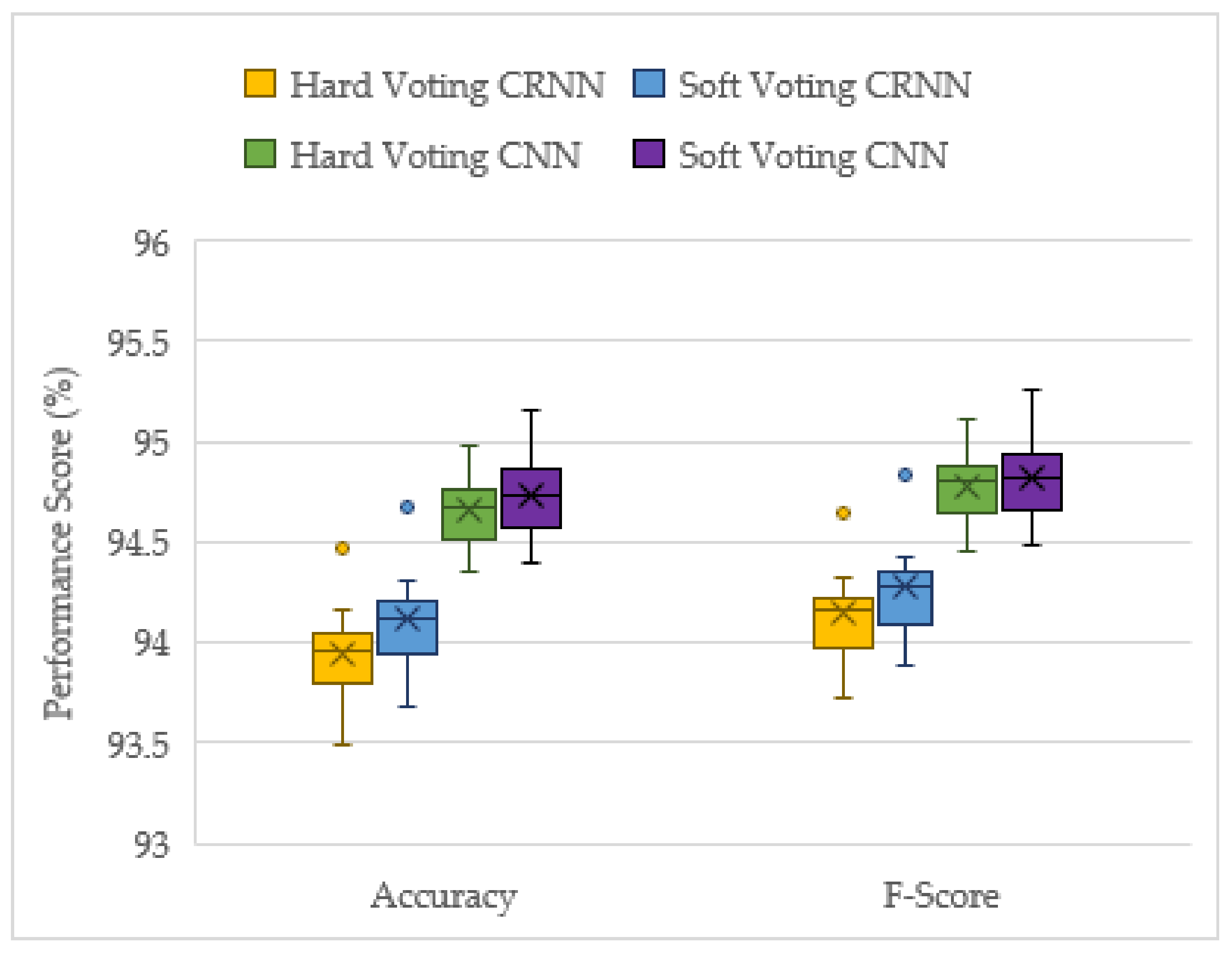
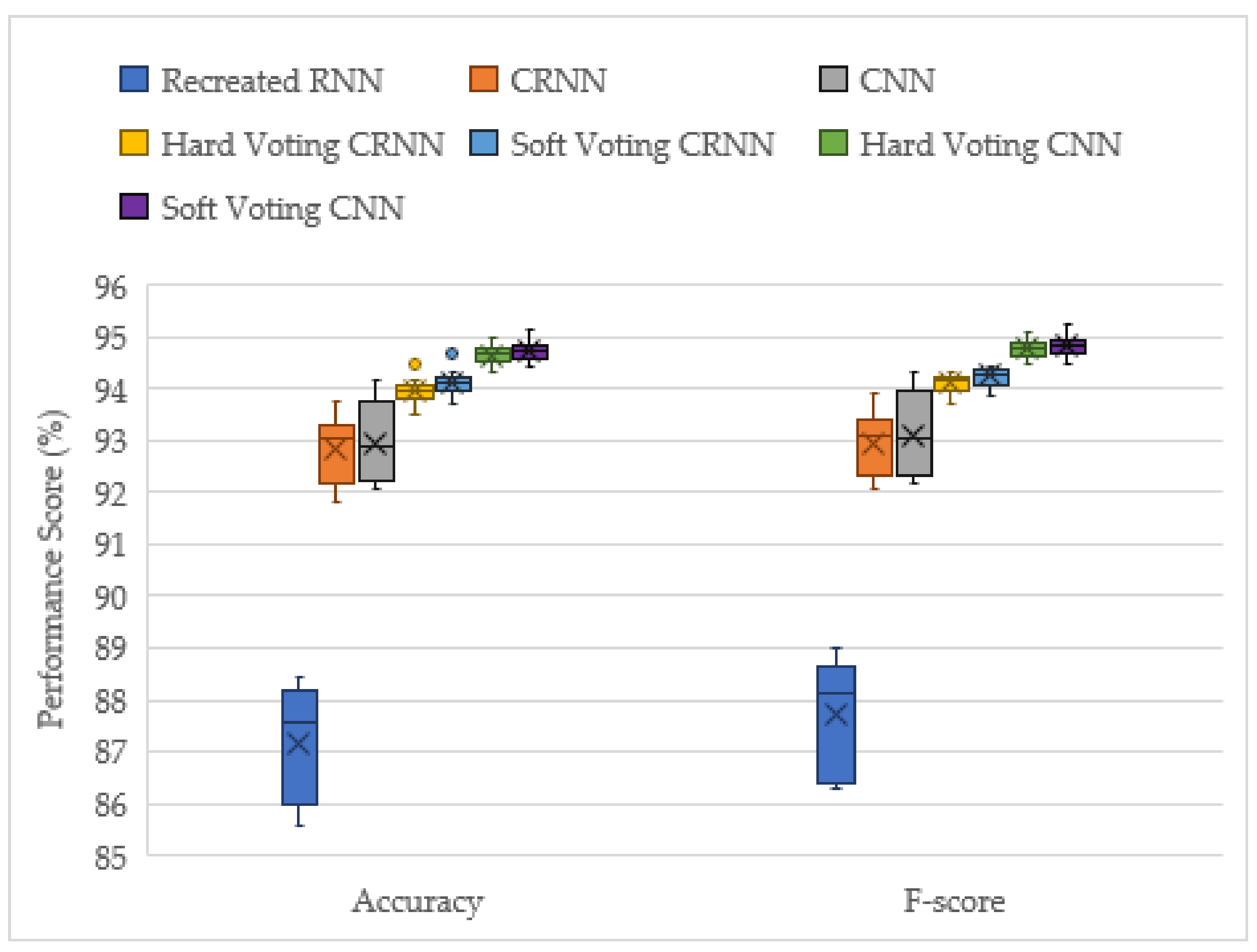
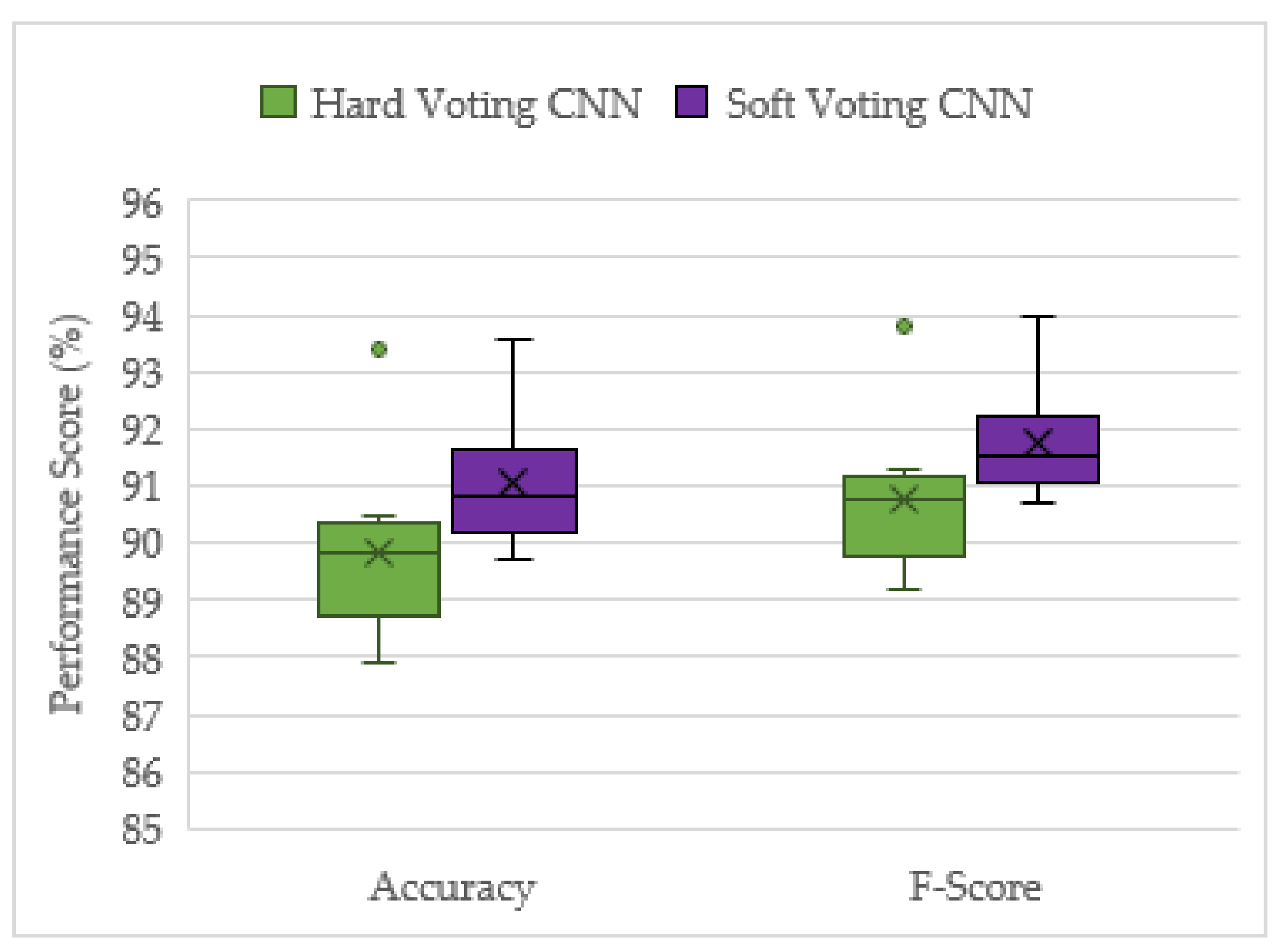
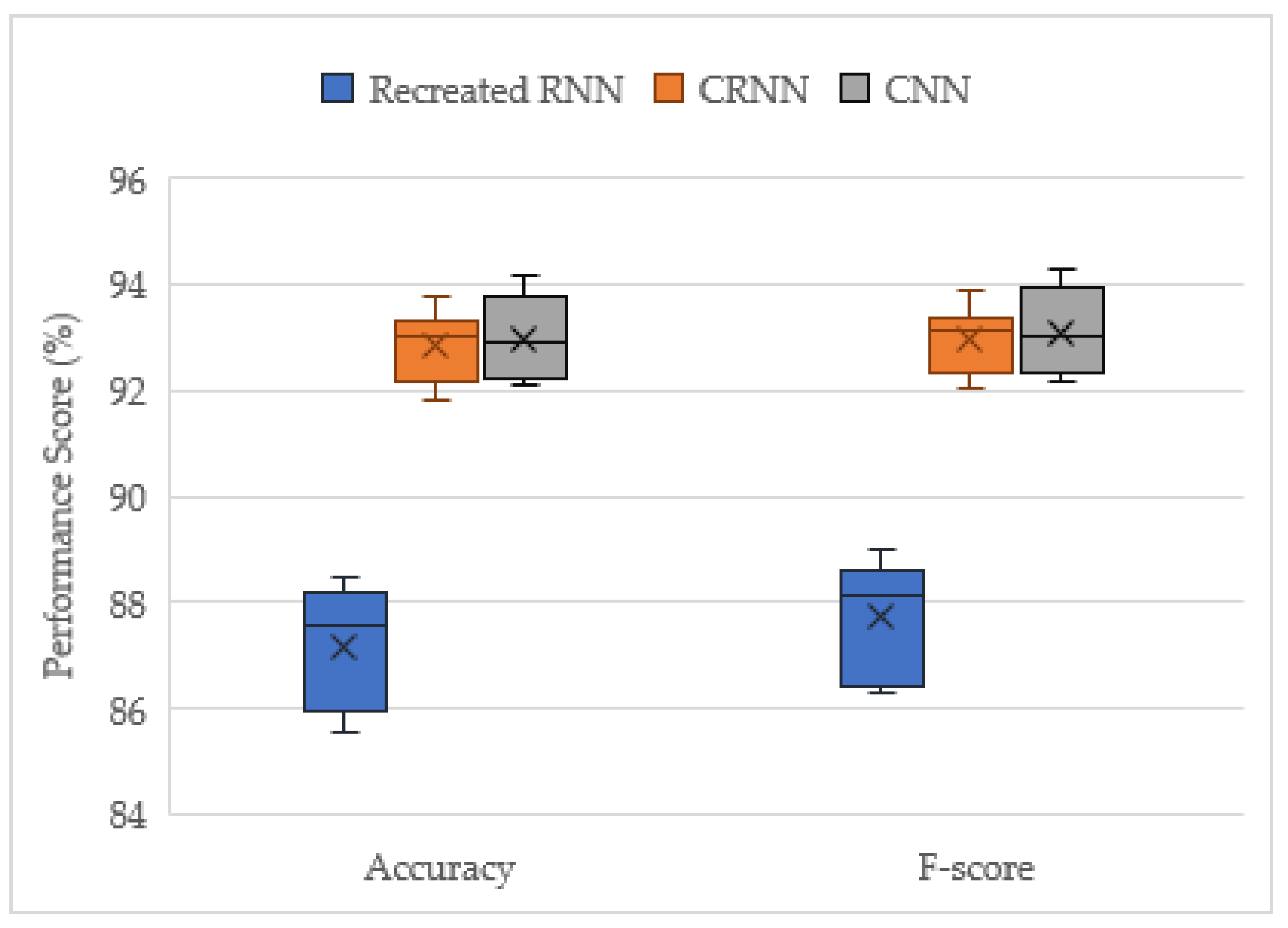
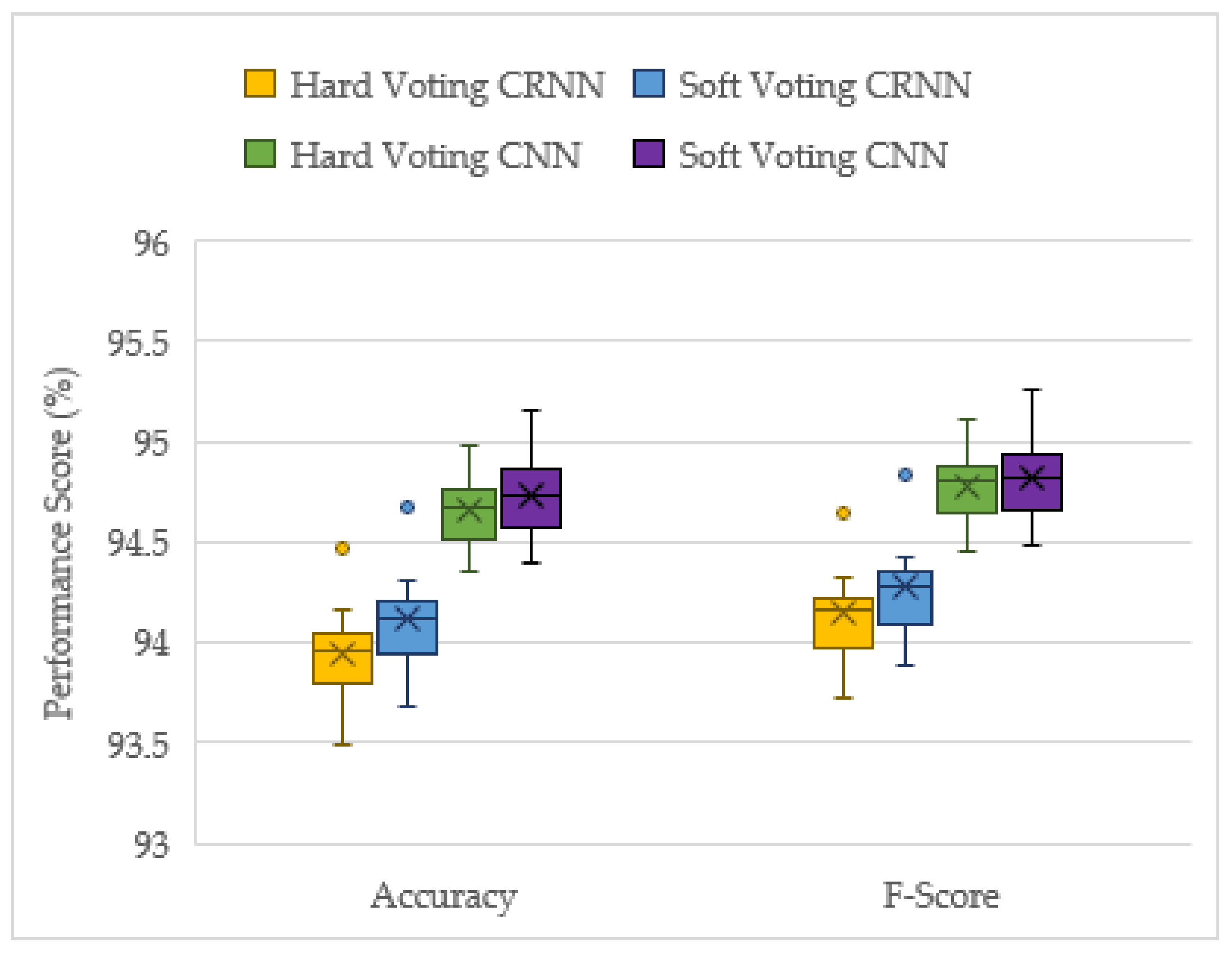
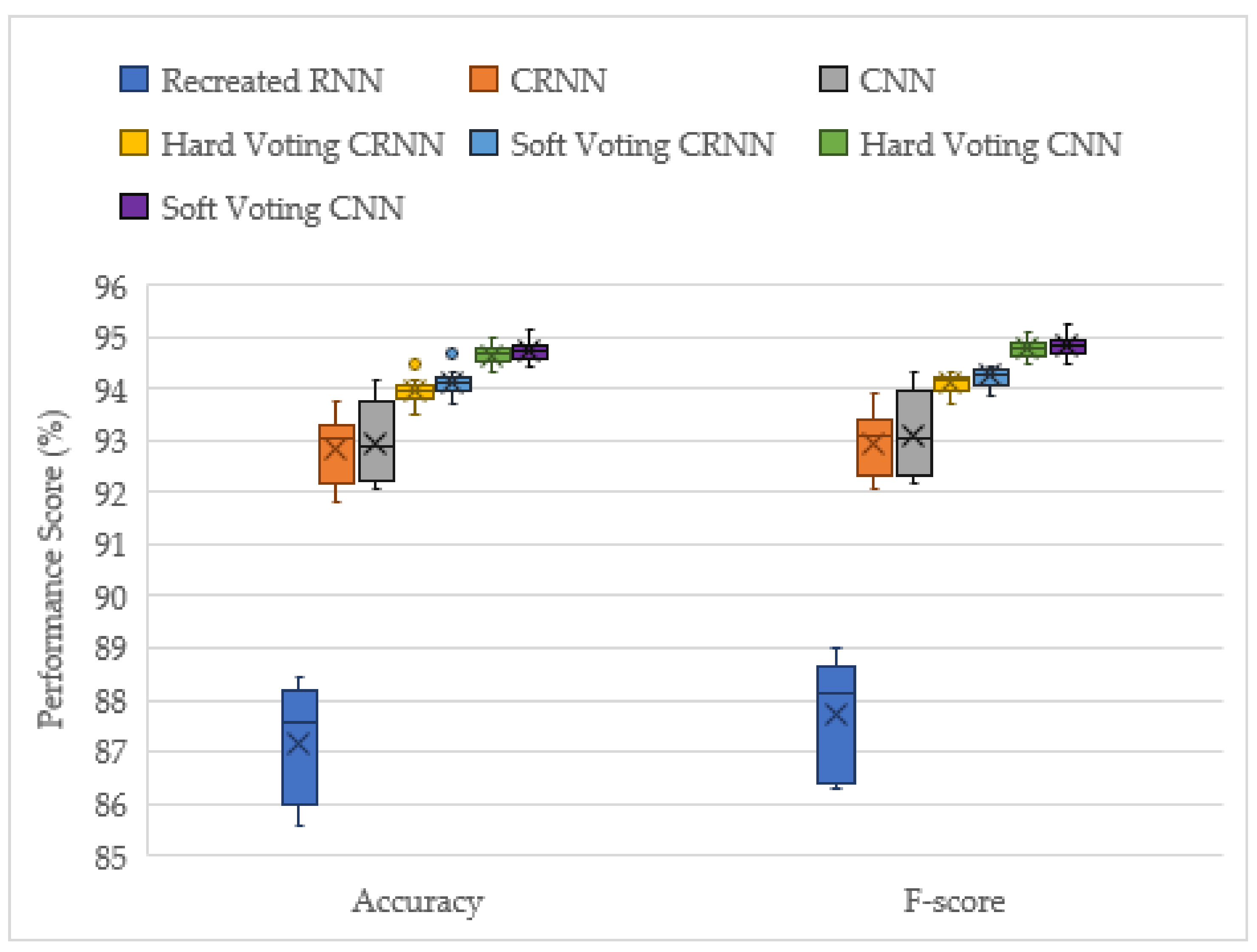
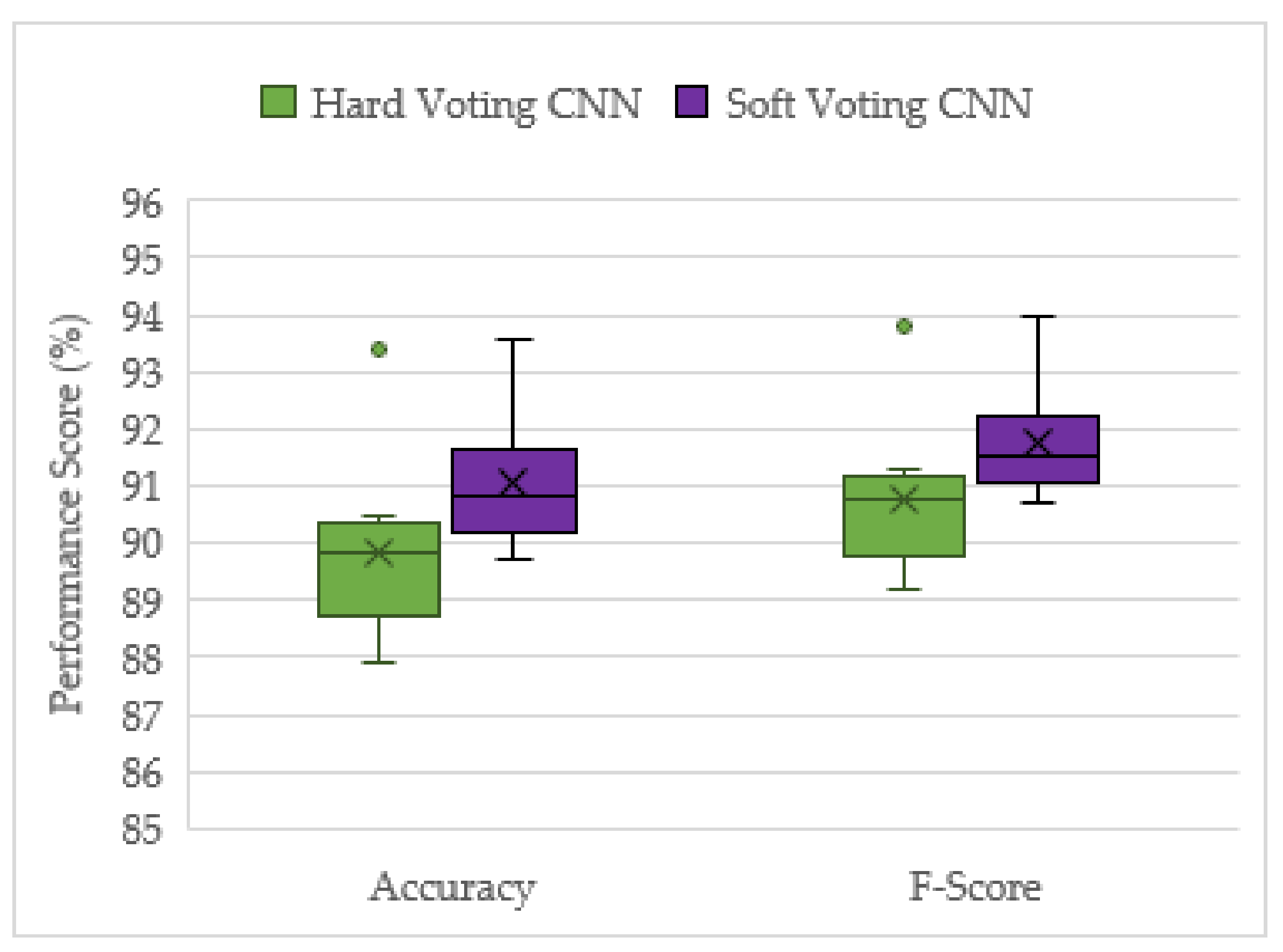
This project has demonstrated the effectiveness of ensemble deep learning models for the acoustic identification of multirotor UAVs, which achieved classification accuracies as high as 94.7 and 91.0% from the unseen augmented and real-world testing datasets, respectively. The investigation conducted on the optimized solo model architectures resulted in the CNN and CRNN models outperforming the recreated top performing model from [
16], an RNN model. In this study, the acoustic signals were transformed into mel-spectrograms, and CNNs have been shown to be the best suited for image processing tasks. The solo CNN model performs slightly better than the CRNN, but it has more instability in its results. Furthermore, when late fusion was used, the CNN voting ensemble significantly outperformed the CRNN ensemble, and the CRNNs stability advantage was lost. Hence, both the reported advantages of the CRNN models [
15] were not found in late fusion, and the CNN model was shown to be the best suited for this acoustic UAV detection application.
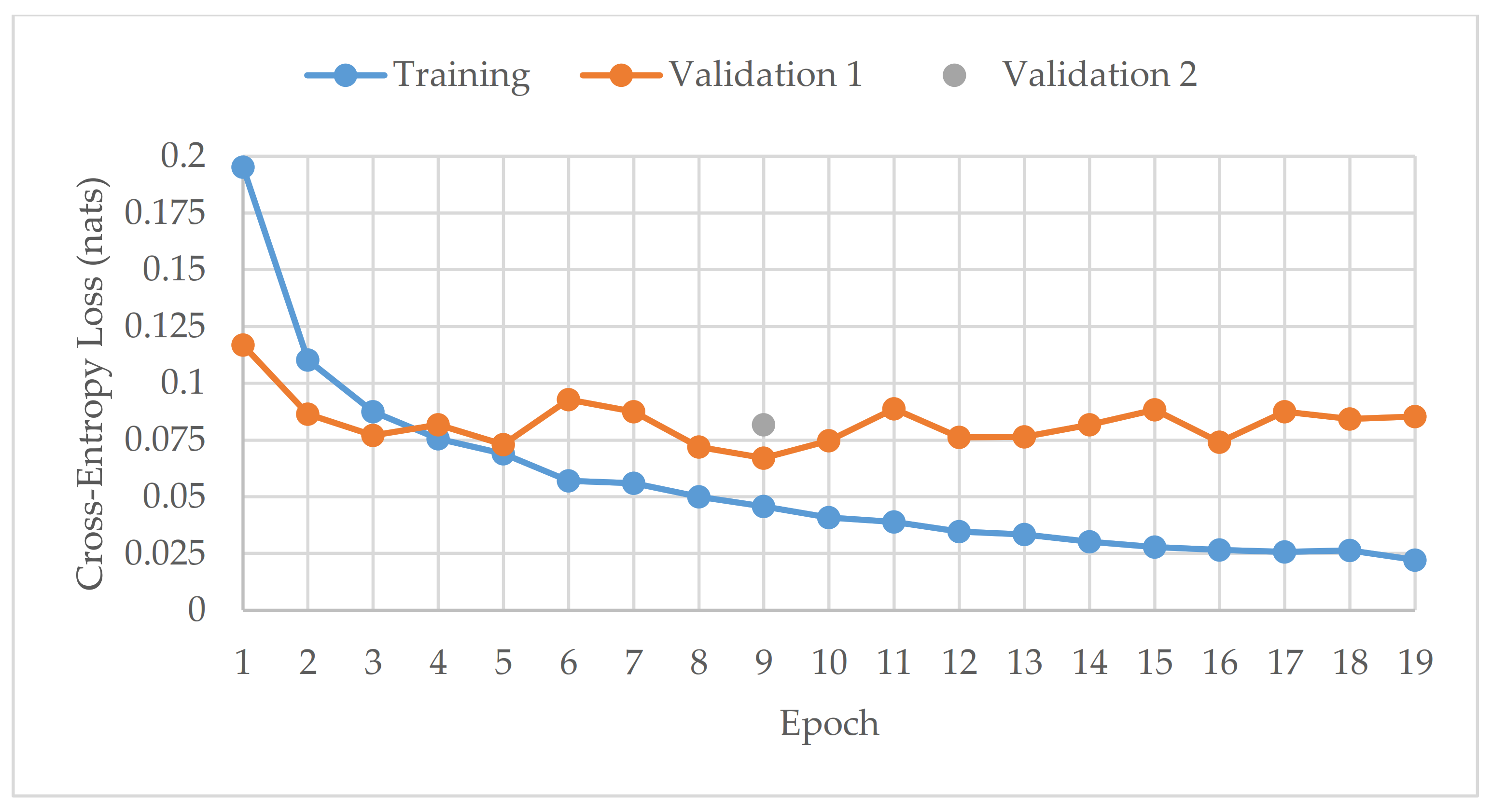
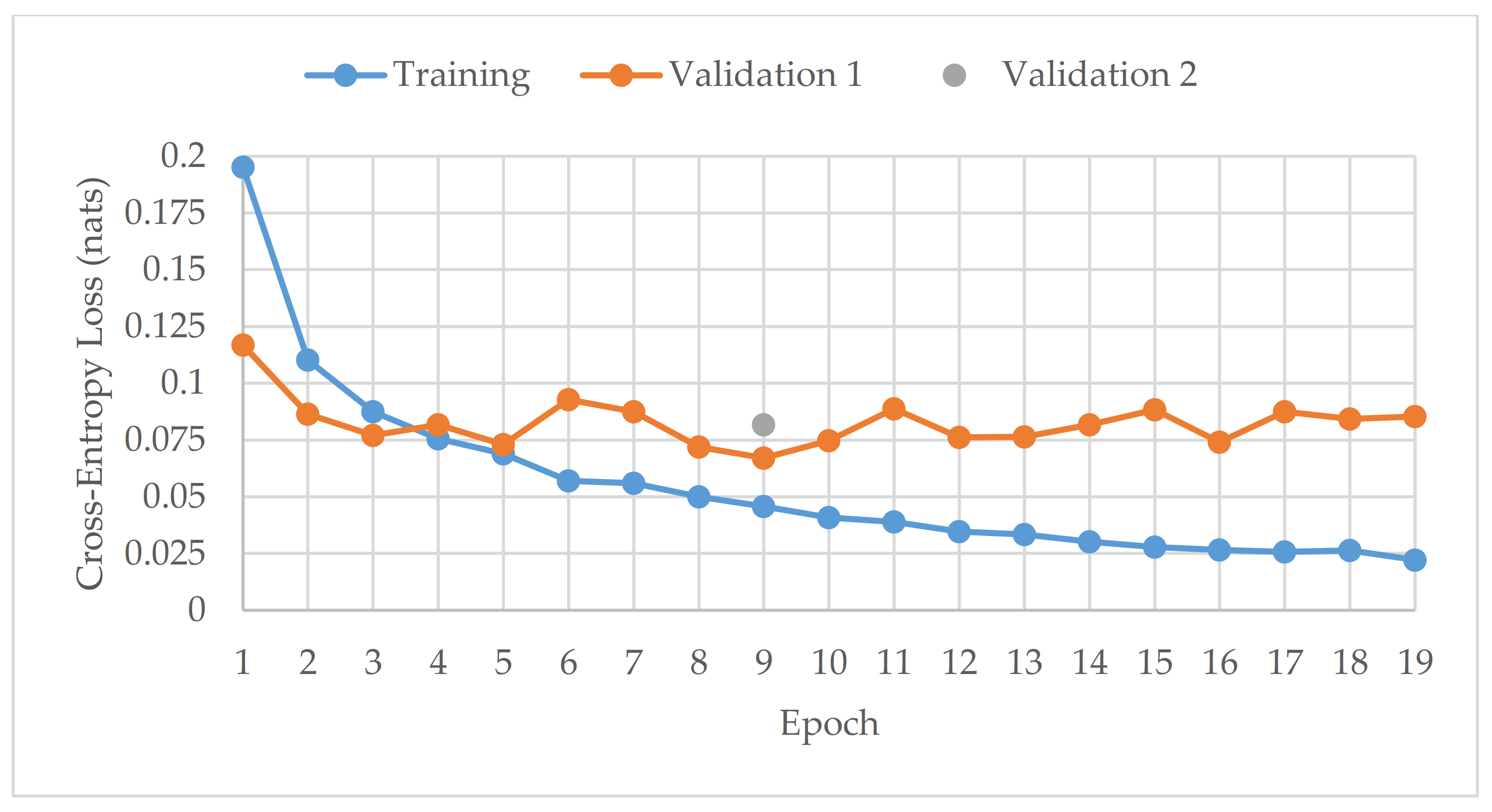
This study has also shown that late fusion networks do not require optimal hyperparameters to work well, as arbitrary hyperparameters were used, yet their performance was higher compared to the solo models with optimized hyperparameters. In addition, the instability of the performance results was significantly reduced with late fusion. The only drawback of using late fusion networks is that they take significantly more time to train, since they have more than one model requiring training (ten in this case). However, time matters more when the models are making predictions. Once all the models are trained, the prediction time remains negligible.
The distance between a drone and a microphone is a limiting factor that affects detection performance. Hence, for future work, it would be useful to study at what distances the drone would no longer be detected, and how to optimize the arrangement of microphones around an airport’s perimeter to ensure that the drones can always be detected within a certain radius. This would also lead to acoustically localizing the UAV for taking countermeasures. Flight conditions, such as hovering, low-speed and high-speed flight, are another useful factor to analyze when evaluating detection performance. Future work could evaluate model performance against different flight conditions.
While the developed framework could be applicable to other sound classification problems, such as air and road vehicles, engines and rotating machinery, the networks constructed and optimized here were specific for UAV detection, as they were trained using mel-spectrograms as inputs, representing key acoustic features of the drone/background sounds. The proposed late fusion technique could also be utilized for further work with other detection methods. It could be applied to create a voting ensemble of acoustic, radar and visual models, which would then improve the overall detection performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}