1. Introduction
Video action detection has improved dramatically in the last few years, owing largely to the adoption of deep learning action recognition models [
1,
2,
3,
4] and video databases [
5,
6,
7]. In addition, many prominent convolution neural networks [
8,
9,
10,
11] are available in the literature for the image recognition task. However, these CNN’s cannot model the motion feature of individuals effectively from a crowd video. Using these CNN’s for aerial action recognition can provide a variety of real-life applications for search and rescue using the dataset proposed in [
12,
13]. Aerial and drone surveillance can also be used for real-time purposes, such as detecting odd behavior in border areas [
14], violence and suspicious activity in crowds [
15], urban and rural scene understanding. However, due to the intrinsic complexity of aerial footage, motion modeling in action detection remains a difficult task. The variable nature of human characteristics from different angles and heights is one of the primary challenges in aerial or drone monitoring.
The critical need for a practical approach of action recognition is that it must be applied simultaneously from various heights of live stream video, environment, and with single or multiple humans. Various approaches for multi-human action recognition are summarized in [
16], with a detailed discussion on opportunities and challenges. The benefit of using drone surveillance is that a wide remote area can be searched in less time. We have recently seen different surveillance tasks, such as using drones for traffic control and crowd monitoring during COVID 19. These activities demonstrate the potential and future of drone surveillance. Automation of such surveillance applications, on the other hand, is essential for taking it to the next level. This automation necessitates on-device video analysis. Also, the capability of the drone is improving in terms of battery life, storage capacity, and processing capability. There is a pressing need for sophisticated algorithms that can detect and recognize persons and their activities and emotions. Most known action recognition algorithms use a two-stage procedure: they estimate the optical flow using the EPE (expected predicted error), then feed the estimated optical flow into the subsequent action recognition module. However, the recent articles [
17,
18] indicate that this co-relationship is not vital for the overall modeling of action recognition. Due to the availability of adequate data where object features are visible, the deep learning algorithm’s performance with ground-level images has recently been improved a lot. Deep learning techniques, on the other hand, are being tested in aerial drone surveillance. The existing action recognition model’s performance is subpar in aerial and drone surveillance due to a lack of accurate data on individual persons’ temporal actions.
Large visual variances in characteristics, such as occlusions, position variations, and illumination alterations, provide substantial aerial surveillance issues in practical implementation. Deep learning models use human features to understand the shape, texture, and size in the spatial-temporal domain for action categorization. Such qualities are not immediately apparent in drone-captured videos. Robust temporal modeling of the individual is essential for the full presentation of human action traits. This research provides several levels, including a novel architecture, a quick and accurate temporal motion modeling framework, and an upgraded temporal network for action identification to address these issues and employ them for search and rescue in emergencies. The crucial contribution of this paper is as follows:
To the best of our knowledge, this is the first time a unique architecture has been offered to address the multi-class challenge of activity recognition in aerial and drone surveillance.
The proposed architecture uses a unified approach for faster motion featuring modeling (FMFM) and accurate action recognition (AAR) working together for better performance.
A unique five-class-action dataset for aerial drone surveillance was introduced, with approximately 480 video clips distributed in five different classes.
It developed and trained a unique video-based action detection model that can correctly classify human action in drone videos.
2. Literature
In recent years, search and rescue have received a lot of attention. It might be more effective if deep learning techniques like activity recognition, object detection, and object classification were used. As a result, some critical state-of-the-art research suitable for the automation of search and rescue applications is explored here. Human activity recognition has been a hot topic in recent years, and numerous algorithms for intelligent surveillance systems have been developed in the literature [
19]. However, traditional algorithms for action recognition use manual feature extraction [
20,
21,
22,
23], and hence performance is not up to the mark comparatively. Also, it requires lots of human effort unnecessarily. The emergence of recent deep learning algorithms for intelligent surveillance [
24,
25] shows the capability of deep learning algorithms. However, applying these models to many humans present in the same scene, especially in an unstructured environment, is complicated, and the article [
16] gives a detailed discussion on the complexity and opportunity of this task. Deep learning models are popular nowadays due to the dataset availability, which is critical for getting adequate performance in the field of action recognition, [
25] outlined the current challenges for real-world applications. Analysis of deep learning models shows the key to the success of deep learning models is the availability of datasets, and this enables the models to learn the features required for classification of human action. Several such datasets are available in the literature, such as [
26] introduced a video level action dataset called UCF and article [
5] proposes a similar dataset called kinetics. However, each dataset has its limitation, which limits its use in different applications.
Table 1 presents a summarized review of the literature for some key papers and datasets in drone-based surveillance recently.
These datasets have been utilized to perform profound learning algorithms, such as T-CNN [
27], the temporary sector network [
28], and the temporary pyramid network [
10]. Furthermore, the modeling of movement and appearance is supported by a variant of a 3D convolution network with a model for deformation attention [
4]. Models of spatial-temporal feature extraction for action recognition have had tremendous success in recent years; for example, a composition model based on spatially and temporally distinguished elements is suggested in [
29]. In addition, [
30] recommends a transferable technique for recognizing action using a two-stream neural convolution network. Another field of action recognition that can be useful for search and rescue is hand gesture recognition, and a two-stage convolution neural network is recently proposed in [
31].
Other methods of action recognition use the body key points for classifying action to different classes, such as in [
32], in which both 2D and 3D features of body key points are used. In [
33], a human action recognition model is proposed based on pose estimation, specifically on pose estimated map, and experimented with the ntu rgb + d [
34] and UTD-111MHAD [
35] datasets. These models for action recognition performed well with ground-level action recognition. However, these algorithms do not perform well in aerial or drone surveillance due to its angle and height being captured. Likewise, in a work of aerial action recognition [
13], a dataset was developed, and multiple deep learning algorithms have been tried.
Nonetheless, the performance of algorithms applied on this dataset is deficient. The problem with such a dataset is that the features are not explored, and hence the deep learning algorithm could not learn properly for the classification of action. Recently, a few datasets have been published in aerial and drone surveillance and can be used for action recognition, such as in [
36,
37]. In the past few years, the use of a drone has been increasing, and it covers almost every field of surveillance, such as road safety and traffic analysis [
38], crop monitoring [
39], and border area surveillance [
40]. Recent work has been published in this field, which uses drone surveillance using a deep learning action recognition model for search and rescue [
41]. In the field of aerial action recognition, [
42] proposed a disjoint multitasking approach for action detection in drone videos. However, the training sample is deficient and could not be a generalized framework for all.
These drone applications need models trained on an aerial dataset for analysis and surveillance to improve performance. Pre-trained object detection (OD) and action detection models are not useful in drones or aerial surveillance. The performances with diverse ground-level object detection tasks are popular for models like Mask R-CNN, RCNN [
43], SPP-Net [
44], Fast R-CNN [
45], and Faster R-CNN [
46]. These models were used to identify actions; however, their inference time is the main drawback for such two-stage OD algorithms. In the OD family, SSD [
47] has performance comparable to other listed algorithms and lowers inference time to one of the best inference time algorithms such as YOLO (You Look Only Once). However, as shown in work [
13], these algorithms are not sufficiently good for long-term and aerial videos. In some works, a separate module for detecting the human body and its extension with other models for detecting action is used [
48]. Due to its feature and angle, it may be helpful to use this separate module for both tasks for aerial monitoring.
4. Methodology
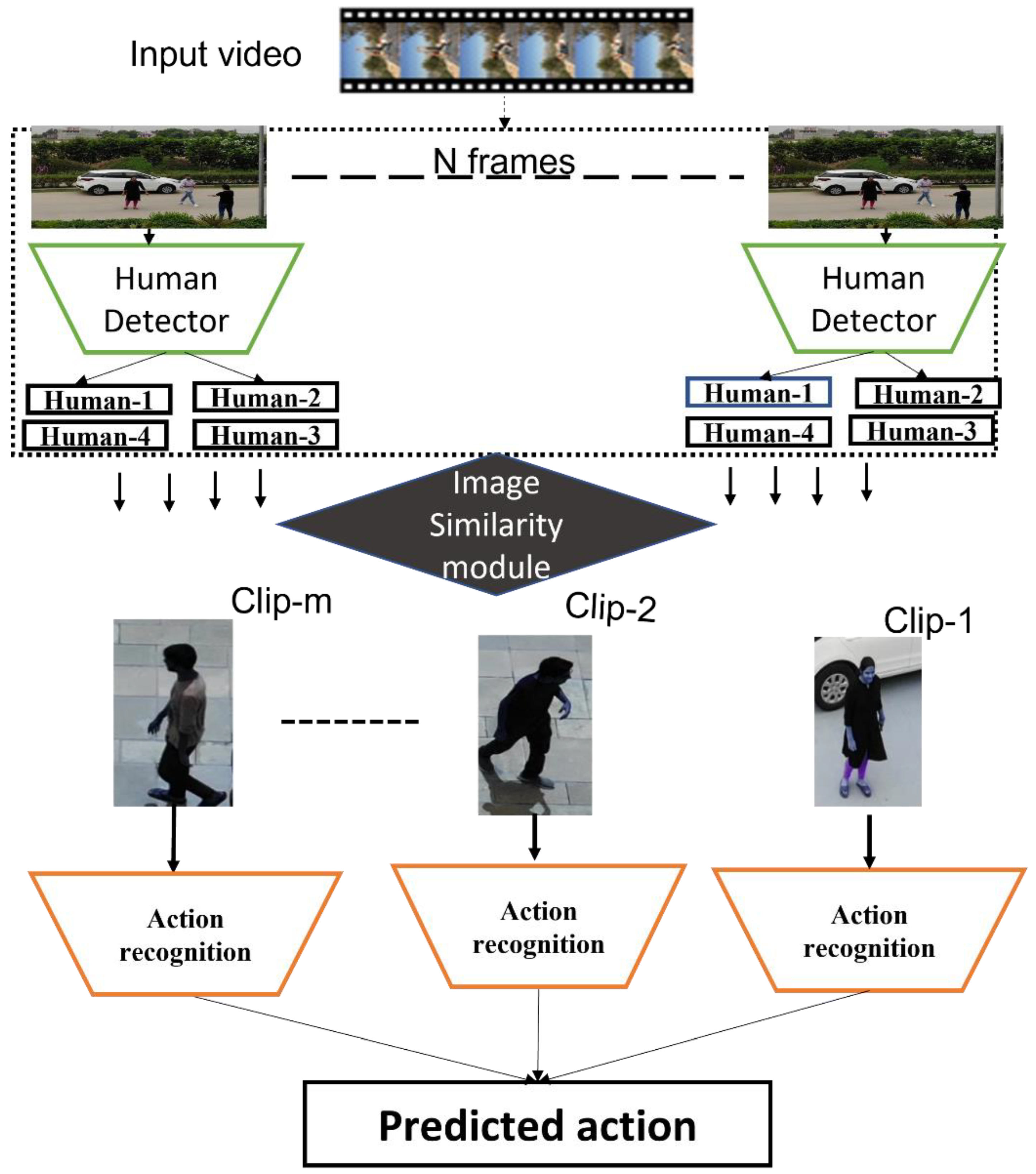
The proposed approach for search and rescue uses drones as a tool for monitoring disaster-affected areas. This paper develops an end-to-end trainable system for faster motion feature modeling and action recognition from crowd surveillance videos. The architecture of the proposed methodology is explained in
Figure 1. This approach combines two different modules. Hence, the architecture and its work are presented with the help of each module’s mathematical background. Some necessary notations used in this paper are as follows: For the video clips, each video clip Xi = [c ∗ l∗ h ∗ w]. Where I = f (x, y) represents the frames of the video clip, c stands for the number of channels, l is for the number of the frame in each video clip, h and w represents the height and width of each frame.
4.1. Faster Motion Feature Modeling (FMFM)
Multiple modules are interconnected and trained together for the accurate and faster motion modeling of temporal features. This combines deep learning model object detection and traditional computer vision algorithms to extract detected bounding boxes. First, an individual human’s temporal feature model is extracted based on the image similarity from the original crowd monitoring video. For this, the initial step is detecting the human precisely. After the humans are detected accurately, the output image is passed to the second part of FMFM, which extracts the detected human, calculates image similarity, and patches most similar extracted images together in the form of video-clip. Thus, the whole process of FMFM is divided into two critical steps.
In this way, the crowd monitoring video dataset is converted into individual human action videos. Thus, each video has a sufficient human feature, which can be utilized later for accurate action recognition. Another advantage of FMFM is that it removes the background’s effect, affecting the performance of the action recognition algorithm. Mostly, models are trained in a typical environment, and it fails when applied in a real-time environment or when the background changes.
As discussed above, the process of FMFM starts with detecting humans precisely, so here are some state-of-the-art object detection techniques that can be utilized for detecting humans in aerial surveillance images and videos.
Faster R-CNN: The original paper of Faster R-CNN [
46], the model with less inference time for object detection, was proposed based on a region-based approach. In this, fewer region proposals are generated than other region-based object detection category algorithms. Initially, the VGG-16 network was used as a feature extractor for region proposals in the Faster RCNN network. However, over time, some advanced models, like inception and MobileNet, were used to implement Faster R-CNN. Here, in our experiment, This module uses Faster RCNN with an inception network as a feature extractor.
SSD (Single-shot detection): SSD was originally proposed in [
47], and it uses multiple-layer features of feature extractor network VGG16 for detecting the objects. In this approach, classification and localization are both done with a single network. In our proposed model for object detection, inception and MobileNet’s base architecture are used as the backbone.
Basically, object detection is a combination of object localization and object classification in an image I = f(h, w). Applying object detection on a video stream or video-clip
requires applying the same process on each frame of the video clip.
where Yi is the output label, i.e., human, car, truck, bus, for a good quality object detection model, two different types of loss, localization loss and classification loss, need to be optimized. Therefore, the localization loss is defined as Lloc (y, y′) and classification loss as Lclass (y, y′), in which y is the ground truth object class, and y′ denotes the predicted object class.
4.2. Accurate Action Classification (AAR)
This paper approaches the search and rescue task for humans as a multi-class activity recognition problem in drone surveillance. Usually, in drone surveillance, the height and angle of surveillance change with time, making it more difficult. Identifying a specific action from the image captured where multiple humans are present and possibly all doing different activities is quite challenging and requires detecting each action individually. Therefore, the proposed architecture uses two different modules, FMFM and AAR, which accurately detect each action. However, in drone video surveillance, action recognition could be performed with the help of spatial features. The spatial features of humans could be combined with motion features to classify the actions accurately. In both categories, various experiments have been performed in this study with the existing models and the combination of different architecture such as 2D ConvNet with RNN and 2D ConvNet with Time-Distributed RNN and with the proposed architecture using 3D ConvNet. However, for recognizing few actions required for emergency identification in disaster, motion features are required, and hence this paper finds models that use spatial and motion features together are more suitable for such tasks. For example, in the case of finding humans through their actions, waving hands is a primary action, requiring spatial and temporal features. The mathematical modeling of action recognition is as follows:
where Zi represents the output class of the action recognition model, I represent the image, and
represents the input video for action recognition module.
where function A represents the action recognition based on 2D spatial features, and T function represents the action classification feature extraction based on motion features. Equation (5) represents the working of CNN + RNN, and CNN + Time distributed RNN models used in our experimentation, where two different networks are used to extract features parallel in the end, both the features are combined for action classification.
4.2.1. Action Classification with Spatial Features
Human actions such as lying, sitting, fighting, shaking hands could be easily recognized by the image’s spatial features. Image classification models can recognize such features. Some important 2D ConvNet used in this paper is as follows:
Resnet50: This is a 50-layer deep convolution neural network that uses the residual function. It starts from 7 × 7 convolution with stride two and max pool kernel of size 3 × 3 with stride 2. After that, at four different stages, it uses the residual function of sizes 3, 4, 6, and 3. Thus, each residual function contains three convolution networks of sizes 1 × 1, 3 × 3, and 1 × 1 [
51].
Resnet152: In this, the network depth was 152 layers with the residual function. It also starts with a convolutional layer of 7 × 7, and all other convolution layers are patched in the form of residual function as in Resnet50 [
51].
VGG16: This is a type of convolution layer with 16 layers. In this network, 13 convolution layers are present with three fully connected layers [
52].
4.2.2. Action Classification with Temporal Features
Multiple architectures were designed and trained for action recognition with spatio-temporal features. Spatio-temporal features are captured through different networks such as 2D ConvNet, RNN, and time distributed RNN. The architecture of the models was as follows:
2D ConvNet with RNN: In this research, the experiments were performed with a five-layer 2D ConvNet working in parallel with three layers RNN combined with three dense layers in the end for feature classification. Two-dimensional ConvNet extracts spatial features, and RNN networks extract the motion features from the sequence of frames. Extracted features are then passed to the network’s dense layer after flattening it into a single dimension vector. Both networks working in parallel are merged into a single network with the concatenate feature available in Keras.289
2D ConvNet with time distributed RNN: this network consists of 5-layer 2D ConvNet with three layers of time distributed RNN layer and one RNN layer working in parallel for spatial and motion feature extraction. Both the networks are then merged for overall feature classification with three dense layers finally.
Proposed architecture of 3D ConvNet: our proposed network for action recognition uses the modified architecture of VGG16 with 12 3D ConvNet and two dense layers in the end. Convolution layers are stacked in the fashion as it appears in VGG16 with 3 × 3 × 3 convolution filters in the first layer having 64 kernels. The detailed structure of the proposed network is represented in
Table 3. The relu activation function is used at each layer except the last dense layer, where the softmax activation function is applied.
4.3. Proposed Architecture and Its Operation
The proposed operational architecture contains two different stages, i.e., FMFM and AAR as explained above. In this, in the beginning, humans are detected in surveillance videos, and the output of the human detection module is then passed to the function written for cropping the bounding boxes predicted. It uses human coordinates detected by a human detection module for a single or multiple humans in a surveillance image. Furthermore, the cropped image function’s output is passed to another module, which combines the cropped images based on similarity. For the similarity of images, multiple techniques were tested and based on the best outcome with the mean square error (mse) result, and the proposed module uses mse for stacking.
where
is the video clip formed with mse (mean square error) parameter. mse is used here to group mot similar images together as per the pixel values of images:
where
are the individual output image from the object detection module. Each detected human is cropped by the function,
and
are the different instances of humans cropped.
In this, the proposed architecture uses a patch human detected output of 60 consecutive frames together for stacking it into individual action recognition video clips. Finally, the output individual action video clips are passed through the proposed action recognition sub module for final action recognition.
The overall objective of the proposed approach is to minimize the unified loss represented by
, which is a combination of object detection loss
, and mean square error (mse) for patching action classification loss
. The detailed equation of loss is explained through Equation 8. In this, y and y′ represent the output class for human detection. Human and non-human are the class labels for this. Overall, our final output is based on the 5-action class, where z represents the ground truth labels and z′ is for the predicted class.
5. Experiments and Results
The result of the experiments was evaluated with the proposed dataset using the metric of action classification accuracy. Furthermore, extensive experiments were performed with various 2-D and 3-D models, which deal with the spatial and temporal features of input videos in the dataset. This section covers the details of all the experiments and reports the result in the most suitable format.
5.1. Experimental Setup
The experiment is set up on the 6 GB RAM, 4 GB NVIDIA-GPU workstations. Python 3 which is an opensource software is used with its OpenCV package for preprocessing and post-processing the dataset. The tensorFlow environment is used on top of Python3 as the base for all the experiments performed in this paper. In addition, various other Python packages, such as Keras, tensorboard, etc., were used throughout the experiments.
5.2. Experiments
The experiments were performed on the dataset described in
Section 3, which consists of two different datasets, one for human detection and the other for action recognition proposed in this paper. At the primary level, experiments were performed with object detection models for recognizing the action in drone videos. After some preprocessing, it is converted into five-class action recognition with the dataset for human detection, and three different object detection models were trained using transfer learning. Experimental results with object detection model, Faster RCNN, SSD Inception, and SSD MobileNet for action recognition motivate us to develop an architecture where the features are exposed for classification. Therefore, this paper proposed a novel architecture for this. The proposed architecture was tested with the help of two different trainable networks, FMFM and AAR. For the first module, three different human detection modules were trained with more than 20,000 steps and their best-tuned hyperparameters. In this phase, cropping Haman and stacking the maximum matched extracted human, which is also be termed as motion feature modeling of the individual human, was performed to optimize different image matching algorithms.
The second stage of our experimentation was designing and testing a novel action recognition model that could recognize drone surveillance videos’ human action. For this, three different models, with the help of transfer learning, were trained on our dataset. Moreover, as the learning of 2D models is not sufficient for accurately classifying the action, two different state-of-the-art models were also trained on our dataset (CNN + RNN, CNN + TimeDLSTM). These experiments motivated us to design a slightly complex but accurate model for classifying the models based on the video’s spatio-temporal features. All these models were trained and were tuned with their best hyperparameter values.
5.2.1. Training and Testing
In this paper, the result was obtained and reported by training three models for object detection for action recognition and the same three models for human detection for the proposed architecture. For the second module, AAR, three 2D ConvNets were trained on our dataset, also, including proposed network state-of-the-art models that were trained and optimized for the best hyperparameter values. Twelve different networks were trained and compared based on the evaluation parameters such as mAP (mean average precision) for object detection models and validation accuracy for action classification models. For the training and testing of models, data were divided into a 7:3 ratio. Each model was trained up to the saturation point.
5.2.2. Results
The proposed action recognition module uses a convolution neural network feature for feature extraction in a video frame. Starting from the object detection models applied,
Table 4 represents the result, and it shows that the performance of SSD model is comparable to Faster RCNN with lesser inference time. Here, Faster RCNN stands for Faster Region Based Convolution Neural Network model in the family of object detection. While, two variant of SSD (Single shot detection) are used, ie. With Inception as backbone, and MobileNet variant. Performance is compared based on the primary performance measure metric mAP stands for mean average precision, and then inference time with unit milli seconds is used. In contrast, the recurrent neural network works with multiple video frames to extract and utilize the temporal feature to classify video into a class. For action recognition models trained on our dataset, the result of each model is reported in
Table 5 and
Table 6.
Table 5 summarizes the experimentation result with the 2D ConvNet trained on our dataset using transfer learning with three different models, ie. Resnet 50, resnet 152, and VGG16. The result obtained in this paper is compared with the state-of-the-result in
Table 7. Moreover,
Table 7 reports the result of all the models applied to our dataset based on parameters training accuracy, training loss, validation accuracy, and validation loss. Okutama is a standard dataset published for aerial human detection and action recognition with the benchmark result 0.18 mAP as shown in
Table 7. While, in some other work listed in
Table 7, multilevel pedestrian detection (PD) has been attempted with 0.28 mAP. Convolution neural network (CNN) along with recurrent neural network (RNN) and time distributed long short term memory unit (LSTM) has also been used and we have compared their result in
Table 7.
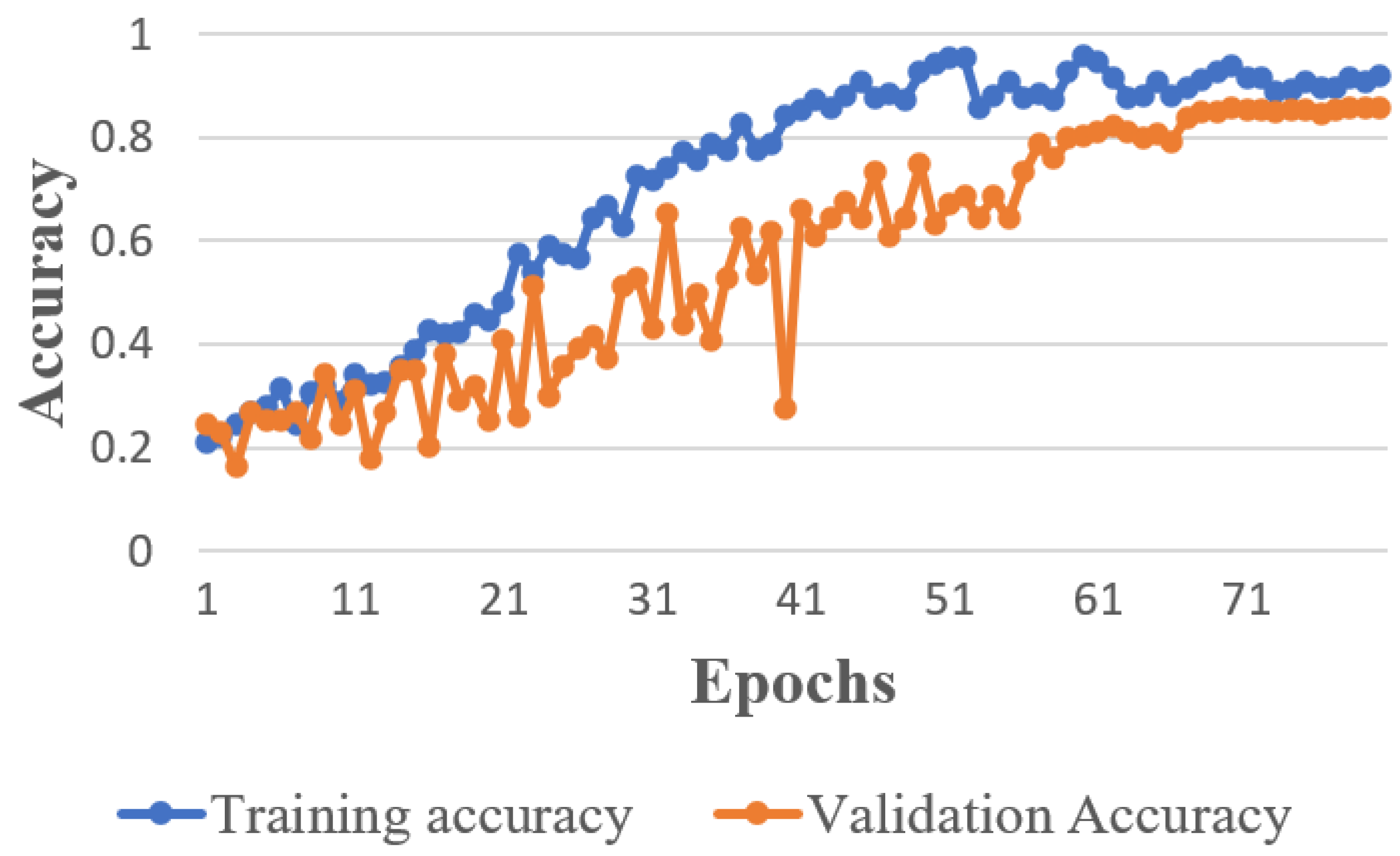
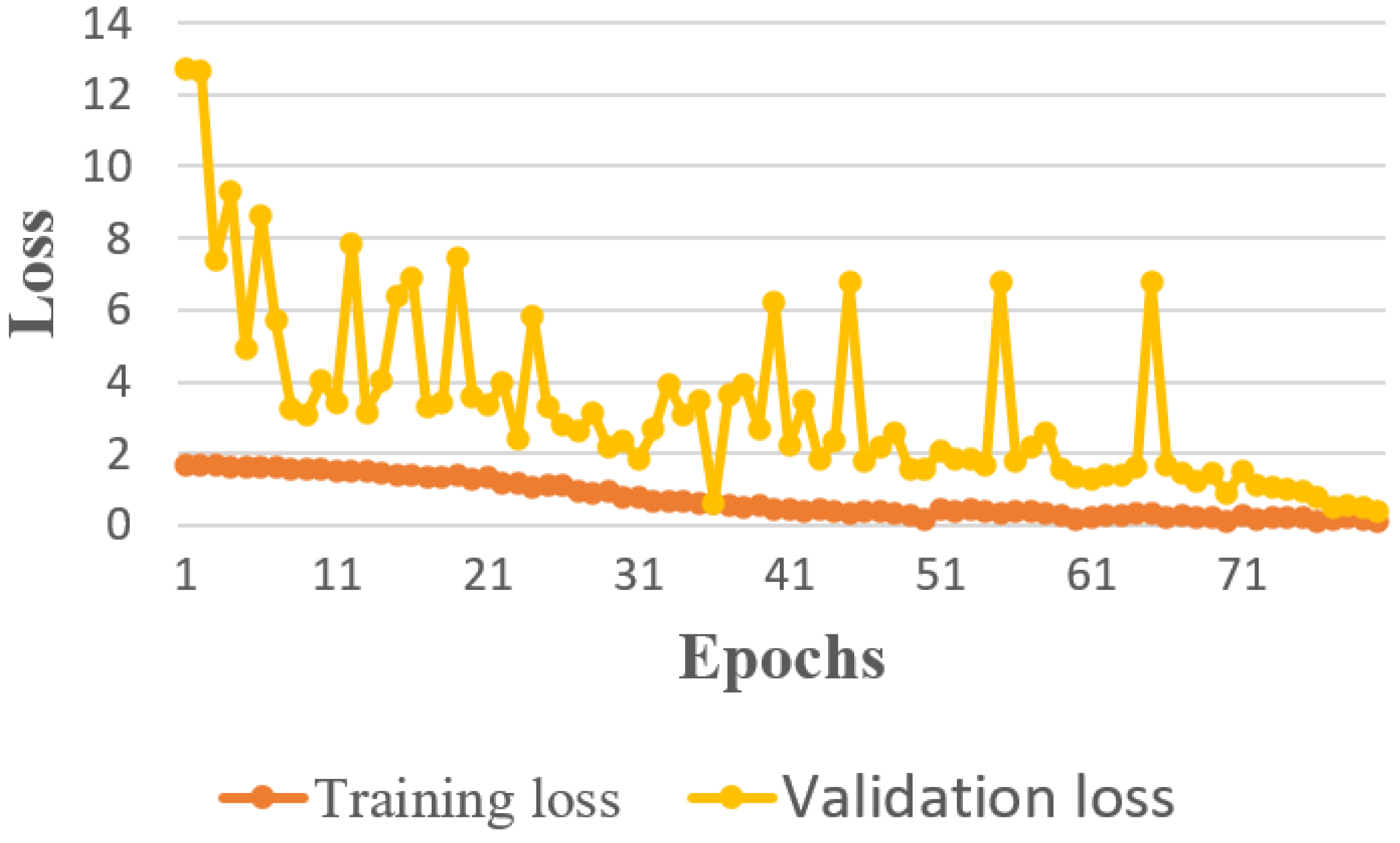
Figure 3 and
Figure 4 represent the loss and accuracy of the proposed action recognition model trained on our developed dataset. The proposed architecture’s incremental testing was performed in another level of testing, and each module was tested for the outcome as action recognition. The result of incremental module testing is reported in
Table 8.
6. Discussion
The proposed architecture was tested at various levels, and one of the most important analyses we performed was through incremental module testing. Although in some pre-various work, object detection models have been directly used to recognize action, we also applied it directly to recognize the action.
Table 8 shows the performance of object detection models applied for action recognition. However, it achieves only 0.39 mAP with the state-of-the-art model faster RCNN. However, when it is applied for human detection, it can detect the human with a 0.833 mAP value; the comparison of various human detection models trained and tested on the proposed dataset is represented in
Table 4. The second module proposed an action recognition model and was also tested independently on the proposed action recognition video dataset. The maximum accuracy we achieved with the proposed model was 0.85, which was validation accuracy with a training accuracy of 0.89. The detailed comparative result is represented in
Table 7 and
Table 8. Finally, this paper proposes an accurate and faster 3D temporal motion modeling architecture, and this was applied to the input video. While testing the architecture with the validation video, the architecture achieved maximum accuracy with 0.90 validation accuracy and is represented in
Table 8. However, these performances have certain limitations: as the height of the drone will increase, the human feature changes, especially in drone footage captured from above. These experiments were performed on the drone footage captured from our DJI Mavic Pro drone, with the camera having a 60 frame per second rate. Images and videos were captured from 10 to 50 m height. Some important failure cases arose when we tested with the dataset published in the aerial image of the Okutama dataset since the height from where those images were captured was more than 60 m. Our experimental result, and the incremental analysis of each module, observed that using both proposed modules (FMFM and AAR) together could achieve higher accuracy than any other combination.








{kind=link}
{kind=link}
{kind=link}
{kind=link}