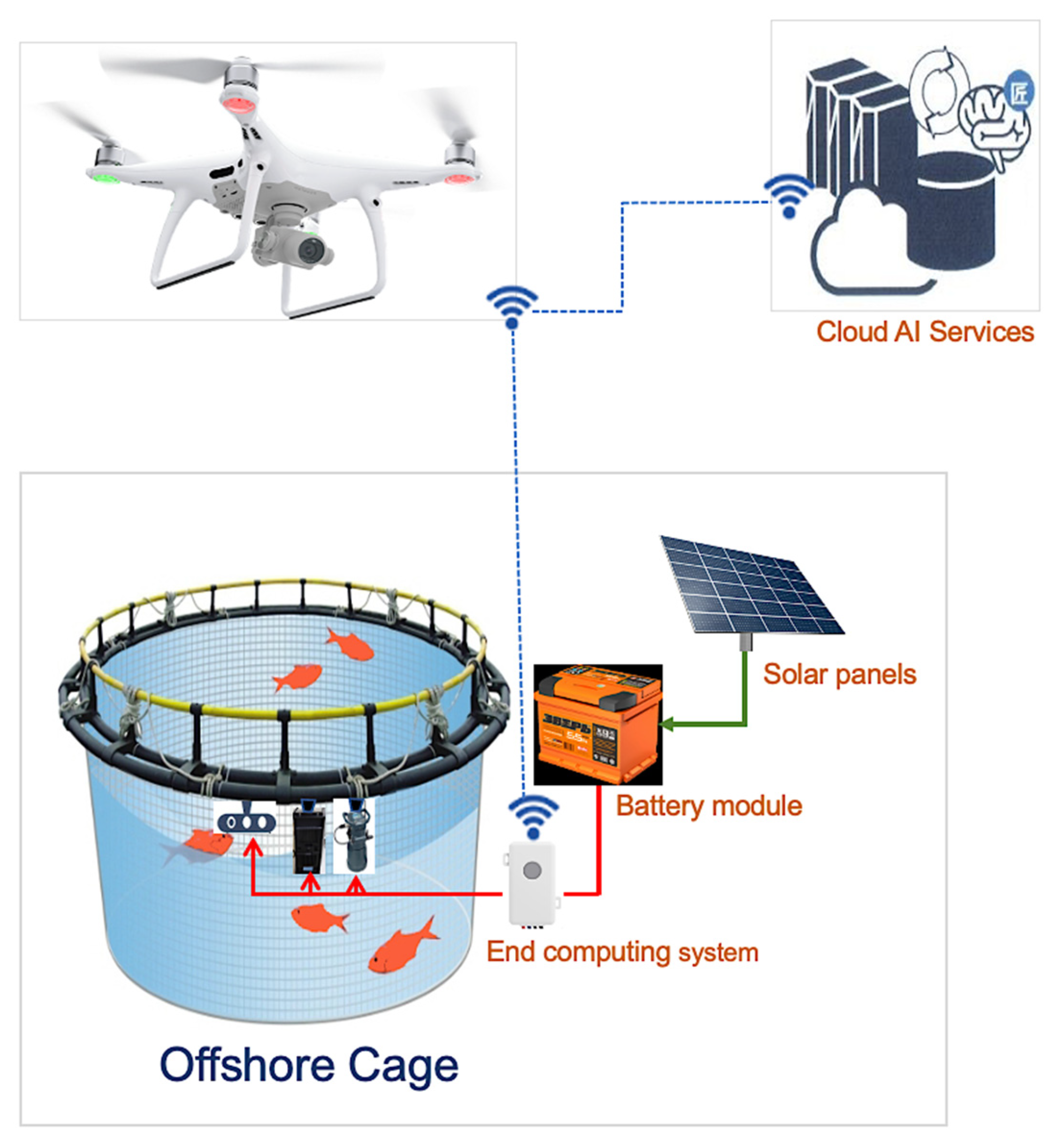
2.1. System Components and Functions
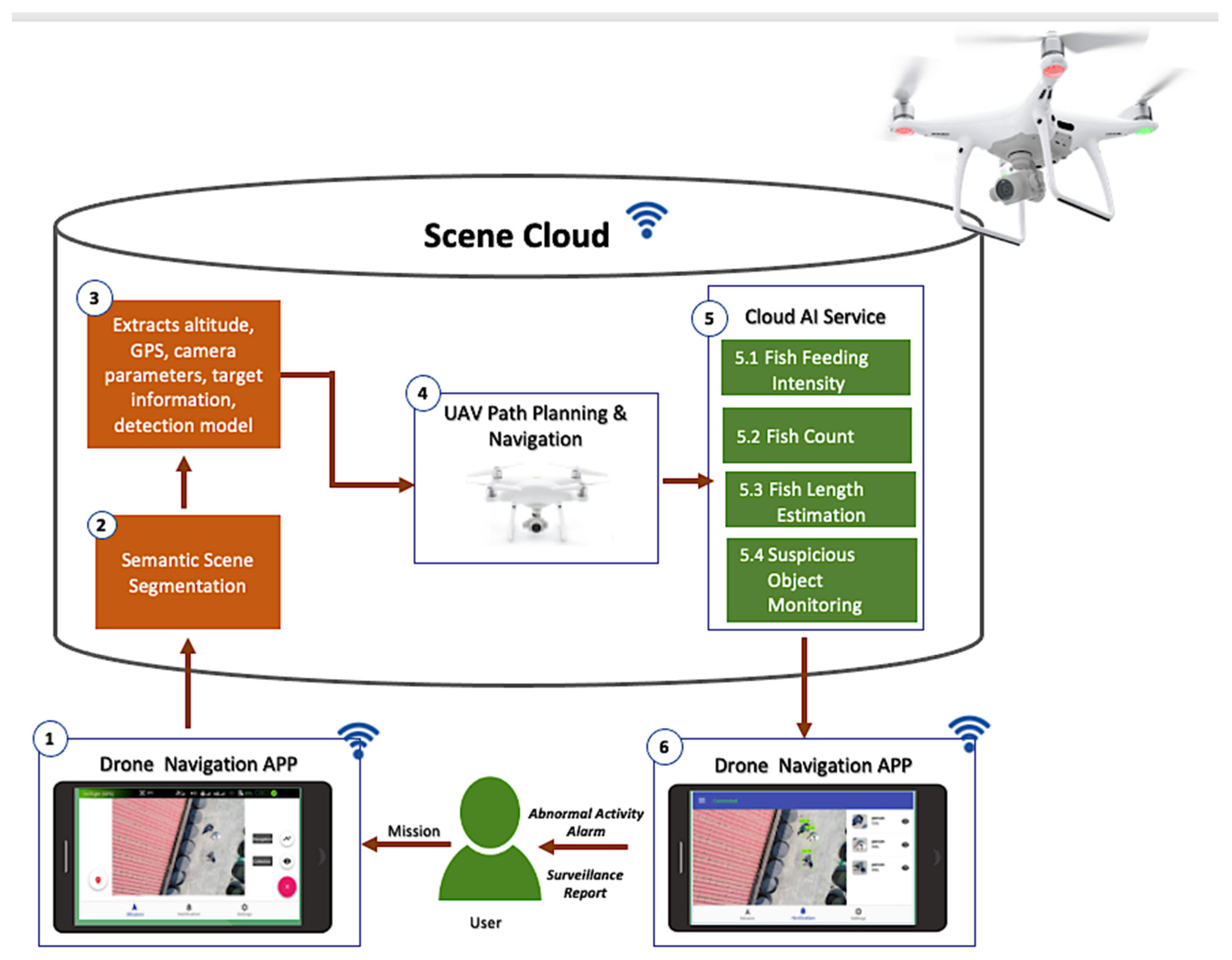
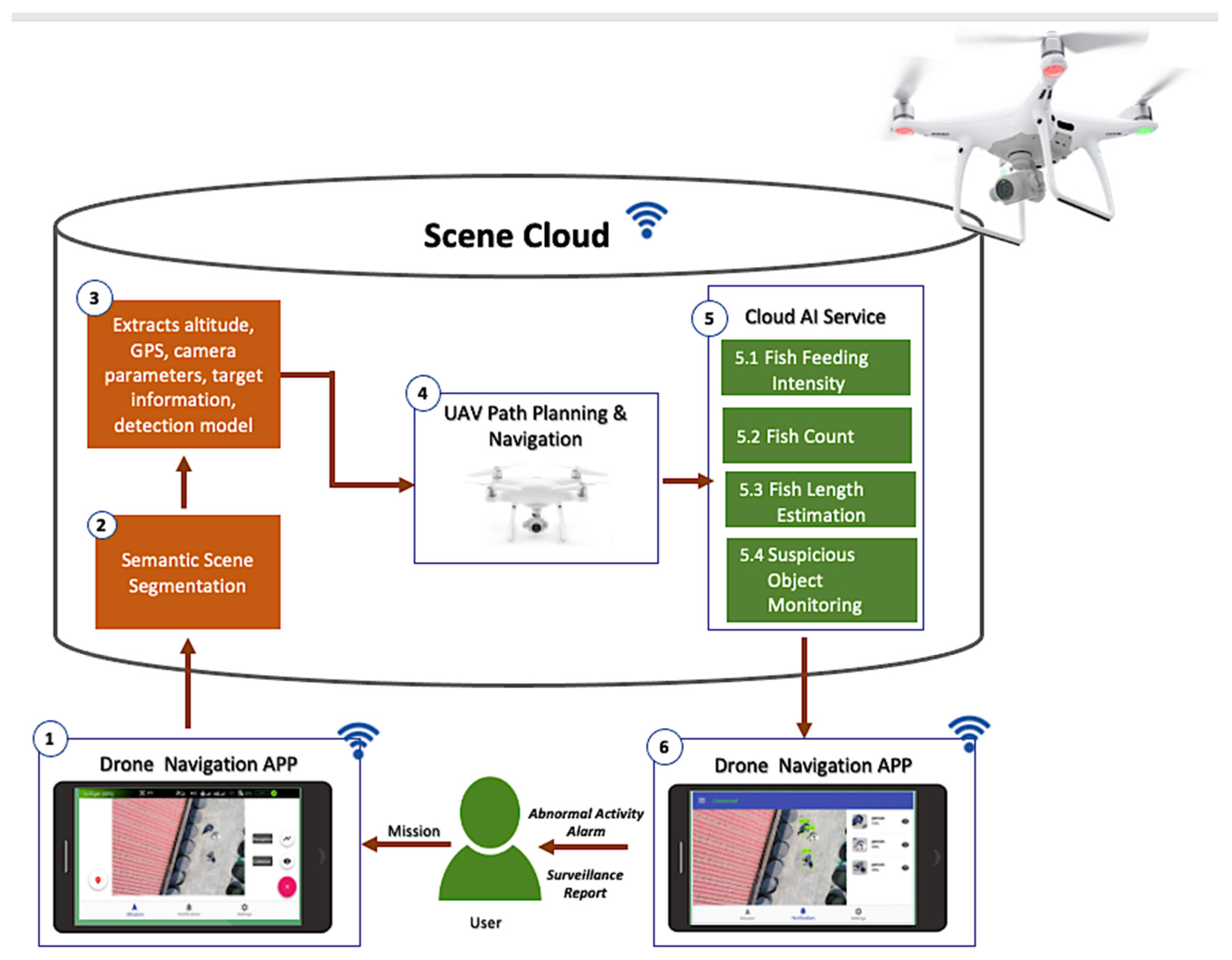
This section provides details and components of our visual surveillance system. The framework in
Figure 1 contains three main elements: drone, Drone Navigation App, and scene cloud.
The drone navigation app is a personalized mobile application installed on the user’s device. It sends instructions and receives data from the drone, and at the same time sends data and receives alerts or notifications from the scene cloud. Using the Drone Navigation App, the user selects a mission that the drone must execute. This mobile application, developed using the Java language, can be installed on mobile devices with IOS or Android platforms and WIFI capability to connect to the drone and the cloud of the area.
After the user selects the mission, the drone navigation app will command the drone to fly at high altitude above the aquaculture farm to capture the aerial image of the aquaculture site. It will then send these images to the cloud for semantic scene segmentation to locate the target object in the field. Semantic scene segmentation labels or classifies specific regions of captured images for scene understanding. It analyzes the concept and nature of objects and recognizes them and their corresponding shapes in the scene. First, it detects the object, identifies its shape, and then performs object classification [
8].
For semantic scene segmentation, the locations of the objects taken from the aerial images were already known, manually marked, and saved in the scene cloud database. These objects can be aquaculture tanks, box nets, ships, and personnel. Mask R-CNN [
9] is a deep-learning convolutional neural network utilized for image segmentation and distinguishes the different objects in the images. Detection of various objects in the scene is needed to perform physical surveillance of the aquaculture site, which will allow the drone to identify its target object for its mission. Understanding the scene will allow the drone to navigate its target object correctly.
We integrated a two-dimensional (2D) semantic representation of the scene to locate the necessary objects in the aquaculture site. The result of the semantic scene segmentation is the visual and geometrical information of the semantic object that defines the checkpoints for the inspection work. Each checkpoint is associated with the corresponding global positioning system (GPS) signal. The altitude of the drone in
Figure 2 locates the 2D objects such as aquaculture tanks and cages.
The scene cloud functions as the brain of the system, equipped with different services capable of decision making and analysis. The altitude, GPS information, camera parameters, target information, and detection model are the information stored in the cloud used for the unmanned aerial vehicle (UAV) path planning and navigation. The scene cloud utilizes the Google Firebase platform as its architecture and the scene dataset keeps the status of the scene updated. A database-management application was designed for its management so that users can easily search for information.
The drone path planning and navigation are the core of this paper. It contains the mechanisms, design, and procedures of its autonomous capability. Planning the path to navigate the target object or facility is relevant in performing surveillance for the drone to arrive at its target or destination safely. This plan will enable the drone to avoid obstacles during the flight which may cause damage, in order to safely navigate to its destination using the navigation path-planning service of the scene cloud. We integrated various algorithms and techniques for the drone’s autonomous navigation capability. The details of the drone path planning and navigation are in
Section 2.2.
Once the target object is established, the autonomous drone uses the calculated path from the path planning to navigate to the target object and perform individual monitoring tasks (e.g., fish feeding intensity and suspicious object monitoring). The drone once again takes the video of the monitoring tasks and sends it to the scene cloud to execute the corresponding AI service. The AI services process the data and sends an alert for abnormal activity, suspicious events, or the level of the fish feeding. Instead of utilizing the drone to include graphics processing, the AI services, as part of the cloud, save a large amount of power consumed by graphics processing, enabling the drone to use its power to perform surveillance. The convolutional neural networks and other technical details for the semantic scene segmentation and cloud AI services are presented in
Section 2.3.
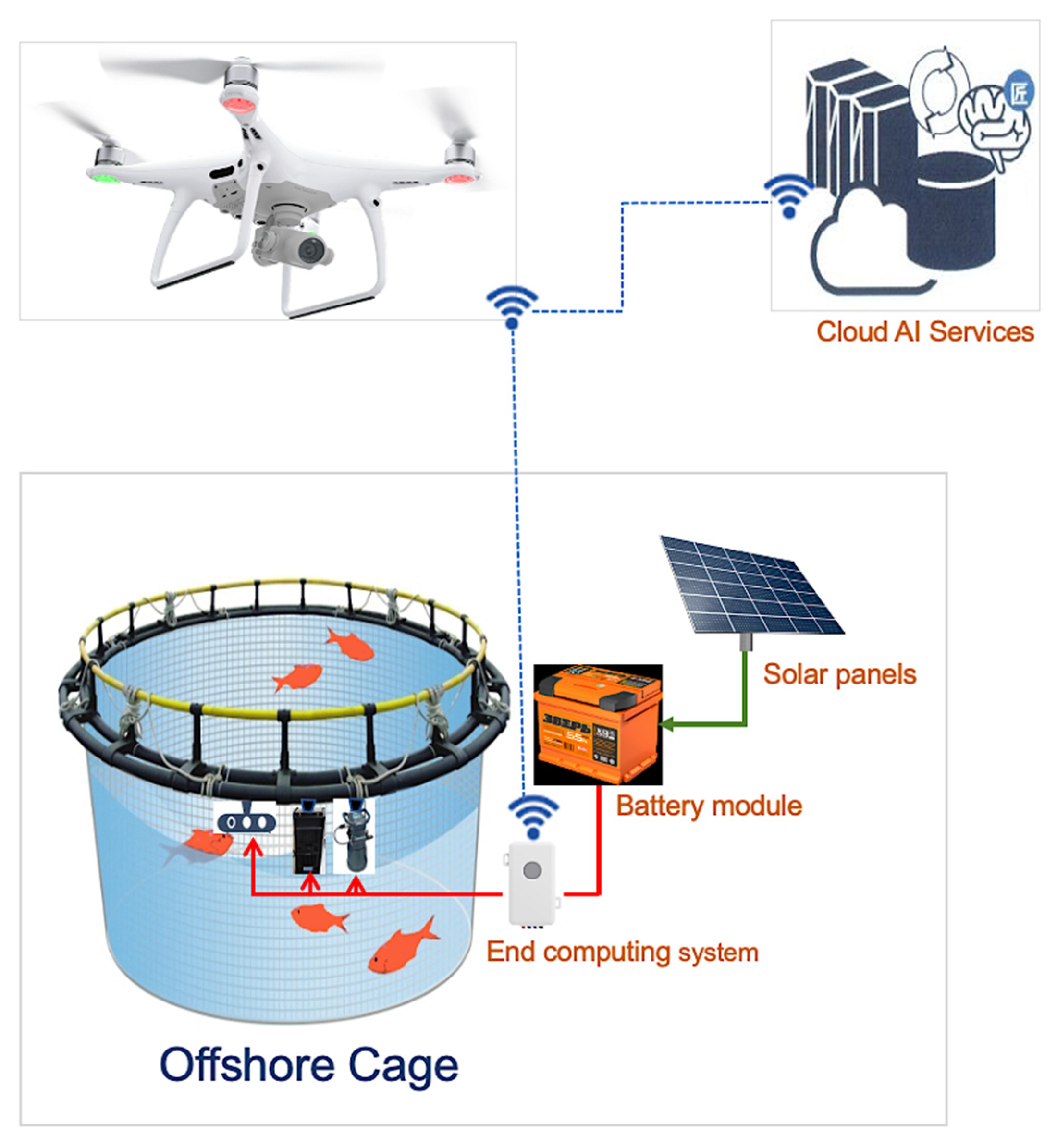
Additionally, the drone can serve as a gateway to connect the underwater cameras (e.g., stereo camera system, sonar camera) to the cloud AI services to perform additional fish surveillance such as fish count and fish-length estimation using the underwater camera.
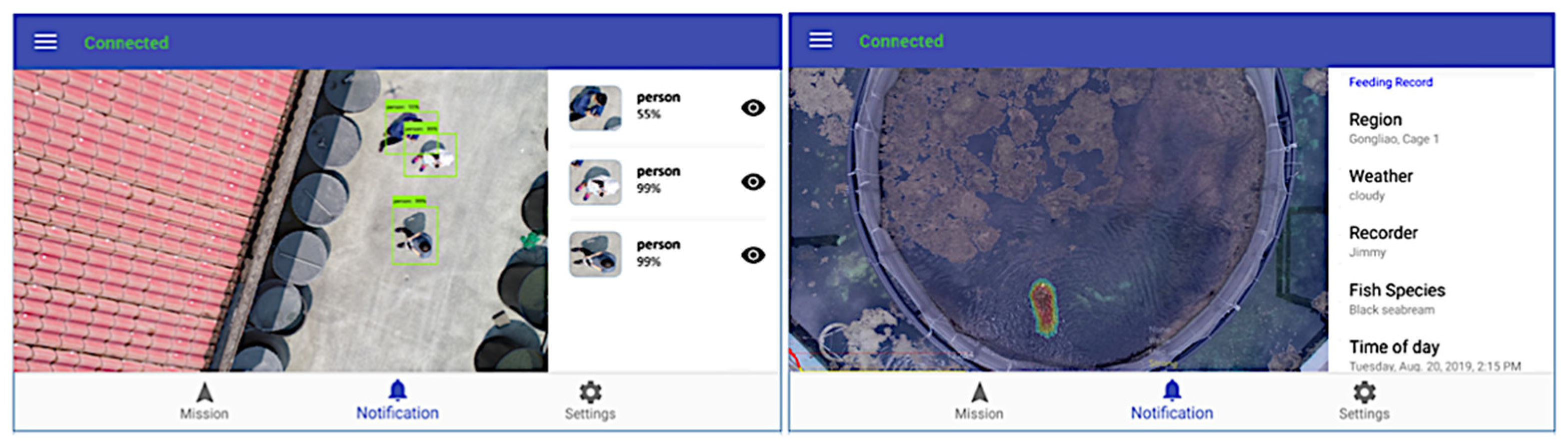
Suspicious object monitoring can detect suspicious objects, which could be ships or humans, that can cause possible security threats to aquaculture farms. If a human is identified as a suspicious object, the corresponding AI service instructs the drone to continue the navigation. The computed altitude and camera pose parameters will be the basis for capturing the facial image of the suspicious human object. The captured image is sent to the cloud to perform further face recognition using FaceNet [
10] deep-learning model. It will compare the newly captured images with the images of the authorized persons or staff in the scene database. This approach will distinguish workers from nonworkers or authorized from nonauthorized individuals and alerts the user for detected intruders. In executing the AI service for a fish-feeding-intensity mission, the cloud must first detect a fish cage or pond in the aquaculture site. Upon detection of the target object, the cloud will provide the altitude and camera position parameters for the drone to auto-navigate and proceed to the area of the fish cages. When the drone arrives at its target destination, it will then capture the feeding activity at the fish cage facility. The captured video is sent to the cloud for further processing and executes the fish-feeding-intensity evaluation and sends the feeding level to the users using the drone navigation APP.
2.2. Drone Path Planning and Navigation
For path planning, the scene cloud will use the GPS information of the detected object or the target goal (e.g., fish boxes for fish feeding intensity) to plan the path and sends this information to the user’s device. This user’s device has the drone navigation app installed and controls the drone using its WIFI channel as the communication device. The drone is also equipped with WIFI to communicate with the user’s device and scene cloud. The D* Lite algorithm [
11], works by reversing the A-star (A*) search framework [
12] using an incremental heuristic method for its search functions. Its key feature involves using previous search results to identify the path-planning requirement instead of solving each search from the start. If connections between nodes are created, the data are modified and only affected nodes are recalculated. It also identifies the best path or the shortest path with the lowest navigation cost using the following equation:
where
is the total score from the starting point through node
to the target point. Meanwhile,
is the actual distance from the starting point to node
and
is the estimated distance from node
to the target point. When
, no calculation is made. If
is the actual distance from node n to the target point, then node
is the node on the best path.
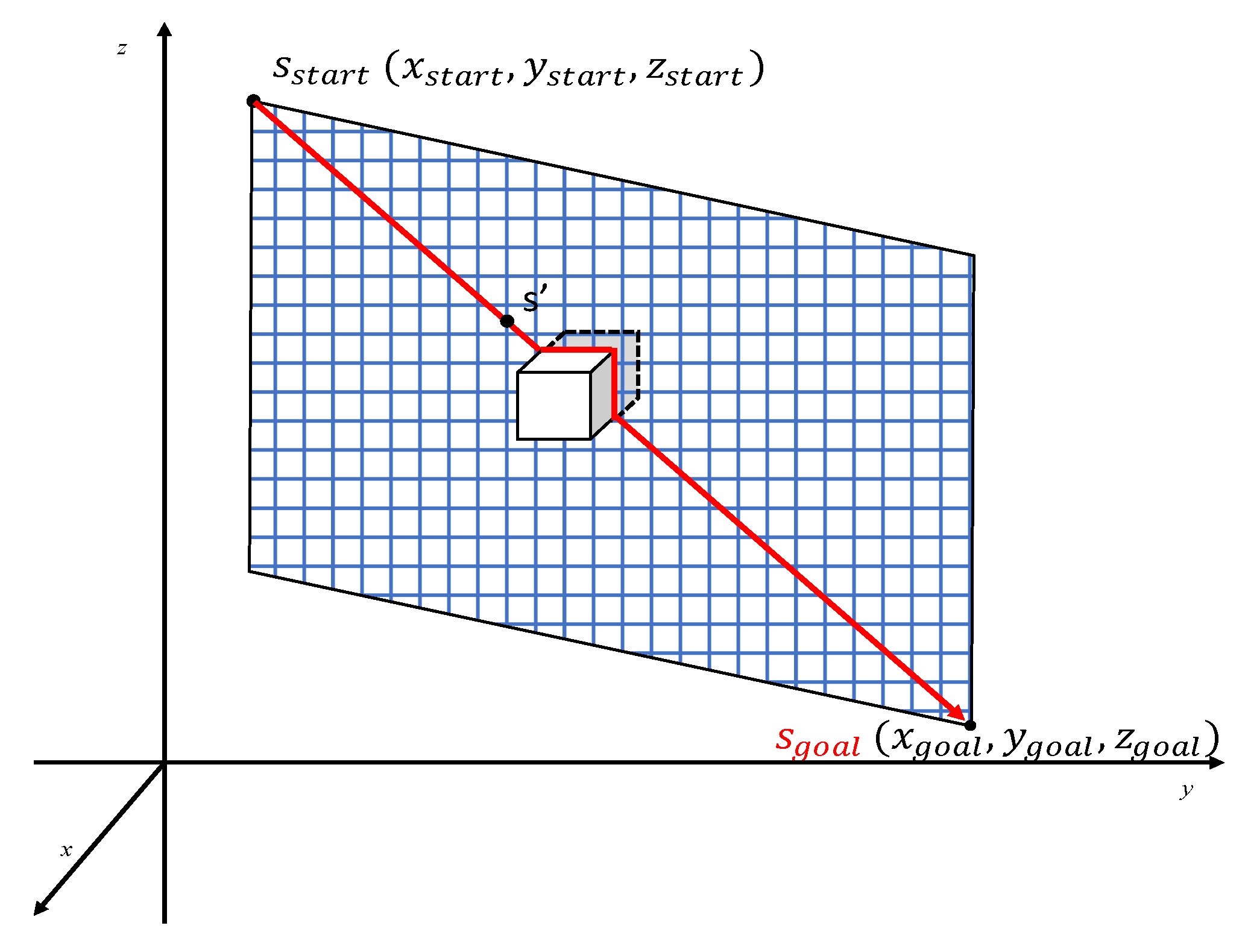
Since drone navigation is a dynamic planning problem due to its actual changing environments or characteristics, possible obstacles are present during the drone navigation process. The drone should be able to collect information and send it to the scene cloud to plan the path of an unfamiliar map in real-time. The D* Lite [
11] algorithm for path planning works for a dynamic environment and is the most suitable for drone navigation. It uses the current position as the starting point for the calculation and searches backward from the target point to the starting point. In drone navigation using the D* Lite algorithm to navigate a three-dimensional space, for the space coordinates of the starting point
, and target point
, the
axis and
axis correspond to the GPS coordinates of longitude and latitude positions, respectively; the
axis represents the drone’s navigational height.
Figure 3 is a schematic diagram of drone navigation, and the blue grid is the drone flight map. This map is a plane composed of four points (
), (
), (
), (
). When encountering obstacles, the edge is updated, and the path is re-panned. Hence, if an obstacle (white box) suddenly appears during the navigation at the top, a new plan or path is created from the scene cloud and sends this information for the drone to avoid the obstacle until it reaches its target destination or path.
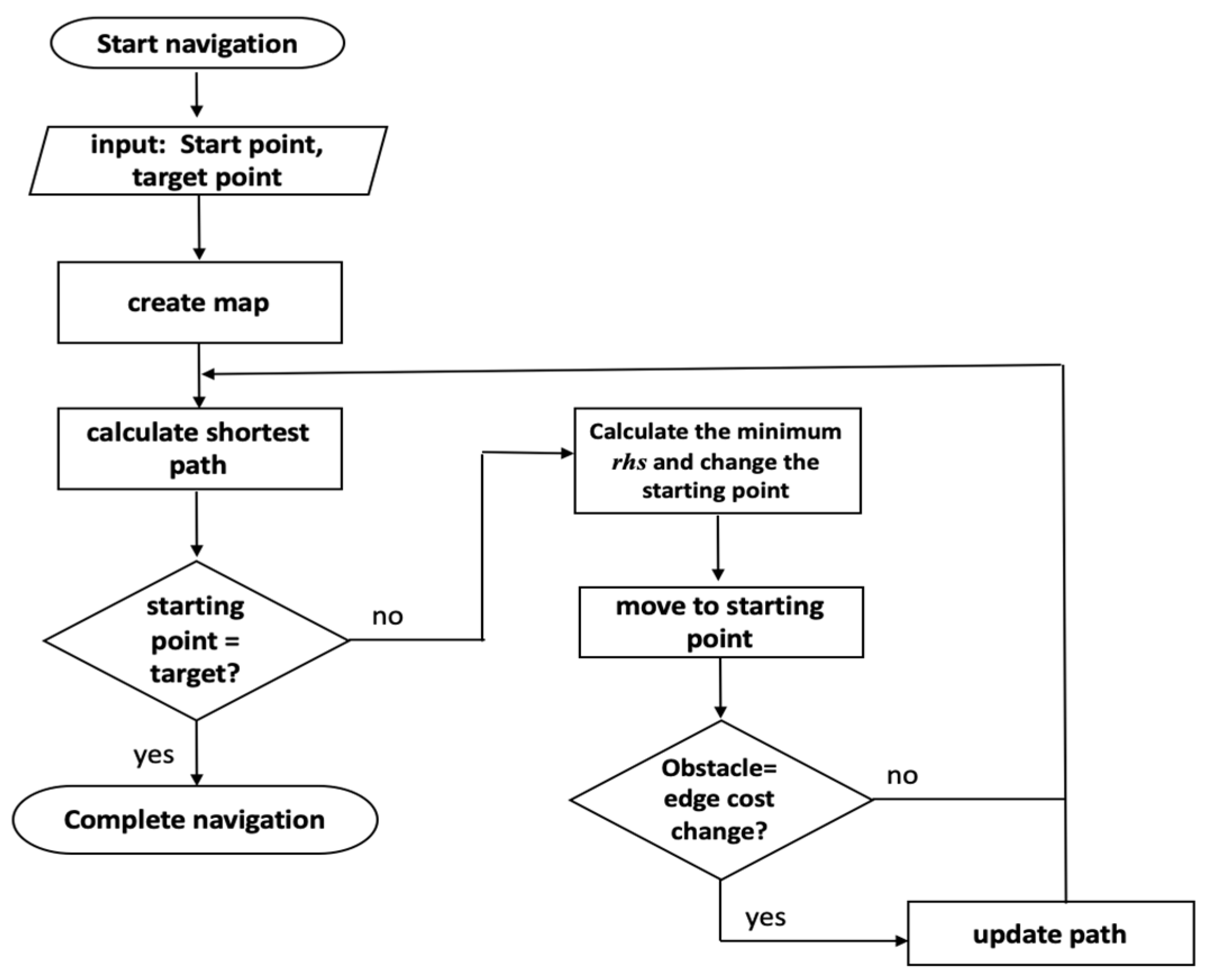
Figure 4 represents the flow chart of our drone navigation. As an initialization and to create the navigation map, the start-point and target point are needed. After building the plan map, the estimation of the shortest path (
Figure 3) follows next. The shortest path ensures that the drone has the minimum navigation cost from its current to target location [
13]. The drone now uses the computed shortest path in its navigation and checks if the starting point is the same as the target point. Once it reaches an equivalent value for the starting point and target point, the navigation task or mission is complete.
Otherwise, if the starting point is not the same as the target point, the navigation continues. It will then compute and finds the minimum vertex position to change the current starting point and moves to this new position. During the navigation, it will check for new obstacles in the area. If obstructions are detected, the path is recomputed using the shortest path function. If not, it will first update the current path plan, and then it will continue to calculate the fastest path. The path planning computation iterates until the drone’s starting point is the same as its target point. The drone has reached its destination and completed its task once the start point is equal to the target point.
The sequence interaction diagram shows the order of interaction between the app, drone, cloud database, and the cloud services and how they work together to execute and complete visual surveillance.
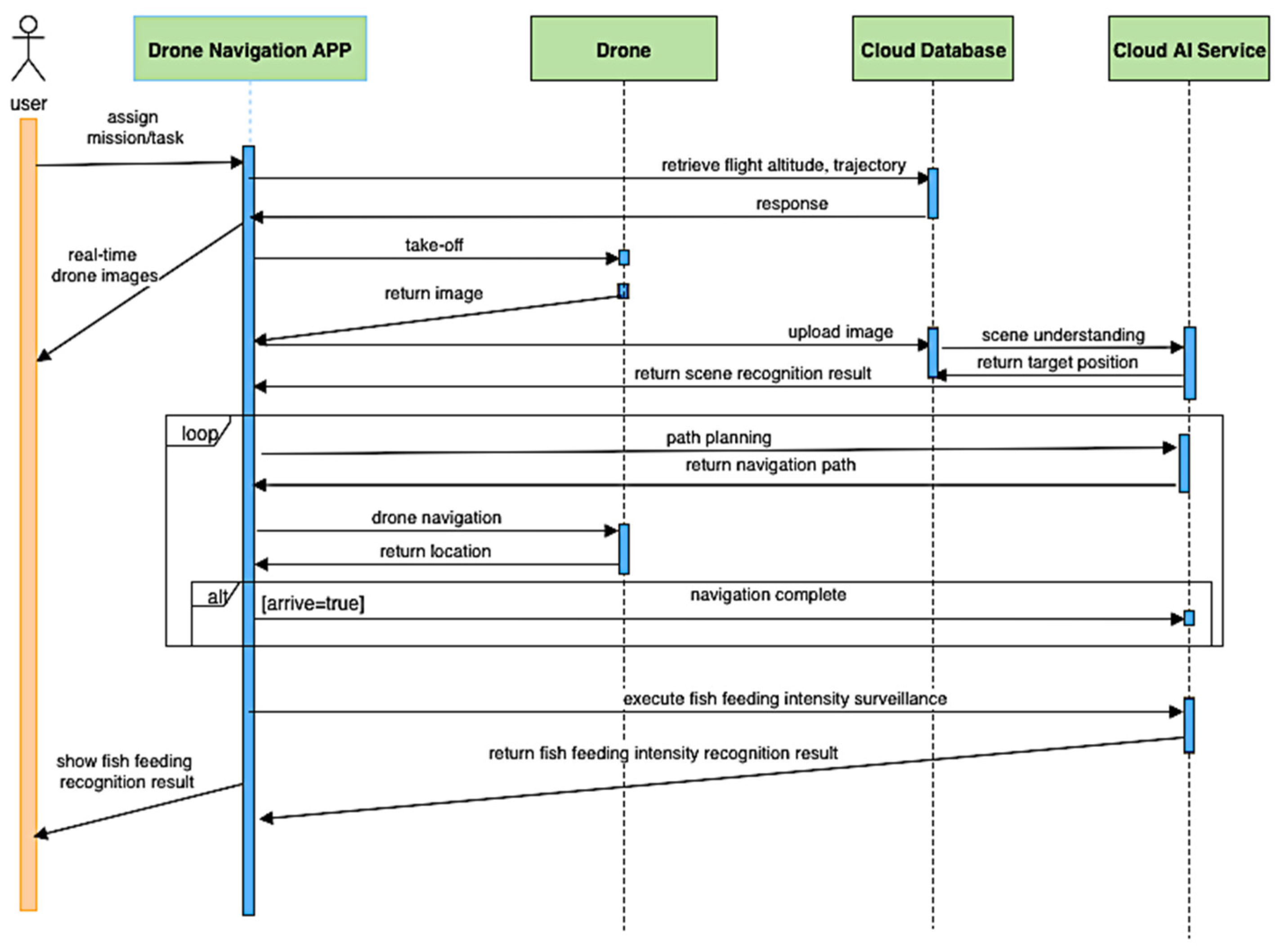
Figure 5 is the sequence diagram for the fish feeding intensity. Initially, the user selects the mission using the Drone Navigation App, which serves as the communication channel for the drone, cloud database, and cloud service for the drone take-off, capturing images and setting the route or path for the drone to navigate. The drone obtains the necessary parameters for navigation from the cloud database, the internal and external camera parameters, field knowledge for field analysis, path planning, and feeding monitoring.
When the drone takes off for the first time, it will perform scene analysis. The drone is first navigated at an altitude of 100 m to capture the image of the scene and sends it to the cloud database. After receiving the captured images, the cloud semantic understanding function searches for the location of the monitored objects from the scene. Once the captured scene is analyzed, it will send this information to the drone navigation app to perform drone navigation. The cloud provides the GPS coordinates of the drone, the location of the target object, the knowledge about the scene, route navigation to guide the drone towards the correct destination for monitoring. The drone continues to navigate until it reaches its target destination. The algorithm previously mentioned recalculates or modifies the navigation path in case there are obstacles along the way to avoid damage to the drone. Once the drone reaches the destination of the assigned mission or task, it will capture the fish feeding activity and sends data to the cloud AI service to evaluate the feeding level. This feeding level is forwarded to the user using the navigation app.
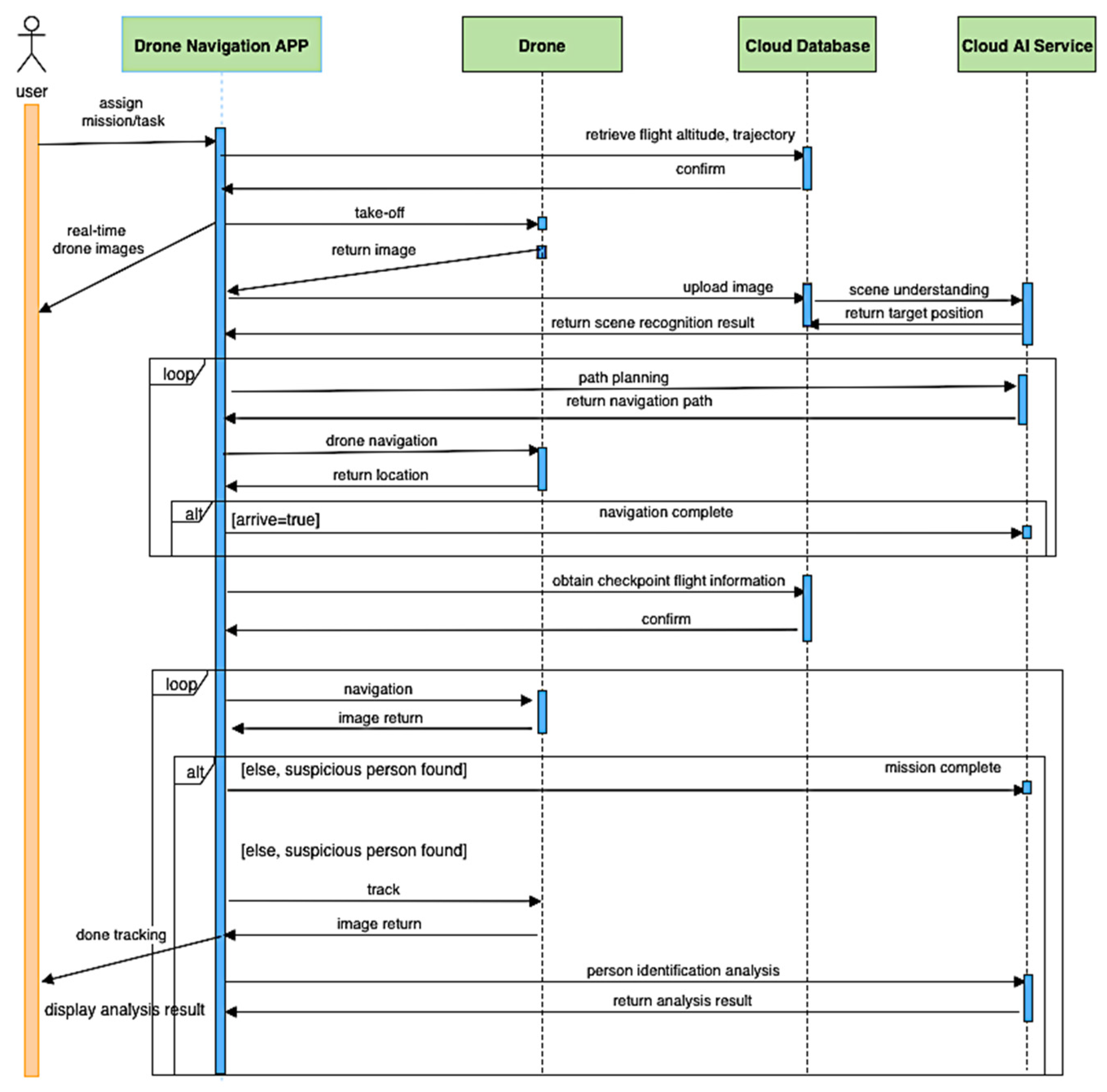
Figure 6 is the sequence diagram for monitoring the personnel in the aquaculture site. The same steps are integrated as for drone navigation in
Figure 5. The only difference is that the personnel monitoring task is continuous even after obtaining the checkpoint. The drone monitors all individuals found on the site, one at a time. It captures the facial image of each person and sends it to the cloud AI service to perform face recognition. Once the cloud detects a suspicious person based on the facial images sent by the drone, the cloud alerts the user using the navigation app. If there is no suspicious person from the people present in the aquaculture site, the mission ends.
2.3. Experimental Procedures and Materials
The semantic object detection used the mean average precision, suspicious person detection integrated intersection over union, and person identification utilized the equation TP/(TP + FP) × 100. We used the following formula for fish feeding intensity:
where TP (true positives) is a result that a positive class was predicted correctly; TN (true negative) is a result that a negative class was predicted correctly; FN (false negative) is when a positive class gets a negative class result; and FP (false positive) is when a negative class gets a positive result. Aside from accuracy, we also measured the precision, recall, and F-score value for the fish feeding-intensity evaluation. The definition of F-score is as follows:
The experimental aquaculture site is at Aqua Center, Gong Liao, New Taipei City, Taiwan. The experimental data used were RGB videos captured using the Phantom 4 Pro V2.0. The drone navigation and DB management apps used the Java programming language for its implementation. Similarly, we used an Intel Core i7 3.4 GHz personal computer and NVIDIA GeForce 1080ti GPU for neural network model training. Two GoPro cameras was used as the stereo camera lens for the fish-length estimation.
The details of the different convolutional neural networks used, their corresponding parameters, training and evaluation methods, and datasets are presented in the following sections:
2.3.1. Convolutional Neural Networks (CNNs)
Deep learning has become famous for optimizing the results of various tasks for classification, recognition, or detection problems. CNNs are inspired by the concept of natural visual perception of living creatures [
14]. CNN is a deep-learning method, taking images as input and performing processing using the idea of convolution to extract features or characteristics of the images. It generates the required output in the last layer, a fully connected layer where each node is linked to all other nodes in the previous layer [
15]. Each convolution has a convolutional layer for feature extraction. Convolution preserves the relationship between pixels as it uses various filters to detect edges, blur, and sharpen images.
One component of convolution is activation functions, which define the weighted sum of its input nodes and then transform it as an output of the layer. They are nonlinearities that take a single number and perform mathematical operations on it. Furthermore, the addition of pooling layers reduces the computational requirement and reduces the number of connections between layers [
14]. All AI services in this article used CNN as their methodology for learning features.
2.3.2. Semantic Segmentation
For site monitoring, there are different objects, such as box nets, ponds, and houses, for consideration. The Mask R-CNN deep-learning model [
9] recognizes these objects present in the scene. The Mask RCNN first proposes regions of the possible objects from the input image. It will then predict those objects, refine the corresponding bounding box, and generate the object’s mask on a pixel level using the proposed regions as its basis. We trained the Mask R-CNN using the image sequences captured from the aquaculture site at different times and perspectives. We manually marked the locations of aquaculture tanks, box nets, work platforms, and personnel in the captured images.
Figure 7 shows the images captured using the drone with an altitude of 150 m since it can cover most of the objects in the aquaculture site. The objects marked are fish ponds, box nets, and houses. There were two types of fish ponds: box nets and the ordinary pond. Fish ponds were further classified into rounded or square fish ponds. The box nets’ location is in the open sea with 12 m diameter. Box nets were used for fish feeding-behavior analysis. Each object in the aquaculture site covers at least 30% of the scope of the screen before marking. A total of 114 images were manually labeled using LabelMe for the Mask R-CNN training and 200 images were used for testing. The parameters used for training the Mask R-CNN are learning _rate = 0.001, weight_decay = 0.001, and ephocs = 1000.
2.3.3. Fish Feeding Intensity
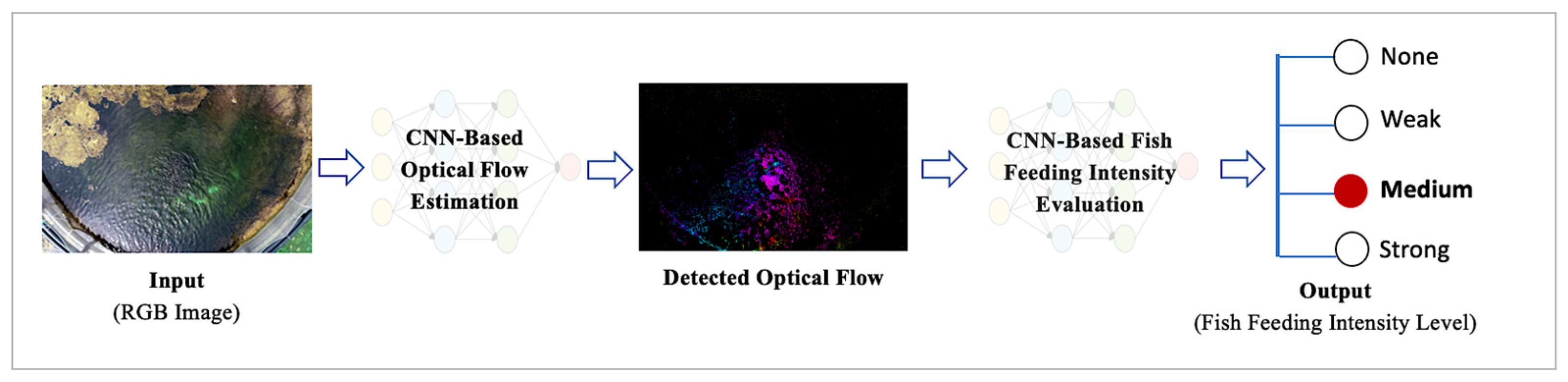
The fish feeding intensity is a part of the AI service which can evaluate the level of satiety of fish. As shown in
Figure 8, we combined two deep neural network models: CNN-based optical flow estimation for motion estimation and CNN-based fish feeding-intensity evaluation to generate higher-accuracy results. For the optical flow estimation, we used video interpolation-based CNN [
16] to estimate and generate the optical flow from our RGB input image sequences. The generated optical flow is used as input to the I3D model to determine the level of feeding intensity as none, weak, medium, or strong. The I3D model, as a two-stream approach, takes both the RGB video and the sequences of our preprocessed optical flow images [
17] as inputs.
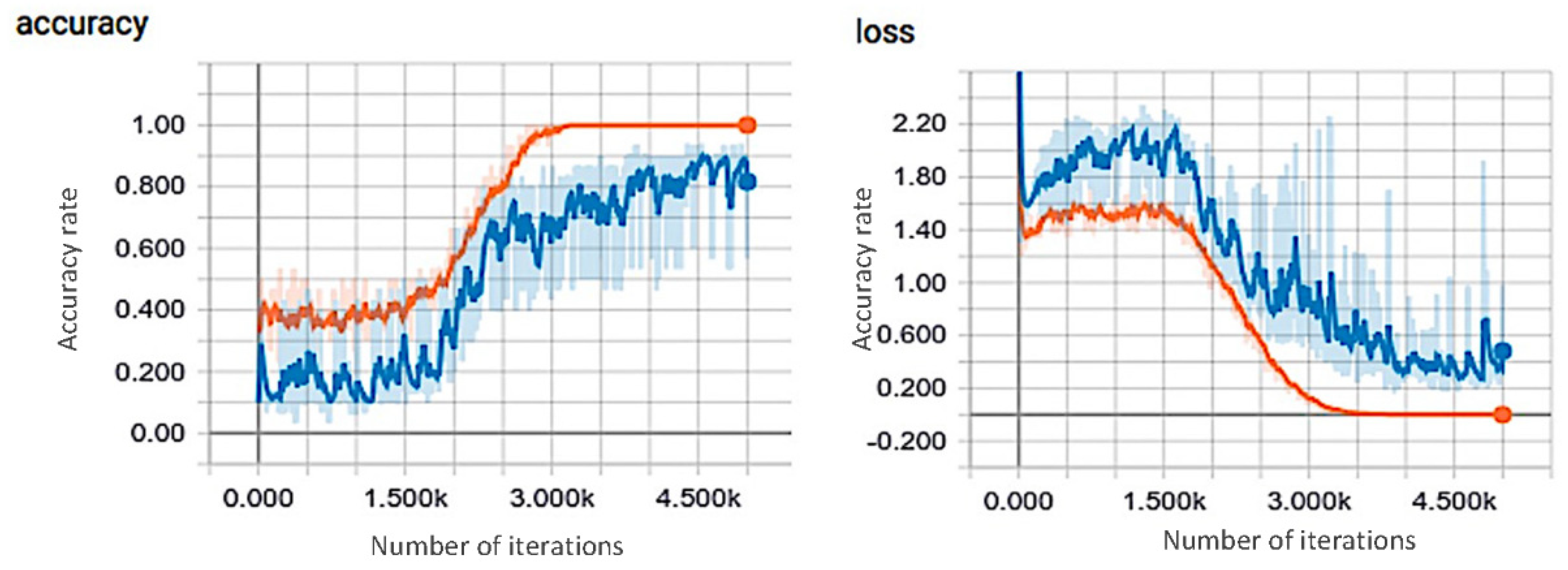
In preparing the dataset for the I3D model, we generated 216,000 frames or 6750 video segments from 24 collected fish feeding activity videos. Each image frame is manually labeled using one of the four categories: none, weak, medium, or strong. These image frames were resized into smaller sizes (256 × 256 pixels) and cropped into 224 × 224 patches. The leave-one-out cross-validation method was the basis for the distribution of the training and testing dataset. In training the I3D model, we used 4000 epochs with a batch size of 30, a learning rate of 0.0001, and a decay rate of 0.1. The complete details for the fish feeding-intensity evaluation are in a paper by Ubina et al. [
18].
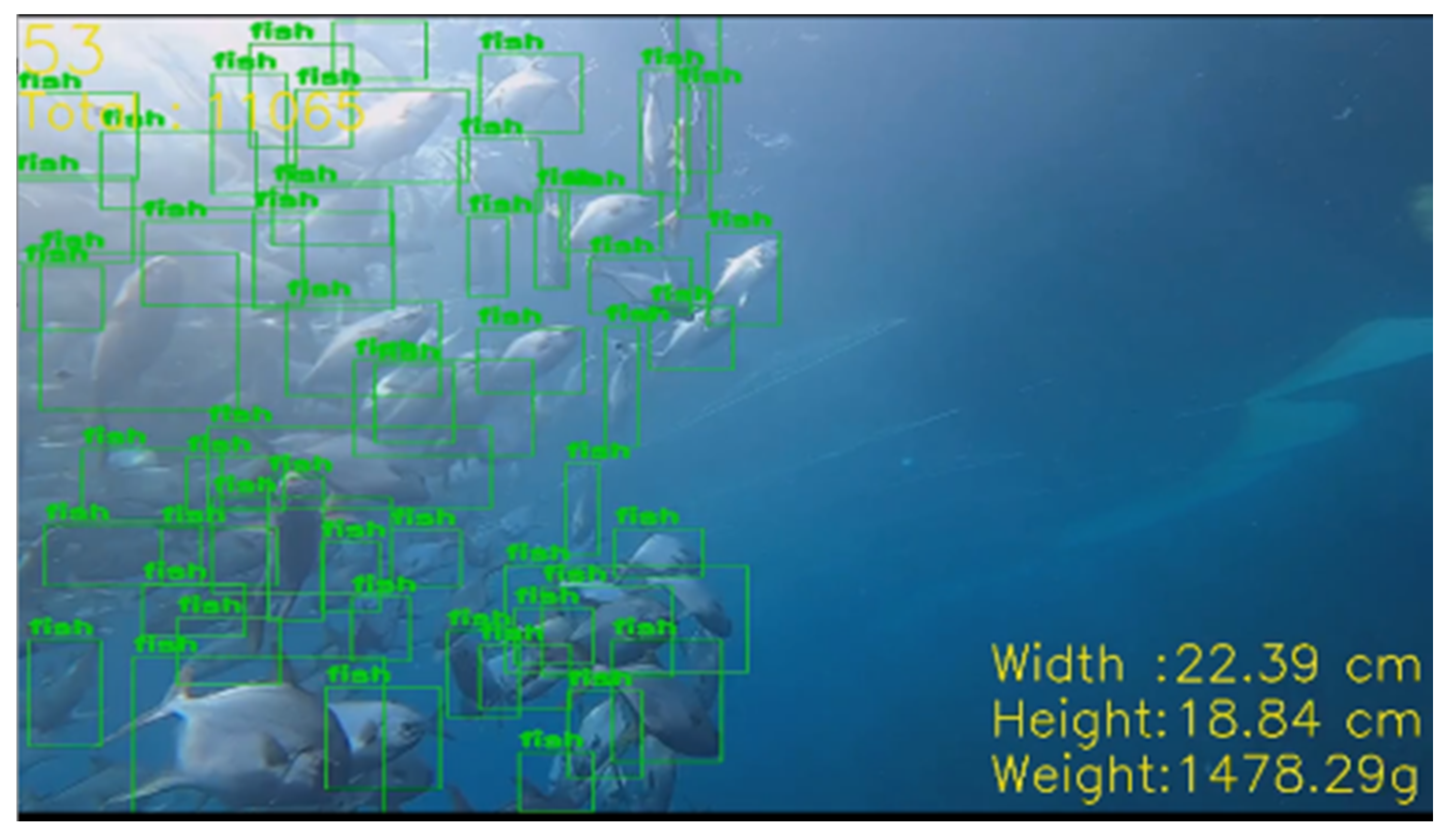
2.3.4. Fish Count
To achieve real-time monitoring for fish, we applied an architecture for fish detection using YOLOV4 [
19], which is very popular in terms of speed and high efficiency in object detection. In retraining the YOLOV4, we used 200 images, and each image is labeled with around 110 fish. The batch_size is equal to 8, and the number of iterations is 2000. To determine the number of fish for each frame, we calculated the total number of fish as 30,000, with an actual volume of 11,996.57 cubic meters and a collected image frame of 45,000. We compared the ratio of the average number of fish for each image frame with the total number of fish. To calculate this, we used the following formula:
To calculate the density, we divided the estimated value of the total fish by the actual volume, where the unit used is the number of fish per cubic meter.
2.3.5. Fish-Length Estimation
We used a stereo-image camera system to estimate the fish body length to calculate the fish density. To determine the fish body length, we used a deep stereo-matching neural network and used the left image to reconstruct the right image. We also derived the optical flow or movement of the fish for each frame using its forward and backward motions to generate an intermediate frame.
We generated the optical flow of each image using a pretrained, unsupervised deep-learning optical-flow model based on the video interpolation method [
16]. The optical flow is the basis for calculating the disparity value of the two images by summing up the pixelwise residual displacement for each pixel in the target fish object. In computing the 3D coordinates of the pixel value, the disparity is combined with the camera parameters to reconstruct the 3D point cloud of the target object to estimate the fish body length.
Instead of using a single image frame to estimate the body length, we considered the different postures of the fish for each image frame. By tracking the fish across frames, we calculated the body length for each frame and obtained the average, which serves as the final body length. We integrated the Principal Component Analysis (PCA) method in analyzing the length, width, and height of the 3D fish using the front and side positions.
2.3.6. Suspicious Object Monitoring
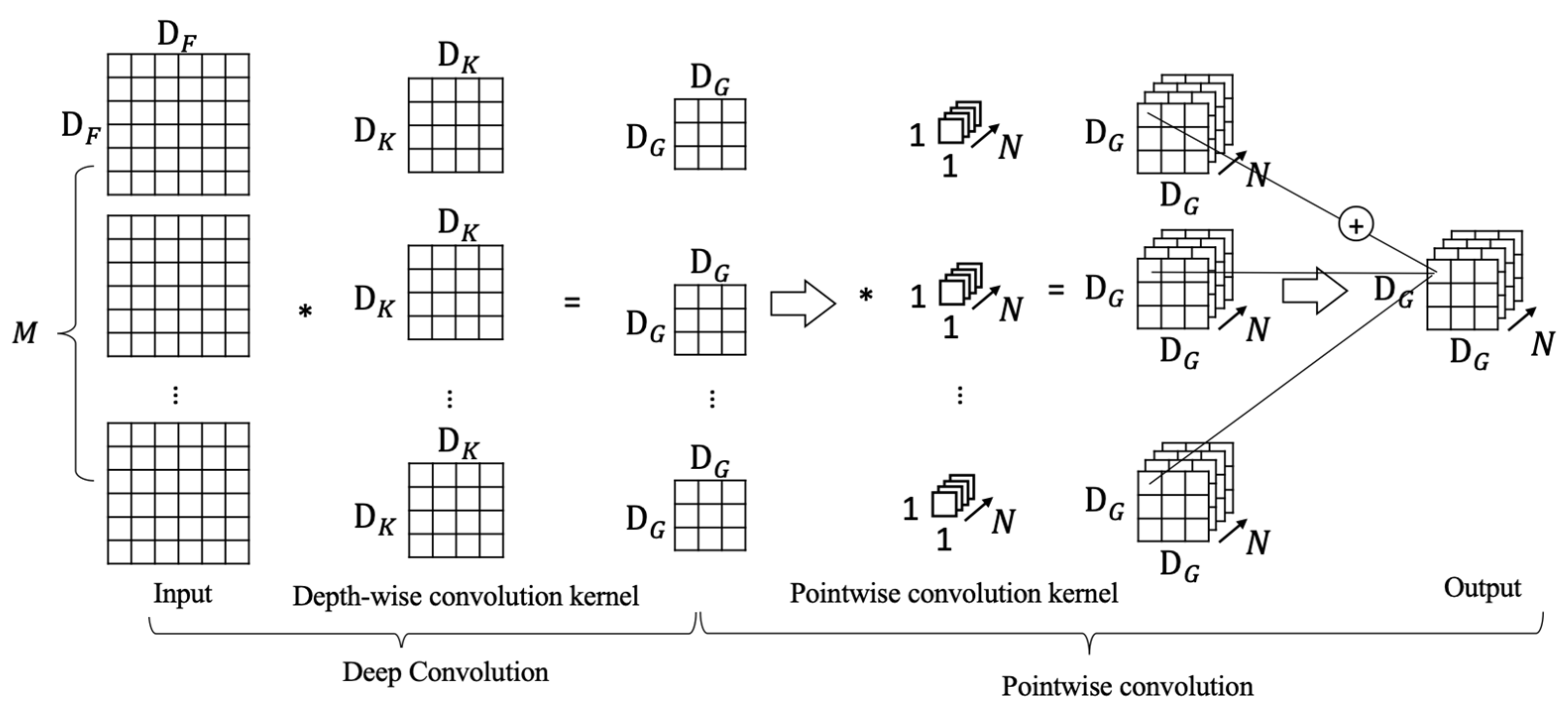
To detect suspicious objects in the site, we adopted a streamlined architecture using depthwise separable convolutions with MobileNet [
20]. This is a lightweight and efficient model that reduces the number of parameters, so it meets the real-time calculation requirements. The depthwise separable convolution decomposes a standard convolution into deep convolution (depthwise convolution and 1 × 1 pointwise convolution).
Figure 9 shows the framework of the depthwise separable convolution using the input (
). The convolution kernel (
) can produce (
) output after convolution. The depth separable convolution together with the input size of (
) and the convolution kerne
l (
) are convolved to produce (
). This output is further convolved with the point-by-point convolution kernel (
) and adds the result of the
channel to produce the result (
), which is an output of the same channel as the standard convolution kernel. This method has reduced the amount of calculation by eight to nine times. We used LabelMe to manually provide the label of the collected aerial images for the suspicious person dataset. The suspicious objects may appear both in inland aquaculture farms (people) or in the open sea (ship vessels or boats). The data sets were captured involving suspicious persons with various postures in the field, such as walking, fish stealing, and sitting.
In training the MobileNets [
20], we loaded the pretrained model ssd_inception_v2_coco and set the batch_size to 24 to increase the speed and accuracy. The COCO dataset was utilized to fine-tune the final parameters of the neural network. The dataset contains 3328 images at 20 different checkpoints, with at most five persons in each image. We utilized 80% of those data for training and 20% for testing.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}