

Simultaneous Astronaut Accompanying and Visual Navigation in Semi-Structured and Dynamic Intravehicular Environment


Abstract
1. Introduction
2. Astronaut Detection in Diverse Postures and Orientations
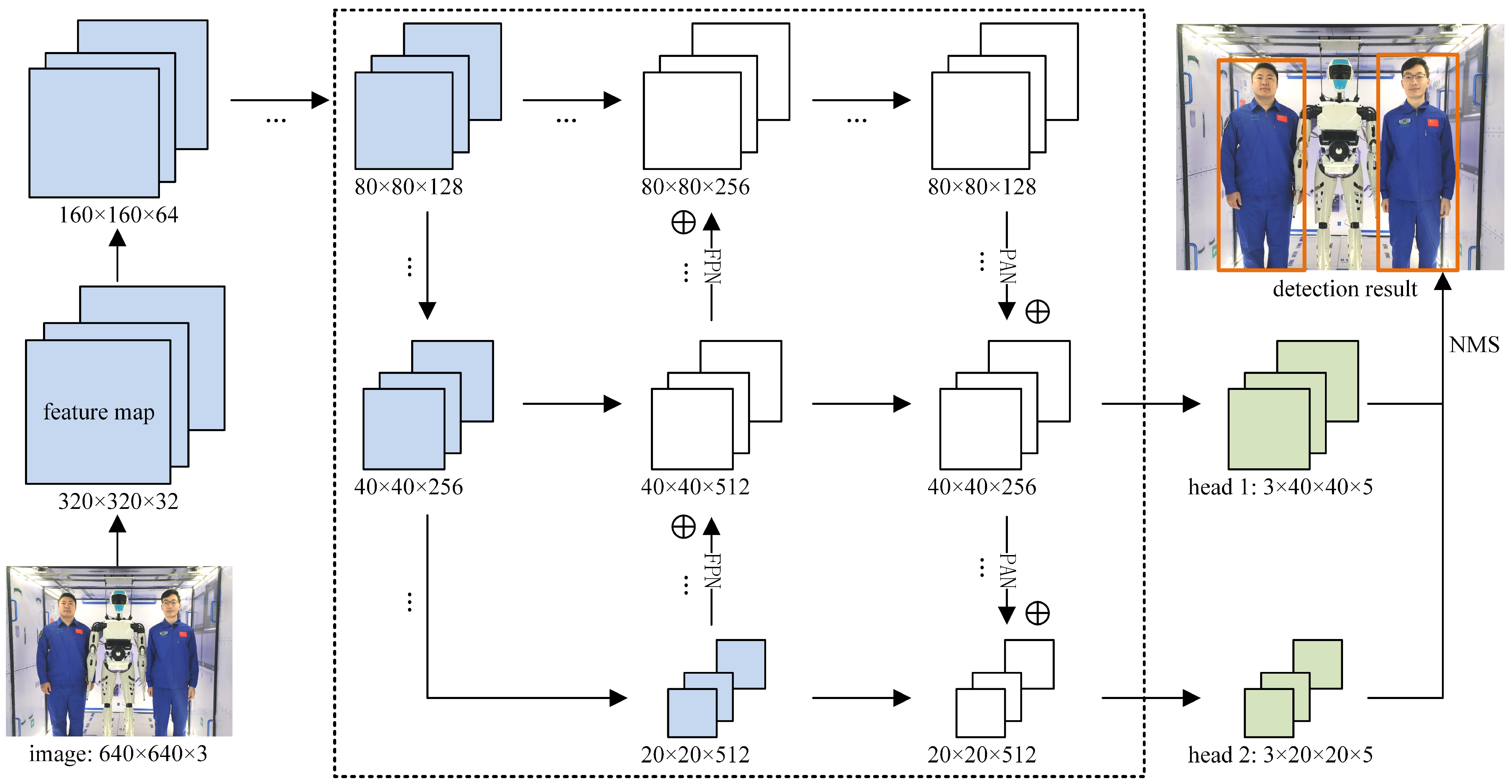
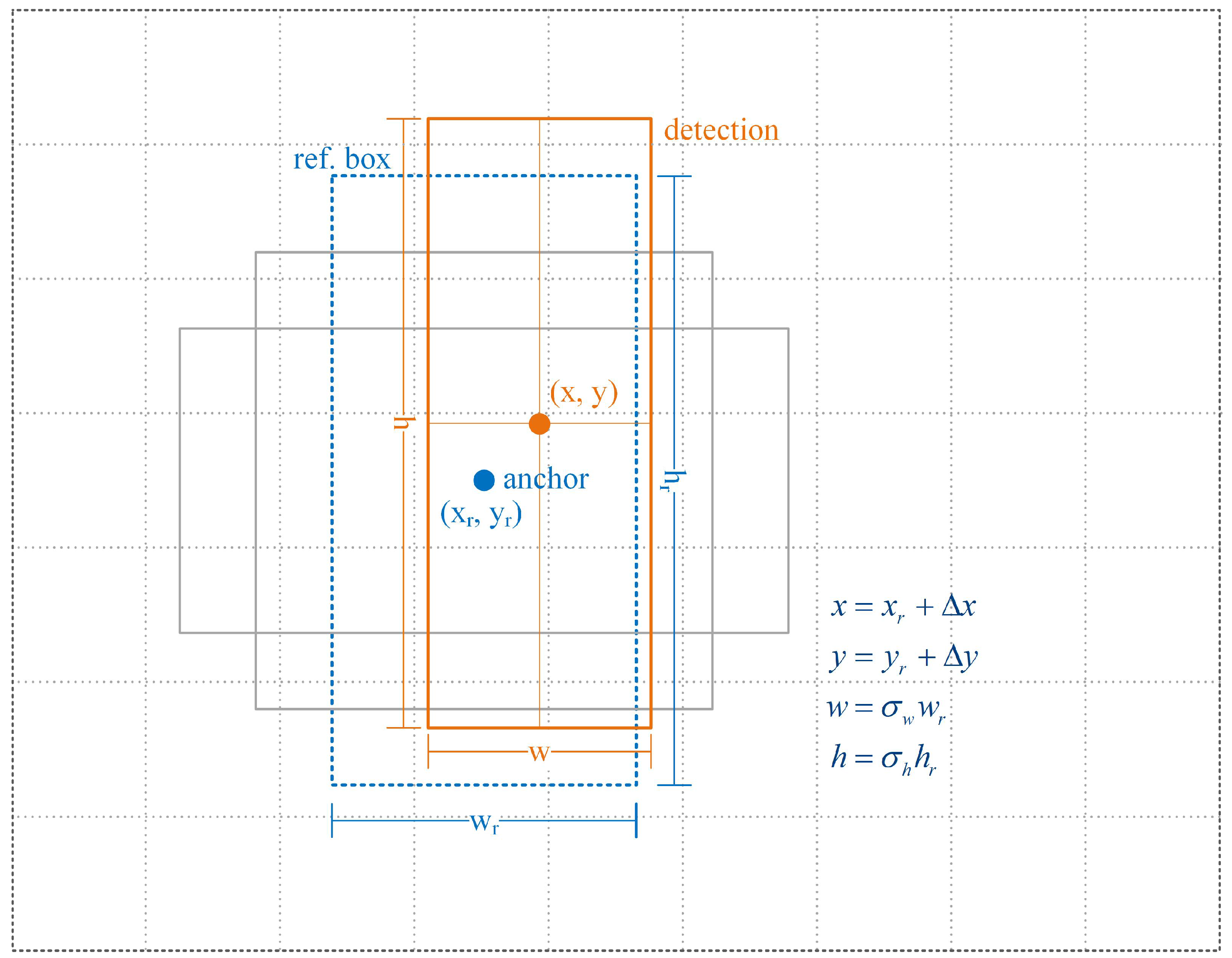
2.1. Design of the Customized Astronaut-Detection Network
- (1)
- Astronauts can present diverse postures and orientations during intravehicular activities, such as standing upside down and climbing with handrails.
- (2)
- Astronauts may wear similar uniforms, which are hard to distinguish.
- (3)
- Images can be taken from any position or orientation by IRA in microgravity.
- (4)
- It is possible to simplify the astronaut detector while maintaining satisfactory performance by utilizing the relatively fixed and stable background and the limited range of motion in the space station.
- (5)
- There is a limited number of crew members onboard the space station at the same time.
2.2. Astronaut-Detection Dataset for Network Fine Tuning
2.3. Network Pre-Training and Fine Tuning
3. Visual Navigation in Semi-Structured and Dynamic Environments
3.1. Map-Based Navigation in Semi-Structured Environments
- (A)
- Construction of the visual navigation map
- (1)
- Build initial map using standard visual SLAM technique.
- (2)
- Maps are optimized to minimize the distortion and the overall reprojection error.
- (3)
- The optimized maps are registered to the space station with a set of known points.
- (B)
- Map-based localization and orientation
3.2. Robust Navigation during Human–Robot Collaboration
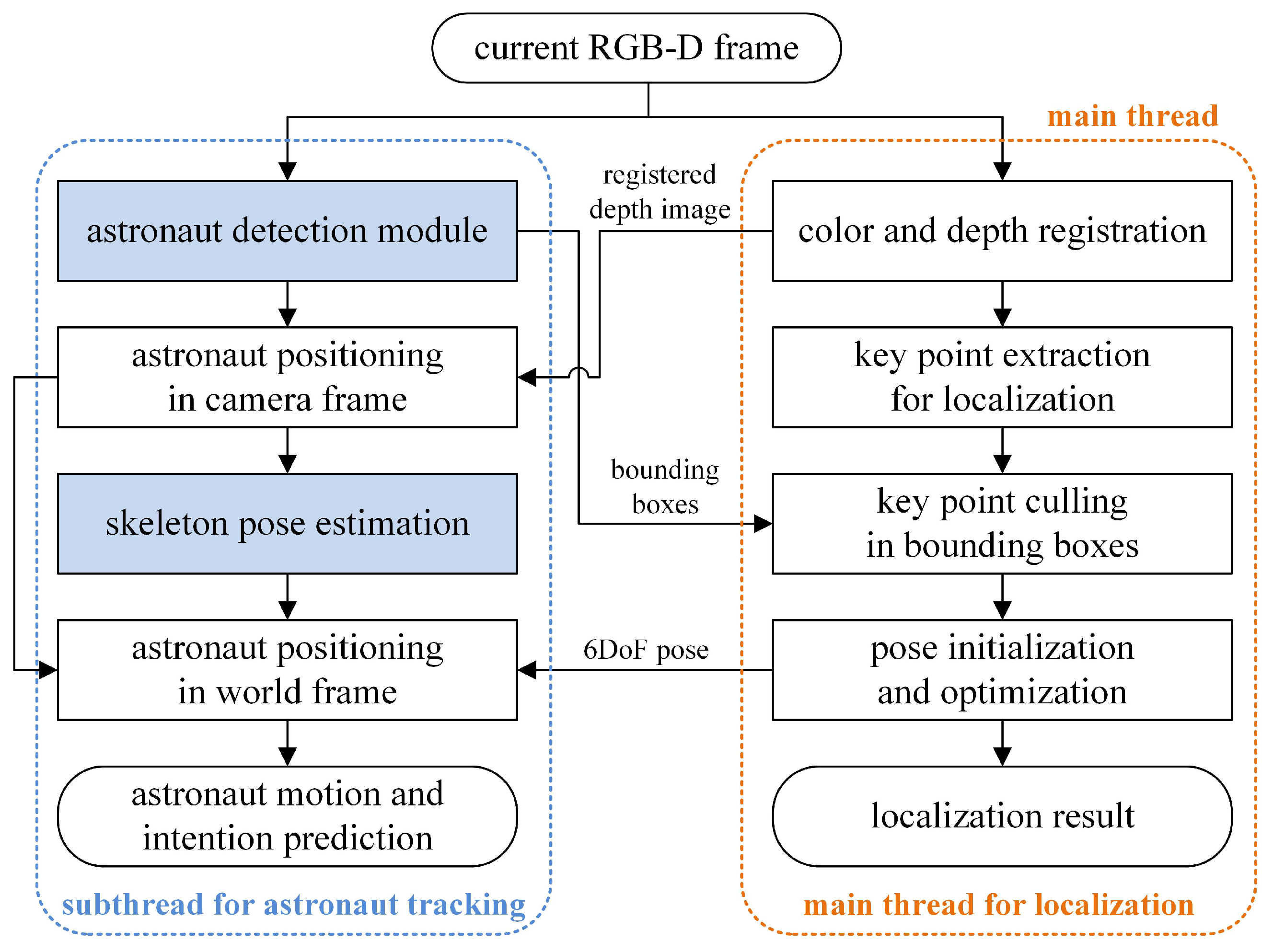
4. Astronaut Visual Tracking and Motion Prediction
- (A)
- Matching with predicted trajectory
- (B)
- Matching with geometric similarity
- (C)
- Matching with other clues
5. Experimental Results and Discussion
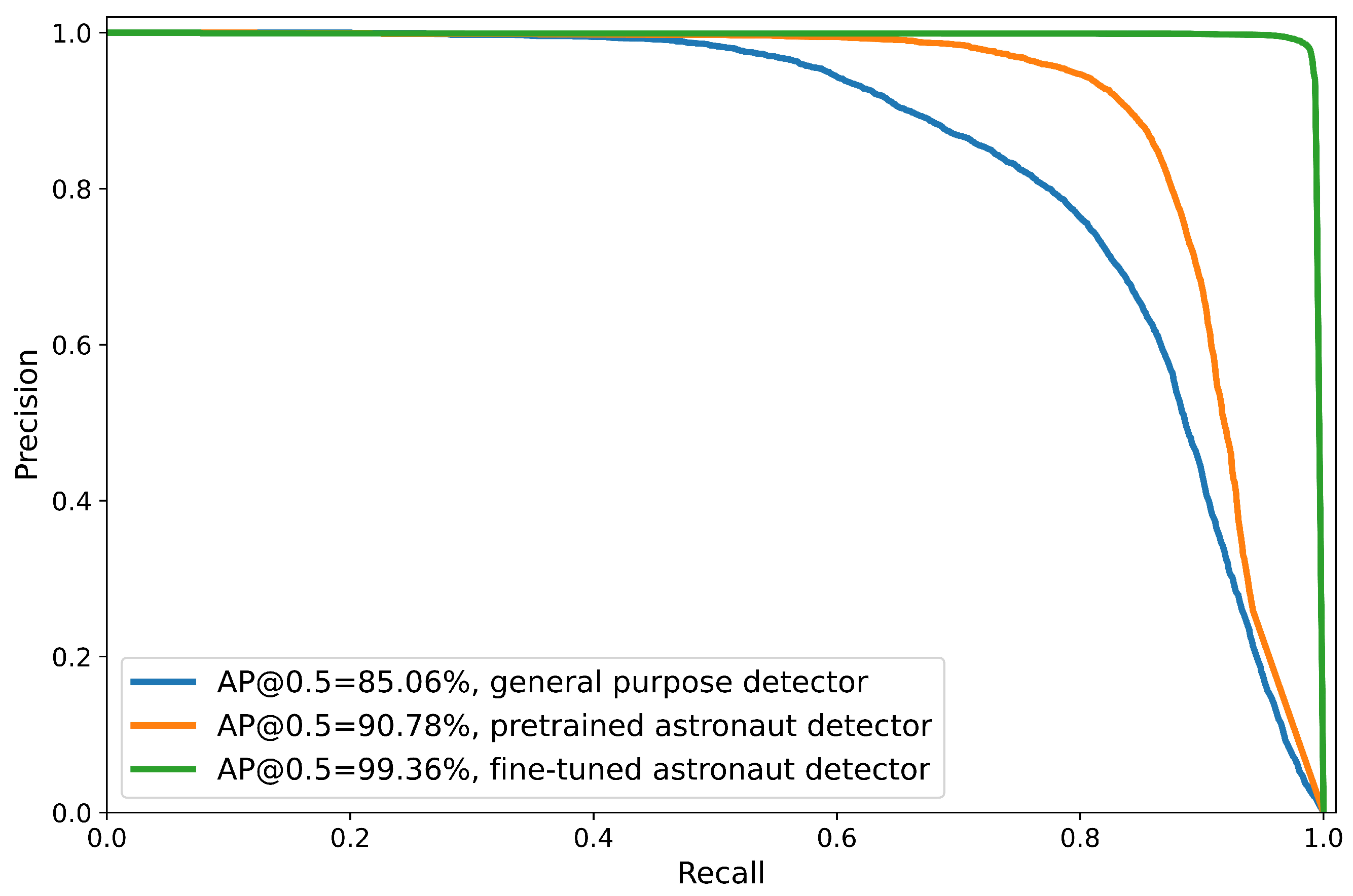
5.1. Evaluation of the Customized Astronaut Detector
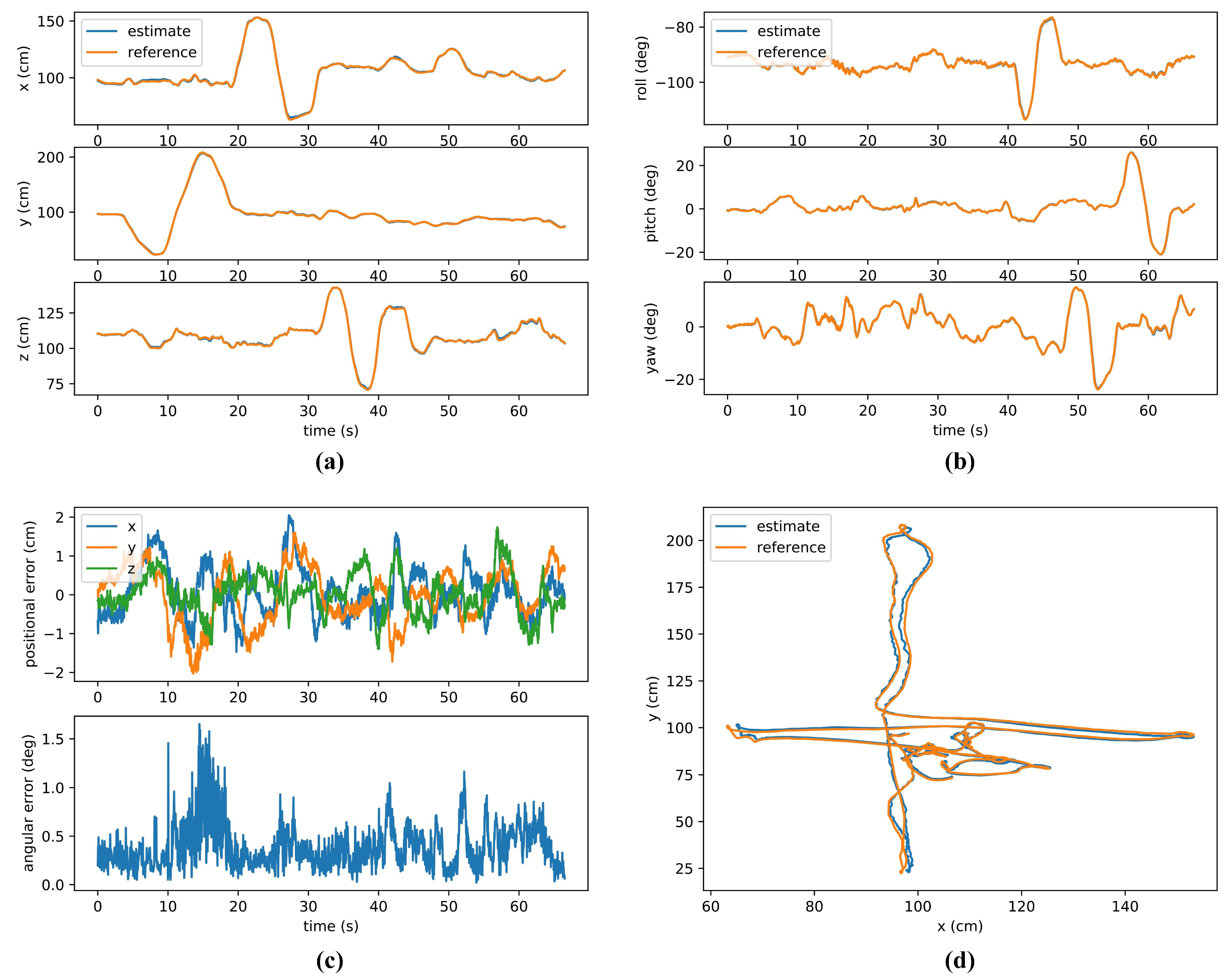
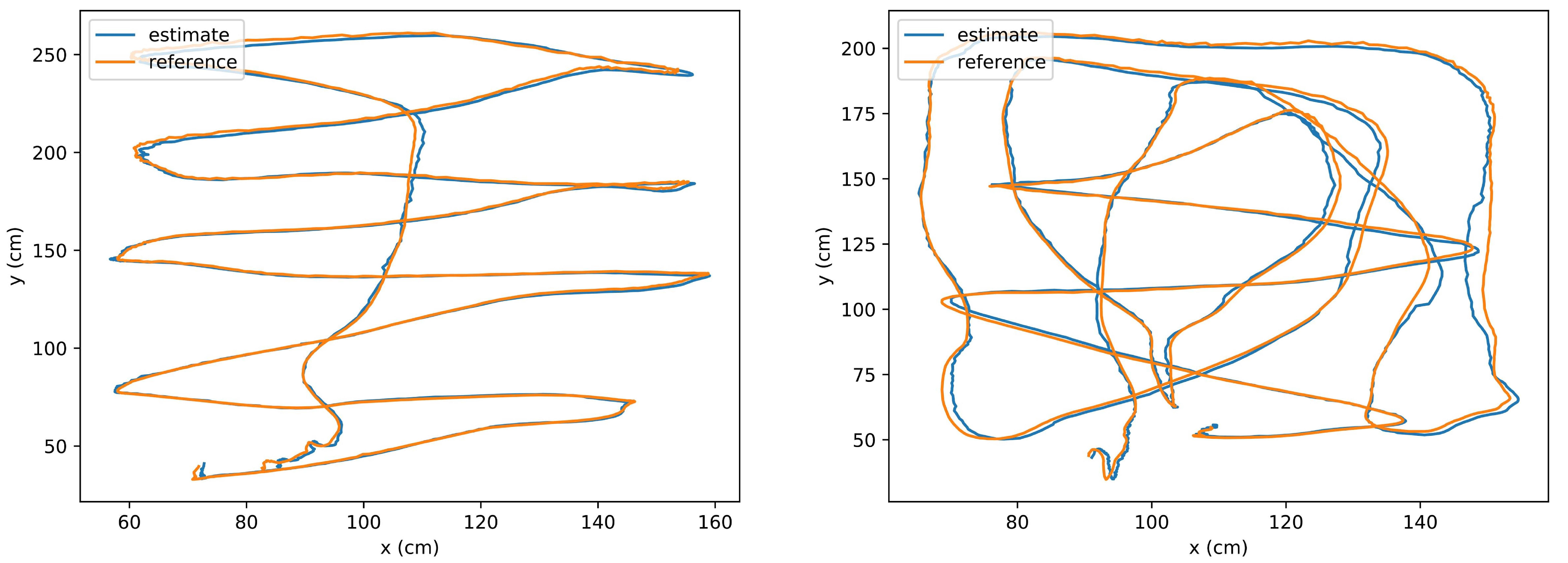
5.2. Evaluation of Map-Based Navigation in Semi-Structured and Dynamic Environments
- (A)
- Performance in static environment
- (B)
- Performance in dynamic environment
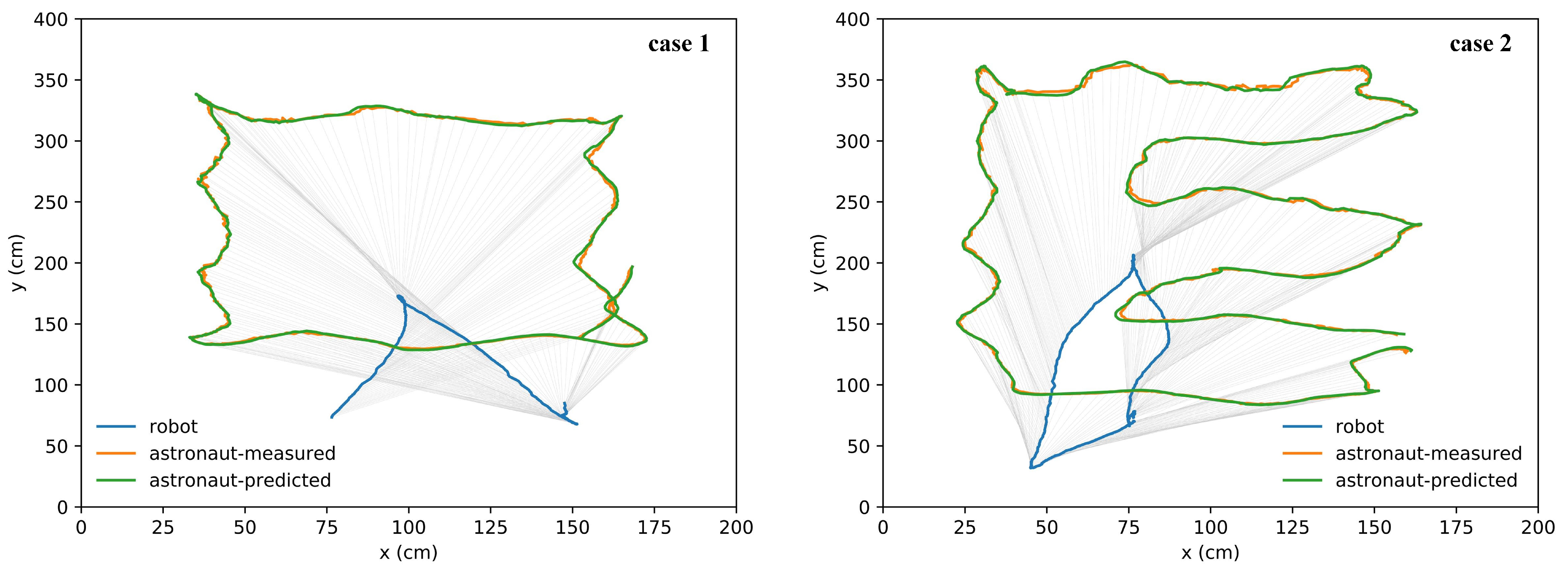
5.3. Verification of Simultaneous Astronaut Accompanying and Visual Navigation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IRA | Intravehicular robotic assistants |
| CIMON | Crew interactive mobile companion |
| IFPS | Intelligent formation personal satellite |
| SPHERES | Synchronized position hold engage and reorient experimental satellite |
| ISS | Internationall Space Station |
| JEM | Japanese experiment module |
| FPN | Feature pyramid network |
| PAN | Path aggregation network |
| IOU | Intersection over union |
| CIOU | Complete intersection over union |
| COCO | Common object in context |
| RGB-D | Red green blue-depth |
| SFM | Structure from motion |
| SLAM | Simultaneous localization and mapping |
| PnP | Perspective-n-point |
| AP | Average precision |
| MAP | Maximum a posteriori |
References
- Sgobba, T.; Kanki, B.; Clervoy, J.F. Space Safety and Human Performance, 1st ed.; Butterworth-Heinemann: Oxford, UK, 2018; pp. 357–376. Available online: https://www.elsevier.com/books/space-safety-and-human-performance/sgobba/978-0-08-101869-9 (accessed on 10 October 2022).
- Russo, A.; Lax, G. Using artificial intelligence for space challenges: A survey. Appl. Sci. 2022, 12, 5106. [Google Scholar] [CrossRef]
- Miller, M.J.; McGuire, K.M.; Feigh, K.M. Information flow model of human extravehicular activity operations. In Proceedings of the 2015 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2015. [Google Scholar]
- Miller, M.J. Decision support system development for human extravehicular activity. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2017. [Google Scholar]
- Akbulut, M.; Ertas, A.H. Establishing reduced thermal mathematical model (RTMM) for a space equipment: An integrative review. Aircr. Eng. Aerosp. Technol. 2022, 94, 1009–1018. [Google Scholar] [CrossRef]
- Li, D.; Zhong, L.; Zhu, W.; Xu, Z.; Tang, Q.; Zhan, W. A survey of space robotic technologies for on-Orbit assembly. Space Sci. Technol. 2022, 2022, 9849170. [Google Scholar] [CrossRef]
- Smith, T.; Barlow, J.; Bualat, M. Astrobee: A new platform for free-flying robotics on the international space station. In Proceedings of the 13th International Symposium on Artificial Intelligence, Robotics, and Automation in Space, Beijing, China, 20–22 June 2016. [Google Scholar]
- Mitani, S.; Goto, M.; Konomura, R. Int-ball: Crew-supportive autonomous mobile camera robot on ISS/JEM. In Proceedings of the 2019 IEEE Aerospace Conference, Yellowstone Conference Center, Big Sky, MT, USA, 2–9 March 2019. [Google Scholar]
- Experiment CIMON—Astronaut Assistance System. Available online: https://www.dlr.de/content/en/articles/missions-projects/horizons/experimente-horizons-cimon.html (accessed on 10 October 2022).
- Zhang, R.; Wang, Z.K.; Zhang, Y.L. A person-following nanosatellite for in-cabin astronaut assistance: System design and deep-learning-based astronaut visual tracking implementation. Acta Astronaut. 2019, 162, 121–134. [Google Scholar] [CrossRef]
- Liu, Y.Q.; Li, L.; Ceccarelli, M.; Li, H.; Huang, Q.; Wang, X. Design and testing of BIT flying robot. In Proceedings of the 23rd CISM IFToMM Symposium, Online, 20–24 September 2020; Available online: http://doi.org/10.1007/978-3-030-58380-4_9 (accessed on 10 October 2022).
- NASA Facts Robonaut 2, Technical Report. Available online: https://www.nasa.gov/sites/default/files/files/Robonaut2_508.pdf (accessed on 10 October 2022).
- Meet Skybot F-850, the Humanoid Robot Russia Is Launching into Space. Available online: https://www.space.com/russia-launching-humanoid-robot-into-space.html (accessed on 10 October 2022).
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F. Deep neural network based vehicle and pedestrian detection for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Avdelidis, N.P.; Tsourdos, A.; Lafiosca, P.; Plaster, R.; Plaster, A.; Droznika, M. Defects recognition algorithm development from visual UAV inspections. Sensors 2022, 22, 4682. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Wang, Z.K.; Zhang, Y.L. Astronaut visual tracking of flying assistant robot in space station based on deep learning and probabilistic model. Int. J. Aerosp. Eng. 2018, 2018, 6357185. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, Y.L.; Zhang, X.Y. Tracking in-cabin astronauts Using deep learning and head motion clues. Int. J. Aerosp. Eng. 2018, 9, 2680–2693. [Google Scholar] [CrossRef]
- Saenz-Otero, A.; Miller, D.W. Initial SPHERES operations aboard the International Space Station. In Proceedings of the 6th IAA Symposium on Small Satellites for Earth Observation, Berlin, Germany, 23–26 April 2008. [Google Scholar]
- Prochniewicz, D.; Grzymala, M. Analysis of the impact of multipath on Galileo system measurements. Remote Sens. 2021, 13, 2295. [Google Scholar] [CrossRef]
- Coltin, B.; Fusco, J.; Moratto, Z.; Alexandrov, O.; Nakamura, R. Localization from visual landmarks on a free-flying robot. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Seoul, Republic of Korea, 8–9 October 2016. [Google Scholar]
- Kim, P.; Coltin, B.; Alexandrov, O. Robust visual localization in changing lighting conditions. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, Marina Bay Sands, Singapore, 29 May–3 June 2017. [Google Scholar]
- Xiao, Z.; Wang, K.; Wan, Q.; Tan, X.; Xu, C.; Xia, F. A2S-Det: Efficiency anchor matching in aerial image oriented object detection. Remote Sens. 2021, 13, 73. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition, In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016.
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- COCO Common Objects in Context. Available online: https://cocodataset.org/ (accessed on 10 October 2022).
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2020, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Jiang, C.; Jiang, W. Efficient structure from motion for large-scale UAV images: A review and a comparison of SfM tools. ISPRS J. Photogramm. Remote. Sens. 2020, 167, 230–251. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Koletsis, E.; Cartwright, W.; Chrisman, N. Identifying approaches to usability evaluation. In Proceedings of the 2014 Geospatial Science Research Symposium, Melbourne, Australia, 2–3 December 2014. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Irmak, E.; Ertas, A.H. A review of robust image enhancement algorithms and their applications. In Proceedings of the 2016 IEEE Smart Energy Grid Engineering Conference, Oshawa, ON, Canada, 21–24 August 2016. [Google Scholar]
- Romero-Ramirez, F.J.; Muñoz-Salinas, R.; Medina-Carnicer, R. Speeded up detection of squared fiducial markers. Image Vis. Comput. 2018, 76, 38–47. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, C.; Fan, F.; Zhang, Y. Taikobot: A full-size and free-flying humanoid robot for intravehicular astronaut assistance and spacecraft housekeeping. Machines 2022, 10, 933. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Robotic Assistant | Navigation Method | Accuracy | Additional Devices | Dynamic Scene | Drawbacks |
|---|---|---|---|---|---|
| SPHERES [19] | radio-based | 0.5 cm/2.5° | ultrasonic beacons | yes | limited workspace |
| Astrobee [7] | map-based | 5~12 cm/1°~6° | not required | no | for static scene |
| Int-Ball [8] | marker-based | 2 cm/3° | marker | yes | limited field of view |
| CIMON [9] | vision-based | / | / | / | / |
| IFPS [10] | map-based | 1~2 cm/0.5° | not required | no | for static scene |
| Robonaut2 [12] | / | / | / | / | / |
| Skybot F-850 [13] | / | / | / | / | / |
| Proposed | map-based | 1~2 cm/0.5° | not required | yes | / |
| Detection Head | Grid System | Prior Bounding Boxes | Ratio | Predictions for Each Anchor |
|---|---|---|---|---|
| 1 | 40 × 40 | [100, 200] | 1/2 | ×3 |
| [200, 100] | 2/1 | |||
| [150, 150] | 1/1 | |||
| 2 | 20 × 20 | [200, 400] | 1/2 | ×3 |
| [400, 200] | 2/1 | |||
| [300, 300] | 1/1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Fan, L.; Zhang, Y. Simultaneous Astronaut Accompanying and Visual Navigation in Semi-Structured and Dynamic Intravehicular Environment. Drones 2022, 6, 397. https://doi.org/10.3390/drones6120397
Zhang Q, Fan L, Zhang Y. Simultaneous Astronaut Accompanying and Visual Navigation in Semi-Structured and Dynamic Intravehicular Environment. Drones. 2022; 6(12):397. https://doi.org/10.3390/drones6120397
Chicago/Turabian StyleZhang, Qi, Li Fan, and Yulin Zhang. 2022. "Simultaneous Astronaut Accompanying and Visual Navigation in Semi-Structured and Dynamic Intravehicular Environment" Drones 6, no. 12: 397. https://doi.org/10.3390/drones6120397
APA StyleZhang, Q., Fan, L., & Zhang, Y. (2022). Simultaneous Astronaut Accompanying and Visual Navigation in Semi-Structured and Dynamic Intravehicular Environment. Drones, 6(12), 397. https://doi.org/10.3390/drones6120397