

ARSD: An Adaptive Region Selection Object Detection Framework for UAV Images


 ,
,
Abstract
:1. Introduction
- (1)
- UAV image datasets often provide higher resolution images, but the objects in these images are always in low resolution. For example, the image size in general image datasets VOC2007/2012 and MS COCO is approximately 500 × 400 and 600 × 400, respectively. However, in the UAV image dataset VisDrone2021-DET [17], the image size is 2000 × 1500 while the object size is only about 50 × 50 pixels.
- (2)
- The size of the objects depends on the altitude at which the drone takes the image. The higher the drone is, the smaller the object is in the images [18].
- (3)
- The targets are not evenly distributed. Some regions in an image are plain backgrounds, while other regions are mostly occupied by objects.
- (1)
- An effective and efficient object detection framework is proposed to adaptively crop high-resolution UAV images according to object density based on clustering algorithms. This can significantly reduce the training and processing time of the UAV images.
- (2)
- This paper proposes the Self-adaptive Intensive Region Selecting Algorithm to select the object-dense region in UAV images. It reduces the number of sub-regions for further object detection. This enables the framework to be more suitable for the limited UAV hardware computing power.
- (3)
- This paper also proposes that an additional detection head is added to deal with the varying object sizes in UAV images. This helps the framework detect small objects more easily and increases detection accuracy.
2. Materials and Methods
2.1. Overall Region Detection Network (ORDN) and Key Region Detection Network (KRDN)
2.2. Self-Adaptive Intensive Region Selecting Algorithm (SIRSA)
2.2.1. Fixed Points Density-Based Clustering Algorithm (FPDCA)
| Algorithm 1: Fixed Points Density-based Clustering Algorithm |
| Input: N: number of sub-regions, Q: the set of bounding box centers, r: distance of algorithm, : threshold of the distance of vector. |
| Output: the set of sub-regions S |
| 1: for |
| 2: |
| 3: for |
| 4: |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: if |
| 10: break from line 3; |
| 11: end if |
| 12: end for |
| 13: end for |
| 14: if |
| 15: |
| 16: else |
| 17: |
| 18: end if |
2.2.2. Adaptive Sub-Regions Selection Algorithm (ASSA)
3. Results
3.1. Datasets and Evaluation Metrics
3.2. Model Scaling Scheme for Two-Stage Framework
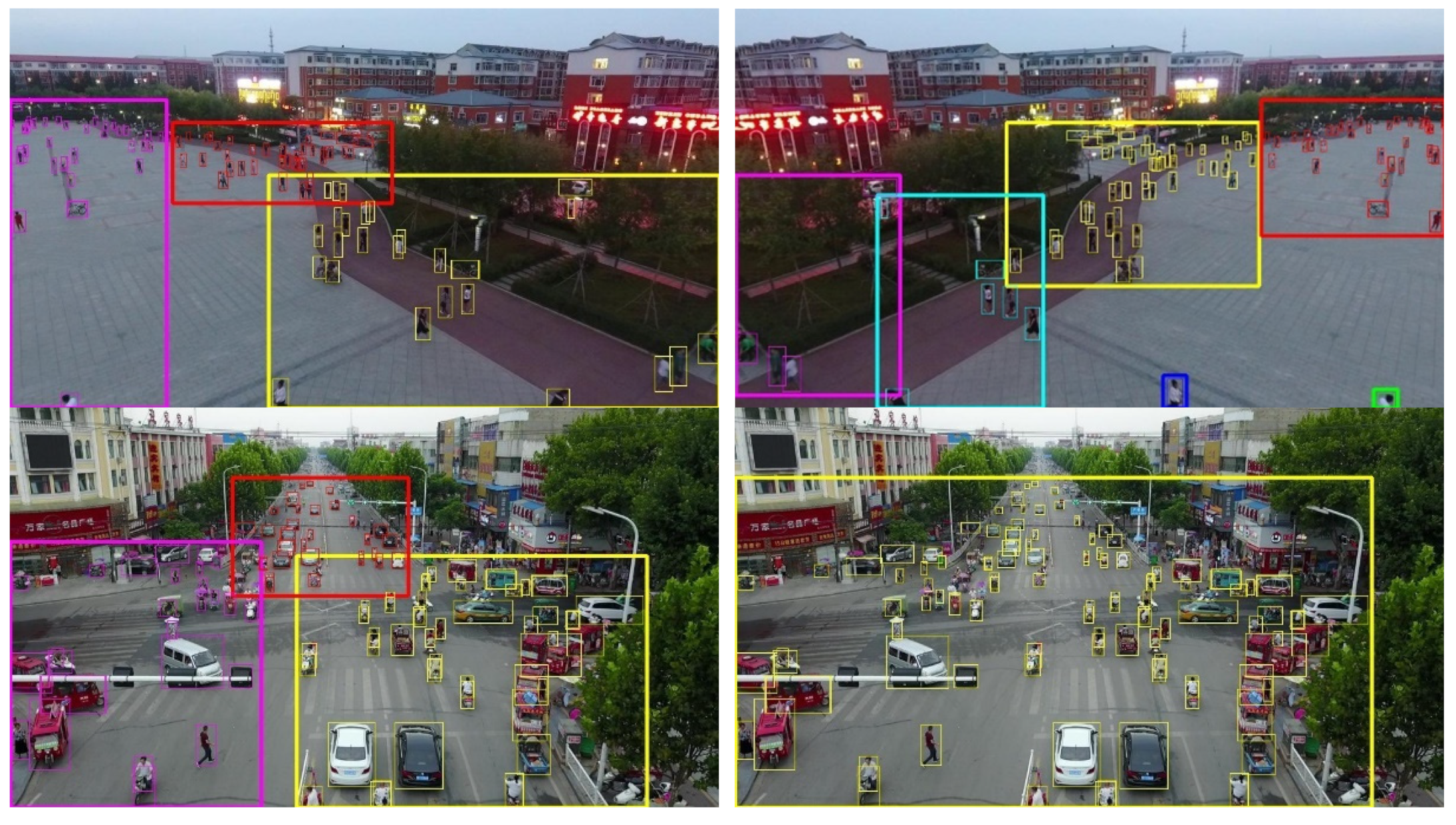
3.3. Qualitative Result
3.4. Quantitative Evaluation
3.5. Ablation Study
- (1)
- Effect of the large-scale and lightweight network. The results are from different scales YOLOv5n and YOLOv5m, trained on VisDrone2021-DET, as shown in Figure 6. Within the same computation time, YOLOv5n performs better than YOLOv5m. Therefore, we choose the large-scale YOLOv5n as the base model of ORDN.
- (2)
- Effect ofadditional prediction head. Though experiments show that adding a detection head for small-scale objects makes the GFLOPs increase from 48.1 to 59.1, the performance of an additional detection head is prominent. The experiment is to increase the size of the network to compare different accuracy under different time consumption. As shown in Figure 6, YOLOv5m-AH is YOLOv5m with an additional detection head. The mAP of the net with an additional detection head (blue line, YOLOv5m-AH) is 1.5% higher than without an additional head (green line, YOLOv5m) in the same processing time (3.0 ms). It not only saves the computing power of the hardware, but also improves the mAP considerably in each category.
- (3)
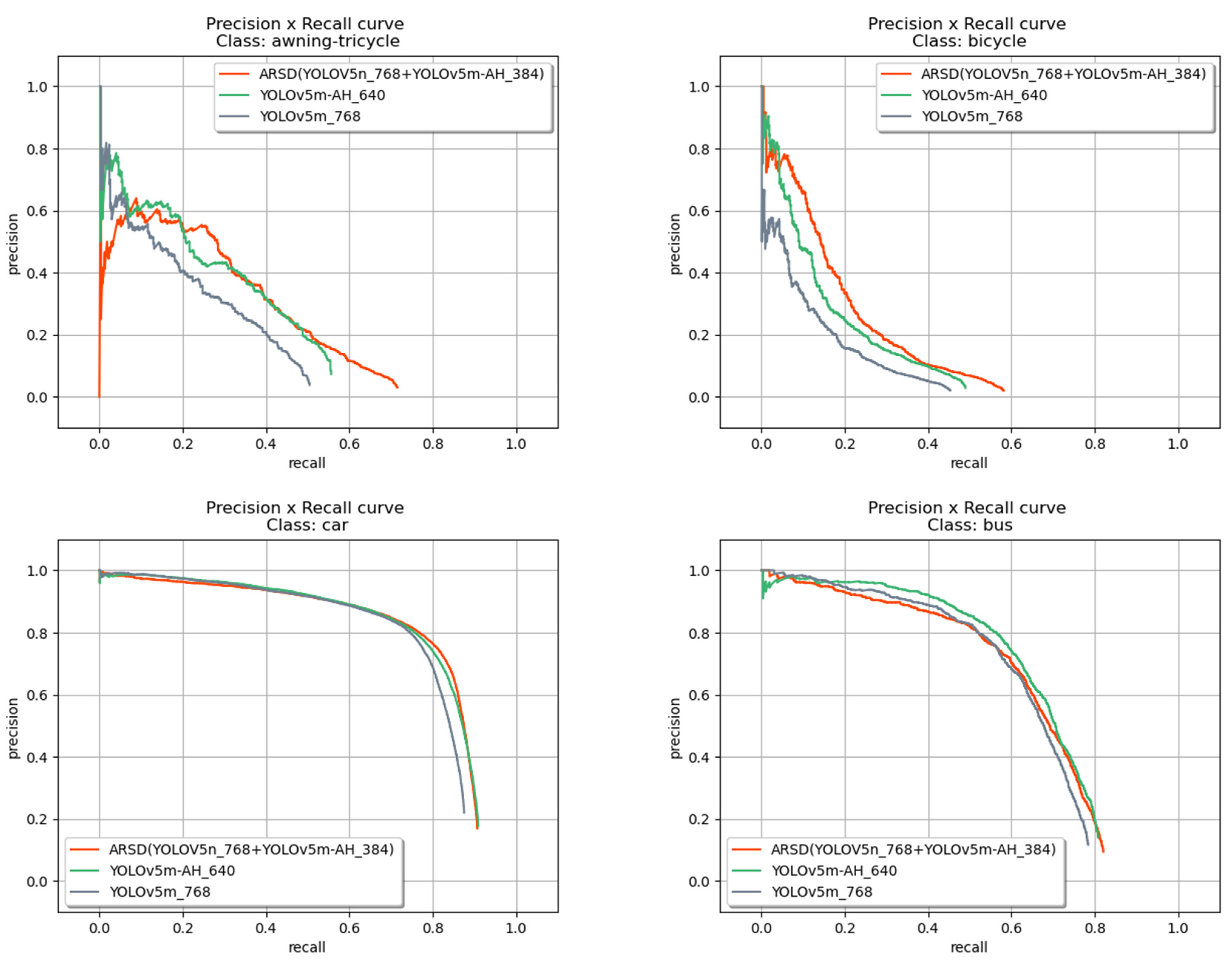
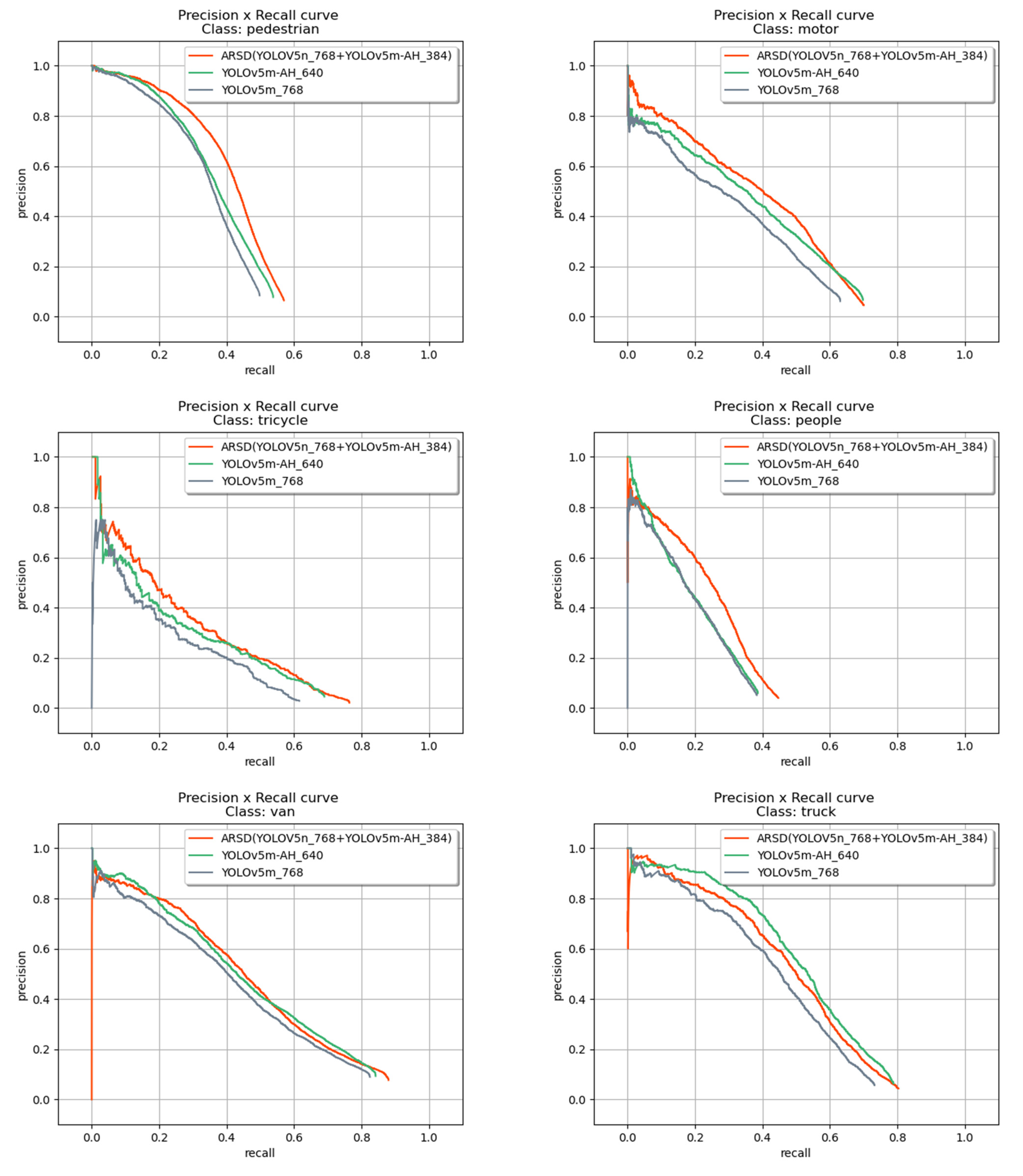
- Effect of two-stage structure. To demonstrate the effect of an additional detection head and two-stage framework, this paper chooses three networks with the same computation time: 768 × 768 YOLOv5m, 640 × 640 YOLOv5m-AH, and our two-stage framework (768 × 768 YOLOv5n + 384 × 384 YOLOv5m-AH). Based on the results shown in Figure 7, our two-stage framework is more accurate in small-scale categories such as Pedestrian, People, and Bicycle. However, results in large-scale categories such as bus and truck are not as good as the one-stage structure. The reason for this phenomenon is that the increase is caused by the additional small object true positives predicted from sub-regions and the decrease is caused by the false positives predicted from sub-regions that match large ground truth boxes.
- (4)
- Effect of FPDCA. The proposed method performs well on clustering, as indicated by Figure 5. In addition, as shown by lines 1, 2, and 6 in Table 3, when using FPDCA as the SIRSA basic cluster method, the result outperforms K-means and Mean-Shift by 0.7% and 1.2%, respectively, in AP50. This shows that it is useful to consider density information when obtaining clusters. The object detection accuracy indicated by AP and AP50 increases as the number of clusters increases from 2 to 4. However, the gain is subtle while the computational complexity also increases. For example, lines 6 and 9 in Table 3 show that AP and AP50 only improves by 0.97% and 0.6%, respectively, when the number of clusters increases from 3 to 4.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hird, J.N.; Montaghi, A.; McDermid, G.J.; Kariyeva, J.; Moorman, B.J.; Nielsen, S.E.; McIntosh, A.C.S. Use of Unmanned Aerial Vehicles for Monitoring Recovery of Forest Vegetation on Petroleum Well Sites. Remote Sens. 2017, 9, 413. [Google Scholar] [CrossRef]
- Shao, Z.; Li, C.; Li, D.; Altan, O.; Zhang, L.; Ding, L. An Accurate Matching Method for Projecting Vector Data Into Surveillance Video To Monitor And Protect Cultivated Land. ISPRS Int. J. Geo-Inf. 2020, 9, 448. [Google Scholar] [CrossRef]
- Shen, Q.; Jiang, L.; Xiong, H. Person Tracking and Frontal Face Capture with UAV. In Proceedings of the IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018; pp. 1412–1416. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond Rgb: Very High Resolution Urban Remote Sensing with Multimodal Deep Networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Yuan, Z.; Jin, J.; Chen, J.; Sun, L.; Muntean, G.M. ComProSe: Shaping Future Public Safety Communities with ProSe-based UAVs. IEEE Commun. Mag. 2017, 55, 165–171. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Heravi, A.; Thaheem, M.J.; Maqsoom, A. Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages. Drones 2021, 6, 5. [Google Scholar] [CrossRef]
- Kundid Vasić, M.; Papić, V. Improving the Model for Person Detection in Aerial Image Sequences Using the Displacement Vector: A Search and Rescue Scenario. Drones 2022, 6, 19. [Google Scholar] [CrossRef]
- Reckling, W.; Mitasova, H.; Wegmann, K.; Kauffman, G.; Reid, R. Efficient Drone-Based Rare Plant Monitoring Using a Species Distribution Model and AI-Based Object Detection. Drones 2021, 5, 110. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal Speed And Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Kalra, I.; Singh, M.; Nagpal, S.; Singh, R.; Vatsa, M.; Sujit, P.B. Dronesurf: Benchmark Dataset for Drone-Based Face Recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (Fg 2019), Lille, France, 14–18 May 2019; pp. 1–7. [Google Scholar]
- Glenn, J. Yolov5 Release v6.1. 2022, 2, 7, 10. Available online: https://github.com/ultralytics/yolov5/releases/tag/v6.1 (accessed on 25 August 2022).
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. Tph-Yolov5: Improved Yolov5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference And Fine-Tuning for Small Object Detection. arXiv 2022, arXiv:2202.06934. [Google Scholar]
- Zhang, J.; Huang, J.; Chen, X.; Zhang, D. How To Fully Exploit the Abilities of Aerial Image Detectors. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted Boxes Fusion: Ensembling Boxes From Different Object Detection Models. Image Vis. Comput. 2021, 107, 104117. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm as 136: A k-Means Clustering Algorithm. J. R. Stat. Society. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach Toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, Y.; Zhao, X. Object Detection Using Clustering Algorithm Adaptive Searching Regions In Aerial Images. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 651–664. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; Da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A Global-Local Self-Adaptive Network for Drone-View Object Detection. IEEE Trans. Image Process. 2020, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Zhong, Y.; Li, X. Slimyolov3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8311–8320. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 190–191. [Google Scholar]
- Liao, J.; Piao, Y.; Su, J.; Cai, G.; Huang, X.; Chen, L.; Huang, Z.; Wu, Y. Unsupervised Cluster Guided Object Detection in Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11204–11216. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pedestrian | People | Bicycle | Car | Van | Truck | Tricycle | Awning-Tricycle | Bus | Motor | Average AP50 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOV3 | 18.1 | 9.9 | 2 | 56.6 | 17.5 | 17.6 | 6.7 | 2.9 | 32.4 | 17 | 17.1 |
| SlimYOLOv3 [31] | 17.4 | 9.3 | 2.4 | 55.7 | 18.3 | 16.9 | 9.1 | 3 | 26.9 | 17 | 17.6 |
| Faster-RCNN | 21.7 | 12.7 | 11.5 | 63.2 | 37.8 | 29.9 | 22.5 | 12.3 | 50.6 | 28.4 | 29.1 |
| FPN | 33 | 25.8 | 13.9 | 69.4 | 40 | 34.3 | 27.4 | 13.4 | 49.1 | 37.6 | 35.6 |
| YOLOv5m | 45.2 | 35.7 | 13.7 | 77.8 | 41 | 37.9 | 20.7 | 10.8 | 50.9 | 30.1 | 36.8 |
| YOLOv5l-TPH | 53.5 | 29.7 | 25.9 | 87 | 55.3 | 61.5 | 34.9 | 31.2 | 73.5 | 50.6 | 50.3 |
| ARSD | 68.8 | 56.8 | 40.68 | 88.17 | 61.53 | 53.74 | 49 | 26.19 | 72.78 | 61.3 | 57.9 |
| Method | AP | AP50 | AP75 | AP↗ | AP50↗ | AP75↗ |
|---|---|---|---|---|---|---|
| ClusDet [32] | 26.7 | 50.6 | 24.7 | 8.34 | 7.3 | 11.91 |
| DMNet [33] | 28.2 | 47.6 | 28.9 | 6.84 | 10.3 | 7.71 |
| UCGNet [34] | 32.8 | 53.1 | 33.9 | 2.24 | 4.8 | 2.71 |
| GLASN [31] | 32.5 | 55.8 | 33 | 2.54 | 2.1 | 3.61 |
| ARSD | 35.04 | 57.9 | 36.61 | - | - | - |
| Methods | Cluster Methods | Number of Clusters | Candidate Sub-Regions | Remaining Sub-Regions | AP | AP50 | |
|---|---|---|---|---|---|---|---|
| 1 | K-means | K-means | 3 | 4830 | 4830 | 22.64 | 40.6 |
| 2 | DNSCAN | Mean-Shift | - | 5559 | 5559 | 22.31 | 40.1 |
| 3 | ARSD | FPDCA | 2 | 3220 | 3220 (0) | 20.59 | 37.76 |
| 4 | ARSD | FPDCA | 2 | 3220 | 2146 (1/3) | 19.16 | 35.63 |
| 5 | ARSD | FPDCA | 2 | 3220 | 1610 (1/2) | 18.33 | 33.4 |
| 6 | ARSD | FPDCA | 3 | 4830 | 4830 (0) | 22.93 | 41.31 |
| 7 | ARSD | FPDCA | 3 | 4830 | 3220 (1/3) | 21.6 | 39.6 |
| 8 | ARSD | FPDCA | 3 | 4830 | 2415 (1/2) | 20.05 | 37.1 |
| 9 | ARSD | FPDCA | 4 | 6440 | 6440 (0) | 23.9 | 41.92 |
| 10 | ARSD | FPDCA | 4 | 6440 | 4293 (1/3) | 22.32 | 40.15 |
| 11 | ARSD | FPDCA | 4 | 6440 | 3220 (1/2) | 21.12 | 37.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, Y.; Zhong, Y.; Huang, Y.; Han, Y.; Cui, Y.; Yang, Q.; Li, Z.; Yuan, Z.; Li, Q. ARSD: An Adaptive Region Selection Object Detection Framework for UAV Images. Drones 2022, 6, 228. https://doi.org/10.3390/drones6090228
Wan Y, Zhong Y, Huang Y, Han Y, Cui Y, Yang Q, Li Z, Yuan Z, Li Q. ARSD: An Adaptive Region Selection Object Detection Framework for UAV Images. Drones. 2022; 6(9):228. https://doi.org/10.3390/drones6090228
Chicago/Turabian StyleWan, Yuzhuang, Yi Zhong, Yan Huang, Yi Han, Yongqiang Cui, Qi Yang, Zhuo Li, Zhenhui Yuan, and Qing Li. 2022. "ARSD: An Adaptive Region Selection Object Detection Framework for UAV Images" Drones 6, no. 9: 228. https://doi.org/10.3390/drones6090228
APA StyleWan, Y., Zhong, Y., Huang, Y., Han, Y., Cui, Y., Yang, Q., Li, Z., Yuan, Z., & Li, Q. (2022). ARSD: An Adaptive Region Selection Object Detection Framework for UAV Images. Drones, 6(9), 228. https://doi.org/10.3390/drones6090228