



Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method


Abstract
:1. Introduction
2. Background
2.1. Problem Description
- I is a set of N agents.
- S is a set of states of the environment, and is the initial state.
- is a set of actions for the agents. It is an action tuple .
- T is the state transition probability function .
- R is the reward when agents take actions in state S, it depends on all the agents.
- is a set of observations for the agents.
- O is a table of the observation probabilities, where is the probability that are observed by all the agents, respectively.
- h is the maximum number of steps in an episode which is called “horizon”.
2.2. Actor–Critic Algorithm
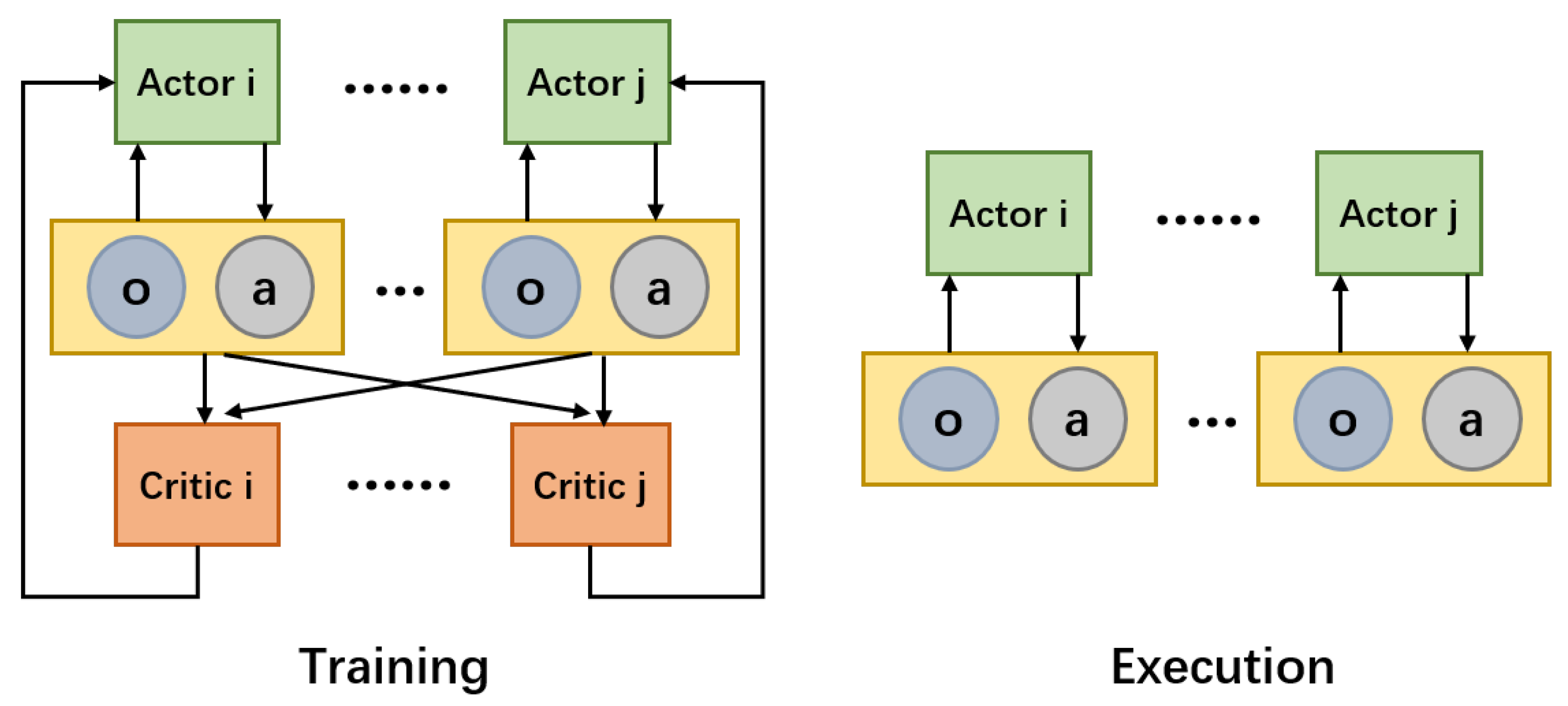
2.3. Centralized Training and Decentralized Execution Architecture
3. Methodology
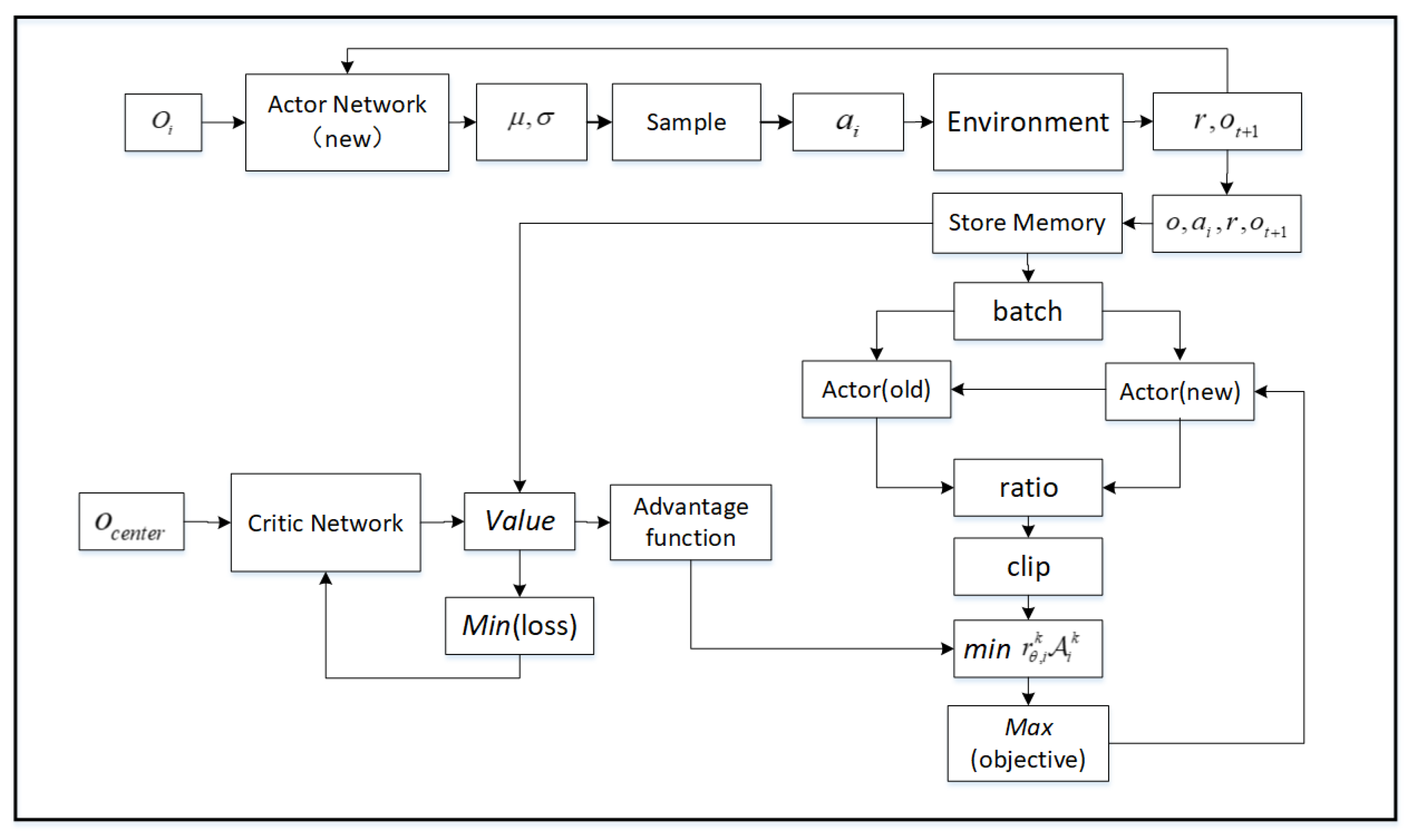
3.1. Proximal Policy Optimization with CTDE
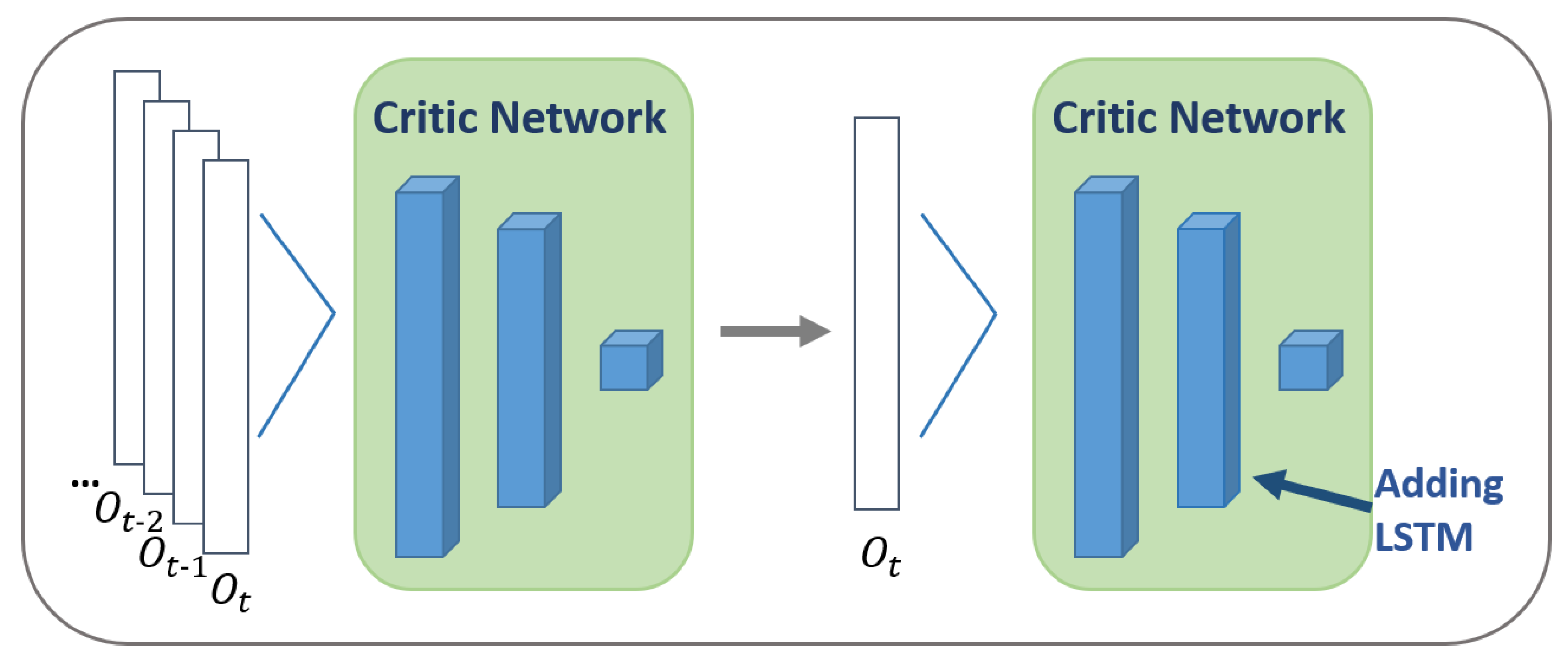
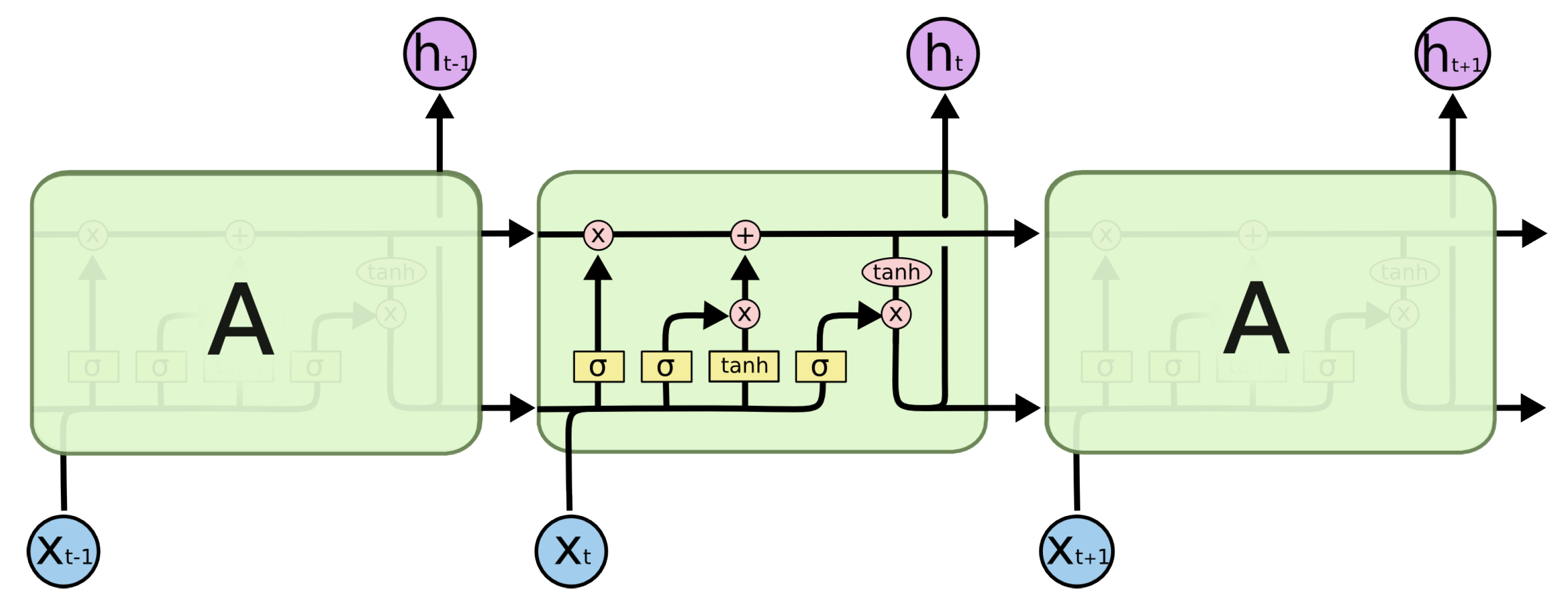
3.2. Adding RNN Layer for Incomplete Information
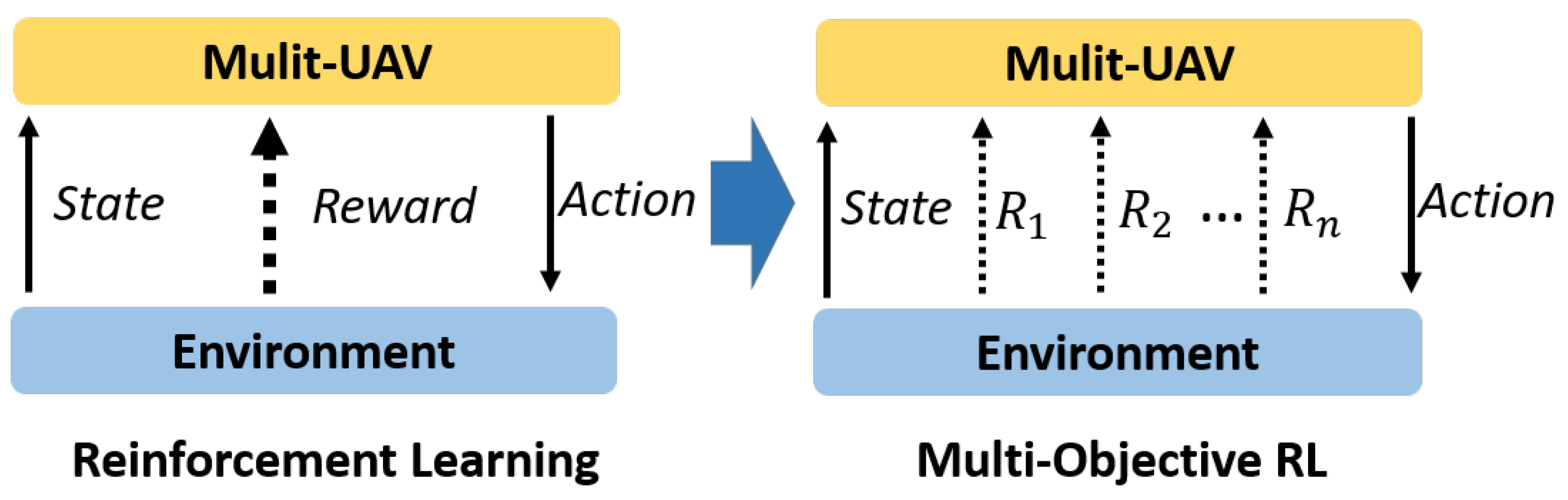
3.3. Multi-Objective Joint Optimization
4. Experiment
4.1. Experimental Setup
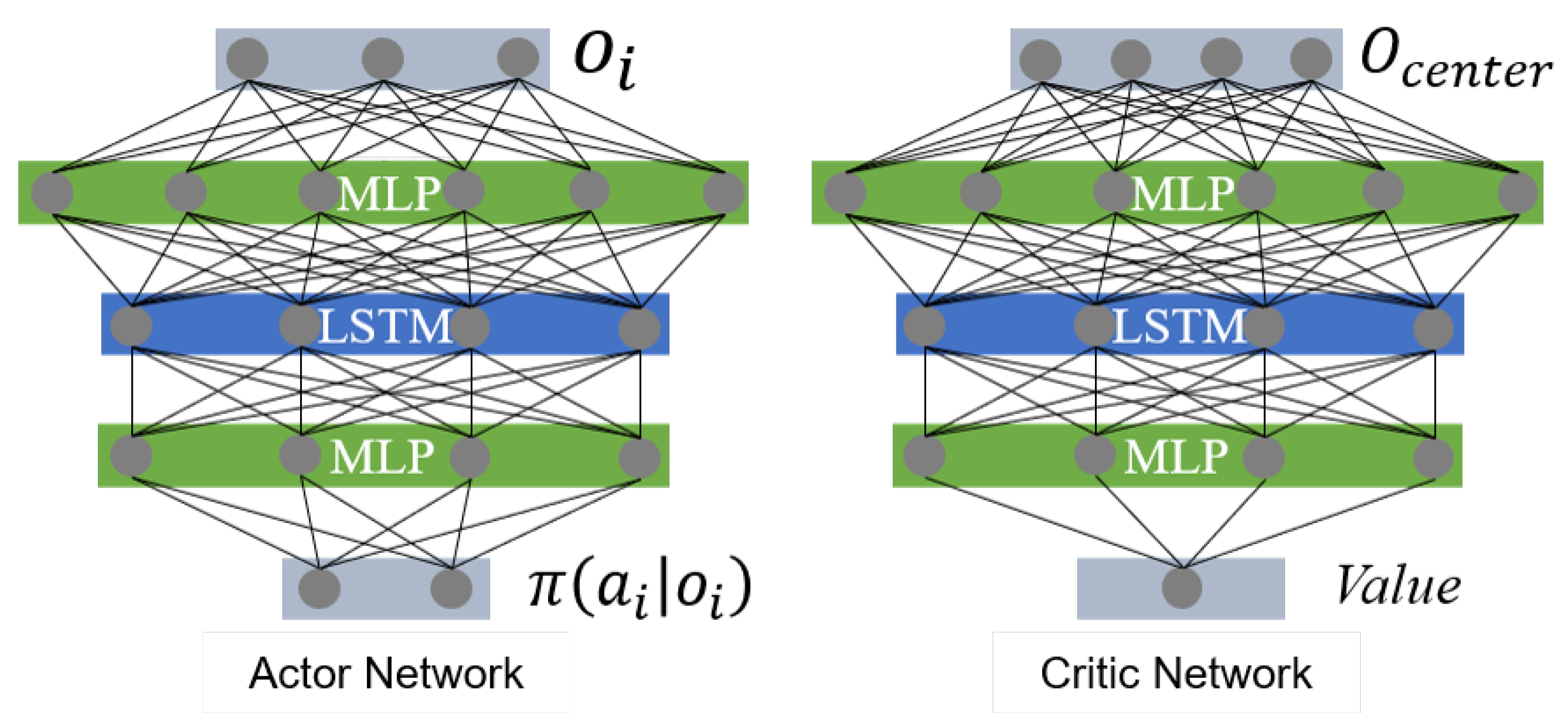
4.2. Network Architecture
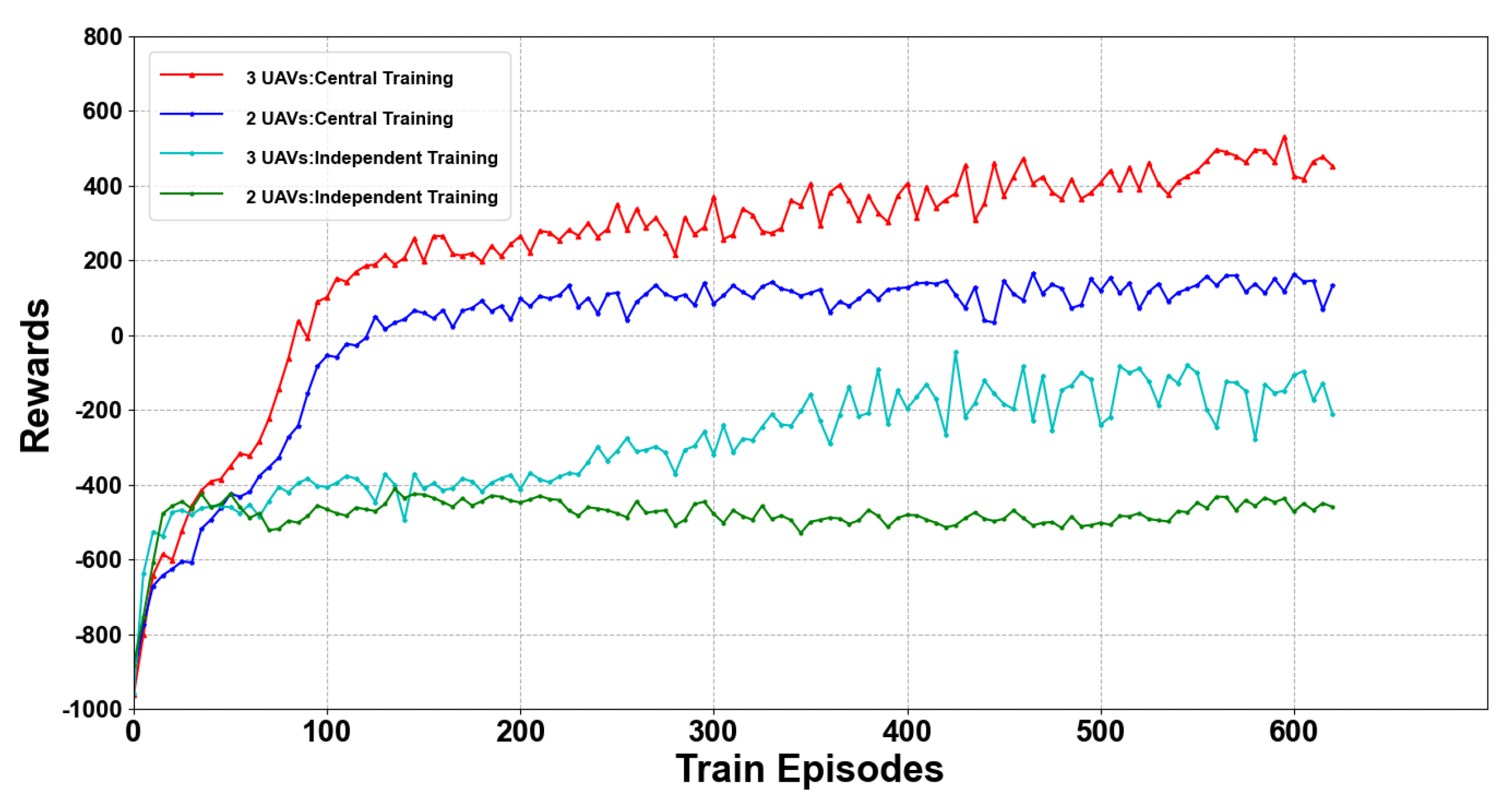
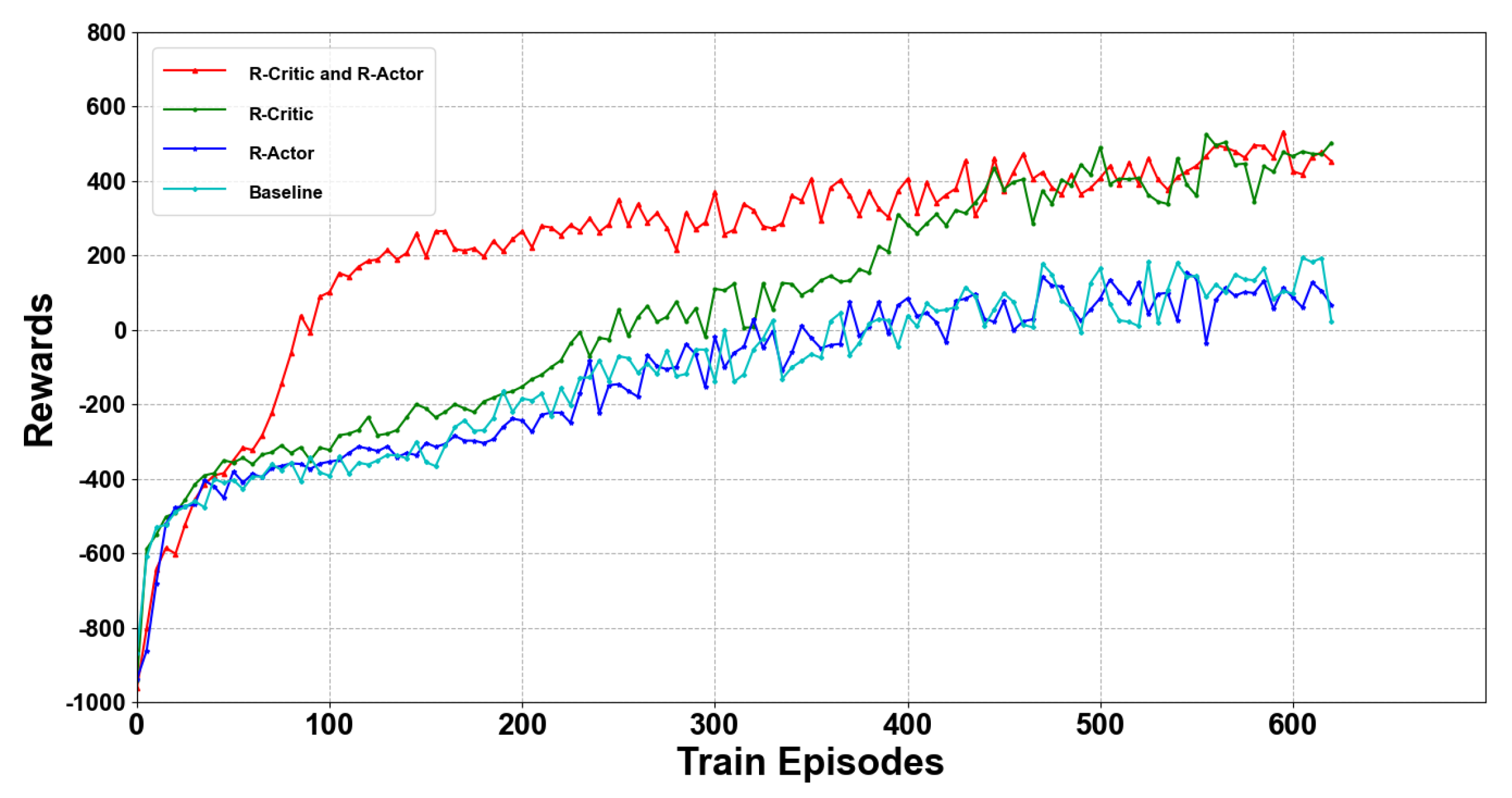
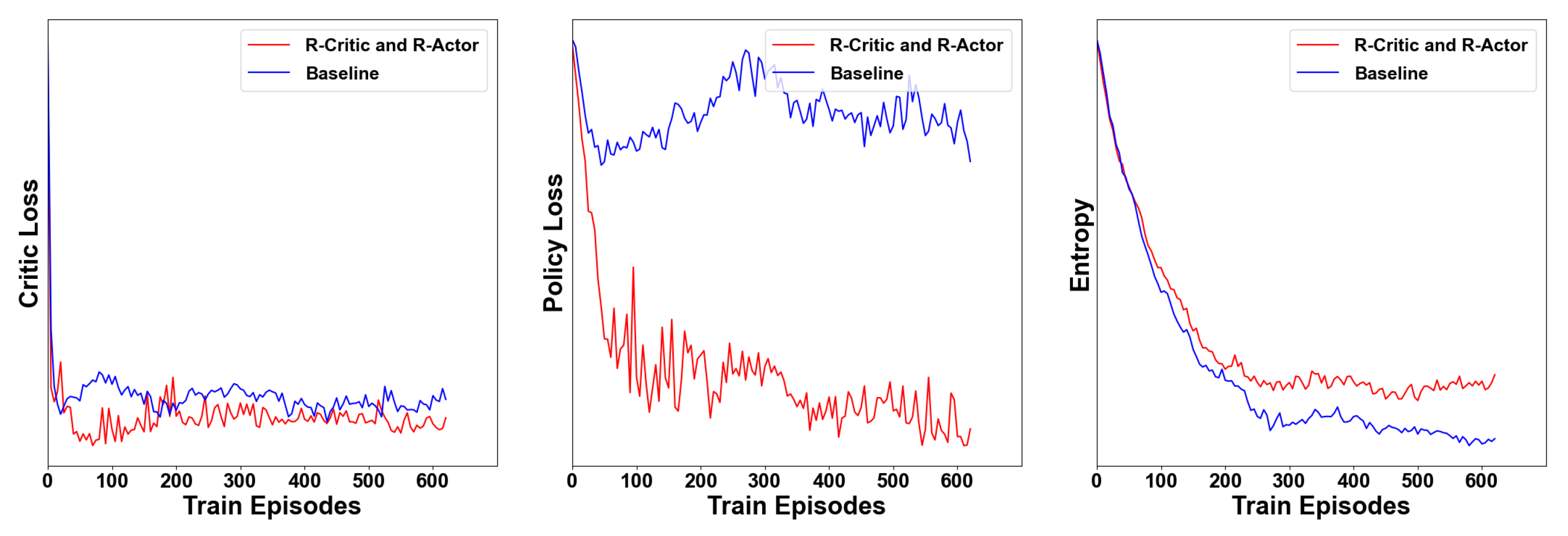
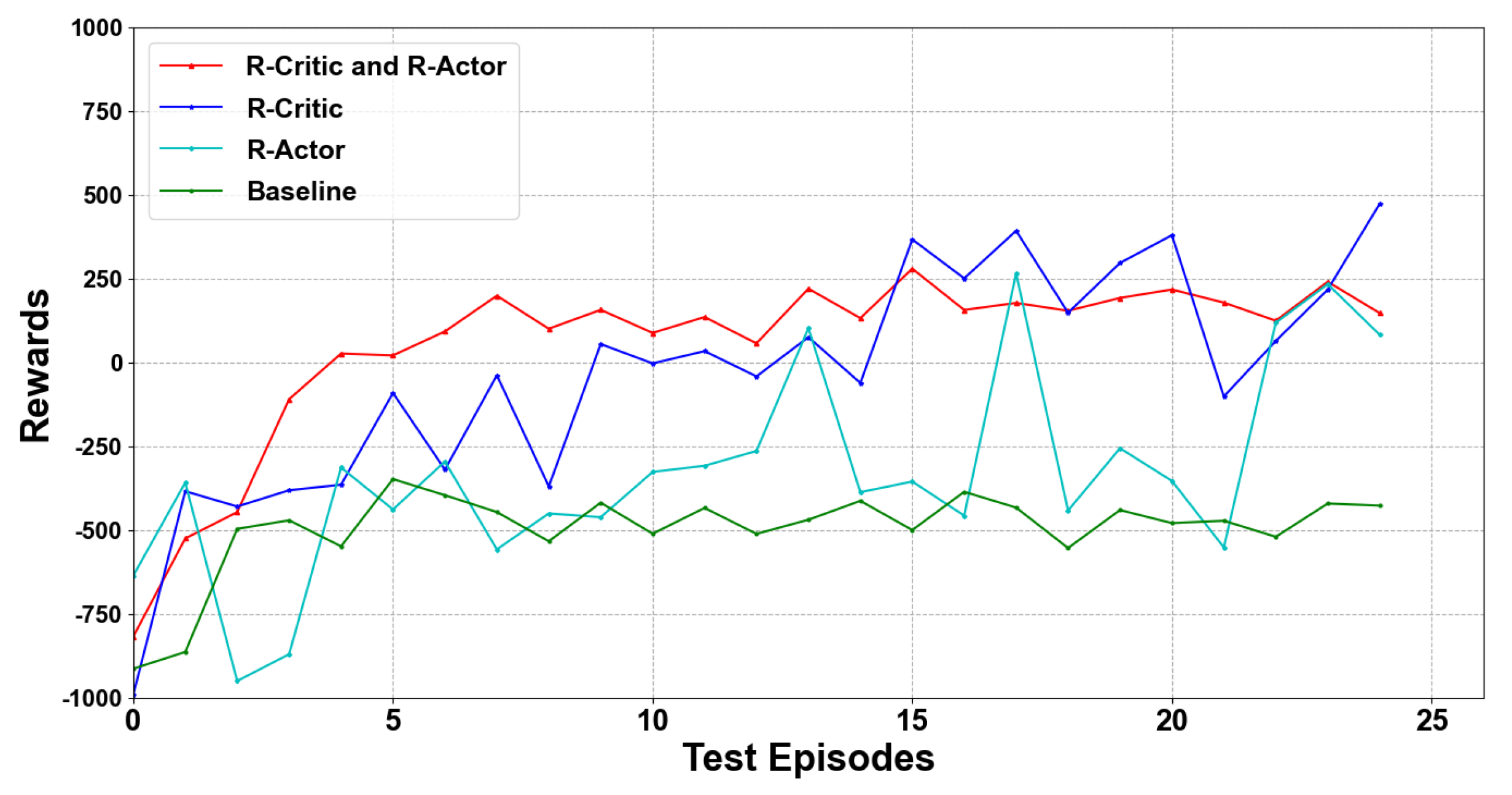
4.3. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohiuddin, A.; Tarek, T.; Zweiri, Y.; Gan, D. A survey of single and multi-UAV aerial manipulation. Unmanned Syst. 2020, 8, 119–147. [Google Scholar] [CrossRef]
- Stern, R. Multi-agent path finding–An overview. In Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2019; pp. 96–115. [Google Scholar]
- Ma, H.; Wagner, G.; Felner, A.; Li, J.; Kumar, T.; Koenig, S. Multi-agent path finding with deadlines. arXiv 2018, arXiv:1806.04216. [Google Scholar]
- Ngatchou, P.; Zarei, A.; El-Sharkawi, A. Pareto multi objective optimization. In Proceedings of the 13th International Conference on, Intelligent Systems Application to Power Systems, Arlington, VA, USA, 6–10 November 2005; pp. 84–91. [Google Scholar]
- Konak, A.; Coit, D.W.; Smith, A.E. Multi-objective optimization using genetic algorithms: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 992–1007. [Google Scholar] [CrossRef]
- Tang, J.; Duan, H.; Lao, S. Swarm intelligence algorithms for multiple unmanned aerial vehicles collaboration: A comprehensive review. In Artificial Intelligence Review; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–33. [Google Scholar]
- Wang, Y.; Bai, P.; Liang, X.; Wang, W.; Zhang, J.; Fu, Q. Reconnaissance mission conducted by UAV swarms based on distributed PSO path planning algorithms. IEEE Access 2019, 7, 105086–105099. [Google Scholar] [CrossRef]
- Wan, Y.; Zhong, Y.; Ma, A.; Zhang, L. An Accurate UAV 3-D Path Planning Method for Disaster Emergency Response Based on an Improved Multiobjective Swarm Intelligence Algorithm. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef] [PubMed]
- Shao, S.; Peng, Y.; He, C.; Du, Y. Efficient path planning for UAV formation via comprehensively improved particle swarm optimization. ISA Trans. 2020, 97, 415–430. [Google Scholar] [CrossRef] [PubMed]
- Krell, E.; Sheta, A.; Balasubramanian, A.P.R.; King, S.A. Collision-free autonomous robot navigation in unknown environments utilizing PSO for path planning. J. Artif. Intell. Soft Comput. Res. 2019, 9, 267–282. [Google Scholar] [CrossRef] [Green Version]
- Ajeil, F.H.; Ibraheem, I.K.; Sahib, M.A.; Humaidi, A.J. Multi-objective path planning of an autonomous mobile robot using hybrid PSO-MFB optimization algorithm. Appl. Soft Comput. 2020, 89, 106076. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Luo, W.; Tang, Q.; Fu, C.; Eberhard, P. Deep-sarsa based multi-UAV path planning and obstacle avoidance in a dynamic environment. In Proceedings of the International Conference on Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2018; pp. 102–111. [Google Scholar]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed energy-efficient multi-UAV navigation for long-term communication coverage by deep reinforcement learning. IEEE Trans. Mob. Comput. 2019, 19, 1274–1285. [Google Scholar] [CrossRef]
- Bayerlein, H.; Theile, M.; Caccamo, M.; Gesbert, D. Multi-UAV path planning for wireless data harvesting with deep reinforcement learning. IEEE Open J. Commun. Soc. 2021, 2, 1171–1187. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Vera, J.M.; Abad, A.G. Deep reinforcement learning for routing a heterogeneous fleet of vehicles. In Proceedings of the 2019 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019; pp. 1–6. [Google Scholar]
- Brittain, M.; Wei, P. Autonomous separation assurance in an high-density en route sector: A deep multi-agent reinforcement learning approach. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, NZ, USA, 27–30 October 2019; pp. 3256–3262. [Google Scholar]
- Wang, Z.; Yao, H.; Mai, T.; Xiong, Z.; Yu, F.R. Cooperative Reinforcement Learning Aided Dynamic Routing in UAV Swarm Networks. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 1–6. [Google Scholar]
- Ibarz, B.; Leike, J.; Pohlen, T.; Irving, G.; Legg, S.; Amodei, D. Reward learning from human preferences and demonstrations in atari. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Li, K.; Zhang, T.; Wang, R. Deep reinforcement learning for multiobjective optimization. IEEE Trans. Cybern. 2020, 51, 3103–3114. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Tian, Y.; Ma, P.; Rus, D.; Sueda, S.; Matusik, W. Prediction-guided multi-objective reinforcement learning for continuous robot control. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 10607–10616. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Amato, C.; Konidaris, G.; Cruz, G.; Maynor, C.A.; How, J.P.; Kaelbling, L.P. Planning for decentralized control of multiple robots under uncertainty. In Proceedings of the 2015 IEEE International Conference On Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2015; pp. 1241–1248. [Google Scholar]
- Bernstein, D.S.; Givan, R.; Immerman, N.; Zilberstein, S. The complexity of decentralized control of Markov decision processes. Math. Oper. Res. 2002, 27, 819–840. [Google Scholar] [CrossRef]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; Volume 12. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. In Proceedings of the 2015 AAAI Fall Symposium Series, Arlington, VA, USA, 12–14 November 2015. [Google Scholar]
- Krichen, M.; Adoni, W.Y.H.; Mihoub, A.; Alzahrani, M.Y.; Nahhal, T. Security Challenges for Drone Communications: Possible Threats, Attacks and Countermeasures. In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 184–189. [Google Scholar]
- Alrayes, F.S.; Alotaibi, S.S.; Alissa, K.A.; Maashi, M.; Alhogail, A.; Alotaibi, N.; Mohsen, H.; Motwakel, A. Artificial Intelligence-Based Secure Communication and Classification for Drone-Enabled Emergency Monitoring Systems. Drones 2022, 6, 222. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Episode | Episode length | Rollout thread | Clip | Discount | Entropy coefficient |
|---|---|---|---|---|---|
| 625 | 200 | 16 | 0.2 | 0.99 | 0.1 |
| Buffer size | Batch size | FC layer dim | RNN hidden dim | Activation | Optimizer |
| 500 | 32 | 128 | 64 | Relu | Adam |
| Time Cost | Coverage | Success Rate | Reference Speed | |
|---|---|---|---|---|
| Our method | 92 | 57.9% | 92.7% | 0.126 s |
| RL baseline | 93 | 54.5% | 90.1% | 0.115 s |
| DPSO | 97 | 41.2% | 65.2% | 1.35 s |
| GAPSO | 95 | 43.7% | 62.1% | 1.16 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Dong, Q.; Shang, X.; Wu, Z.; Wang, J. Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method. Drones 2023, 7, 10. https://doi.org/10.3390/drones7010010
Chen Y, Dong Q, Shang X, Wu Z, Wang J. Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method. Drones. 2023; 7(1):10. https://doi.org/10.3390/drones7010010
Chicago/Turabian StyleChen, Yu, Qi Dong, Xiaozhou Shang, Zhenyu Wu, and Jinyu Wang. 2023. "Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method" Drones 7, no. 1: 10. https://doi.org/10.3390/drones7010010
APA StyleChen, Y., Dong, Q., Shang, X., Wu, Z., & Wang, J. (2023). Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method. Drones, 7(1), 10. https://doi.org/10.3390/drones7010010