
Image-to-Image Translation-Based Structural Damage Data Augmentation for Infrastructure Inspection Using Unmanned Aerial Vehicle


Abstract
:1. Introduction
2. Related Works
2.1. Generation of Structural Damage Images
2.2. Data Augmentation
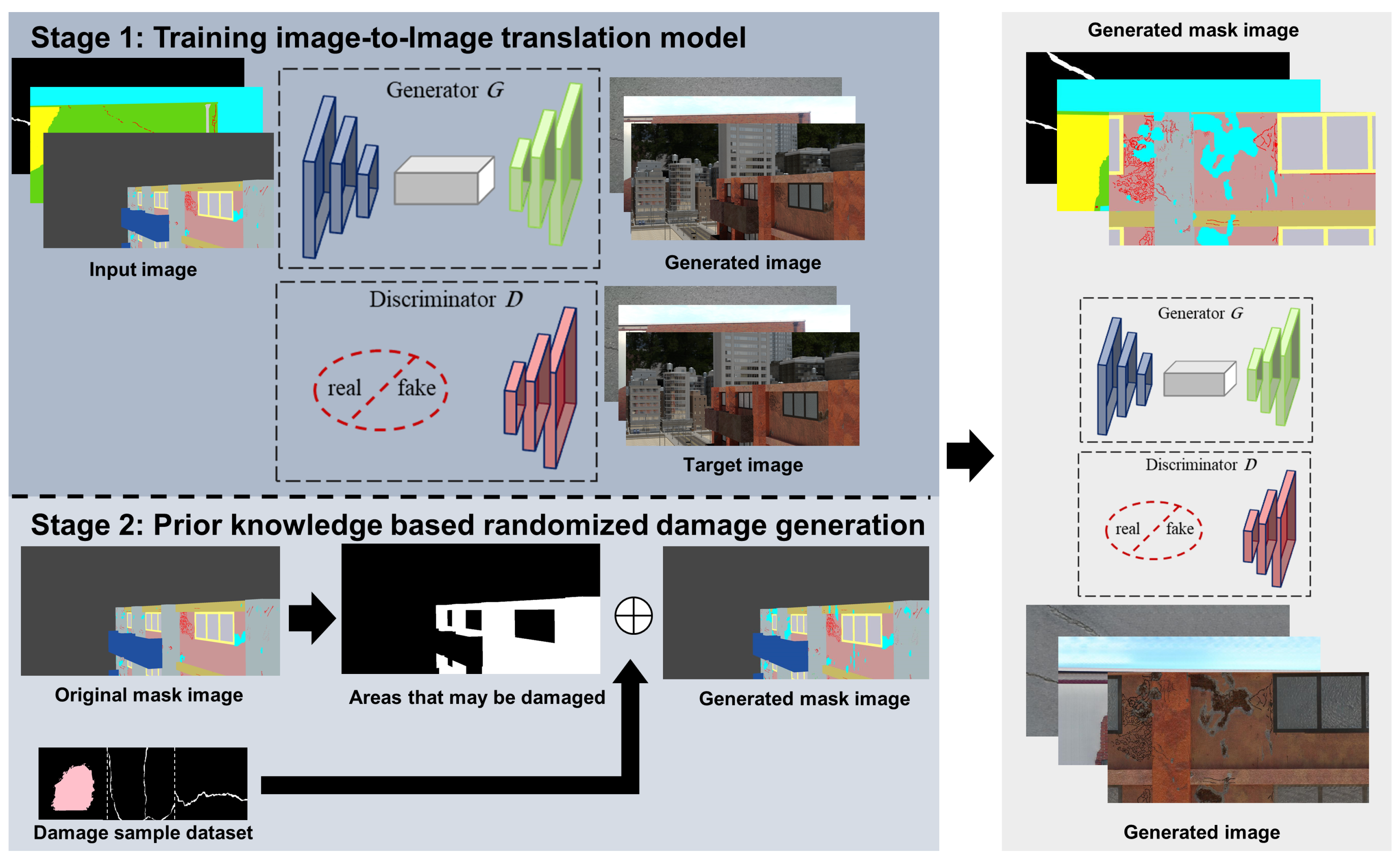
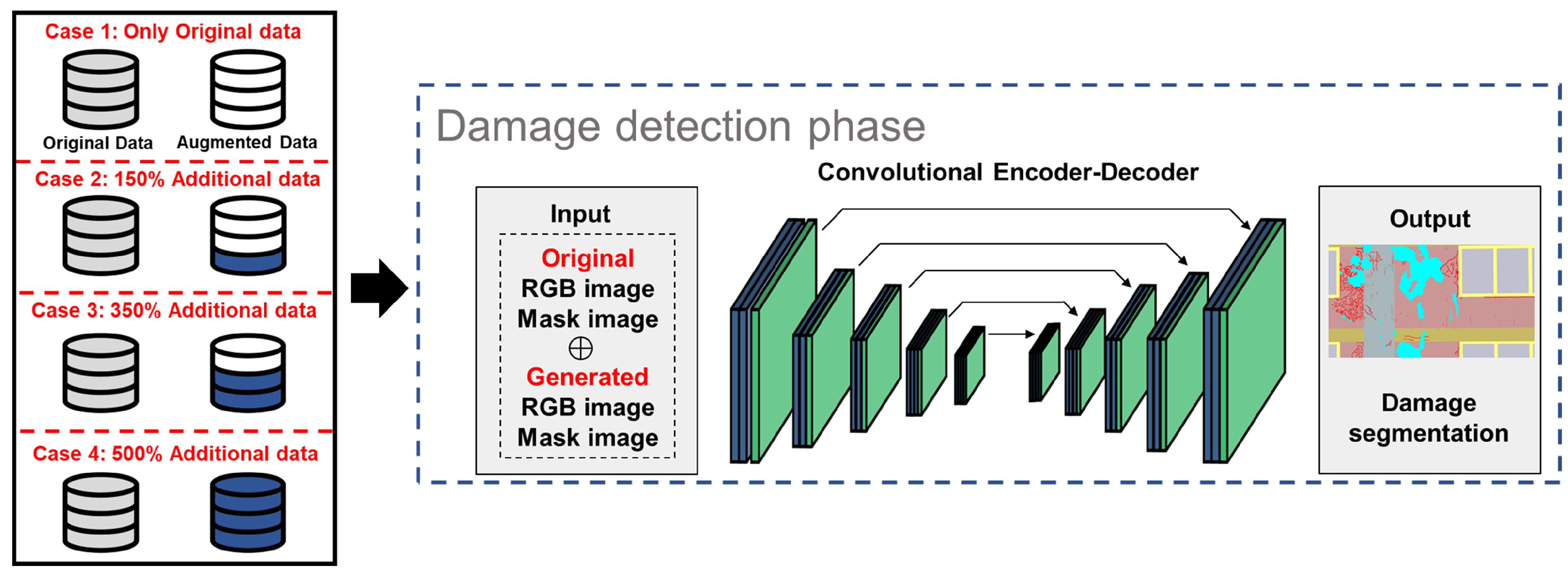
3. Proposed Methodology
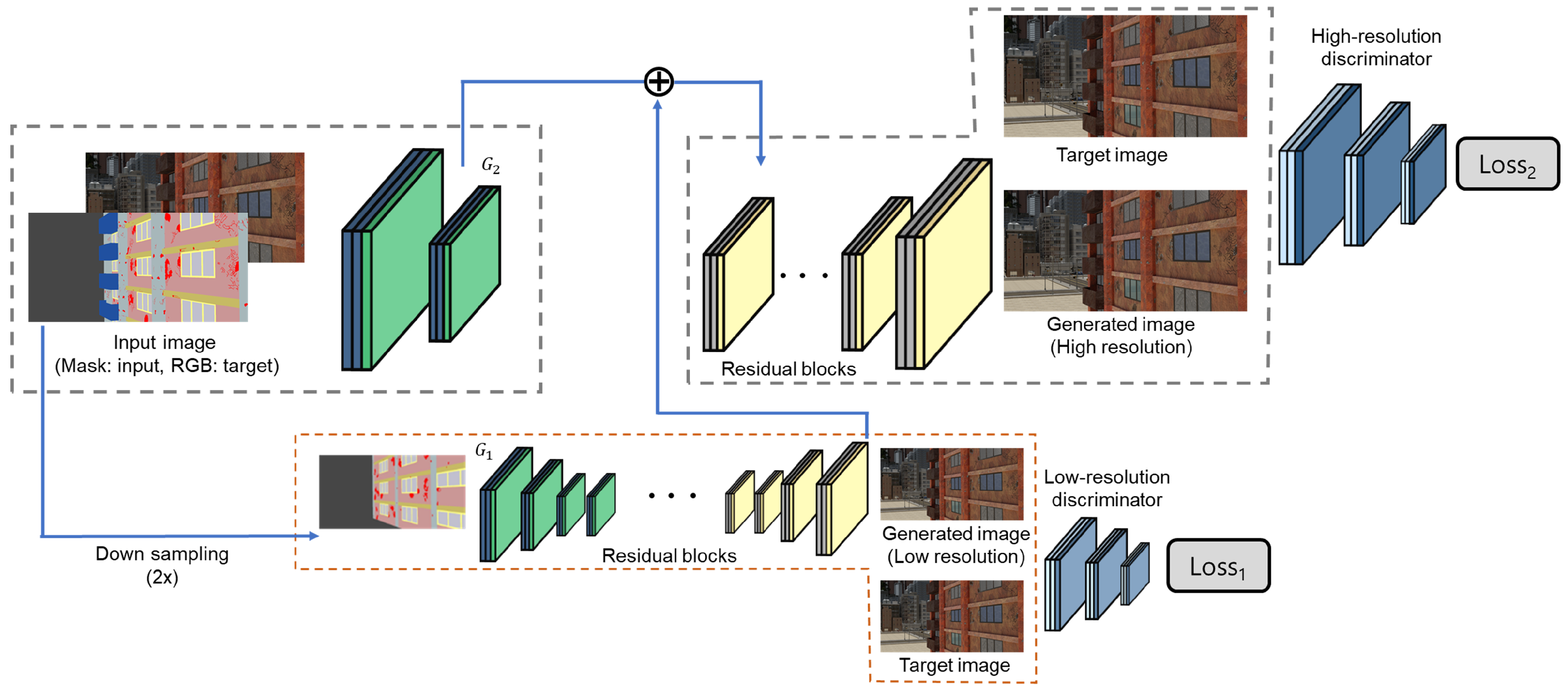
3.1. Stage 1: Image-to-Image Translation Model for Structural Damage Image Augmentation
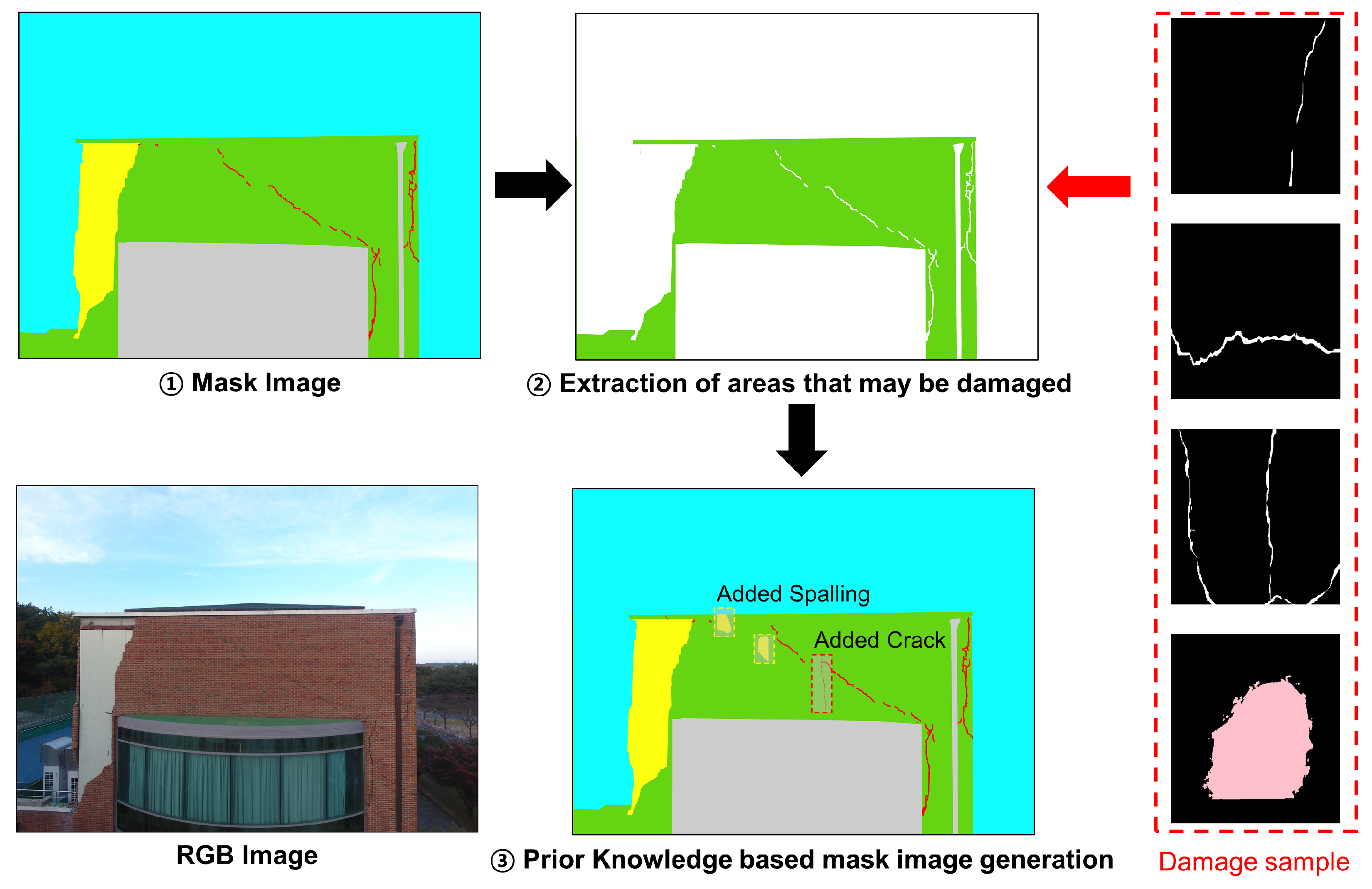
3.2. Stage 2: Prior-Knowledge-Based Randomized Damage Generation
4. Experiments
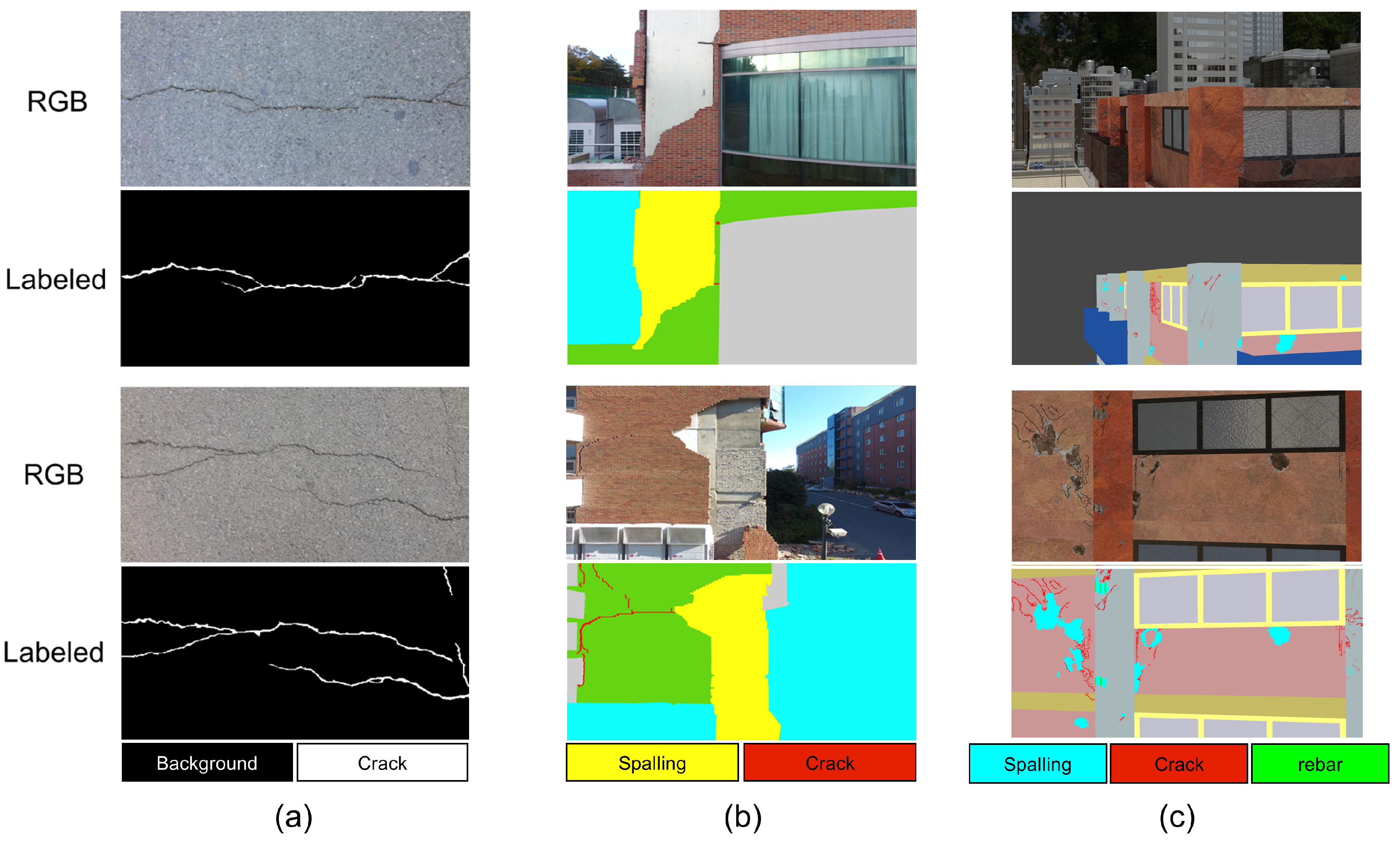
4.1. Datasets
4.1.1. Dataset 1: Public Crack Images
4.1.2. Dataset 2: Post-Earthquake Damaged Brick Cladding Structure
4.1.3. Dataset 3: Post-Earthquake Structure in a Synthetic Environment
4.2. Data Augmentation Results
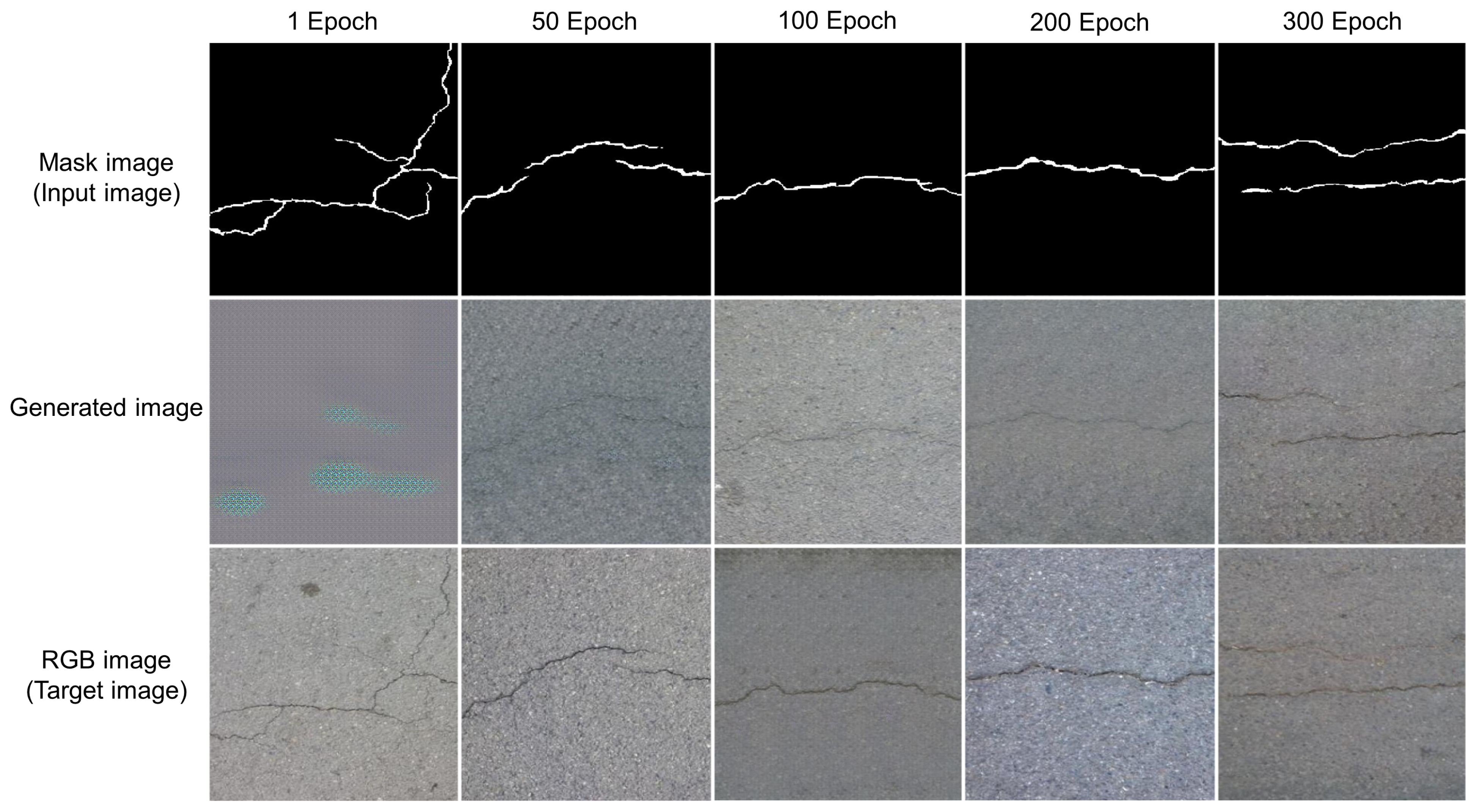
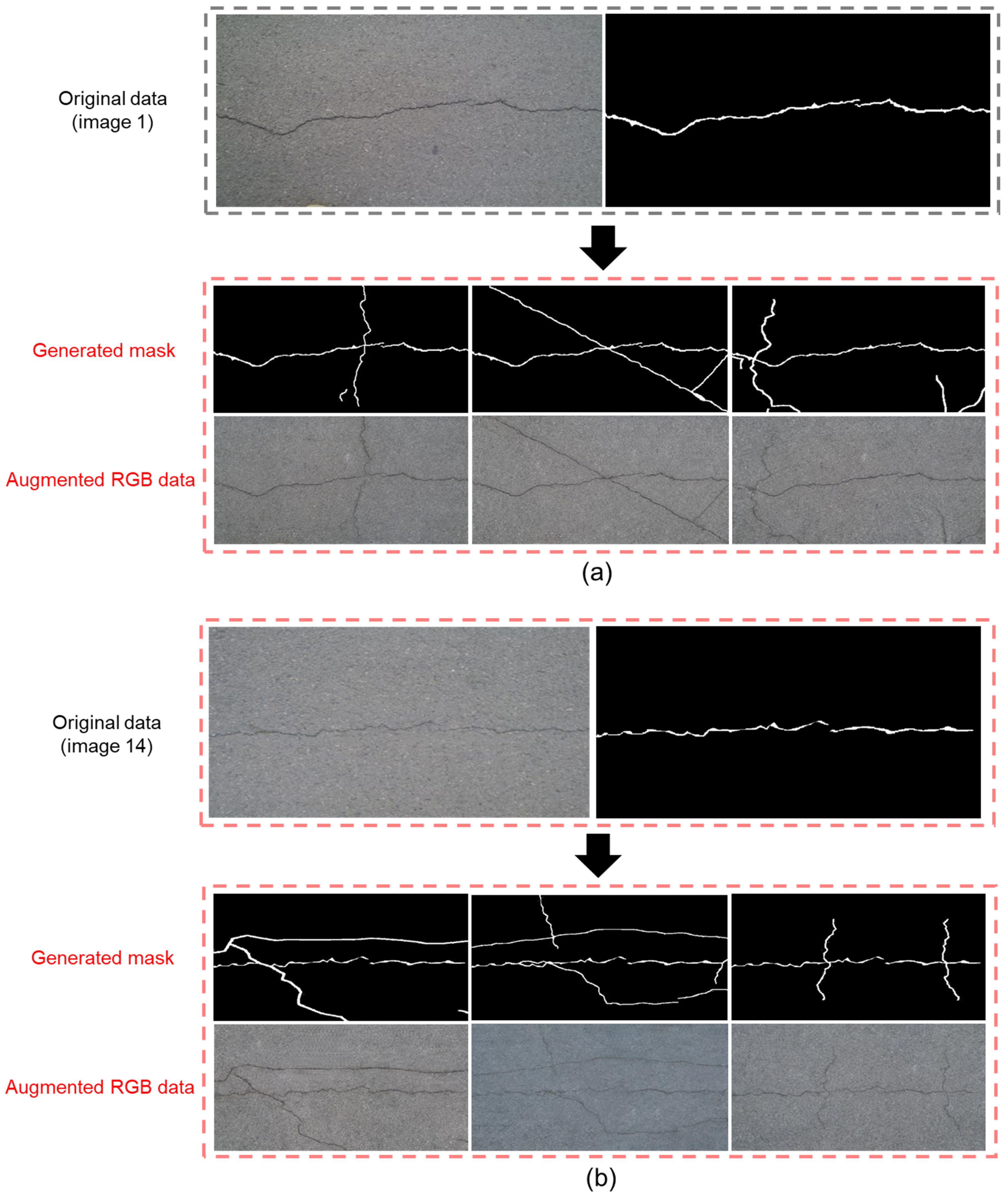
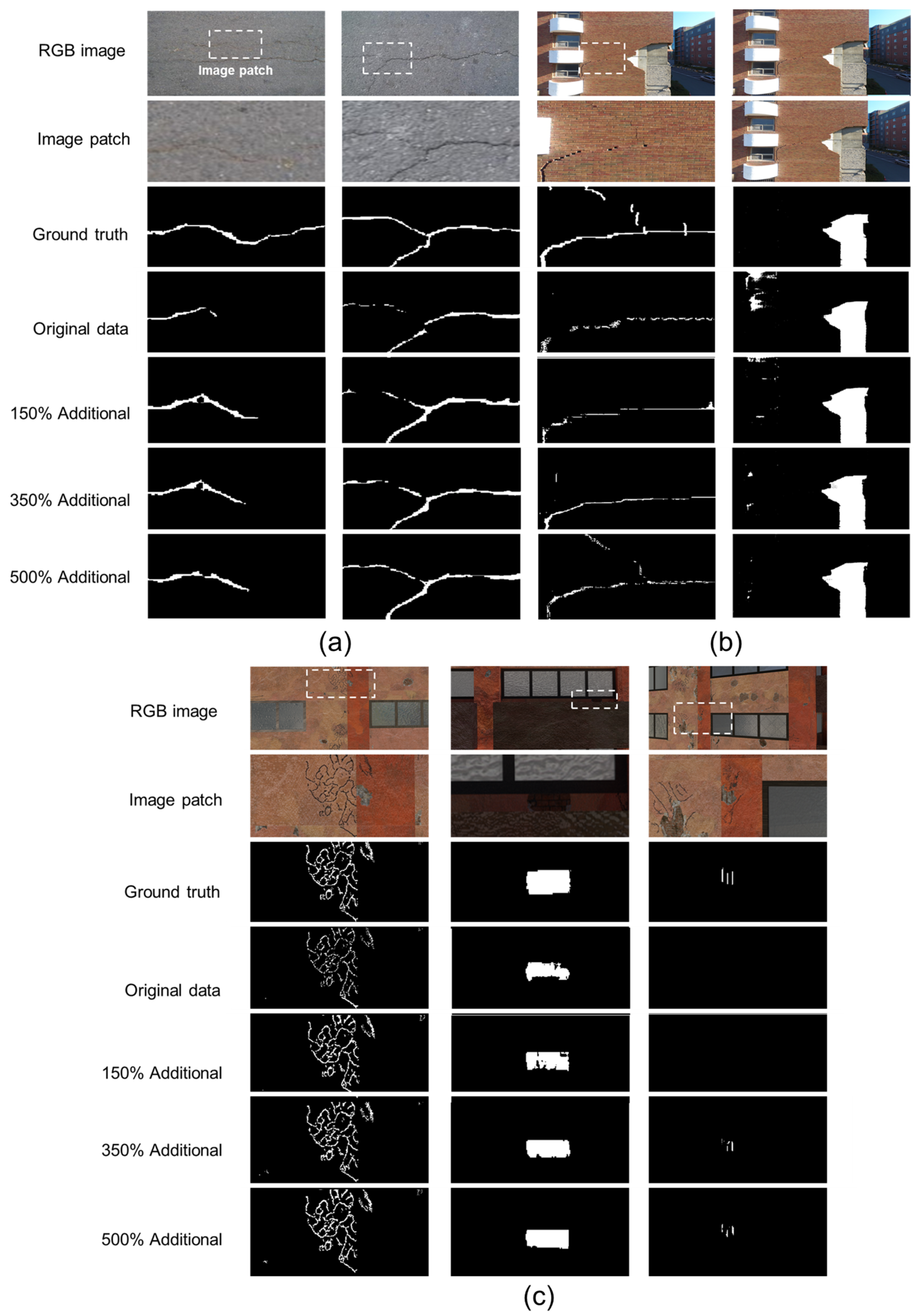
4.2.1. Data Augmentation Results for Dataset 1
4.2.2. Data Augmentation Results for Dataset 2
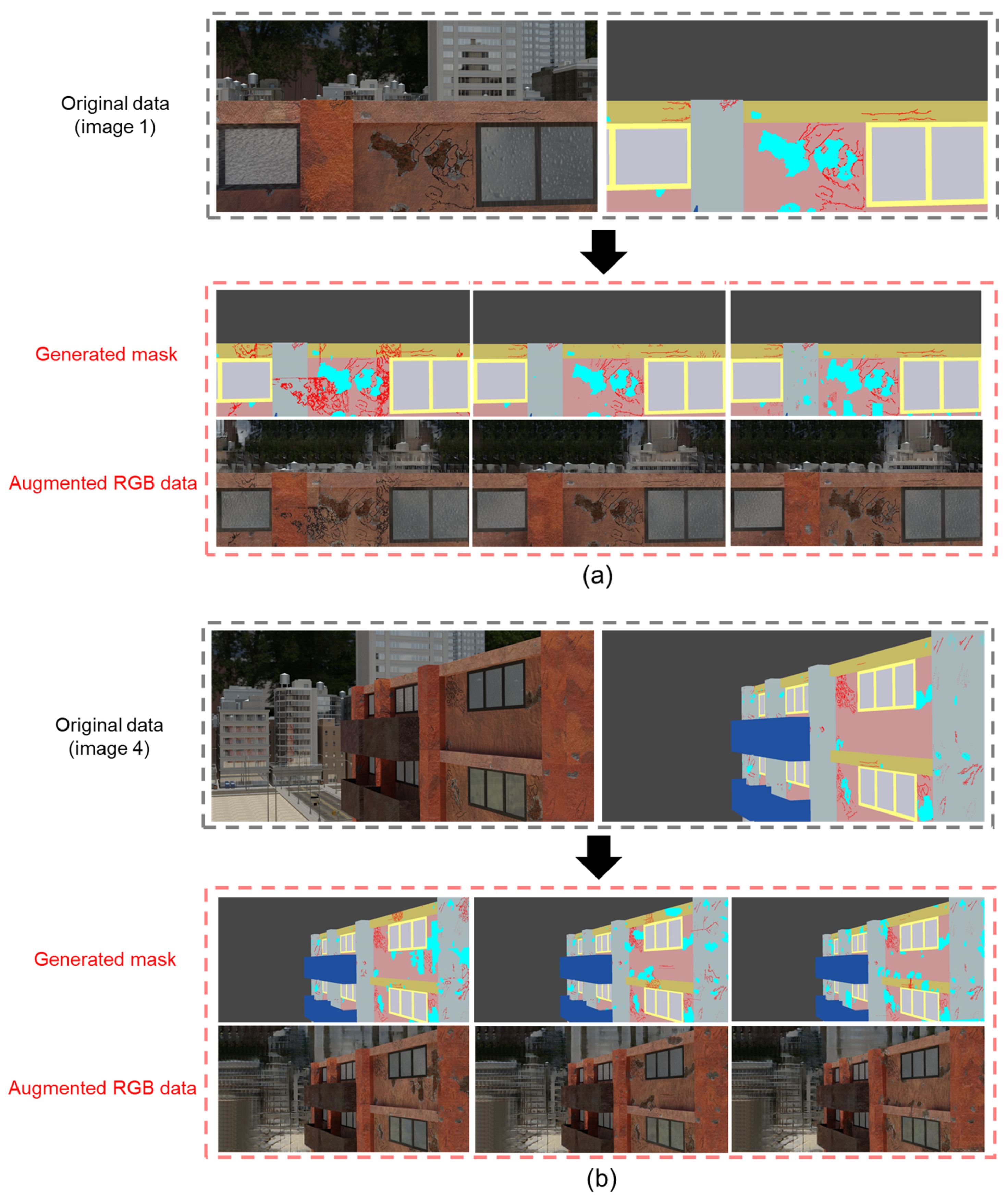
4.2.3. Data Augmentation Results for Dataset 3
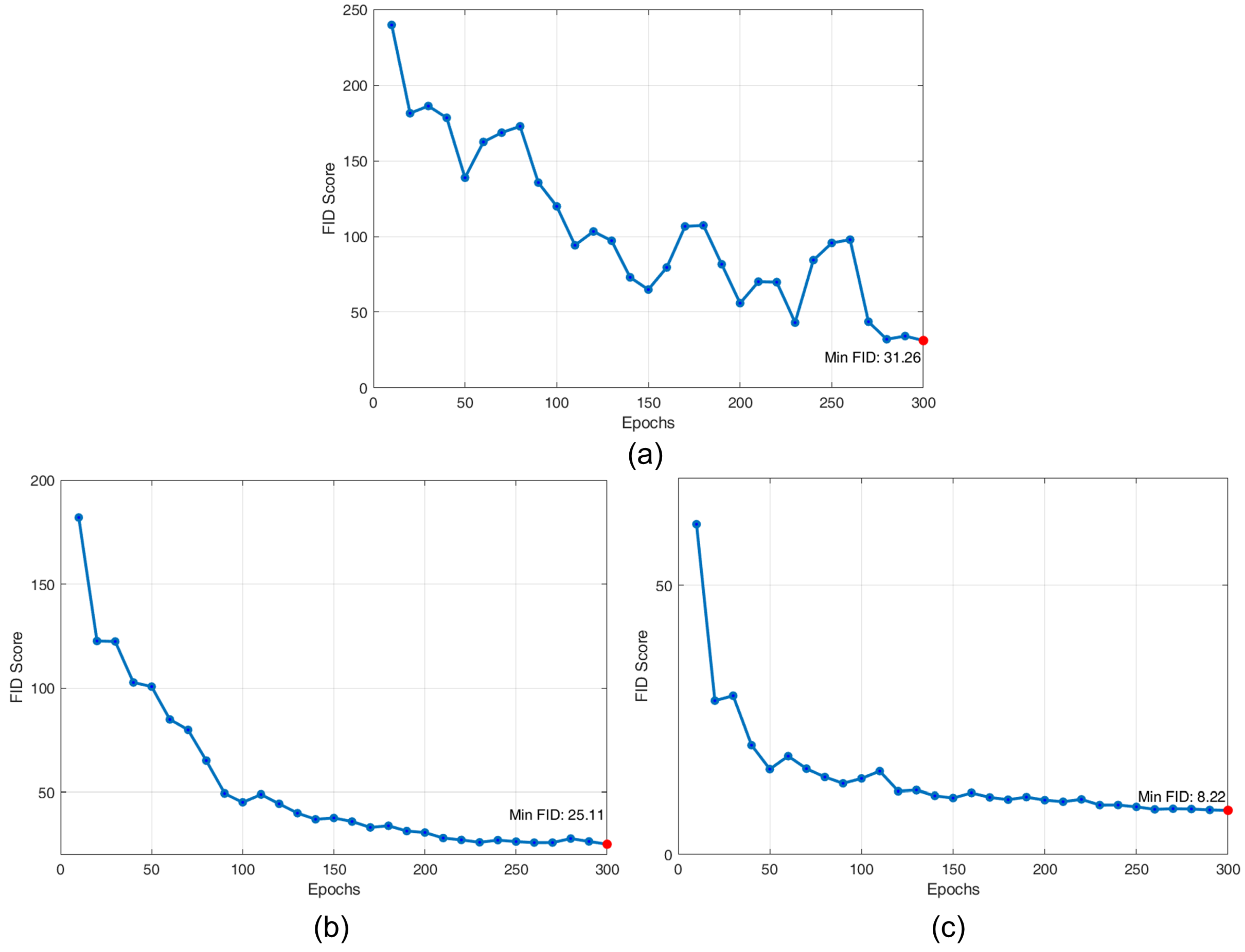
4.2.4. Quantitative Evaluation
4.3. Comparison of Damage Detection Performance according to Data Augmentation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Perry, B.J.; Guo, Y.; Atadero, R.; van de Lindt, J.W. Streamlined bridge inspection system utilizing unmanned aerial vehicles (UAVs) and machine learning. Measurement 2020, 164, 108048. [Google Scholar] [CrossRef]
- Yuan, C.; Xiong, B.; Li, X.; Sang, X.; Kong, Q. A novel intelligent inspection robot with deep stereo vision for three-dimensional concrete damage detection and quantification. Struct. Health Monit. 2022, 21, 788–802. [Google Scholar] [CrossRef]
- Ghosh Mondal, T.; Jahanshahi, M.R.; Wu, R.T.; Wu, Z.Y. Deep learning-based multi-class damage detection for autonomous post-disaster reconnaissance. Struct. Control. Health Monit. 2020, 27, e2507. [Google Scholar] [CrossRef]
- Jung, H.J.; Lee, J.H.; Yoon, S.; Kim, I.H. Bridge Inspection and condition assessment using Unmanned Aerial Vehicles (UAVs): Major challenges and solutions from a practical perspective. Smart Struct. Syst. Int. J. 2019, 24, 669–681. [Google Scholar]
- Gwon, G.H.; Lee, J.H.; Kim, I.H.; Jung, H.J. CNN-Based Image Quality Classification Considering Quality Degradation in Bridge Inspection Using an Unmanned Aerial Vehicle. IEEE Access 2023, 11, 22096–22113. [Google Scholar] [CrossRef]
- Svendsen, B.T.; Øiseth, O.; Frøseth, G.T.; Rønnquist, A. A hybrid structural health monitoring approach for damage detection in steel bridges under simulated environmental conditions using numerical and experimental data. Struct. Health Monit. 2023, 22, 540–561. [Google Scholar] [CrossRef]
- Yao, Y.; Tung, S.T.E.; Glisic, B. Crack detection and characterization techniques—An overview. Struct. Control. Health Monit. 2014, 21, 1387–1413. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated crack detection on concrete bridges. IEEE Trans. Autom. Sci. Eng. 2014, 13, 591–599. [Google Scholar] [CrossRef]
- Gao, Y.; Mosalam, K.M. Deep transfer learning for image-based structural damage recognition. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Modarres, C.; Astorga, N.; Droguett, E.L.; Meruane, V. Convolutional neural networks for automated damage recognition and damage type identification. Struct. Control. Health Monit. 2018, 25, e2230. [Google Scholar] [CrossRef]
- Kim, I.H.; Jeon, H.; Baek, S.C.; Hong, W.H.; Jung, H.J. Application of crack identification techniques for an aging concrete bridge inspection using an unmanned aerial vehicle. Sensors 2018, 18, 1881. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Yoon, S.; Kim, B.; Gwon, G.H.; Kim, I.H.; Jung, H.J. A new image-quality evaluating and enhancing methodology for bridge inspection using an unmanned aerial vehicle. Smart Struct. Syst. 2021, 27, 209–226. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1542–1547. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Wang, J.; Perez, L. The effectiveness of data augmentation in image classification using deep learning. Convolutional Neural Netw. Vis. Recognit. 2017, 11, 1–8. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Dunphy, K.; Fekri, M.N.; Grolinger, K.; Sadhu, A. Data augmentation for deep-learning-based multiclass structural damage detection using limited information. Sensors 2022, 22, 6193. [Google Scholar] [CrossRef]
- Jeong, I.; Kim, H.; Cho, H.; Park, H.; Kim, T. Initial structural damage detection approach via FE-based data augmentation and class activation map. Struct. Health Monit. 2023, 22, 3225–3249. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Spencer Jr, B.F. Physics-based graphics models in 3D synthetic environments as autonomous vision-based inspection testbeds. Sensors 2022, 22, 532. [Google Scholar] [CrossRef]
- Wang, S.; Rodgers, C.; Zhai, G.; Matiki, T.N.; Welsh, B.; Najafi, A.; Wang, J.; Narazaki, Y.; Hoskere, V.; Spencer Jr, B.F. A graphics-based digital twin framework for computer vision-based post-earthquake structural inspection and evaluation using unmanned aerial vehicles. J. Infrastruct. Intell. Resil. 2022, 1, 100003. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Gao, L.; Xie, K.; Wu, X.; Lu, Z.; Li, C.; Sun, J.; Lin, T.; Sui, J.; Ni, X. Generating synthetic CT from low-dose cone-beam CT by using generative adversarial networks for adaptive radiotherapy. Radiat. Oncol. 2021, 16, 1–16. [Google Scholar]
- Lee, H.; Kang, M.; Song, J.; Hwang, K. Pix2Pix-based data augmentation method for building an image dataset of black ice. Journal of Korean Society of Transportation 2022, 40, 539–554. [Google Scholar] [CrossRef]
- Bang, S.; Baek, F.; Park, S.; Kim, W.; Kim, H. Image augmentation to improve construction resource detection using generative adversarial networks, cut-and-paste, and image transformation techniques. Autom. Constr. 2020, 115, 103198. [Google Scholar] [CrossRef]
- Toda, R.; Teramoto, A.; Kondo, M.; Imaizumi, K.; Saito, K.; Fujita, H. Lung cancer CT image generation from a free-form sketch using style-based pix2pix for data augmentation. Sci. Rep. 2022, 12, 12867. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Liu, X.; Królczyk, G.; Sulowicz, M.; Glowacz, A.; Gardoni, P.; Li, Z. Damage detection for conveyor belt surface based on conditional cycle generative adversarial network. Sensors 2022, 22, 3485. [Google Scholar] [CrossRef]
- Weng, X.; Huang, Y.; Li, Y.; Yang, H.; Yu, S. Unsupervised domain adaptation for crack detection. Autom. Constr. 2023, 153, 104939. [Google Scholar] [CrossRef]
- Liu, H.; Yang, C.; Li, A.; Huang, S.; Feng, X.; Ruan, Z.; Ge, Y. Deep domain adaptation for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1669–1681. [Google Scholar] [CrossRef]
- Qi, Y.; Yuan, C.; Li, P.; Kong, Q. Damage analysis and quantification of RC beams assisted by Damage-T Generative Adversarial Network. Eng. Appl. Artif. Intell. 2023, 117, 105536. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Cheng, H.D. CrackGAN: Pavement crack detection using partially accurate ground truths based on generative adversarial learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1306–1319. [Google Scholar] [CrossRef]
- Sekar, A.; Perumal, V. Cfc-gan: Forecasting road surface crack using forecasted crack generative adversarial network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21378–21391. [Google Scholar] [CrossRef]
- Varghese, S.; Hoskere, V. Unpaired image-to-image translation of structural damage. Adv. Eng. Informatics 2023, 56, 101940. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Communications of the ACM. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 Octorber–2 November 2019; pp. 6023–6032. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Jamshidi, M.; El-Badry, M.; Nourian, N. Improving Concrete Crack Segmentation Networks through CutMix Data Synthesis and Temporal Data Fusion. Sensors 2023, 23, 504. [Google Scholar] [CrossRef]
- Çelik, F.; König, M. A sigmoid-optimized encoder–decoder network for crack segmentation with copy-edit-paste transfer learning. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1875–1890. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. High-resolution concrete damage image synthesis using conditional generative adversarial network. Autom. Constr. 2023, 147, 104739. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Ahmadi, A.; Khalesi, S.; Bagheri, M. Automatic road crack detection and classification using image processing techniques, machine learning and integrated models in urban areas: A novel image binarization technique. J. Ind. Syst. Eng. 2018, 11, 85–97. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2039–2047. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Pak, M.; Kim, S. Crack detection using fully convolutional network in wall-climbing robot. In Proceedings of the Advances in Computer Science and Ubiquitous Computing: CSA-CUTE, Macau, China, 18–20 December 2019; Springer: Berlin/Heidelberg, Germany, 2021; pp. 267–272. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef]
- Kulkarni, S.; Singh, S.; Balakrishnan, D.; Sharma, S.; Devunuri, S.; Korlapati, S.C.R. CrackSeg9k: A collection and benchmark for crack segmentation datasets and frameworks. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 179–195. [Google Scholar]
- Hoskere, V.A. Developing Autonomy in Structural Inspections through Computer Vision and Graphics. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana, IL, USA, 2020. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Data | 150% Additional Data | 350% Additional Data | 500% Additional Data | ||
|---|---|---|---|---|---|
| Dataset 1 | Crack | 41.04% | 48.48% (18.13%) * | 49.21% (19.91%) | 49.12% (19.69%) |
| Dataset 2 | Crack | 4.85% | 14.17% (192.16%) | 14.74% (203.92%) | 15.84% (226.60%) |
| Spalling | 95% | 95.52% (0.55%) | 96.87% (1.97%) | 96.79% (1.88%) | |
| Dataset 3 | Crack | 26.99% | 37.20% (37.83%) | 39.02% (44.57%) | 39.61% (46.76%) |
| Spalling | 79.74% | 80.40% (0.83%) | 81.39% (2.07%) | 81.62% (2.36%) | |
| Exposed Rebar | 1.25% | 7.05% (464%) | 17.29% (1283.2%) | 30.7% (2356%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gwon, G.-H.; Lee, J.-H.; Kim, I.-H.; Baek, S.-C.; Jung, H.-J. Image-to-Image Translation-Based Structural Damage Data Augmentation for Infrastructure Inspection Using Unmanned Aerial Vehicle. Drones 2023, 7, 666. https://doi.org/10.3390/drones7110666
Gwon G-H, Lee J-H, Kim I-H, Baek S-C, Jung H-J. Image-to-Image Translation-Based Structural Damage Data Augmentation for Infrastructure Inspection Using Unmanned Aerial Vehicle. Drones. 2023; 7(11):666. https://doi.org/10.3390/drones7110666
Chicago/Turabian StyleGwon, Gi-Hun, Jin-Hwan Lee, In-Ho Kim, Seung-Chan Baek, and Hyung-Jo Jung. 2023. "Image-to-Image Translation-Based Structural Damage Data Augmentation for Infrastructure Inspection Using Unmanned Aerial Vehicle" Drones 7, no. 11: 666. https://doi.org/10.3390/drones7110666
APA StyleGwon, G. -H., Lee, J. -H., Kim, I. -H., Baek, S. -C., & Jung, H. -J. (2023). Image-to-Image Translation-Based Structural Damage Data Augmentation for Infrastructure Inspection Using Unmanned Aerial Vehicle. Drones, 7(11), 666. https://doi.org/10.3390/drones7110666