1. Introduction
The rapid advancement in the fields of unmanned aerial vehicles (UAVs) and synthetic aperture radar (SAR) has led to significant breakthroughs in remote sensing capabilities [
1,
2]. The integration of SAR technology with UAVs [
1,
2] has unlocked the potential for acquiring high-definition imagery from above, providing a versatile tool for detailed surveillance and analysis across vast and varied landscapes. Building upon this development, these high-resolution SAR images captured by UAVs are revolutionizing the Internet of Things (IoT) landscape by enriching the spectrum of data available for automated processing and interpretation. In the realm of IoTs, UAVs equipped with vision systems have become pivotal in tasks requiring extensive area coverage with precision, such as monitoring wildlife migration patterns in their natural habitats or providing real-time data on environmental conditions for ecological studies.
Meanwhile, deep neural networks (DNNs) have proven to be particularly effective in processing the complex data obtained from SAR images [
3,
4]. Their advanced representation capabilities facilitate accurate analysis and have been instrumental in the development of SAR automatic target recognition (SAR-ATR) models [
5,
6,
7,
8]. By leveraging the computational prowess of DNNs, these models have rapidly gained popularity due to their efficiency and reliability in identifying and classifying targets in diverse environments.
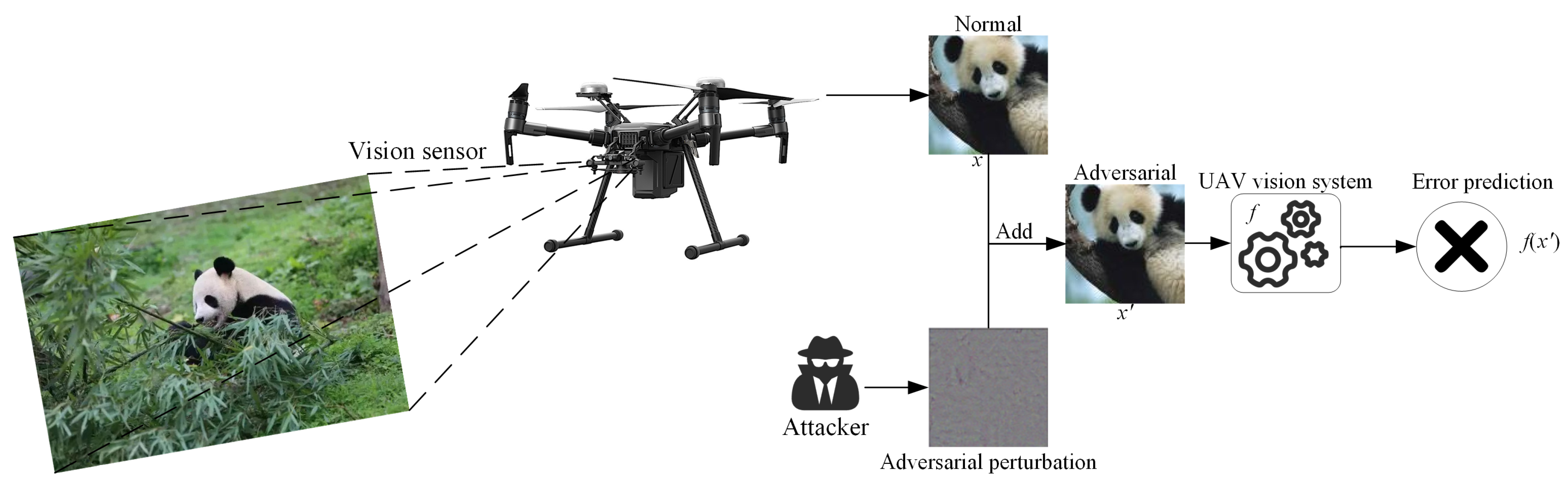
Although the integration of DNNs into UAV vision systems has markedly improved their capability to deal with complex data, it has concurrently opened up a vector for a new type of threat—adversarial attacks [
9]. These attacks are executed through the generation of adversarial examples, which are seemingly normal images that have been meticulously modified with imperceptible perturbations. These alterations are calculated and crafted to exploit the inherent vulnerabilities of DNNs, causing them to misinterpret the image and make incorrect decisions [
10]. The process of its attack implementation is shown in
Figure 1. Such adversarial attacks on UAV vision systems can lead to unpredictable behavior and severely impact the security of data acquisition and transmission in UAV-assisted IoTs [
11]. In scenarios where UAVs are employed for critical missions, such as search and rescue operations, security surveillance, or precision agriculture, a false classification could lead to dire outcomes. For instance, an adversarial image could cause a UAV to overlook a lost hiker it was tasked to locate or misidentify a benign object as a security threat, triggering unwarranted responses. Moreover, the challenge is exacerbated by the fact that these perturbations are designed to be imperceptible to human analysts, which means that the reliability of UAV systems could be compromised without immediate detection. This underlines the urgency for the research and development of defense strategies that can detect and neutralize adversarial examples before they impact UAVs.
In order to address this emerging threat, researchers propose two defense strategies: active and passive defense strategies. Active defense methods increase the robustness of models against adversarial attacks through techniques like adversarial training [
12,
13] and network distillation [
14], which are applied during training. In contrast, passive defense involves detecting and filtering adversarial inputs during model deployment. Our research focuses on passive defense, aiming to identify features that differentiate adversarial from clean samples, thereby enabling the detection of adversarial examples and safeguarding the model from potential attacks.
As a reflection of the ongoing efforts in the deep learning community, there is intensive research on adversarial detection. Numerous passive defense techniques have been developed to tackle adversarial attacks. Hendrycks and Gimpel [
15] proposed three methods: Reconstruction, PCA, and Softmax, which, while effective against FGSM [
9] and BIM [
16] attacks, have limitations in detecting more sophisticated threats. Metzen et al. [
17] developed an adversarial detection network (ADN), which enhances binary detection in pretrained networks and shows promise against FGSM, DeepFool [
18], and BIM attacks but not against the more challenging C&W [
19] attacks. Gong et al. [
20] made further attempts to improve an ADN, yet it remained inadequate for C&W attack detection. Xu et al. [
21] suggested that adversarial example generation is linked to excessive input dimensions and introduced feature squeezing to identify adversarial instances by contrasting the outputs of squeezed and original samples. This approach shows potential in detecting C&W attacks, but its precision still requires enhancement.
In summary, while the aforementioned methods show efficiency in detecting adversarial attacks, such as FGSM and BIM, they fall short when faced with more potent threats like the C&W attack.
Building on this premise, researchers have demonstrated that the adversarial perturbations from C&W attacks tend to be subtler than those from other methods like FGSM when executed under comparable conditions [
22]. As a result, adversarial examples crafted via C&W attacks are notably more challenging to detect. In this paper, we classify such finely perturbed instances as strong adversarial examples typified by the C&W attack. In contrast, examples with more pronounced perturbations, like those from FGSM attacks, are deemed weak adversarial examples.
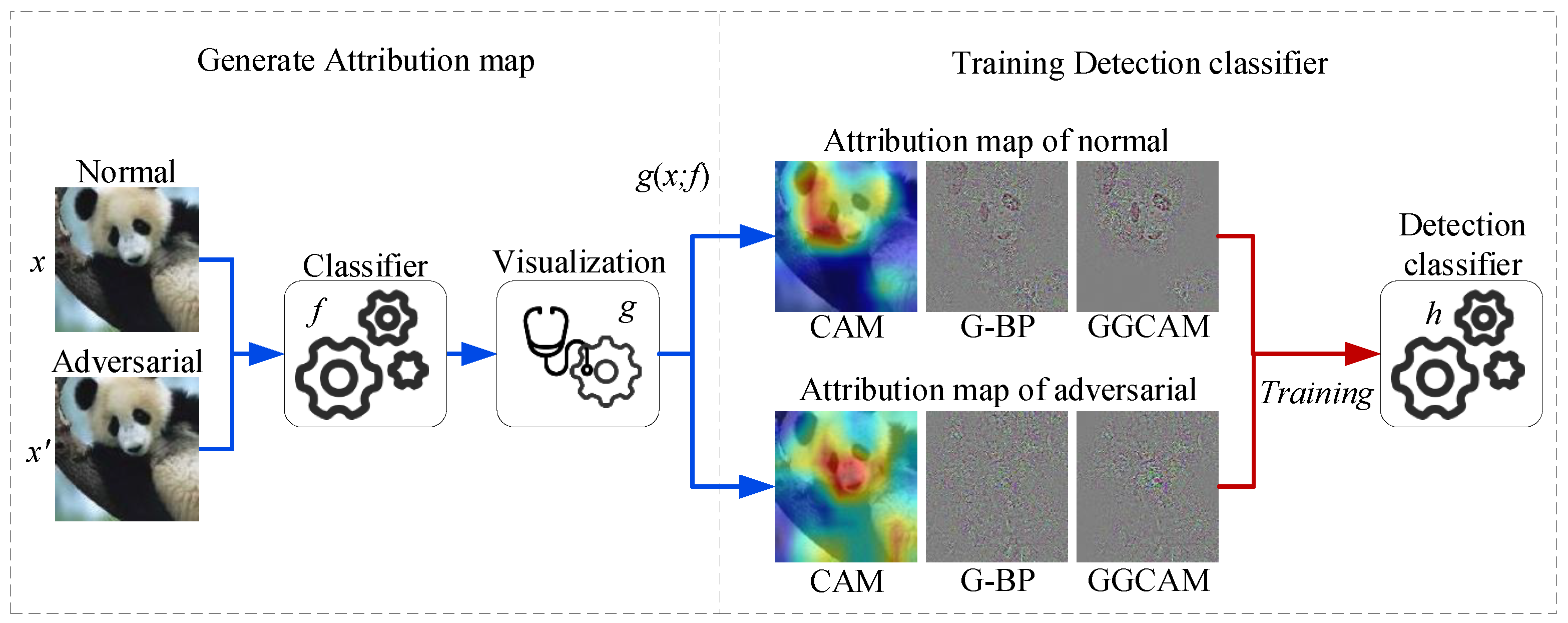
Additionally, recent studies have revealed that the convolutional layers in convolutional neural networks (CNNs) inherently function as object detectors, even without explicit object location supervision. Consequently, visualizing the model by extracting the features detected by each CNN layer is possible. In this paper, we have expanded upon earlier versions [
23]. We have added a significant amount of more detailed charts, conducted adversarial detection experiments based on different attribute maps, and further compared our method with several state-of-the-art approaches. We propose an adversarial detection method for UAV vision systems based on different attribution maps. The proposed methods consist of two steps. Firstly, we generate attribution maps for both clear and adversarial samples using three different types of attribution maps, including class activation mapping (CAM) [
24], guided backpropagation (G-BP) [
25], and guided Grad-CAM (GGCAM) [
26]. We then tried to train a binary classifier by using the generated attribution maps to detect adversarial samples. Through experiment analysis, there are distinguishing features between the attribution maps of clear and adversarial samples. In particular, the G-BP and GGCAM of clear samples have discrimination contour features, but after adversarial perturbations are added, the contour features are destroyed, showing that the attribution maps generated by model visualization techniques can effectively distinguish adversarial samples from clear samples. We conducted experiments on ImageNet, and the results show that when using three different attribution maps, this method can detect not only weak adversarial samples, such as FGSM and BIM, but also strong adversarial samples, like C&W. Among them, the detection success rate achieved using G-BP reached up to 99.58%, surpassing the state-of-the-art methods.
The main contributions of this paper are as follows:
(1) This paper presents novel model visualization techniques that are introduced for the first time to detect adversarial examples. Model visualization approaches are employed to analyze sample features, and we find the attribution maps of adversarial and clear samples differ considerably. Specifically, the contour features of G-BP and GGCAM are destroyed when the adversarial perturbations are added.
(2) We propose a novel adversarial detection method for UAV vision systems via attribution maps. When using different attribute maps, the success rate of adversarial sample detection can reach more than 90%. Among them, the detection success rate based on the G-BP map can reach 99.58%, which is 1.68% higher than the state-of-the-art method.
3. Methodology
In recent years, researchers have studied the interpretability of DNNs from two aspects: models [
43,
44,
45] and samples [
40,
46,
47]. This paper approaches the issue of adversarial example detection from the sampling perspective, utilizing model visualization techniques to produce attribution maps for both clean and adversarial samples, thereby investigating their distinguishing features. It is acknowledged that the smaller the perturbations in adversarial examples, the more challenging they are to detect. Consequently, this study opts for untargeted attacks to generate adversarial samples, aiming to minimize the perturbations introduced.
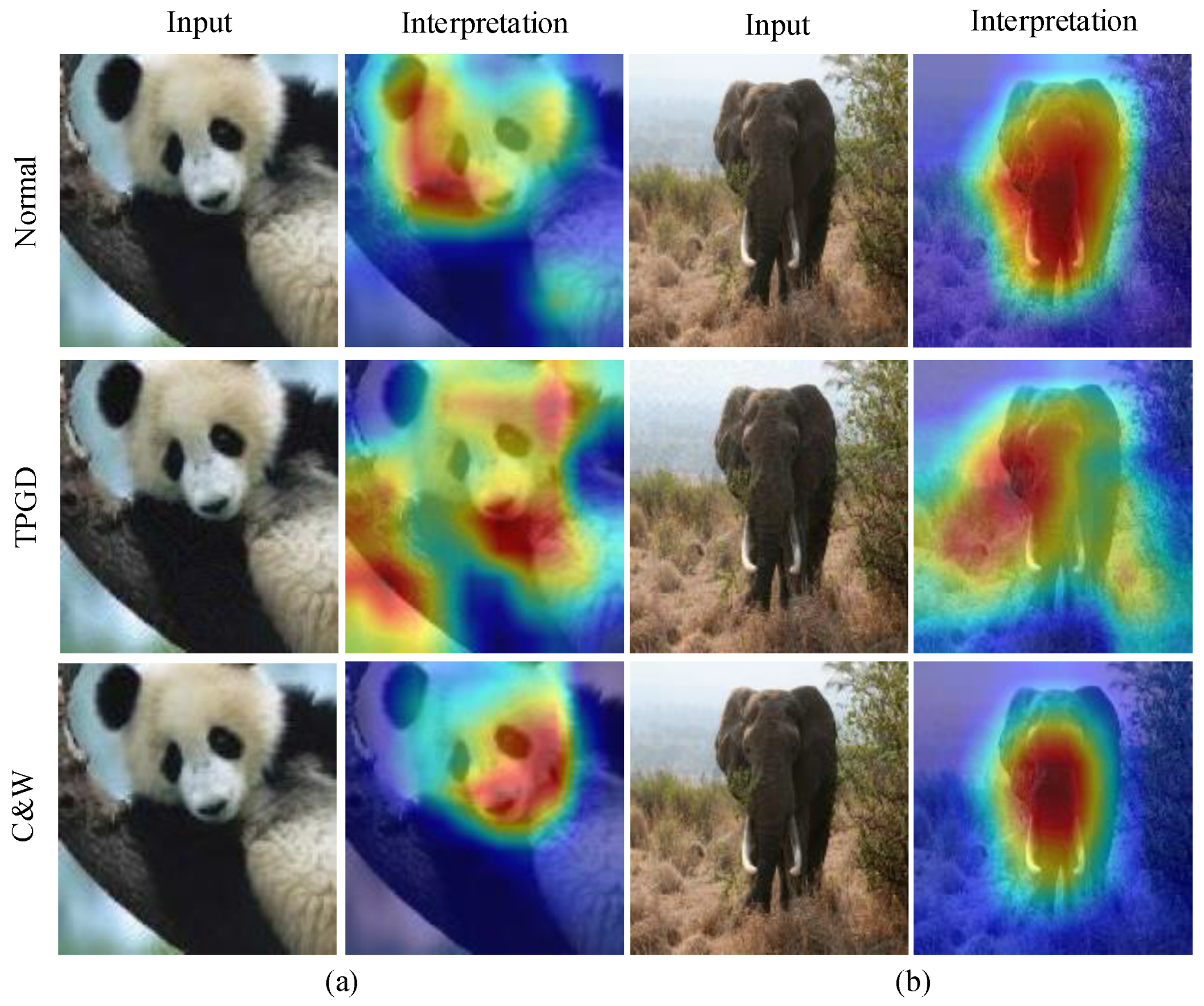
Inspired by the study of model interpretability [
48], we find a large gap between the CAM of normal and adversarial samples. So, for example, we select two samples and transform them into adversarial samples by using the C&W and TPGD [
49] methods. Then, we compare their CAMs, as shown in
Figure 2. Normal represents the clear sample and its corresponding attribution map. The highlighted part contains the most abundant input information, revealing the causal relationship between model output (classification) and input. The row of TPGD is the adversarial samples and their corresponding attribution maps generated by the TPGD method. The highlighted part of the attribution map of the adversarial sample shows a great change, which has a high degree of differentiation compared with the attribution map of normal samples. Meanwhile, it also reveals the causal relationship between model misclassification and perturbation input. Similarly, the third row presents adversarial samples and their attribution maps created by C&W. When compared to TPGD, the differences in attribution maps with C&W are much less pronounced, confirming the strength of C&W as a white-box attack [
22].
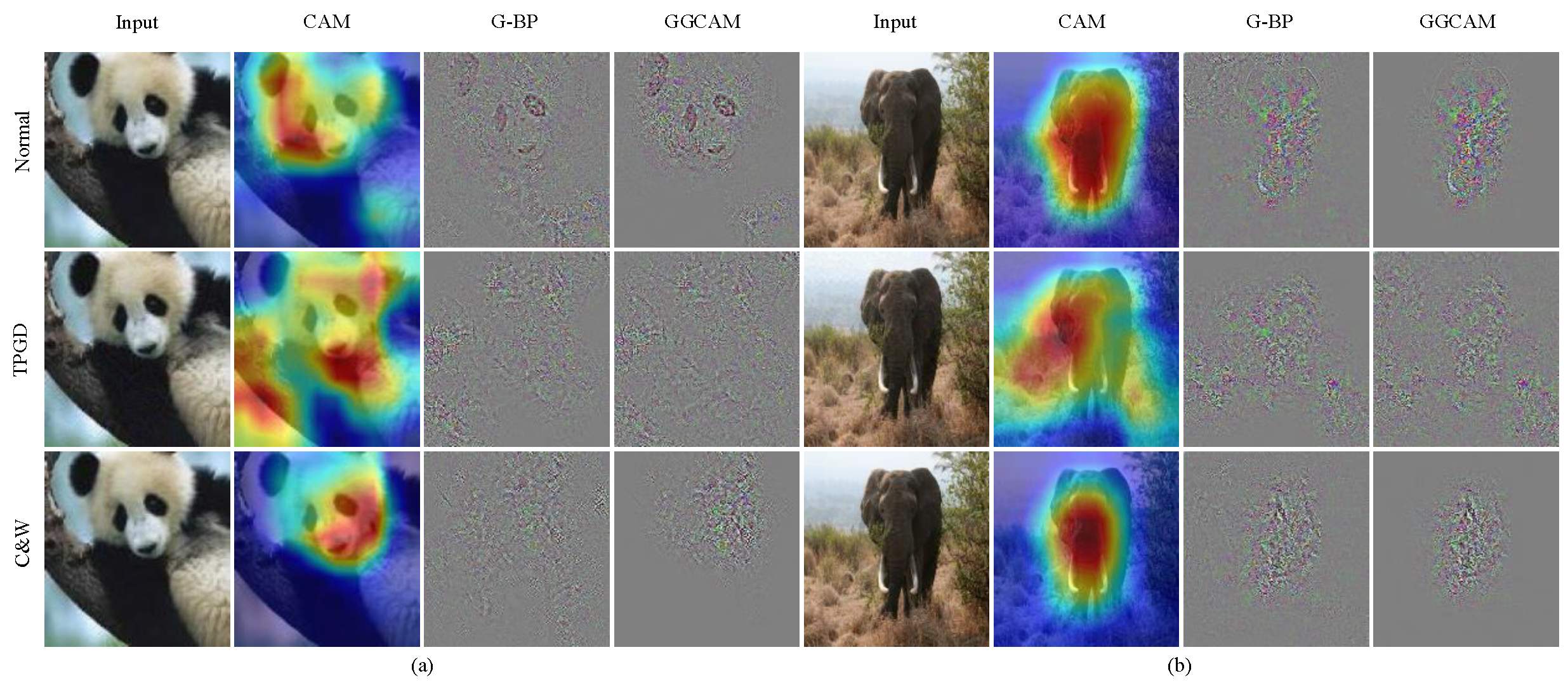
Figure 2 shows that there is a significant difference between the clear and adversarial samples by comparing their attribution maps. Which attribution map has the maximum identification is the key to designing adversarial detection algorithms in this paper. Therefore, we extracted the CAM, G-BP and GGCAM of the two samples in
Figure 2, respectively, for comparison, as shown in
Figure 3.
We have noted that CAMs exhibit limited differentiation for certain attacks, such as the C&W method. Conversely, guided backpropagation (G-BP) and guided Grad-CAM (GGCAM) demonstrate higher levels of discrimination: the Normal samples display distinct contour features in their attribution maps (see
Figure 3: Normal), allowing for rough classification judgments by visual inspection. The introduction of adversarial perturbations, however, leads to a pronounced disruption of these contours in the clear samples (see
Figure 3: TPGD and C&W), rendering the residual features unintelligible to the human observer. Hence, the disparities in G-BP and GGCAM between the clean and adversarial samples could provide a sufficient basis for detecting adversarial instances. Beyond TPGD and C&W attacks, this study also examines BIM, DeepFool, FGSM, One Pixel, PGD, Square, and Autoattack, employing a total of seven adversarial sample generation methods. The resulting attribution maps are depicted in
Figure 4.
Figure 4 shows the comparison of attribution maps between nine adversarial samples and clear samples, among which OnePixel modified one pixel point, and AutoAttack is the adversarial sample generation method, which integrates APGD [
50], APGDT [
50], FAB [
51], and Square [
52]. At the same time, we use the
norm, respectively, to calculate the difference between the clear and adversarial samples.
The analysis reveals that the attribution maps for the adversarial samples exhibit discernible alterations following the introduction of adversarial perturbations when compared to clear samples. Notably, the attribution maps measured using the norm in CAM display the most pronounced differences, characterized by brighter colors and more significant pixel value variations. In contrast, the variations between G-BP and GGCAM are even more apparent, with the contour features of clear samples experiencing substantial disruption. Consequently, the attribution maps generated by CAM, G-BP, and GGCAM demonstrate effective capabilities in identifying adversarial samples.
5. Experiment
In this section, we set up three experiments: (1) EfficientNet-B0 as the detector, which verifies the effectiveness of attribution maps. We compare which of the three attribute maps is most suitable for detecting adversarial samples. (2) ResNet50 as the detector, further illustrating that when we choose different classifiers, the attribution maps can also obtain good accuracy. (3) Comparisons with state-of-the-art methods. The experimental part selects the ImageNet validation set as the dataset. Adversarial samples are generated by five attacks, including C&W, BIM, FGSM, PGD, and AutoAttack (APGD, APGDT, FAB, and Square). The code in this paper is implemented via the PyTorch deep learning framework, and we use the TorchAttacks library to generate the adversarial samples.
5.1. Dataset and Models
ImageNet [
55] consists of over 1.2 million images across 1000 diverse categories. It is widely used for benchmarking machine learning models in visual object recognition due to its variety of classes and high volume of data. In the context of UAVs, leveraging ImageNet can significantly aid in developing robust object classification algorithms, which are critical for UAV autonomous navigation and operational tasks, such as surveillance or search and rescue. Utilizing ImageNet for adversarial sample detection in UAV data transmission and output processing is crucial because it represents a broad spectrum of real-world scenarios that UAVs may encounter. In this paper, due to the extensive size of the ImageNet dataset, only the verification set consisting of 50,000 images was utilized as the data source.
We selected EfficientNet-B0 and ResNet50 as our classifier models and trained them using the attribution maps of adversarial and normal samples. For EfficientNet-B0, we follow the scaling method proposed by Tan et al. [
53]. Additionally, we employ the same RMSprop optimizer with a decay of 0.9 and a momentum of 0.9, alongside a learning rate warm-up and exponential decay, as suggested by Tan et al. [
53]. As for ResNet50, following the research of He et al. [
54], we utilized a batch normalization momentum of 0.1 and a standard cross-entropy loss function. The model was trained using SGD with momentum, with an initial learning rate set as recommended, which was adjusted following a cosine decay schedule.
5.1.1. Training Sets and Validation Sets
We selected the first 40,000 images in the ImagNet validation set as the normal class. By using the C&W method, these samples were also transformed into adversarial samples and used as an adversarial sample class (not every normal sample can be converted into an adversarial sample). In the training, we selected 20% of the data as the verification set through random sampling, and the remaining 80% of the data was used for training.
Table 2 shows the training set and verification set.
In training, we selected 20% of the data in the training set as the verification set through random sampling, and the remaining 80% of the data was used for training.
Table 2 shows the training set and verification set.
Finally, our training set contained 32,000 normal samples and 17,616 adversarial samples, and the verification set contained 8000 normal samples and 4403 adversarial samples.
5.1.2. Test Sets
We selected the remaining 10,000 images in the ImagNet validation set as the normal class, and these 10,000 images were converted into five types of adversarial samples by using the C&W, BIM, FGSM, PGD, and AutoAttack methods, which were used as the adversarial samples in the test set. AutoAttack integrates the APGD, APGDT, FAB, and Square attack methods.
Table 3 shows the test sets.
5.2. Performance Metrics
The effectiveness of the method is assessed using four key metrics: true-negative (
), true-positive (
), false-positive (
), and false-negative (
). These metrics provide insights into the classification performance. When the positive class in the test dataset is correctly classified as a positive class, it is considered as
.
is achieved when a negative class is accurately predicted as a negative class.
occurs when a positive class is mistakenly classified as a negative class. Conversely,
happens when a negative class is incorrectly predicted as a positive class. In this paper, the evaluation criteria for the effectiveness of the method are based on the combination of precision (Equation (
10)), recall (Equation (
11)), and accuracy (Equation (
12)).
5.3. Experiments Using EfficientNet-B0
As shown in
Table 4, the results show that all three attribution maps (CAM, GGCAM, and G-BP) can effectively detect adversarial samples. The average accuracy of CAM is 94.06%, and in comparison with other attribution maps, CAM is lower than GGCAM and G-BP in terms of recall rate, precision, and accuracy. The results show that the difference in the CAM between the normal and adversarial samples is smaller than the other two attribute maps, which contradicts the calculation of the
norm. This indicates that calculating the difference in the attribute maps by using the
norm is not suitable. The average accuracy of GGCAM is 99.38%, which is higher than that of CAM by 5.32%. G-BP has the best effect, with an average accuracy of 99.56%, 0.18% higher than GGCAM. Therefore, the detection of C&W, BIM, FGSM, PGD, and AutoAttack can be realized well via G-BP.
5.4. Experiments Using ResNe50
As shown in
Table 5, the detection model is replaced by ResNe50. The results of this experiment are similar to the experiments using EfficientNet-B0. The average accuracy of CAM is 93.03%, which is lower than that of GGCAM and G-BP in terms of recall, precision, and accuracy. When compared with the EfficientNet-B0 used in Experiment 1, the accuracy of CAM decreases by 1.03%, whereas that of GGCAM only decreases by 0.014%. Therefore, using CAM for adversarial sample detection is not stable compared to GGCAM. Meanwhile, all the evaluation indexes of G-BP are higher than CAM and GGCAM. The average accuracy is almost the same as in Experiment 1, even increasing by 0.02%. Therefore, G-BP is better adapted to the detection of adversarial samples.
5.5. Comparisons with State-of-the-Art Methods
Our detection approach was benchmarked against the leading state-of-the-art adversarial detection methods, including kernel density (KD) [
39], local intrinsic dimensionality (LID) [
56], Mahalanobis distance (MD) [
57], LiBRe [
58], S-N [
59], and EPS-N [
59]. By adhering to the experimental protocols established by Zhang et al. [
59], our implementation employs the ResNet50 architecture as the foundation for our detector. As indicated in
Table 6, our proposed methods exhibit robust performance, surpassing other approaches in average detection success rate across various attack vectors.
5.6. Discussion
The proposed method based on attribution maps can effectively detect C&W, BIM, FGSM, PGD, and other attacks. The average detection accuracy of G-BP can reach 99.58%, indicating that the attribute maps can distinguish clear samples from adversarial samples. We choose the attribution maps as the distinguishing features. This method is feasible and independent of the choice of classifiers.
Further analyzing our approach, we focus on error examples in detecting C&W attacks under the Efficientnet-B0 model. In the case of misclassified normal samples (
Figure 6), we observe two types of errors. Samples (a) and (b) have relatively clear contours, but the model fails to recognize these features (the highlighted part is not on the contour feature), leading to incorrect classification. Conversely, samples (c) and (d), with fuzzy contours, are also misclassified. This suggests that the model does not consistently extract contour features, leading to the misidentification of these samples as adversarial examples. Improving the steady extraction of contour features in samples will be our focus in future work.
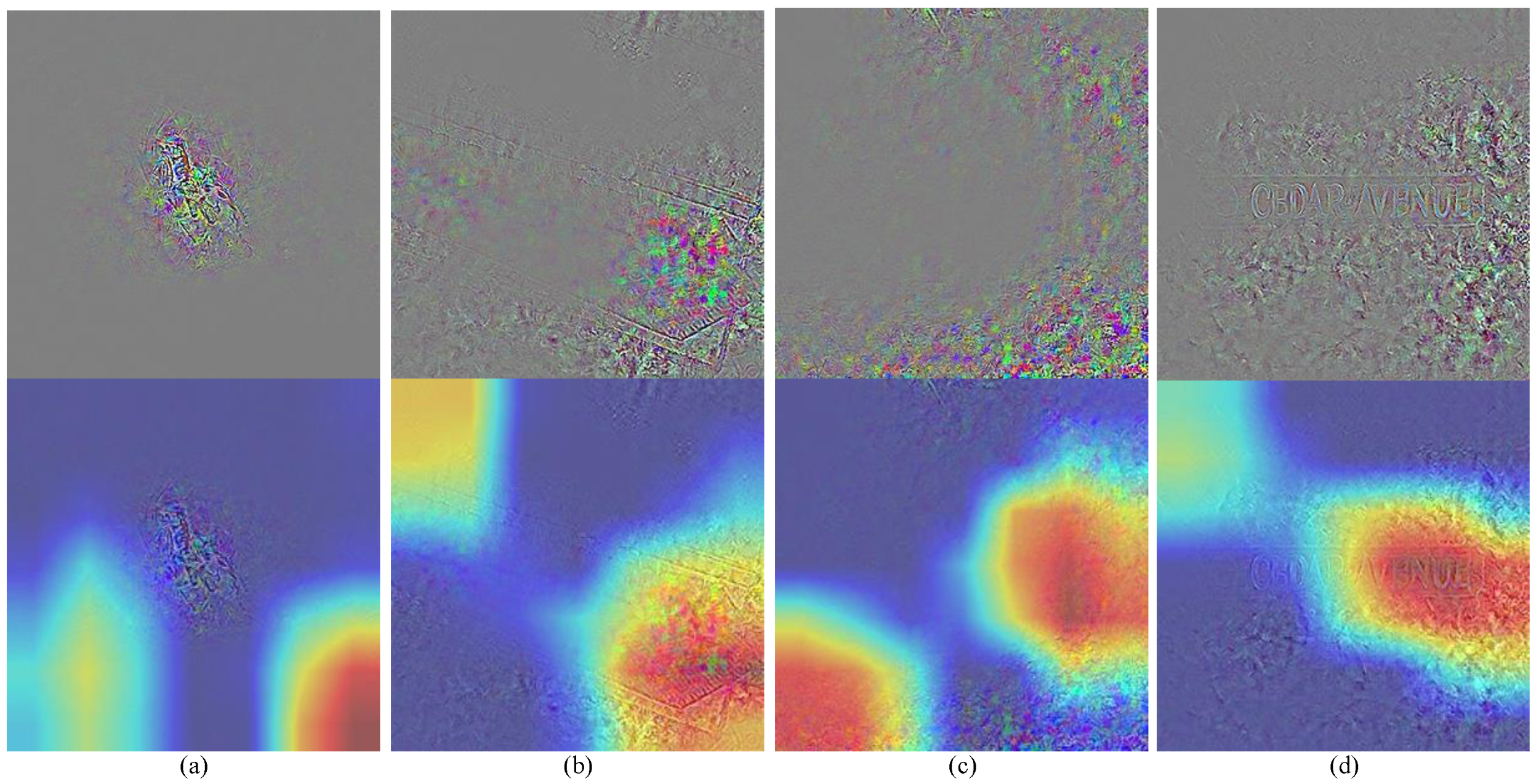
For misclassified adversarial examples (
Figure 7), again, we notice two scenarios. In cases (a) and (c), the object’s contour almost disappears due to adversarial perturbations. The model’s regions of interest are not focused on areas with significant gradient changes. This type of error may be attributed to an issue within the model itself. In cases (b) and (d), the partial contours remain visible despite increased adversarial perturbations. A human observer can distinguish objects like a bench or the alphabet. The model focuses on areas with rich contoured features, leading to the misclassification of these adversarial samples as normal. This indicates that the adversarial perturbations added during example generation are not always sufficient.
Our analysis identifies two main issues. The first concerns the stability of contour feature extraction in a small number of samples. As shown in
Figure 6c,d, these normal samples’ contour information is not fully captured in the attribution maps. This suggests that our method may struggle with consistently extracting contour features, especially from samples with limited instances. The second issue arises in classes with a small number of samples. Despite the adversarial perturbations, the contour features are not completely disrupted.
Figure 7b,d show that only parts of the contours are affected by the perturbations. The remaining intact contour information can lead to misclassification. This underscores the challenge of effectively disrupting the contour features in adversarial samples, particularly in classes with fewer instances.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}