Abstract
This paper proposes a fault tolerant control strategy for drone interceptors with fixed wings and reaction jets subject to actuator faults. The drone interceptors have both continuous and discrete actuators, which pose a challenge to the control system design. The proposed fault tolerant control system consists of two parts, a nonlinear virtual control law and a dynamic control allocator. To deal with system uncertainty and quantization error, a virtual control law with a parameter update law is designed by command filtered backstepping. Then, a fault weighting dynamic control allocation algorithm is developed to distribute the virtual control signal to the actuators on the drone interceptor. When an actuator fault occurs, the proposed fault weighting dynamic control allocation scheme can redistribute the control signals to the remaining actuators. The effectiveness of the proposed algorithm is confirmed by numerical simulation.
1. Introduction
Drone interceptors, also called interceptor drones or drone interdictions, are unique agile UAVs (unmanned aerial vehicles) that specialize in destroying other drones before they achieve their goals. To accomplish this, an agile UAV launches at a moment’s notice, covers a sizable distance fast, outmaneuvers the opposing drone, and intercepts it. Even though the technology is recent, existing reaction jet systems can provide solutions. Drone interceptors can employ reaction jets to enhance maneuverability and agility [1,2]. Drone interceptors with multiple actuators can also increase the fault tolerance ability of the control system [3,4].
In the past several decades, various nonlinear and robust control methods have been applied to the control system design of interceptors with multiple actuators [5]. In [6], a variable structure control is used in the control system design of interceptors with aerodynamic surfaces and reaction jets. Considering the coupling effect of the flight control system, a second order sliding mode control algorithm is designed for the autopilot system of the interceptor in [7]. Based on the extended state observer, an autopilot system is proposed to reduce couplings [8]. For an agile air to air interceptor, a robust backstepping control method is proposed in [9]. The θ-D method is a nonlinear suboptimal algorithm which solves the Hamilton–Jacobi–Bellman equation by adding perturbations to the cost function [10]. A nonlinear control law of an interceptor with tail fins and reaction jets is developed by the θ-D method in [11]. For the longitudinal autopilot design, a suboptimal control algorithm is proposed by the θ-D method [12]. μ-synthesis methods are also used in the flight control systems. In [13], a three-loop control law is developed via Hꝏ and μ-synthesis methods. Feedback linearization method is an effective approach to design nonlinear flight control systems [14,15]. For interceptors with dual control systems, a nonlinear control law is designed by input–output linearization [16]. However, the above methods do not fully consider the cooperation between discrete and continuous actuators and the problem of fault tolerance.
Since there is actuator redundancy in the interceptor control system, we need to consider the cooperation of different actuators. There are two types of actuators on the interceptor. The aerodynamic control surfaces are continuous while the reaction jets are discrete, which brings difficulty in the design of the control system. Control allocation is one of the effective approaches to solve actuator redundancy and handle actuator faults [17]. In [18], an observer-based adaptive variable structure control law is proposed for an interceptor with dual control systems by using a fuzzy allocation algorithm. Considering the autopilot dynamics of the interceptor with aerodynamic control surfaces and reaction jets, an adaptive control law is designed by sliding mode control and optimal control allocation [2]. For interceptors with blended aero-fin and lateral impulsive thrust, a classical control system with optimal control allocation module is designed in [19]. Approximate linear models are used in the above methods, which may be limited for implementing in a wide range of flight conditions. To realize the control of UAV with nonlinear characteristics, a fault tolerant controller is proposed by observer-based adaptive dynamic inversion [4]. Based on the boundary estimation, an adaptive fault-tolerant control algorithm is designed for attitude control under joint actuator faults and uncertain parameters [20]. An on-line sliding mode control allocation scheme for the fault tolerant control of aircraft is designed in [21]. Based on quadratic programming and integer linear programming techniques, a fault tolerant control method that includes a fault detection and control allocation algorithms is designed in [22]. For these optimization-based allocations, the mapping relationship between the virtual control command and the true control inputs is static. Compared to static control allocation, dynamic control allocation provides an additional degree of freedom to account for different actuators [23].
It is not appropriate to use traditional missiles to intercept drones from the perspective of cost performance, because missiles are more expensive and drones are cheaper. Unlike traditional intercepting missiles [24,25,26], drone interceptors are essentially flying hammers. Ramming interceptors are not single-use munitions, and each unit is actually supposed to fly multiple times. When designing the control system, it becomes more important to consider the fault tolerance of the system.
For the interceptor with aerodynamic surfaces and reaction jets, each pulse thrust has only two states of working and non-working. The thrust cannot be adjusted, and it cannot be stopped after starting until the work is completed, which has obvious discrete and nonlinear working characteristics. At the same time, the aerodynamic control system changes continuously. Therefore, the controller design of the whole is a challenging problem. In order to deal with this hybrid system and actuator fault tolerance problem, a fault weighting dynamic control allocation (FWDCA) algorithm is proposed.
In this paper, a fault tolerant autopilot system for interceptors with aerodynamic surfaces and reaction jets is designed. The autopilot system involves a fault weighting dynamic control allocator and a virtual control law. First, an FWDCA algorithm is developed. Then, a robust virtual control law is designed by using command filtered backstepping [27] with a parameter update law to produce the virtual control effort signals for the interceptor with uncertainties. The dynamic control allocator distributes the virtual signals to the actuators on the interceptor by the FWDCA strategy.
This paper is organized as follows. Section 2 presents the nonlinear system model of an interceptor with dual control systems. In Section 3, the FWDCA algorithm is proposed for the interceptor with aerodynamic surfaces and reaction jets. In Section 4, a nonlinear virtual control law with a parameter update law is designed. Simulation results are shown in Section 5 and conclusions are given in Section 6.
2. Nonlinear Model of the Interceptor
For a drone interceptor with aerodynamic surfaces and reaction jets, the nonlinear model can be expressed as
where , , and ϕ are the angle of attack, sideslip angle, pitch angle and roll angle, respectively; , and are roll, pitch, and yaw rotational rates, respectively; , and are the moments of inertia; , and are aerodynamic forces along the x, y and z axis, respectively; , and are aerodynamic moments in roll, pitch and yaw, respectively. The aerodynamic forces and moments can be expressed as
where is dynamic pressure; is reference surface; is reference length; , , , , and are aerodynamic coefficients. These coefficients can be expressed by angle-of-attack, sideslip angle, angular rates, and control surface deflection as
where , , and are aerodynamic force coefficients; , , , , , , and are aerodynamic moment coefficients. In order to track the normal acceleration commands, two augmented system states are designed as
where and are normal acceleration commands; and are normal accelerations. For the divert acceleration is maintained by the aerodynamic lift, the acceleration can be approximately expressed as
where and are accelerations along the y and z axes of the interceptor body frame, respectively. Define the system states , , and the control inputs as
Taking Equations (1)–(3) into account and considering the choices of , , and , we rearrange the dynamic model of the interceptor as
where the control matrix and , , , , and can be calculated from Equations (1)–(3) and is not given due to the length of the paper. , and are the system uncertainties. Suppose , and are norm bounded as
where are unknown constants and .
3. Fault Weighting Dynamic Control Allocation
3.1. Fault Weighting Dynamic Control Allocation Strategy
Considering the system (8) subject to actuator faults, we can rewrite the third Equation (8) as
where the effectiveness gain . The parameters and satisfy , . If means the ith actuator works perfectly, and if means a fault occurs.
Proceeding to Equation (10), the control matrix is
where , , , , . The variables with the same control effort are combined to form the virtual control inputs as
Considering (12), we divide as
where . Following the transformation of the control allocation, the original system has four control inputs changed to two virtual inputs. The advantage is that it is convenient to deal with system redundancy and fault tolerance issues. Then, in Equation (10) and virtual control in Equation (12) can be expressed as
The virtual control law is not the actual control effort of individual actuator. The virtual control law is required to be distributed to actual actuators by FWDCA algorithm. Suppose the constraint of the control input is given by [23].
where
and is the sampling time; is the maximal actuator rates. The command is determined by solving the mixed optimal problem
subject to
where is the desired steady state control input; , and are the positive definite weighting matrices. The fault weighting dynamic control allocation will depend on the effectiveness of the actuators. In the fault free case, . When faults occur, the associated actuator will be weighted heavily since becomes small.
The reaction control force of the interceptor is large enough. In fact, if we do not consider the consumption of the reaction pulse thrust, the output of the reaction control system can directly act as normal accelerations, so the response speed is almost without delay. We only need to adjust the appropriate parameters and allocate more control to the reaction force system to ensure that the system will not be saturated, but at the same time we need to balance the consumption of the reaction force system.
3.2. Fault Estimation
The actuator dynamics can be expressed as [16]
where , , and are command variables; and are time constants of fins actuators and reaction jets, respectively. The actuators of aerodynamic control surfaces are slow, whereas reaction jets are fast. In the presence of an actuator fault, the ith actuator dynamics can be rewritten as
where and are the time constant and command variable of ith actuator. To estimate values for the loss of effectiveness, a group of observers are designated as
where is the output of the ith observer, is the output error feedback coefficient of the state observer and is the estimated value of the loss in effectiveness. The error dynamics have the following form
where and . The adaptive law of is designed as
where . Consider the following Lyapunov function
The derivative of the Lyapunov function (25) is
By substituting Equation (24) into Equation (26), we obtain
Define a set . When , we have . Hence, . Note that the command in Equation (23). Therefore, if , we obtain . By Applying LaSalle’s invariance principle, we find that the only solution that can stay identically in is the trivial solution . Thus, we obtain and .
3.3. Desired Steady State Control Input
Suppose the desired steady state control input is . With the pitch loop as an example, the decoupled linearized equations are given by
where , , , , . It follows from Equations (28) and (29) that the angle-of-attack and the pitch rate at a steady state satisfy
Substituting Equations (28) and (31) into Equation (30), we obtain
The normal acceleration is principally maintained by the angle-of-attack, so that we choose and is obtained as
By the same approach, we obtain the steady input in yaw loop as
Remark 1:
The three weighting matrices play important roles in the control allocation algorithm. A largeensures the corresponding actuator converges fast to its desired position; A largemakes the actuator move slowly; a largeprevents the actuator from consuming too much energy. The design parametercan be seen as the forward control input, it does not affect the system stability and does not need to be known precisely. Therefore, we use a decoupled approximate model to design.
4. Nonlinear Virtual Control Law Design
4.1. Virtual Control Law
Define the tracking error vectors as
where is the tracking command, and are the command filtered terms which can be obtain by the following filters
with and as the outputs of the filters, where . Therefore, represents the unachieved portion of . and are design parameters. is picked as the small perturbation in virtual control law design.
Define the boundary layer
where and is “quasi-steady-state” of the command filter. By setting the small perturbation parameter , the unique “quasi-steady-state” solution to thecommand filter is obtained as or and . The proposed virtual control law can be obtained in the following steps.
Step 1. The time derivative of is calculated as
The Lyapunov function candidate is chosen as
The derivative of along the system trajectories satisfies
Observing Equations (9) and (40), we design the virtual control law as
where ,, is a hyperbolic tangent function and the parameter is designed as
with the adaptation gain and . Consider the augmented Lyapunov function candidate
where . The derivative of along the system trajectories is given by
The function satisfies the following property [1]
where is a positive constant. Substituting Equation (45) into Equation (44), we have
By considering , we obtain
where can be made arbitrarily small by choosing and , which is small enough.
The time derivative of is given as
The virtual control law is chosen as
where , and the parameter is designed as
with the adaptation gain and . Define and consider the augmented Lyapunov function candidate
The derivative of along the system trajectories is given by
where can be made arbitrarily small by choosing and , which is small enough.
The time derivative of is
The virtual control law is designed as
where , and the parameter is designed as
with the adaptation gain and . Define and choose a Lyapunov function candidate as
Substituting Equations (54) and (55) into Equation (56), we obtain the derivative of as
where . Define and , we obtain
This implies that when . Therefore, the error states are bounded and converge to an arbitrarily small invariant set
Step 2. Replacing , in terms and by to compensate the tracking dynamics of the command filters, we can rewrite the virtual control law as
where is defined as
where . The compensation is chosen as
with and . If the signals are tracked well, the compensation terms and are zeros and , . The tracking error can be guaranteed. However, the signals are not always well tracked. The stability analysis is give in the following.
4.2. Stability Analysis
First, a useful concept is introduced before the stability analysis. If there exists positive constants and , such that , and , the signal are said to be order of , denoted as [14]. Since , it is straightforward to calculate that
Choose a Lyapunov function candidate as
The time derivative of is
We can ensure that the compensated tracking error converges to an arbitrarily small neighborhood of zero exponentially. Further, by choosing proper parameters , and , we have .
Because the order of the nonlinear system is high, the stability of and are addressed in the following by the perturbation theory to reduce the complexity of the analysis.
Define the state vectors and as
The derivatives of and are expressed as
where and are obtained based on Equations (1)–(3). Considering the perturbation theory [14], we obtain that the system stability, as determined by the boundary layer. We set
In the time scale, the derivative of is obtained as
where is written as
The matrix is Hurwitz. Thus, the boundary layer model is stable and . Through the above stability analysis, we obtain that the tracking errors can converge to an arbitrarily small neighborhood of zero.
Remark 2:
In conventional command filtered backstepping control, Young’s inequalityis used to counteract the bounded uncertainty by the nonlinear damping term [12]. The system error states will converge to an arbitrarily small neighborhood of zero, if we choose as small as possible. However, excessive reduction of the parameter enlarges the nonlinear damping term, which is undesirable. In the proposed approach, the hyperbolic tangent function is introduced to deal with the system uncertainty. Since , even if is selected as a very small constant, the virtual control signal will not become very large.
5. Simulation Results
In this section, the performance of the proposed fault tolerant control law for the interceptor is investigated by numerical simulations. The tracking acceleration commands are set to be and ; One pulse thrust can produce a force of 2500 N. The aerodynamic coefficients are obtained from [16]. The parameters of the virtual control law are chosen as , and ; The parameters of command filter are chosen as and ; The matrices , and are chosen as , and . The parameters and are and . The desired control inputs and are chosen as and . In the simulation, the proposed fault tolerant control law is compared with the feedback linearization (FL) control law. The simulation results for the interceptor are shown in Figure 1, Figure 2 and Figure 3.
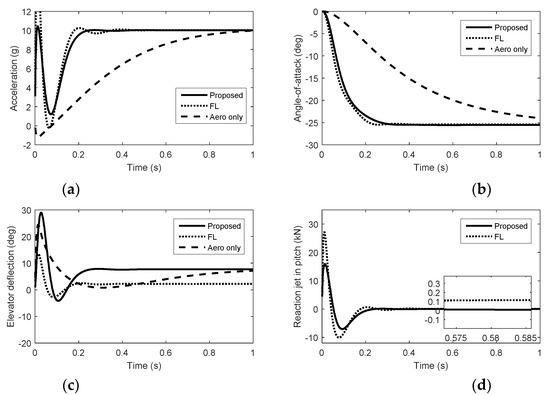
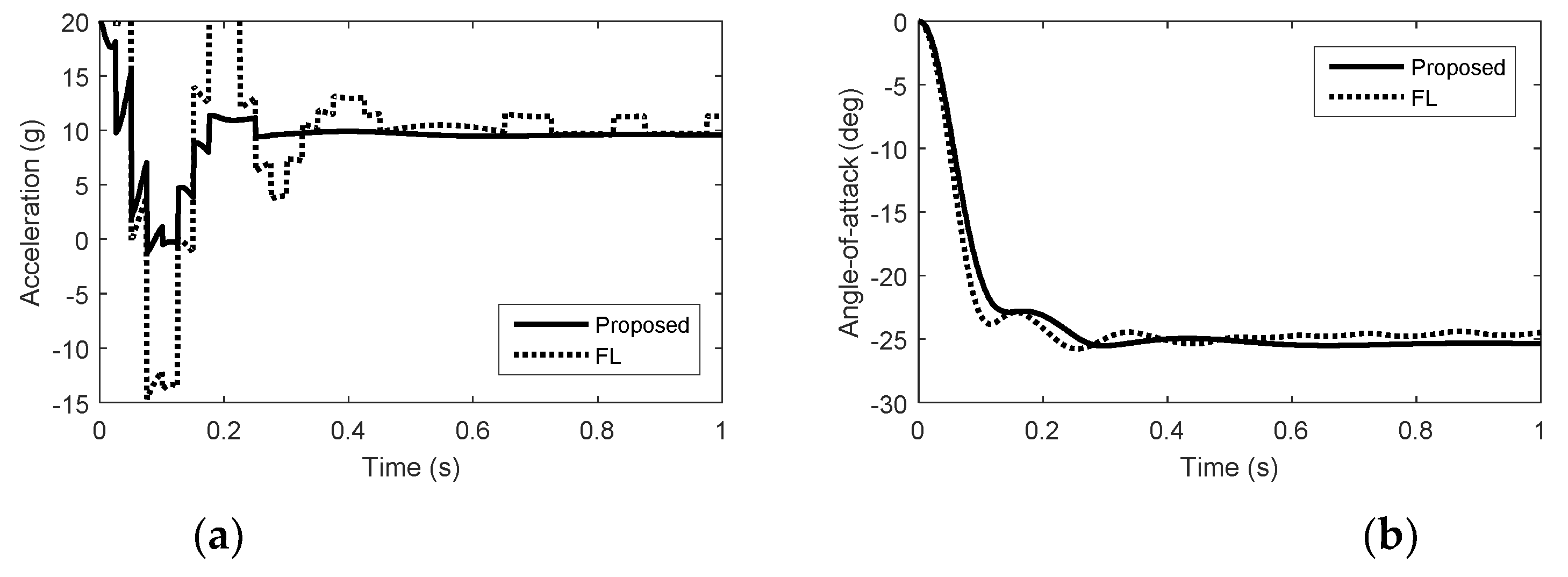
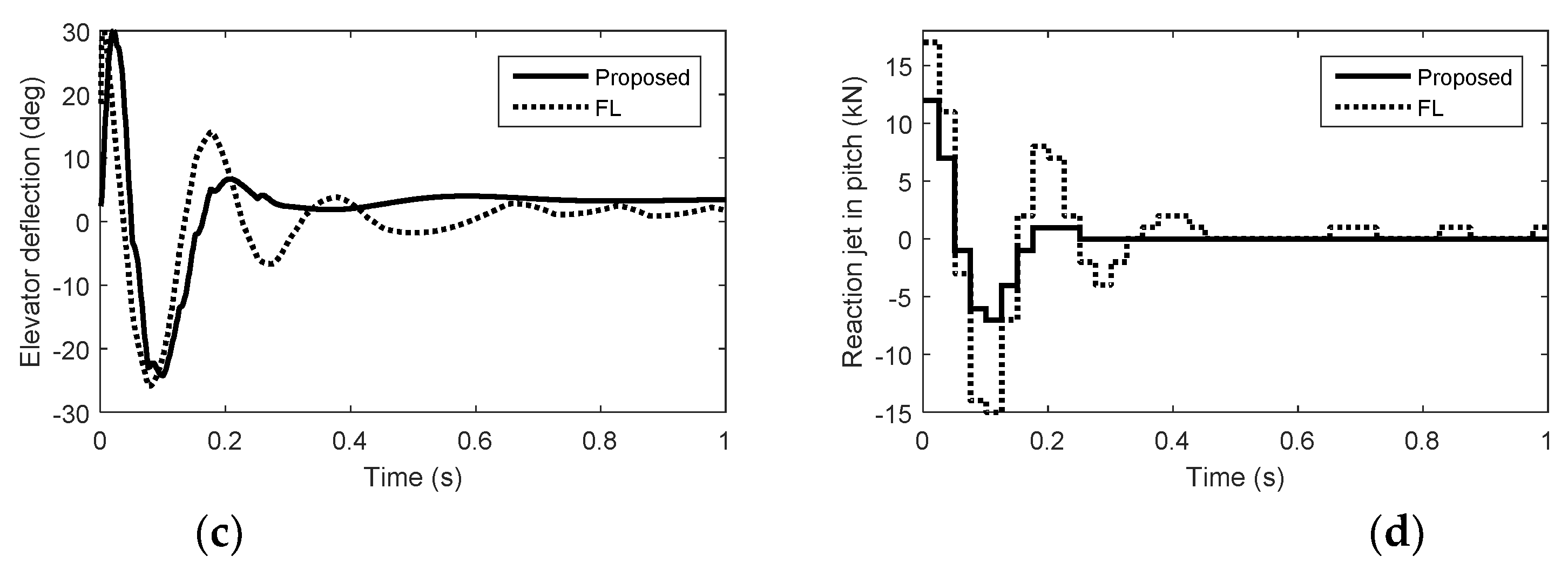
Figure 1.
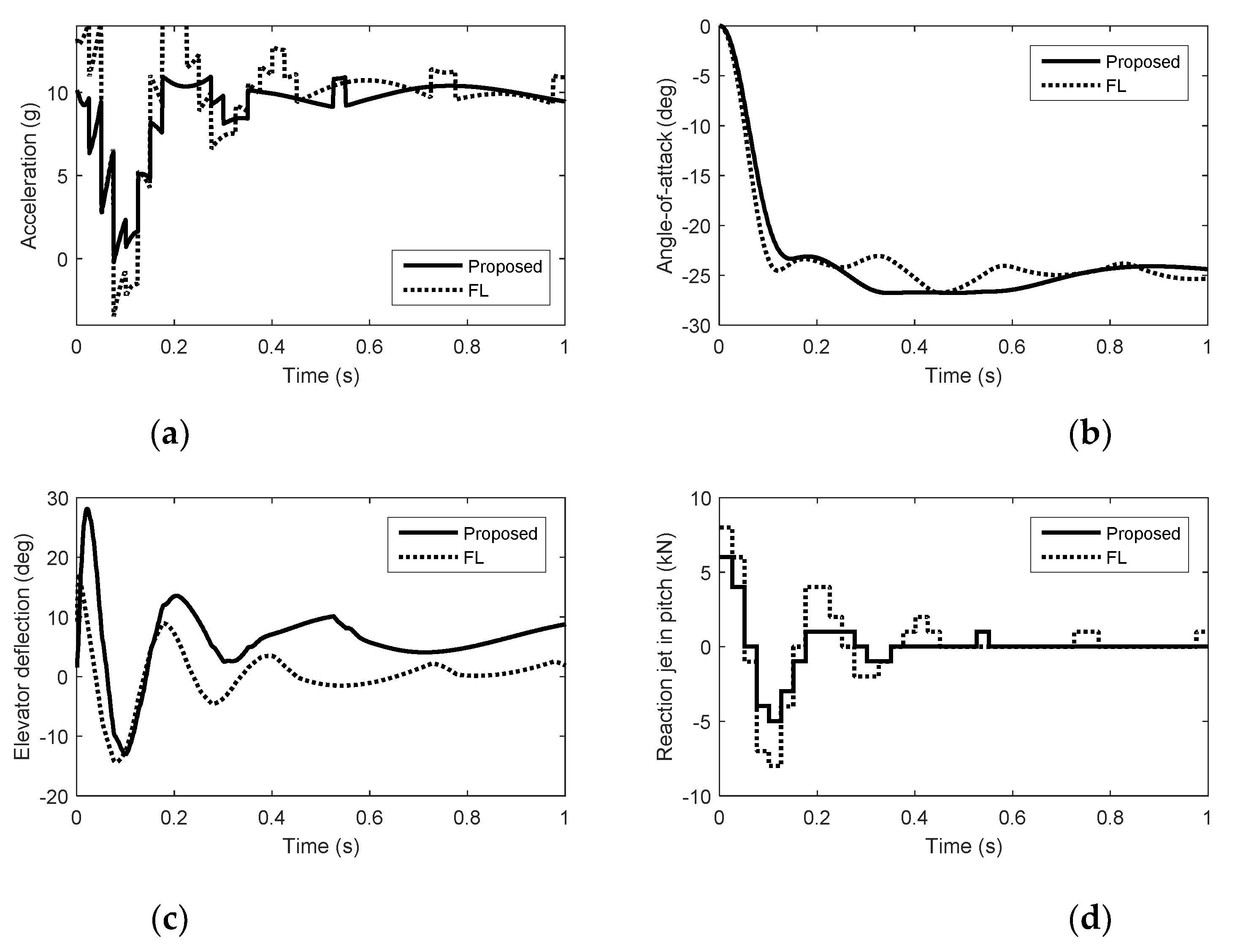
Simulation results in pitch. (a) Acceleration. (b) Angle of attack. (c) Elevator deflection. (d) Reaction jet in pitch.
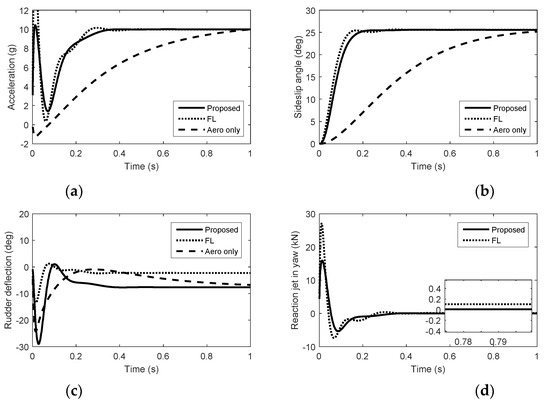
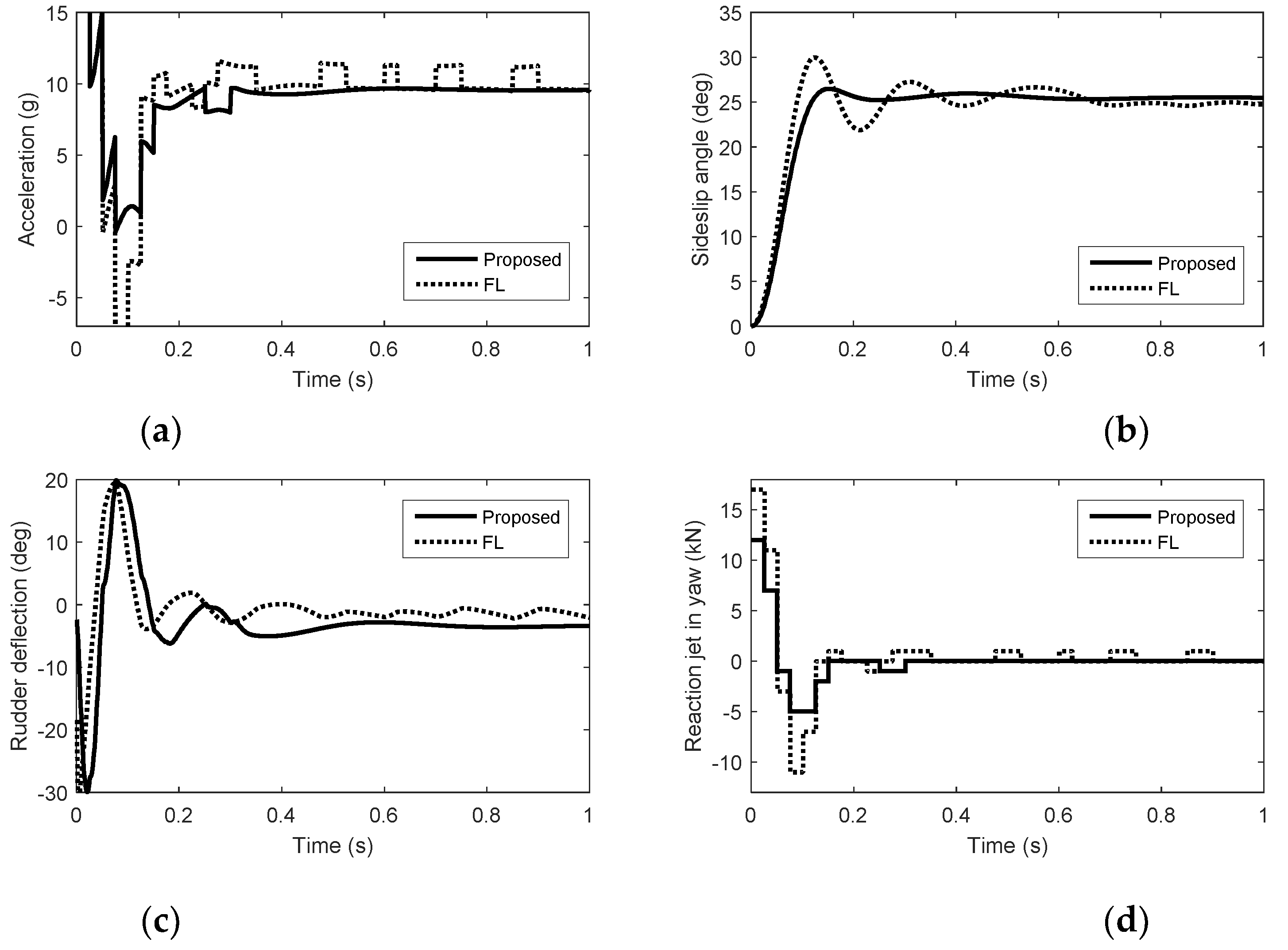
Figure 2.
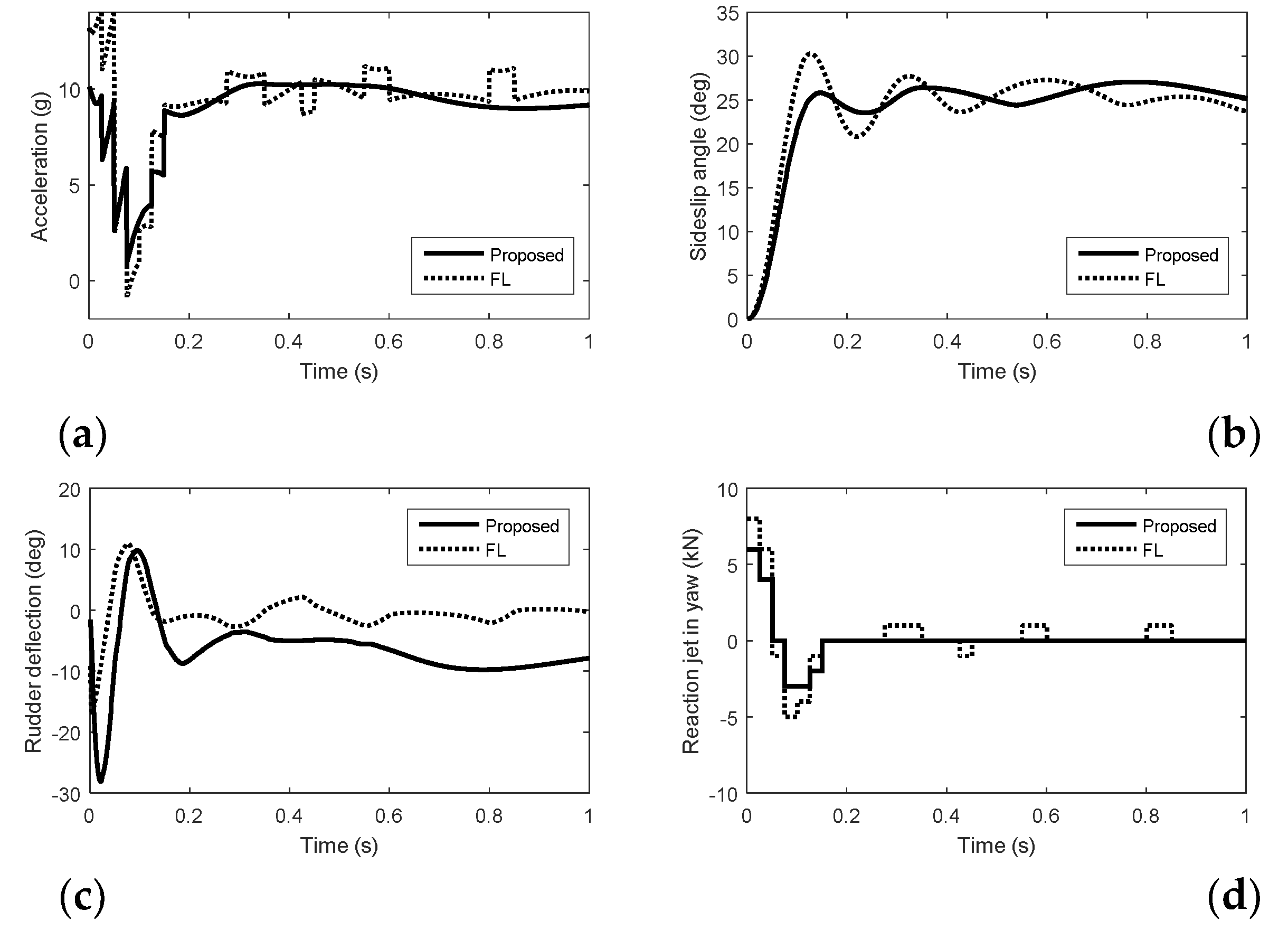
Simulation results in yaw. (a) Acceleration. (b) Sideslip angle. (c) Rudder deflection. (d) Reaction jet in yaw.
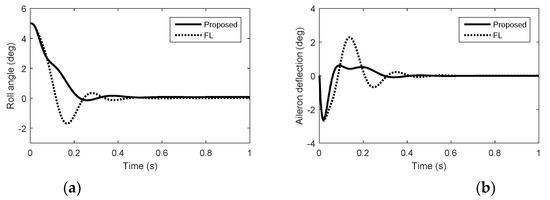
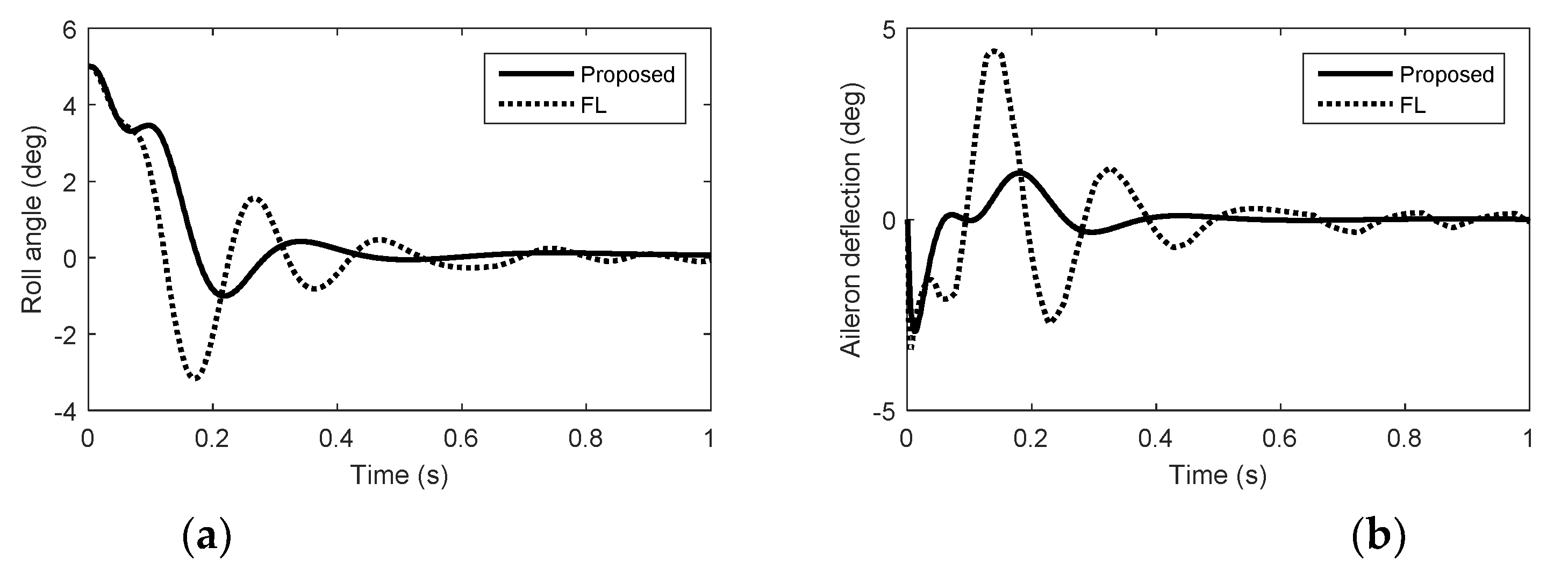
Figure 3.
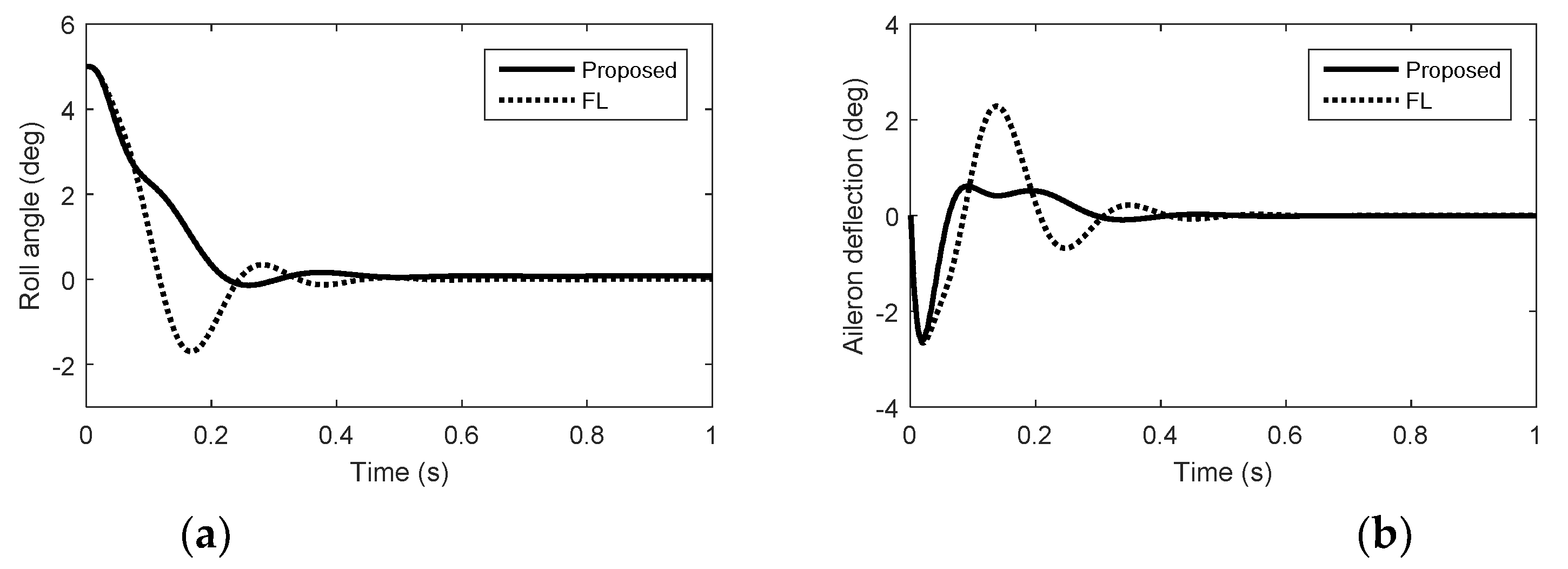
Simulation results in roll. (a) Roll angel. (b) Aileron deflection.
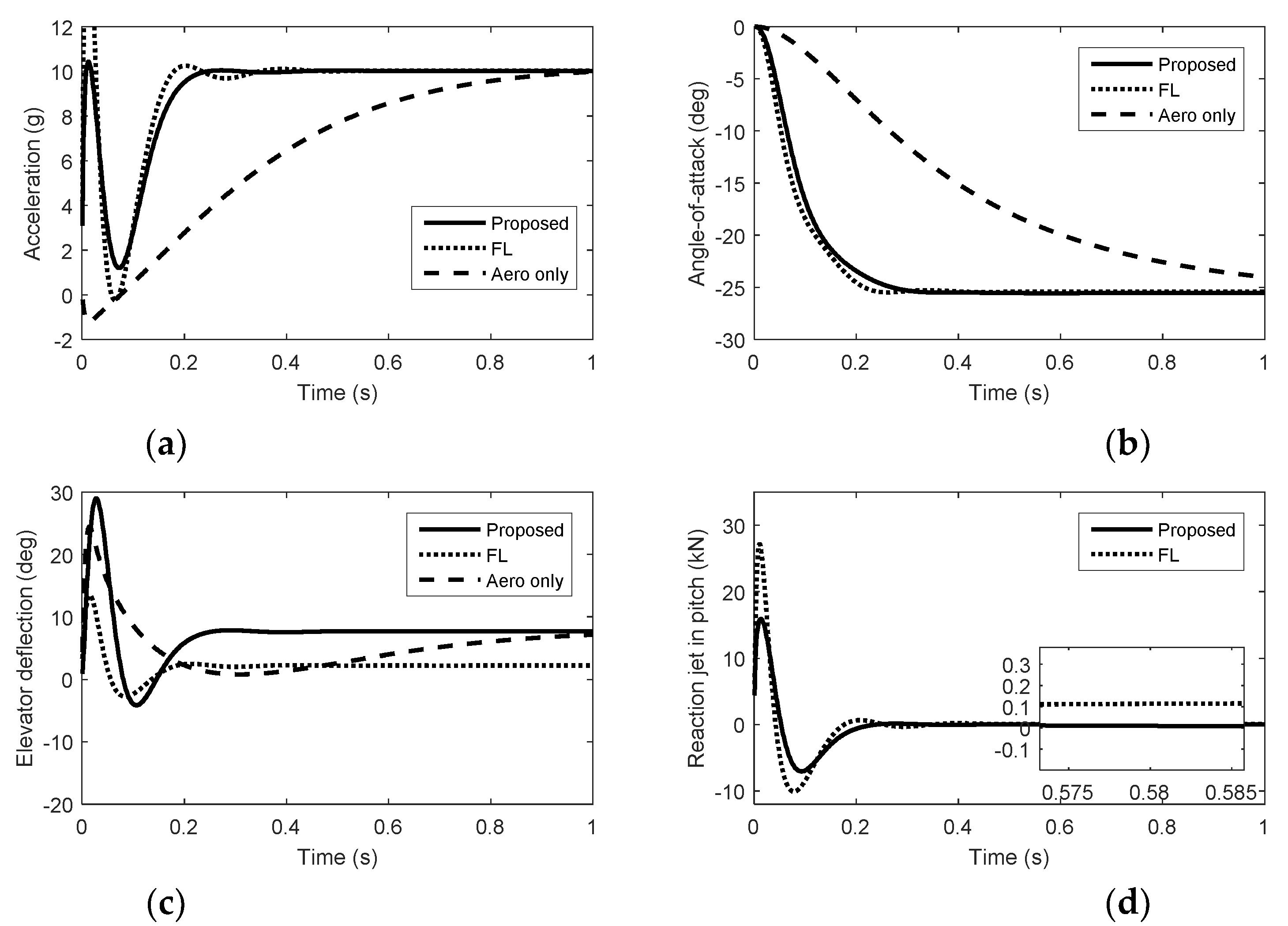
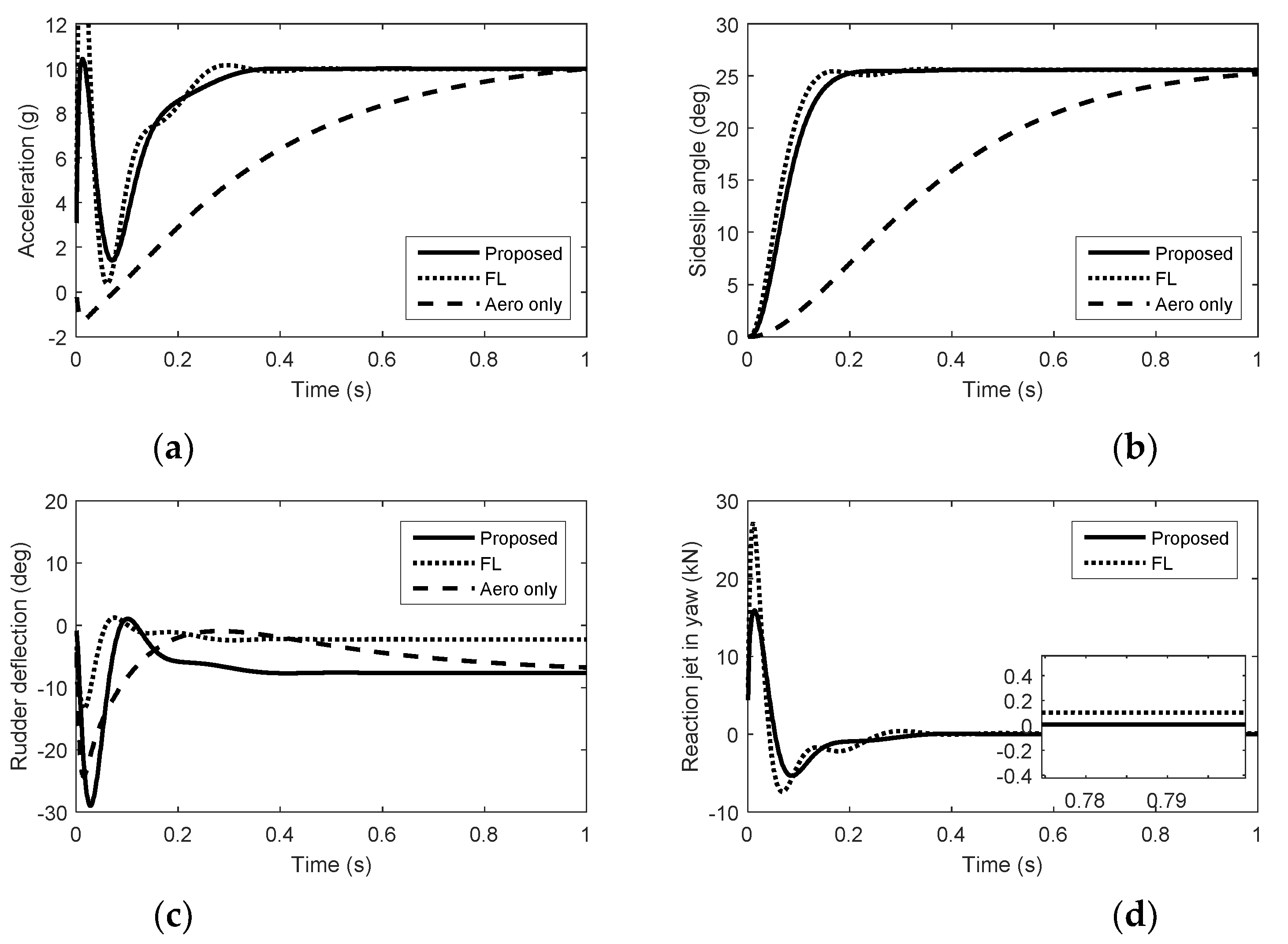
From Figure 1, Figure 2 and Figure 3, we can see that there is nonminimum phase phenomenon when the interceptor controlled purely by aerodynamic control surfaces. The acceleration response delay is large and the rise time under pure aerodynamic control is about 0.9 s. The introduction of the reaction system effectively compensates for this delay, significantly improving the speed of maneuver tracking. The interceptor with aerodynamic surfaces and reaction jets, under the proposed method and FL approach, there are no minimum phase phenomenon. The norm accelerations under the proposed method and FL are both stabilized after 0.2 s. However, the elevator and rudder deflections under FL are smaller than that under the proposed method and the forces generated by reaction jets under FL are larger than that under the proposed method, because under FL, the reaction jets and tail fins counteract each other after the angle-of-attack and sideslip angle have been generated. Therefore, it is hard to reach the fullest potential of aerodynamic control surfaces by the blending principle of FL. For the agile interceptor with two different types of actuators, the acceleration commands can be tracked by several combinations of inputs of the actuators. In the proposed approach, reaction jets cooperate with aerodynamic control surfaces very well and the fast response of the acceleration command can also be realized with less energy of the reaction jets by regulating the control allocation parameters. When the angle-of-attack and sideslip angle have been generated, the deflections of elevator and rudder under the proposed method are close to the case of aero only. The forces of reaction jets and aerodynamic control surfaces counteract each other under FL, which means the energy of the reaction jets is still consumed when the angle-of-attack and sideslip angle have been generated.
In practical applications, the reaction jets are pulsed control effectors modeled as zero-order holders with a sample time of 25 ms. Simulation results with quantization errors are given in Figure 4, Figure 5 and Figure 6.
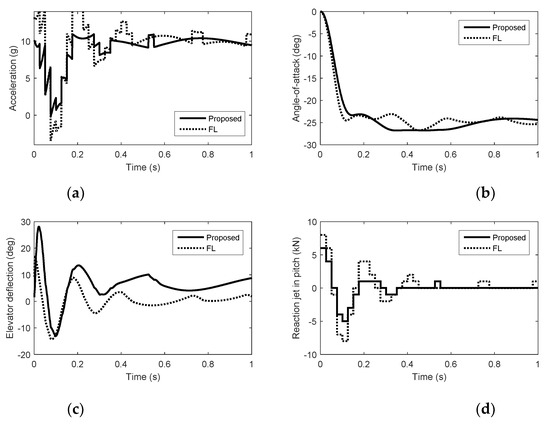
Figure 4.
Simulation results in pitch with quantization errors. (a) Acceleration. (b) Angle of attack. (c) Elevator deflection. (d) Reaction jet in pitch.
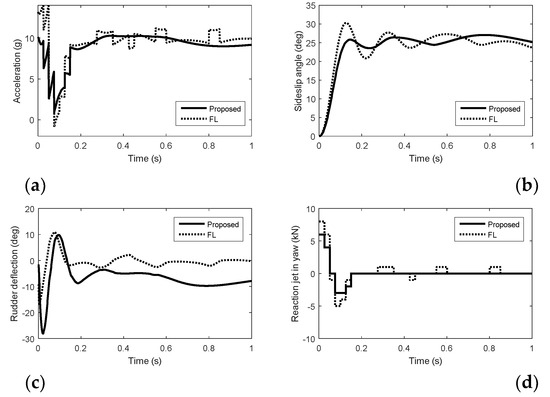
Figure 5.
Simulation results in yaw with quantization errors. (a) Acceleration. (b) Sideslip angle. (c) Rudder deflection. (d) Reaction jet in yaw.
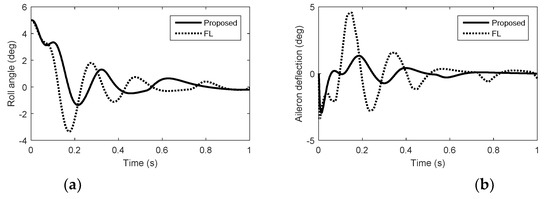
Figure 6.
Simulation results in roll with quantization errors. (a) Roll angel. (b) Aileron deflection.
The control system tracks the acceleration command smoothly under the proposed method than that under FL when the angle-of-attack and sideslip angle have been generated, because the norm acceleration is maintained by both aerodynamic control surfaces and reaction jets under FL. In Figure 1, Figure 2 and Figure 3, we can see that the forces of the reaction jets under FL in pitch and yaw do not converge to zero when the acceleration commands are tracked. In Figure 4, Figure 5 and Figure 6, when the angle-of-attack and sideslip angle are built up, the reaction jets under FL are still involved in controlling the attitude of the interceptor. The amount of pulse thrust consumption in pitch and yaw under the proposed method are 30 and 18, respectively, while the amount of pulse thrust consumption in pitch and yaw under FL are 57 and 33, respectively. Since the cooperation problem of the two different actuators are fully considered, the response speed of the proposed autopilot system is ensured while the consumption of pulse thrusts is reduced.
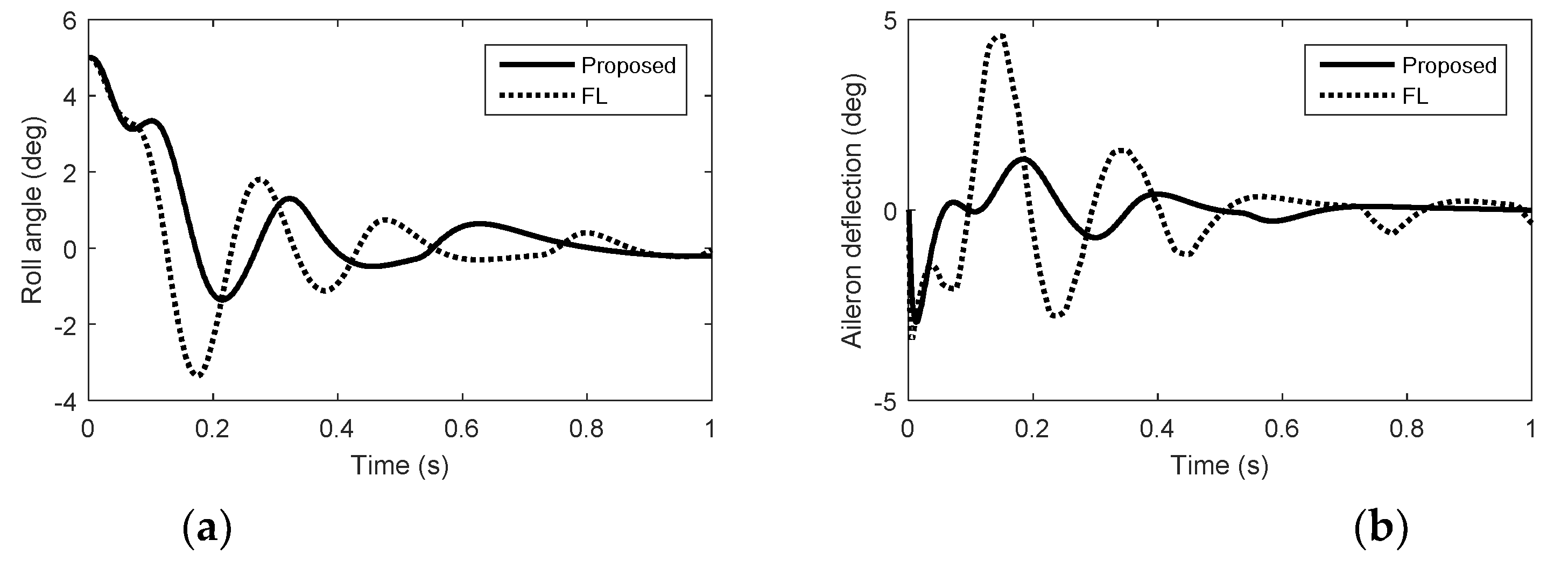
In the actuator fault case, we consider the damage of the aerodynamic control surfaces and the reaction control system failure due to the interactions between the airflow and the reaction jets. We suppose that the aerodynamic control surfaces lose 60% effectiveness and the reaction jets lose 50% effectiveness. Simulation results with quantization errors are given in Figure 7, Figure 8 and Figure 9. In Figure 7, Figure 8 and Figure 9, we can see that the autopilot system with FWDCA tracks norm acceleration commands fast and smoothly in the presence of the quantization errors and actuator faults. At 0.1 s, the acceleration under FL becomes negative, which is unexpected. The amount of pulse thrust consumption in pitch and yaw under the proposed method are 41 and 36, respectively, while the amount of pulse thrust consumption in pitch and yaw under FL are 106 and 61, respectively. Compared with no actuator faults, the amount of pulse thrust consumption increases by 60.4% under the proposed method, whereas the amount of pulse thrust consumption increases by 85.6% under the FL. In the case of actuator faults, the cooperation of the actuator of the proposed method is still better than FL.
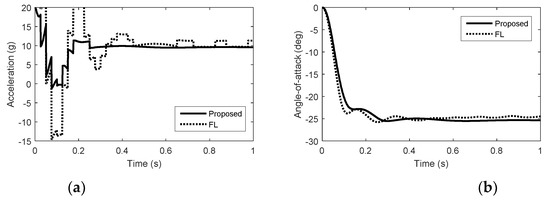
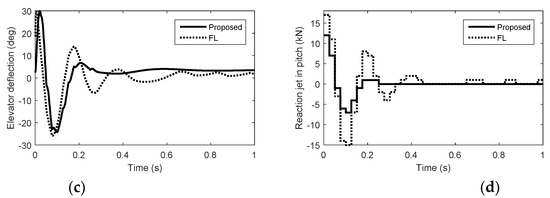
Figure 7.
Simulation results in pitch with quantization errors and actuator faults. (a) Acceleration. (b) Angle of attack. (c) Elevator deflection. (d) Reaction jet in pitch.
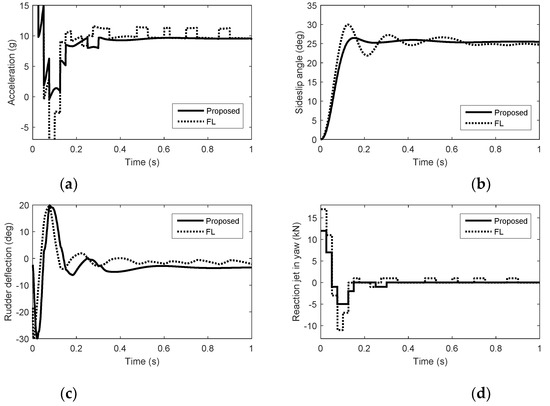
Figure 8.
Simulation results in yaw with quantization errors and actuator faults. (a) Acceleration. (b) Sideslip angle. (c) Rudder deflection. (d) Reaction jet in yaw.
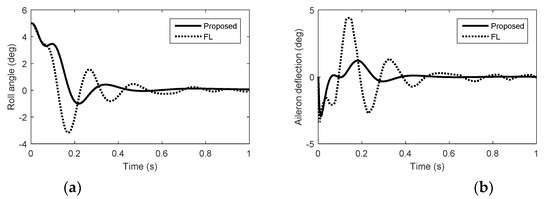
Figure 9.
Simulation results in yaw with quantization errors and actuator faults. (a) Roll angel. (b) Aileron deflection.
6. Conclusions
In this paper, a fault tolerant control system with FWDCA is proposed for the interceptor with aerodynamic control surfaces and reaction jets in the presence of quantization errors and actuator faults. The nonlinear control system of the interceptor consists of a robust virtual control law and an FWDCA algorithm. The adaptive virtual control law is proposed by using command filtered backstepping with a parameter update law to produce virtual control signals. The hyperbolic tangent function is introduced to reduce the value of the nonlinear damping term. The FWDCA algorithm is proposed to optimally allocate the virtual signals to the actuators. In the proposed method, the cooperation problem of aerodynamic control surfaces and reaction jets is considered, the consumption of reaction jets is reduced. Simulation results show that the proposed control system tracks norm acceleration commands fast and smoothly under the quantization errors and actuator faults.
Author Contributions
Conceptualization, B.X. and J.Z.; methodology, B.X.; software, Q.M.; validation, B.X., Q.M. and J.F.; formal analysis, B.X.; investigation, B.X.; resources, Q.M.; data curation, Q.M.; writing—original draft preparation, B.X.; writing—review and editing, Q.M. and J.Z.; visualization, J.F.; supervision, B.X.; project administration, B.X.; funding acquisition, B.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China grant number 61603183, Open Project Funds for the Key Laboratory of Space Photoelectric Detection and Perception, Ministry of Industry and Information Technology grant number NJ2022025-06, and Fundamental Research Funds for the Central Universities grant number NJ2022025.
Data Availability Statement
Data sharing is not applied.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, D.; Xu, B. Adaptive dynamic surface guidance law with input saturation constraint and autopilot dynamics. J. Guid. Control Dyn. 2016, 39, 1152–1159. [Google Scholar] [CrossRef]
- Xu, B.; Zhou, D.; Liang, Z.; Zhou, G. Robust adaptive sliding sector control and control allocation of a missile with aerodynamic control surfaces and reaction jets. Proc. Inst. Mech. Eng. Part G: J. Aerosp. Eng. 2017, 231, 397–406. [Google Scholar] [CrossRef]
- Puchalski, R.; Giernacki, W. UAV fault detection methods, state-of-the-art. Drones 2022, 6, 330. [Google Scholar] [CrossRef]
- Dong, Z.; Liu, K.; Wang, S. Sliding mode disturbance observer-based adaptive dynamic inversion fault-tolerant control for fixed-wing UAV. Drones 2022, 6, 295. [Google Scholar] [CrossRef]
- Härkegard, O.; Glad, S.T. Resolving actuator redundancy—Optimal control vs. control allocation. Automatica 2005, 41, 137–144. [Google Scholar] [CrossRef]
- Thukral, A.; Innocenti, M. Sliding mode missile pitch autopilot synthesis for high angle of attack maneuvering. IEEE Trans. Control Syst. Technol. 1998, 6, 359–371. [Google Scholar] [CrossRef]
- Han, T.; Hu, Q. Robust autopilot design for STT missiles with multiple disturbances using twisting control. Aerosp. Sci. Technol. 2017, 70, 428–434. [Google Scholar] [CrossRef]
- Mohammadi, M.R.; Jegarkandi, M.F.; Moarrefianpour, A. Robust roll autopilot design to reduce couplings of a tactical missile. Aerosp. Sci. Technol. 2016, 51, 142–150. [Google Scholar] [CrossRef]
- Mattei, G.; Monaco, S. Nonlinear autopilot design for an asymmetric missile using robust backstepping control. J. Guid. Control Dyn. 2015, 37, 1462–1476. [Google Scholar] [CrossRef]
- Xin, M.; Balakrishnan, S.N. A new method for suboptimal control of a class of non-linear systems. Optim. Control Appl. Methods 2005, 26, 55–83. [Google Scholar] [CrossRef]
- Li, Q.; Zhou, D. Nonlinear autopilot design for interceptors with tail fins and pulse thrusters via θ-D approach. J. Syst. Eng. Electron. 2014, 25, 273–280. [Google Scholar] [CrossRef]
- Xin, M.; Balakrishnan, S.N. Nonlinear H∞ missile longitudinal autopilot design with θ-D method. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 41–56. [Google Scholar] [CrossRef]
- Choi, B.; Kang, S.; Kim, H.J.; Jun, B.E.; Lee, J.I.; Tahk, M.J.; Park, C. Roll-pitch-yaw integrated μ-synthesis for high angle-of-attack missiles. Aerosp. Sci. Technol. 2012, 23, 270–279. [Google Scholar] [CrossRef]
- Khalil, H. Nonlinear Systems, 3rd ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 2002. [Google Scholar]
- Hu, Q.; Li, B.; Zhang, Y. Robust attitude control design for spacecraft under assigned velocity and control constraints. ISA Trans. 2013, 52, 480–493. [Google Scholar] [CrossRef]
- Zhou, D.; Shao, C. Dynamics and autopilot design for endoatmospheric interceptors with dual control systems. Aerosp. Sci. Technol. 2009, 13, 291–300. [Google Scholar] [CrossRef]
- Johansen, T.A.; Fossen, T.I. Control allocation—A survey. Autom. 2013, 49, 1087–1103. [Google Scholar] [CrossRef]
- Chang, Y.; Yuan, R.; Tan, X.; Yi, j. Observer-based adaptive sliding mode control and fuzzy allocation for aero and reaction jets’ missile. Proc. Inst. Mech. Eng. Part G: J. Aerosp. Eng. 2016, 230, 498–511. [Google Scholar] [CrossRef]
- Xing, L.; Zhang, K.; Chen, W. Optimal Control and Output Feedback Considerations for Missile with Blended Aero-fin and Lateral Impulsive Thrust. Chin. J. Aeronaut. 2010, 23, 401–408. [Google Scholar]
- Lei, R.; Chen, L. Adaptive fault-tolerant control based on boundary estimation for space robot under joint actuator faults and uncertain parameters. Def. Technol. 2019, 15, 964–971. [Google Scholar] [CrossRef]
- Alwi, H.; Edwards, C. Fault tolerant control using sliding modes with on-line control allocation. Autom. 2008, 44, 1859–1866. [Google Scholar] [CrossRef]
- He, J.; Qi, R.; Jiang, R.; Zhai, R. Fault-tolerant control with mixed aerodynamic surfaces and RCS jets for hypersonic reentry vehicles. Chin. J. Aeronaut. 2017, 30, 780–795. [Google Scholar] [CrossRef]
- Härkegard, O. Dynamic control allocation using constrained quadratic programming. J. Guid. Control Dyn. 2004, 27, 1028–1034. [Google Scholar] [CrossRef]
- Brierley, S.D. and Longchamp, R. Application of sliding-mode control to air-air interception problem. IEEE Trans. Aerosp. Electron. Syst. 1990, 26, 306–325. [Google Scholar] [CrossRef]
- Manchester, I.R.; Savkin, A.V. Circular navigation missile guidance with incomplete information and uncertain autopilot model. J. Guid. Control Dyn. 2004, 27, 1078–1083. [Google Scholar]
- Reisner, D. and Shima, T. Optimal guidance-to-collision law for an accelerating exoatmospheric interceptor missile. J. Guid. Control Dyn. 2013, 36, 1695–1708. [Google Scholar] [CrossRef]
- Dong, W.; Farrell, J.A.; Polycarpou, M.M.; Djapic, V.; Sharma, M. Command filtered adaptive backstepping. IEEE Trans. Cotrol Syst. Technol. 2012, 20, 566–580. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).