

Object Detection-Based System for Traffic Signs on Drone-Captured Images
 ,
, 
Abstract
:1. Introduction
- Increasing dependence on poorly interoperable proprietary technologies.
- The risk that they entail for people, other vehicles, and property.
2. Related Work
- Small object detection. Objects are usually small in size in UAV images, and deep neural networks based on convolution kernels usually overlook or heavily compress small objects’ intrinsic features and patterns, especially when the images have a high resolution.
- Occlusion. The objects are generally occluded by other objects or background obstacles in drone-based scenes.
- Large-scale variations. The objects usually have a significant variation in scale, even for objects of the same class.
- Viewpoint variation. Since the dataset contains images captured from a top-view angle, while other images might be captured from a lower-view angle, the features learned from the object at different angles are not transferable in principle.
3. Proposed Solution
3.1. Dataset Collection
3.1.1. Dataset for Preliminary Study
3.1.2. Datasets Used
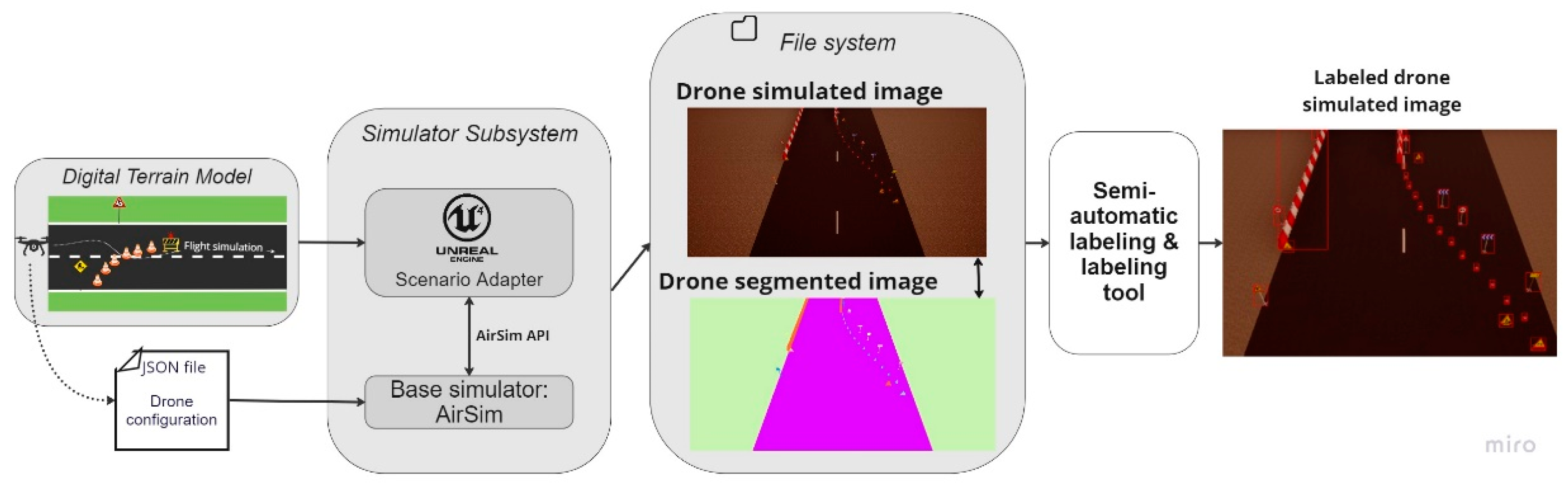
3.1.3. Videos Generated with AirSim (Drone Simulation Environment)
3.1.4. Images from Drone Flight Videos
3.1.5. Cones Dataset
3.1.6. Dataset Used in Training
3.2. Election and Training of the Object Detection Model
- A region proposal algorithm is used to create bounding boxes or locations of potential objects in the image. In the R-CNN architecture, it is an algorithm such as Edge Boxes.
- A feature generation stage is used to gather information about these objects’ features, so a CNN is generally used.
- A final stage of final classification determines the object’s class.
- A regression layer is used to improve the accuracy of the object’s bounding box coordinates.
3.3. Geolocation of Detected Traffic Signs
- Establish the transformation formula of the pixel coordinate frame to the East-North-Up (ENU) frame through the camera frame. For this purpose, the rotation of the ENU frame matrix of the drone camera is calculated. The position of the drone in ENU frame values is obtained.
- Calculate the position of the signal in the image using the image size and the bounding box.
- Finally, calculate the target signal’s depth and the target’s latitude and longitude in terms of the target position in the ENU frame. Transform the ENU frame coordinates into the World Geodetic System (GPS coordinates).
4. Results and Discussion
4.1. Evaluation of the Object Detection Model
4.1.1. Evaluation Metrics
- Precision (P): is the ratio of True Positive (TP) detections to all positive detections, including False Positives (FP).
- Recall (R): is the ratio of True Positive (TP) detections to all real positives, including those that were not detected, that is, False Negatives (FN).
- Precision/recall curve (p(r)): is produced by combining the two previous metrics. The precision-recall curve helps to select the best threshold that maximizes both precision and recall.
- IoU (Intersection over Union): is a metric that measures the degree to which the real boundary box, which is frequently manually labeled, and the predicted boundary box overlap, as it is shown in Figure 13. This is the parameter used to establish a threshold to discriminate between a false positive and a true positive prediction (0 there is no overlap, 1 there is full overlap).

4.1.2. Evaluation with the New Dataset under PASCAL-VOC Challenge 2010+ Criteria
4.1.3. Evaluation with the New Dataset under Microsoft COCO 2016 Challenge Criteria
4.2. Detection Results
4.2.1. Detections on Images from Videos Generated by Drone Simulation Environment
4.2.2. Detections on Images from Drone Flight Videos
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADAS | Automated Driver Assistance Systems |
| AI | Artificial Intelligence |
| AP | Average Precision |
| CNN | Convolutional Neural Networks |
| DMNet | Density-Map guided object detection Network |
| ENU | East-North-Up |
| FP | False Positive |
| G-RCNN | Granulated R-CNN |
| GTSDB | German Traffic Sign Detection Benchmark |
| IoU | Intersection over Union |
| mAP | Mean Average Precision |
| P | Precision |
| R | Recall |
| R-CNN | Region-based CNN |
| R-FCN | Region-based Fully Convolutional Network |
| RoI | Region of Interest |
| RPN | Region Proposal Network |
| SSD | Single Shot MultiBox Detector |
| TP | True Positive |
| TSD | Traffic Sign Detection |
| UAS | Unmanned Aircraft Systems |
| UAV | Unmanned Aerial Vehicles |
| YOLO | You Only Look Once |
References
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the Unmanned Aerial Vehicles (UAVs): A Comprehensive Review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Nouacer, R.; Hussein, M.; Espinoza, H.; Ouhammou, Y.; Ladeira, M.; Castiñeira, R. Towards a Framework of Key Technologies for Drones. Microprocess. Microsyst. 2020, 77, 103142. [Google Scholar] [CrossRef]
- C4DConsortium ECSEL Comp4Drones. Available online: https://www.comp4drones.eu/ (accessed on 10 November 2022).
- C4DConsortium. D1.1—Specification of Industrial Use Cases Version 2.1; COMP4DRONES: Madrid, Spain, 30 April 2021. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS′16), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Pramanik, A.; Pal, S.K.; Maiti, J.; Mitra, P. Granulated RCNN and Multi-Class Deep SORT for Multi-Object Detection and Tracking. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 171–181. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Visison (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]
- Mittal, P.; Singh, R.; Sharma, A. Deep Learning-Based Object Detection in Low-Altitude UAV Datasets: A Survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, X.; Chan, S.; Chen, S.; Liu, H. Faster R-CNN for Small Traffic Sign Detection. In Proceedings of the Computer Vision; Yang, J., Hu, Q., Cheng, M.-M., Wang, L., Liu, Q., Bai, X., Meng, D., Eds.; Springer: Singapore, 2017; pp. 155–165. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 737–746. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle Detection in Aerial Imagery: A Small Target Detection Benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Wang, J.; Guo, W.; Pan, T.; Yu, H.; Duan, L.; Yang, W. Bottle Detection in the Wild Using Low-Altitude Unmanned Aerial Vehicles. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 439–444. [Google Scholar]
- Maldonado-Bascon, S.; Lafuente-Arroyo, S.; Gil-Jimenez, P.; Gomez-Moreno, H.; Lopez-Ferreras, F. Road-Sign Detection and Recognition Based on Support Vector Machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 264–278. [Google Scholar] [CrossRef]
- Ayachi, R.; Afif, M.; Said, Y.; Atri, M. Traffic Signs Detection for Real-World Application of an Advanced Driving Assisting System Using Deep Learning. Neural Process. Lett. 2020, 51, 837–851. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A Cascaded R-CNN With Multiscale Attention and Imbalanced Samples for Traffic Sign Detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Tabernik, D.; Skočaj, D. Deep Learning for Large-Scale Traffic-Sign Detection and Recognition. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1427–1440. [Google Scholar] [CrossRef]
- Tai, S.-K.; Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Jiang, X.; Yu, H. Deep Learning for Traffic Sign Recognition Based on Spatial Pyramid Pooling with Scale Analysis. Appl. Sci. 2020, 10, 6997. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Shen, L.; You, L.; Peng, B.; Zhang, C. Group Multi-Scale Attention Pyramid Network for Traffic Sign Detection. Neurocomputing 2021, 452, 1–14. [Google Scholar] [CrossRef]
- Li, X.; Xie, Z.; Deng, X.; Wu, Y.; Pi, Y. Traffic Sign Detection Based on Improved Faster R-CNN for Autonomous Driving. J. Supercomput. 2022, 78, 7982–8002. [Google Scholar] [CrossRef]
- Tsai, Y.; Wei, C.C. Accelerated Disaster Reconnaissance Using Automatic Traffic Sign Detection with UAV and AI. In Proceedings of the Computing in Civil Engineering 2019: Smart Cities, Sustainability, and Resilience, Atlanta, GE, USA, 17–19 June 2019; pp. 405–411. [Google Scholar] [CrossRef]
- Huang, L.; Qiu, M.; Xu, A.; Sun, Y.; Zhu, J. UAV Imagery for Automatic Multi-Element Recognition and Detection of Road Traffic Elements. Aerospace 2022, 9, 198. [Google Scholar] [CrossRef]
- Houben, S.; Stallkamp, J.; Salmen, J.; Schlipsing, M.; Igel, C. Detection of Traffic Signs in Real-World Images: The German Traffic Sign Detection Benchmark. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Ertler, C.; Mislej, J.; Ollmann, T.; Porzi, L.; Neuhold, G.; Kuang, Y. The Mapillary Traffic Sign Dataset for Detection and Classification on a Global Scale. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings of the Part XXIII 2020, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 68–84. [Google Scholar]
- Mathias, M.; Timofte, R.; Benenson, R.; Van Gool, L. Traffic Sign Recognition—How Far Are We from the Solution? In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Shakhuro, V.; Konushin, A.; NRU Higher School of Economics. Lomonosov Moscow State University Russian Traffic Sign Images Dataset. Comput. Opt. 2016, 40, 294–300. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Field and Service Robotics: Results of the 11th International Conference; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Traffic-Cone-Image-Dataset. Available online: https://github.com/ncs-niva/traffic-cone-image-dataset (accessed on 24 November 2022).
- Saryazdi, S. Duckietown LFV Using Pure Pursuit and Object Detection. Available online: https://github.com/saryazdi/Duckietown-Object-Detection-LFV/blob/dd08889a9e379c6cba85c24fb35743e6294c952f/DuckietownObjectDetectionDataset.md (accessed on 17 November 2022).
- Dai, H. Real-Time Traffic Cones Detection For Automatic Racing. Available online: https://github.com/MarkDana/RealtimeConeDetection (accessed on 23 November 2022).
- Ananth, S. Faster R-CNN for Object Detection. Available online: https://towardsdatascience.com/faster-r-cnn-for-object-detection-a-technical-summary-474c5b857b46 (accessed on 29 November 2022).
- Faster R-CNN—Torchvision Main Documentation. Available online: https://pytorch.org/vision/main/models/faster_rcnn.html (accessed on 12 September 2022).
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar]
- Mo, N.; Yan, L. Improved Faster RCNN Based on Feature Amplification and Oversampling Data Augmentation for Oriented Vehicle Detection in Aerial Images. Remote Sens. 2020, 12, 2558. [Google Scholar] [CrossRef]
- De Mello, A.R.; Barbosa, F.G.O.; Fonseca, M.L.; Smiderle, C.D. Concrete Dam Inspection with UAV Imagery and DCNN-Based Object Detection. In Proceedings of the 2021 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 24–26 August 2021; pp. 1–6. [Google Scholar]
- Aktaş, M.; Ateş, H.F. Small Object Detection and Tracking from Aerial Imagery. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 688–693. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Zhao, X.; Pu, F.; Wang, Z.; Chen, H.; Xu, Z. Detection, Tracking, and Geolocation of Moving Vehicle From UAV Using Monocular Camera. IEEE Access 2019, 7, 101160–101170. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Akyon, F.C.; Onur Altinuc, S.; Temizel, A. Slicing Aided Hyper Inference and Fine-Tuning for Small Object Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 966–970. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Commercial Drone Industry Trends Report; DroneDeploy: San Francisco, CA, USA, May 2018.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Detection Model | Traffic Sign Detection (TSD) | UAV Images/Videos | |||
|---|---|---|---|---|---|
| - Fast + | + Accuracy - | One-stage algorithms | YOLO | ||
| SSD | X | ||||
| YOLOv2 | X | X | |||
| YOLOv4 | |||||
| Two-stage algorithms | R-CNN | ||||
| Fast R-CNN | |||||
| Faster R-CNN | X | X | |||
| Mask R-CNN | X | ||||
| G-RCNN | |||||
| Cascade R-CNN | |||||
| CornetNet | |||||
| Flight No. | Images Captured | Height | Degrees | Direction |
|---|---|---|---|---|
| 1 | 533 | 20 m | 45° | Railway |
| 2 | 591 | 20 m | 45° | Parallel to railway |
| 3 | 234 | 30 m | Zenithal | Railway |
| 4 | 511 | 20 m | 35° | Railway |
| 5 | 596 | 20 m | 35° | Parallel to railway |
| 6 | 573 | 20 m | 50° | Railway |
| 7 | 530 | 20 m | 50° | Parallel to railway |
| 8 | 437 | 12 m | 45° | Railway |
| 9 | 525 | 15 m | 45° | Zig zag |
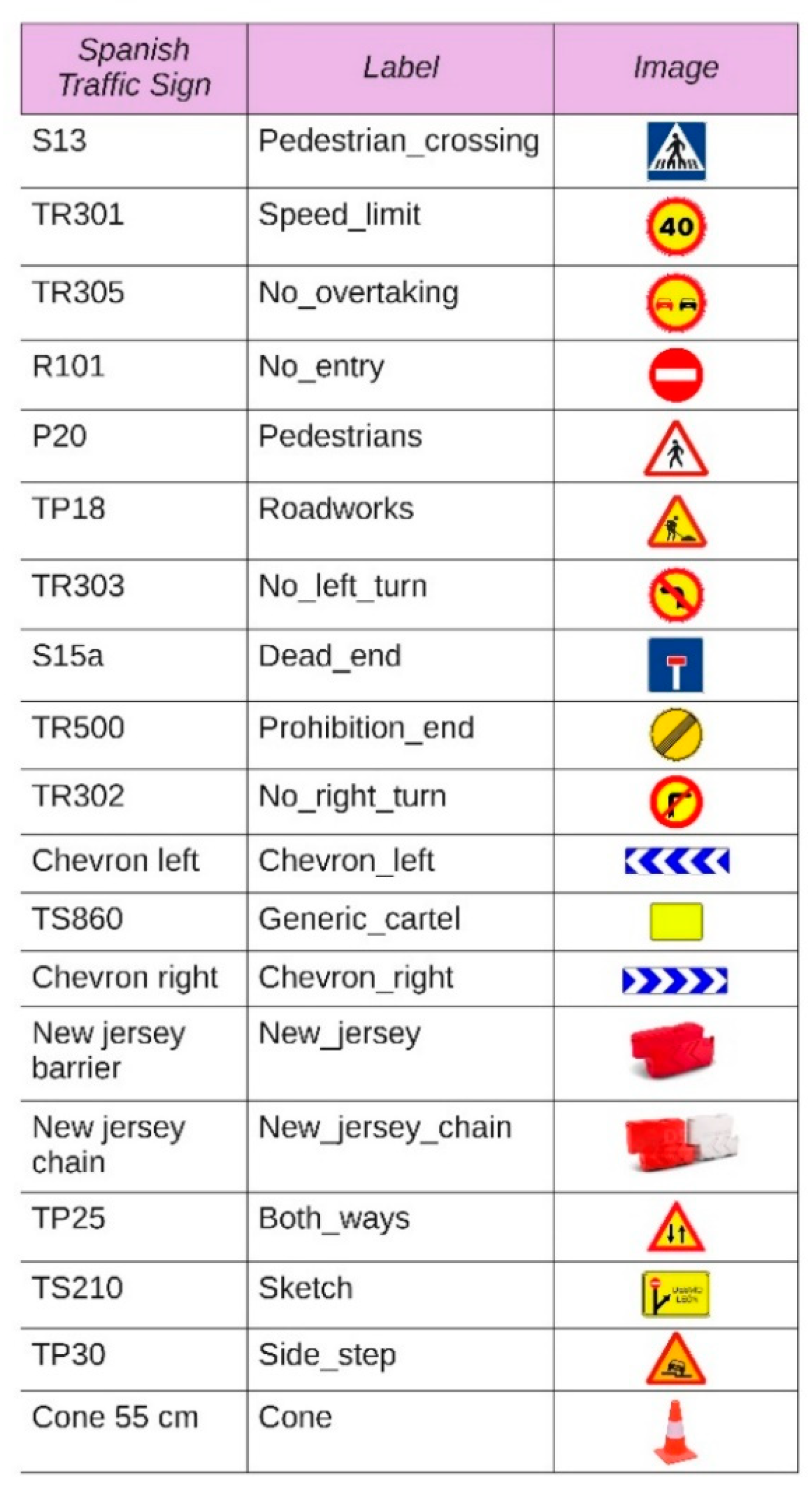
| Traffic Sign Class | Train | Test |
|---|---|---|
| Pedestrian_crossing | 24,189 | 2687 |
| Speed_limit | 9279 | 1137 |
| No_overtaking | 2037 | 263 |
| No_entry | 1374 | 167 |
| Pedestrians | 1305 | 160 |
| Roadworks | 1280 | 169 |
| No_left_turn | 416 | 47 |
| Dead_end | 367 | 41 |
| Prohibition_end | 270 | 34 |
| No_right_turn | 170 | 22 |
| Chevron_left | 141 | 20 |
| Generic_cartel | 139 | 15 |
| Chevron_right | 107 | 19 |
| New_jersey | 102 | 16 |
| New_jersey_chain | 92 | 14 |
| Both_ways | 94 | 10 |
| Sketch | 85 | 9 |
| Side_step | 63 | 7 |
| Cone | 14 | 2 |
| Traffic Sign Class | Average Precision (AP) % | Mean Average Precision (mAP) % |
|---|---|---|
| New_jersey_chain | 95.03 | 56.30 |
| Pedestrian_crossing | 93.55 | |
| No_overtaking | 89.49 | |
| No_entry | 88.58 | |
| Prohibition_end | 81.50 | |
| Pedestrians | 80.16 | |
| Sketch | 79.76 | |
| Speed_limit | 78.55 | |
| Side_step | 71.79 | |
| No_left_turn | 70.75 | |
| Dead_end | 68.08 | |
| Roadworks | 60.66 | |
| No_right_turn | 42.70 | |
| Chevron_left | 37.77 | |
| Chevron_right | 23.79 | |
| New_jersey | 3.90 | |
| Both_ways | 3.65 | |
| Generic_cartel | 0.00 | |
| Cone | 0 |
| Average Precision Type | Area Size | Average Precision (AP) % |
|---|---|---|
| or AP | All | 43.8 |
| All | 60.5 | |
| All | 51.8 | |
| Small | 30.6 | |
| Medium | 47.3 | |
| Large | 66.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naranjo, M.; Fuentes, D.; Muelas, E.; Díez, E.; Ciruelo, L.; Alonso, C.; Abenza, E.; Gómez-Espinosa, R.; Luengo, I. Object Detection-Based System for Traffic Signs on Drone-Captured Images. Drones 2023, 7, 112. https://doi.org/10.3390/drones7020112
Naranjo M, Fuentes D, Muelas E, Díez E, Ciruelo L, Alonso C, Abenza E, Gómez-Espinosa R, Luengo I. Object Detection-Based System for Traffic Signs on Drone-Captured Images. Drones. 2023; 7(2):112. https://doi.org/10.3390/drones7020112
Chicago/Turabian StyleNaranjo, Manuel, Diego Fuentes, Elena Muelas, Enrique Díez, Luis Ciruelo, César Alonso, Eduardo Abenza, Roberto Gómez-Espinosa, and Inmaculada Luengo. 2023. "Object Detection-Based System for Traffic Signs on Drone-Captured Images" Drones 7, no. 2: 112. https://doi.org/10.3390/drones7020112